25 Rastreo de contactos
Esta página muestra el análisis descriptivo de los datos de rastreo de contactos, abordando algunas consideraciones clave y enfoques exclusivos de este tipo de datos.
Esta página hace referencia a muchas de las competencias básicas de gestión y visualización de datos de R tratadas en otras páginas (por ejemplo, limpieza de datos, pivoteo, tablas, análisis de series temporales), pero destacaremos ejemplos específicos del rastreo de contactos que han sido útiles para la toma de decisiones operativas. Por ejemplo, esto incluye la visualización de los datos de seguimiento del rastreo de contactos a lo largo del tiempo o a través de áreas geográficas, o la producción de tablas limpias de Indicadores Clave de Rendimiento (KPI) para los supervisores del rastreo de contactos.
Para la demostración utilizaremos datos de rastreo de contactos de la plataforma Go.Data. Los principios que aquí se exponen son válidos para los datos de rastreo de contactos de otras plataformas, sólo que puede ser necesario realizar diferentes pasos de preprocesamiento de datos en función de la estructura de los mismos.
Puedes leer más sobre el proyecto Go.Data en el sitio de documentación de Github o en su Comunidad de Prácticas.
25.1 Preparation
Cargar paquetes
Este trozo de código muestra la carga de los paquetes necesarios para los análisis. En este manual destacamos p_load() de pacman, que instala el paquete si es necesario y lo carga para su uso. También puedes cargar los paquetes instalados con library() de R base. Consulta la página sobre fundamentos de R para obtener más información sobre los paquetes de R.
pacman::p_load(
rio, # importación de datos
here, # rutas relativas de archivos
janitor, # limpieza de datos y tablas
lubridate, # trabajar con fechas
epikit, # función age_categories()
apyramid, # pirámides de edad
tidyverse, # manipulación y visualización de datos
RColorBrewer, # paletas de colores
formattable, # tablas de fantasía
kableExtra # formateo de tablas
)Importar datos
Importaremos conjuntos de datos de muestra de contactos y de su “seguimiento”. Estos datos se han recuperado y desanidado de la API Go.Data y se han almacenado como archivos “.rds”.
Puedes descargar todos los datos de ejemplo de este manual en la página de descarga de manuales y datos.
Si deseas descargar los datos de seguimiento de contactos de ejemplo específicos de esta página, utiliza los tres enlaces de descarga que aparecen a continuación:
Clica para descargar los datos de casos de la investigación (archivo .rds)
Clica para descargar los datos del registro de contactos (archivo .rds)
Clica para descargar los datos de seguimiento de los contactos (archivo .rds)
En su formato original los archivos descargables, reflejan los datos proporcionados por la API de Go.Data (puedes aprender sobre las API aquí). A modo de ejemplo, aquí limpiaremos los datos para que sean más fáciles de leer en esta página. Si estás utilizando una instancia de Go.Data, puedes ver las instrucciones completas sobre cómo recuperar sus datos aquí.
A continuación, los conjuntos de datos se importan utilizando la función import() del paquete rio. Consulta la página sobre importación y exportación para conocer las distintas formas de importar datos. Utilizamos here() para especificar la ruta del archivo - debes escribir la ruta del archivo específica de tu ordenador. A continuación, utilizamos select() para seleccionar sólo ciertas columnas de los datos, para simplificar la demostración.
Datos de casos
Estos datos son una tabla de los casos, y la información sobre ellos.
cases <- import(here("data", "godata", "cases_clean.rds")) %>%
select(case_id, firstName, lastName, gender, age, age_class,
occupation, classification, was_contact, hospitalization_typeid)Aquí están los casos nrow(cases):
Datos de contactos
Estos datos son una tabla de todos los contactos e información sobre ellos. De nuevo, proporciona tu propia ruta de acceso al archivo. Después de la importación, realizamos algunos pasos preliminares de limpieza de datos que incluyen:
- Establecer age_class como factor e invertir el orden de los niveles para que las edades más jóvenes sean las primeras
- Seleccionar sólo una columna determinada, renombrando una de ellas
- Asignar artificialmente a “Djembe” las filas a las que les falta el nivel 2 de administración, para mejorar la claridad de algunas visualizaciones de ejemplo
contacts <- import(here("data", "godata", "contacts_clean.rds")) %>%
mutate(age_class = forcats::fct_rev(age_class)) %>%
select(contact_id, contact_status, firstName, lastName, gender, age,
age_class, occupation, date_of_reporting, date_of_data_entry,
date_of_last_exposure = date_of_last_contact,
date_of_followup_start, date_of_followup_end, risk_level, was_case, admin_2_name) %>%
mutate(admin_2_name = replace_na(admin_2_name, "Djembe"))Aquí están las filas de los datos de contactos (nrow(contacts)):
Datos de seguimiento
Estos datos son registros de las interacciones de “seguimiento” con los contactos. Se supone que cada contacto tiene un encuentro diario durante los 14 días siguientes a su exposición.
Importamos y realizamos algunos pasos de limpieza. Seleccionamos ciertas columnas y también convertimos una columna de caracteres a todos los valores en minúsculas.
followups <- rio::import(here::here("data", "godata", "followups_clean.rds")) %>%
select(contact_id, followup_status, followup_number,
date_of_followup, admin_2_name, admin_1_name) %>%
mutate(followup_status = str_to_lower(followup_status))Aquí están las primeras 50 filas de followups (cada fila es una interacción de seguimiento, con el estado del resultado en la columna followup_status):
Datos de las relaciones
Aquí importamos datos que muestran la relación entre casos y contactos. Seleccionamos cierta columna para mostrarlos.
relationships <- rio::import(here::here("data", "godata", "relationships_clean.rds")) %>%
select(source_visualid, source_gender, source_age, date_of_last_contact,
date_of_data_entry, target_visualid, target_gender,
target_age, exposure_type)A continuación se muestran las primeras 50 filas de los datos de relaciones (relationships), cuyos registros son todas las relaciones entre casos y contactos.
25.2 Análisis descriptivo
Puedes utilizar las técnicas tratadas en otras páginas de este manual para realizar análisis descriptivos de los casos, contactos y sus relaciones. A continuación se ofrecen algunos ejemplos.
Datos demográficos
Como se muestra en la página dedicada a las pirámides demográficas, se puede visualizar la distribución por edades y por sexos (aquí utilizamos el paquete apyramid).
Edad y sexo de los contactos
La pirámide que se muestra a continuación compara la distribución de la edad de los contactos, por género. Observa que los contactos a los que les falta la edad se incluyen en su propia barra en la parte superior. Puedes cambiar este comportamiento por defecto, pero entonces considera listar el número que falta en una leyenda.
apyramid::age_pyramid(
data = contacts, # utilizar los datos de contactos
age_group = "age_class", # columna de edad categórica
split_by = "gender") + # género para las mitades de la pirámide
labs(
fill = "Gender", # título de la leyenda
title = "Age/Sex Pyramid of COVID-19 contacts")+ # título del gráfico
theme_minimal() # fondo simple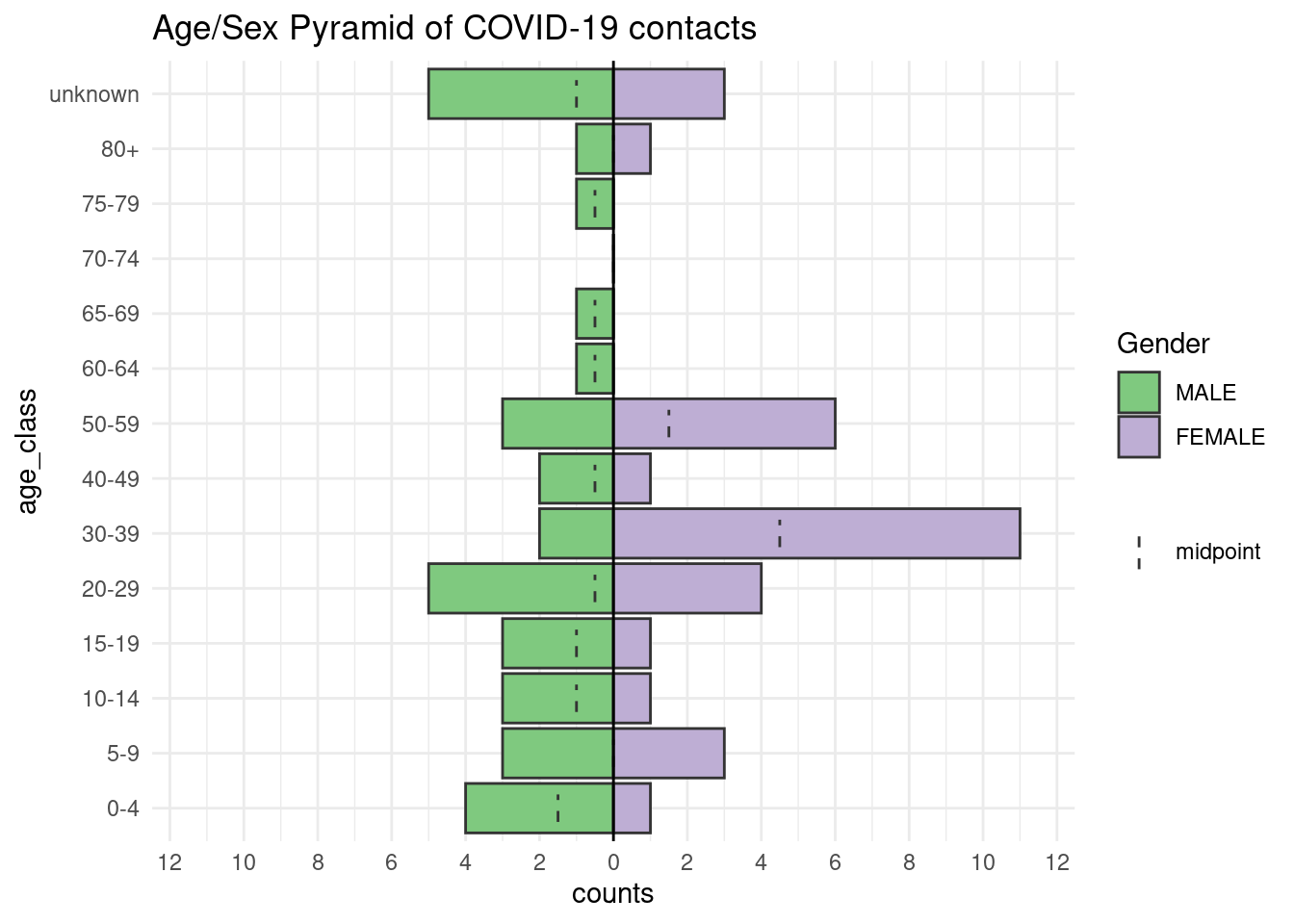
Con la estructura de datos Go.Data, los datos relationships contienen las edades tanto de los casos como de los contactos, por lo que podrías utilizar ese conjunto de datos y crear una pirámide de edades que muestre las diferencias entre estos dos grupos de personas. El dataframe relationships será mutado para transformar las columnas numéricas de edad en categorías (véase la página de limpieza de datos y funciones básicas). También pivotamos el dataframe a largo para facilitar el trazado con ggplot2 (ver Pivotar datos).
relation_age <- relationships %>%
select(source_age, target_age) %>%
transmute( # transmute es como mutate() pero elimina todas las demás columnas no mencionadas
source_age_class = epikit::age_categories(source_age, breakers = seq(0, 80, 5)),
target_age_class = epikit::age_categories(target_age, breakers = seq(0, 80, 5)),
) %>%
pivot_longer(cols = contains("class"), names_to = "category", values_to = "age_class") # pivotar largo
relation_age## # A tibble: 200 × 2
## category age_class
## <chr> <fct>
## 1 source_age_class 80+
## 2 target_age_class 15-19
## 3 source_age_class <NA>
## 4 target_age_class 50-54
## 5 source_age_class <NA>
## 6 target_age_class 20-24
## 7 source_age_class 30-34
## 8 target_age_class 45-49
## 9 source_age_class 40-44
## 10 target_age_class 30-34
## # … with 190 more rowsAhora podemos representar este conjunto de datos transformado con age_pyramid() como antes, pero sustituyendo gender con la category (contacto, o caso).
apyramid::age_pyramid(
data = relation_age, # utilizar los datos de relación modificados
age_group = "age_class", # columna de edad categórica
split_by = "category") + # por casos y contactos
scale_fill_manual(
values = c("orange", "purple"), # para especificar colores Y etiquetas
labels = c("Case", "Contact"))+
labs(
fill = "Legend", # título de la leyenda
title = "Age/Sex Pyramid of COVID-19 contacts and cases")+ # título del gráfico
theme_minimal() # fondo simple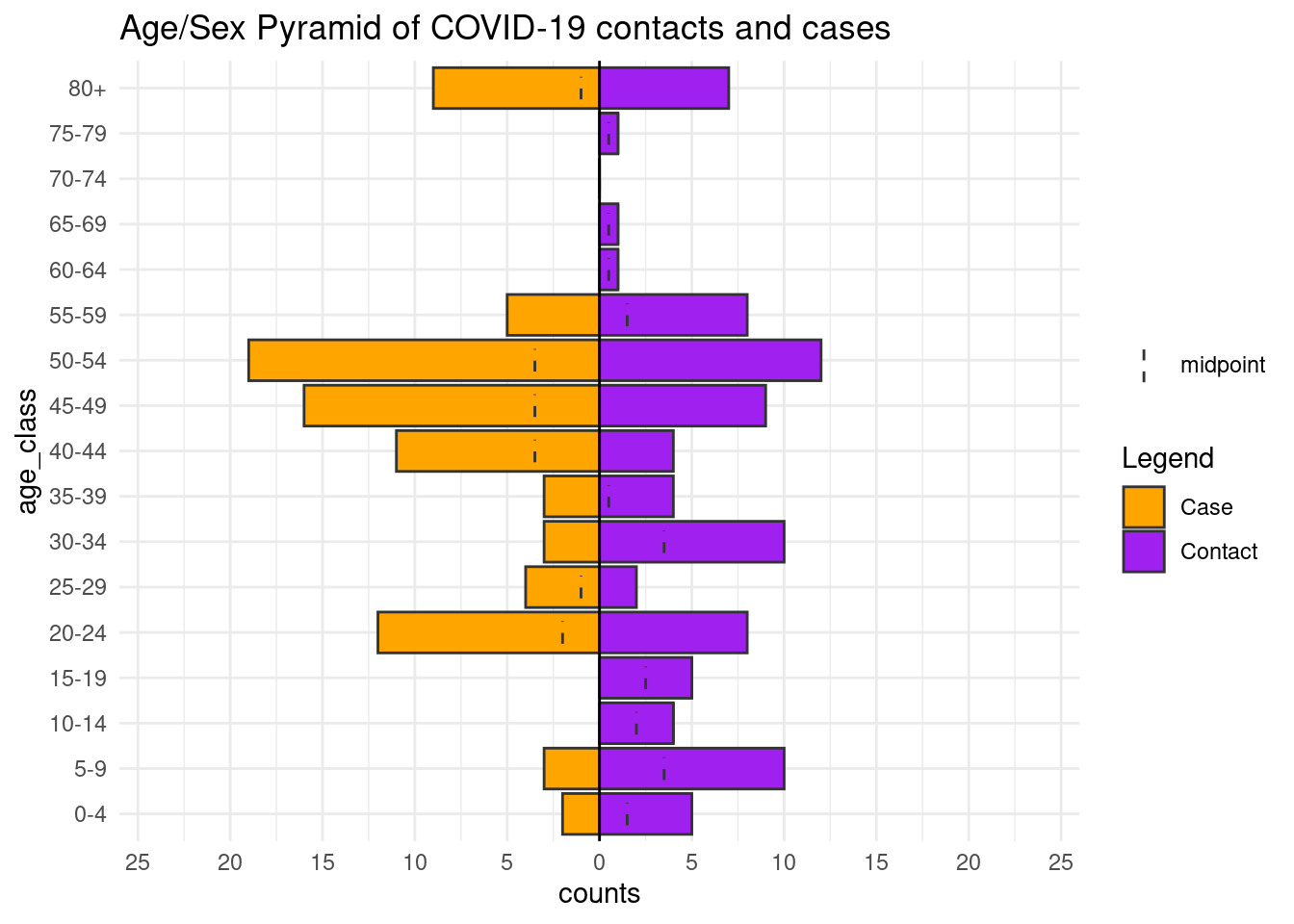
También podemos ver otras características como el desglose profesional (por ejemplo, en forma de gráfico circular).
# Limpiar los datos y obtener los recuentos por ocupación
occ_plot_data <- cases %>%
mutate(occupation = forcats::fct_explicit_na(occupation), # convertir en categoría los valores faltantes NA
occupation = forcats::fct_infreq(occupation)) %>% # ordenar los niveles de los factores por orden de frecuencia
count(occupation) # obtener los recuentos por ocupación
# Hacer un gráfico de tarta
ggplot(data = occ_plot_data, mapping = aes(x = "", y = n, fill = occupation))+
geom_bar(width = 1, stat = "identity") +
coord_polar("y", start = 0) +
labs(
fill = "Occupation",
title = "Known occupations of COVID-19 cases")+
theme_minimal() +
theme(axis.line = element_blank(),
axis.title = element_blank(),
axis.text = element_blank())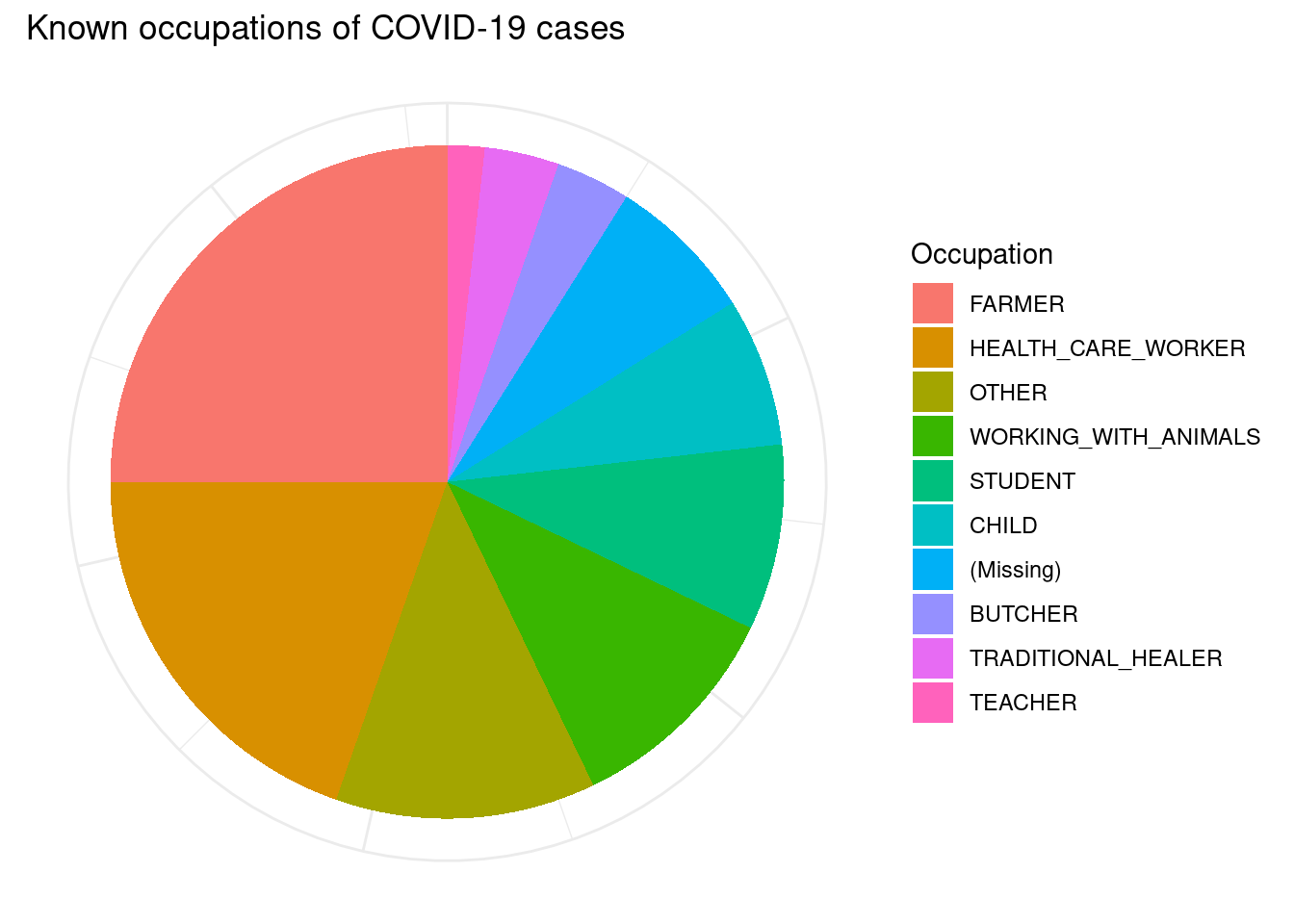
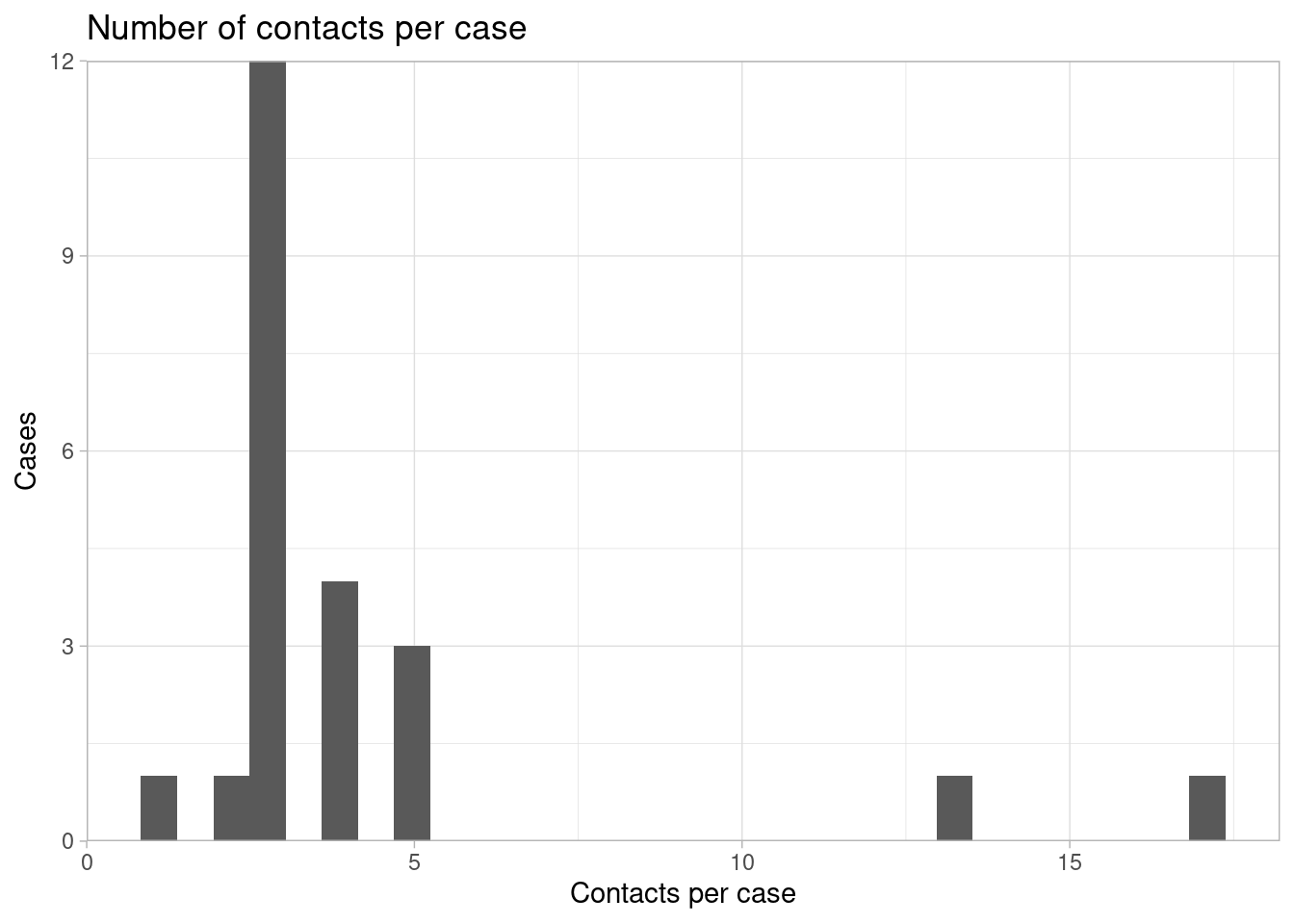
Contactos por caso
El número de contactos por caso puede ser una métrica importante para evaluar la calidad de la enumeración de los contactos y la conformidad de la población con la respuesta de salud pública.
Dependiendo de la estructura de datos, esto puede evaluarse con un juego de datos que contenga todos los casos y contactos. En el conjunto de datos de Go.Data, los vínculos entre los casos (“fuentes”) y los contactos (“objetivos”) se almacenan en relationships.
En este conjunto de datos, cada fila es un contacto, y el caso de origen aparece en la fila. No hay contactos que tengan relaciones con múltiples casos, pero si esto existiese, puede ser necesario tenerlos en cuenta antes de representarlo (¡y explorarlos también!).
Comenzamos contando el número de filas (contactos) por caso de origen. Esto se guarda como un dataframe.
## # A tibble: 23 × 2
## source_visualid n
## <chr> <int>
## 1 CASE-2020-0001 13
## 2 CASE-2020-0002 5
## 3 CASE-2020-0003 2
## 4 CASE-2020-0004 4
## 5 CASE-2020-0005 5
## 6 CASE-2020-0006 3
## 7 CASE-2020-0008 3
## 8 CASE-2020-0009 3
## 9 CASE-2020-0010 3
## 10 CASE-2020-0012 3
## # … with 13 more rowsUtilizamos geom_histogram() para trazar estos datos como un histograma.
ggplot(data = contacts_per_case)+ # comenzar con el dataframe de recuento creado anteriormente
geom_histogram(mapping = aes(x = n))+ # imprimir histograma del número de contactos por caso
scale_y_continuous(expand = c(0,0))+ # eliminar el exceso de espacio por debajo de 0 en el eje y
theme_light()+ # simplificar el fondo
labs(
title = "Number of contacts per case",
y = "Cases",
x = "Contacts per case"
)
25.3 Seguimiento de contactos
Los datos de rastreo de contactos suelen contener datos de “seguimiento”, que registran los resultados de los controles diarios de los síntomas de las personas en cuarentena. El análisis de estos datos puede servir de base para la estrategia de respuesta e identificar a los contactos con riesgo de pérdida de seguimiento o con riesgo de desarrollar la enfermedad.
Limpieza de datos
Estos datos pueden existir en una variedad de formatos. Pueden existir como una hoja de Excel de formato “ancho” con una fila por contacto y una columna por “día” de seguimiento. Consulta Pivotar datos para ver las descripciones de los datos “largos” y “anchos” y cómo pivotar los datos anchos o largos.
En nuestro ejemplo de Go.Data, estos datos se almacenan en el dataframe followups, que tiene un formato “largo” con una fila por interacción de seguimiento. Las primeras 50 filas tienen este aspecto:
PRECAUCIÓN: Ten cuidado con los duplicados al tratar los datos de seguimiento, ya que podría haber varios seguimientos erróneos en el mismo día para un contacto determinado. Tal vez parezca un error, pero refleja la realidad: por ejemplo, un rastreador de contactos podría enviar un formulario de seguimiento a primera hora del día cuando no pudo contactar con el contacto, y enviar un segundo formulario cuando se le pudo contactar más tarde. Dependerá del contexto operativo la forma en que desees gestionar los duplicados, pero asegúrate de documentar claramente tu enfoque.
Veamos cuántos casos de filas “duplicadas” tenemos:
followups %>%
count(contact_id, date_of_followup) %>% # obtiene contact_days únicos
filter(n > 1) # ver los registros en los que el recuento es superior a 1 ## # A tibble: 3 × 3
## contact_id date_of_followup n
## <chr> <date> <int>
## 1 <NA> 2020-09-03 2
## 2 <NA> 2020-09-04 2
## 3 <NA> 2020-09-05 2En nuestros datos de ejemplo, los únicos registros a los que se aplica esto son los que carecen de ID. Podemos eliminarlos. Pero, a efectos de demostración, mostraremos los pasos para la eliminación de la duplicación de modo que sólo haya un registro de seguimiento por persona y por día. Para más detalles, consulta la página de De-duplicación. Asumiremos que el registro de encuentro más reciente es el correcto. También aprovechamos la oportunidad para limpiar la columna followup_number (el “día” de seguimiento que debe ir de 1 a 14).
followups_clean <- followups %>%
# De-duplicar
group_by(contact_id, date_of_followup) %>% # agrupa filas por día de contacto
arrange(contact_id, desc(date_of_followup)) %>% # ordena filas, por contacto-día, por fecha de seguimiento (la más reciente arriba)
slice_head() %>% # mantiene sólo la primera fila por identificador único de contacto
ungroup() %>%
# Otras limpiezas
mutate(followup_number = replace(followup_number, followup_number > 14, NA)) %>% # limpia datos erróneos
drop_na(contact_id) # elimina las filas en las que falta contact_idPara cada encuentro de seguimiento, tenemos un estado de seguimiento (como si el encuentro se produjo y, si es así, el contacto tuvo síntomas o no). Para ver todos los valores podemos ejecutar un tabyl() rápido (de janitor) o table() (de R base) (ver Tablas descriptivas) por followup_status para ver la frecuencia de cada uno de los resultados.
En este conjunto de datos, “seen_not_ok” significa “visto con síntomas”, y “seen_ok” significa “visto sin síntomas”.
followups_clean %>%
tabyl(followup_status)## followup_status n percent
## missed 10 0.02325581
## not_attempted 5 0.01162791
## not_performed 319 0.74186047
## seen_not_ok 6 0.01395349
## seen_ok 90 0.20930233Gráfica en el tiempo
Como los datos de las fechas son continuos, utilizaremos un histograma para representarlos con date_of_followup asignado al eje-x. Podemos conseguir un histograma “apilado” especificando un argumento fill = dentro de aes(), que asignamos a la columna followup_status. En consecuencia, se puede establecer el título de la leyenda utilizando el argumento fill = de labs().
Podemos ver que los contactos se identificaron en oleadas (presumiblemente correspondientes a las oleadas epidémicas de casos), y que la finalización del seguimiento no parece haber mejorado a lo largo de la epidemia.
ggplot(data = followups_clean)+
geom_histogram(mapping = aes(x = date_of_followup, fill = followup_status)) +
scale_fill_discrete(drop = FALSE)+ # muestra todos los niveles del factor (followup_status) en la leyenda, incluso los no utilizados
theme_classic() +
labs(
x = "",
y = "Number of contacts",
title = "Daily Contact Followup Status",
fill = "Followup Status",
subtitle = str_glue("Data as of {max(followups$date_of_followup, na.rm=T)}")) # Subtítulo dinámico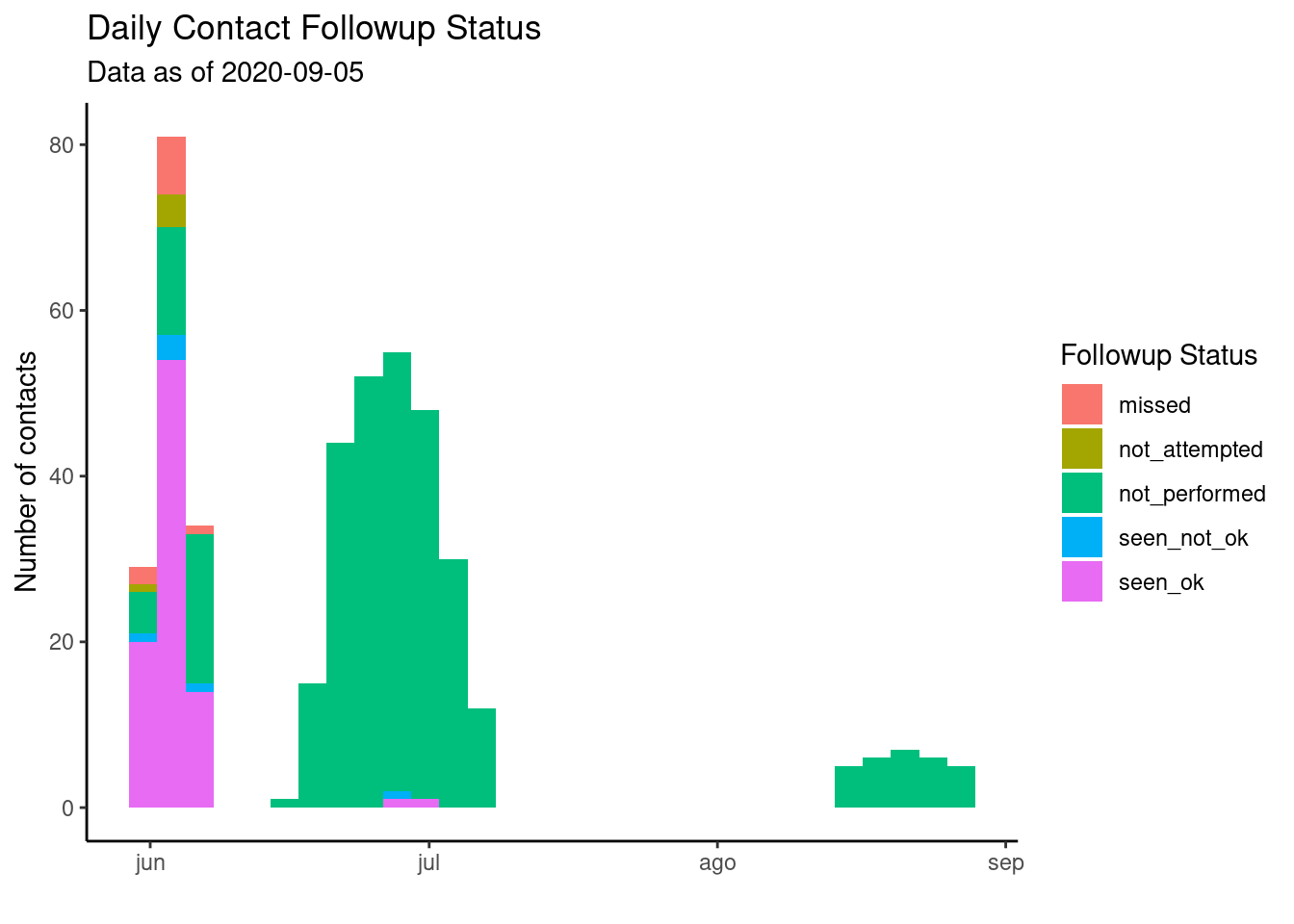
PRECAUCIÓN: Si estás preparando muchos gráficos (por ejemplo, para múltiples jurisdicciones) querrás que las leyendas aparezcan de forma idéntica incluso con diferentes niveles de finalización o composición de los datos. Puede haber gráficos para los cuales no todos los estados de seguimiento están presentes, pero todavía quieres que esas categorías aparezcan en las leyendas. En ggplot (como arriba), puedes especificar el argumento drop = FALSE de scale_fill_discrete(). En las tablas, utiliza tabyl() que muestra los recuentos de todos los niveles de los factores, o si utilizas count() de dplyr añade el argumento .drop = FALSE para incluir los recuentos de todos los niveles de los factores.
Seguimiento individual diario
Si tu brote es lo suficientemente pequeño, es posible que quieras mirar cada contacto individualmente y ver su estado a lo largo del seguimiento. Afortunadamente, este conjunto de datos de seguimiento ya contiene una columna con el “número” de día de seguimiento (1-14). Si no existe en tus datos, puedes crearla calculando la diferencia entre la fecha de encuentro y la fecha en la que el seguimiento debía comenzar para el contacto.
Un mecanismo de visualización conveniente (si el número de casos no es demasiado grande) puede ser un gráfico de calor, hecho con geom_tile(). Mira más detalles en la página Gráficos de calor.
ggplot(data = followups_clean)+
geom_tile(mapping = aes(x = followup_number, y = contact_id, fill = followup_status),
color = "grey")+ # Cuadrículas grises
scale_fill_manual( values = c("yellow", "grey", "orange", "darkred", "darkgreen"))+
theme_minimal()+
scale_x_continuous(breaks = seq(from = 1, to = 14, by = 1))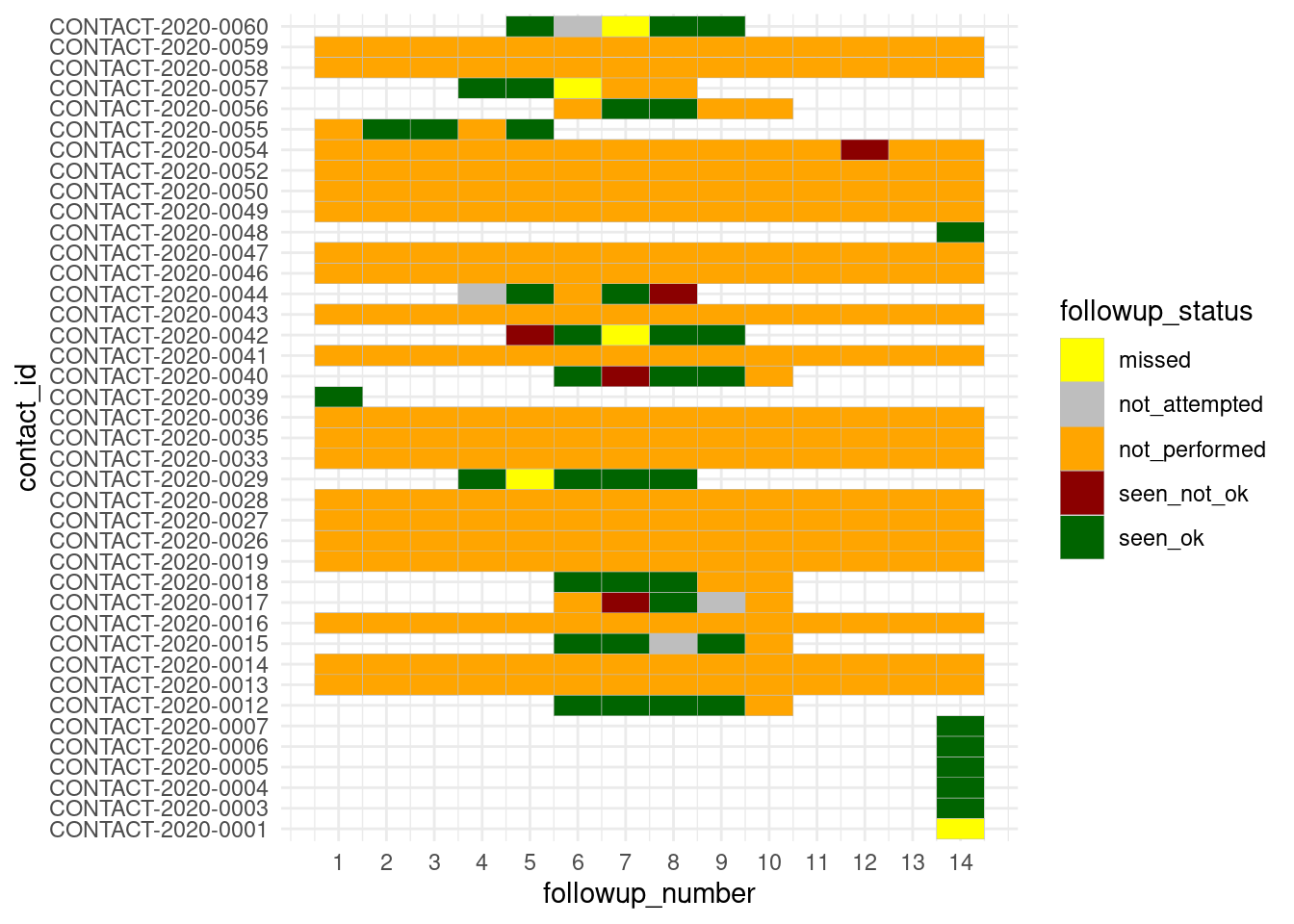
Analizar por grupos
Tal vez estos datos de seguimiento se consulten diaria o semanalmente para la toma de decisiones operativas. Es posible que desees desgloses más significativos por zona geográfica o por equipo de seguimiento de contactos. Podemos hacerlo ajustando las columnas proporcionadas a group_by().
plot_by_region <- followups_clean %>% # comienza con los datos de seguimiento
count(admin_1_name, admin_2_name, followup_status) %>% # obtiene los recuentos por región-status único (crea la columna 'n' con los recuentos)
# comenzar ggplot()
ggplot( # comienza ggplot
mapping = aes(x = reorder(admin_2_name, n), # reordena los niveles del factor admin por los valores numéricos de la columna 'n'
y = n, # altura de las barras de la columna 'n'
fill = followup_status, # colorear las barras apiladas según su estado
label = n))+ # para pasar a geom_label()
geom_col()+ # barras apiladas, asignación heredada de arriba
geom_text( # añade texto, asignación heredada de arriba
size = 3,
position = position_stack(vjust = 0.5),
color = "white",
check_overlap = TRUE,
fontface = "bold")+
coord_flip()+
labs(
x = "",
y = "Number of contacts",
title = "Contact Followup Status, by Region",
fill = "Followup Status",
subtitle = str_glue("Data as of {max(followups_clean$date_of_followup, na.rm=T)}")) +
theme_classic()+ # simplifica el fondo
facet_wrap(~admin_1_name, strip.position = "right", scales = "free_y", ncol = 1) # introduce facetas
plot_by_region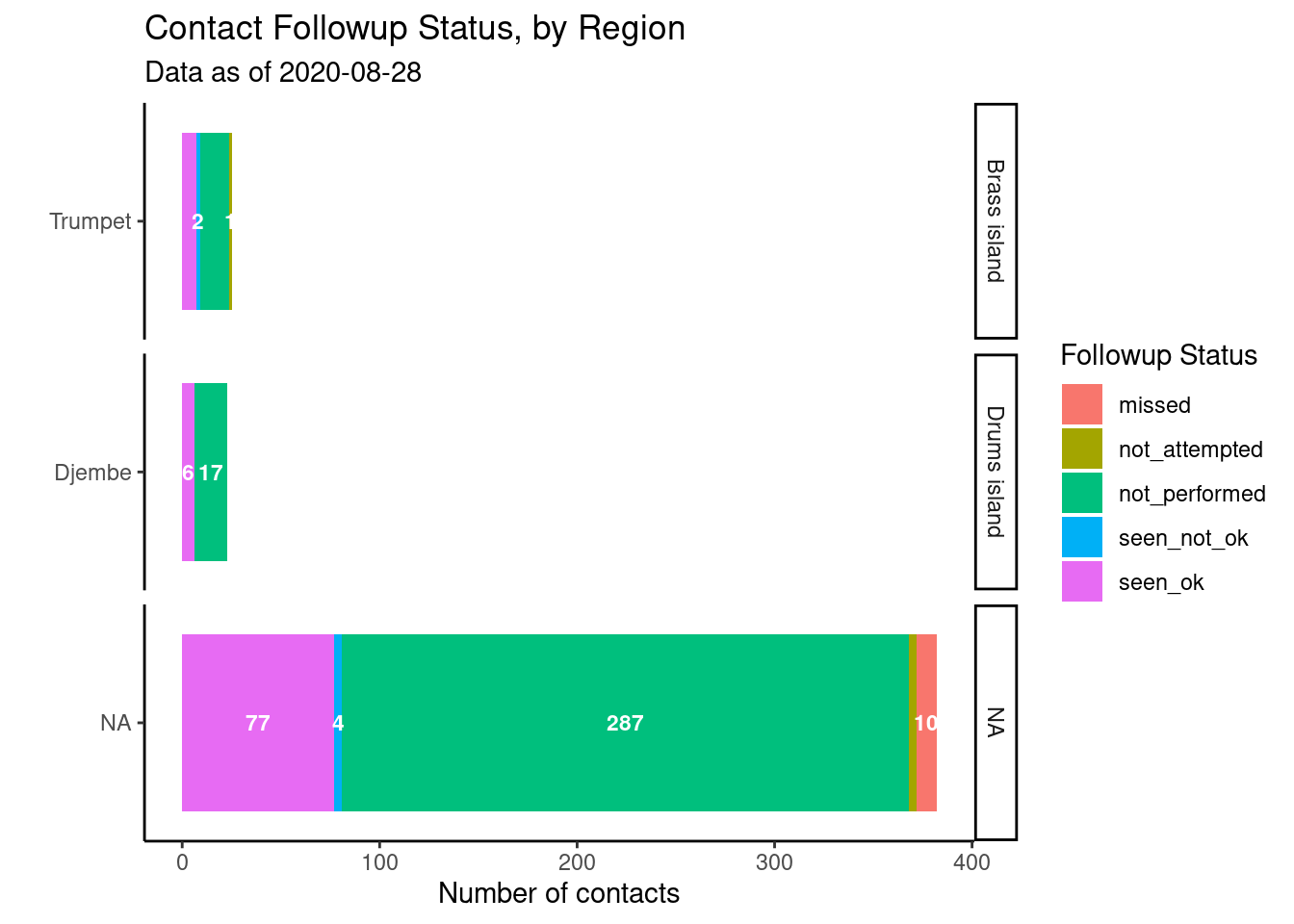
25.4 Tablas KPI
Hay una serie de Indicadores Clave de Rendimiento (KPI) que pueden calcularse y seguirse a distintos niveles de desagregación y a lo largo de diferentes períodos de tiempo para supervisar el rendimiento del rastreo de contactos. Una vez que se tienen los cálculos y el formato básico de la tabla, es bastante fácil cambiar los diferentes KPI.
Existen numerosas fuentes de KPI de rastreo de contactos, como ésta de ResolveToSaveLives.org. La mayor parte del trabajo consistirá en recorrer la estructura de datos y pensar en todos los criterios de inclusión/exclusión. A continuación mostramos algunos ejemplos, utilizando la estructura de metadatos de Go.Data:
| Categoría | Indicador | Numerador Go.Data | Denominador Go.Data |
|---|---|---|---|
| Indicador de proceso - Velocidad de rastreo de contactos | % de casos entrevistados y aislados en las 24 horas siguientes a la notificación del caso | COUNT OF case_id WHERE (date_of_reporting - date_of_data_entry) < 1 day AND (isolation_startdate - date_of_data_entry) < 1 day |
COUNT OF case_id
|
| Indicador de proceso - Velocidad de rastreo de contactos | % de contactos notificados y puestos en cuarentena en las 24 horas siguientes a la solicitud | COUNT OF contact_id WHERE followup_status == “SEEN_NOT_OK” OR “SEEN_OK” AND date_of_followup - date_of_reporting < 1 day |
COUNT OF contact_id
|
| Indicador de proceso - Completitud de las pruebas | % de nuevos casos sintomáticos examinados y entrevistados en los 3 días siguientes al inicio de los síntomas | COUNT OF case_id WHERE (date_of_reporting - date_of_onset) < =3 days |
COUNT OF case_id
|
| Indicador de resultado - Global | % de nuevos casos entre la lista de contactos existente | COUNT OF case_id WHERE was_contact == “TRUE” |
COUNT OF case_id
|
A continuación veremos un ejercicio de ejemplo para crear una bonita tabla visual para mostrar el seguimiento de los contactos en las áreas de administración. Al final, lo haremos apto para la presentación con el paquete formattable (pero podrías usar otros paquetes como flextable - ver Tablas para presentaciones).
La forma de crear una tabla como ésta dependerá de la estructura de los datos de seguimiento de contactos. Utiliza la página de tablas descriptivas para aprender a resumir los datos utilizando las funciones de dplyr.
Crearemos una tabla que será dinámica y cambiará a medida que cambien los datos. Para que los resultados sean interesantes, estableceremos una report_date que nos permita simular la ejecución de la tabla en un día determinado (elegimos el 10 de junio de 2020). Los datos se filtran por esa fecha.
# Set "Report date" to simulate running the report with data "as of" this date
report_date <- as.Date("2020-06-10")
# Create follow-up data to reflect the report date.
table_data <- followups_clean %>%
filter(date_of_followup <= report_date)Ahora, basándonos en nuestra estructura de datos, haremos lo siguiente:
- Comienza con los datos de
followupsy resúmelos para contener, para cada contacto único:
- La fecha del último registro (sin importar el estado del encuentro)
- La fecha del último encuentro en el que el contacto fue “visto”
- El estado del encuentro en ese último encuentro “visto” (por ejemplo, con síntomas, sin síntomas)
- Uniremos estos datos a los de los contactos, que contienen otra información como el estado general del contacto, la fecha de la última exposición a un caso, etc. También calcularemos las métricas de interés para cada contacto, como los días desde la última exposición
- Agrupamos los datos de contacto mejorados por región geográfica (`admin_2_name) y calculamos las estadísticas resumidas por región
- Por último, damos un buen formato a la tabla para su presentación
Primero resumimos los datos de seguimiento para obtener la información de interés:
followup_info <- table_data %>%
group_by(contact_id) %>%
summarise(
date_last_record = max(date_of_followup, na.rm=T),
date_last_seen = max(date_of_followup[followup_status %in% c("seen_ok", "seen_not_ok")], na.rm=T),
status_last_record = followup_status[which(date_of_followup == date_last_record)]) %>%
ungroup()Así es como se ven estos datos:
Ahora añadiremos esta información a los datos de contacts y calcularemos algunas columnas adicionales.
contacts_info <- followup_info %>%
right_join(contacts, by = "contact_id") %>%
mutate(
database_date = max(date_last_record, na.rm=T),
days_since_seen = database_date - date_last_seen,
days_since_exposure = database_date - date_of_last_exposure
)Así es como se ven estos datos. Observa la columna contacts a la derecha, y la nueva columna calculada en el extremo derecho.
A continuación, resumimos los datos de los contactos por región, para conseguir un dataframe conciso de columnas de estadísticas resumidas.
contacts_table <- contacts_info %>%
group_by(`Admin 2` = admin_2_name) %>%
summarise(
`Registered contacts` = n(),
`Active contacts` = sum(contact_status == "UNDER_FOLLOW_UP", na.rm=T),
`In first week` = sum(days_since_exposure < 8, na.rm=T),
`In second week` = sum(days_since_exposure >= 8 & days_since_exposure < 15, na.rm=T),
`Became case` = sum(contact_status == "BECAME_CASE", na.rm=T),
`Lost to follow up` = sum(days_since_seen >= 3, na.rm=T),
`Never seen` = sum(is.na(date_last_seen)),
`Followed up - signs` = sum(status_last_record == "Seen_not_ok" & date_last_record == database_date, na.rm=T),
`Followed up - no signs` = sum(status_last_record == "Seen_ok" & date_last_record == database_date, na.rm=T),
`Not Followed up` = sum(
(status_last_record == "NOT_ATTEMPTED" | status_last_record == "NOT_PERFORMED") &
date_last_record == database_date, na.rm=T)) %>%
arrange(desc(`Registered contacts`))Y ahora aplicamos el estilo de los paquetes formattable y knitr, incluyendo una nota a pie de página que muestra la fecha “a partir de”.
contacts_table %>%
mutate(
`Admin 2` = formatter("span", style = ~ formattable::style(
color = ifelse(`Admin 2` == NA, "red", "grey"),
font.weight = "bold",font.style = "italic"))(`Admin 2`),
`Followed up - signs`= color_tile("white", "orange")(`Followed up - signs`),
`Followed up - no signs`= color_tile("white", "#A0E2BD")(`Followed up - no signs`),
`Became case`= color_tile("white", "grey")(`Became case`),
`Lost to follow up`= color_tile("white", "grey")(`Lost to follow up`),
`Never seen`= color_tile("white", "red")(`Never seen`),
`Active contacts` = color_tile("white", "#81A4CE")(`Active contacts`)
) %>%
kable("html", escape = F, align =c("l","c","c","c","c","c","c","c","c","c","c")) %>%
kable_styling("hover", full_width = FALSE) %>%
add_header_above(c(" " = 3,
"Of contacts currently under follow up" = 5,
"Status of last visit" = 3)) %>%
kableExtra::footnote(general = str_glue("Data are current to {format(report_date, '%b %d %Y')}"))| Admin 2 | Registered contacts | Active contacts | In first week | In second week | Became case | Lost to follow up | Never seen | Followed up - signs | Followed up - no signs | Not Followed up |
|---|---|---|---|---|---|---|---|---|---|---|
| Djembe | 59 | 30 | 44 | 0 | 2 | 15 | 22 | 0 | 0 | 0 |
| Trumpet | 3 | 1 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| Venu | 2 | 0 | 0 | 0 | 2 | 0 | 2 | 0 | 0 | 0 |
| Congas | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 0 | 0 |
| Cornet | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 0 | 0 |
| Note: | ||||||||||
| Data are current to jun 10 2020 |
25.5 Matrices de transmisión
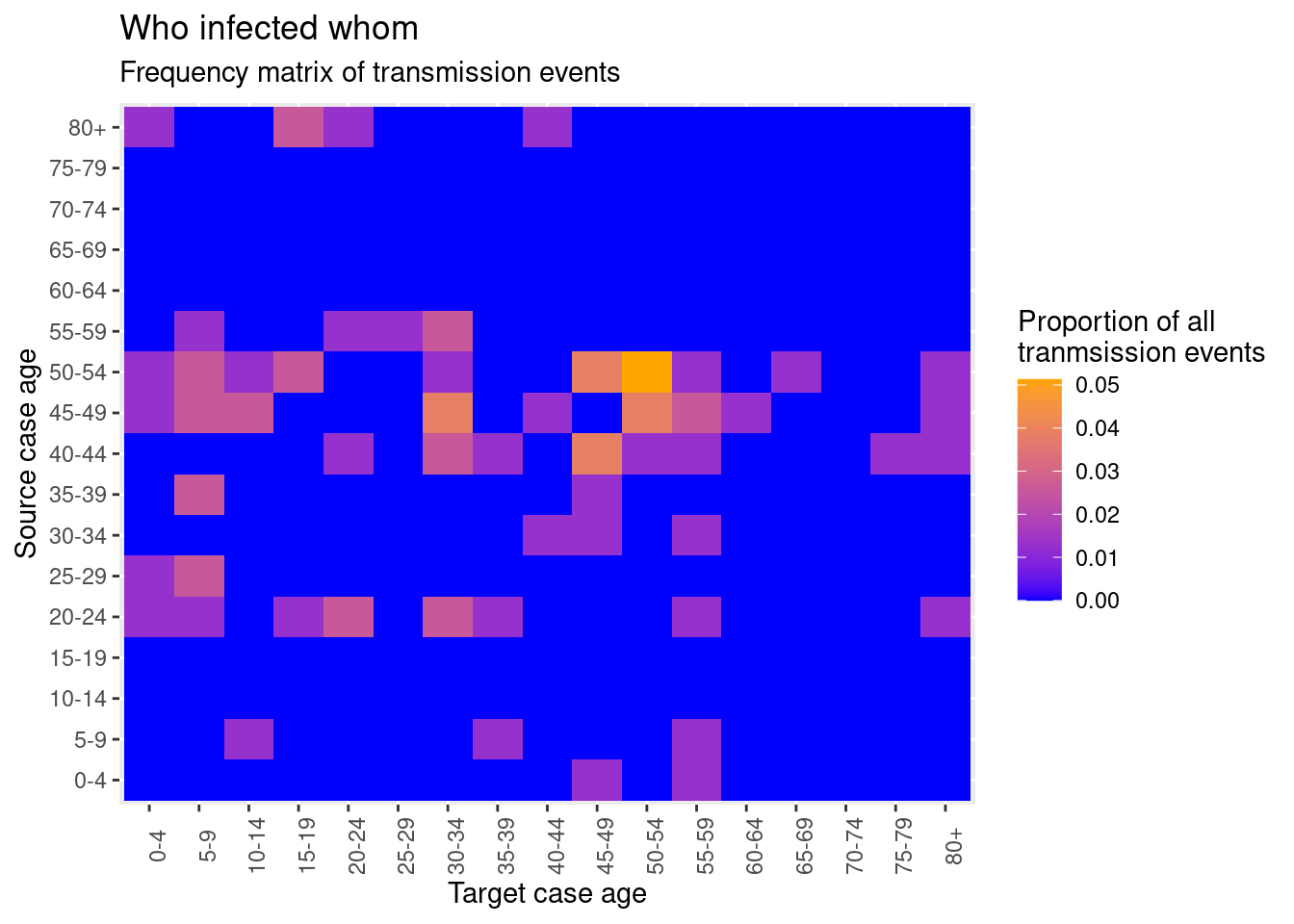
Como se discutió en la página de Gráficos de calor, puedes crear una matriz de “quién infectó a quién” utilizando geom_tile().
Cuando se crean nuevos contactos, Go.Data almacena esta información de relación en el punto final de la API relationships; y podemos ver las primeras 50 filas de este conjunto de datos a continuación. Esto significa que podemos crear un gráfico de calor con relativamente pocos pasos, dado que cada contacto ya está unido a su caso de origen.
Al igual que en el caso de la pirámide de edad que compara casos y contactos, podemos seleccionar las pocas variables que necesitamos y crear columnas con agrupaciones categóricas de edad tanto para las fuentes (casos) como para los objetivos (contactos).
heatmap_ages <- relationships %>%
select(source_age, target_age) %>%
mutate( # transmute es como mutate() pero elimina todas las demás columnas
source_age_class = epikit::age_categories(source_age, breakers = seq(0, 80, 5)),
target_age_class = epikit::age_categories(target_age, breakers = seq(0, 80, 5))) Como se ha descrito anteriormente, creamos una tabulación cruzada;
cross_tab <- table(
source_cases = heatmap_ages$source_age_class,
target_cases = heatmap_ages$target_age_class)
cross_tab## target_cases
## source_cases 0-4 5-9 10-14 15-19 20-24 25-29 30-34 35-39 40-44 45-49 50-54 55-59 60-64 65-69 70-74 75-79 80+
## 0-4 0 0 0 0 0 0 0 0 0 1 0 1 0 0 0 0 0
## 5-9 0 0 1 0 0 0 0 1 0 0 0 1 0 0 0 0 0
## 10-14 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
## 15-19 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
## 20-24 1 1 0 1 2 0 2 1 0 0 0 1 0 0 0 0 1
## 25-29 1 2 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
## 30-34 0 0 0 0 0 0 0 0 1 1 0 1 0 0 0 0 0
## 35-39 0 2 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0
## 40-44 0 0 0 0 1 0 2 1 0 3 1 1 0 0 0 1 1
## 45-49 1 2 2 0 0 0 3 0 1 0 3 2 1 0 0 0 1
## 50-54 1 2 1 2 0 0 1 0 0 3 4 1 0 1 0 0 1
## 55-59 0 1 0 0 1 1 2 0 0 0 0 0 0 0 0 0 0
## 60-64 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
## 65-69 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
## 70-74 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
## 75-79 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
## 80+ 1 0 0 2 1 0 0 0 1 0 0 0 0 0 0 0 0convertimos en formato largo con proporciones;
long_prop <- data.frame(prop.table(cross_tab))y creamos un mapa de calor para la edad.
ggplot(data = long_prop)+ # utiliza datos largos, con proporciones como Freq
geom_tile( # visualizarlo en mosaicos
aes(
x = target_cases, # el eje-x es la edad de los casos
y = source_cases, # el eje-y es la edad del infector
fill = Freq))+ # el color del mosaico es la columna Freq de los datos
scale_fill_gradient( # ajusta el color de relleno de los mosaicos
low = "blue",
high = "orange")+
theme(axis.text.x = element_text(angle = 90))+
labs( # etiquetas
x = "Target case age",
y = "Source case age",
title = "Who infected whom",
subtitle = "Frequency matrix of transmission events",
fill = "Proportion of all\ntranmsission events" # título de la leyenda
)