4 Transición a R
A continuación, te ofrecemos algunos consejos y recursos que resultan útiles si te estás pasando a R.
R se introdujo a finales de la década de 1990 y desde entonces su alcance ha crecido de forma espectacular. Sus capacidades son tan amplias que las alternativas comerciales han reaccionado a los desarrollos de R para seguir siendo competitivas. (lee este artículo que compara R, SPSS, SAS, STATA y Python).
Además, R es mucho más fácil de aprender que hace 10 años. Antes, R tenía fama de ser difícil para los principiantes. Ahora es mucho más fácil, con interfaces de usuario amigables como RStudio, código intuitivo como tidyverse, y muchos recursos tutoriales.
¡No te dejes intimidar, ven a descubrir el mundo de R!
4.1 Desde Excel
La transición de Excel directamente a R es un objetivo muy alcanzable. Puede parecer desalentador, ¡pero puedes hacerlo!
Es cierto que alguien con grandes conocimientos de Excel puede realizar actividades muy avanzadas sólo con Excel, incluso utilizando herramientas de scripting como VBA. Excel se utiliza en todo el mundo y es una herramienta esencial para la epidemiología. Sin embargo, complementarlo con R puede mejorar y ampliar drásticamente tus flujos de trabajo.
Beneficios
Descubrirás que el uso de R ofrece inmensos beneficios en cuanto a ahorro de tiempo, análisis más consistentes y precisos, reproducibilidad, posibilidad de compartir y una corrección de errores más rápida. Como cualquier software nuevo, hay una “curva de aprendizaje” en la que hay que invertir tiempo para familiarizarse. Los dividendos serán significativos y se te abrirá un inmenso abanico de nuevas posibilidades con R.
Excel es un software muy conocido que permite que un principiante pueda realizar análisis y visualizaciones simples con “apuntar y clicar” de manera sencilla. En comparación, puede llevar un par de semanas sentirse cómodo con las funciones y la interfaz de R. Sin embargo, R ha evolucionado en los últimos años para ser mucho más amigable con los principiantes.
Muchos flujos de trabajo de Excel se basan en la memoria y en la repetición, por lo que hay muchas posibilidades de error. Además, generalmente la limpieza de datos, la metodología de análisis y las ecuaciones utilizadas están ocultas a la vista. A un nuevo colega le puede llevar mucho tiempo aprender lo que hace un libro de Excel y cómo resolver problemas que surjan. Con R, todos los pasos se escriben explícitamente en el script y pueden verse, editarse, corregirse y aplicarse fácilmente a otros conjuntos de datos.
Para comenzar tu transición de Excel a R debes ajustar tu mentalidad en algunos aspectos importantes:
Datos ordenados (tidy data)
Debes utilizar datos “ordenados” (tidy), legibles por la máquina en lugar de datos desordenados “legibles por el ser humano”. Estos son los tres requisitos principales que los datos “ordenados” deben cumplir, como se explica en este tutorial sobre datos “ordenados” en R:
- Cada variable debe tener su propia columna
- Cada observación debe tener su propia fila
- Cada valor debe tener su propia celda
Para los usuarios de Excel: piensa en el papel que desempeñan las “tablas” de Excel para estandarizar los datos y hacer que el formato sea más predecible.
Un ejemplo de datos “ordenados” sería el listado de casos utilizado en este manual: cada variable está contenida en una columna, cada observación (un caso) tiene su propia fila y cada valor está en una sola celda. A continuación, puede ver las primeras 50 filas del listado:
La principal razón por la que nos encontramos con datos no ordenados es porque muchas hojas de cálculo en Excel están diseñadas para dar prioridad a la lectura fácil por parte de los humanos, no a la lectura fácil por parte de las máquinas/el software.
Para ayudarte a ver la diferencia, a continuación se presentan algunos ejemplos ficticios de datos no ordenados, los cuales dan prioridad a la legibilidad humana sobre la legibilidad-mecánica:
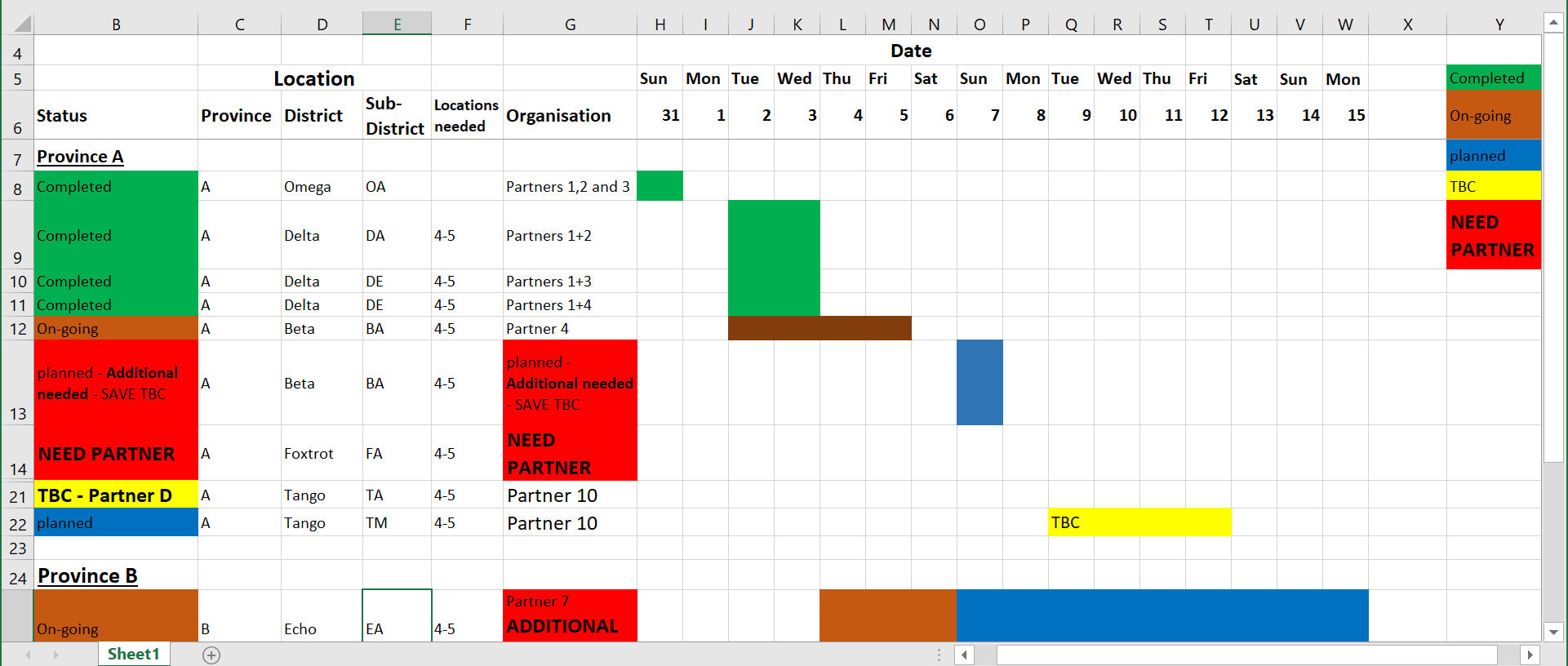
Problemas: En la hoja de cálculo de arriba, hay celdas combinadas que no son fácilmente digeridas por R. No está claro qué fila debe utilizarse para la “cabecera”. A la derecha hay un diccionario basado en colores y los valores de las celdas están representados por colores, lo que tampoco es fácilmente interpretado por R (¡ni por los humanos que padecen daltonismo!). Además, se combinan diferentes informaciones en una celda (varias organizaciones asociadas que trabajan en un área, o el estado “TBC” en la misma celda que “Partner D”).
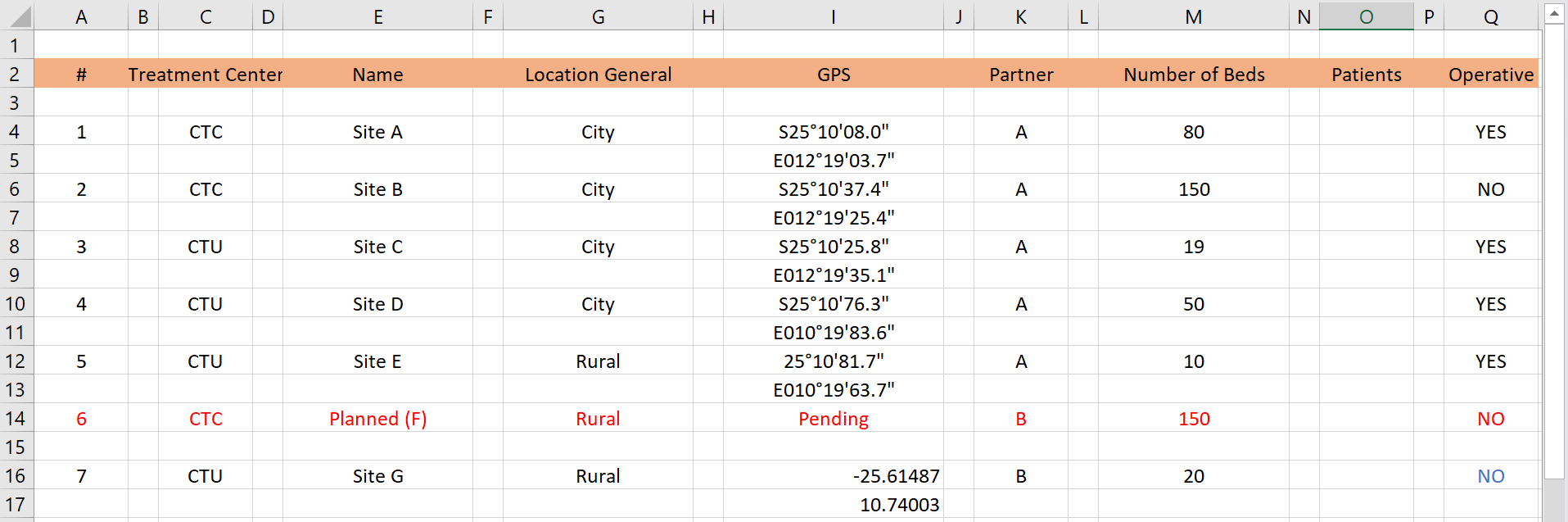
Problemas:* En la hoja de cálculo anterior, hay numerosas filas y columnas vacías adicionales dentro de los datos, lo que provocará dolores de cabeza a la hora de limpiarlos con R. Además, las coordenadas GPS están repartidas en dos filas para un centro de tratamiento determinado. Y, una nota adicional, ¡las coordenadas GPS están en dos formatos diferentes!
Los datos “ordenados” pueden no ser tan legibles para el ojo humano, pero facilitan mucho la limpieza y el análisis de los datos. Los datos ordenados pueden almacenarse en varios formatos, por ejemplo, “largos” o “anchos” (véase la página sobre Pivotar datos), pero se siguen observando los principios anteriores.
Funciones
Puede que la palabra “función” en R sea nueva, pero el concepto existe también en Excel y se le conoce como fórmulas. Las fórmulas en Excel también requieren una sintaxis precisa (por ejemplo, la colocación de puntos y comas y paréntesis). Lo único que hay que hacer es aprender algunas funciones nuevas y cómo funcionan en R.
Scripts
En lugar de clicar en los botones y arrastrar las celdas, escribirás cada paso y procedimiento en un “script” (secuencia de órdenes). Los usuarios de Excel pueden estar familiarizados con las “macros VBA”, que también emplean un enfoque de scripting (secuencia de comandos VBA).
El script de R consiste en instrucciones paso a paso. Esto permite que cualquier colega pueda leer el script y ver fácilmente los pasos que has dado. Esto también ayuda a depurar errores o cálculos inexactos. Consulta la sección sobre scripts del capítulo Fundamentos de R para ver algunos ejemplos.
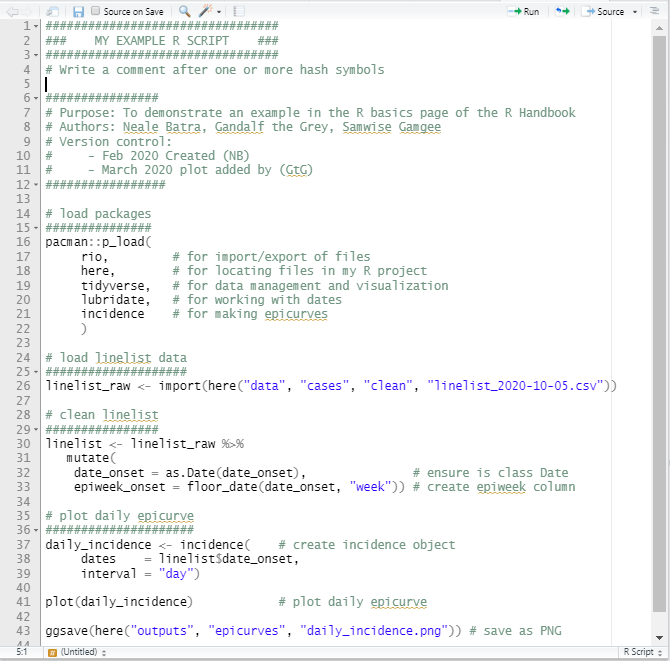
Este es un ejemplo de un script en R:
Recursos en la migración Excel a R
Aquí hay algunos enlaces a tutoriales que te ayudarán en la transición a R desde Excel:
Interacción R-Excel
R tiene formas robustas de importar libros de Excel, trabajar con los datos, exportar/guardar archivos de Excel y trabajar con los detalles de las hojas de Excel.
Es cierto que algunos de los formatos más estéticos de Excel pueden perderse en la traducción (por ejemplo, la cursiva, el texto lateral, etc.). Si tu flujo de trabajo requiere que pases documentos de un lado a otro entre R y Excel conservando el formato original de Excel, prueba paquetes como openxlsx.
4.2 Desde Stata
Llegando a R desde Stata
A muchas personas en el campo de la epidemiología se les enseña primero a usar Stata, y puede parecer desalentador pasar a R. Sin embargo, si eres un usuario habitual de Stata, el salto a R es ciertamente más manejable de lo que podrías pensar. Si bien hay algunas diferencias clave entre Stata y R en la forma en que se pueden crear y modificar los datos, así como en la forma en que se implementan las funciones de análisis - después de aprender estas diferencias clave serás capaz de adaptar tus habilidades.
A continuación, se presentan algunas traducciones clave entre Stata y R, que pueden ser útiles mientras revisas esta guía.
Notas generales
| STATA | R |
|---|---|
| Sólo se puede ver y manipular unos datos a la vez | Puedes ver y manipular varios conjuntos de datos al mismo tiempo, por lo que con frecuencia tendrás que especificar el conjunto de datos dentro del código |
| Comunidad en línea disponible a través de https://www.statalist.org/ | Comunidad online disponible a través de RStudio, StackOverFlow y R-bloggers |
| Funcionalidad de apuntar y clicar como una opción | Funcionalidad mínima de apuntar y clicar |
Ayuda para los comandos disponibles mediante el [comando] help
|
Ayuda disponible con la [función]? o mediante búsqueda en el panel de ayuda |
| Comentar el código usando * o /// o /* TEXTO * / | Comment code using # |
| Casi todos los comandos son propios de Stata. Las funciones nuevas/escritas por el usuario pueden instalarse como archivos ado utilizando el [paquete] ssc install | R se instala con las funciones base, pero el uso típico implica la instalación de otros paquetes desde CRAN (véase el capítulo sobre Fundamentos de R) |
| El análisis se suele escribir en un archivo do | El análisis se escribe en un script de R en el panel de fuentes de RStudio. Los scripts de R markdown son una alternativa. |
Directorio de trabajo
| STATA | R |
|---|---|
| Los directorios de trabajo implican rutas de archivo absolutas (por ejemplo, “C:/nombredeusuario/documentos/proyectos/datos/”) | Los directorios de trabajo pueden ser absolutos, o relativos a la carpeta raíz del proyecto utilizando el paquete here (ver Importar y exportar) |
| Ver el directorio de trabajo actual con pwd | Utiliza getwd() o here() (si utilizas el paquete here), con paréntesis vacíos |
| Establecer el directorio de trabajo con cd “ubicación de la carpeta” | Usar setwd("ubicación de la carpeta"), o set_here("ubicación de la carpeta"), si utilizas el paquete here) |
Importación y visualización de datos
| STATA | R |
|---|---|
| Comandos específicos por tipo de archivo | Usar import() del paquete rio para casi todos los tipos de archivos. Existen funciones específicas como alternativas (véase Importar y exportar) |
| La lectura de los archivos csv se realiza mediante la importación delimitada “nombrearchivo.csv” | Usar import("nombredearchivo.csv")
|
| La lectura de los archivos xslx se realiza mediante la importación de excel “nombre de archivo.xlsx” | Usar import("nombredearchivo.xlsx")
|
| Examinar sus datos en una nueva ventana utilizando el comando browse | Ver unos datos en el panel de origen de RStudio utilizando View(datos). Es necesario especificar el nombre de los datos a la función en R porque se pueden mantener varios conjuntos de datos al mismo tiempo. Atención a la “V” mayúscula en esta función
|
| Obtener una visión general de alto nivel de su set de datos utilizando summarize, que proporciona los nombres de las variables y la información básica | Obtener una visión general de los datos mediante summary(datos)
|
Manipulación básica de datos
| STATA | R |
|---|---|
| Las columnas de los datos suelen denominarse “variables” | Más a menudo se denominan “columnas” o a veces “vectores” o “variables” |
| No es necesario especificar los datos | En cada uno de los siguientes comandos, es necesario especificar los datos - véase la página sobre Limpieza de datos y funciones básicas para ver ejemplos |
| Las nuevas variables se crean con el comando generate varname = | Generar nuevas variables utilizando la función mutate(varname = ). Consultar la página sobre Limpieza de datos y funciones básicas para obtener detalles sobre todas las funciones de dplyr que aparecen a continuación. |
| Las variables se renombran mediante rename nombre_antiguo nombre_nuevo | Las columnas pueden renombrarse mediante la función rename(nombre_antiguo = nombre_nuevo) |
| Las variables se eliminan con drop variable | Las columnas pueden eliminarse mediante la función select() con el nombre de la columna detrás de un signo menos, entre paréntesis |
| Las variables factoriales se pueden etiquetar utilizando una serie de comandos como label define | El etiquetado de los valores puede hacerse convirtiendo la columna en tipo Factor y especificando los niveles. Mira en la página sobre Factores. Los nombres de las columnas no suelen estar etiquetados como en Stata. |
Análisis descriptivo
| STATA | R |
|---|---|
| Tabular los recuentos de una variable mediante el tab variable | Proporcionar los datos y el nombre de la columna al comando table() como table(conjunto_de_datos\(nombre_columna). Alternativamente, utilizar count(varname) del paquete **dplyr**, como se explica en [Agrupar datos](#grouping-data) La tabulación cruzada de dos variables en una tabla de 2x2 se realiza con **tab** *variable1 variable2* | Utilizar `table(datos\)nombre_variable1, datos$nombre_variable2 o count(nombre_variable1, nombre_variable2)` |
Aunque esta lista ofrece una visión general de los fundamentos de la traducción de los comandos de Stata a R, no es exhaustiva. Hay muchos otros grandes recursos para los usuarios de Stata que podrían ser de interés en tu transición a R:
4.3 Desde SAS
Pasar de SAS a R
SAS se utiliza habitualmente en las agencias de salud pública y en los campos de investigación académica. Aunque la transición a un nuevo lenguaje no suele ser un proceso sencillo, entender las diferencias clave entre SAS y R puede ayudarte a empezar a navegar por el nuevo lenguaje utilizando el lenguaje de partida. A continuación se describen las principales traducciones en materia de gestión de datos y análisis descriptivo entre SAS y R.
Notas generales
| SAS | R |
|---|---|
| Comunidad en línea disponible a través del Servicio de Atención al Cliente de SAS | Comunidad online disponible a través de RStudio, StackOverFlow y R-bloggers |
Ayuda para los comandos disponibles mediante help [comando]
|
Ayuda disponible usando mediante [función]? o buscando en el panel de ayuda |
Comentar el código usando * TEXTO ; o /* TEXTO */
|
Comentar el código usando # |
Casi todos los comandos están incorporados. Los usuarios pueden escribir nuevas funciones utilizando macros SAS, SAS/IML, SAS Component Language (SCL) y, más recientemente, los procedimientos Proc Fcmp y Proc Proto
|
R se instala con las funciones base, pero el uso típico implica la instalación de otros paquetes desde CRAN (véase la página sobre Fundamentos de R) |
| El análisis suele realizarse escribiendo un programa SAS en la ventana del Editor. | Análisis escrito en un script de R en el panel de fuentes de RStudio. Los scripts de R markdown son una alternativa. |
Directorio de trabajo
| SAS | R |
|---|---|
Los directorios de trabajo pueden ser absolutos o relativos a la carpeta raíz del proyecto, definiendo la carpeta raíz con %let rootdir=/ruta raíz; %include "&rootdir/subfoldername/archivo"
|
Los directorios de trabajo pueden ser absolutos, o relativos a la carpeta raíz del proyecto utilizando el paquete here (ver Importar y exportar) |
Ver el directorio de trabajo actual con %put %sysfunc(getoption(work));
|
Utilizar getwd() o here() (si utilizas el paquete here), con paréntesis vacíos |
Establecer el directorio de trabajo con libname "ubicación de la carpeta"
|
Utiliza setwd("ubicación de la carpeta"), o set_here("ubicación de la carpeta") si utilizas el paquete here
|
Importación y visualización de datos
| SAS | R |
|---|---|
Utiliza el procedimiento Proc Import o la sentencia Data Step Infile. |
Utiliza import() del paquete rio para casi todos los tipos de archivos. Existen funciones específicas como alternativas (véase Importar y exportar) |
La lectura de los archivos csv se realiza mediante Proc Import datafile="nombre de archivo.csv" out=nombre de archivo dbms=CSV; run; O mediante la sentencia Data Step Infile
|
Utiliza import(“nombredearchivo.csv”) |
La lectura de los archivos xslx se realiza utilizando Proc Import datafile="filename.xlsx" out=work.filename dbms=xlsx; run; O utilizando la sentencia [Data Step Infile |
Use](http://support.sas.com/techsup/technote/ts673.pdf) |
| Examinar los datos en una nueva ventana abriendo la ventana del Explorador y seleccionar la biblioteca deseada y los datos | Ver unos datos en el panel de RStudio utilizando View(datos). Se necesita especificar el nombre del set de datos a la función en R porque se pueden mantener múltiples conjuntos de datos al mismo tiempo. Atención a la “V” mayúscula en esta función |
Manipulación básica de datos
| SAS | R |
|---|---|
| Las columnas de los datos suelen denominarse “variables” | Más a menudo se denominan “columnas” o a veces “vectores” o “variables” |
| No es necesario ningún procedimiento especial para crear una variable. Las nuevas variables se crean simplemente escribiendo el nombre de la nueva variable, seguido de un signo igual, y luego una expresión para el valor | Generar nuevas variables utilizando la función mutate(). Consulta la página sobre Limpieza de datos y funciones básicas para obtener detalles sobre todas las funciones de dplyr que aparecen a continuación. |
Las variables se renombran utilizando rename *nombre_antiguo=nuevo_nombre*. |
Las columnas pueden renombrarse mediante la función rename(nuevo_nombre = nombre_antiguo)
|
Las variables se guardan con **keep**=nombre de la variable
|
Las columnas pueden seleccionarse mediante la función select() con el nombre de la columna entre paréntesis |
Las variables se eliminan con **drop**=nombre de la variable
|
Las columnas pueden eliminarse mediante la función select() con el nombre de la columna detrás de un signo menos, entre paréntesis |
Las variables factoriales pueden etiquetarse en el mediante la sentencia Label
|
El etiquetado de los valores puede hacerse convirtiendo la columna en una de tipo Factor y especificando los niveles. Véase la página sobre Factores. Los nombres de las columnas no se suelen etiquetar. |
Los registros se seleccionan utilizando la sentencia Where o If. Las condiciones de selección múltiple se separan con el comando “and”. |
Los registros se seleccionan mediante la función filter() con múltiples condiciones de selección separadas por un operador AND (&) o una coma |
Los datos se combinan utilizando la sentencia Merge. Los datos que se van a combinar deben ordenarse primero mediante el procedimiento Proc Sort. |
El paquete dplyr ofrece algunas funciones para fusionar conjuntos de datos. Para más detalles, consulta la página de Unir datos. |
Análisis descriptivo
| SAS | R |
|---|---|
Obtener una visión general de los datos mediante el procedimiento Proc Summary, que proporciona los nombres de las variables y las estadísticas descriptivas |
Obtener una visión general de tus datos mediante summary(datos) o skim(datos) del paquete skimr
|
Tabular los recuentos de una variable utilizando proc freq data=Dataset; Tables varname; Run;
|
Véase la página sobre tablas descriptivas. Las opciones incluyen table() de R base, y tabyl() del paquete janitor, entre otras. Ten en cuenta que tendrás que especificar los datos y el nombre de la columna, ya que R mantiene múltiples conjuntos de datos. |
La tabulación cruzada de dos variables en una tabla 2x2 se realiza con proc freq data=Dataset; Tables rowvar* colvar; Run;
|
De nuevo, se puedes utilizar table(), tabyl() u otras opciones como se describe en la página de tablas descriptivas. |
Algunos recursos útiles:
4.4 Interoperabilidad de los datos
Consulta la página de importación y exportación para obtener detalles sobre cómo el paquete rio puede importar y exportar los archivos .dta de STATA, los archivos .xpt y .sas7bdat de SAS, los archivos .por y .sav de SPSS, y muchos otros.