As pirâmides demográficas são úteis para mostrar as distribuições de idade e sexo. Um código semelhante pode ser usado para visualizar os resultados de perguntas de pesquisa do tipo Likert (por exemplo “Concordo plenamente”, “Concordo”, “Neutro”, “Discordo”, “Discordo totalmente”). Nesta página, cobrimos o seguinte:
ggplot()Este pedaço de código mostra o carregamento de pacotes necessários para as análises. Neste manual, enfatizamos p_load() de pacman, que instala o pacote se necessário e o carrega para uso. Você também pode carregar pacotes instalados com library() de R base. Veja a página em Introdução ao R para mais informações sobre pacotes R.
pacman::p_load(rio, # para importar dados
here, # para localizar arquivos
tidyverse, # para limpar, manipular e plotar os dados (inclui o pacote ggplot2)
apyramid, # um pacote dedicado à criação de pirâmides de idades
janitor, # tabelas e dados de limpeza
stringr) # trabalhando com strings para títulos, legendas, etc.Para começar, importamos a lista (linelist) limpa de casos de uma simulação de epidemia de Ebola. Se você quiser acompanhar, clique para baixar o linelist “clean” (como um arquivo .rds). Importe dados com a função import() do pacote rio (ele lida com muitos tipos de arquivo como .xlsx, .csv, .rds - veja a página Importar e exportar para detalhes).
# import case linelist
linelist <- import("linelist_cleaned.rds")As primeiras 50 linhas da linelist são exibidas abaixo.
Para fazer uma pirâmide demográfica tradicional de idade / sexo, os dados devem primeiro ser limpos das seguintes maneiras:
Se estiver usando categorias de idade, os valores da coluna devem ser corrigidos em ordem, seja alfanumérico padrão ou definido intencionalmente pela conversão para o fator de classe.
Abaixo, usamos tabyl() de janitor para inspecionar as colunas gender e age_cat5.
linelist %>%
tabyl(age_cat5, gender) age_cat5 f m NA_
0-4 640 416 39
5-9 641 412 42
10-14 518 383 40
15-19 359 364 20
20-24 305 316 17
25-29 163 259 13
30-34 104 213 9
35-39 42 157 3
40-44 25 107 1
45-49 8 80 5
50-54 2 37 1
55-59 0 30 0
60-64 0 12 0
65-69 0 12 1
70-74 0 4 0
75-79 0 0 1
80-84 0 1 0
85+ 0 0 0
<NA> 0 0 86Também executamos um histograma rápido na coluna idade para garantir que esteja limpo e classificado corretamente:
hist(linelist$age)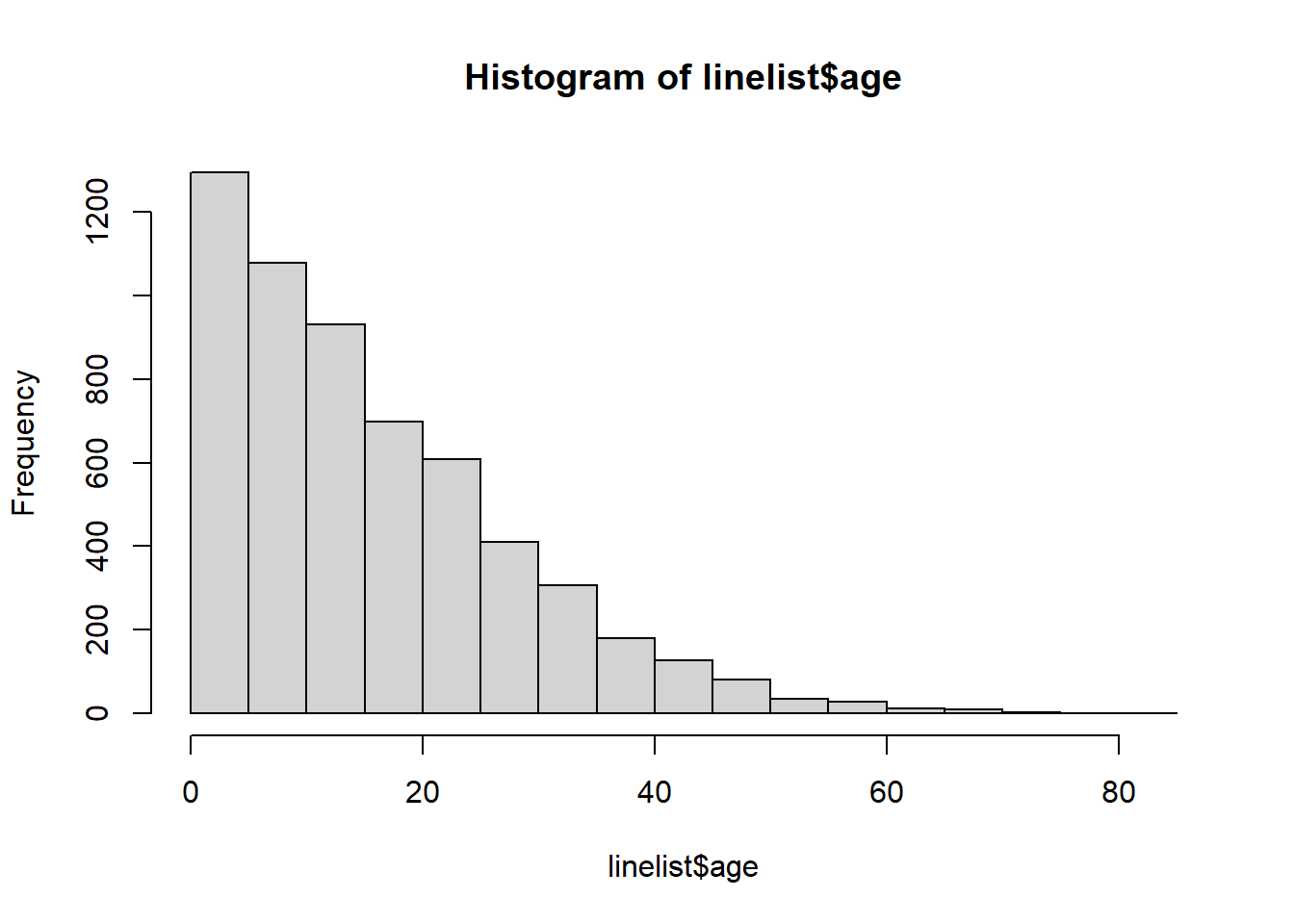
O pacote apyramid é um produto do projeto R4Epis. Você pode ler mais sobre este pacote aqui. Ele permite que você crie rapidamente uma pirâmide de idades. Para situações mais sutis, veja a seção abaixo usando ggplot(). Você pode ler mais sobre o pacote apyramid em sua página de Ajuda inserindo ?Age_pyramid em seu console R.
Usando o conjunto de dados linelist limpo, podemos criar uma pirâmide de idade com um simples comando age_pyramid(). Neste comando:
data = é definido como o quadro de dados (data frame) linelistage_group = (para o eixo y) é definido como o nome da coluna categórica de idade (entre aspas)split_by = (para o eixo x) é definido para a coluna de gênero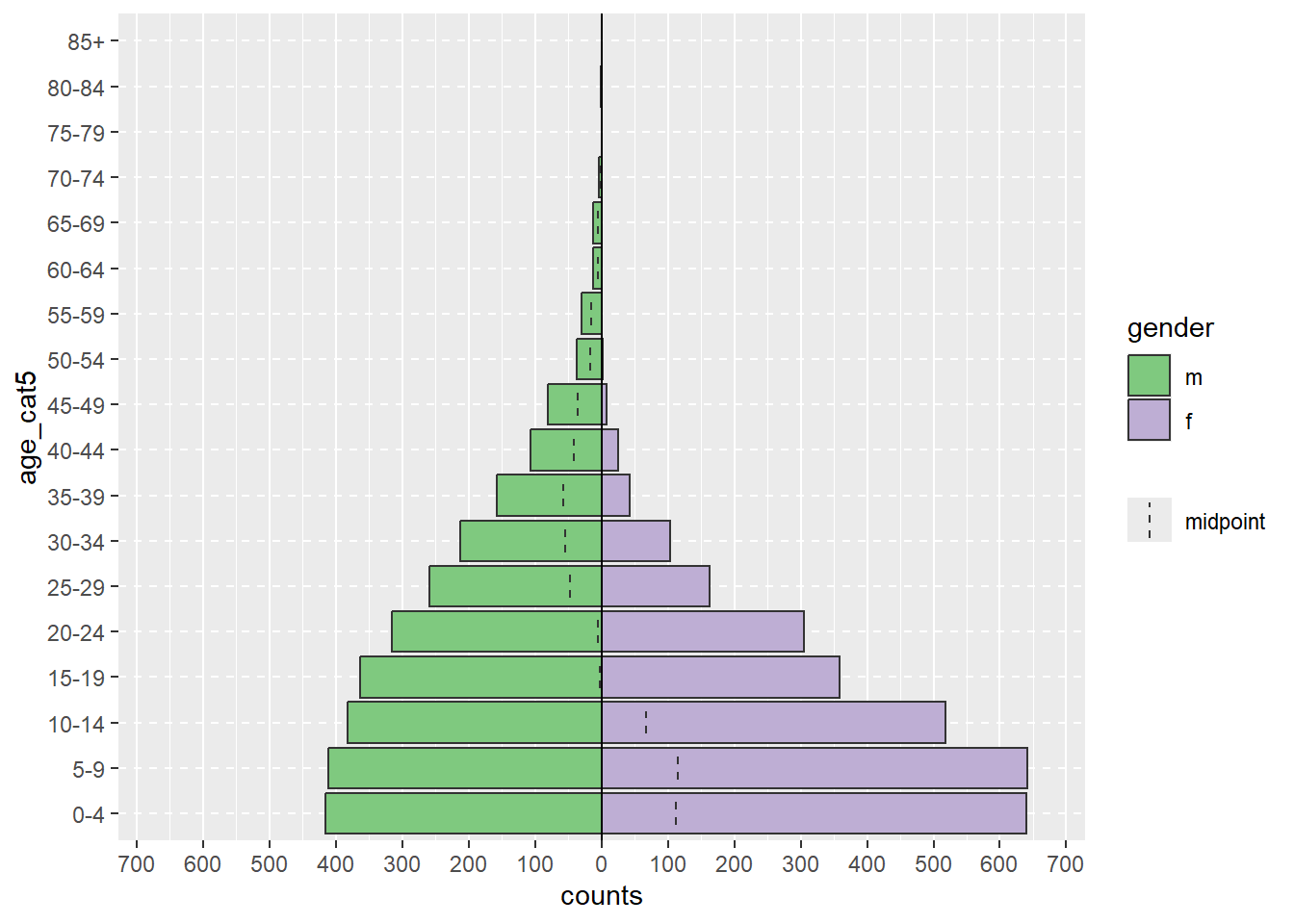
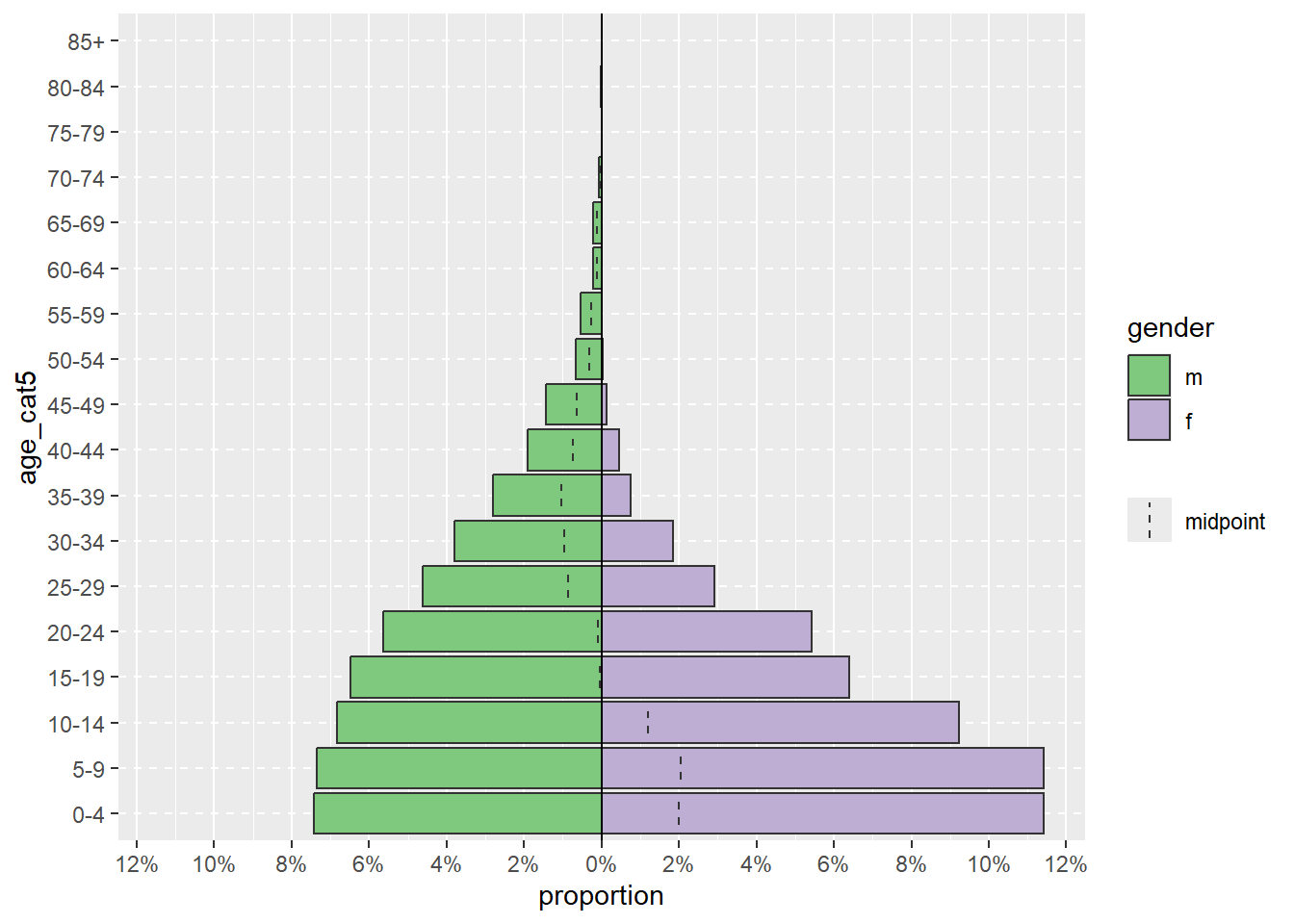
A pirâmide pode ser exibida com a porcentagem de todos os casos no eixo x, em vez de contagens, incluindo proporcional = VERDADEIRO.
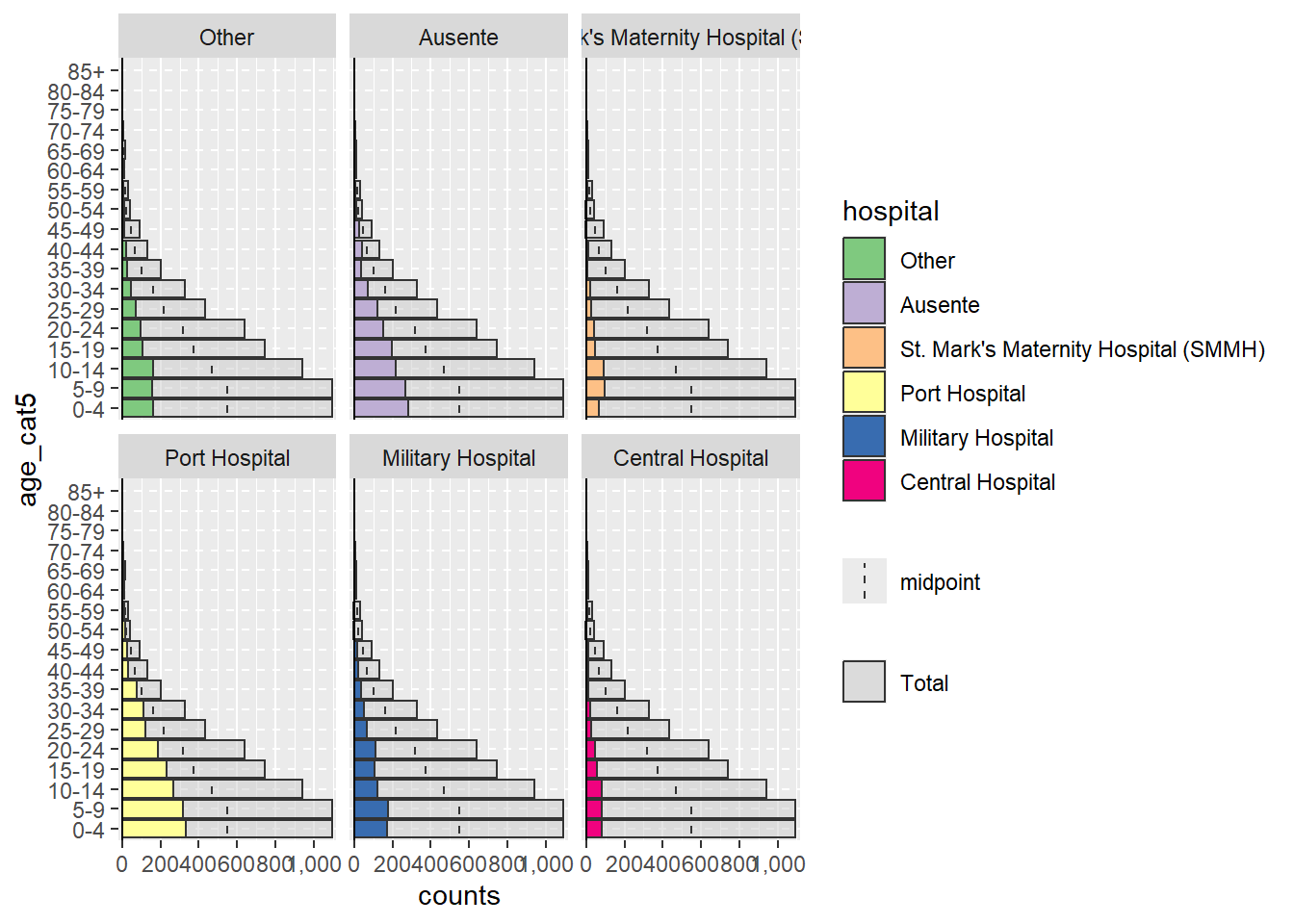
Ao usar o pacote agepyramid, se a coluna split_by for binária (por exemplo, masculino / feminino ou sim / não), o resultado aparecerá como uma pirâmide. No entanto, se houver mais de dois valores na coluna split_by (não incluindo NA), a pirâmide aparecerá como um gráfico de barra facetada com barras cinza no “fundo” indicando o intervalo dos dados não facetados para aquele grupo de idade. Nesse caso, os valores de split_by = aparecerão como rótulos na parte superior de cada painel de faceta. Por exemplo, abaixo está o que ocorre se split_by = é atribuído à coluna hospital.
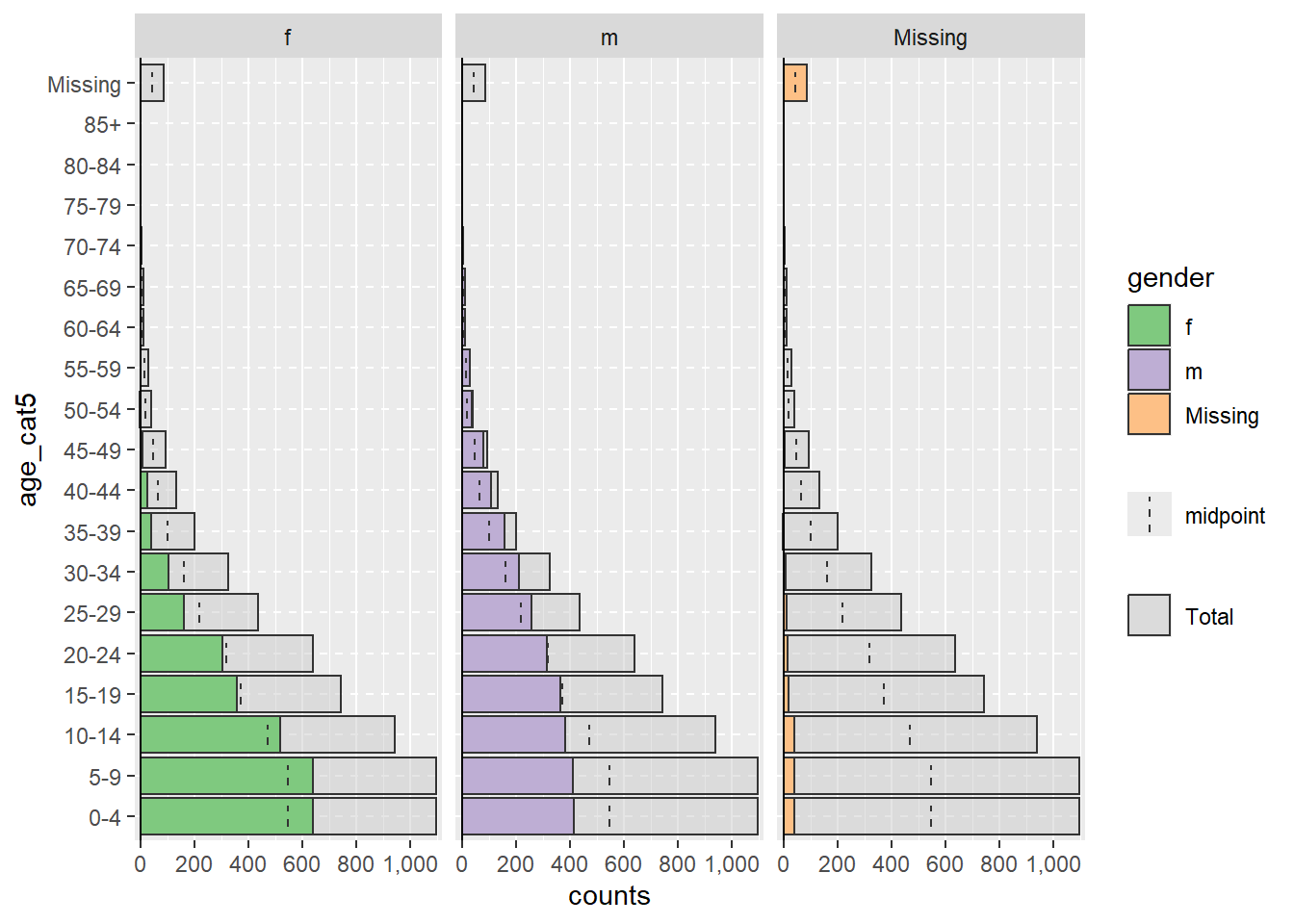
As linhas que têm valores faltantes NA nas colunas split_by = ou age_group =, se codificadas como NA, não irão acionar o facetamento mostrado acima. Por padrão, essas linhas não serão mostradas. No entanto, você pode especificar que eles apareçam em um gráfico de barras adjacente e como uma faixa etária separada no topo, especificando na.rm = FALSE.
Por padrão, as barras exibem contagens (não %), uma linha intermediária tracejada para cada grupo é mostrada e as cores são verde / roxo. Cada um desses parâmetros pode ser ajustado, conforme mostrado abaixo:
Você também pode adicionar comandos ggplot() adicionais ao gráfico usando a sintaxe ggplot() “+” padrão, como temas estéticos e ajustes de rótulo:
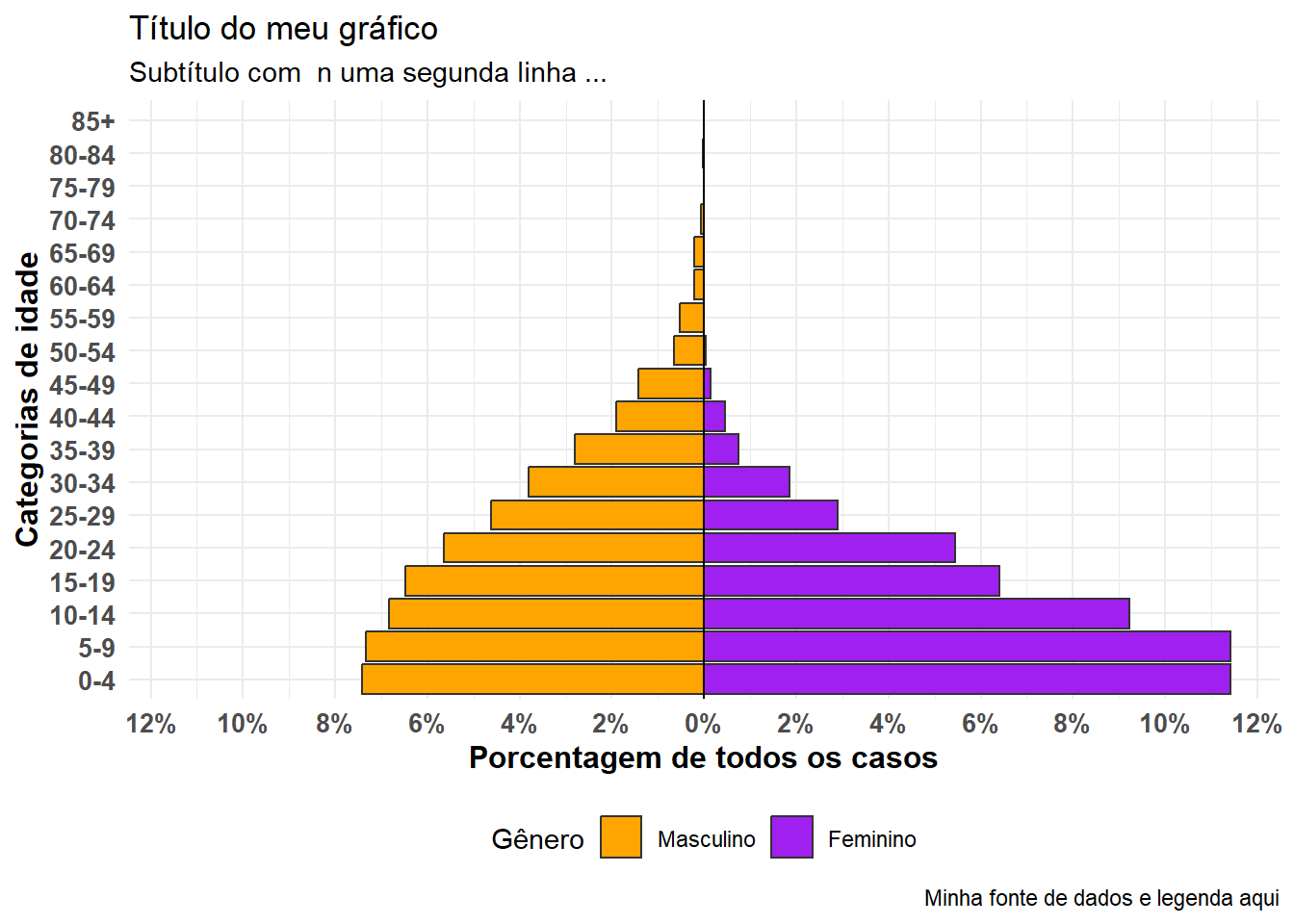
Os exemplos acima assumem que seus dados estão em um formato de linelist, com cada linha correspondendo a uma observação. Se seus dados já estão agregados em contagens por categoria de idade, você ainda pode usar o pacote apyramid, conforme mostrado abaixo.
Para demonstração, agregamos os dados da linelist em contagens por categoria de idade e sexo, em um formato “amplo” ou “wide”. Isso simulará como se seus dados estivessem em contagens para começar. Saiba mais sobre agrupamento de dados e pivoteamento de dados em suas respectivas páginas.
… o que faz com que o conjunto de dados tenha a seguinte aparência: com colunas para categoria de idade e contagens masculinas, contagens femininas e contagens ausentes.
Para configurar esses dados para a pirâmide de idade, vamos organizar os dados no formato “longo” com a função pivot_longer() de dplyr. Isso ocorre porque ggplot() geralmente prefere dados “longos”, e apyramid está usando ggplot().
Em seguida, use os argumentos split_by = e count = de age_pyramid() para especificar as respectivas colunas nos dados:
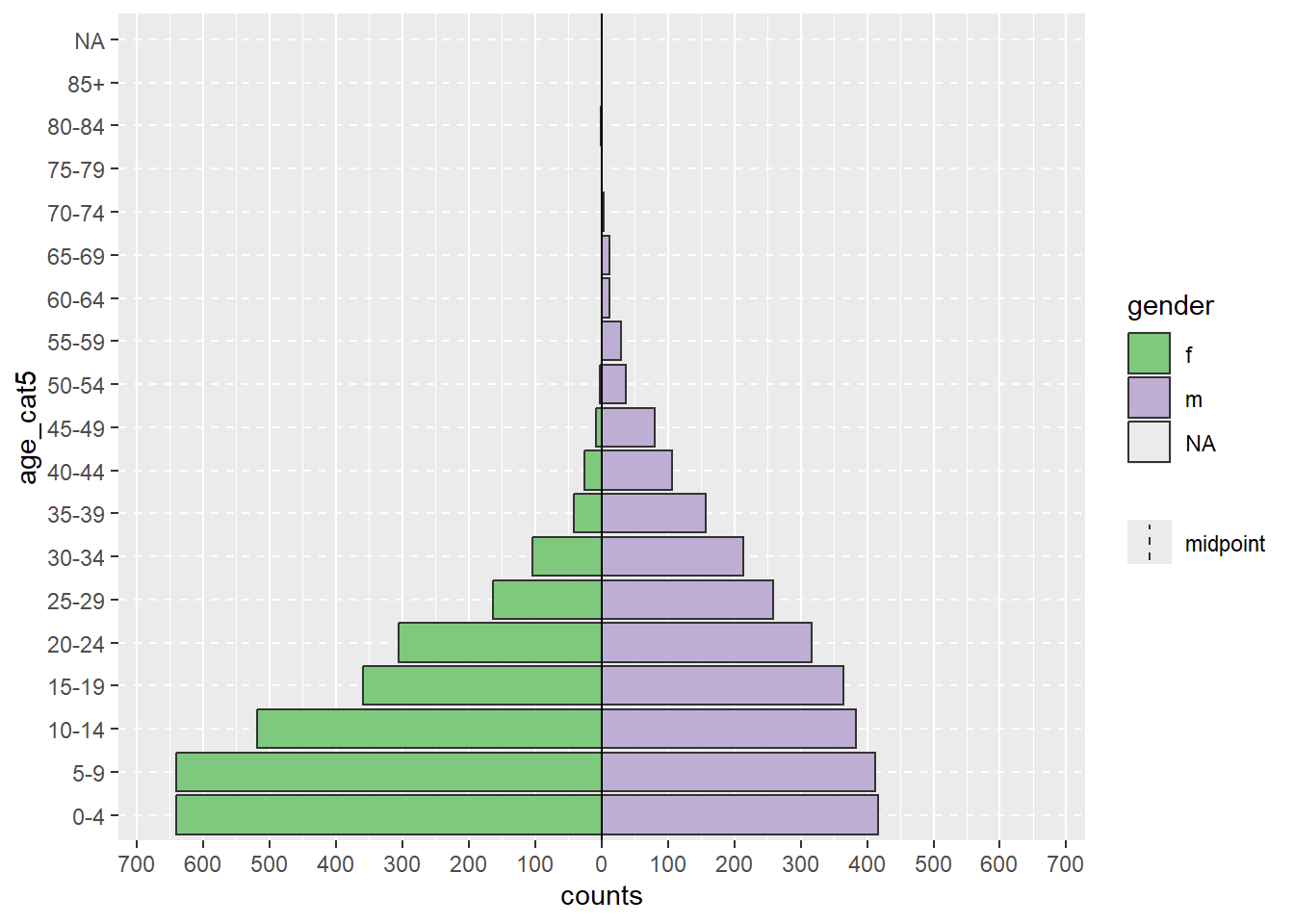
Observe acima, que a ordem dos fatores de “m” e “f” é diferente (pirâmide invertida). Para ajustar a ordem, você deve redefinir o gênero nos dados agregados como um fator e ordenar os níveis conforme desejado. Veja a página Fatores.
ggplot()Usar ggplot() para construir sua pirâmide de idade permite mais flexibilidade, mas requer mais esforço e compreensão de como ggplot() funciona. Também é mais fácil cometer erros acidentalmente.
Para usar ggplot() para fazer pirâmides demográficas, você cria dois gráficos de barra (um para cada gênero), converte os valores em um gráfico para negativo e, finalmente, vira os eixos x e y para exibir os gráficos de barra verticalmente, suas bases encontro no meio da trama.
Essa abordagem usa a coluna numérica idade, não a coluna categórica de age_cat5. Portanto, vamos verificar se a classe desta coluna é realmente numérica.
class(linelist$age)[1] "numeric"Você poderia usar a mesma lógica abaixo para construir uma pirâmide de dados categóricos usando geom_col() ao invés de geom_histogram().
Primeiro, entenda que para fazer essa pirâmide usando ggplot() a abordagem é a seguinte:
Dentro de ggplot(), crie dois histogramas usando a coluna numérica de idade. Crie um para cada um dos dois valores de agrupamento (neste caso, gêneros masculino e feminino). Para fazer isso, os dados de cada histograma são especificados em seus respectivos comandos geom_histogram(), com os respectivos filtros aplicados à linelist.
Um gráfico terá valores de contagem positivos, enquanto o outro terá suas contagens convertidas em valores negativos - isso cria a “pirâmide” com o valor 0 no meio do gráfico. Os valores negativos são criados usando um termo especial do ggplot2 ..count.. e multiplicando por -1.
O comando coord_flip() muda os eixos X e Y, resultando na viragem dos gráficos na vertical e na criação da pirâmide.
Por último, os rótulos de valor do eixo de contagem devem ser alterados para que apareçam como contagens “positivas” em ambos os lados da pirâmide (apesar dos valores subjacentes em um lado serem negativos).
Uma versão simples disso, usando geom_histogram(), está abaixo:
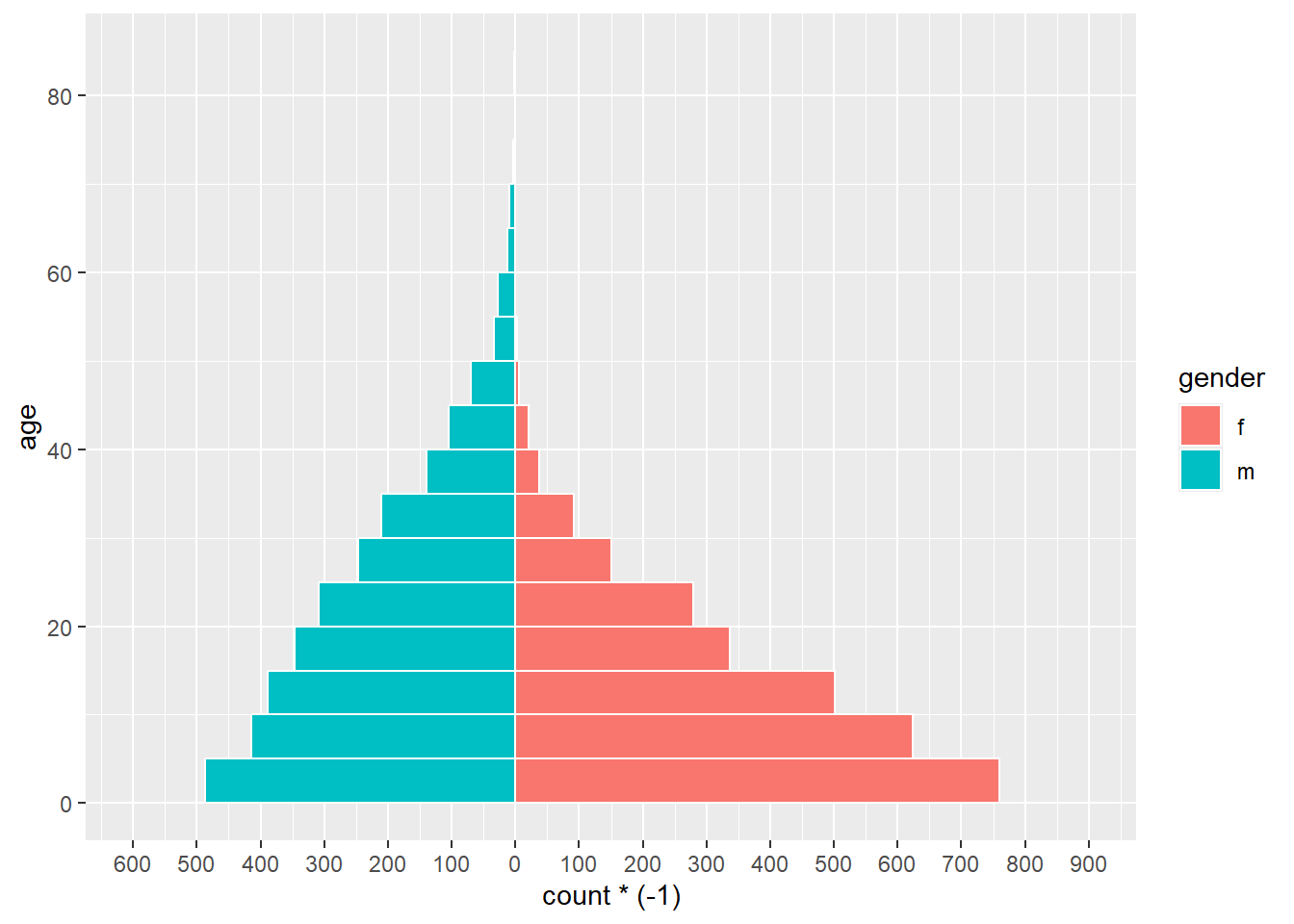
**_ PERIGO: _** Se os limites do seu eixo de contagem forem definidos muito baixos e uma barra de contagem ultrapassá-los, a barra desaparecerá totalmente ou será reduzida artificialmente ! Observe isso ao analisar dados que são atualizados rotineiramente. Evite que os limites do eixo de contagem se ajustem automaticamente aos seus dados, conforme abaixo.
Há muitas coisas que você pode alterar / adicionar a esta versão simples, incluindo:
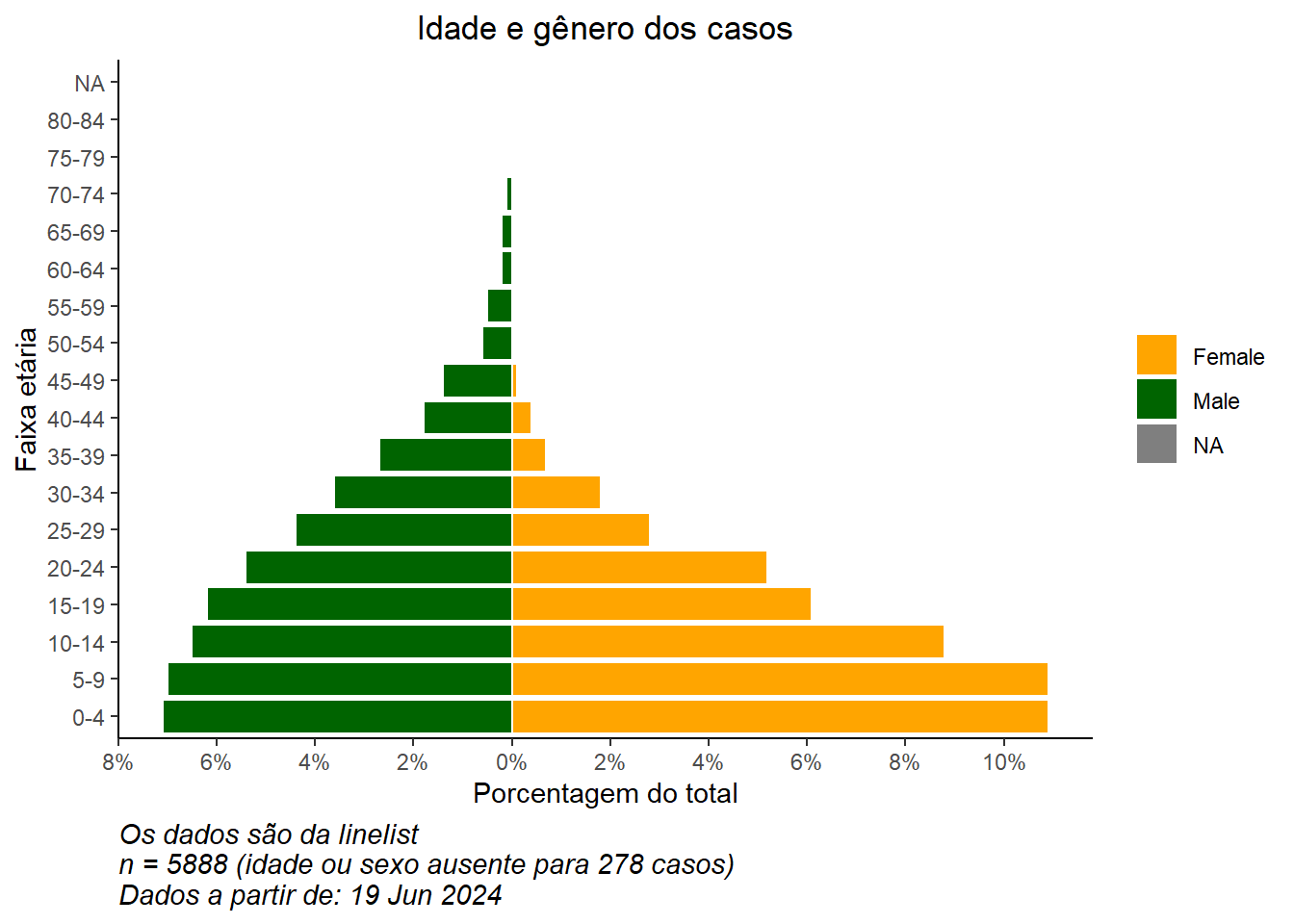
Converta contagens em porcentagens
Para converter contagens em porcentagens (do total), faça isso em seus dados antes de plotar. Abaixo, temos as contagens de idade e gênero, então ungroup(), e então mutate() para criar novas colunas de porcentagem. Se você quiser porcentagens por gênero, pule a etapa de desagrupamento.
É importante ressaltar que salvamos os valores máximos e mínimos para que saibamos quais devem ser os limites da escala. Eles serão usados no comando ggplot() abaixo.
max_per <- max(pyramid_data$percent, na.rm = T)
min_per <- min(pyramid_data$percent, na.rm = T)
max_per[1] 10.9min_per[1] -7.1Finalmente, fazemos o ggplot() nos dados de porcentagem. Especificamos scale_y_continuous() para estender os comprimentos predefinidos em cada direção (positivo e “negativo”). Usamos floor() e ceiling() para arredondar decimais na direção apropriada (para baixo ou para cima) para o lado do eixo.
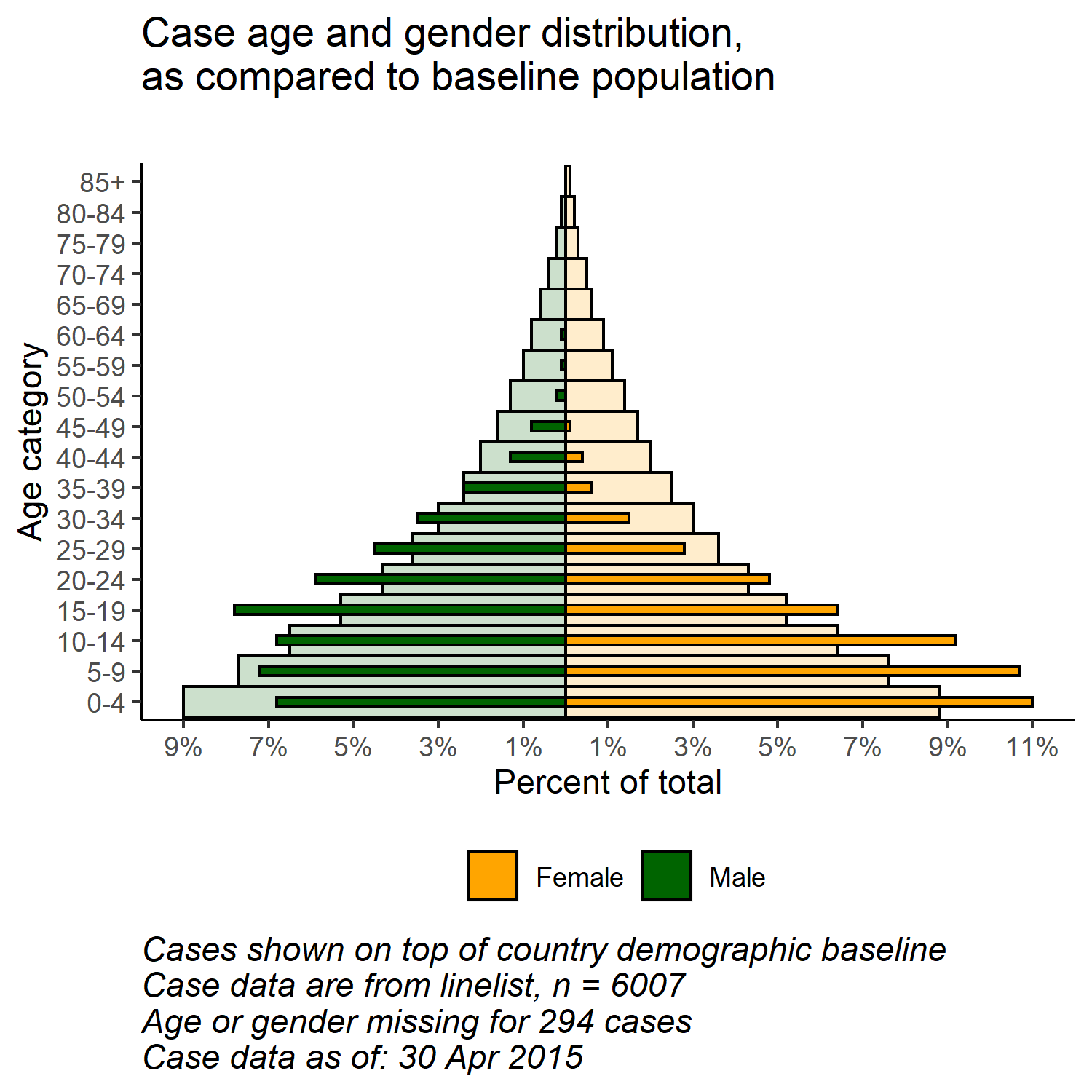
Com a flexibilidade de ggplot(), você pode ter uma segunda camada de barras no fundo que representam a pirâmide populacional “verdadeira” ou “linha de base”. Isso pode fornecer uma boa visualização para comparar o observado com a linha de base.
Importe e visualize os dados populacionais (consulte a página Baixar manual e dados):
# importar os dados demográficos da população
pop <- rio::import("country_demographics.csv")Primeiro, algumas etapas de gerenciamento de dados:
Aqui gravamos a ordem das categorias de idade que queremos que apareçam. Devido a algumas peculiaridades na forma como o ggplot() é implementado, neste cenário específico é mais fácil armazená-los como um vetor de caracteres e usá-los posteriormente na função de gráfico.
# registrar níveis corretos de gatos com idade
age_levels <- c("0-4","5-9", "10-14", "15-19", "20-24",
"25-29","30-34", "35-39", "40-44", "45-49",
"50-54", "55-59", "60-64", "65-69", "70-74",
"75-79", "80-84", "85+")Combine a população e os dados do caso por meio da função dplyr bind_rows():
bind_rows())Revise o conjunto de dados de população alterado
Agora implemente o mesmo para a linelist do caso. Um pouco diferente porque começa com linhas de caso, não conta.
Revise o conjunto de dados de caso alterado
Agora os dois data frames estão combinados, um em cima do outro (eles têm os mesmos nomes de coluna). Podemos “nomear” cada frame de dados e usar o argumento .id = para criar uma nova coluna “data_source” que indicará de qual frame de dados cada linha se originou. Podemos usar esta coluna para filtrar no ggplot().
Armazene os valores percentuais máximos e mínimos, usados na função de plotagem para definir a extensão da plotagem (e não encurte nenhuma barra!)
# Defina a extensão do eixo percentual, usado para os limites do gráfico
max_per <- max(pyramid_data$percent, na.rm = T)
min_per <- min(pyramid_data$percent, na.rm = T)Agora o gráfico é feito com ggplot():
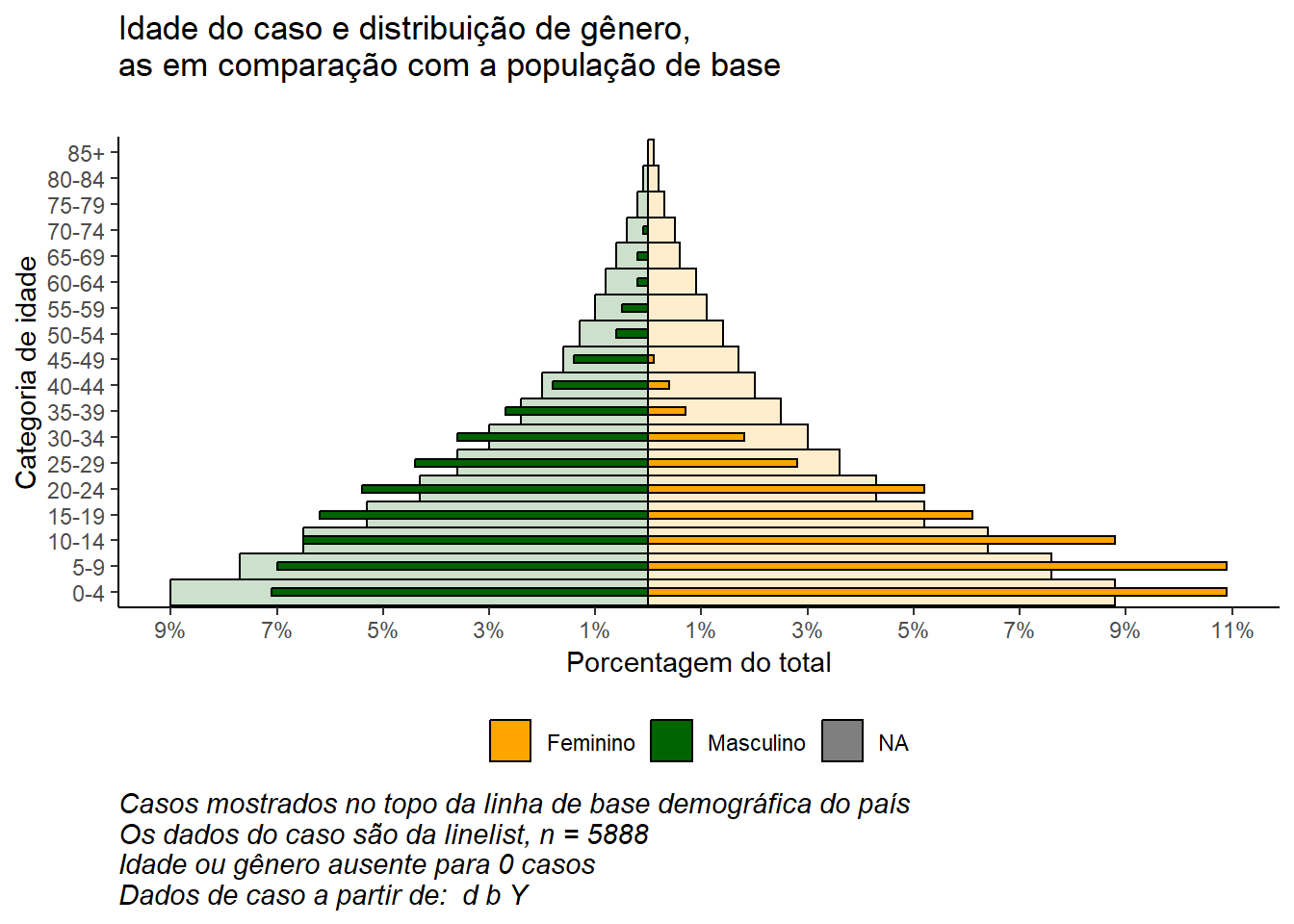
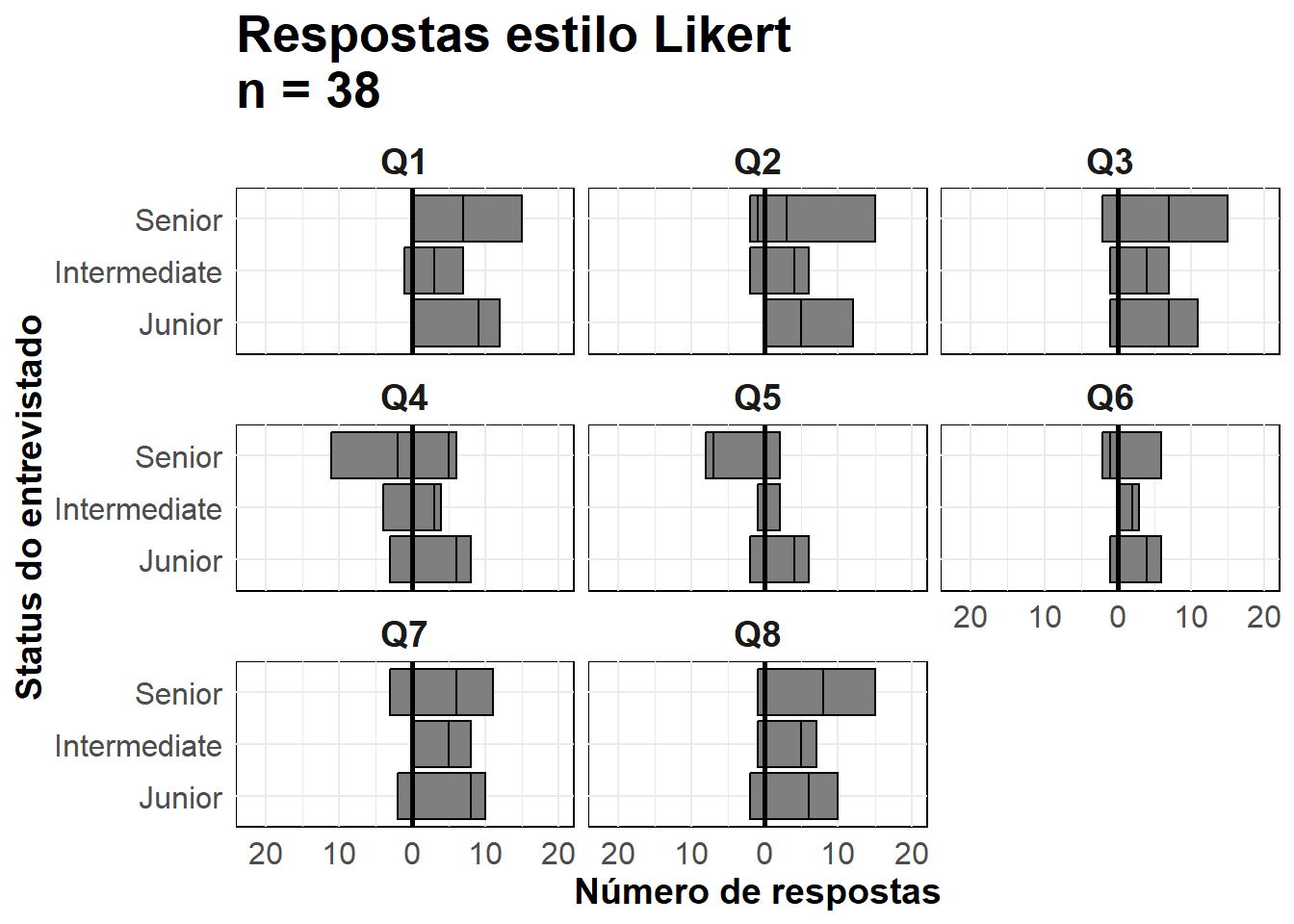
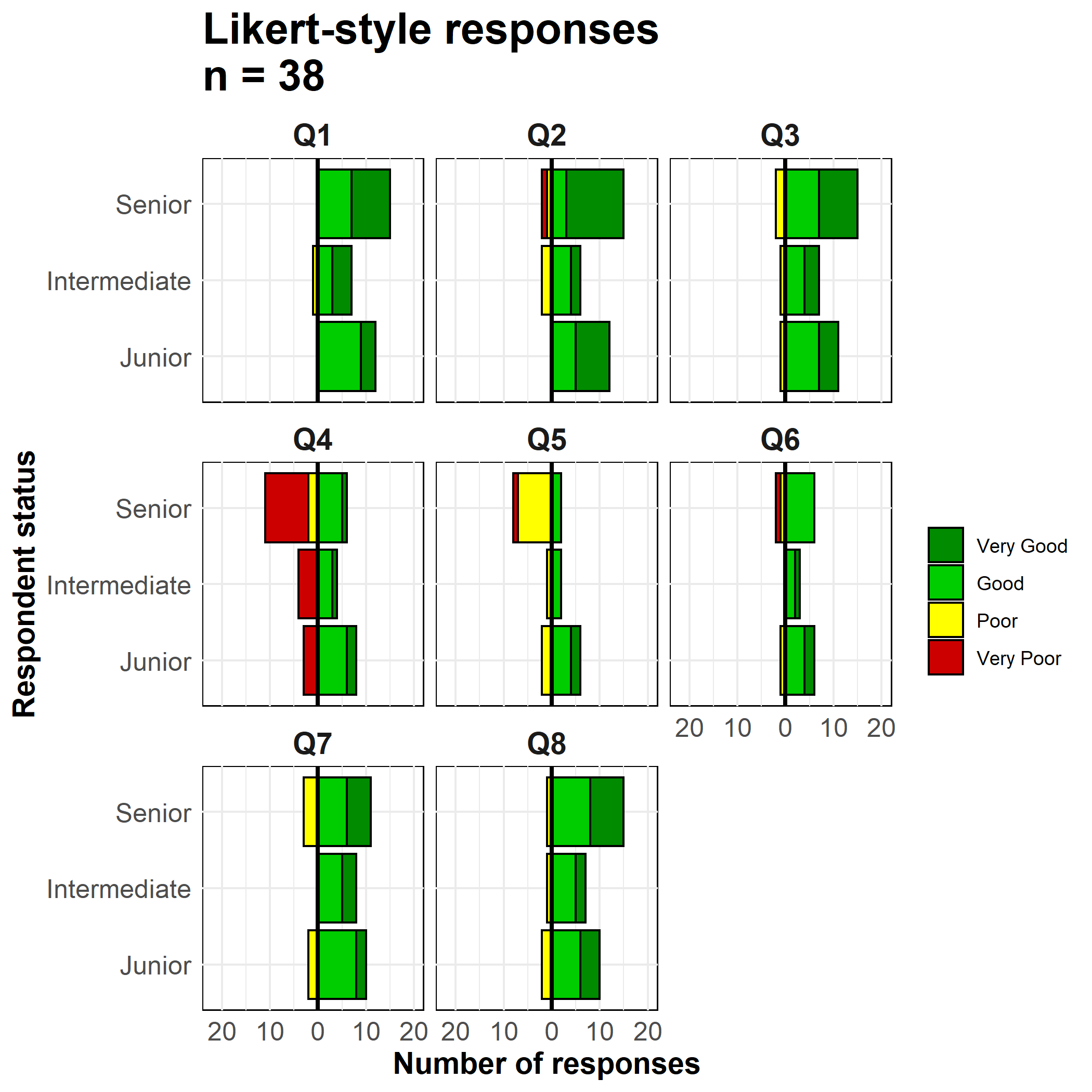
As técnicas usadas para fazer uma pirâmide populacional com ggplot() também podem ser usadas para fazer gráficos de dados de pesquisa em escala Likert.
Importe os dados (consulte a página Baixar manual e dados se desejar).
# importar os dados de resposta da pesquisa likert
likert_data <- rio::import("likert_data.csv")Comece com dados parecidos com estes, com uma classificação categórica de cada entrevistado (status) e suas respostas a 8 perguntas em uma escala do tipo Likert de 4 pontos (“Muito ruim”, “Ruim”, “Bom”, “Muito bom”).
Primeiro, algumas etapas de gerenciamento de dados:
direção dependendo se a resposta foi geralmente “positiva” ou “negativa”status e a coluna RespostaAgora faça o gráfico. Como nas pirâmides de idades acima, estamos criando dois gráficos de barra e invertendo os valores de um deles para negativo.
Usamos geom_bar() porque nossos dados são uma linha por observação, não contagens agregadas. Usamos o termo especial ggplot2 ..count.. em um dos gráficos de barra para inverter os valores negativos (* -1) e definimos position = "stack" para que os valores sejam empilhados no topo de cada um.