17 Tablas descriptivas
Esta página muestra el uso de janitor, dplyr, gtsummary, rstatix y R base para resumir datos y crear tablas con estadísticas descriptivas.
En esta página se explica cómo crear* las tablas subyacentes, mientras que en la página Tablas para presentaciones se explica cómo darles un buen formato e imprimirlas.*
Cada uno de estos paquetes tiene ventajas y desventajas en cuanto a la simplicidad del código, la accesibilidad de los resultados y la calidad de los resultados impresos. Utiliza esta página para decidir qué enfoque se ajusta a tu situación.
Tienes varias opciones para producir tablas de resumen de tabulación y tabulación cruzada. Algunos de los factores a tener en cuenta son la simplicidad del código, la posibilidad de personalización, la salida deseada (impresa en la consola de R, como dataframe, o como una imagen .png/.jpeg/.html “bonita”), y la facilidad de posprocesamiento. Ten en cuenta los siguientes puntos a la hora de elegir la herramienta para tu situación.
- Utiliza
tabyl()de janitor para producir y “adornar” tabulaciones y tabulaciones cruzadas - Utiliza
get_summary_stats()de rstatix para generar fácilmente dataframes de estadísticas de resumen numérico para múltiples columnas y/o grupos - Utiliza
summarise()ycount()de dplyr para obtener estadísticas más complejas, ordenar las salidas de los dataframes o preparar los datos paraggplot() - Utiliza
tbl_summary() de gtsummary para producir tablas detalladas listas para su publicación - Utiliza
table()de R base si no tienes acceso a los paquetes anteriores
17.1 Preparación
Cargar paquetes
Este trozo de código muestra la carga de los paquetes necesarios para los análisis. En este manual destacamos p_load() de pacman, que instala el paquete si es necesario y lo carga para su uso. También puedes cargar los paquetes instalados con library() de R base. Consulta la página sobre Fundamentos de R para obtener más información sobre los paquetes de R.
pacman::p_load(
rio, # Importación de ficheros
here, # localizador de ficheros
skimr, # obtener una visión general de los datos
tidyverse, # gestión de datos + gráficos ggplot2
gtsummary, # resumen estadístico y tests
rstatix, # resumen estadístico y pruebas estadísticas
janitor, # añadir totales y porcentajes a las tablas
scales, # convertir fácilmente proporciones en porcentajes
flextable # convertir tablas en imágenes bonitas
)Importar datos
Importamos los datos de casos de una epidemia de ébola simulada. Si quieres seguir el proceso, clica para descargar linelist “limpio” (como archivo .rds). Importa los datos con la función import() del paquete rio (acepta muchos tipos de archivos como .xlsx, .rds, .csv - Mira la página de importación y exportación para más detalles).
# importar el listado de casos
linelist <- import("linelist_cleaned.rds")A continuación se muestran las primeras 50 filas del listado.
17.2 Visualizar datos
Paquete skimr
Utilizando el paquete skimr, puedes obtener una visión detallada y estéticamente agradable de cada una de las variables de tu conjunto de datos. Lee más sobre skimr en su página de github.
A continuación, se aplica la función skim() a todo el dataframe linelist. Se produce una visión general del dataframe y un resumen de cada columna (por tipo).
## obtener información sobre cada variable de un conjunto de datos
skim(linelist)| Name | linelist |
| Number of rows | 5888 |
| Number of columns | 30 |
| _______________________ | |
| Column type frequency: | |
| character | 13 |
| Date | 4 |
| factor | 2 |
| numeric | 11 |
| ________________________ | |
| Group variables | None |
Variable type: character
| skim_variable | n_missing | complete_rate | min | max | empty | n_unique | whitespace |
|---|---|---|---|---|---|---|---|
| case_id | 0 | 1.00 | 6 | 6 | 0 | 5888 | 0 |
| outcome | 1323 | 0.78 | 5 | 7 | 0 | 2 | 0 |
| gender | 278 | 0.95 | 1 | 1 | 0 | 2 | 0 |
| age_unit | 0 | 1.00 | 5 | 6 | 0 | 2 | 0 |
| hospital | 0 | 1.00 | 5 | 36 | 0 | 6 | 0 |
| infector | 2088 | 0.65 | 6 | 6 | 0 | 2697 | 0 |
| source | 2088 | 0.65 | 5 | 7 | 0 | 2 | 0 |
| fever | 249 | 0.96 | 2 | 3 | 0 | 2 | 0 |
| chills | 249 | 0.96 | 2 | 3 | 0 | 2 | 0 |
| cough | 249 | 0.96 | 2 | 3 | 0 | 2 | 0 |
| aches | 249 | 0.96 | 2 | 3 | 0 | 2 | 0 |
| vomit | 249 | 0.96 | 2 | 3 | 0 | 2 | 0 |
| time_admission | 765 | 0.87 | 5 | 5 | 0 | 1072 | 0 |
Variable type: Date
| skim_variable | n_missing | complete_rate | min | max | median | n_unique |
|---|---|---|---|---|---|---|
| date_infection | 2087 | 0.65 | 2014-03-19 | 2015-04-27 | 2014-10-11 | 359 |
| date_onset | 256 | 0.96 | 2014-04-07 | 2015-04-30 | 2014-10-23 | 367 |
| date_hospitalisation | 0 | 1.00 | 2014-04-17 | 2015-04-30 | 2014-10-23 | 363 |
| date_outcome | 936 | 0.84 | 2014-04-19 | 2015-06-04 | 2014-11-01 | 371 |
Variable type: factor
| skim_variable | n_missing | complete_rate | ordered | n_unique | top_counts |
|---|---|---|---|---|---|
| age_cat | 86 | 0.99 | FALSE | 8 | 0-4: 1095, 5-9: 1095, 20-: 1073, 10-: 941 |
| age_cat5 | 86 | 0.99 | FALSE | 17 | 0-4: 1095, 5-9: 1095, 10-: 941, 15-: 743 |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 |
|---|---|---|---|---|---|---|---|---|---|
| generation | 0 | 1.00 | 16.56 | 5.79 | 0.00 | 13.00 | 16.00 | 20.00 | 37.00 |
| age | 86 | 0.99 | 16.07 | 12.62 | 0.00 | 6.00 | 13.00 | 23.00 | 84.00 |
| age_years | 86 | 0.99 | 16.02 | 12.64 | 0.00 | 6.00 | 13.00 | 23.00 | 84.00 |
| lon | 0 | 1.00 | -13.23 | 0.02 | -13.27 | -13.25 | -13.23 | -13.22 | -13.21 |
| lat | 0 | 1.00 | 8.47 | 0.01 | 8.45 | 8.46 | 8.47 | 8.48 | 8.49 |
| wt_kg | 0 | 1.00 | 52.64 | 18.58 | -11.00 | 41.00 | 54.00 | 66.00 | 111.00 |
| ht_cm | 0 | 1.00 | 124.96 | 49.52 | 4.00 | 91.00 | 129.00 | 159.00 | 295.00 |
| ct_blood | 0 | 1.00 | 21.21 | 1.69 | 16.00 | 20.00 | 22.00 | 22.00 | 26.00 |
| temp | 149 | 0.97 | 38.56 | 0.98 | 35.20 | 38.20 | 38.80 | 39.20 | 40.80 |
| bmi | 0 | 1.00 | 46.89 | 55.39 | -1200.00 | 24.56 | 32.12 | 50.01 | 1250.00 |
| days_onset_hosp | 256 | 0.96 | 2.06 | 2.26 | 0.00 | 1.00 | 1.00 | 3.00 | 22.00 |
También puedes utilizar la función summary(), de R base, para obtener información completta sobre unos datos, pero esta salida puede ser más difícil de leer que utilizando skimr. Por eso no se muestra a continuación esta salida, para ahorrar espacio de la página.
## obtener información sobre cada variable de un conjunto de datos
summary(linelist)Estadísticas resumidas
Puedes utilizar las funciones de R base para producir estadísticas de resumen sobre una columna numérica. Puedes producir la mayoría de las estadísticas de resumen útiles para una columna numérica utilizando summary(), como se indica a continuación. Ten en cuenta que también debe especificarse el nombre del dataframe, como se muestra a continuación.
summary(linelist$age_years)## Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
## 0.00 6.00 13.00 16.02 23.00 84.00 86Puedes acceder y guardar una parte específica de la misma con los corchetes de índice [ ]:
summary(linelist$age_years)[[2]] # devuelve sólo el 2º elemento## [1] 6
# equivalente, alternativa a la anterior por nombre de elemento
# summary(linelist$age_years)[["1st Qu."]] Puedes mostrar estadísticas individuales con funciones de R base como max(), min(), median(), mean(), quantile(), sd(), y range(). Consulta la página de Fundamentos de R para obtener una lista completa.
PRECAUCIÓN: Si tus datos contienen valores faltantes, R quiere que lo sepas y por ello mostrará NA a menos que se especifique en las funciones matemáticas anteriores que quieres que R ignore los valores faltantes, mediante el argumento na.rm = TRUE.
Puedes utilizar la función get_summary_stats() de rstatix para producir las estadísticas de resumen en un formato de dataframe. Esto puede ser útil para realizar operaciones posteriores o trazar los números. Consulta la página Tests estadísticos simples para obtener más detalles sobre el paquete rstatix y sus funciones.
linelist %>%
get_summary_stats(
age, wt_kg, ht_cm, ct_blood, temp, # columnas para calcular
type = "common") # estadísticas resumidas ## # A tibble: 5 × 10
## variable n min max median iqr mean sd se ci
## <fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 age 5802 0 84 13 17 16.1 12.6 0.166 0.325
## 2 wt_kg 5888 -11 111 54 25 52.6 18.6 0.242 0.475
## 3 ht_cm 5888 4 295 129 68 125. 49.5 0.645 1.26
## 4 ct_blood 5888 16 26 22 2 21.2 1.69 0.022 0.043
## 5 temp 5739 35.2 40.8 38.8 1 38.6 0.977 0.013 0.02517.3 paquete janitor
Los paquetes janitor ofrecen la función tabyl() para producir tabulaciones y tabulaciones cruzadas, que pueden ser “adornadas” o modificadas con funciones de ayuda para mostrar porcentajes, proporciones, recuentos, etc.
A continuación, enlazamos el dataframe linelist con pipe a las funciones de limpieza e imprimimos el resultado. Si lo deseas, también puedes guardar las tablas resultantes con el operador de asignación <-.
Tabyl simple
El uso por defecto de tabyl() en una columna específica produce los valores únicos, los recuentos y sus proporciones por columna. Las proporciones pueden tener muchos dígitos. Puedes ajustar el número de decimales con adorn_rounding() como se describe a continuación.
linelist %>% tabyl(age_cat)## age_cat n percent valid_percent
## 0-4 1095 0.185971467 0.188728025
## 5-9 1095 0.185971467 0.188728025
## 10-14 941 0.159816576 0.162185453
## 15-19 743 0.126188859 0.128059290
## 20-29 1073 0.182235054 0.184936229
## 30-49 754 0.128057065 0.129955188
## 50-69 95 0.016134511 0.016373664
## 70+ 6 0.001019022 0.001034126
## <NA> 86 0.014605978 NAComo puedes ver arriba, si hay valores que faltan se muestran en una fila etiquetada como NA. Puedes suprimirlos con show_na = FALSE. Si no hay valores faltantes, esta fila no aparecerá. Si hay valores faltantes, todas las proporciones se dan como crudas (el denominador incluye los recuentos de NA) y “válidas” (el denominador excluye los recuentos de NA).
Si la columna es de tipo factor y sólo hay ciertos niveles en sus datos, todos los niveles seguirán apareciendo en la tabla. Puedes suprimir esta característica especificando show_missing_levels = FALSE. Lee más en la página de Factores.
Tabulación cruzada
Los recuentos de tabulación cruzada se consiguen añadiendo una o más columnas adicionales dentro de tabyl(). Ten en cuenta que ahora sólo se muestran los recuentos - Las proporciones y porcentajes se pueden añadir con los pasos adicionales que se muestran a continuación.
linelist %>% tabyl(age_cat, gender)## age_cat f m NA_
## 0-4 640 416 39
## 5-9 641 412 42
## 10-14 518 383 40
## 15-19 359 364 20
## 20-29 468 575 30
## 30-49 179 557 18
## 50-69 2 91 2
## 70+ 0 5 1
## <NA> 0 0 86“Adornando” el tabyl
Utiliza las funciones de “adorno” de janitor para añadir totales o convertir a proporciones, porcentajes, o ajustar la visualización de otro modo. A menudo, enlazarás el tabyl con pipe a través de varias de estas funciones.
| Función | Resultado |
|---|---|
adorn_totals() |
Añade los totales (where = “row”, “col”, o “both”). Establecer name = para el “Total”. |
adorn_percentages() |
Convierte los recuentos en proporciones, con denominator = “row”, “col”, o “all” |
adorn_pct_formatting() |
Convierte las proporciones en porcentajes. Especifica los digits =. Elimina el símbolo “%” con affix_sign = FALSE. |
adorn_rounding() |
Para redondear proporciones a digits =. Para redondear porcentajes utiliza adorn_pct_formatting() con digits =. |
adorn_ns() |
Añade recuentos a una tabla de proporciones o porcentajes. indica la position = “rear” para mostrar los recuentos entre paréntesis, o “front” para poner los porcentajes entre paréntesis. |
adorn_title() |
Añade una cadena mediante los argumentos row_name = y/o col_name =
|
Se consciente del orden en que se aplican las funciones anteriores. A continuación, algunos ejemplos.
Una simple tabla unidireccional con porcentajes en lugar de las proporciones por defecto.
linelist %>% # lista de casos
tabyl(age_cat) %>% # tabular recuentos y proporciones por categoría de edad
adorn_pct_formatting() # convertir proporciones en porcentajes## age_cat n percent valid_percent
## 0-4 1095 18.6% 18.9%
## 5-9 1095 18.6% 18.9%
## 10-14 941 16.0% 16.2%
## 15-19 743 12.6% 12.8%
## 20-29 1073 18.2% 18.5%
## 30-49 754 12.8% 13.0%
## 50-69 95 1.6% 1.6%
## 70+ 6 0.1% 0.1%
## <NA> 86 1.5% -Una tabulación cruzada con un total de filas y porcentajes de filas.
linelist %>%
tabyl(age_cat, gender) %>% # recuentos por edad y sexo
adorn_totals(where = "row") %>% # añadir fila con totales
adorn_percentages(denominator = "row") %>% # convertir recuentos en proporciones
adorn_pct_formatting(digits = 1) # convertir proporciones en porcentajes## age_cat f m NA_
## 0-4 58.4% 38.0% 3.6%
## 5-9 58.5% 37.6% 3.8%
## 10-14 55.0% 40.7% 4.3%
## 15-19 48.3% 49.0% 2.7%
## 20-29 43.6% 53.6% 2.8%
## 30-49 23.7% 73.9% 2.4%
## 50-69 2.1% 95.8% 2.1%
## 70+ 0.0% 83.3% 16.7%
## <NA> 0.0% 0.0% 100.0%
## Total 47.7% 47.6% 4.7%Una tabulación cruzada ajustada para que aparezcan tanto los recuentos como los porcentajes.
linelist %>% # lista de casos
tabyl(age_cat, gender) %>% # tabulación cruzada de recuentos
adorn_totals(where = "row") %>% # añadir una fila de totales
adorn_percentages(denominator = "col") %>% # convertir a proporciones
adorn_pct_formatting() %>% # convertir a porcentajes
adorn_ns(position = "front") %>% # mostrar como: "casos (porcent)"
adorn_title( # ajustar títulos
row_name = "Age Category",
col_name = "Gender")## Gender
## Age Category f m NA_
## 0-4 640 (22.8%) 416 (14.8%) 39 (14.0%)
## 5-9 641 (22.8%) 412 (14.7%) 42 (15.1%)
## 10-14 518 (18.5%) 383 (13.7%) 40 (14.4%)
## 15-19 359 (12.8%) 364 (13.0%) 20 (7.2%)
## 20-29 468 (16.7%) 575 (20.5%) 30 (10.8%)
## 30-49 179 (6.4%) 557 (19.9%) 18 (6.5%)
## 50-69 2 (0.1%) 91 (3.2%) 2 (0.7%)
## 70+ 0 (0.0%) 5 (0.2%) 1 (0.4%)
## <NA> 0 (0.0%) 0 (0.0%) 86 (30.9%)
## Total 2807 (100.0%) 2803 (100.0%) 278 (100.0%)Impresión del tabyl
Por defecto, el tabyl se imprimirá en crudo en la consola de R.
Alternativamente, puedes pasar el tabyl a flextable o un paquete similar para imprimirlo como una imagen “bonita” en el visor de RStudio, que podría exportarse como .png, .jpeg, .html, etc. Esto se discute en la página Tablas para presentaciones. Ten en cuenta que si imprimes de esta manera y utilizas adorn_titles(), debes especificar placement = "combined".
linelist %>%
tabyl(age_cat, gender) %>%
adorn_totals(where = "col") %>%
adorn_percentages(denominator = "col") %>%
adorn_pct_formatting() %>%
adorn_ns(position = "front") %>%
adorn_title(
row_name = "Age Category",
col_name = "Gender",
placement = "combined") %>% # esto es necesario para imprimir como imagen
flextable::flextable() %>% # convertir a imagen bonita
flextable::autofit() # formatear a una línea por fila Age Category/Gender |
f |
m |
NA_ |
Total |
|---|---|---|---|---|
0-4 |
640 (22.8%) |
416 (14.8%) |
39 (14.0%) |
1095 (18.6%) |
5-9 |
641 (22.8%) |
412 (14.7%) |
42 (15.1%) |
1095 (18.6%) |
10-14 |
518 (18.5%) |
383 (13.7%) |
40 (14.4%) |
941 (16.0%) |
15-19 |
359 (12.8%) |
364 (13.0%) |
20 (7.2%) |
743 (12.6%) |
20-29 |
468 (16.7%) |
575 (20.5%) |
30 (10.8%) |
1073 (18.2%) |
30-49 |
179 (6.4%) |
557 (19.9%) |
18 (6.5%) |
754 (12.8%) |
50-69 |
2 (0.1%) |
91 (3.2%) |
2 (0.7%) |
95 (1.6%) |
70+ |
0 (0.0%) |
5 (0.2%) |
1 (0.4%) |
6 (0.1%) |
0 (0.0%) |
0 (0.0%) |
86 (30.9%) |
86 (1.5%) |
Uso en otras tablas
Puedes utilizar las funciones adorn_() de janitor en otras tablas, como las creadas por summarise() y count() de dplyr, o table() de R base. Por ejemplo:
## hospital n
## Central Hospital 454
## Military Hospital 896
## Missing 1469
## Other 885
## Port Hospital 1762
## St. Mark's Maternity Hospital (SMMH) 422
## Total 5888Guardar el tabyl
Si conviertes la tabla en una imagen “bonita” con un paquete como flextable, puedes guardarla con funciones de ese paquete - como save_as_html(), save_as_word(), save_as_ppt(), y save_as_image() de flextable (como se discute más ampliamente en la página Tablas para presentaciones). A continuación, la tabla se guarda como un documento de Word, en el que se puede seguir editando a mano.
linelist %>%
tabyl(age_cat, gender) %>%
adorn_totals(where = "col") %>%
adorn_percentages(denominator = "col") %>%
adorn_pct_formatting() %>%
adorn_ns(position = "front") %>%
adorn_title(
row_name = "Age Category",
col_name = "Gender",
placement = "combined") %>%
flextable::flextable() %>% # convertir a imagen
flextable::autofit() %>% # asegurar sólo una línea por fila
flextable::save_as_docx(path = "tabyl.docx") # guardar como documento Word en la carpeta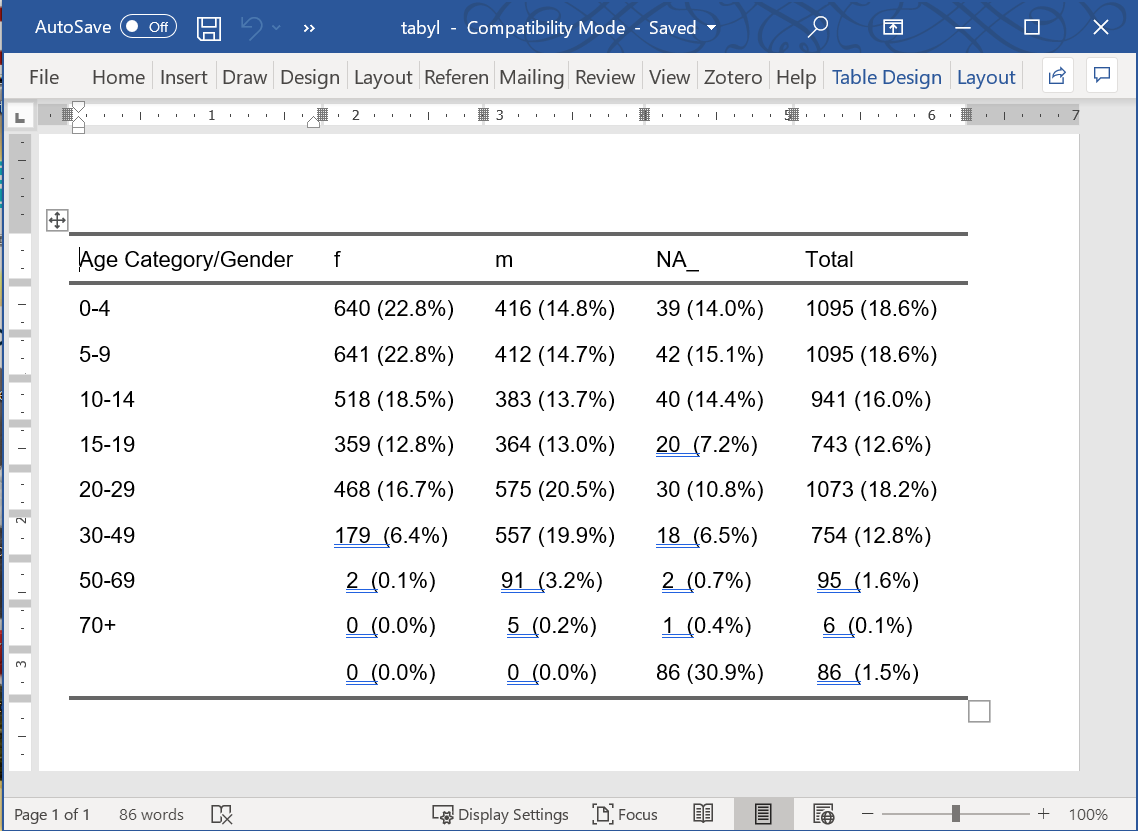
Estadísticas
Puedes aplicar a las tabyl tests estadísticos como chisq.test() o fisher.test() del paquete stats, como se muestra a continuación. Ten en cuenta que los valores faltantes no están permitidos, por lo que se excluyen de la tabulación con show_na = FALSE.
age_by_outcome <- linelist %>%
tabyl(age_cat, outcome, show_na = FALSE)
chisq.test(age_by_outcome)##
## Pearson's Chi-squared test
##
## data: age_by_outcome
## X-squared = 6.4931, df = 7, p-value = 0.4835Consulta la página sobre Tests estadísticos sencillos para obtener más código y consejos sobre estadística.
Otros consejos
- Incluye el argumento
na.rm = TRUEpara excluir los valores faltantes de cualquiera de los cálculos anteriores. - Si aplicas cualquier función de ayuda
adorn_*()a tablas no creadas portabyl(), puedes especificar una(s) columna(s) particular(es) para aplicarlas comoadorn_percentage(,,,c(cases,deaths))(especifícalos en el cuarto argumento sin nombre). La sintaxis no es sencilla. Considera la posibilidad de utilizarsummarise()en su lugar. - Puedes leer más detalles en la página de janitor y en esta viñeta de tabyl.
17.4 paquete dplyr
dplyr forma parte de los paquetes tidyverse y es una herramienta de gestión de datos muy común. La creación de tablas con las funciones de dplyr summarise() y count() es un enfoque útil para calcular estadísticas de resumen, resumir por grupos o pasar tablas a ggplot().
summarise() crea un nuevo dataframe de resumen. Si los datos no están agrupados, se producirá un dataframe de una fila con las estadísticas de resumen especificadas de todo el dataframe. Si los datos están agrupados, el nuevo dataframe tendrá una fila por grupo (véase la página Agrupar datos).
Dentro del paréntesis de summarise(), se proporcionan los nombres de cada nueva columna de resumen, seguidos de un signo de igualdad y de una función estadística a aplicar.
SUGERENCIA: La función summarise funciona tanto con la ortografía británica como con la estadounidense (summarise() y summarize()).
Obtener recuentos
La función más sencilla de aplicar dentro de summarise() es n(). Deja los paréntesis vacíos para contar el número de filas.
linelist %>% # comienza con linelist
summarise(n_rows = n()) # devuelve un nuevo dataframe de resumen con la columna n_rows## n_rows
## 1 5888Esto se vuelve más interesante si hemos agrupado los datos de antemano.
linelist %>%
group_by(age_cat) %>% # agrupa los datos por valores únicos en la columna age_cat
summarise(n_rows = n()) # devuelve el número de filas *por grupo## # A tibble: 9 × 2
## age_cat n_rows
## <fct> <int>
## 1 0-4 1095
## 2 5-9 1095
## 3 10-14 941
## 4 15-19 743
## 5 20-29 1073
## 6 30-49 754
## 7 50-69 95
## 8 70+ 6
## 9 <NA> 86El comando anterior se puede acortar utilizando la función count() en su lugar. count() hace lo siguiente:
- Agrupa los datos por las columnas que se le proporcionan
- Los resume con
n()(creando la columnan) - Desagrupa los datos
## age_cat n
## 1 0-4 1095
## 2 5-9 1095
## 3 10-14 941
## 4 15-19 743
## 5 20-29 1073
## 6 30-49 754
## 7 50-69 95
## 8 70+ 6
## 9 <NA> 86Puedes cambiar el nombre de la columna de recuentos de la n por defecto a otra cosa especificando a name =.
Los recuentos tabulados de dos o más columnas de agrupación se siguen devolviendo en formato “largo”, con los recuentos en la columna n. Consulta la página sobre Pivotar datos para conocer los formatos de datos “long” y “wide”.
## age_cat outcome n
## 1 0-4 Death 471
## 2 0-4 Recover 364
## 3 0-4 <NA> 260
## 4 5-9 Death 476
## 5 5-9 Recover 391
## 6 5-9 <NA> 228
## 7 10-14 Death 438
## 8 10-14 Recover 303
## 9 10-14 <NA> 200
## 10 15-19 Death 323
## 11 15-19 Recover 251
## 12 15-19 <NA> 169
## 13 20-29 Death 477
## 14 20-29 Recover 367
## 15 20-29 <NA> 229
## 16 30-49 Death 329
## 17 30-49 Recover 238
## 18 30-49 <NA> 187
## 19 50-69 Death 33
## 20 50-69 Recover 38
## 21 50-69 <NA> 24
## 22 70+ Death 3
## 23 70+ Recover 3
## 24 <NA> Death 32
## 25 <NA> Recover 28
## 26 <NA> <NA> 26Mostrar todos los niveles
Si estás tabulando una columna de tipo factor, puedes asegurarte de que se muestren todos los niveles (no sólo los niveles con valores en los datos) añadiendo .drop = FALSE en el comando summarise() o count().
Esta técnica es útil para estandarizar sus tablas/gráficos. Por ejemplo, si está creando cifras para varios subgrupos, o creando repetidamente la cifra para informes de rutina. En cada una de estas circunstancias, la presencia de valores en los datos puede fluctuar, pero puedes definir niveles que permanezcan constantes.
Para más información, consulta la página sobre factores.
Proporciones
Las proporciones pueden añadirse pasando la tabla por mutate() para crear una nueva columna. Define la nueva columna como la columna de recuentos (n por defecto) dividida por la sum() de la columna de recuentos (esto producirá una proporción).
Ten en cuenta que en este caso, sum() en el comando mutate() producirá la suma de toda la columna n para utilizarla como denominador de la proporción. Como se explica en la página Agrupar datos, si sum() se utiliza en datos agrupados (por ejemplo, si el comando mutate() sigue inmediatamente a un comando group_by()), producirá sumas por grupo. Como se acaba de indicar, count() termina sus acciones desagrupando. Por lo tanto, en este escenario obtenemos proporciones de columnas completas.
Para mostrar fácilmente los porcentajes, puedes envolver la proporción en la función percent() del paquete scales (Ten en cuenta que se convierte en tipo carácter).
age_summary <- linelist %>%
count(age_cat) %>% # agrupa y cuenta por sexo (produce la columna "n")
mutate( # crea porcentaje de columna - mira el denominador
percent = scales::percent(n / sum(n)))
# imprime
age_summary## age_cat n percent
## 1 0-4 1095 18.60%
## 2 5-9 1095 18.60%
## 3 10-14 941 15.98%
## 4 15-19 743 12.62%
## 5 20-29 1073 18.22%
## 6 30-49 754 12.81%
## 7 50-69 95 1.61%
## 8 70+ 6 0.10%
## 9 <NA> 86 1.46%A continuación se presenta un método para calcular las proporciones dentro de los grupos. Se basa en diferentes niveles de agrupación de datos que se aplican y eliminan selectivamente. En primer lugar, los datos se agrupan en función del outcome mediante group_by(). A continuación, se aplica count(). Esta función agrupa además los datos por age_cat y devuelve los recuentos para cada combinación de outcome-age-cat. Es importante destacar que, al finalizar tu proceso, count() también desagrupa la agrupación age_cat, por lo que la única agrupación de datos que queda es la agrupación original por outcome. Por lo tanto, el paso final del cálculo de las proporciones (denominador sum(n)) sigue estando agrupado por outcome.
age_by_outcome <- linelist %>% # comienza con linelist
group_by(outcome) %>% # agrupa por resultado
count(age_cat) %>% # agrupa y cuenta por age_cat, y luego elimina la agrupación age_cat
mutate(percent = scales::percent(n / sum(n))) # calcula el porcentaje - observa que el denominador es por grupo de resultadosGráficas
Mostrar una tabla “larga” como la anterior con ggplot() es relativamente sencillo. Los datos están naturalmente en formato “largo”, que es aceptado naturalmente por ggplot(). Mira más ejemplos en las páginas Conceptos básicos de ggplot y consejos de ggplot.
linelist %>% # comienza con linelist
count(age_cat, outcome) %>% # agrupa y tabula los recuentos en dos columnas
ggplot()+ # pasa el nuevo data frame a ggplot
geom_col( # crea un gráfico de barras
mapping = aes(
x = outcome, # asigna el resultado al eje x
fill = age_cat, # mapea age_cat al relleno
y = n)) # mapea la columna de recuentos `n` a la altura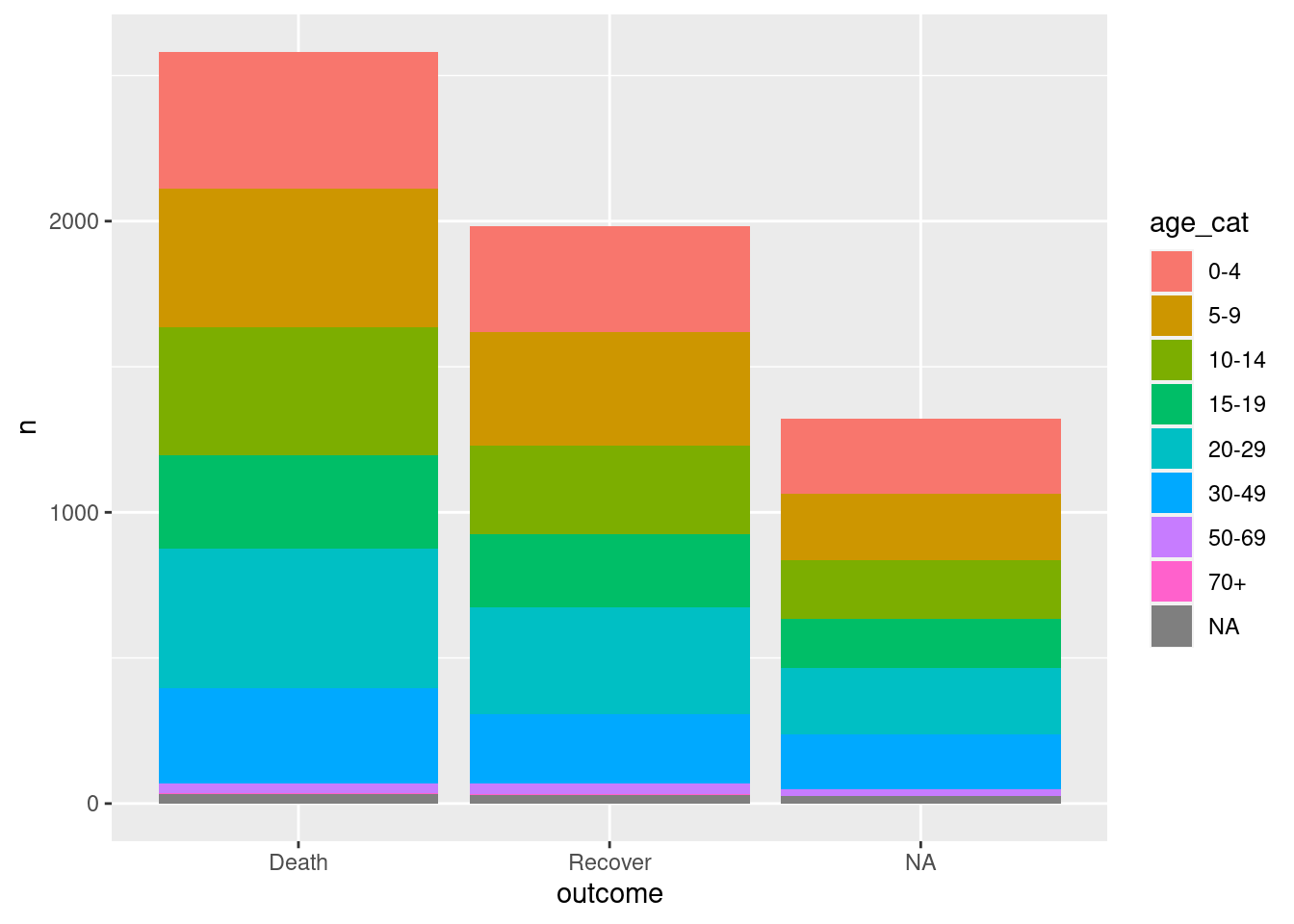
Estadísticas resumidas
Una de las principales ventajas de dplyr y de summarise() es la capacidad de producir resúmenes estadísticos más avanzados como median(), mean(), max(), min(), sd() (desviación estándar) y percentiles. También puedes utilizar sum() para mostrar el número de filas que cumplen ciertos criterios lógicos. Al igual que en el caso anterior, estas salidas pueden producirse para todo el conjunto de dataframes o por grupos.
La sintaxis es la misma: dentro de los paréntesis de summarise() se proporcionan los nombres de cada nueva columna de resumen, seguidos de un signo de igualdad y de una función estadística para aplicar. Dentro de la función estadística, indica la(s) columna(s) con la(s) que se va a operar y cualquier argumento relevante (por ejemplo, na.rm = TRUE para la mayoría de las funciones matemáticas).
También puedes utilizar sum() para mostrar el número de filas que cumplen un criterio lógico. La expresión que contiene se cuenta si se evalúa como TRUE. Por ejemplo:
-
sum(age_years < 18, na.rm=T)
-
sum(gender == "male", na.rm=T)
sum(response %in% c("Likely", "Very Likely"))
A continuación, se resumen los datos de linelist para describir los días de retraso desde el inicio de los síntomas hasta el ingreso en el hospital (columna days_onset_hosp), por hospital.
summary_table <- linelist %>% # comienza con linelist, y guarda como nuevo objeto
group_by(hospital) %>% # agrupa todos los cálculos por hospital
summarise( # sólo se devolverán las siguientes columnas de resumen
cases = n(), # número de filas por grupo
delay_max = max(days_onset_hosp, na.rm = T), # retraso máximo
delay_mean = round(mean(days_onset_hosp, na.rm=T), digits = 1), # retraso medio, redondeado
delay_sd = round(sd(days_onset_hosp, na.rm = T), digits = 1), # desviación estándar de los retrasos, redondeada
delay_3 = sum(days_onset_hosp >= 3, na.rm = T), # número de filas con retraso de 3 o más días
pct_delay_3 = scales::percent(delay_3 / cases) # convierte la columna de retrasos definida anteriormente en porcentaje
)
summary_table # print## # A tibble: 6 × 7
## hospital cases delay_max delay_mean delay_sd delay_3 pct_delay_3
## <chr> <int> <dbl> <dbl> <dbl> <int> <chr>
## 1 Central Hospital 454 12 1.9 1.9 108 24%
## 2 Military Hospital 896 15 2.1 2.4 253 28%
## 3 Missing 1469 22 2.1 2.3 399 27%
## 4 Other 885 18 2 2.2 234 26%
## 5 Port Hospital 1762 16 2.1 2.2 470 27%
## 6 St. Mark's Maternity Hospital (SMMH) 422 18 2.1 2.3 116 27%Algunos consejos:
- Utilizar
sum()con una sentencia lógica para “contar” las filas que cumplen ciertos criterios (==) - Ten en cuenta el uso de
na.rm = TRUEdentro de funciones matemáticas comosum(), de lo contrario se mostraráNAsi hay algún valor faltante - Utiliza la función
percent()del paquete scales para convertir fácilmente a porcentajes - Ajusta la
accuracy =(precisión) a 0,1 o 0,01 para garantizar 1 o 2 decimales respectivamente - Utilizar
round()de R base para especificar los decimales - Para calcular estas estadísticas en todo el set de datos, utiliza
summarise()singroup_by() - Puedes crear columnas para los propósitos de cálculos posteriores (por ejemplo, denominadores) que eventualmente se eliminan de tu dataframe con
select().
Estadísticas condicionales
Es posible que desees producir estadísticas condicionales, por ejemplo, el máximo de filas que cumplen ciertos criterios. Esto se puede hacer sub-configurando la columna con corchetes [ ]. El ejemplo siguiente devuelve la temperatura máxima de los pacientes clasificados con o sin fiebre. Sin embargo, ten en cuenta que puede ser más adecuado añadir otra columna al comando group_by() y pivot_wider() (como se demuestra a continuación).
linelist %>%
group_by(hospital) %>%
summarise(
max_temp_fvr = max(temp[fever == "yes"], na.rm = T),
max_temp_no = max(temp[fever == "no"], na.rm = T)
)## # A tibble: 6 × 3
## hospital max_temp_fvr max_temp_no
## <chr> <dbl> <dbl>
## 1 Central Hospital 40.4 38
## 2 Military Hospital 40.5 38
## 3 Missing 40.6 38
## 4 Other 40.8 37.9
## 5 Port Hospital 40.6 38
## 6 St. Mark's Maternity Hospital (SMMH) 40.6 37.9Pegar valores
La función str_glue() de stringr es útil para combinar valores de varias columnas en una nueva columna. En este contexto, se suele utilizar después del comando summarise().
En la página Caracteres y cadenas, se discuten varias opciones para combinar columnas, incluyendo unite(), y paste0(). En este caso de uso, abogamos por str_glue() porque es más flexible que unite() y tiene una sintaxis más sencilla que paste0().
A continuación, el dataframe de summary_table (creado anteriormente) se muta de manera que las columnas delay_mean y delay_sd se combinan, se añade el formato de paréntesis a la nueva columna y se eliminan sus respectivas columnas antiguas.
Luego, para hacer la tabla más presentable, se añade una fila de totales con adorn_totals() de janitor (que ignora las columnas no numéricas). Por último, utilizamos select() de dplyr para reordenar y renombrar los nombres de las columnas.
Ahora puedes pasar a flextable e imprimir la tabla a Word, .png, .jpeg, .html, Powerpoint, RMarkdown, etc. (ver la página de Tablas para presentaciones).
summary_table %>%
mutate(delay = str_glue("{delay_mean} ({delay_sd})")) %>% # combina y formatea otros valores
select(-c(delay_mean, delay_sd)) %>% # elimina dos columnas antiguas
adorn_totals(where = "row") %>% # añade el total de la fila
select( # ordena y renombra las cols
"Hospital Name" = hospital,
"Cases" = cases,
"Max delay" = delay_max,
"Mean (sd)" = delay,
"Delay 3+ days" = delay_3,
"% delay 3+ days" = pct_delay_3
)## Hospital Name Cases Max delay Mean (sd) Delay 3+ days % delay 3+ days
## Central Hospital 454 12 1.9 (1.9) 108 24%
## Military Hospital 896 15 2.1 (2.4) 253 28%
## Missing 1469 22 2.1 (2.3) 399 27%
## Other 885 18 2 (2.2) 234 26%
## Port Hospital 1762 16 2.1 (2.2) 470 27%
## St. Mark's Maternity Hospital (SMMH) 422 18 2.1 (2.3) 116 27%
## Total 5888 101 - 1580 -Percentiles
Los percentiles y cuartiles en dplyr merecen una mención especial. Para mostrar los cuantiles, utiliza quantile() con los valores predeterminados o especifica el valor o los valores que deseas con probs =.
# obtiene valores de percentil de edad por defecto (0%, 25%, 50%, 75%, 100%)
linelist %>%
summarise(age_percentiles = quantile(age_years, na.rm = TRUE))## age_percentiles
## 1 0
## 2 6
## 3 13
## 4 23
## 5 84
# obtiene valores de percentil de edad especificados manualmente (5%, 50%, 75%, 98%)
linelist %>%
summarise(
age_percentiles = quantile(
age_years,
probs = c(.05, 0.5, 0.75, 0.98),
na.rm=TRUE)
)## age_percentiles
## 1 1
## 2 13
## 3 23
## 4 48Si deseas mostrar cuantiles por grupo, puedes encontrar salidas largas y menos útiles si simplemente añades otra columna a group_by(). Por lo tanto, prueba este enfoque en su lugar: crea una columna para cada nivel de cuantil deseado.
# obtiene valores de percentil de edad especificados manualmente (5%, 50%, 75%, 98%)
linelist %>%
group_by(hospital) %>%
summarise(
p05 = quantile(age_years, probs = 0.05, na.rm=T),
p50 = quantile(age_years, probs = 0.5, na.rm=T),
p75 = quantile(age_years, probs = 0.75, na.rm=T),
p98 = quantile(age_years, probs = 0.98, na.rm=T)
)## # A tibble: 6 × 5
## hospital p05 p50 p75 p98
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 Central Hospital 1 12 21 48
## 2 Military Hospital 1 13 24 45
## 3 Missing 1 13 23 48.2
## 4 Other 1 13 23 50
## 5 Port Hospital 1 14 24 49
## 6 St. Mark's Maternity Hospital (SMMH) 2 12 22 50.2Aunque summarise() de dplyr ofrece ciertamente un control más fino, puedes encontrar que todas las estadísticas de resumen que necesitas pueden producirse con get_summary_stat() del paquete rstatix. Si se opera con datos agrupados, if mostrará 0%, 25%, 50%, 75% y 100%. Si se aplica a datos no agrupados, puedes especificar los percentiles con probs = c(.05, .5, .75, .98).
linelist %>%
group_by(hospital) %>%
rstatix::get_summary_stats(age, type = "quantile")## # A tibble: 6 × 8
## hospital variable n `0%` `25%` `50%` `75%` `100%`
## <chr> <fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Central Hospital age 445 0 6 12 21 58
## 2 Military Hospital age 884 0 6 14 24 72
## 3 Missing age 1441 0 6 13 23 76
## 4 Other age 873 0 6 13 23 69
## 5 Port Hospital age 1739 0 6 14 24 68
## 6 St. Mark's Maternity Hospital (SMMH) age 420 0 7 12 22 84
linelist %>%
rstatix::get_summary_stats(age, type = "quantile")## # A tibble: 1 × 7
## variable n `0%` `25%` `50%` `75%` `100%`
## <fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 age 5802 0 6 13 23 84Resumir datos agregados
Si comienza con datos agregados, al utilizar n() devuelve el número de filas, no la suma de los recuentos agregados. Para obtener sumas, utiliza sum() en la columna de recuentos de los datos.
Por ejemplo, digamos que se empieza con el dataframe de recuentos que se muestra a continuación, llamado linelist_agg - muestra en formato “largo” los recuentos de casos por resultado y género.
A continuación creamos este dataframe de ejemplo de recuentos de casos de linelist por resultado y sexo (se eliminan los valores faltantes para mayor claridad).
## outcome gender n
## 1 Death f 1227
## 2 Death m 1228
## 3 Recover f 953
## 4 Recover m 950Para sumar los recuentos (en la columna n) por grupo, puedes utilizar summarise() pero establecer la nueva columna igual a sum(n, na.rm=T)`. Para añadir un elemento condicional a la operación de suma, puedes utilizar la sintaxis del subconjunto [ ] en la columna de recuentos.
linelist_agg %>%
group_by(outcome) %>%
summarise(
total_cases = sum(n, na.rm=T),
male_cases = sum(n[gender == "m"], na.rm=T),
female_cases = sum(n[gender == "f"], na.rm=T))## # A tibble: 2 × 4
## outcome total_cases male_cases female_cases
## <chr> <int> <int> <int>
## 1 Death 2455 1228 1227
## 2 Recover 1903 950 953
across() varias columnas
Puedes utilizar summarise() en varias columnas utilizando across(). Esto facilita la vida cuando se desea calcular las mismas estadísticas para muchas columnas. Escribe across() dentro de summarise() y especifica lo siguiente:
.cols =como un vector de nombres de columnasc()o funciones de ayuda “tidyselect” (explicadas más adelante).fns =la función a realizar (sin paréntesis) - puedes proporcionar varias dentro de unalist()
A continuación, mean() se aplica a varias columnas numéricas. Se nombra explícitamente un vector de columnas a .cols = y se especifica una única función mean (sin paréntesis) a .fns =. Cualquier argumento adicional para la función (por ejemplo, na.rm=TRUE) se proporciona después de .fns =, separado por una coma.
Puede ser difícil conseguir el orden correcto de los paréntesis y las comas cuando se utiliza across(). Recuerda que dentro de across() debes incluir las columnas, las funciones y cualquier argumento extra necesario para las funciones.
linelist %>%
group_by(outcome) %>%
summarise(across(.cols = c(age_years, temp, wt_kg, ht_cm), # columnas
.fns = mean, # function
na.rm=T)) # argumentos extra## # A tibble: 3 × 5
## outcome age_years temp wt_kg ht_cm
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 Death 15.9 38.6 52.6 125.
## 2 Recover 16.1 38.6 52.5 125.
## 3 <NA> 16.2 38.6 53.0 125.Se pueden ejecutar varias funciones a la vez. A continuación se proporcionan las funciones mean y sd a .fns = dentro de una list(). Tienes la oportunidad de proporcionar nombres de caracteres (por ejemplo, “mean” y “sd”) que se añaden en los nuevos nombres de columna.
linelist %>%
group_by(outcome) %>%
summarise(across(.cols = c(age_years, temp, wt_kg, ht_cm), # columnas
.fns = list("mean" = mean, "sd" = sd), # multiples functiones
na.rm=T)) # argumentos extra## # A tibble: 3 × 9
## outcome age_years_mean age_years_sd temp_mean temp_sd wt_kg_mean wt_kg_sd ht_cm_mean ht_cm_sd
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Death 15.9 12.3 38.6 0.962 52.6 18.4 125. 48.7
## 2 Recover 16.1 13.0 38.6 0.997 52.5 18.6 125. 50.1
## 3 <NA> 16.2 12.8 38.6 0.976 53.0 18.9 125. 50.4Aquí están esas funciones de ayuda “tidyselect” que puedes proporcionar a .cols = para seleccionar columnas:
-
everything()- todas las demás columnas no mencionadas -
last_col()- la última columna -
where()- aplica una función a todas las columnas y selecciona las que son TRUE -
starts_with()- coincide con un prefijo especificado. Ejemplo:starts_with("date") -
ends_with()- coincide con un sufijo especificado. Ejemplo:ends_with("_end") -
contains()- columnas que contienen una cadena de caracteres. Ejemplo:contains("time") -
matches()- para aplicar una expresión regular (regex). Ejemplo:contains("[pt]al") -
num_range()- -
any_of()- coincide con el nombre de la columna. Es útil si el nombre puede no existir. Ejemplo:any_of(date_onset, date_death, cardiac_arrest)
Por ejemplo, para producir la media de cada columna numérica utiliza where() y proporciona la función as.numeric() (sin paréntesis). Todo esto queda dentro del comando across().
linelist %>%
group_by(outcome) %>%
summarise(across(
.cols = where(is.numeric), # todas las columnas numéricas del data frame
.fns = mean,
na.rm=T))## # A tibble: 3 × 12
## outcome generation age age_years lon lat wt_kg ht_cm ct_blood temp bmi days_onset_hosp
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Death 16.7 15.9 15.9 -13.2 8.47 52.6 125. 21.3 38.6 45.6 1.84
## 2 Recover 16.4 16.2 16.1 -13.2 8.47 52.5 125. 21.1 38.6 47.7 2.34
## 3 <NA> 16.5 16.3 16.2 -13.2 8.47 53.0 125. 21.2 38.6 48.3 2.07Pivote más ancho
Si prefieres tu tabla en formato “ancho” puedes transformarla utilizando la función pivot_wider() de tidyr. Es probable que tengas que renombrar las columnas con rename(). Para más información, consulta la página sobre Pivotar datos.
El ejemplo siguiente comienza con la tabla “larga” age_by_outcome de la sección de proporciones. La creamos de nuevo y la imprimimos, para mayor claridad:
age_by_outcome <- linelist %>% # comienza con linelist
group_by(outcome) %>% # agrupa por resultado
count(age_cat) %>% # agrupa y cuenta por age_cat, y luego elimina la agrupación age_cat
mutate(percent = scales::percent(n / sum(n))) # calcula el porcentaje - observa que el denominador es por grupo de resultadosPara pivotar más ampliamente, creamos las nuevas columnas a partir de los valores de la columna existente age_cat (estableciendo names_from = age_cat). También especificamos que los nuevos valores de la tabla provendrán de la columna existente n, con values_from = n. Las columnas no mencionadas en nuestro comando de pivoteo (outcome) permanecerán sin cambios en el extremo izquierdo.
age_by_outcome %>%
select(-percent) %>% # mantiene sólo los recuentos para simplificar
pivot_wider(names_from = age_cat, values_from = n) ## # A tibble: 3 × 10
## # Groups: outcome [3]
## outcome `0-4` `5-9` `10-14` `15-19` `20-29` `30-49` `50-69` `70+` `NA`
## <chr> <int> <int> <int> <int> <int> <int> <int> <int> <int>
## 1 Death 471 476 438 323 477 329 33 3 32
## 2 Recover 364 391 303 251 367 238 38 3 28
## 3 <NA> 260 228 200 169 229 187 24 NA 26Total de filas
Cuando summarise() opera con datos agrupados no produce automáticamente estadísticas “totales”. A continuación, se presentan dos enfoques para añadir una fila de totales:
adorn_totals() de janitor
Si tu tabla consiste sólo en recuentos o proporciones/porcentajes que pueden sumarse en un total, entonces puedes añadir totales de suma usando adorn_totals() de janitor como se describe en la sección anterior. Ten en cuenta que esta función sólo puede sumar las columnas numéricas - si deseas calcular otras estadísticas de resumen total, mira el siguiente enfoque con dplyr.
A continuación, linelist se agrupa por género y se resume en una tabla que describe el número de casos con resultado conocido, los fallecidos y los recuperados. Al pasar la tabla por adorn_totals() se añade una fila total en la parte inferior que refleja la suma de cada columna. Las funciones posteriores adorn_*() ajustan la visualización como se indica en el código.
linelist %>%
group_by(gender) %>%
summarise(
known_outcome = sum(!is.na(outcome)), # Número de filas del grupo en las que no falta el resultado
n_death = sum(outcome == "Death", na.rm=T), # Número de filas en el grupo donde el resultado es Death
n_recover = sum(outcome == "Recover", na.rm=T), # Número de filas del grupo en las que el resultado es Recovered
) %>%
adorn_totals() %>% # Adorna fila total (sumas de cada columna numérica)
adorn_percentages("col") %>% # Obtiene las proporciones de las columnas
adorn_pct_formatting() %>% # Convierte las proporciones a porcentajes
adorn_ns(position = "front") # Muestra % y recuentos (con los recuentos delante)## gender known_outcome n_death n_recover
## f 2180 (47.8%) 1227 (47.5%) 953 (48.1%)
## m 2178 (47.7%) 1228 (47.6%) 950 (47.9%)
## <NA> 207 (4.5%) 127 (4.9%) 80 (4.0%)
## Total 4565 (100.0%) 2582 (100.0%) 1983 (100.0%)
summarise() en los datos “totales” y luego bind_rows()
Si tu tabla consta de estadísticas de resumen como median(), mean(),, etc., el enfoque adorn_totals() mostrado anteriormente no será suficiente. En tu lugar, para obtener los estadísticos de resumen de todo el set de datos debe calcularlos con un comando summarise() separado y luego vincular los resultados a la tabla de resumen agrupada original. Para hacer el enlace puedes utilizar bind_rows() de dplyr descrito en la página de unión de datos. A continuación se muestra un ejemplo:
Se puede hacer una tabla resumen de resultados por hospital con group_by() y summarise() así:
by_hospital <- linelist %>%
filter(!is.na(outcome) & hospital != "Missing") %>% # Elimina los casos en los que falta el resultado o el hospital
group_by(hospital, outcome) %>% # Agrupa los datos
summarise( # Crea nuevas columnas de resumen de los indicadores de interés
N = n(), # Número de filas por grupo de hospital-resultado
ct_value = median(ct_blood, na.rm=T)) # Valor mediano de CT por grupo
by_hospital # print table## # A tibble: 10 × 4
## # Groups: hospital [5]
## hospital outcome N ct_value
## <chr> <chr> <int> <dbl>
## 1 Central Hospital Death 193 22
## 2 Central Hospital Recover 165 22
## 3 Military Hospital Death 399 21
## 4 Military Hospital Recover 309 22
## 5 Other Death 395 22
## 6 Other Recover 290 21
## 7 Port Hospital Death 785 22
## 8 Port Hospital Recover 579 21
## 9 St. Mark's Maternity Hospital (SMMH) Death 199 22
## 10 St. Mark's Maternity Hospital (SMMH) Recover 126 22Para obtener los totales, ejecuta el mismo comando summarise() pero agrupando los datos sólo por resultado (no por hospital), de la siguiente manera:
totals <- linelist %>%
filter(!is.na(outcome) & hospital != "Missing") %>%
group_by(outcome) %>% # Agrupado sólo por resultado, no por hospital
summarise(
N = n(), # Estas estadísticas son ahora sólo por resultado
ct_value = median(ct_blood, na.rm=T))
totals # imprimir tabla## # A tibble: 2 × 3
## outcome N ct_value
## <chr> <int> <dbl>
## 1 Death 1971 22
## 2 Recover 1469 22Podemos unir estos dos dataframes. Ten en cuenta que by_hospital tiene 4 columnas, mientras que totals tiene 3 columnas. Al utilizar bind_rows(), las columnas se combinan por nombre, y cualquier espacio extra se rellena con NA (por ejemplo, los valores de la columna hospital para las dos nuevas filas de totals). Después de enlazar las filas, convertimos estos espacios vacíos en “Total” utilizando replace_na() (véase la página de limpieza de datos y funciones básicas).
table_long <- bind_rows(by_hospital, totals) %>%
mutate(hospital = replace_na(hospital, "Total"))Aquí está la nueva tabla con las filas “Total” en la parte inferior.
Esta tabla tiene un formato “largo”, que puede ser lo que quieres. Opcionalmente, puedes pivotar esta tabla más ampliamente para hacerla más legible. Mira la sección sobre pivoteo más amplio arriba, y la página Pivotar datos. También puedes añadir más columnas, y organizarla de forma agradable. Este código está abajo.
table_long %>%
# Pivotar más ancho y formato
#############################
mutate(hospital = replace_na(hospital, "Total")) %>%
pivot_wider( # Pivota de largo a ancho
values_from = c(ct_value, N), # los nuevos valores proceden de las columnas ct y count
names_from = outcome) %>% # los nuevos nombres de columna proceden de outcomes
mutate( # Añade nuevas columnas
N_Known = N_Death + N_Recover, # número con resultado conocido
Pct_Death = scales::percent(N_Death / N_Known, 0.1), # porcentaje de casos que murieron (a 1 decimal)
Pct_Recover = scales::percent(N_Recover / N_Known, 0.1)) %>% # porcentaje de casos que se recuperaron (a 1 decimal)
select( # Reordena las columnas
hospital, N_Known, # columnas iniciales
N_Recover, Pct_Recover, ct_value_Recover, # columnas de recuperados
N_Death, Pct_Death, ct_value_Death) %>% # columnas de fallecidos
arrange(N_Known) # Ordenar las filas de menor a mayor (fila Total en la parte inferior)## # A tibble: 6 × 8
## # Groups: hospital [6]
## hospital N_Known N_Recover Pct_Recover ct_value_Recover N_Death Pct_Death ct_value_Death
## <chr> <int> <int> <chr> <dbl> <int> <chr> <dbl>
## 1 St. Mark's Maternity Hospital (SMMH) 325 126 38.8% 22 199 61.2% 22
## 2 Central Hospital 358 165 46.1% 22 193 53.9% 22
## 3 Other 685 290 42.3% 21 395 57.7% 22
## 4 Military Hospital 708 309 43.6% 22 399 56.4% 21
## 5 Port Hospital 1364 579 42.4% 21 785 57.6% 22
## 6 Total 3440 1469 42.7% 22 1971 57.3% 22Y luego puedes imprimir esto muy bien como una imagen - abajo está la salida impresa con flextable. Puedes leer más en profundidad sobre este ejemplo y cómo lograr esta tabla “bonita” en la página Tablas para presentaciones.
Hospital |
Total cases with known outcome |
Recovered |
Died |
||||
|---|---|---|---|---|---|---|---|
Total |
% of cases |
Median CT values |
Total |
% of cases |
Median CT values |
||
St. Mark's Maternity Hospital (SMMH) |
325 |
126 |
38.8% |
22 |
199 |
61.2% |
22 |
Central Hospital |
358 |
165 |
46.1% |
22 |
193 |
53.9% |
22 |
Other |
685 |
290 |
42.3% |
21 |
395 |
57.7% |
22 |
Military Hospital |
708 |
309 |
43.6% |
22 |
399 |
56.4% |
21 |
Missing |
1,125 |
514 |
45.7% |
21 |
611 |
54.3% |
21 |
Port Hospital |
1,364 |
579 |
42.4% |
21 |
785 |
57.6% |
22 |
Total |
3,440 |
1,469 |
42.7% |
22 |
1,971 |
57.3% |
22 |
17.5 Paquete gtsummary
Si deseas imprimir tus estadísticas de resumen en un gráfico bonito y listo para tu publicación, puedes utilizar el paquete gtsummary y tu función tbl_summary(). El código puede parecer complejo al principio, pero los resultados se ven muy bien y se imprimen en tu panel de RStudio Viewer como una imagen HTML. Lea esta viñeta.
También puedes añadir los resultados de las pruebas estadísticas a las tablas de gtsummary. Este proceso se describe en la sección gtsummary de la página Tests estadísticos simples.
Para introducir tbl_summary() mostraremos primero el comportamiento más básico, que realmente produce una tabla grande y bonita. Luego, examinaremos en detalle cómo hacer ajustes y tablas más a medida.
Tabla resumen
El comportamiento por defecto de tbl_summary() es bastante increíble: toma las columnas que proporcionas y crea una tabla de resumen en un solo comando. La función imprime las estadísticas apropiadas para el tipo de columna: mediana y rango intercuartil (IQR) para las columnas numéricas, y recuentos (%) para las columnas categóricas. Los valores faltantes se convierten en “Missing”. Se añaden notas a pie de página para explicar las estadísticas, mientras que el N total se muestra en la parte superior.
linelist %>%
select(age_years, gender, outcome, fever, temp, hospital) %>% # mantiene sólo las columnas de interés
tbl_summary() # por defecto| Characteristic | N = 5,8881 |
|---|---|
| age_years | 13 (6, 23) |
| Unknown | 86 |
| gender | |
| f | 2,807 (50%) |
| m | 2,803 (50%) |
| Unknown | 278 |
| outcome | |
| Death | 2,582 (57%) |
| Recover | 1,983 (43%) |
| Unknown | 1,323 |
| fever | 4,549 (81%) |
| Unknown | 249 |
| temp | 38.80 (38.20, 39.20) |
| Unknown | 149 |
| hospital | |
| Central Hospital | 454 (7.7%) |
| Military Hospital | 896 (15%) |
| Missing | 1,469 (25%) |
| Other | 885 (15%) |
| Port Hospital | 1,762 (30%) |
| St. Mark's Maternity Hospital (SMMH) | 422 (7.2%) |
| 1 Median (IQR); n (%) | |
Ajustes
Ahora explicaremos cómo trabaja la función y cómo hacer los ajustes. Los argumentos clave se detallan a continuación:
by =
Puedes estratificar tu tabla por una columna (por ejemplo, por resultado), creando una tabla de dos vías.
statistic =
Usa una ecuación para especificar qué estadísticas mostrar y cómo mostrarlas. La ecuación tiene dos lados, separados por una tilde ~. En el lado derecho, entre comillas, está la visualización estadística deseada, y en el izquierdo están las columnas a las que se aplicará esa visualización.
- El lado derecho de la ecuación utiliza la sintaxis de
str_glue()de stringr (véase Caracteres y cadenas), con la cadena de visualización deseada entre comillas y los propios estadísticos entre llaves. Puedes incluir estadísticas como “n” (para los recuentos), “N” (para el denominador), “mean”, “median”, “sd”, “max”, “min”, percentiles como “p##” como “p25”, o porcentaje del total como “p”. Consulta?tbl_summarypara obtener más detalles. - Para el lado izquierdo de la ecuación, puedes especificar las columnas por su nombre (por ejemplo,
ageoc(age, gender)) o utilizando ayudantes comoall_continuous(),all_categorical(),contains(),starts_with(), etc.
Un ejemplo sencillo de una ecuación statistic = podría ser como el siguiente, para imprimir sólo la media de la columna age_years:
linelist %>%
select(age_years) %>% # mantiene sólo las columnas de interés
tbl_summary( # crea tabla resumen
statistic = age_years ~ "{mean}") # imprime la media de edad| Characteristic | N = 5,8881 |
|---|---|
| age_years | 16 |
| Unknown | 86 |
| 1 Mean | |
Una ecuación un poco más compleja podría tener el aspecto de "({min}, {max})", incorporando los valores máximo y mínimo entre paréntesis y separados por una coma:
linelist %>%
select(age_years) %>% # conserva sólo las columnas de interés
tbl_summary( # crea tabla resumen
statistic = age_years ~ "({min}, {max})") # imprime min y max de edad| Characteristic | N = 5,8881 |
|---|---|
| age_years | (0, 84) |
| Unknown | 86 |
| 1 (Range) | |
También puedes diferenciar la sintaxis para columnas separadas o tipos de columnas. En el ejemplo más complejo de abajo, el valor proporcionado a statistc = es una lista que indica que para todas las columnas continuas la tabla debe imprimir la media con la desviación estándar entre paréntesis, mientras que para todas las columnas categóricas debe imprimir el n, el denominador y el porcentaje.
digits =
Ajusta los dígitos y el redondeo. Opcionalmente, se puede especificar que sea sólo para columnas continuas (como a continuación).
label =
Ajustar cómo debe mostrarse el nombre de la columna. Proporciona el nombre de la columna y la etiqueta deseada separados por una tilde. El valor por defecto es el nombre de la columna.
missing_text =
Ajustar cómo se muestran los valores faltantes. El valor por defecto es “Unknown”.
type =
Se utiliza para ajustar cuántos niveles de la estadística se muestran. La sintaxis es similar a statistic = en el sentido de que se proporciona una ecuación con columnas a la izquierda y un valor a la derecha. Dos escenarios comunes incluyen:
type = all_categorical() ~ "categorical"Fuerza a las columnas dicotómicas (por ejemplo,feversí/no) a mostrar todos los niveles en lugar de sólo la fila “sí”type = all_continuous() ~ "continuous2"Permite estadísticas de varias líneas por variable, como se muestra en una sección posterior
En el siguiente ejemplo, cada uno de estos argumentos se utiliza para modificar la tabla resumen original:
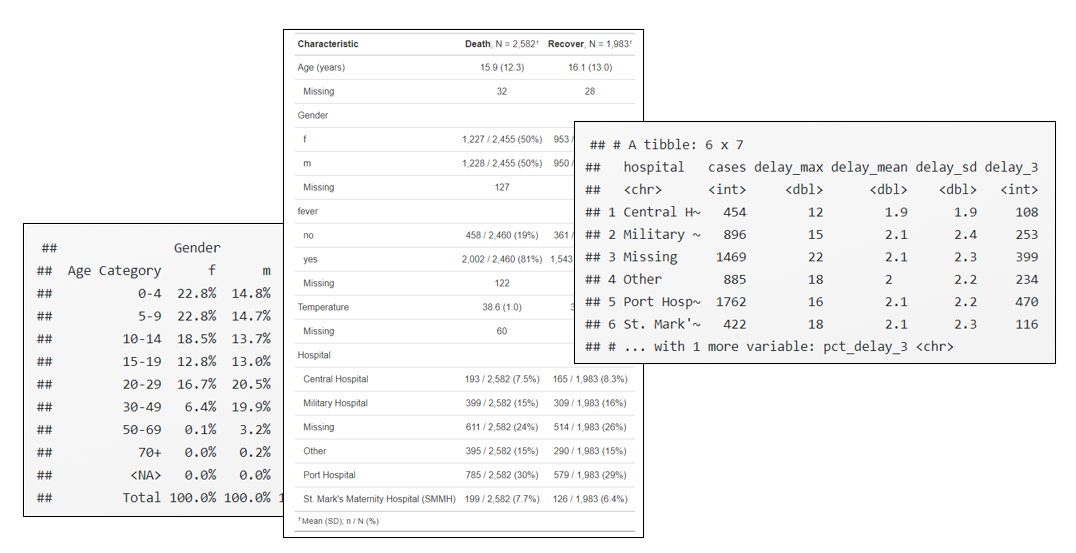
linelist %>%
select(age_years, gender, outcome, fever, temp, hospital) %>% # conserva sólo las columnas de interés
tbl_summary(
by = outcome, # estratifica toda la tabla por resultado
statistic = list(all_continuous() ~ "{mean} ({sd})", # estadísticas y formato de las columnas continuas
all_categorical() ~ "{n} / {N} ({p}%)"), # estadísticas y formato para columnas categóricas
digits = all_continuous() ~ 1, # redondeo para columnas continuas
type = all_categorical() ~ "categorical", # fuerza la visualización de todos los niveles categóricos
label = list( # muestra las etiquetas de las columnas
outcome ~ "Outcome",
age_years ~ "Age (years)",
gender ~ "Gender",
temp ~ "Temperature",
hospital ~ "Hospital"),
missing_text = "Missing" # cómo deben mostrarse los valores perdidos
)## 1323 observations missing `outcome` have been removed. To include these observations, use `forcats::fct_explicit_na()` on `outcome` column before passing to `tbl_summary()`.| Characteristic | Death, N = 2,5821 | Recover, N = 1,9831 |
|---|---|---|
| Age (years) | 15.9 (12.3) | 16.1 (13.0) |
| Missing | 32 | 28 |
| Gender | ||
| f | 1,227 / 2,455 (50%) | 953 / 1,903 (50%) |
| m | 1,228 / 2,455 (50%) | 950 / 1,903 (50%) |
| Missing | 127 | 80 |
| fever | ||
| no | 458 / 2,460 (19%) | 361 / 1,904 (19%) |
| yes | 2,002 / 2,460 (81%) | 1,543 / 1,904 (81%) |
| Missing | 122 | 79 |
| Temperature | 38.6 (1.0) | 38.6 (1.0) |
| Missing | 60 | 55 |
| Hospital | ||
| Central Hospital | 193 / 2,582 (7.5%) | 165 / 1,983 (8.3%) |
| Military Hospital | 399 / 2,582 (15%) | 309 / 1,983 (16%) |
| Missing | 611 / 2,582 (24%) | 514 / 1,983 (26%) |
| Other | 395 / 2,582 (15%) | 290 / 1,983 (15%) |
| Port Hospital | 785 / 2,582 (30%) | 579 / 1,983 (29%) |
| St. Mark's Maternity Hospital (SMMH) | 199 / 2,582 (7.7%) | 126 / 1,983 (6.4%) |
| 1 Mean (SD); n / N (%) | ||
Estadísticas de varias líneas para variables continuas
Si deseas imprimir varias líneas de estadísticas para variables continuas, puedes indicarlo estableciendo type = a “continuous2”. Puedes combinar todos los elementos mostrados anteriormente en una tabla eligiendo qué estadísticas quiere mostrar. Para ello, debes indicar a la función que deseas obtener una tabla escribiendo el tipo como “continuous2”. El número de valores faltantes se muestra como “Desconocido”.
linelist %>%
select(age_years, temp) %>% # conserva sólo las columnas de interés
tbl_summary( # crea tabla resumen
type = all_continuous() ~ "continuous2", # indica que quieres imprimir múltiples estadísticas
statistic = all_continuous() ~ c(
"{mean} ({sd})", # línea 1: media y DE
"{median} ({p25}, {p75})", # línea 2: mediana y RIQ
"{min}, {max}") # línea 3: mín. y máx.
)| Characteristic | N = 5,888 |
|---|---|
| age_years | |
| Mean (SD) | 16 (13) |
| Median (IQR) | 13 (6, 23) |
| Range | 0, 84 |
| Unknown | 86 |
| temp | |
| Mean (SD) | 38.56 (0.98) |
| Median (IQR) | 38.80 (38.20, 39.20) |
| Range | 35.20, 40.80 |
| Unknown | 149 |
Hay muchas otras formas de modificar estas tablas, incluyendo la adición de valores p, el ajuste del color y los títulos, etc. Muchas de ellas se describen en la documentación (escribe ?tbl_summary en la Consola), y algunas se dan en la sección de Tests estadísticos sencillos.
17.6 R base
Puedes utilizar la función table() para tabular y cruzar las columnas. A diferencia de las opciones anteriores, debes especificar el dataframe cada vez que haga referencia a un nombre de columna, como se muestra a continuación.
ATENCIÓN: Los valores NA (missing) no se tabularán a menos que se incluya el argumento useNA = "always" (que también podría establecerse como “no” o “ifany”). .
CONSEJO: Puedes utilizar el %$% de magrittr para eliminar la necesidad de repetir las llamadas al dataframe dentro de las funciones de R base. Por ejemplo, lo siguiente podría escribirse linelist %$% table(outcome, useNA = "always")
table(linelist$outcome, useNA = "always")##
## Death Recover <NA>
## 2582 1983 1323Se pueden cruzar varias columnas enumerándolas una tras otra, separadas por comas. Opcionalmente, se puede asignar a cada columna un “nombre” como Outcome = linelist$outcome.
age_by_outcome <- table(linelist$age_cat, linelist$outcome, useNA = "always") # guarda la tabla como objeto
age_by_outcome # imprime la tabla##
## Death Recover <NA>
## 0-4 471 364 260
## 5-9 476 391 228
## 10-14 438 303 200
## 15-19 323 251 169
## 20-29 477 367 229
## 30-49 329 238 187
## 50-69 33 38 24
## 70+ 3 3 0
## <NA> 32 28 26Proporciones
Para producir las proporciones, pasa la tabla anterior a la función prop.table(). Utiliza el argumento margins = para especificar si deseas que las proporciones sean de filas (1), de columnas (2) o de toda la tabla (3). Para mayor claridad, eniazamos la tabla con pipe a la función round() de R base, especificando 2 dígitos.
# obtiene las proporciones de la tabla definida anteriormente, por filas, redondeadas
prop.table(age_by_outcome, 1) %>% round(2)##
## Death Recover <NA>
## 0-4 0.43 0.33 0.24
## 5-9 0.43 0.36 0.21
## 10-14 0.47 0.32 0.21
## 15-19 0.43 0.34 0.23
## 20-29 0.44 0.34 0.21
## 30-49 0.44 0.32 0.25
## 50-69 0.35 0.40 0.25
## 70+ 0.50 0.50 0.00
## <NA> 0.37 0.33 0.30Totales
Para añadir los totales de filas y columnas, pasa la tabla a addmargins(). Esto funciona tanto para recuentos como para proporciones.
addmargins(age_by_outcome)##
## Death Recover <NA> Sum
## 0-4 471 364 260 1095
## 5-9 476 391 228 1095
## 10-14 438 303 200 941
## 15-19 323 251 169 743
## 20-29 477 367 229 1073
## 30-49 329 238 187 754
## 50-69 33 38 24 95
## 70+ 3 3 0 6
## <NA> 32 28 26 86
## Sum 2582 1983 1323 5888Convertir en dataframe
Convertir un objeto table() directamente en un dataframe no es sencillo. A continuación se muestra un enfoque:
- Crea la tabla, sin utilizar
useNA = "always". En su lugar, convierte los valoresNAen “(Missing)” confct_explicit_na()de forcats. - Añade los totales (opcional) pasando por
addmargins() - Pipe a la función R base
as.data.frame.matrix() - Enviar la tabla a la función
rownames_to_column()de tibble, especificando el nombre de la primera columna - Imprime, visualiza o exporta según desees. En este ejemplo utilizamos
flextable()del paquete flextable como se describe en la página Tablas para presentaciones. Esto imprimirá en el panel de visualización de RStudio como una bonita imagen HTML.
table(fct_explicit_na(linelist$age_cat), fct_explicit_na(linelist$outcome)) %>%
addmargins() %>%
as.data.frame.matrix() %>%
tibble::rownames_to_column(var = "Age Category") %>%
flextable::flextable()Age Category |
Death |
Recover |
(Missing) |
Sum |
|---|---|---|---|---|
0-4 |
471 |
364 |
260 |
1,095 |
5-9 |
476 |
391 |
228 |
1,095 |
10-14 |
438 |
303 |
200 |
941 |
15-19 |
323 |
251 |
169 |
743 |
20-29 |
477 |
367 |
229 |
1,073 |
30-49 |
329 |
238 |
187 |
754 |
50-69 |
33 |
38 |
24 |
95 |
70+ |
3 |
3 |
0 |
6 |
(Missing) |
32 |
28 |
26 |
86 |
Sum |
2,582 |
1,983 |
1,323 |
5,888 |