17 Tabelas descritivas
Esta página demonstra o uso dos pacotes janitor, dplyr, gtsummary, rstatix, e R base para gerar um resumo dos dados e criar tabelas com estatísticas descritivas.
Esta página explica como criar* as tabelas básicas e detalhadas, enquanto que a página Tabelas para apresentações descreve como formatar e imprimir essas tabelas de forma visualmente agradável.*
Cada um destes pacotes tem vantagens e desvantagens em relação à simplicidade do código, acessibilidade dos resultados gerados, e qualidade da impressão destes resultados. Utilize esta página para decidir qual abordagem funciona melhor para a sua realidade.
Você tem várias opções para produzir tabelas simples e tabelas cruzadas (também conhecidas como tabelas de contingência). Entretanto, é necessário levar em consideração alguns fatores, como a simplicidade do código R utilizado; a capacidade de personalização deste código; a forma de geração dos resultados (para visualização no terminal do R, ou como uma tabela de dados (data frame), e/ou como uma imagem ‘bonita’ nos formatos .png/.jpeg/.html); e a facilidade de pós-processamento dos resultados gerados. Leve em consideração os pontos abaixo ao escolher uma ferramenta para atender as suas necessidades.
- Use a função
tabyl()do janitor para produzir e personalizar tabulações simples e tabulações cruzadas
- Use a função
get_summary_stats()do rstatix para gerar tabelas com resumos estatísticos de diferentes colunas e/ou grupos de dados de forma fácil
- Use as funções
summarise()ecount()do dplyr para realizar análises estatísticas mais complexas, gerar tabelas de dados organizadas, ou preparar os dados para utilizar na funçãoggplot()
- Use a função
tbl_summary()do gtsummary para produzir tabelas detalhadas prontas para publicação
- Use a função
table()do R base se você não tiver acesso aos pacotes citados acima
17.1 Preparação
Carregue os pacotes R
O código abaixo realiza o carregamento dos pacotes necessários para a análise dos dados. Neste manual, enfatizamos o uso da função p_load(), do pacman, que instala os pacotes, caso não estejam instalados, e os carrega no R para utilização. Também é possível carregar pacotes instalados utilizando a função library(), do r base. Para mais informações sobre os pacotes do R, veja a página Introdução ao R.
pacman::p_load(
rio, # importa arquivos
here, # localiza arquivos
skimr, # gera visualização dos dados
tidyverse, # gestão dos dados + gráficos no ggplot2
gtsummary, # resumo estatísticos e testes
rstatix, # resumo e testes estatísticos
janitor, # adiciona números absolutos e porcentagens às tabelas
scales, # facilmente converte proporções para porcentagens
flextable # converte tabelas para o formato de imagens
)Importe os dados no R
Nós iremos importar o banco de dados de casos de uma simulação de epidemia de Ebola. Se você quiser acompanhar os passos abaixo, clique aqui para fazer o download do banco de dados ‘limpo’ (como arquivo .rds). Importe seus dados utilizando a função import() do pacote rio (esta função importa muitos tipos de arquivos, como .xlsx, .rds, .csv - veja a página Importar e exportar para detalhes).
# importe o banco de dados limpo
linelist <- import("linelist_cleaned.rds")As primeiras 50 linhas do banco de dados são mostradas abaixo.
17.2 Explore seus dados
Pacote skimr
Ao utilizar o pacote skimr, você pode obter um resumo detalhado e esteticamente agradável de cada variável do seu banco de dados. Leia mais sobre o skimr na sua página no github.
Abaixo, a função skim() é aplicada a todos os dados do objeto linelist, criado no código acima. Após execução do código, uma visão geral dos dados e um resumo de cada coluna (por classe) são gerados.
## obtenha informações sobre cada variável no banco de dados
skim(linelist)| Name | linelist |
| Number of rows | 5888 |
| Number of columns | 30 |
| _______________________ | |
| Column type frequency: | |
| character | 13 |
| Date | 4 |
| factor | 2 |
| numeric | 11 |
| ________________________ | |
| Group variables | None |
Variable type: character
| skim_variable | n_missing | complete_rate | min | max | empty | n_unique | whitespace |
|---|---|---|---|---|---|---|---|
| case_id | 0 | 1.00 | 6 | 6 | 0 | 5888 | 0 |
| outcome | 1323 | 0.78 | 5 | 7 | 0 | 2 | 0 |
| gender | 278 | 0.95 | 1 | 1 | 0 | 2 | 0 |
| age_unit | 0 | 1.00 | 5 | 6 | 0 | 2 | 0 |
| hospital | 0 | 1.00 | 5 | 36 | 0 | 6 | 0 |
| infector | 2088 | 0.65 | 6 | 6 | 0 | 2697 | 0 |
| source | 2088 | 0.65 | 5 | 7 | 0 | 2 | 0 |
| fever | 249 | 0.96 | 2 | 3 | 0 | 2 | 0 |
| chills | 249 | 0.96 | 2 | 3 | 0 | 2 | 0 |
| cough | 249 | 0.96 | 2 | 3 | 0 | 2 | 0 |
| aches | 249 | 0.96 | 2 | 3 | 0 | 2 | 0 |
| vomit | 249 | 0.96 | 2 | 3 | 0 | 2 | 0 |
| time_admission | 765 | 0.87 | 5 | 5 | 0 | 1072 | 0 |
Variable type: Date
| skim_variable | n_missing | complete_rate | min | max | median | n_unique |
|---|---|---|---|---|---|---|
| date_infection | 2087 | 0.65 | 2014-03-19 | 2015-04-27 | 2014-10-11 | 359 |
| date_onset | 256 | 0.96 | 2014-04-07 | 2015-04-30 | 2014-10-23 | 367 |
| date_hospitalisation | 0 | 1.00 | 2014-04-17 | 2015-04-30 | 2014-10-23 | 363 |
| date_outcome | 936 | 0.84 | 2014-04-19 | 2015-06-04 | 2014-11-01 | 371 |
Variable type: factor
| skim_variable | n_missing | complete_rate | ordered | n_unique | top_counts |
|---|---|---|---|---|---|
| age_cat | 86 | 0.99 | FALSE | 8 | 0-4: 1095, 5-9: 1095, 20-: 1073, 10-: 941 |
| age_cat5 | 86 | 0.99 | FALSE | 17 | 0-4: 1095, 5-9: 1095, 10-: 941, 15-: 743 |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 | hist |
|---|---|---|---|---|---|---|---|---|---|---|
| generation | 0 | 1.00 | 16.56 | 5.79 | 0.00 | 13.00 | 16.00 | 20.00 | 37.00 | ▁▆▇▂▁ |
| age | 86 | 0.99 | 16.07 | 12.62 | 0.00 | 6.00 | 13.00 | 23.00 | 84.00 | ▇▅▁▁▁ |
| age_years | 86 | 0.99 | 16.02 | 12.64 | 0.00 | 6.00 | 13.00 | 23.00 | 84.00 | ▇▅▁▁▁ |
| lon | 0 | 1.00 | -13.23 | 0.02 | -13.27 | -13.25 | -13.23 | -13.22 | -13.21 | ▅▃▃▆▇ |
| lat | 0 | 1.00 | 8.47 | 0.01 | 8.45 | 8.46 | 8.47 | 8.48 | 8.49 | ▅▇▇▇▆ |
| wt_kg | 0 | 1.00 | 52.64 | 18.58 | -11.00 | 41.00 | 54.00 | 66.00 | 111.00 | ▁▃▇▅▁ |
| ht_cm | 0 | 1.00 | 124.96 | 49.52 | 4.00 | 91.00 | 129.00 | 159.00 | 295.00 | ▂▅▇▂▁ |
| ct_blood | 0 | 1.00 | 21.21 | 1.69 | 16.00 | 20.00 | 22.00 | 22.00 | 26.00 | ▁▃▇▃▁ |
| temp | 149 | 0.97 | 38.56 | 0.98 | 35.20 | 38.20 | 38.80 | 39.20 | 40.80 | ▁▂▂▇▁ |
| bmi | 0 | 1.00 | 46.89 | 55.39 | -1200.00 | 24.56 | 32.12 | 50.01 | 1250.00 | ▁▁▇▁▁ |
| days_onset_hosp | 256 | 0.96 | 2.06 | 2.26 | 0.00 | 1.00 | 1.00 | 3.00 | 22.00 | ▇▁▁▁▁ |
Você também pode usar a função summary(), do R base, para obter informações sobre o banco de dados inteiro, mas os resultados obtidos podem ser mais difíceis de visualizar do que utilizando o skimr. O resultado da análise com summary() não é mostrado abaixo, visando poupar espaço na página.
## obtenha informações sobre cada coluna no banco de dados
summary(linelist)Resumos estatísticos
Você pode utilizar as funções do R base para obter resumos estatísticos de uma coluna com dados numéricos. Boa parte das análises estatísticas mais úteis com este tipo de coluna pode ser obtido utilizando a função summary(), como mostrado abaixo. Observe que o nome da tabela de dados e da coluna (linelist) precisam ser especificados como mostrado abaixo.
summary(linelist$age_years) Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
0.00 6.00 13.00 16.02 23.00 84.00 86 Você pode obter e salvar uma parte específica da análise utilizando o indexador com colchetes [ ]:
summary(linelist$age_years)[[2]] # obtém apenas o resultado da análise no índice [2][1] 6# alternativa equivalente ao indexador [2], utilizando o nome do campo:
# summary(linelist$age_years)[["1st Qu."]] Você pode obter estatísticas individuais com outras funções do R base, como max(), min(), median(), mean(), quantile(), sd(), e range(). Veja a página Introdução ao R para uma lista completa.
CUIDADO: Caso seus dados contenham campos em branco, o R quer que você saiba disso e irá gerar NA na análise. Isso só não irá ocorrer caso você ‘peça’ para o R ignorar esses campos em branco nas funções matemáticas acima. Isso pode ser realizado com o argumentona.rm = TRUE.
Você pode usar a função get_summary_stats(), do rstatix, para obter o resumo estatístico em formato de quadro de dados (data frame). Isso pode ser útil na execução de comandos posteriores ou para criação de gráficos com os valores. Veja a página Testes estatísticos simples para mais detalhes do pacote rstatix e suas funções.
linelist %>%
get_summary_stats(
age, wt_kg, ht_cm, ct_blood, temp, # variáveis para realizar o cálculo
type = "common") # tipo do resumo estatístico a ser gerado# A tibble: 5 × 10
variable n min max median iqr mean sd se ci
<fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 age 5802 0 84 13 17 16.1 12.6 0.166 0.325
2 wt_kg 5888 -11 111 54 25 52.6 18.6 0.242 0.475
3 ht_cm 5888 4 295 129 68 125. 49.5 0.645 1.26
4 ct_blood 5888 16 26 22 2 21.2 1.69 0.022 0.043
5 temp 5739 35.2 40.8 38.8 1 38.6 0.977 0.013 0.02517.3 Pacote janitor
O pacote janitor contém a função tabyl(), que gera tabulações simples e tabulações cruzadas que podem ser modificadas com funções auxiliares para mostrarem porcentagens, proporções, contagens, etc.
Abaixo, nós utilizamos as funções do janitor no banco de dados linelist, criado anteriormente, e visualizamos o resultado da análise. Se necessário, é possível salvar as tabelas geradas utilizando o operador <-, e atribuindo elas a um novo objeto no R.
Básico do tabyl
O uso do tabyl(), no modo padrão, em uma coluna específica produz uma tabela com os valores únicos desta coluna, suas contagens, e “porcentagens” (proporções, na realidade). Como as proporções podem ter muitos dígitos, é possível ajustar o número de casas decimais com a função adorn_rounding(), descrita abaixo.
linelist %>% tabyl(age_cat) age_cat n percent valid_percent
0-4 1095 0.185971467 0.188728025
5-9 1095 0.185971467 0.188728025
10-14 941 0.159816576 0.162185453
15-19 743 0.126188859 0.128059290
20-29 1073 0.182235054 0.184936229
30-49 754 0.128057065 0.129955188
50-69 95 0.016134511 0.016373664
70+ 6 0.001019022 0.001034126
<NA> 86 0.014605978 NAComo observado acima, se existirem campos em branco na coluna analisada, eles são mostrados em uma linha chamada <NA>. Você pode omitir estes campos com o atributo show_na = FALSE. Se não existirem campos em branco, essa linha não irá aparecer. Se estes campos existirem, todas as proporções são geradas como ‘brutas’ (coluna ‘percent’ gerada, em que a quantidade de campos NA está inclusa no denominador) e ‘válidas’ (coluna ‘valid_percent’, onde a quantidade de campos NA não é considerada no cálculo).
Se a coluna for um fator (da classe Factor) e apenas alguns níveis dessa classe estiverem presentes em seus dados, todos os níveis desta classe serão mostrados na tabela de análise. Você pode omitir essa característica ao usar o atributo show_missing_levels = FALSE. Leia mais na página Fatores.
Tabulação cruzada (tabela de contingência)
As quantidades absolutas das tabulações cruzadas são obtidas ao adicionarmos uma ou mais variáveis dentro da função tabyl(). Observe que agora apenas os números absolutos são obtidos - proporções e porcentagens podem ser adicionadas à análise com etapas adicionais mostradas abaixo.
linelist %>% tabyl(age_cat, gender) age_cat f m NA_
0-4 640 416 39
5-9 641 412 42
10-14 518 383 40
15-19 359 364 20
20-29 468 575 30
30-49 179 557 18
50-69 2 91 2
70+ 0 5 1
<NA> 0 0 86Personalizando o tabyl
Use as funções “adorn”, do janitor, para adicionar ao resultado da análise as colunas de números absolutos assim como converter para proporções, percentuais, ou ajustar o formato de gerado. Você utilizar essas funções nas tabelas geradas pelo tabyl frequentemente.
| Função | Resultado |
|---|---|
adorn_totals() |
Adiciona uma linha/coluna com os totais (where = “row”, “col”, or “both”). “row”: linhas; “col”: colunas; “both”: ambas. Atribua ao campo name = o nome “Total”. |
adorn_percentages() |
Converte contagens absolutas para proporções, escolhendo o denominator = “row”, “col”, or “all”. |
adorn_pct_formatting() |
Converte proporções para percentuais. Especifique o número de casas decimais com o atributo digits =. Remova o símbolo “%” com o atributo affix_sign = FALSE. |
adorn_rounding() |
Arredonde as proporções utilizando digits = nº de casas decimais. Para arredondar percentuais, utilize a função adorn_pct_formatting() com digits =. |
adorn_ns() |
Adicione a tabela as quantidades absolutas com as proporções ou porcentagens. Utilize o atributo position = “rear” para mostrar as quantidades em parênteses, ou “front” para colocar as porcentagens em parênteses. |
adorn_title() |
Adiciona títulos à tabela gerada através dos argumentos row_name = e/ou col_name = |
Preste atenção na ordem em que você utiliza estas funções. Abaixo estão alguns exemplos:
Uma tabela simples com porcentagens no lugar das proporções, que são padrão.
linelist %>% # fonte dos dados
tabyl(age_cat) %>% # tabula números absolutos e proporções por idade
adorn_pct_formatting() # converte as proporções para porcentagens age_cat n percent valid_percent
0-4 1095 18.6% 18.9%
5-9 1095 18.6% 18.9%
10-14 941 16.0% 16.2%
15-19 743 12.6% 12.8%
20-29 1073 18.2% 18.5%
30-49 754 12.8% 13.0%
50-69 95 1.6% 1.6%
70+ 6 0.1% 0.1%
<NA> 86 1.5% -Uma tabela cruzada com os números absolutos e porcentagens de cada linha.
linelist %>%
tabyl(age_cat, gender) %>% # contagens absolutas e proporções cruzando idade e gênero
adorn_totals(where = "row") %>% # adiciona uma linha chamada 'Total', com os totais
adorn_percentages(denominator = "row") %>% # converte os números absolutos para proporções
adorn_pct_formatting(digits = 1) # converte as proporções para porcentagens age_cat f m NA_
0-4 58.4% 38.0% 3.6%
5-9 58.5% 37.6% 3.8%
10-14 55.0% 40.7% 4.3%
15-19 48.3% 49.0% 2.7%
20-29 43.6% 53.6% 2.8%
30-49 23.7% 73.9% 2.4%
50-69 2.1% 95.8% 2.1%
70+ 0.0% 83.3% 16.7%
<NA> 0.0% 0.0% 100.0%
Total 47.7% 47.6% 4.7%O código abaixo modifica uma tabela cruzada de dados de forma que as quantidades absolutas e os percentuais sejam mostrados.
linelist %>% # fonte dos dados
tabyl(age_cat, gender) %>% # geração da tabela cruzada
adorn_totals(where = "row") %>% # adiciona uma linha "Total", com os totais
adorn_percentages(denominator = "col") %>% # converte as quantidades absolutas para proporções
adorn_pct_formatting() %>% # converte as proporções para porcentagens
adorn_ns(position = "front") %>% # mostra os dados como: "n° absoluto (porcentagem)"
adorn_title( # nomeia os títulos das colunas e linhas
row_name = "Age Category",
col_name = "Gender") Gender
Age Category f m NA_
0-4 640 (22.8%) 416 (14.8%) 39 (14.0%)
5-9 641 (22.8%) 412 (14.7%) 42 (15.1%)
10-14 518 (18.5%) 383 (13.7%) 40 (14.4%)
15-19 359 (12.8%) 364 (13.0%) 20 (7.2%)
20-29 468 (16.7%) 575 (20.5%) 30 (10.8%)
30-49 179 (6.4%) 557 (19.9%) 18 (6.5%)
50-69 2 (0.1%) 91 (3.2%) 2 (0.7%)
70+ 0 (0.0%) 5 (0.2%) 1 (0.4%)
<NA> 0 (0.0%) 0 (0.0%) 86 (30.9%)
Total 2,807 (100.0%) 2,803 (100.0%) 278 (100.0%)Convertendo a tabela do tabyl para uma imagem
Por padrão, o tabyl vai gerar uma tabela ‘crua’ no seu console do R.
Adicionalmente, você pode obter a tabela no tabyl e utiliza-la nas funções do pacote flextable, ou outros pacotes similares, para gerar uma tabela no formato de imagem no RStudio Viewer, que pode ser exportada nos formatos .png, .jpeg, .html, etc. Isto é discutido na página Tabelas para apresentação. Observe que, caso você gere a tabela desta forma e utilize a função adorn_titles(), você precisa aplicar o atributo placement = "combined".
linelist %>% # fonte dos dados
tabyl(age_cat, gender) %>% # geração da tabela cruzada
adorn_totals(where = "row") %>% # adiciona uma linha "Total", com os totais
adorn_percentages(denominator = "col") %>% # converte as quantidades absolutas para proporções
adorn_pct_formatting() %>% # converte as proporções para porcentagens
adorn_ns(position = "front") %>%
adorn_title(
row_name = "Age Category",
col_name = "Gender",
placement = "combined") %>% # isto é necessário para gerar a tabela como imagem
flextable::flextable() %>% # converte a tabela em imagem
flextable::autofit() # formata a tabela em linha por colunaAge Category/Gender | f | m | NA_ |
|---|---|---|---|
0-4 | 640 (22.8%) | 416 (14.8%) | 39 (14.0%) |
5-9 | 641 (22.8%) | 412 (14.7%) | 42 (15.1%) |
10-14 | 518 (18.5%) | 383 (13.7%) | 40 (14.4%) |
15-19 | 359 (12.8%) | 364 (13.0%) | 20 (7.2%) |
20-29 | 468 (16.7%) | 575 (20.5%) | 30 (10.8%) |
30-49 | 179 (6.4%) | 557 (19.9%) | 18 (6.5%) |
50-69 | 2 (0.1%) | 91 (3.2%) | 2 (0.7%) |
70+ | 0 (0.0%) | 5 (0.2%) | 1 (0.4%) |
0 (0.0%) | 0 (0.0%) | 86 (30.9%) | |
Total | 2,807 (100.0%) | 2,803 (100.0%) | 278 (100.0%) |
Personalizando outras tabelas com funções ‘adorn’
Você pode utilizar as funções adorn_*(), do pacote janitor, em outras tabelas, como as criadas pelas funções summarise() e count() do pacote dplyr, ou table() do R base. Simplesmente aplique a tabela gerada à função desejada do pacote janitor. Por exemplo:
linelist %>%
count(hospital) %>% # função do pacote dplyr
adorn_totals() # função do pacote janitor hospital n
Ausente 1469
Central Hospital 454
Military Hospital 896
Other 885
Port Hospital 1762
St. Mark's Maternity Hospital (SMMH) 422
Total 5888Salvando a tabela do tabyl
Se você converteu a tabela para uma imagem ‘bonita’ utilizando um pacote como flextable, você pode salvar ela com as funções desse pacote - utilizando as funções save_as_html(), save_as_word(), save_as_ppt(), e save_as_image() do flextable (discutido em detalhes na página Tabelas para apresentação). No código abaixo, a tabela é salva em um documento Word, onde poderá ser editada manualmente.
linelist %>%
tabyl(age_cat, gender) %>%
adorn_totals(where = "col") %>%
adorn_percentages(denominator = "col") %>%
adorn_pct_formatting() %>%
adorn_ns(position = "front") %>%
adorn_title(
row_name = "Faixa-Etária",
col_name = "Gênero",
placement = "combined") %>%
flextable::flextable() %>% # converte para imagem
flextable::autofit() %>% # garante apenas uma linha por coluna
flextable::save_as_docx(path = "tabyl.docx") # salva a imagem como um documento Word no endereço do documento (filepath)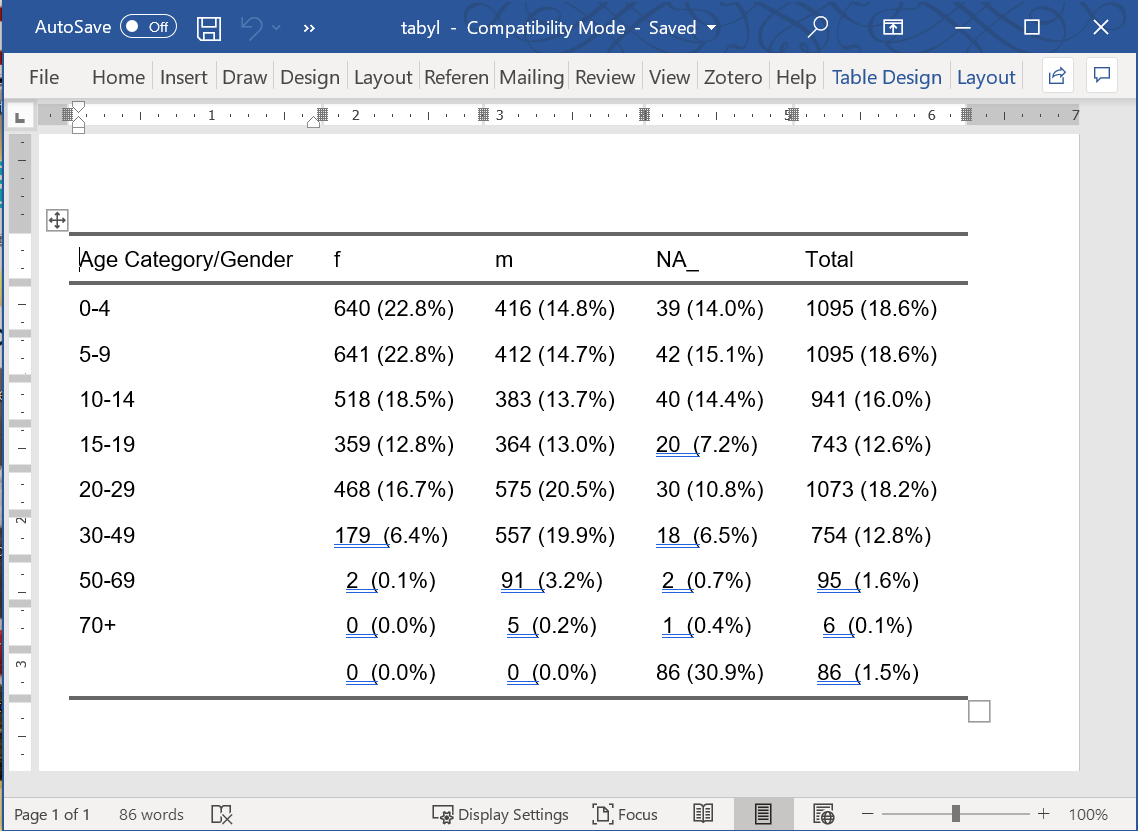
Análises estatísticas
Como mostrado abaixo, você pode aplicar testes estatísticos nas tabelas dos tabyls, como chisq.test() ou fisher.test() do pacote stats. Observe que campos em branco não são permitidos, devendo serem excluídos do tabyl com o atributo show_na = FALSE.
age_by_outcome <- linelist %>%
tabyl(age_cat, outcome, show_na = FALSE)
chisq.test(age_by_outcome)
Pearson's Chi-squared test
data: age_by_outcome
X-squared = 6.4931, df = 7, p-value = 0.4835Veja a página Testes estatísticos simples para mais códigos e dicas sobre estatística.
Outras dicas
- Utilize o argumento
na.rm = TRUEpara excluir campos em brancos de qualquer um dos cálculos acima.
- Se utilizar qualquer função
adorn_*()em tabelas criadas com outra função além dotabyl(), você pode especificar a(s) coluna(s) para aplicar o “adorn”, como emadorn_percentage(,,,c(cases,deaths))(onde a porcentagem será adicionada somente no quarto argumento da análise). Como a sintaxe não é simples, considere utilizar a funçãosummarise()em seu lugar.
- Você pode obter mais detalhes na página do janitor e nesse resumo do tabyl.
17.4 Pacote dplyr
dplyr faz parte dos pacotes tidyverse, sendo uma ferramenta de gestão de dados muito comum. Criar tabelas com as funções summarise() e count() do dplyr é uma abordagem útil para obter resumos estatísticos, resumos por grupos, ou para utilizá-las no ggplot().
A função summarise() cria uma nova tabela resumo dos dados. Se os dados não são agrupados, esta função gera uma tabela de dados de uma linha com os resumos estatísticos desejados do banco de dados inteiro. Se os dados são agrupados, a nova tabela terá um linha por grupo (veja a página Agrupando dados).
Dentro dos parênteses da função summarise(), você pode incluir os nomes de cada nova coluna, seguido pelo sinal de igual e uma função estatística a ser utilizada.
DICA: A função summarise pode ser escrita na forma do inglês britânico e americano (summarise() e summarize()).
Obtendo as quantidades absolutas
A função mais simples para utilizar dentro de summarise() é a função n(). Não insira nada dentro dos parênteses para a função contar o total de linhas.
linelist %>% # inicia com o banco de dados 'linelist'
summarise(n_rows = n()) # gera uma nova tabela com uma coluna contendo o número de linhas n_rows
1 5888Esta análise é mais interessante se agruparmos os dados antes.
linelist %>%
group_by(age_cat) %>% # agrupe os dados por valores únicos da coluna 'age_cat'
summarise(n_rows = n()) # gera o número de linhas *por grupo*# A tibble: 9 × 2
age_cat n_rows
<fct> <int>
1 0-4 1095
2 5-9 1095
3 10-14 941
4 15-19 743
5 20-29 1073
6 30-49 754
7 50-69 95
8 70+ 6
9 <NA> 86O código acima pode ser encurtado ao utilizar a função count() em vez de summarise() e n(). A função count() faz o seguinte:
- Agrupa os dados de acordo com as colunas escolhidas
- Gera um resumo destes grupos utilizando a função
n()(criando a colunan)
- Desagrupa os dados
linelist %>%
count(age_cat) age_cat n
1 0-4 1095
2 5-9 1095
3 10-14 941
4 15-19 743
5 20-29 1073
6 30-49 754
7 50-69 95
8 70+ 6
9 <NA> 86Você pode mudar o nome da coluna resultante n para um diferente, ao especificar o novo nome com o atributo name =.
Os resultados das contagens de duas ou mais colunas usadas para agrupar os dados são gerados no formato “longo”, com as contagens na coluna n. Veja a página sobre Pivotando dados para aprender sobre as tabelas nos formatos “longos” e “amplos”.
linelist %>%
count(age_cat, outcome) age_cat outcome n
1 0-4 Death 471
2 0-4 Recover 364
3 0-4 <NA> 260
4 5-9 Death 476
5 5-9 Recover 391
6 5-9 <NA> 228
7 10-14 Death 438
8 10-14 Recover 303
9 10-14 <NA> 200
10 15-19 Death 323
11 15-19 Recover 251
12 15-19 <NA> 169
13 20-29 Death 477
14 20-29 Recover 367
15 20-29 <NA> 229
16 30-49 Death 329
17 30-49 Recover 238
18 30-49 <NA> 187
19 50-69 Death 33
20 50-69 Recover 38
21 50-69 <NA> 24
22 70+ Death 3
23 70+ Recover 3
24 <NA> Death 32
25 <NA> Recover 28
26 <NA> <NA> 26Mostre todos os níveis da classe factor
Se você estiver tabelando uma coluna da classe factor, é possível fazer com que todos os níveis dessa classe sejam mostrados (não apenas os níveis presentes nos dados) ao adicionar o atributo .drop = FALSE dentro das funções summarise() ou count().
Está técnica é útil para padronizar suas tabelas/gráficos. Por exemplo, se você estiver criando figuras para diferentes sub-grupos, ou precisar criar um mesmo tipo de figura para relatórios de rotina. Em cada uma dessas circuntâncias, os valores nos dados podem variar, mas é possível definir níveis que continuem constantes.
Veja a página sobre Fatores para mais informações.
Proporções
Colunas com proporções podem ser criadas ao canalizar (pipe) a tabela gerada para a função mutate(). A partir disso, as proporções podem ser calculadas através da divisão das quantidades absolutas geradas na coluna de contagem (n por padrão), divididos pela soma (sum()) de todas as contagens nessa coluna.
Observe que, neste caso, utilizar a função sum() dentro do mutate() irá gerar a soma da coluna n inteira, e utilizá-la como denominador no cálculo das proporções. Como explicado na página de agrupamento de dados, se sum() for utilizada em dados agrupados (por exemplo, se o mutate() for imediatamente seguido pela função group_by()), as somas serão realizadas por grupos. Como dito acima, a função count() termina as suas ações realizando o desagrupamento dos dados. Assim, neste cenário, nós obtemos as proporções da coluna inteira, e não apenas dos grupos.
Para facilmente mostrar os percentuais, é possível incorporar a proporção gerada dentro da função percent(), do pacote scales (tenha em mente que isso converte a porcentagem para a classe character).
age_summary <- linelist %>%
count(age_cat) %>% # agrupe e conte por gênero (produz a coluna 'n'), finaliza desagrupando os dados
mutate( # cria a porcentagem da coluna - observe o denominador
percent = scales::percent(n / sum(n)))
# print
age_summary age_cat n percent
1 0-4 1095 18.60%
2 5-9 1095 18.60%
3 10-14 941 15.98%
4 15-19 743 12.62%
5 20-29 1073 18.22%
6 30-49 754 12.81%
7 50-69 95 1.61%
8 70+ 6 0.10%
9 <NA> 86 1.46%Abaixo, um método para calcular proporções dentro dos grupos é mostrado. Esta metodologia utiliza os diferentes níveis de agrupamento e desagrupamento de dados. Primeiro, os dados são agrupados de acordo com o outcome, utilizando a função group_by(). Então, a função count() é aplicada. Essa função realiza mais agrupamentos dos dados utilizando a variável age_cat, e gera contagens para cada combinação outcome-age-cat. Lembre-se que, ao finalizar o processo, a função count() também desagrupa os grupos age_cat. Assim, o único grupo de dados restante é o agrupamento inicial pelo outcome. Assim, a etapa final em que as proporções são calculadas (denominador sum(n)) é realizada com o grupo outcome.
age_by_outcome <- linelist %>% # inicie com os dados do linelist
group_by(outcome) %>% # agrupe por outcome
count(age_cat) %>% # agrupe e conte por age_cat, e então remova os grupos age_cat
mutate(percent = scales::percent(n / sum(n))) # calcule as porcentagem - repare que o denominador é o grupo outcomeVisualização dos dados
Utilizar a função ggplot() com os dados de uma tabela no formato “longo”, como a mostrada acima, é relativamente simples. Esses dados, no formato “longo”, são facilmente aceitos pelo ggplot(). Veja mais exemplos nas páginas básico do ggplot e dicas do ggplot.
linelist %>% # inicie com a linelist
count(age_cat, outcome) %>% # agrupe e tabule as contagens utilizando duas variáveis
ggplot()+ # utilize a tabulação gerada no ggplot
geom_col( # crie um gráfico de barras
mapping = aes(
x = outcome, # mapeie o grupo outcome para o eixo x
fill = age_cat, # mapeie o grupo age_cat para o fill
y = n)) # mapeie as contagens (coluna 'n') para o eixo y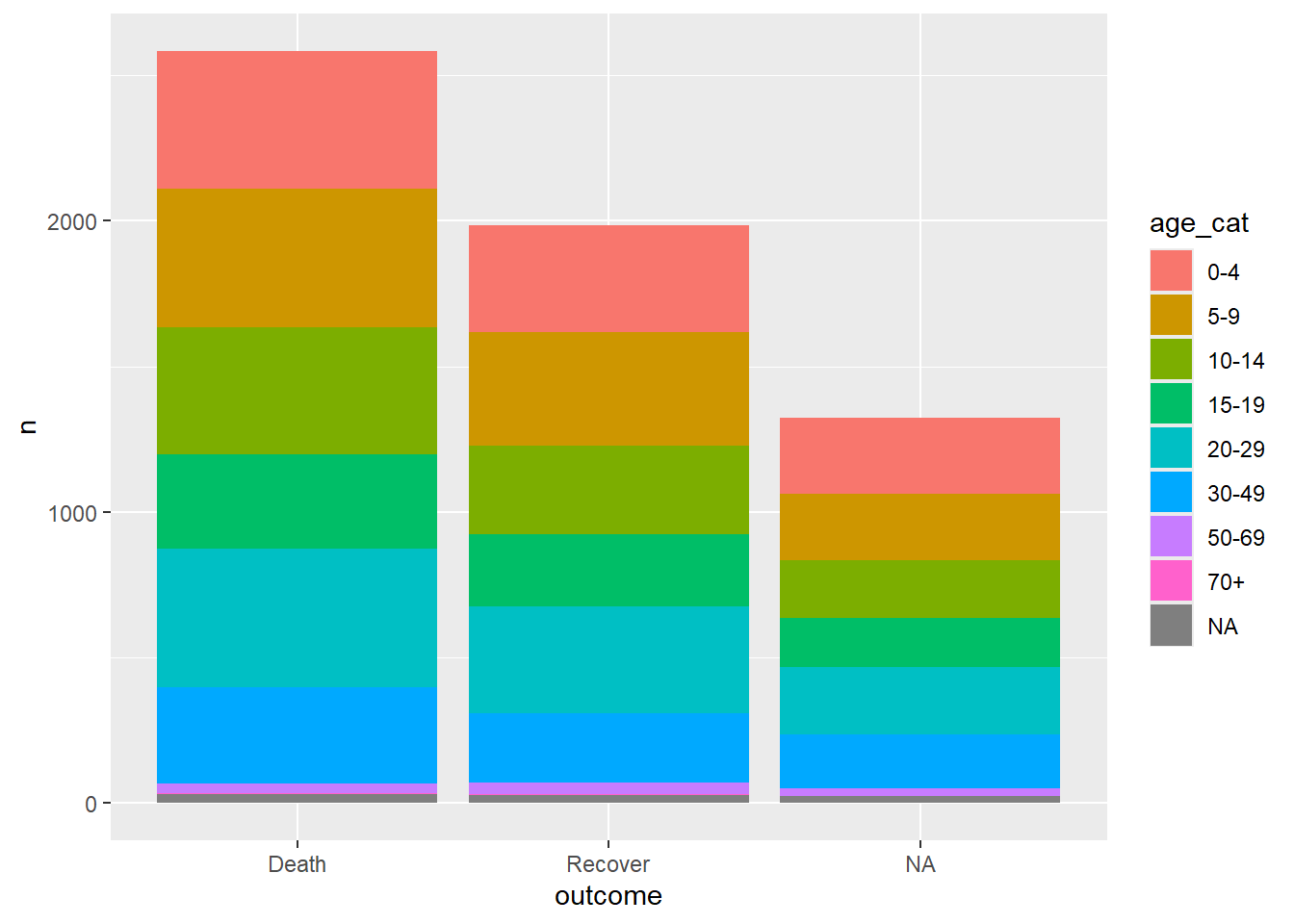
Resumo estatístico
Uma das principais vantagens do pacote dplyr e da função summarise() é a habilidade deles gerarem resumos estatísticos mais avançados, como median(), mean(), max(), min(), sd() (desvio padrão), e percentis. Você também pode utilizar a função sum() para contar o número de linhas que cumprem certos critérios lógicos. Como mostrado acima, essas informações podem ser obtidas com todo o banco de dados, ou por grupos.
A sintaxe é a mesma - dentro dos parênteses da função summarise(), você adiciona os nomes de cada nova coluna resumo, seguido pelos sinais de igual e a função estatística a ser realizada. Dentro da função estatística, escolha a(s) coluna(s) para serem utilizadas no cálculo, e qualquer outro argumento relevante (exemplo: na.rm = TRUE para boa parte das funções matemáticas).
Como dito acima, a função sum() também pode ser utilizada para obter o número de linhas que cumprem certos critérios lógicos. São contadas apenas as linhas que forem verdade (TRUE) para os critérios em parênteses. Por exemplo:
sum(age_years < 18, na.rm=T)
sum(gender == "male", na.rm=T)
sum(response %in% c("Likely", "Very Likely"))
Abaixo, os dados do linelist são analisados para avaliar os dias entre o início dos sintomas e a admissão no hospital (coluna days_onset_hosp), de acordo com o hospital.
summary_table <- linelist %>% # inicie com o linelist, salvando os novos dados como um novo objeto
group_by(hospital) %>% # agrupe todos os cálculos por hospital
summarise( # apenas as colunas abaixo serão geradas
cases = n(), # n° de casos por grupo
delay_max = max(days_onset_hosp, na.rm = T), # tempo máximo entre o ínicio dos sintomas e a admissão
delay_mean = round(mean(days_onset_hosp, na.rm=T), digits = 1), # tempo médio, arredondado
delay_sd = round(sd(days_onset_hosp, na.rm = T), digits = 1), # desvio padrão do intervalo de tempo, arredondado
delay_3 = sum(days_onset_hosp >= 3, na.rm = T), # n° de acsos com intervalo igual ou maior à 3 dias
pct_delay_3 = scales::percent(delay_3 / cases) # gera nova coluna convertendo o delay_3 em porcentagem
)
summary_table # exporte a tabela# A tibble: 6 × 7
hospital cases delay_max delay_mean delay_sd delay_3 pct_delay_3
<chr> <int> <dbl> <dbl> <dbl> <int> <chr>
1 Ausente 1469 22 2.1 2.3 399 27%
2 Central Hospital 454 12 1.9 1.9 108 24%
3 Military Hospital 896 15 2.1 2.4 253 28%
4 Other 885 18 2 2.2 234 26%
5 Port Hospital 1762 16 2.1 2.2 470 27%
6 St. Mark's Maternity … 422 18 2.1 2.3 116 27% Algumas dicas:
Use a função
sum()com uma expressão lógica para quantificar linhas que cumprem certos critérios (==)
Repare no uso do argumento
na.rm = TRUEdentro de funções matemáticas comosum(). Seu uso impede queNAseja gerado caso existam campos em branco
Use a função
percent(), do pacote scales, para facilmente obter as porcentagens- Escolha
accuracy =para 0.1 ou 0.01 para garantir 1 ou 2 vírgulas decimais, respectivamente
- Escolha
Use a função
round(), do pacote R base, para arredondar e especificar quantidade de casas decimais
Para obter dados estatísticos do banco de dados completo, utilize a função
summarise()sem a funçãogroup_by()
Você pode criar colunas para realizar cálculos futuros (ex.: como denominadores), que podem ser, posteriormente, retiradas da sua tabela de dados com a função
select().
Estatísticas condicionais
Você pode querer realizar análises estatísticas condicionais - por exemplo, a quantidade de linhas que cumprem certos critérios. Isto pode ser feito ao utilizar os colchetes [ ] para especificar os grupos desejados dentro de uma coluna. No código abaixo, a temperatura máxima dos pacientes com e sem febre é obtida. Entranto, neste caso, é melhor criar uma nova coluna utilizando as funções group_by() e pivot_wider() (como demonstrado abaixo).
linelist %>%
group_by(hospital) %>%
summarise(
max_temp_fvr = max(temp[fever == "yes"], na.rm = T),
max_temp_no = max(temp[fever == "no"], na.rm = T)
)# A tibble: 6 × 3
hospital max_temp_fvr max_temp_no
<chr> <dbl> <dbl>
1 Ausente 40.6 38
2 Central Hospital 40.4 38
3 Military Hospital 40.5 38
4 Other 40.8 37.9
5 Port Hospital 40.6 38
6 St. Mark's Maternity Hospital (SMMH) 40.6 37.9Unindo colunas
A função str_glue(), do pacote stringr, é útil para combinar valores de diferentes colunas em uma nova coluna. Geralmente, essa função é aplicada após utilizar a função summarise().
Na página sobre Caracteres e strings, várias opções para combinar colunas são discutidas, incluindo as funções unite() e paste0(). Entretanto, nós recomendamos a função str_glue() por ser mais flexível do que unite() e possuir uma sintaxe mais simples do que paste0().
Abaixo, a tabela summary_table (criada acima) é modificada de forma que as colunas delay_mean e delay_sd sejam combinadas. A nova coluna é gerada com os dados formatados utilizando parênteses, e as colunas utilizadas são removidas.
Então, para tornar a coluna mais apresentável, uma linha com os totais é adicionada com a função adorn_totals(), do pacote janitor (que ignora colunas não-numéricas). Finalmente, nós utilizamos a função select(), do pacote dplyr, para reordenar as colunas e renomeá-las como desejado.
Também é possível utilizar as funções do flextable para exportar a tabela para Word, .png, .jpeg, .html, Powerpoint, RMarkdown, etc.! (veja a página Tabelas para apresentações).
summary_table %>%
mutate(delay = str_glue("{delay_mean} ({delay_sd})")) %>% # crie uma nova coluna ao combinar e formatar valores de outras colunas
select(-c(delay_mean, delay_sd)) %>% # remova as duas colunas utilizadas
adorn_totals(where = "row") %>% # adiciona uma linha com os totais
select( # reorganize e renomeie as colunas
"Nome do Hospital" = hospital,
"Casos" = cases,
"Atraso máximo" = delay_max,
"Média (dp)" = delay,
"Atraso 3+ dias" = delay_3,
"% atrasos 3+ dias" = pct_delay_3
) Nome do Hospital Casos Atraso máximo Média (dp)
Ausente 1469 22 2.1 (2.3)
Central Hospital 454 12 1.9 (1.9)
Military Hospital 896 15 2.1 (2.4)
Other 885 18 2 (2.2)
Port Hospital 1762 16 2.1 (2.2)
St. Mark's Maternity Hospital (SMMH) 422 18 2.1 (2.3)
Total 5888 101 -
Atraso 3+ dias % atrasos 3+ dias
399 27%
108 24%
253 28%
234 26%
470 27%
116 27%
1580 -Percentis
O cálculo dos percentis e quantis no dplyr merece uma menção especial. Para obter os quantis, utilize a função quantile() com os intervalos padrões, ou especifique os valores alterando o atributo probs =.
# obtenha os percentis padrões da variável age (0%, 25%, 50%, 75%, 100%)
linelist %>%
summarise(age_percentiles = quantile(age_years, na.rm = TRUE))Warning: Returning more (or less) than 1 row per `summarise()` group was deprecated in
dplyr 1.1.0.
ℹ Please use `reframe()` instead.
ℹ When switching from `summarise()` to `reframe()`, remember that `reframe()`
always returns an ungrouped data frame and adjust accordingly. age_percentiles
1 0
2 6
3 13
4 23
5 84# obtenha os percentis em diferentes níveis da mesma variável (5%, 50%, 75%, 98%)
linelist %>%
summarise(
age_percentiles = quantile(
age_years,
probs = c(.05, 0.5, 0.75, 0.98),
na.rm=TRUE)
)Warning: Returning more (or less) than 1 row per `summarise()` group was deprecated in
dplyr 1.1.0.
ℹ Please use `reframe()` instead.
ℹ When switching from `summarise()` to `reframe()`, remember that `reframe()`
always returns an ungrouped data frame and adjust accordingly. age_percentiles
1 1
2 13
3 23
4 48Se você quiser obter os quantis por grupos, é mais viável utilizar a função group_by() e criar novas colunas, uma vez que isso irá gerar dados mais claros em relação ao método acima, onde seriam obtidos resultados longos e menos úteis. Desta forma, experimente essa abordagem: crie um coluna para cada nível de quantil desejado.
# obtenha os valores de percentis nos níveis desejados de acordo com a variável age (5%, 50%, 75%, 98%), agrupando os dados por hospital
linelist %>%
group_by(hospital) %>%
summarise(
p05 = quantile(age_years, probs = 0.05, na.rm=T),
p50 = quantile(age_years, probs = 0.5, na.rm=T),
p75 = quantile(age_years, probs = 0.75, na.rm=T),
p98 = quantile(age_years, probs = 0.98, na.rm=T)
)# A tibble: 6 × 5
hospital p05 p50 p75 p98
<chr> <dbl> <dbl> <dbl> <dbl>
1 Ausente 1 13 23 48.2
2 Central Hospital 1 12 21 48
3 Military Hospital 1 13 24 45
4 Other 1 13 23 50
5 Port Hospital 1 14 24 49
6 St. Mark's Maternity Hospital (SMMH) 2 12 22 50.2Enquanto a função summarise() do dplyr certamente possibilita mais controle das alterações, todos os resumos estatísticos de que precisa podem ser produzidos com a função get_summary_stat(), do pacote rstatix. Ao ser utilizado em dados agrupados, esta função vai retornar percentis de 0%, 25%, 50%, 75%, e 100%. Se utilizado em dados não agrupados, você pode especificar os percentis com o atributo probs = c(.05, .5, .75, .98).
linelist %>%
group_by(hospital) %>%
rstatix::get_summary_stats(age, type = "quantile")# A tibble: 6 × 8
hospital variable n `0%` `25%` `50%` `75%` `100%`
<chr> <fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Ausente age 1441 0 6 13 23 76
2 Central Hospital age 445 0 6 12 21 58
3 Military Hospital age 884 0 6 14 24 72
4 Other age 873 0 6 13 23 69
5 Port Hospital age 1739 0 6 14 24 68
6 St. Mark's Maternity Hospital (… age 420 0 7 12 22 84linelist %>%
rstatix::get_summary_stats(age, type = "quantile")# A tibble: 1 × 7
variable n `0%` `25%` `50%` `75%` `100%`
<fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 age 5802 0 6 13 23 84Obtenha um resumo dos dados agregados
Se você iniciar sua análise com dados agregados, ao utilizar a função n() você irá obter o número de linhas, não a soma das contagens agregadas. Para obter as somas, use a função sum() na coluna de contagens.
Por exemplo, suponha que você está iniciando com a tabela de contagens abaixo, chamada linelist_agg - ela mostra no formato “longo” as contagens do número de casos por outcome e gender.
Para fins de exemplificação, abaixo, nós criamos uma tabela de dados com a quantidade de casos por outcome e gender dos dados do linelist (campos em branco foram removidos para facilitar o entendimento).
linelist_agg <- linelist %>%
drop_na(gender, outcome) %>%
count(outcome, gender)
linelist_agg outcome gender n
1 Death f 1227
2 Death m 1228
3 Recover f 953
4 Recover m 950Para somar as contagens (da coluna n) por grupo, você pode usar a função summarise() e ajustar a nova coluna para ser igual à sum(n, na.rm=T). Para adicionar um elemento condicional à essa operação, você pode selecionar, na coluna de contagem (n), uma parte dos dados utilizando os colchetes [ ].
linelist_agg %>%
group_by(outcome) %>%
summarise(
total_cases = sum(n, na.rm=T),
male_cases = sum(n[gender == "m"], na.rm=T),
female_cases = sum(n[gender == "f"], na.rm=T))# A tibble: 2 × 4
outcome total_cases male_cases female_cases
<chr> <int> <int> <int>
1 Death 2455 1228 1227
2 Recover 1903 950 953across() em mais de uma coluna
Você pode utilizar a função summarise() em mais de uma coluna utilizado a função across(). Isto torna o trabalho mais fácil quando você quer obter a mesma estatística de muitas colunas. Coloque across() dentro de summarise() e especifique o seguinte:
.cols =vetor com o nome das colunasc()ou funções auxiliares do “tidyselect” (explicado abaixo)
.fns =a função a ser aplicada (sem parênteses) - você pode fornecer múltiplas funções dentro de umalist()
Abaixo, a função mean() é aplicada para diferentes colunas numéricas. Um vetor com as colunas é dado explicitamente para o atributo .cols = e uma função simples (mean) é especificada (sem parênteses) em .fns =. Quaisquer argumentos adicionais para a função (por ex.: na.rm=TRUE) são colocados após .fns =, separados por uma vírgula.
Pode ser difícil acertar a ordem dos parênteses e vírgulas ao utilizar across(). Lembre que, dentro do across(), você deve incluir as colunas, as funções, e qualquer argumento extra que seja necessário para as funções.
linelist %>%
group_by(outcome) %>%
summarise(across(.cols = c(age_years, temp, wt_kg, ht_cm), # colunas utilizadas
.fns = mean, # função aplicada
na.rm=T)) # argumentos extrasWarning: There was 1 warning in `summarise()`.
ℹ In argument: `across(...)`.
ℹ In group 1: `outcome = "Death"`.
Caused by warning:
! The `...` argument of `across()` is deprecated as of dplyr 1.1.0.
Supply arguments directly to `.fns` through an anonymous function instead.
# Previously
across(a:b, mean, na.rm = TRUE)
# Now
across(a:b, \(x) mean(x, na.rm = TRUE))# A tibble: 3 × 5
outcome age_years temp wt_kg ht_cm
<chr> <dbl> <dbl> <dbl> <dbl>
1 Death 15.9 38.6 52.6 125.
2 Recover 16.1 38.6 52.5 125.
3 <NA> 16.2 38.6 53.0 125.Funções múltiplas podem ser executadas de uma vez. Abaixo, o atributo .fns = recebe as funções mean e sd dentro de uma list(). Você tem a oportunidade de escolher nomes das características (ex.: “mean” e “sd”) que serão colocadas inseridas ao nome das novas colunas.
linelist %>%
group_by(outcome) %>%
summarise(across(.cols = c(age_years, temp, wt_kg, ht_cm), # colunas
.fns = list("mean" = mean, "sd" = sd), # múltiplas funções
na.rm=T)) # argumentos extras# A tibble: 3 × 9
outcome age_years_mean age_years_sd temp_mean temp_sd wt_kg_mean wt_kg_sd
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Death 15.9 12.3 38.6 0.962 52.6 18.4
2 Recover 16.1 13.0 38.6 0.997 52.5 18.6
3 <NA> 16.2 12.8 38.6 0.976 53.0 18.9
# ℹ 2 more variables: ht_cm_mean <dbl>, ht_cm_sd <dbl>Aqui são as funções auxiliares “tidyselect”, que você pode utilizar em .cols = para selecionar colunas:
everything()- todas as outras colunas não mencionadas
last_col()- a última coluna
where()- aplica uma função à todas as colunas, e seleciona apenas aquelas que são verdadeiras (TRUE)
starts_with()- seleciona colunas cujos nomes iniciam com determinado prefixo. Exemplo:starts_with("date")ends_with()- seleciona colunas cujos normes terminam com determinado sufixo. Exemplo:ends_with("_end")
contains()- colunas que contêm determinada sequência de caracteres. Exemplo:contains("time")matches()- aplica a sintaxe de uma expressão regular (regex). Exemplo:contains("[pt]al")
num_range()-any_of()- seleciona colunas com certos nomes. Útil caso o nome buscado não exista. Exemplo:any_of(date_onset, date_death, cardiac_arrest)
Por exemplo, para obter a média de cada coluna numérica, use a função where() e aplique a função as.numeric() (sem os parêntesese) para escolher as colunas numéricas, e então obtenha a média com mean. Tudo isso dentro da função across().
linelist %>%
group_by(outcome) %>%
summarise(across(
.cols = where(is.numeric), # all numeric columns in the data frame
.fns = mean,
na.rm=T))# A tibble: 3 × 12
outcome generation age age_years lon lat wt_kg ht_cm ct_blood temp
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Death 16.7 15.9 15.9 -13.2 8.47 52.6 125. 21.3 38.6
2 Recover 16.4 16.2 16.1 -13.2 8.47 52.5 125. 21.1 38.6
3 <NA> 16.5 16.3 16.2 -13.2 8.47 53.0 125. 21.2 38.6
# ℹ 2 more variables: bmi <dbl>, days_onset_hosp <dbl>Utilizando o pivot_wider()
Se você preferir sua tabela no formato “largo”, você pode transformar ela utilizando a função pivot_wider(), do pacote tidyr. Você provavelmente precisará renomear as colunas com a função rename(). Para mais informações, veja a página sobre Pivoteando os dados.
O exemplo abaixo utiliza a tabela age_by_outcome com formato “longo”, da seção de proporções. Para faciliar o entendimento, nós criamos essa tabela novamente, e mostramos como é seu formato “longo”:
age_by_outcome <- linelist %>% # inicie com o linelist
group_by(outcome) %>% # agrupe por outcome
count(age_cat) %>% # agrupe e conte por age_cat, e então remova o agrupamento age_cat
mutate(percent = scales::percent(n / sum(n))) # calcule a porcentagem - observe que o denominador é o grupo outcomePara realizar o pivoteamento para a tabela criada fique no formato “largo”, nós criamos as novas colunas a partir dos valores na coluna existente age_cat (ao configurar names_from = age_cat). Nós também especificamos que os valores da nova tabela virão da coluna existente n, utilizando o atributo values_from = n. As colunas não mencionadas no nosso comando de pivoteamento (outcome) continuarão sem alterações na extremidade esquerda da tabela final.
age_by_outcome %>%
select(-percent) %>% # para não complicar, mantenha apenas as contagens
pivot_wider(names_from = age_cat, values_from = n) # A tibble: 3 × 10
# Groups: outcome [3]
outcome `0-4` `5-9` `10-14` `15-19` `20-29` `30-49` `50-69` `70+` `NA`
<chr> <int> <int> <int> <int> <int> <int> <int> <int> <int>
1 Death 471 476 438 323 477 329 33 3 32
2 Recover 364 391 303 251 367 238 38 3 28
3 <NA> 260 228 200 169 229 187 24 NA 26Adicionando as linhas com os totais
Quando a função summarise() é utilizada em dados agrupados, a linha com os “totais” não é produzida automaticamente. Abaixo, duas abordagens para adicionar esta linha são mostrados:
Função adorn_totals() do pacote janitor
Se sua tabela contém apenas contagens ou proporções/porcentagens, que podem ser somados para obter os totais, então é possível realizar essa soma utilizando a função adorn_totals(), do pacote janitor, como descrito na seção acima. Observe que esta função consegue somar apenas as colunas numéricas - se você quiser calcular outros resumos estatísticos, veja a próxima abordagem com o pacote dplyr.
Abaixo, os dados do linelist são agrupados por gênero e resumidos em uma tabela que descreve o número de casos com evolução conhecida (outcome), mortes (deaths) ou recuperados (recovered). Ao canalizar a tabela para a função adorn_totals(), uma linha com os totais é adicionada no final para refletir a soma de cada coluna. As próximas funções adorn_*() ajustam o design, como comentado no código.
linelist %>%
group_by(gender) %>%
summarise(
known_outcome = sum(!is.na(outcome)), # N° de linhas em que o outcome não é desconhecido
n_death = sum(outcome == "Death", na.rm=T), # N° de linhas em que o outcome é Death
n_recover = sum(outcome == "Recover", na.rm=T), # N° de linhas em que o outcome é Recovered
) %>%
adorn_totals() %>% # Adiciona a linha 'total' (soma de cada coluna numérica)
adorn_percentages("col") %>% # Obtenha as proporções
adorn_pct_formatting() %>% # Converta as proporções para porcentagens
adorn_ns(position = "front") # mostra % e n° absolutos juntos (com n° absoluto na frente) gender known_outcome n_death n_recover
f 2,180 (47.8%) 1,227 (47.5%) 953 (48.1%)
m 2,178 (47.7%) 1,228 (47.6%) 950 (47.9%)
<NA> 207 (4.5%) 127 (4.9%) 80 (4.0%)
Total 4,565 (100.0%) 2,582 (100.0%) 1,983 (100.0%)Uso da função summarise() nos dados “totais” seguido por bind_rows()
Se sua tabela consistir for feita de resumos estatísticos como median(), mean(), etc, a funçãoadorn_totals() utilizada acima não será suficiente. Assim, para obter o resumo estatístico de todo o banco de dados, você precisa calcular eles com uma função summarise() separada e, então, conectar os resultados à tabela resumo inicial. Para fazer essa conexão, você pode usar a função bind_rows(), do pacote dplyr, descrito na página Agrupando dados. Abaixo está um exemplo:
Você pode criar uma tabela resumo com os resultados da intersecção por hospital, com as funções group_by() e summarise() da seguinte forma:
by_hospital <- linelist %>%
filter(!is.na(outcome) & hospital != "Missing") %>% # Remova os casos sem resultado (outcome) ou nome do hospital
group_by(hospital, outcome) %>% # Agrupe os dados
summarise( # Crie um novo resumo com as colunas com os indicadores de interesse
N = n(), # N° de linhas por grupo hospital-outcome
ct_value = median(ct_blood, na.rm=T)) # Obtenha a média dos valores CT por grupo
by_hospital # exporte a tabela# A tibble: 12 × 4
# Groups: hospital [6]
hospital outcome N ct_value
<chr> <chr> <int> <dbl>
1 Ausente Death 611 21
2 Ausente Recover 514 21
3 Central Hospital Death 193 22
4 Central Hospital Recover 165 22
5 Military Hospital Death 399 21
6 Military Hospital Recover 309 22
7 Other Death 395 22
8 Other Recover 290 21
9 Port Hospital Death 785 22
10 Port Hospital Recover 579 21
11 St. Mark's Maternity Hospital (SMMH) Death 199 22
12 St. Mark's Maternity Hospital (SMMH) Recover 126 22Para obter os totais, execute a mesma função summarise(), mas com os dados agrupados apenas por outcome (não por hospital), da seguinte forma:
totals <- linelist %>%
filter(!is.na(outcome) & hospital != "Missing") %>%
group_by(outcome) %>% # Agrupado apenas por outcome, não por hospital
summarise(
N = n(), # Essas estatísticas são apenas por outcome
ct_value = median(ct_blood, na.rm=T))
totals # exporte a tabela gerada# A tibble: 2 × 3
outcome N ct_value
<chr> <int> <dbl>
1 Death 2582 22
2 Recover 1983 21Agora, nós podemos unir as duas tabelas geradas. Observe que a tabela by_hospital tem 4 colunas, enquanto a tabela totals tem 3 colunas. Ao utilizar a função bind_rows(), as colunas são combinadas por nome, onde cada espaço extra (linhas a mais) são preenchidos com NA (ex.: na coluna hospital os campos das duas novas linhas de totals). Após unir as linhas, nós iremos converter esses espaços em branco para “Total” utilizando a função replace_na() (veja a página Limpando os dados e funções essenciais).
table_long <- bind_rows(by_hospital, totals) %>%
mutate(hospital = replace_na(hospital, "Total"))Aqui está a nova tabela com as linhas “Total” no final.
Esta tabela está no formato “longo/comprido”, que pode ser o desejado. Opcionalmente, você pode mudar essa tabela para o formato largo, de forma a torná-la mais fácil de interpretar. Veja a seção acima sobre como transformar a tabela para o formato “largo”, ou na página Pivoteando dados. Você também pode adicionar mais colunas, e ajustá-las de forma que considere mais agradável. Segue o código:
table_long %>%
# Muda para o formato amplo e formata a tabela
########################
mutate(hospital = replace_na(hospital, "Total")) %>%
pivot_wider( # Mude de "longo" para "largo"
values_from = c(ct_value, N), # novos valores provenientes das colunas ct e de contagen (n)
names_from = outcome) %>% # novos nomes das colunas proveniente dos outcomes
mutate( # adiciona novas colunas
N_Known = N_Death + N_Recover, # casos com evolução (outcome) conhecido
Pct_Death = scales::percent(N_Death / N_Known, 0.1), # percentual de casos que evoluíram para óbito (até 1ª casa decimal)
Pct_Recover = scales::percent(N_Recover / N_Known, 0.1)) %>% # percentual de casos que recuperaram (até a 1ª casa decimal)
select( # Reordena as colunas
hospital, N_Known, # Coluna introdutórias
N_Recover, Pct_Recover, ct_value_Recover, # Colunas dos recuperados
N_Death, Pct_Death, ct_value_Death) %>% # Colunas de óbitos
arrange(N_Known) # Organize as linhas do menor para o maior (linha com totais por último)# A tibble: 7 × 8
# Groups: hospital [7]
hospital N_Known N_Recover Pct_Recover ct_value_Recover N_Death Pct_Death
<chr> <int> <int> <chr> <dbl> <int> <chr>
1 St. Mark's M… 325 126 38.8% 22 199 61.2%
2 Central Hosp… 358 165 46.1% 22 193 53.9%
3 Other 685 290 42.3% 21 395 57.7%
4 Military Hos… 708 309 43.6% 22 399 56.4%
5 Ausente 1125 514 45.7% 21 611 54.3%
6 Port Hospital 1364 579 42.4% 21 785 57.6%
7 Total 4565 1983 43.4% 21 2582 56.6%
# ℹ 1 more variable: ct_value_Death <dbl>Após isso, você pode exportar essa tabela como uma imagem - abaixo, o resultado é exportado com o pacote flextable. Para mais detalhes sobre esse exemplo, e sobre como produzir uma imagem dessa forma, leia a página Tabelas para apresentações.
Hospital | Total cases with known outcome | Recovered | Died | ||||
|---|---|---|---|---|---|---|---|
Total | % of cases | Median CT values | Total | % of cases | Median CT values | ||
St. Mark's Maternity Hospital (SMMH) | 325 | 126 | 38.8% | 22 | 199 | 61.2% | 22 |
Central Hospital | 358 | 165 | 46.1% | 22 | 193 | 53.9% | 22 |
Other | 685 | 290 | 42.3% | 21 | 395 | 57.7% | 22 |
Military Hospital | 708 | 309 | 43.6% | 22 | 399 | 56.4% | 21 |
Ausente | 1,125 | 514 | 45.7% | 21 | 611 | 54.3% | 21 |
Port Hospital | 1,364 | 579 | 42.4% | 21 | 785 | 57.6% | 22 |
Total | 4,565 | 1,983 | 43.4% | 21 | 2,582 | 56.6% | 22 |
17.5 Pacote gtsummary
Se você quer exportar seu resumo estatístico em um gráfico ‘bonito’, pronto para publicação, você pode usar o pacote gtsummary e sua função tbl_summary(). Em um primeiro momento, o código pode parecer complexo, mas as tabelas geradas são lindas e exportadas para o seu painel do RStudio Viewer como uma imagem HTML. Veja um tutorial mais detalhado aqui.
Você também pode adicionar os resultados dos testes estatísticos nas tabelas geradas pelo gtsummary. Este processo está decrito na seção do gtsummary, da página testes estatísticos simples.
Para introduzir a função tbl_summary(), nós vamos primeiro demostrar seu funcionamento básico, que produz uma tabela bonita e extensa. Então, examinaremos em detalhes como fazer ajustes finos e tabelas mais customizadas.
Tabela resumo
O comportamento padrão do tbl_summary() é incrível - ele utiliza as colunas fornecidas e cria uma tabela resumo em apenas um comando. Esta função realiza as estatísticas apropriadas de acordo com a classe da coluna: média e intervalo interquartil (IQR) para colunas numéricas, e contagens (%) para colunas categóricas. Valores em branco são convertidos para “Unknown”. Notas de rodapé são adicionadas para explicar as estatísticas utilizadas, enquanto a quantidade total N é mostrada no topo.
# Use a função abaixo para que a tabela saia em portugês
theme_gtsummary_language("pt")
linelist %>%
select(age_years, gender, outcome, fever, temp, hospital) %>% # mantenha apenas as colunas de interesse
tbl_summary() # função no modo padrão| Características | N = 5,8881 |
|---|---|
| age_years | 13 (6, 23) |
| Desconhecido | 86 |
| gender | |
| f | 2,807 (50%) |
| m | 2,803 (50%) |
| Desconhecido | 278 |
| outcome | |
| Death | 2,582 (57%) |
| Recover | 1,983 (43%) |
| Desconhecido | 1,323 |
| fever | 4,549 (81%) |
| Desconhecido | 249 |
| temp | 38.80 (38.20, 39.20) |
| Desconhecido | 149 |
| hospital | |
| Ausente | 1,469 (25%) |
| Central Hospital | 454 (7.7%) |
| Military Hospital | 896 (15%) |
| Other | 885 (15%) |
| Port Hospital | 1,762 (30%) |
| St. Mark's Maternity Hospital (SMMH) | 422 (7.2%) |
| 1 Mediana (AIQ); n (%) | |
Ajustes
Agora iremos explicar como esta função funciona e como fazer ajustes. Os argumentos chave estão detalhados abaixo:
by =
Você pode estratificar a sua tabela utilizando uma coluna (ex.: outcome), ao criar uma tabela de duas vias.
statistic =
Use as equações para especificar quais estatísticas mostrar e como mostrá-las. Existem dois lados para essa equação, separados por um til ~. Do lado direito, entre aspas, é colocado o teste estatístico desejado, e no lado esquerdo são colocadas as colunas em que esse teste será aplicado.
- O lado direito da equação utiliza a sintaxe da função
str_glue(), do pacote stringr (veja mais em Caractéres e Strings), com o texto a ser mostrado entre aspas e o teste estatístico dentro de colchetes encaracolados{ }. Você pode incluir estatísticas como “n” (para contagens), “N” (para denominador), “mean” (média), “median” (mediana), “sd” (desvio padrão), “max” (valor máximo), “min” (valor mínimo), percentis “p##” como “p25”, ou percentual do total como “p”. Utilize o comando?tbl_summarypara mais detalhes.
- No lado esquerdo da equação, você pode especificar colunas por nome (ex.:
ageouc(age, gender)) ou utilizando funções auxiliares comoall_continuous(),all_categorical(),contains(),starts_with(), etc.
Uma exemplo simples da equação statistic = é mostrado abaixo, onde apenas a média da coluna age_years é obtida:
linelist %>%
select(age_years) %>% # mantenha apenas as colunas de interesse
tbl_summary( # crie uma tabela resumo
statistic = age_years ~ "{mean}") # calcule a média de idades (age)| Características | N = 5,8881 |
|---|---|
| age_years | 16 |
| Desconhecido | 86 |
| 1 Média | |
Uma equação um pouco mais complexa é obtida "({min}, {max})", incorporando os valores mínimos e máximos dentro de parênteses e separados por vírgula:
linelist %>%
select(age_years) %>% # mantenha apenas as colunas de interesse
tbl_summary( # crie uma tabela resumo
statistic = age_years ~ "({min}, {max})") # calcule o min e max da idade (age)| Características | N = 5,8881 |
|---|---|
| age_years | (0, 84) |
| Desconhecido | 86 |
| 1 (Amplitude) | |
Você também pode utilizar uma sintaxe diferente para colunas distintas ou diferentes tipos de colunas. Em um exemplo mais complexo, mostrado abaixo, o argumento dado à statistic = é uma list (list) indicando que para todas as colunas com valores contínuos, a tabela deve gerar a média com o desvio padrão em parênteses, enquanto que, para colunas categóricas, ela deve gerar o n, o denominador, e o percentual.
digits =
Ajuste a quantidade de dígitos e de arredondamento. Opcionalmente, isto pode ser limitado à colunas contínuas apenas (como mostrado abaixo).
label =
Ajuste como o rótulo da coluna deve ser mostrado. Forneça o nome da coluna e o rótulo desejado, separado por um til ~. O padrão do rótulo é o nome da coluna.
missing_text =
Ajuste como os campos em branco são mostrados. A opção padrão é “Unknown”.
type =
Isto é utilizado para ajustar quantos níveis das estatísticas são mostradas. A sintaxe é similar ao atributo statistic =, pois você fornece uma equação com colunas no lado esquerdo, e um valor no lado direito. Dois cenários comuns incluem:
type = all_categorical() ~ "categorical"Força colunas dicotômicas (ex.:feversim/não) a mostrar todos os níveis em vez de apenas a linha “sim”
type = all_continuous() ~ "continuous2"Permite a realização de estatísticas em múltiplas linha (“multi-line”) por variável, como mostrado em seção posterior
No exemplo abaixo, cada um desses argumentos é utilizado para modificar a tabela resumo original:
linelist %>%
select(age_years, gender, outcome, fever, temp, hospital) %>% # utilize apenas as colunas de interesse
tbl_summary(
by = outcome, # estratifique a tabela inteira pelo outcome
statistic = list(all_continuous() ~ "{mean} ({sd})", # estatísticas e formatação para colunas contínuas
all_categorical() ~ "{n} / {N} ({p}%)"), # estatísticas e formatação para colunas categóricas
digits = all_continuous() ~ 1, # arredondamento para colunas contínuas
type = all_categorical() ~ "categorical", # force todos os níveis de colunas categóricas a serem mostrados
label = list( # mostre etiquetas de acordo com o nome das colunas
outcome ~ "Outcome",
age_years ~ "Age (years)",
gender ~ "Gender",
temp ~ "Temperature",
hospital ~ "Hospital"),
missing_text = "Missing" # como valores em branco devem ser mostrados
)1323 observations missing `outcome` have been removed. To include these observations, use `forcats::fct_na_value_to_level()` on `outcome` column before passing to `tbl_summary()`.| Características | Death, N = 2,5821 | Recover, N = 1,9831 |
|---|---|---|
| Age (years) | 15.9 (12.3) | 16.1 (13.0) |
| Missing | 32 | 28 |
| Gender | ||
| f | 1,227 / 2,455 (50%) | 953 / 1,903 (50%) |
| m | 1,228 / 2,455 (50%) | 950 / 1,903 (50%) |
| Missing | 127 | 80 |
| fever | ||
| no | 458 / 2,460 (19%) | 361 / 1,904 (19%) |
| yes | 2,002 / 2,460 (81%) | 1,543 / 1,904 (81%) |
| Missing | 122 | 79 |
| Temperature | 38.6 (1.0) | 38.6 (1.0) |
| Missing | 60 | 55 |
| Hospital | ||
| Ausente | 611 / 2,582 (24%) | 514 / 1,983 (26%) |
| Central Hospital | 193 / 2,582 (7.5%) | 165 / 1,983 (8.3%) |
| Military Hospital | 399 / 2,582 (15%) | 309 / 1,983 (16%) |
| Other | 395 / 2,582 (15%) | 290 / 1,983 (15%) |
| Port Hospital | 785 / 2,582 (30%) | 579 / 1,983 (29%) |
| St. Mark's Maternity Hospital (SMMH) | 199 / 2,582 (7.7%) | 126 / 1,983 (6.4%) |
| 1 Média (Desvio Padrão); n / N (%) | ||
Estatísticas de múltiplas linhas (“multi-line”) para variáveis contínuas
Se você quiser obter múltiplas linhas de estatísticas para variáveis contínuas, é possível indicar isto ao ajustar o atributo type = para “continuous2”. É possível combinar todos os elementos mostrados anteriormente em uma tabela, ao escolher quais estatísticas quer mostrar. Para fazer isso, é necessário ‘dizer’ para a função que você quer a tabela de volta ao inserir seu tipo como “continous2”. A quantidade de campos em braco é mostrado como “Unknown”.
linelist %>%
select(age_years, temp) %>% # mantenha apenas colunas de interesse
tbl_summary( # crie tabelas resumo
type = all_continuous() ~ "continuous2", # indique que você quer obter mais de uma estatística
statistic = all_continuous() ~ c(
"{mean} ({sd})", # linha 1: média e desvio padrão
"{median} ({p25}, {p75})", # linha 2: média e IQR
"{min}, {max}") # linha 3: min e max
)| Características | N = 5,888 |
|---|---|
| age_years | |
| Média (Desvio Padrão) | 16 (13) |
| Mediana (AIQ) | 13 (6, 23) |
| Amplitude | 0, 84 |
| Desconhecido | 86 |
| temp | |
| Média (Desvio Padrão) | 38.56 (0.98) |
| Mediana (AIQ) | 38.80 (38.20, 39.20) |
| Amplitude | 35.20, 40.80 |
| Desconhecido | 149 |
Existem diversas formas de modificar essas tabelas, como adicionar valores do p, ajustar cores e títulos, etc. Muitas destas modificações estão descritas na documentação (digite ?tbl_summary no Console), e algumas destas são mostradas na seção sobre testes estatísticos.
17.6 Pacote R base
Você pode usar a função table() para tabular e realizar tabulações cruzadas das colunas. Diferente das opções acima, você precisa especificar o quadro de dados cada vez que o nome de uma coluna é apontado, como mostrado abaixo.
CUIDADO: NA valores em branco não serão tabulados a não ser que você coloque o argumento useNA = "always" (que também pode ser ajustado para “no” ou “ifany”).
DICA: É possível usar o %$% do pacote magrittr para remover a necessidade de repetir a quantidade de vezes que o quadro de dados é chamado dentro das funções do pacote R base. Por exemplo, o código abaixo poderia ser reescrito como linelist %$% table(outcome, useNA = "always")
table(linelist$outcome, useNA = "always")
Death Recover <NA>
2582 1983 1323 Múltiplas colunas podem ser utilizadas para tabulação cruzada ao listá-las uma após a outra, separadas por vírgulas. Opcionalmente, você pode dar um “nome” a cada coluna, como em Outcome = linelist$outcome.
age_by_outcome <- table(linelist$age_cat, linelist$outcome, useNA = "always") # salve a tabela como objeto
age_by_outcome # exporte a tabela
Death Recover <NA>
0-4 471 364 260
5-9 476 391 228
10-14 438 303 200
15-19 323 251 169
20-29 477 367 229
30-49 329 238 187
50-69 33 38 24
70+ 3 3 0
<NA> 32 28 26Proporções
Para obter proporções, utilize a tabela acima na função prop.table(). Use o argumento margins = para especificar caso você queira que as proporções sejam calculadas das linhas (1), colunas (2), ou da tabela inteira (3). No código abaixo, encadeamos (“piped”) a tabela com a função round(), do R base, especificando 2 dígitos.
# obtenhas as proporções da tabela definida acima, por linhas, arredondado
prop.table(age_by_outcome, 1) %>% round(2)
Death Recover <NA>
0-4 0.43 0.33 0.24
5-9 0.43 0.36 0.21
10-14 0.47 0.32 0.21
15-19 0.43 0.34 0.23
20-29 0.44 0.34 0.21
30-49 0.44 0.32 0.25
50-69 0.35 0.40 0.25
70+ 0.50 0.50 0.00
<NA> 0.37 0.33 0.30Totais
Para adicionar colunas e linhas com totais, passe a tabela gerada para a função addmargins(). Isto funciona para contagens e proporções.
addmargins(age_by_outcome)
Death Recover <NA> Sum
0-4 471 364 260 1095
5-9 476 391 228 1095
10-14 438 303 200 941
15-19 323 251 169 743
20-29 477 367 229 1073
30-49 329 238 187 754
50-69 33 38 24 95
70+ 3 3 0 6
<NA> 32 28 26 86
Sum 2582 1983 1323 5888Converta para um quadro de dados
Converter um objeto table() diretamente para um quadro de dado (data frame)s não é simples. Uma possível abordagem é mostrada abaixo:
- Crie a tabela, sem utilizar
useNA = "always". Em vez disso, converta os valoresNApara “(Missing)” com a funçãofct_explicit_na(), do pacote forcats.
- Adicione os totais (opcional) ao aplicar a tabela na função
addmargins()
- Utilize a tabela na função do R base
as.data.frame.matrix()
- Transforme a tabela utilizando a função do pacote tibble,
rownames_to_column(), especificando o nome da primeira coluna
- Exporte, Visualize, ou exporte como desejado. Neste exemplo, nós utilizamos a função
flextable(), do pacote flextable, como descrito na página Tabelas para apresentação. Isto irá exportar a tabela para o RStudio viewer como uma linda imagem HTML.
table(fct_explicit_na(linelist$age_cat), fct_explicit_na(linelist$outcome)) %>%
addmargins() %>%
as.data.frame.matrix() %>%
tibble::rownames_to_column(var = "Age Category") %>%
flextable::flextable()Age Category | Death | Recover | (Missing) | Sum |
|---|---|---|---|---|
0-4 | 471 | 364 | 260 | 1,095 |
5-9 | 476 | 391 | 228 | 1,095 |
10-14 | 438 | 303 | 200 | 941 |
15-19 | 323 | 251 | 169 | 743 |
20-29 | 477 | 367 | 229 | 1,073 |
30-49 | 329 | 238 | 187 | 754 |
50-69 | 33 | 38 | 24 | 95 |
70+ | 3 | 3 | 0 | 6 |
(Missing) | 32 | 28 | 26 | 86 |
Sum | 2,582 | 1,983 | 1,323 | 5,888 |
17.7 Recursos extras
Muitas das informações desta página foram adaptadas destes recursos e tutoriais online: