18 Tests estadísticos sencillos
Esta página muestra cómo realizar tests estadísticos sencillos utilizando R base, rstatix y gtsummary.
- Prueba o Test T de Student
- Prueba o Test de Shapiro-Wilk
- Prueba o Test de suma de rangos de Wilcoxon
- Prueba o Test de Kruskal-Wallis
- Prueba o Test de Chi-cuadrado
- Correlaciones entre variables numéricas
…Se pueden realizar otras muchas pruebas. Solo mostraremos éstas, las más comunes y enlazaremos con más documentación.
Cada uno de los paquetes mencionados tienen unos usos específicos:
- Utiliza las funciones de R base para imprimir una salida estadística en la consola de R
- Utiliza las funciones rstatix para devolver los resultados en un dataframe, o si deseas que las pruebas se ejecuten por grupos
- Utiliza gtsummary si tienes interés en rápidamente tablas listas para su publicación
18.1 Preparación
Cargar paquetes
Este trozo de código muestra la carga de los paquetes necesarios para los análisis. En este manual destacamos la función p_load() de pacman, que instala el paquete si es necesario y lo carga para su uso. También puedes cargar los paquetes ya instalados con el comando library() de R base Consulta la página sobre fundamentos de R para obtener más información sobre los paquetes de R.
pacman::p_load(
rio, # Importación de ficheros
here, # localizador de ficheros
skimr, # obtener una visión general de los datos
tidyverse, # gestión de datos + gráficos ggplot2,
gtsummary, # resumen estadístico y pruebas
rstatix, # estadísticas
corrr, # análisis de correlación para variables numéricas
janitor, # añadir totales y porcentajes a las tablas
flextable # conversión de tablas a HTML
)Importar datos
Importaremos los datos de casos de una epidemia de ébola simulada. Si quieres seguir el proceso, clica para descargar linelist “limpio” (archivo linelist_cleaned.rds). Importa tus datos con la función import() del paquete rio (acepta muchos tipos de archivos como .xlsx, .rds, .csv - Mira la página de importación y exportación para más detalles).
# importar linelist
linelist <- import("linelist_cleaned.rds")A continuación se muestran las primeras 50 filas del listado.
18.2 ** R base**
Puedes utilizar las funciones de ** R base** para realizar pruebas estadísticas. Los comandos son relativamente sencillos y los resultados se imprimen en la consola de R para su visualización. Sin embargo, las salidas suelen ser listas y, por lo tanto, son más difíciles de manipular en el caso que se desee utilizar los resultados en operaciones posteriores.
Tests-T
Un test-t, también llamado “Test t de Student” o “Prueba t de Student”, se utiliza normalmente para determinar si existe una diferencia significativa entre las medias de alguna variable numérica entre dos grupos. Aquí mostraremos la sintaxis para hacer esta prueba dependiendo de si las columnas se encuentran o no en el mismo dataframe.
Sintaxis 1: Esta es la sintaxis cuando las columnas numéricas y categóricas están en el mismo dataframe. Sitúa la columna numérica en el lado izquierdo de la ecuación y la columna categórica en el lado derecho. Especifica los datos en data =. Opcionalmente, establece paired = TRUE, conf.level = (0.95 por defecto), y alternative = (ya sea “two.sided”, “less”, o “greater”). Escribe ?t.test para obtener más detalles.
## comparar la edad media por grupo de resultados con un test-t
t.test(age_years ~ gender, data = linelist)##
## Welch Two Sample t-test
##
## data: age_years by gender
## t = -21.344, df = 4902.3, p-value < 2.2e-16
## alternative hypothesis: true difference in means between group f and group m is not equal to 0
## 95 percent confidence interval:
## -7.571920 -6.297975
## sample estimates:
## mean in group f mean in group m
## 12.60207 19.53701Sintaxis 2: Puedes comparar dos vectores numéricos separados utilizando esta sintaxis alternativa. Por ejemplo, si las dos columnas están en dataframes diferentes.
t.test(df1$age_years, df2$age_years)También se puede utilizar una prueba t de Student para determinar si la media de una muestra es significativamente diferente de algún valor específico. Aquí realizamos una prueba t de una muestra con la media poblacional conocida/hipotética como mu =:
t.test(linelist$age_years, mu = 45)Prueba de Shapiro-Wilk
El test de Shapiro-Wilk puede utilizarse para determinar si una muestra procede de una población distribuida normalmente (un supuesto en muchas otras pruebas y análisis, como la prueba t). Sin embargo, sólo puede utilizarse en una muestra de entre 3 y 5000 observaciones. Para muestras más grandes puede ser útil un gráfico de cuantiles.
shapiro.test(linelist$age_years)Test de suma de rangos de Wilcoxon
El test de suma de rangos de Wilcoxon, también llamada test U de Mann-Whitney, se utiliza a menudo para ayudar a determinar si dos muestras numéricas proceden de la misma distribución cuando tus poblaciones no se distribuyen normalmente o tienen una varianza desigual.
## comparar la distribución de edad por grupo de resultados con un test de wilcox
wilcox.test(age_years ~ outcome, data = linelist)##
## Wilcoxon rank sum test with continuity correction
##
## data: age_years by outcome
## W = 2501868, p-value = 0.8308
## alternative hypothesis: true location shift is not equal to 0Test de Kruskal-Wallis
El test de Kruskal-Wallis es una extensión del test de suma de rangos de Wilcoxon. Puede utilizarse para comprobar las diferencias en la distribución de más de dos muestras. Cuando sólo se utilizan dos muestras, los resultados son idénticos a los del test de suma de rangos de Wilcoxon.
## comparar la distribución de edad por grupo de resultados con un test de kruskal-wallis
kruskal.test(age_years ~ outcome, linelist)##
## Kruskal-Wallis rank sum test
##
## data: age_years by outcome
## Kruskal-Wallis chi-squared = 0.045675, df = 1, p-value = 0.8308Test de Chi-cuadrado
El test de Chi-cuadrado de Pearson se utiliza para comprobar las diferencias significativas entre grupos categóricos.
## comparar las proporciones en cada grupo con un test de chi-cuadrado
chisq.test(linelist$gender, linelist$outcome)##
## Pearson's Chi-squared test with Yates' continuity correction
##
## data: linelist$gender and linelist$outcome
## X-squared = 0.0011841, df = 1, p-value = 0.972518.3 Paquete rstatix
El paquete rstatix ofrece la posibilidad de ejecutar pruebas estadísticas y recuperar los resultados en un formato “amigable”. Los resultados se encuentran automáticamente en un dataframe para que puedan realizar operaciones posteriores con los resultados. También es fácil agrupar los datos que se pasan a las funciones, de modo que las estadísticas se ejecutan para cada grupo.
Estadísticas resumidas
La función get_summary_stats() es una forma rápida de generar estadísticas de resumen. Únicamente tienes que tienes que seleccionar tu dataframe al aplicar esta función así como especificar las columnas que deseas analizar. Si no se especifica ninguna columna, las estadísticas se calculan para todas ellas.
Por defecto, la función devuelve una gama completa de estadísticas de resumen: n, max, min, mediana, cuartil 25%, cuartil 75%, IQR, desviación absoluta mediana (mad), media, desviación estándar, error estándar y un intervalo de confianza de la media.
linelist %>%
rstatix::get_summary_stats(age, temp)## # A tibble: 2 × 13
## variable n min max median q1 q3 iqr mad mean sd se ci
## <fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 age 5802 0 84 13 6 23 17 11.9 16.1 12.6 0.166 0.325
## 2 temp 5739 35.2 40.8 38.8 38.2 39.2 1 0.741 38.6 0.977 0.013 0.025Puedes especificar un subconjunto de estadísticas de resumen a calcular proporcionando uno de los siguientes valores a type =: “full”, “common”, “robust”, “five_number”, “mean_sd”, “mean_se”, “mean_ci”, “median_iqr”, “median_mad”, “quantile”, “mean”, “median”, “min”, “max”.
También puede utilizarse con datos agrupados, de forma que se devuelva una fila por cada variable de agrupación:
linelist %>%
group_by(hospital) %>%
rstatix::get_summary_stats(age, temp, type = "common")## # A tibble: 12 × 11
## hospital variable n min max median iqr mean sd se ci
## <chr> <fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Central Hospital age 445 0 58 12 15 15.7 12.5 0.591 1.16
## 2 Central Hospital temp 450 35.2 40.4 38.8 1 38.5 0.964 0.045 0.089
## 3 Military Hospital age 884 0 72 14 18 16.1 12.4 0.417 0.818
## 4 Military Hospital temp 873 35.3 40.5 38.8 1 38.6 0.952 0.032 0.063
## 5 Missing age 1441 0 76 13 17 16.0 12.9 0.339 0.665
## 6 Missing temp 1431 35.8 40.6 38.9 1 38.6 0.97 0.026 0.05
## 7 Other age 873 0 69 13 17 16.0 12.5 0.422 0.828
## 8 Other temp 862 35.7 40.8 38.8 1.1 38.5 1.01 0.034 0.067
## 9 Port Hospital age 1739 0 68 14 18 16.3 12.7 0.305 0.598
## 10 Port Hospital temp 1713 35.5 40.6 38.8 1.1 38.6 0.981 0.024 0.046
## 11 St. Mark's Maternity Hospital (SMMH) age 420 0 84 12 15 15.7 12.4 0.606 1.19
## 12 St. Mark's Maternity Hospital (SMMH) temp 410 35.9 40.6 38.8 1.1 38.5 0.983 0.049 0.095Por último, también se puede utilizar rstatix para realizar las siguientes pruebas estadísticas:
Test-T
Utiliza una sintaxis de fórmula para especificar las columnas numéricas y categóricas:
linelist %>%
t_test(age_years ~ gender)## # A tibble: 1 × 10
## .y. group1 group2 n1 n2 statistic df p p.adj p.adj.signif
## * <chr> <chr> <chr> <int> <int> <dbl> <dbl> <dbl> <dbl> <chr>
## 1 age_years f m 2807 2803 -21.3 4902. 9.89e-97 9.89e-97 ****Utiliza ~ 1 y especifica mu = para un test-T de una muestra. Esto también puede hacerse por grupo.
linelist %>%
t_test(age_years ~ 1, mu = 30)## # A tibble: 1 × 7
## .y. group1 group2 n statistic df p
## * <chr> <chr> <chr> <int> <dbl> <dbl> <dbl>
## 1 age_years 1 null model 5802 -84.2 5801 0Si procede, las pruebas estadísticas pueden realizarse por grupos, como se muestra a continuación:
## # A tibble: 3 × 8
## gender .y. group1 group2 n statistic df p
## * <chr> <chr> <chr> <chr> <int> <dbl> <dbl> <dbl>
## 1 f age_years 1 null model 2807 -29.8 2806 7.52e-170
## 2 m age_years 1 null model 2803 5.70 2802 1.34e- 8
## 3 <NA> age_years 1 null model 192 -3.80 191 1.96e- 4Prueba de Shapiro-Wilk
Como ya se ha dicho, el tamaño de la muestra debe estar entre 3 y 5000.
linelist %>%
head(500) %>% # las 500 primeras filas de la lista de casos, sólo como ejemplo
shapiro_test(age_years)## # A tibble: 1 × 3
## variable statistic p
## <chr> <dbl> <dbl>
## 1 age_years 0.917 6.67e-16Prueba de suma de rangos de Wilcoxon
linelist %>%
wilcox_test(age_years ~ gender)## # A tibble: 1 × 9
## .y. group1 group2 n1 n2 statistic p p.adj p.adj.signif
## * <chr> <chr> <chr> <int> <int> <dbl> <dbl> <dbl> <chr>
## 1 age_years f m 2807 2803 2829274 3.47e-74 3.47e-74 ****Prueba de Kruskal-Wallis
También conocida como la prueba U de Mann-Whitney.
linelist %>%
kruskal_test(age_years ~ outcome)## # A tibble: 1 × 6
## .y. n statistic df p method
## * <chr> <int> <dbl> <int> <dbl> <chr>
## 1 age_years 5888 0.0457 1 0.831 Kruskal-WallisPrueba de Chi-cuadrado
La función para la prueba de chi-cuadrado funciona con tablas, así que primero creamos una tabulación cruzada. Hay muchas formas de crear una tabulación cruzada (véase Tablas descriptivas), pero aquí utilizamos tabyl() de janitor y eliminamos la columna más a la izquierda de las etiquetas de valores antes de pasarla a chisq_test().
## # A tibble: 1 × 6
## n statistic p df method p.signif
## * <dbl> <dbl> <dbl> <int> <chr> <chr>
## 1 5888 3.53 0.473 4 Chi-square test nsSe pueden ejecutar muchas más funciones y pruebas estadísticas con las funciones de rstatix. Consulta la documentación de rstatix o escribiendo ?rstatix.
18.4 Paquete gtsummary
Utilizaa gtsummary si quieres añadir los resultados de una prueba estadística a una tabla estéticamente presentada, creada con este paquete (como se describe en la sección gtsummary del capítulo Tablas descriptivas).
La realización de pruebas estadísticas de comparación con tbl_summary se lleva a cabo añadiendo la función add_p a una tabla y especificando qué prueba utilizar. Es posible obtener p-valores corregidos para múltiples pruebas utilizando la función add_q. Ejecuta ?tbl_summary para obtener más detalles.
Prueba de Chi-cuadrado
Compara las proporciones de una variable categórica en dos grupos. La prueba estadística por defecto de add_p(), cuando se aplica a una variable categórica es realizar una prueba de independencia de chi-cuadrado con corrección de continuidad, pero si algúna celda de valores esperados es inferior a 5, se utiliza una prueba exacta de Fisher.
linelist %>%
select(gender, outcome) %>% # mantiene las variables de interés
tbl_summary(by = outcome) %>% # produce la tabla resumen y especifica la variable de agrupación
add_p() # especifica qué test realizar## 1323 observations missing `outcome` have been removed. To include these observations, use `forcats::fct_explicit_na()` on `outcome` column before passing to `tbl_summary()`.| Characteristic | Death, N = 2,5821 | Recover, N = 1,9831 | p-value2 |
|---|---|---|---|
| gender | >0.9 | ||
| f | 1,227 (50%) | 953 (50%) | |
| m | 1,228 (50%) | 950 (50%) | |
| Unknown | 127 | 80 | |
| 1 n (%) | |||
| 2 Pearson's Chi-squared test | |||
Tests-T
Compara la diferencia de medias de una variable continua en dos grupos. Por ejemplo, hace la comparación de la media de edad por resultado del paciente.
linelist %>%
select(age_years, outcome) %>% # mantiene las variables de interés
tbl_summary( # produce la tabla resumen
statistic = age_years ~ "{mean} ({sd})", # especifica qué estadísticas mostrar
by = outcome) %>% # especifica la variable de agrupación
add_p(age_years ~ "t.test") # especifica qué prueba realizar## 1323 observations missing `outcome` have been removed. To include these observations, use `forcats::fct_explicit_na()` on `outcome` column before passing to `tbl_summary()`.| Characteristic | Death, N = 2,5821 | Recover, N = 1,9831 | p-value2 |
|---|---|---|---|
| age_years | 16 (12) | 16 (13) | 0.6 |
| Unknown | 32 | 28 | |
| 1 Mean (SD) | |||
| 2 Welch Two Sample t-test | |||
Test de suma de rangos de Wilcoxon
Compara la distribución de una variable continua en dos grupos. Por defecto se utiliza la prueba de suma de rangos de Wilcoxon y la mediana (IQR) cuando se comparan dos grupos. Sin embargo, para datos no distribuidos normalmente o para comparar varios grupos, la prueba de Kruskal-wallis es más apropiada.
linelist %>%
select(age_years, outcome) %>% # mantiene las variables de interés
tbl_summary( # produce la tabla resumen
statistic = age_years ~ "{median} ({p25}, {p75})", # especifica que estadistica mostrar (esta es por defecto asi que puede quitarse)
by = outcome) %>% # especifica la variable de agrupación
add_p(age_years ~ "wilcox.test") # especifica qué prueba realizar (por defecto así que se pueden dejar los paréntesis vacíos)## 1323 observations missing `outcome` have been removed. To include these observations, use `forcats::fct_explicit_na()` on `outcome` column before passing to `tbl_summary()`.| Characteristic | Death, N = 2,5821 | Recover, N = 1,9831 | p-value2 |
|---|---|---|---|
| age_years | 13 (6, 23) | 13 (6, 23) | 0.8 |
| Unknown | 32 | 28 | |
| 1 Median (IQR) | |||
| 2 Wilcoxon rank sum test | |||
Test de Kruskal-Wallis
Se usa para comparar la distribución de una variable continua en dos o más grupos, independientemente de que los datos se distribuyan normalmente.
linelist %>%
select(age_years, outcome) %>% # mantiene las variables de interés
tbl_summary( # produce la tabla resumen
statistic = age_years ~ "{median} ({p25}, {p75})", # especifica que estadistica mostrar (por defecto asi que puede quitarse)
by = outcome) %>% # especifica la variable de agrupación
add_p(age_years ~ "kruskal.test") # especifica qué test realizar## 1323 observations missing `outcome` have been removed. To include these observations, use `forcats::fct_explicit_na()` on `outcome` column before passing to `tbl_summary()`.| Characteristic | Death, N = 2,5821 | Recover, N = 1,9831 | p-value2 |
|---|---|---|---|
| age_years | 13 (6, 23) | 13 (6, 23) | 0.8 |
| Unknown | 32 | 28 | |
| 1 Median (IQR) | |||
| 2 Kruskal-Wallis rank sum test | |||
18.5 Correlaciones
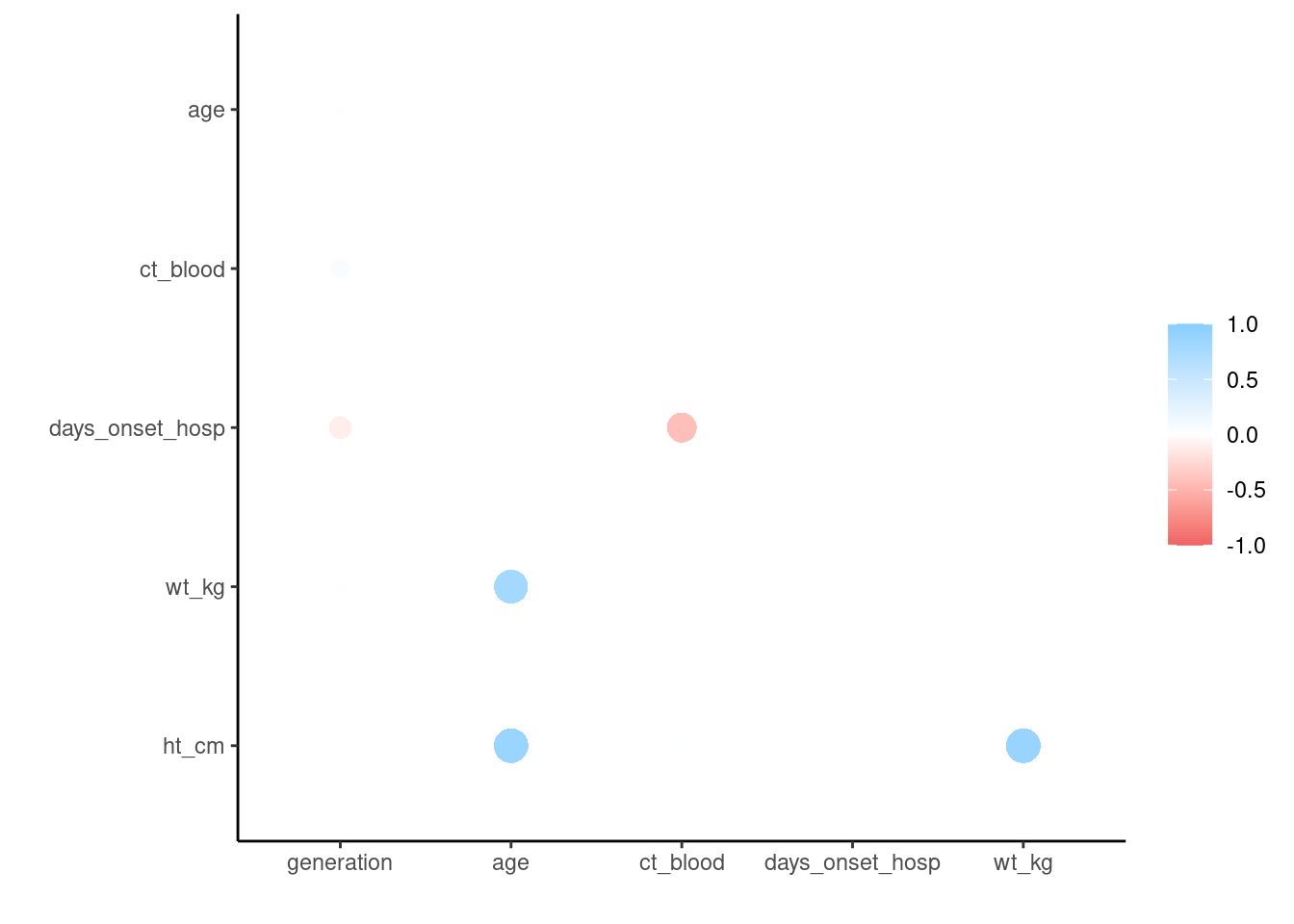
La correlación entre variables numéricas puede investigarse con el paquete corrr de tidyverse. Permite calcular las correlaciones mediante los test de Pearson, tau de Kendall o rho de Spearman. El paquete crea una tabla y también tiene una función para representar automáticamente los valores.
correlation_tab <- linelist %>%
select(generation, age, ct_blood, days_onset_hosp, wt_kg, ht_cm) %>% # keep numeric variables of interest
correlate() # mantiene las variables numéricas de interés
correlation_tab # imprimir## # A tibble: 6 × 7
## term generation age ct_blood days_onset_hosp wt_kg ht_cm
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 generation NA -0.0222 0.179 -0.288 -0.0302 -0.00942
## 2 age -0.0222 NA 0.00849 -0.000635 0.833 0.877
## 3 ct_blood 0.179 0.00849 NA -0.600 -0.00636 0.0181
## 4 days_onset_hosp -0.288 -0.000635 -0.600 NA 0.0153 -0.00953
## 5 wt_kg -0.0302 0.833 -0.00636 0.0153 NA 0.884
## 6 ht_cm -0.00942 0.877 0.0181 -0.00953 0.884 NA
## eliminar entradas duplicadas (la tabla anterior está reflejada)
correlation_tab <- correlation_tab %>%
shave()
## ver la tabla de correlaciones
correlation_tab## # A tibble: 6 × 7
## term generation age ct_blood days_onset_hosp wt_kg ht_cm
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 generation NA NA NA NA NA NA
## 2 age -0.0222 NA NA NA NA NA
## 3 ct_blood 0.179 0.00849 NA NA NA NA
## 4 days_onset_hosp -0.288 -0.000635 -0.600 NA NA NA
## 5 wt_kg -0.0302 0.833 -0.00636 0.0153 NA NA
## 6 ht_cm -0.00942 0.877 0.0181 -0.00953 0.884 NA
## representar correlaciones
rplot(correlation_tab)