22 Medias Móviles
Esta página cubrirá dos métodos para calcular y visualizar las medias móviles:
- Calcular con el paquete slider.
- Calcular dentro de un comando
ggplot()con el paquete tidyquant.
22.1 Preparación
Cargar paquetes
Este trozo de código muestra la carga de los paquetes necesarios para los análisis. En este manual destacamos p_load() de pacman, que instala el paquete si es necesario y lo carga para su uso. También puedes cargar los paquetes instalados con library() de R base. Consulta la página sobre fundamentos de R para obtener más información sobre los paquetes de R.
pacman::p_load(
tidyverse, # para la gestión de datos y viz
slider, # para calcular medias móviles
tidyquant # para calcular medias móviles dentro de ggplot
)Importar datos
Importamos los datos de casos de una epidemia de ébola simulada. Si quieres seguir el proceso, clica para descargar linelist “limpio” (como archivo .rds). Importa los datos con la función import() del paquete rio (maneja muchos tipos de archivos como .xlsx, .csv, .rds - mira la página de importación y exportación para más detalles).
# importar linelist
linelist <- import("linelist_cleaned.xlsx")A continuación se muestran las primeras 50 filas del listado.
22.2 Calcular con slider
Utiliza este enfoque para calcular una media móvil en un dataframe antes de representarla
El paquete slider proporciona varias funciones de “ventana deslizante” para calcular medias móviles, sumas acumulativas, regresiones móviles, etc. Trata un dataframe como un vector de filas, permitiendo la iteración por filas sobre un dataframe.
Estas son algunas de las funciones más comunes:
-
slide_dbl()- itera a través de una columna numérica (de ahí “_dbl”) realizando una operación mediante una ventana deslizante-
slide_sum()- función abreviada de suma móvil paraslide_dbl() -
slide_mean()- función abreviada de media móvil paraslide_dbl()
-
-
slide_index_dbl()- aplica la ventana móvil en una columna numérica utilizando una columna separada para indexar la progresión de la ventana (útil si se rueda por fecha con algunas fechas ausentes)-
slide_index_sum()- Función abreviada de suma móvil con indexación -
slide_index_mean()- Función de acceso directo a la media móvil con indexación
-
El paquete slider tiene muchas otras funciones que se tratan en la sección de Recursos de esta página. Tocamos brevemente las más comunes.
Argumentos básicos
-
.x, el primer argumento por defecto, es el vector sobre el que iterar y al que aplicar la función -
.i =para las versiones de “índice” de las funciones de deslizamiento - proporciona una columna para “indexar” el rollo (véase la sección siguiente) -
.f =, el segundo argumento por defecto, bien:- Una función, escrita sin paréntesis, como
mean, o - Una fórmula, que se convertirá en una función. Por ejemplo
~ .x - mean(.x)devolverá el resultado del valor actual menos la media del valor de la ventana
- Una función, escrita sin paréntesis, como
- Para más detalles, consulta este material de referencia
Tamaño de la ventana
Especifica el tamaño de la ventana utilizando los argumentos .before, .after, o ambos:
-
.before =- Proporcionar un número entero -
.after =- Proporcionar un número entero -
.complete =- Pon este valor aTRUEsi sólo quieres que se realicen cálculos en ventanas completas
Por ejemplo, para conseguir una ventana de 7 días que incluya el valor actual y los seis anteriores, utiliza .before = 6. Para conseguir una ventana “centrada” proporciona el mismo número tanto a .before = como a .after =.
Por defecto, .complete = será FALSE por lo que si la ventana completa de filas no existe, las funciones utilizarán las filas disponibles para realizar el cálculo. Si se ajusta a TRUE, los cálculos sólo se realizan en ventanas completas.
Ventana expansiva
Para lograr operaciones acumulativas, establece el argumento .before = en Inf. Esto realizará la operación sobre el valor actual y todos los que vengan antes.
Balancear por fecha
El caso más probable de uso de un cálculo rotativo en epidemiología aplicada es examinar una medida a lo largo del tiempo. Por ejemplo, una medición continua de la incidencia de casos, basada en el recuento diario de casos.
Si tienes datos de series temporales limpios con valores para cada fecha, puede estar bien utilizar slide_dbl(), como se demuestra aquí en la página de series temporales y detección de brotes.
Sin embargo, en muchas circunstancias de epidemiología aplicada puede haber fechas ausentes en los datos, donde no hay eventos registrados. En estos casos, es mejor utilizar las versiones “index” de las funciones slider.
Datos indexados
A continuación, mostramos un ejemplo utilizando slide_index_dbl() en la lista de casos. Digamos que nuestro objetivo es calcular una incidencia acumulada de 7 días - la suma de casos utilizando una ventana móvil de 7 días. Si estás buscando un ejemplo de media móvil, mira la sección de abajo sobre balanceo agrupado.
Para empezar, se crean los datos daily_counts para reflejar los recuentos diarios de casos de linelist, calculados con count() de dplyr.
# crea un conjunto de datos de recuentos diarios
daily_counts <- linelist %>%
count(date_hospitalisation, name = "new_cases")Aquí está el dataframe daily_counts - hay nrow(daily_counts) filas, cada día está representado por una fila, pero especialmente al principio de la epidemia algunos días no están presentes (no hubo casos admitidos en esos días).
Es crucial reconocer que una función estándar de balanceo (como slide_dbl() utilizaría una ventana de 7 filas, no de 7 días. Por lo tanto, si hay fechas ausentes, ¡algunas ventanas se extenderán realmente más de 7 días naturales!
Se puede conseguir una ventana móvil “inteligente” con slide_index_dbl(). El “índex” significa que la función utiliza una columna independiente como “index” para la ventana móvil. La ventana no se basa simplemente en las filas del dataframe.
Si la columna índex es una fecha, tienes la posibilidad añadida de especificar la extensión de la ventana a .before = y/o .after = en unidades de days() o months() de lubridate. Si haces estas cosas, la función incluirá los días ausentes en las ventanas como si estuvieran allí (como valores NA).
Mostremos una comparación. A continuación, calculamos la incidencia móvil de casos de 7 días con ventanas regulares e indexadas.
rolling <- daily_counts %>%
mutate( # crea columnas nuevas
# usando slide_dbl()
####################
reg_7day = slide_dbl(
new_cases, # calcula sobre new_cases
.f = ~sum(.x, na.rm = T), # la función es sum() con los valores faltantes eliminados
.before = 6), # la ventana es la FILA y 6 FILAS anteriores
# Usando slide_index_dbl()
##########################
indexed_7day = slide_index_dbl(
new_cases, # calcula sobre new_cases
.i = date_hospitalisation, # indexado con date_onset
.f = ~sum(.x, na.rm = TRUE), # la función es sum() con los valores faltantes eliminados
.before = days(6)) # la ventana es el DÍA y los 6 DÍAS anteriores
)Fíjate cómo en la columna normal de las 7 primeras filas el recuento aumenta constantemente a pesar de que las filas no tienen 7 días de diferencia. La columna adyacente “indexada” tiene en cuenta estos días naturales ausentes, por lo que la suma de 7 días son mucho menores, al menos en este periodo de la epidemia en el que los casos están más alejados.
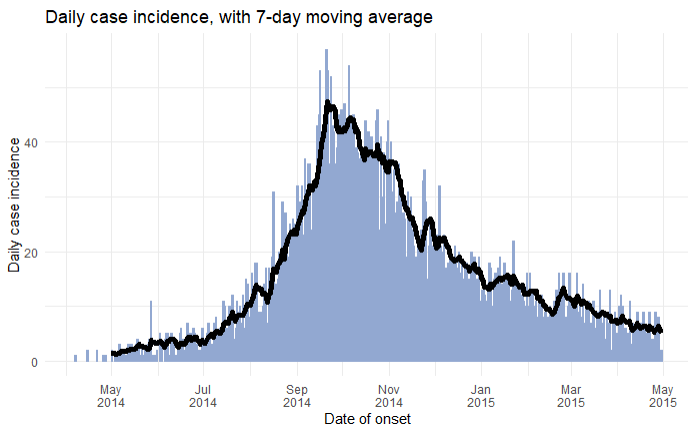
Ahora puede trazar estos datos utilizando ggplot():
ggplot(data = rolling)+
geom_line(mapping = aes(x = date_hospitalisation, y = indexed_7day), size = 1)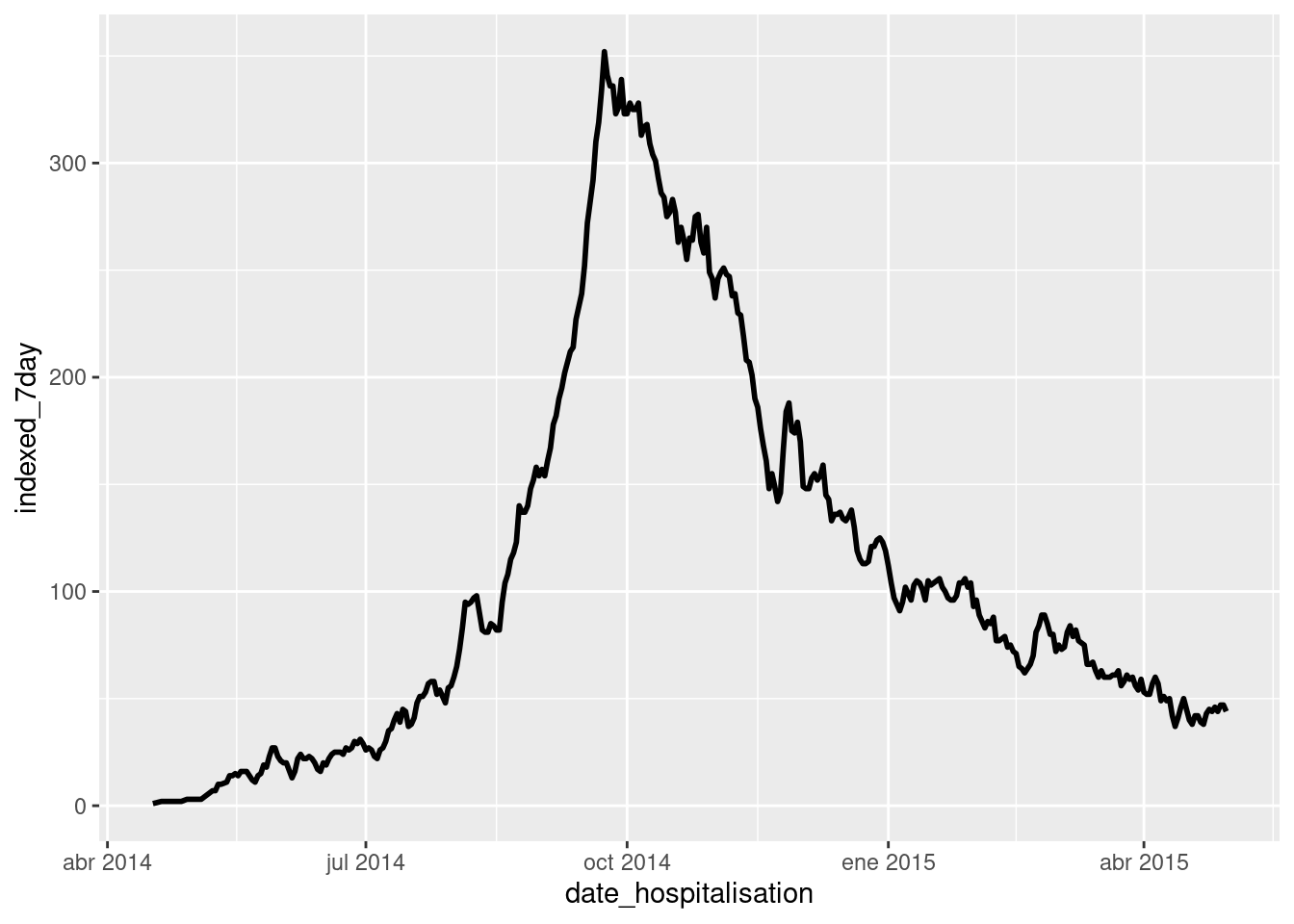
Balanceando por grupo
Si agrupas los datos antes de utilizar una función slider, las ventanas deslizantes se aplicarán por grupo. Ten cuidado de organizar las filas en el orden deseado por grupo.
Cada vez que se inicia un nuevo grupo, la ventana deslizante se reinicia. Por lo tanto, un matiz a tener en cuenta es que si tus datos están agrupados y has establecido .complete = TRUE, tendrás valores vacíos en cada transición entre grupos. A medida que la función se desplaza hacia abajo a través de las filas, cada transición en la columna de agrupación reiniciará la acumulación del tamaño mínimo de la ventana para permitir un cálculo.
Consulta la página del manual sobre Agrupar datos para obtener detalles sobre la agrupación de datos.
A continuación, contamos los casos del listado por fecha y por hospital. Luego ordenamos las filas en orden ascendente, primero ordenando por hospital y luego dentro de éste por fecha. A continuación establecemos group_by(). Entonces podemos crear nuestra nueva media móvil.
grouped_roll <- linelist %>%
count(hospital, date_hospitalisation, name = "new_cases") %>%
arrange(hospital, date_hospitalisation) %>% # ordena las filas por hospital y luego por fecha
group_by(hospital) %>% # agrupa por hospital
mutate( # media móvil
mean_7day_hosp = slide_index_dbl(
.x = new_cases, # recuento de casos por hospitalización-día
.i = date_hospitalisation, # índice de la fecha de ingreso
.f = mean, # utiliza mean()
.before = days(6) # utiliza el día y los 6 días anteriores
)
)Aquí está el nuevo conjunto de datos:
Ahora podemos trazar las medias móviles, mostrando los datos por grupo especificando ~ hospital a facet_wrap() en ggplot(). Para divertirnos, trazamos dos geometrías: una geom_col() que muestra los recuentos de casos diarios y una geom_line() que muestra la media móvil de 7 días.
ggplot(data = grouped_roll)+
geom_col( # traza los recuentos diarios de casos como barras grises
mapping = aes(
x = date_hospitalisation,
y = new_cases),
fill = "grey",
width = 1)+
geom_line( # trazar la media móvil como línea coloreada por hospital
mapping = aes(
x = date_hospitalisation,
y = mean_7day_hosp,
color = hospital),
size = 1)+
facet_wrap(~hospital, ncol = 2)+ # crea mini-gráficos por hospital
theme_classic()+ # se simplifica el fondo
theme(legend.position = "none")+ # se elimina la leyenda
labs( # añade etiquetas a los gráficos
title = "7-day rolling average of daily case incidence",
x = "Date of admission",
y = "Case incidence")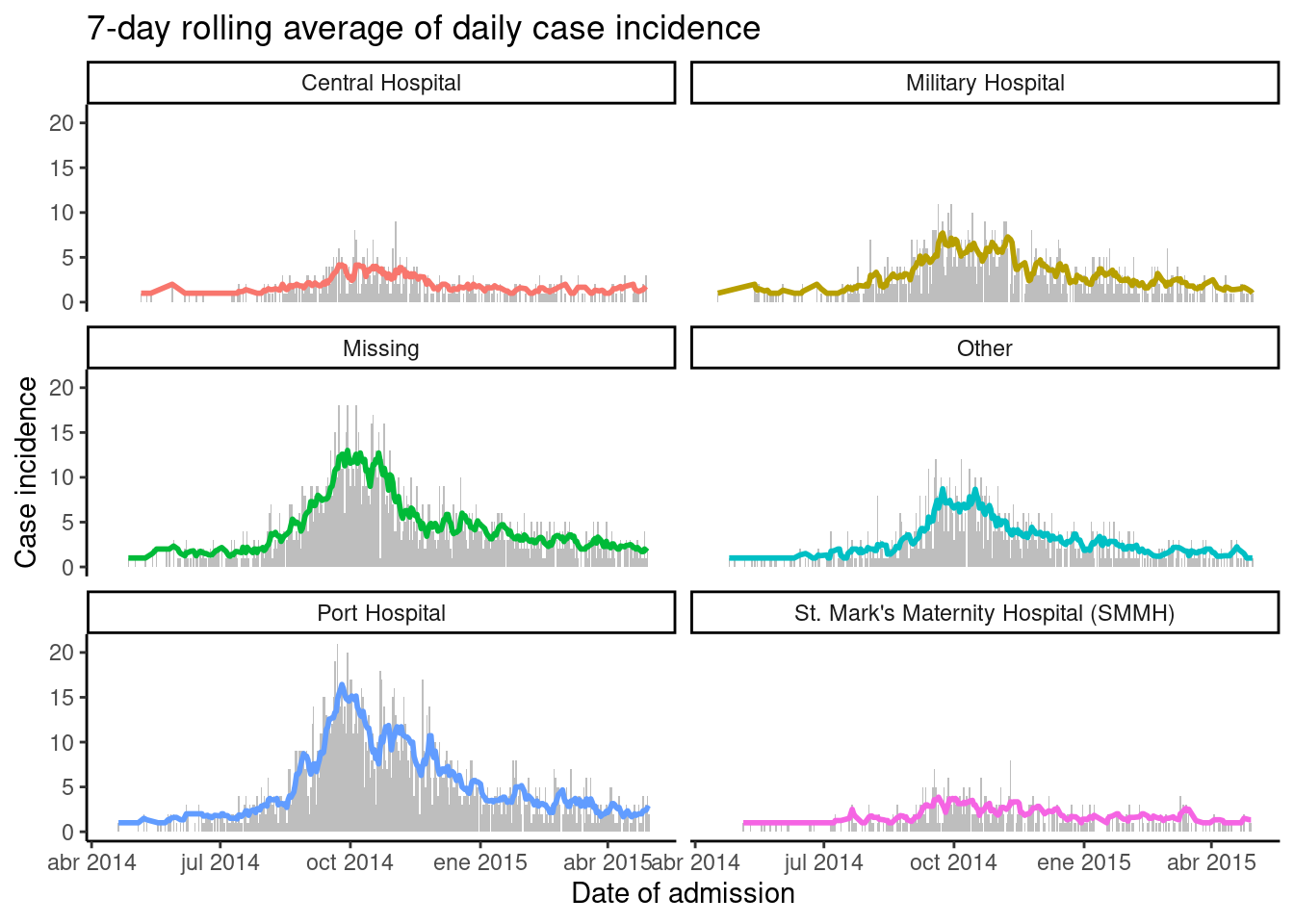
PELIGRO: Si obtienes un error que dice “slide() was deprecated in tsibble 0.9.0 and is now defunct. Please use slider::slide() instead.”, significa que la función slide() del paquete tsibble está enmascarando la función slide() del paquete slider. Soluciona esto especificando el paquete en el comando, como slider::slide_dbl().
22.3 Calcular con tidyquant dentro de ggplot()
El paquete tidyquant ofrece otro enfoque para calcular las medias móviles, esta vez dentro del comando ggplot().
Bajo linelist, los datos se cuentan por fecha de inicio, y esto se traza como una línea descolorida (alpha < 1). Encima hay una línea creada con geom_ma() del paquete tidyquant, con una ventana de 7 días (n = 7) con el color y el grosor especificados.
Por defecto geom_ma() utiliza una media móvil simple (ma_fun = "SMA"), pero se pueden especificar otros tipos, como:
- “EMA” - media móvil exponencial (más peso a las observaciones recientes)
- “WMA” - media móvil ponderada (los
wtsse utilizan para ponderar las observaciones en la media móvil) - Otros se pueden encontrar en la documentación de la función
linelist %>%
count(date_onset) %>% # recuento de casos por día
drop_na(date_onset) %>% # eliminar casos sin fecha de inicio
ggplot(aes(x = date_onset, y = n))+ # inicia ggplot
geom_line( # traza los valores crudos
size = 1,
alpha = 0.2 # línea semitransparente
)+
tidyquant::geom_ma( # representa la media móvil
n = 7,
size = 1,
color = "blue")+
theme_minimal() # fondo sencillo
Consulta esta viñeta para obtener más detalles sobre las opciones disponibles en tidyquant.
22.4 Recursos
Consulta la útil viñeta en línea del paquete slider
La página github del slider
Una viñeta slider
Si tu caso de uso requiere que te “saltes” los fines de semana e incluso los días festivos, puede que te guste el paquete almanac.