26 Análisis de encuestas
26.1 Resumen
Esta página muestra el uso de varios paquetes para el análisis de encuestas.
La mayoría de los paquetes R de encuestas se basan en el paquete survey para realizar análisis ponderados. Utilizaremos survey, así como srvyr (una envoltura para survey que permite la codificación al estilo tidyverse) y gtsummary (una envoltura para survey que permite obtener tablas listas para su publicación). Aunque el paquete original survey no permite la codificación al estilo tidyverse, tiene la ventaja añadida de permitir modelos lineales generalizados ponderados por la encuesta (que se añadirán a esta página más adelante). También demostraremos el uso de una función del paquete sitrep para crear ponderaciones de muestreo (n.b. este paquete no está todavía en CRAN, pero se puede instalar desde github).
La mayor parte de esta página se basa en el trabajo realizado para el proyecto “R4Epis”; para ver el código detallado y las plantillas R-markdown del mismo, consulta la página github de “R4Epis”. Parte del código basado en el paquete de encuestas se basa en las primeras versiones de los estudios de caso de EPIET.
Actualmente, esta página no aborda el cálculo del tamaño de la muestra ni el muestreo. Para una calculadora del tamaño muestral fácil de usar, consulta OpenEpi. La página de conceptos básicos de los SIG del manual tendrá eventualmente una sección sobre muestreo aleatorio espacial, y esta página tendrá eventualmente una sección sobre marcos de muestreo así como cálculos del tamaño de la muestra.
- Datos de encuestas
- Tiempo de observación
- Ponderación
- Objetos de diseño de la encuesta
- Análisis descriptivo
- Proporciones ponderadas
- Tasas ponderadas
26.2 Preparación
Paquetes
Este trozo de código muestra la carga de los paquetes necesarios para los análisis. En este manual destacamos p_load() de pacman, que instala el paquete si es necesario y lo carga para su uso. También se pueden cargar paquetes con library() de R base . Consulta la página sobre fundamentos de R para obtener más información sobre los paquetes de R.
Aquí también mostramos el uso de la función p_load_gh() de pacman para instalar y cargar un paquete de github que aún no ha sido publicado en CRAN.
## load packages from CRAN
pacman::p_load(rio, # Importación de fichero
here, # Localizador de archivos
tidyverse, # gestión de datos + gráficos ggplot2
tsibble, # manejar conjuntos de datos de series temporales
survey, # para funciones de encuesta
srvyr, # paquete dplyr para encuestas
gtsummary, # paquete de encuestas para producir tablas
apyramid, # un paquete dedicado a crear pirámides de edad
patchwork, # para combinar ggplots
ggforce # para gráficos aluviales/sankey
)
## load packages from github
pacman::p_load_gh(
"r4epi/sitrep" # para el tiempo de observación / funciones de ponderación
)Carga de datos
El conjunto de datos de ejemplo utilizado en esta sección:
- datos de encuesta de mortalidad ficticia.
- recuentos de población ficticios para la zona de la encuesta.
- diccionario de datos para los datos de la encuesta de mortalidad ficticia.
Se basa en la encuesta pre-aprobada por la junta de revisión ética de MSF OCA. Los datos ficticios se produjeron como parte del proyecto “R4Epis”. Todo ello se basa en los datos recopilados mediante KoboToolbox, un software de recopilación de datos basado en Open Data Kit.
Kobo permite exportar tanto los datos recogidos como el diccionario de datos para ese conjunto de datos. Recomendamos encarecidamente hacer esto, ya que simplifica la limpieza de los datos y es útil para buscar variables/preguntas.
CONSEJO: El diccionario de datos de Kobo tiene nombres de variables en la columna “name” de la hoja de la encuesta. Los valores posibles para cada variable se especifican en la hoja de opciones. En la hoja de opciones, “name” tiene el valor acortado y las columnas “label::english” y “label::french” tienen las versiones largas correspondientes. Si utilizas la función msf_dict_survey() del paquete epidict para importar un archivo excel del diccionario Kobo, éste se reformulará para que pueda utilizarse fácilmente para recodificar.
PRECAUCIÓN: El conjunto de datos de ejemplo no es lo mismo que una exportación (ya que en Kobo se exportan los diferentes niveles del cuestionario de forma individual) - Mira la sección de datos de la encuesta más abajo para fusionar los diferentes niveles.
Los datos se importan mediante la función import() del paquete rio. Consulta la página sobre importación y exportación para conocer las distintas formas de importar datos.
# importar los datos de la encuesta
survey_data <- rio::import("survey_data.xlsx")
# importar el diccionario en R
survey_dict <- rio::import("survey_dict.xlsx") Más abajo se muestran las primeras 10 filas de la encuesta
También queremos importar los datos de la población de muestreo para poder elaborar las ponderaciones adecuadas. Estos datos pueden estar en diferentes formatos, sin embargo sugerimos tenerlos como se ve a continuación (esto puede ser simplemente escrito en un Excel).
# importar los datos de población
population <- rio::import("population.xlsx")A continuación se muestran las 10 primeras filas de la encuesta.
En el caso de las encuestas por conglomerados, es posible que desees añadir ponderaciones de la encuesta a nivel de conglomerado. Puedes introducir estos datos como se indica más arriba. Alternativamente, si sólo hay unos pocos recuentos, éstos podrían introducirse como se indica a continuación en un tibble. En cualquier caso, tendrá que tener una columna con un identificador de conglomerado que coincida con los datos de tu encuesta, y otra columna con el número de hogares en cada conglomerado.
Limpieza de datos
A continuación se asegura que la columna de fechas tenga el formato adecuado. Hay varias otras maneras de hacer esto (ver la página Trabajar con fechas para más detalles), sin embargo, usar el diccionario para definir las fechas es rápido y fácil.
También creamos una variable de grupo de edad utilizando la función age_categories() de epikit - véase la sección del manual de limpieza de datos para más detalles. Además, creamos una variable de carácter que define en qué distrito se encuentran las distintas agrupaciones.
Por último, recodificamos todas las variables sí/no en variables VERDADERO/FALSO, ya que de lo contrario no pueden ser utilizadas por las funciones de proporción de survey.
## seleccionar los nombres de las variables de fecha del diccionario
DATEVARS <- survey_dict %>%
filter(type == "date") %>%
filter(name %in% names(survey_data)) %>%
## filtrar para que coincidan los nombres de las columnas de los datos
pull(name) # selecciona vars de fecha
## cambiar a fechas
survey_data <- survey_data %>%
mutate(across(all_of(DATEVARS), as.Date))
## añadir los que sólo tienen edad en meses a la variable año (dividir por doce)
survey_data <- survey_data %>%
mutate(age_years = if_else(is.na(age_years),
age_months / 12,
age_years))
## definir variable de grupo de edad
survey_data <- survey_data %>%
mutate(age_group = age_categories(age_years,
breakers = c(0, 3, 15, 30, 45)
))
## create a character variable based off groups of a different variable
survey_data <- survey_data %>%
mutate(health_district = case_when(
cluster_number %in% c(1:5) ~ "district_a",
TRUE ~ "district_b"
))
## seleccionar los nombres de las variables yes/no del diccionario
YNVARS <- survey_dict %>%
filter(type == "yn") %>%
filter(name %in% names(survey_data)) %>%
## filter to match the column names of your data
pull(name) # select yn vars
## cambiar a fechas
survey_data <- survey_data %>%
mutate(across(all_of(YNVARS),
str_detect,
pattern = "yes"))26.3 Datos de encuestas
Existen numerosos diseños de muestreo que pueden utilizarse para las encuestas. Aquí mostraremos el código para: - Estratificado - Conglomerado - Estratificado y conglomerado
Como se ha descrito anteriormente (dependiendo de cómo se diseñe el cuestionario) los datos de cada nivel se exportarían como unos datos separados desde Kobo. En nuestro ejemplo hay un nivel para los hogares y un nivel para los individuos dentro de esos hogares.
Estos dos niveles están vinculados por un identificador único. Para unos datos de Kobo, esta variable es “_index” en el nivel del hogar, que coincide con “_parent_index” en el nivel individual. Esto creará nuevas filas para el hogar con cada individuo que coincida, véase la sección del manual sobre unir datos para más detalles.
## unir los datos de individuos y hogares para formar un conjunto de datos completo
survey_data <- left_join(survey_data_hh,
survey_data_indiv,
by = c("_index" = "_parent_index"))
## crear un identificador único combinando los índices de los dos niveles
survey_data <- survey_data %>%
mutate(uid = str_glue("{index}_{index_y}"))26.4 Tiempo de observación
En el caso de las encuestas de mortalidad, queremos saber cuánto tiempo ha estado presente cada individuo en el lugar para poder calcular una tasa de mortalidad adecuada para nuestro periodo de interés. Esto no es relevante para todas las encuestas, pero en particular para las encuestas de mortalidad es importante, ya que se realizan con frecuencia entre poblaciones móviles o desplazadas.
Para ello, primero definimos nuestro periodo de interés, también conocido como periodo de recuerdo (es decir, el tiempo sobre el que se pide a los participantes que informen al responder a las preguntas). A continuación, podemos utilizar este periodo para establecer las fechas inadecuadas como ausentes, es decir, si las muertes se notifican fuera del periodo de interés.
## establecer el inicio/fin del periodo de recuperación
## puede cambiarse a variables de fecha de los datos
## (por ejemplo, fecha de llegada y fecha del cuestionario)
survey_data <- survey_data %>%
mutate(recall_start = as.Date("2018-01-01"),
recall_end = as.Date("2018-05-01")
)
#establecer fechas inapropiadas a NA basado en reglas
## p.ej. llegadas antes del inicio, salidas después del final
survey_data <- survey_data %>%
mutate(
arrived_date = if_else(arrived_date < recall_start,
as.Date(NA),
arrived_date),
birthday_date = if_else(birthday_date < recall_start,
as.Date(NA),
birthday_date),
left_date = if_else(left_date > recall_end,
as.Date(NA),
left_date),
death_date = if_else(death_date > recall_end,
as.Date(NA),
death_date)
)Entonces podemos utilizar nuestras variables de fecha para definir las fechas de inicio y fin de cada individuo. Podemos utilizar la función find_start_date() de sitrep para afinar la elección de las fechas y luego utilizarla para calcular la diferencia entre días (persona-tiempo).
Fecha de inicio: Evento de llegada más temprano dentro del período de recogida O bien el inicio del período de recogida (definidas de antemano), o una fecha posterior al inicio de la recogida, si procede (por ejemplo, llegadas o nacimientos)
Fecha de finalización: Evento de salida más temprano dentro del periodo de recogida O bien el final del periodo de recogida, o una fecha anterior al final de la recogida si procede (por ejemplo, salidas, fallecimientos)
## crear nuevas variables para las fechas/causas de inicio y fin
survey_data <- survey_data %>%
## elegir la fecha más temprana introducida en la encuesta
## de nacimientos, llegadas a hogares y llegadas a
find_start_date("birthday_date",
"arrived_date",
period_start = "recall_start",
period_end = "recall_end",
datecol = "startdate",
datereason = "startcause"
) %>%
## elegir la fecha más temprana introducida en la encuesta
## de salidas del campamento, fallecimiento y fin del estudio
find_end_date("left_date",
"death_date",
period_start = "recall_start",
period_end = "recall_end",
datecol = "enddate",
datereason = "endcause"
)
## etiquetar los que estaban presentes al inicio/final (excepto nacimientos/muertes)
survey_data <- survey_data %>%
mutate(
## rellenar la fecha de inicio para que sea el comienzo del periodo de recuerdo (para los vacíos)
startdate = if_else(is.na(startdate), recall_start, startdate),
## establecer la causa de inicio como presente al inicio si es igual al periodo de retirada
## a menos que sea igual a la fecha de nacimiento
startcause = if_else(startdate == recall_start & startcause != "birthday_date",
"Present at start", startcause),
## rellenar la fecha final para que sea el final del periodo de retirada (para los que estén vacíos)
enddate = if_else(is.na(enddate), recall_end, enddate),
## establecer la causa final para que esté presente al final si es igual a recall end
## a menos que sea igual a la fecha de defunción
endcause = if_else(enddate == recall_end & endcause != "death_date",
"Present at end", endcause))
## Definir el tiempo de observación en días
survey_data <- survey_data %>%
mutate(obstime = as.numeric(enddate - startdate))26.5 Ponderación
Es importante que elimines las observaciones erróneas antes de añadir los pesos de la encuesta. Por ejemplo, si hay observaciones con tiempo de observación negativo, tendrás que comprobarlas (puedes hacerlo con la función assert_positive_timespan() de sitrep. Otra cosa es si quieres eliminar las filas vacías (por ejemplo, con drop_na(uid)) o eliminar los duplicados (véase la sección del manual sobre De-duplicación para más detalles). También hay que eliminar las que no tienen consentimiento.
En este ejemplo, filtramos los casos que queremos eliminar y los almacenamos en un dataframe separado, de forma que podamos describir los que fueron excluidos de la encuesta. A continuación, utilizamos la función anti_join() de dplyr para eliminar estos casos descartados de los datos de nuestra encuesta.
PELIGRO: No puede haber valores faltantes en la variable de peso, ni en ninguna de las variables relevantes para el diseño de la encuesta (por ejemplo, edad, sexo, estratos o variables de agrupación).
## almacena los casos que abandona para poder describirlos (por ejemplo, no consentir
## o pueblo/cluster equivocado)
dropped <- survey_data %>%
filter(!consent | is.na(startdate) | is.na(enddate) | village_name == "other")
## utilizar los casos descartados para eliminar las filas no utilizadas de los datos de la encuesta
survey_data <- anti_join(survey_data, dropped, by = names(dropped))Como se ha mencionado anteriormente, demostramos cómo añadir ponderaciones para tres diseños de estudio diferentes (estratificado, conglomerado y conglomerado estratificado). Estos requieren información sobre la población de origen y/o los conglomerados encuestados. Utilizaremos el código de conglomerado estratificado para este ejemplo, pero utiliza el que sea más apropiado para tu diseño de estudio.
# estratificado ------------------------------------------------------------------
# crear una variable llamada "surv_weight_strata"
# contiene ponderaciones para cada individuo - por grupo de edad, sexo y distrito sanitario
survey_data <- add_weights_strata(x = survey_data,
p = population,
surv_weight = "surv_weight_strata",
surv_weight_ID = "surv_weight_ID_strata",
age_group, sex, health_district)
## cluster ---------------------------------------------------------------------
# obtiene el número de personas de individuos entrevistados por hogar
# añade una variable con los recuentos de la variable índice del hogar (padre)
survey_data <- survey_data %>%
add_count(index, name = "interviewed")
## crear ponderaciones de clusters
survey_data <- add_weights_cluster(x = survey_data,
cl = cluster_counts,
eligible = member_number,
interviewed = interviewed,
cluster_x = village_name,
cluster_cl = cluster,
household_x = index,
household_cl = households,
surv_weight = "surv_weight_cluster",
surv_weight_ID = "surv_weight_ID_cluster",
ignore_cluster = FALSE,
ignore_household = FALSE)
# estratificado y cluster ------------------------------------------------------
# crear un peso de encuesta para cluster y estratos
survey_data <- survey_data %>%
mutate(surv_weight_cluster_strata = surv_weight_strata * surv_weight_cluster)26.6 Objetos de diseño de la encuesta
Crea un objeto de encuesta de acuerdo con el diseño de tu estudio. Se utiliza de la misma manera que los dataframes para calcular las proporciones ponderadas, etc. Asegúrate que todas las variables necesarias están creadas antes de esto.
Hay cuatro opciones, comenta las que no utilizas: - Aleatorio simple - Estratificado - Conglomerado - Conglomerado estratificado
Para esta plantilla, supondremos que agrupamos las encuestas en dos estratos distintos (distritos sanitarios A y B). Por lo tanto, para obtener las estimaciones globales necesitamos haber combinado las ponderaciones de los grupos y de los estratos.
Como se ha mencionado anteriormente, hay dos paquetes disponibles para hacer esto. El clásico es survey y luego hay un paquete envolvente llamado srvyr que hace objetos y funciones amigables con tidyverse. Mostraremos ambos, pero ten en cuenta que la mayor parte del código de este capítulo utilizará objetos basados en srvyr. La única excepción es que el paquete gtsummary sólo acepta objetos de survey.
Paquete survey
El paquete survey utiliza efectivamente la codificación de R base, por lo que no es posible utilizar pipes (%>%) u otra sintaxis de dplyr. Con el paquete de survey utilizamos la función svydesign() para definir un objeto de encuesta con clusters, pesos y estratos adecuados.
NOTA: necesitamos utilizar la tilde (~) delante de las variables, esto es porque el paquete utiliza la sintaxis de R base de asignación de variables basadas en fórmulas.
# aleatorio simple ---------------------------------------------------------------
base_survey_design_simple <- svydesign(ids = ~1, # 1 para cluster sin ids
weights = NULL, # no se añade peso
strata = NULL, # el muestreo fue simple (sin estratos)
data = survey_data # hay que especificar los datos
)
## estratificado ------------------------------------------------------------------
base_survey_design_strata <- svydesign(ids = ~1, # 1 para cluster sin ids
weights = ~surv_weight_strata, # variable de peso creada anteriormente
strata = ~health_district, # el muestreo se estratificó por distrito
data = survey_data # hay que especificar los datos
)
# cluster ---------------------------------------------------------------------
base_survey_design_cluster <- svydesign(ids = ~village_name, # ids de cluster
weights = ~surv_weight_cluster, # variable de peso creada anteriormente
strata = NULL, # el muestreo fue simple (sin estratos)
data = survey_data # hay que especificar los datos
)
# cluster estratificado ----------------------------------------------------------
base_survey_design <- svydesign(ids = ~village_name, # ids de cluster
weights = ~surv_weight_cluster_strata, # variable de peso creada anteriormente
strata = ~health_district, # el muestreo se estratificó por distrito
data = survey_data # hay que especificar los datos
)Paquete Srvyr
Con el paquete srvyr podemos utilizar la función as_survey_design(), que tiene los mismos argumentos que la anterior pero permite los pipes (%>%), por lo que no es necesario utilizar la tilde (~).
# aleatorio simple ---------------------------------------------------------------
survey_design_simple <- survey_data %>%
as_survey_design(ids = 1, # 1 para cluster sin ids
weights = NULL, # no se añade peso
strata = NULL # el muestreo fue simple (sin estratos)
)
## estratificado ------------------------------------------------------------------
survey_design_strata <- survey_data %>%
as_survey_design(ids = 1, # 1 para cluster sin ids
weights = surv_weight_strata, # variable de peso creada anteriormente
strata = health_district # el muestreo se estratificó por distrito
)
## cluster ---------------------------------------------------------------------
survey_design_cluster <- survey_data %>%
as_survey_design(ids = village_name, # ids de cluster
weights = surv_weight_cluster, # variable de peso creada anteriormente
strata = NULL # el muestreo fue simple (sin estratos)
)
# cluster estratificado ----------------------------------------------------------
survey_design <- survey_data %>%
as_survey_design(ids = village_name, # ids de cluster
weights = surv_weight_cluster_strata, # variable de peso creada anteriormente
strata = health_district # el muestreo se estratificó por distrito
)26.7 Análisis descriptivo
El análisis descriptivo básico y la visualización se tratan extensamente en otros capítulos del manual, por lo que no nos detendremos en ellos aquí. Para más detalles, consulta los capítulos sobre tablas descriptivas, pruebas estadísticas, tablas para presentaciones, conceptos básicos de ggplot e informes con R markdown.
En este apartado nos centraremos en cómo investigar el sesgo de la muestra y visualizarlo. También veremos cómo visualizar el flujo de la población en un entorno de encuesta utilizando diagramas aluviales/sankey.
En general, debes considerar incluir los siguientes análisis descriptivos:
- Número final de agrupaciones, hogares e individuos incluidos
- Número de personas excluidas y motivos de la exclusión
- Mediana (rango) del número de hogares por grupo y de individuos por hogar
Sesgo de muestreo
Compara las proporciones de cada grupo de edad entre tu muestra y la población de origen. Esto es importante para poder resaltar el posible sesgo de muestreo. También puedes repetir esta operación para ver las distribuciones por sexo.
Ten en cuenta que estos valores-p son sólo indicativos, y que una discusión descriptiva (o la visualización con las pirámides de edad que aparecen a continuación) de las distribuciones en tu muestra de estudio en comparación con la población de origen es más importante que la prueba binomial en sí. Esto se debe a que el aumento del tamaño de la muestra suele dar lugar a diferencias que pueden ser irrelevantes después de ponderar los datos.
## recuentos y datos de la población de estudio
ag <- survey_data %>%
group_by(age_group) %>%
drop_na(age_group) %>%
tally() %>%
mutate(proportion = n / sum(n),
n_total = sum(n))
## recuentos y datos de la población de origen
propcount <- population %>%
group_by(age_group) %>%
tally(population) %>%
mutate(proportion = n / sum(n))
## unir las columnas de dos tablas, agrupar por edad, y realizar una
## prueba binomial para ver si n/total es significativamente diferente de la
## proporción de población.
## el sufijo aquí añade texto al final de las columnas en cada uno de los dos conjuntos de datos
left_join(ag, propcount, by = "age_group", suffix = c("", "_pop")) %>%
group_by(age_group) %>%
## broom::tidy(binom.test()) crea un dataframe a partir de la prueba binomial y
## añadirá las variables p.value, parameter, conf.low, conf.high, method, y
## alternativa. Aquí sólo utilizaremos p.value. Puede incluir otras
## columnas si desea informar de los intervalos de confianza
mutate(binom = list(broom::tidy(binom.test(n, n_total, proportion_pop)))) %>%
unnest(cols = c(binom)) %>% # important for expanding the binom.test data frame
mutate(proportion_pop = proportion_pop * 100) %>%
## Ajuste de los valores p para corregir los falsos positivos
## (porque la prueba de múltiples grupos de edad). Esto sólo hará
## una diferencia si tiene muchas categorías de edad
mutate(p.value = p.adjust(p.value, method = "holm")) %>%
## Mostrar sólo valores p superiores a 0,001 (los inferiores se reportan como <0,001)
mutate(p.value = ifelse(p.value < 0.001,
"<0.001",
as.character(round(p.value, 3)))) %>%
## renombra las columnas adecuadamente
select(
"Age group" = age_group,
"Study population (n)" = n,
"Study population (%)" = proportion,
"Source population (n)" = n_pop,
"Source population (%)" = proportion_pop,
"P-value" = p.value
)## # A tibble: 5 × 6
## # Groups: Age group [5]
## `Age group` `Study population (n)` `Study population (%)` `Source population (n)` `Source population (%)` `P-value`
## <chr> <int> <dbl> <dbl> <dbl> <chr>
## 1 0-2 12 0.0256 1360 6.8 <0.001
## 2 3-14 42 0.0896 7244 36.2 <0.001
## 3 15-29 64 0.136 5520 27.6 <0.001
## 4 30-44 52 0.111 3232 16.2 0.002
## 5 45+ 299 0.638 2644 13.2 <0.001Pirámides demográficas
Las pirámides demográficas (o de edad y sexo) son una forma sencilla de visualizar la distribución de la población de la encuesta. También vale la pena considerar la creación de tablas descriptivas de edad y sexo por estratos de la encuesta. Demostraremos el uso del paquete apyramid, ya que permite las proporciones ponderadas utilizando nuestro objeto de diseño de la encuesta creado anteriormente. Otras opciones para crear pirámides demográficas se tratan ampliamente en ese capítulo del manual. También utilizaremos una función envolvente de sitrep llamada age_pyramid() que ahorra algunas líneas de codificación para producir un gráfico con proporciones.
Al igual que con el test binomial formal de la diferencia, vista anteriormente en la sección de sesgo de muestreo, aquí estamos interesados en visualizar si nuestra población muestreada es sustancialmente diferente de la población de origen y si la ponderación corrige esta diferencia. Para ello, utilizaremos el paquete patchwork para mostrar nuestras visualizaciones ggplot una al lado de la otra; para más detalles, consulta la sección sobre la combinación de gráficos en el capítulo de consejos de ggplot del manual. Visualizaremos nuestra población de origen, nuestra población de encuesta no ponderada y nuestra población de encuesta ponderada. También puedes considerar la posibilidad de visualizar por cada estrato de tu encuesta - en nuestro ejemplo aquí sería utilizando el argumento stack_by = "health_district" (ver ?plot_age_pyramid para más detalles).
NOTA: Los ejes-x e y están invertidos en las pirámides
## define los límites y etiquetas del eje-x ---------------------------------------------
## (actualiza estos números para que sean los valores del gráfico)
max_prop <- 35 ## elige la proporción más alta que se quiere mostrar
step <- 5 # elige el espacio que se desea entre etiquetas
## esta parte define el vector usando los números anteriores con saltos de eje
breaks <- c(
seq(max_prop/100 * -1, 0 - step/100, step/100),
0,
seq(0 + step / 100, max_prop/100, step/100)
)
## esta parte define el vector usando los números anteriores con los límites del eje
limits <- c(max_prop/100 * -1, max_prop/100)
## esta parte define el vector usando los números anteriores con las etiquetas de los ejes
labels <- c(
seq(max_prop, step, -step),
0,
seq(step, max_prop, step)
)
## crear gráficos individualmente --------------------------------------------------
## representar la población de origen
## nota: esto necesita estar colapsado para la población total (es decir, eliminando los distritos sanitarios)
source_population <- population %>%
## asegurar que la edad y el sexo son factores
mutate(age_group = factor(age_group,
levels = c("0-2",
"3-14",
"15-29",
"30-44",
"45+")),
sex = factor(sex)) %>%
group_by(age_group, sex) %>%
## sumar los recuentos de cada distrito sanitario
summarise(population = sum(population)) %>%
## eliminar la agrupación para poder calcular la proporción global
ungroup() %>%
mutate(proportion = population / sum(population)) %>%
## representar la pirámide
age_pyramid(
age_group = age_group,
split_by = sex,
count = proportion,
proportional = TRUE) +
## mostrar sólo la etiqueta del eje-y (por lo demás se repite en los tres gráficos)
labs(title = "Source population",
y = "",
x = "Age group (years)") +
## hacer que el eje-x sea el mismo para todos los gráficos
scale_y_continuous(breaks = breaks,
limits = limits,
labels = labels)
## dibujar la población de la muestra no ponderada
sample_population <- age_pyramid(survey_data,
age_group = "age_group",
split_by = "sex",
proportion = TRUE) +
## mostrar sólo la etiqueta del eje-x (por lo demás se repite en los tres gráficos)
labs(title = "Unweighted sample population",
y = "Proportion (%)",
x = "") +
## hacer que el eje-x sea el mismo para todos los gráficos
scale_y_continuous(breaks = breaks,
limits = limits,
labels = labels)
## dibujar la población de la muestra ponderada
weighted_population <- survey_design %>%
## asegurar que las variables son factores
mutate(age_group = factor(age_group),
sex = factor(sex)) %>%
age_pyramid(
age_group = "age_group",
split_by = "sex",
proportion = TRUE) +
## mostrar sólo la etiqueta del eje-x (por lo demás se repite en los tres gráficos)
labs(title = "Weighted sample population",
y = "",
x = "") +
## hacer que el eje-x sea el mismo para todos los gráficos
scale_y_continuous(breaks = breaks,
limits = limits,
labels = labels)
## combinar los tres gráficos ----------------------------------------------------
## combinar tres gráficos uno al lado del otro usando +
source_population + sample_population + weighted_population +
## sólo mostrar una leyenda y definir tema
## observar el uso de & para combinar el tema con plot_layout()
plot_layout(guides = "collect") &
theme(legend.position = "bottom", # mover la leyenda a la parte inferior
legend.title = element_blank(), # eliminar el título
text = element_text(size = 18), # cambiar el tamaño del texto
axis.text.x = element_text(angle = 45, hjust = 1, vjust = 1) # cambiar el texto del eje-x
)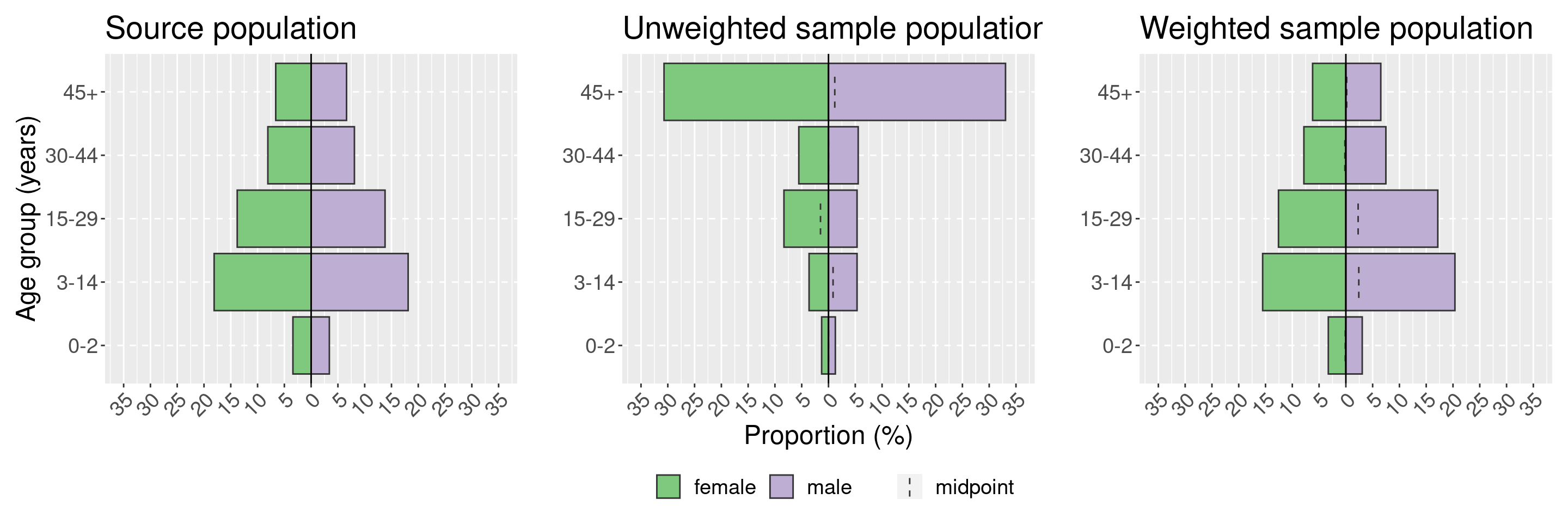
Diagrama aluvial/sankey
Visualizar los puntos de partida y los resultados de los individuos puede ser muy útil para obtener una visión general. Su aplicación es bastante obvia en el caso de las poblaciones móviles, pero hay muchas otras aplicaciones, como las cohortes o cualquier otra situación en la que haya transiciones de estados para los individuos. Estos diagramas tienen varios nombres diferentes, como diagramas aluviales, de sankey y paralelos; los detalles se encuentran en el capítulo del manual sobre diagramas y gráficos.
## resumir datos
flow_table <- survey_data %>%
count(startcause, endcause, sex) %>% # get counts
gather_set_data(x = c("startcause", "endcause")) # cambiar el formato del gráfico
## representa los datos
## en el eje-x están las causas de inicio y fin
## gather_set_data genera un ID para cada combinación posible
## dividiendo por y da las posibles combinaciones inicio/fin
## el valor como n lo da como recuentos (también podría cambiarse a proporción)
ggplot(flow_table, aes(x, id = id, split = y, value = n)) +
## colorear las líneas por sexo
geom_parallel_sets(aes(fill = sex), alpha = 0.5, axis.width = 0.2) +
## rellenar de gris los cuadros de etiquetas
geom_parallel_sets_axes(axis.width = 0.15, fill = "grey80", color = "grey80") +
## cambiar el color y el ángulo del texto (hay que ajustarlo)
geom_parallel_sets_labels(color = "black", angle = 0, size = 5) +
## eliminar las etiquetas de los ejes
theme_void()+
## mover la leyenda a la parte inferior
theme(legend.position = "bottom") 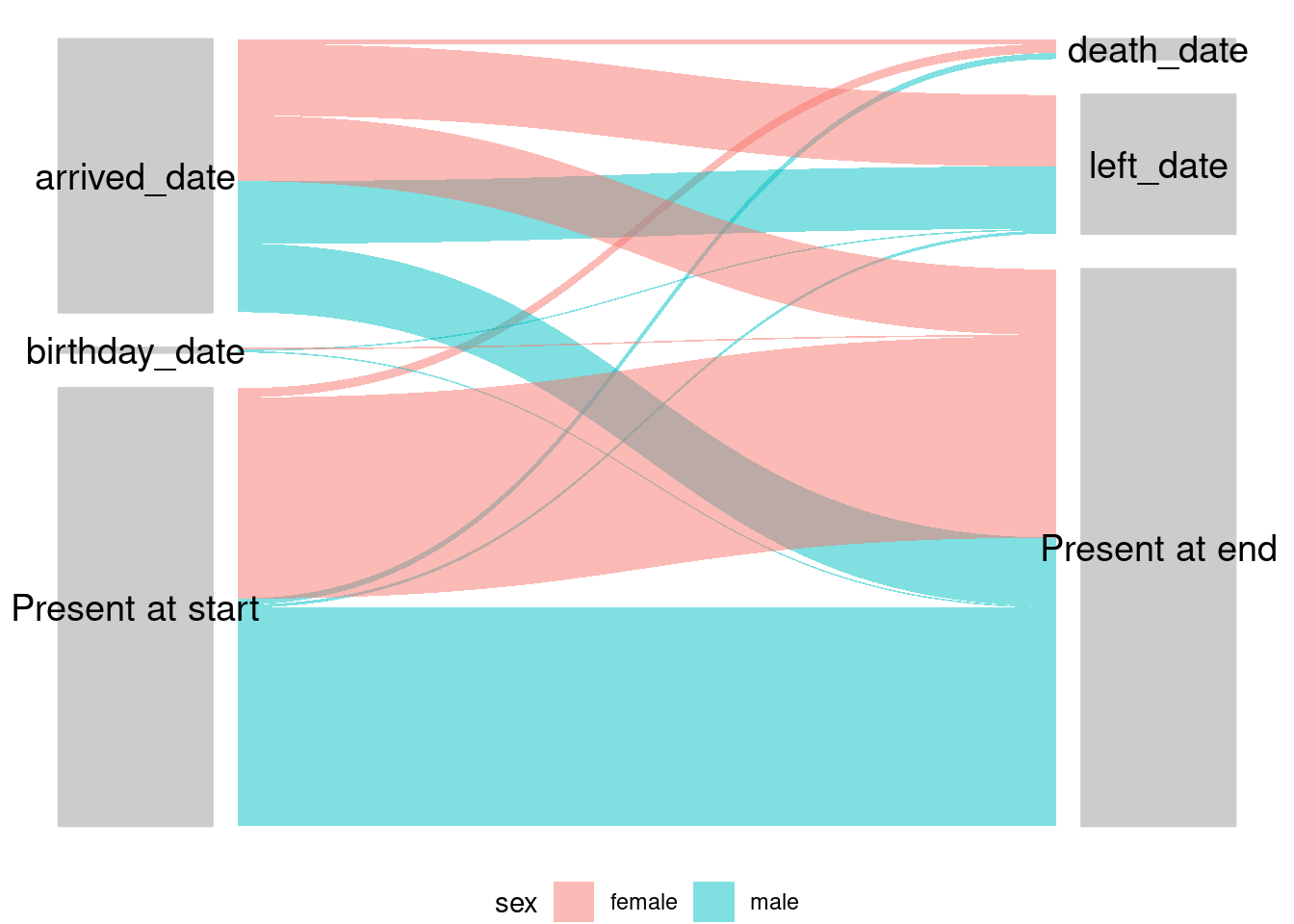
26.8 Proporciones ponderadas
Esta sección detallará cómo producir tablas para recuentos y proporciones ponderadas, con los intervalos de confianza asociados y el efecto del diseño. Hay cuatro opciones diferentes que utilizan funciones de los siguientes paquetes: survey, srvyr, sitrep y gtsummary. Para una codificación mínima que produzca una tabla de estilo epidemiológico estándar, recomendaríamos la función sitrep - que es una envoltura para el código srvyr; Ten en cuenta, sin embargo, que esto no está todavía en CRAN y puede cambiar en el futuro. Por lo demás, es probable que el código de survey sea el más estable a largo plazo, mientras que srvyr se adaptará mejor a los flujos de trabajo de tidyverse. Aunque las funciones de gtsummary tienen mucho potencial, parecen ser experimentales e incompletas en el momento de escribir este artículo.
Paquete survey
Podemos utilizar la función svyciprop() de survey para obtener las proporciones ponderadas y los correspondientes intervalos de confianza del 95%. Se puede extraer un efecto de diseño apropiado utilizando la función svymean() en lugar de svyprop(). Cabe señalar que svyprop() sólo parece aceptar variables entre 0 y 1 (o TRUE/FALSE), por lo que las variables categóricas no funcionarán.
NOTA: Las funciones de survey también aceptan objetos de diseño srvyr, pero aquí hemos utilizado el objeto de diseño de survey sólo por coherencia
## producir recuentos ponderados
svytable(~died, base_survey_design)## died
## FALSE TRUE
## 1406244.43 76213.01
## producir proporciones ponderadas
svyciprop(~died, base_survey_design, na.rm = T)## 2.5% 97.5%
## died 0.0514 0.0208 0.12
## producir proporciones ponderadas
svymean(~died, base_survey_design, na.rm = T, deff = T) %>%
deff()## diedFALSE diedTRUE
## 3.755508 3.755508Podemos combinar las funciones de survey mostradas arriba en una función que definimos nosotros mismos a continuación, llamada svy_prop; y podemos entonces usar esa función junto con map() del paquete purrr para iterar sobre varias variables y crear una tabla. Consulta el capítulo de iteración del manual para obtener más detalles sobre purrr.
# Define la función para calcular recuentos ponderados, proporciones, IC y efecto de diseño.
# x es la variable entre comillas
# design es el objeto de diseño de la encuesta
svy_prop <- function(design, x) {
## poner la variable de interés en una fórmula
form <- as.formula(paste0( "~" , x))
## conservar sólo la columna TRUE de los recuentos de svytable
weighted_counts <- svytable(form, design)[[2]]
## calcular proporciones (multiplicar por 100 para obtener porcentajes)
weighted_props <- svyciprop(form, design, na.rm = TRUE) * 100
## extraer los intervalos de confianza y multiplicar para obtener los porcentajes
weighted_confint <- confint(weighted_props) * 100
## usar svymean para calcular el efecto del diseño y mantener sólo la columna TRUE
design_eff <- deff(svymean(form, design, na.rm = TRUE, deff = TRUE))[[TRUE]]
## combinar en un dataframe
full_table <- cbind(
"Variable" = x,
"Count" = weighted_counts,
"Proportion" = weighted_props,
weighted_confint,
"Design effect" = design_eff
)
## devuelve la tabla como un dataframe
full_table <- data.frame(full_table,
## remove the variable names from rows (is a separate column now)
row.names = NULL)
## cambiar los valores numéricos a numéricos
full_table[ , 2:6] <- as.numeric(full_table[, 2:6])
## devolver dataframe
full_table
}
## iterar sobre varias variables para crear una tabla
purrr::map(
## definir variables de interés
c("left", "died", "arrived"),
## indicar la función utilizada y los argumentos de dicha función (diseño)
svy_prop, design = base_survey_design) %>%
## colapsar la lista en un único dataframe
bind_rows() %>%
## redondear
mutate(across(where(is.numeric), round, digits = 1))## Variable Count Proportion X2.5. X97.5. Design.effect
## 1 left 701199.1 47.3 39.2 55.5 2.4
## 2 died 76213.0 5.1 2.1 12.1 3.8
## 3 arrived 761799.0 51.4 40.9 61.7 3.9Paquete Srvyr
Con srvyr podemos utilizar la sintaxis de dplyr para crear una tabla. Observa que se utiliza la función survey_mean() y se especifica el argumento de la proporción, y también que se utiliza la misma función para calcular el efecto del diseño. Esto se debe a que srvyr envuelve las dos funciones del paquete survey, svyciprop() y svymean(), que se utilizan en la sección anterior.
NOTA: Tampoco parece posible obtener proporciones a partir de variables categóricas utilizando srvyr, si lo necesitas, consulta la sección siguiente utilizando sitrep
## utilizar el objeto de diseño srvyr
survey_design %>%
summarise(
## producir los recuentos ponderados
counts = survey_total(died),
## producir proporciones ponderadas e intervalos de confianza
## multiplicar por 100 para obtener un porcentaje
props = survey_mean(died,
proportion = TRUE,
vartype = "ci") * 100,
## obtener el efecto del diseño
deff = survey_mean(died, deff = TRUE)) %>%
## conservar sólo las filas de interés
## (eliminar los errores estándar y repetir el cálculo de la proporción)
select(counts, props, props_low, props_upp, deff_deff)## # A tibble: 1 × 5
## counts props props_low props_upp deff_deff
## <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 76213. 5.14 2.08 12.1 3.76Aquí también podríamos escribir una función para iterar sobre múltiples variables utilizando el paquete purrr. Consulta el capítulo de iteración del manual para obtener más detalles sobre purrr.
# Definir función para calcular recuentos ponderados, proporciones, IC y efecto de diseño
# diseño es el objeto de diseño de su encuesta
# x es la variable entre comillas
srvyr_prop <- function(design, x) {
summarise(
## utilizando el objeto de diseño de la encuesta
design,
## producir los recuentos ponderados
counts = survey_total(.data[[x]]),
## producir proporciones ponderadas e intervalos de confianza
## multiplicar por 100 para obtener un porcentaje
props = survey_mean(.data[[x]],
proportion = TRUE,
vartype = "ci") * 100,
## produce the design effect
deff = survey_mean(.data[[x]], deff = TRUE)) %>%
## añadir el nombre de la variable
mutate(variable = x) %>%
## conservar sólo las filas de interés
## ( elimina los errores estándar y repite el cálculo de la proporción)
select(variable, counts, props, props_low, props_upp, deff_deff)
}
## iterar sobre varias variables para crear una tabla
purrr::map(
## definir variables de interés
c("left", "died", "arrived"),
## función de estado usando y argumentos para esa función (diseño)
~srvyr_prop(.x, design = survey_design)) %>%
## colapsar la lista en un único dataframe
bind_rows()## # A tibble: 3 × 6
## variable counts props props_low props_upp deff_deff
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 left 701199. 47.3 39.2 55.5 2.38
## 2 died 76213. 5.14 2.08 12.1 3.76
## 3 arrived 761799. 51.4 40.9 61.7 3.93Paquete Sitrep
La función tab_survey() de sitrep es una envoltura para srvyr, que permite crear tablas ponderadas con una codificación mínima. También permite calcular proporciones ponderadas para variables categóricas.
## utilizando el objeto de diseño de la encuesta
survey_design %>%
## pasar los nombres de las variables de interés sin comillas
tab_survey(arrived, left, died, education_level,
deff = TRUE, # calcular el efecto del diseño
pretty = TRUE # unir la proporción y el IC 95%
)## Warning: removing 257 missing value(s) from `education_level`## # A tibble: 9 × 5
## variable value n deff ci
## <chr> <chr> <dbl> <dbl> <chr>
## 1 arrived TRUE 761799. 3.93 51.4% (40.9--61.7)
## 2 arrived FALSE 720658. 3.93 48.6% (38.3--59.1)
## 3 left TRUE 701199. 2.38 47.3% (39.2--55.5)
## 4 left FALSE 781258. 2.38 52.7% (44.5--60.8)
## 5 died TRUE 76213. 3.76 5.1% (2.1--12.1)
## 6 died FALSE 1406244. 3.76 94.9% (87.9--97.9)
## 7 education_level higher 171644. 4.70 42.4% (26.9--59.7)
## 8 education_level primary 102609. 2.37 25.4% (16.2--37.3)
## 9 education_level secondary 130201. 6.68 32.2% (16.5--53.3)Paquete Gtsummary
Con gtsummary no parece haber todavía funciones incorporadas para añadir intervalos de confianza o efecto de diseño. Aquí mostramos cómo definir una función para añadir intervalos de confianza y luego añadir intervalos de confianza a una tabla gtsummary creada con la función tbl_svysummary().
confidence_intervals <- function(data, variable, by, ...) {
## extraer los intervalos de confianza y multiplicar para obtener porcentajes
props <- svyciprop(as.formula(paste0( "~" , variable)),
data, na.rm = TRUE)
## extraer los intervalos de confianza
as.numeric(confint(props) * 100) %>% ## convierte en numérico y multiplica por porcentaje
round(., digits = 1) %>% ## redondea a un dígito
c(.) %>% ## extrae los números de la matriz
paste0(., collapse = "-") ## combina a un solo caracter
}
## utilizando el objeto de diseño del paquete survey
tbl_svysummary(base_survey_design,
include = c(arrived, left, died), ## define las variables que se quieren incluir
statistic = list(everything() ~ c("{n} ({p}%)"))) %>% ## define las estadísticas de interés
add_n() %>% ## añade el total ponderado
add_stat(fns = everything() ~ confidence_intervals) %>% ## añade los ICs
## modify the column headers
modify_header(
list(
n ~ "**Weighted total (N)**",
stat_0 ~ "**Weighted Count**",
add_stat_1 ~ "**95%CI**"
)
)| Characteristic | Weighted total (N) | Weighted Count1 | 95%CI |
|---|---|---|---|
| arrived | 1,482,457 | 761,799 (51%) | 40.9-61.7 |
| left | 1,482,457 | 701,199 (47%) | 39.2-55.5 |
| died | 1,482,457 | 76,213 (5.1%) | 2.1-12.1 |
| 1 n (%) | |||
26.9 Razones ponderadas
Del mismo modo, para los ratios ponderados (como los ratios de mortalidad) puedes utilizar el paquete survey o srvyr. También se pueden escribir funciones (similares a las anteriores) para iterar sobre varias variables. También se podría crear una función para gtsummary como la anterior, pero actualmente no tiene una funcionalidad incorporada.
Paquete survey
ratio <- svyratio(~died,
denominator = ~obstime,
design = base_survey_design)
ci <- confint(ratio)
cbind(
ratio$ratio * 10000,
ci * 10000
)## obstime 2.5 % 97.5 %
## died 5.981922 1.194294 10.76955Paquete Srvyr
survey_design %>%
## proporción de encuesta utilizada para tener en cuenta el tiempo de observación
summarise(
mortality = survey_ratio(
as.numeric(died) * 10000,
obstime,
vartype = "ci")
)## # A tibble: 1 × 3
## mortality mortality_low mortality_upp
## <dbl> <dbl> <dbl>
## 1 5.98 0.349 11.6