24 Salgın Modelleme
24.1 Genel Bakış
Salgın modelleme için, oldukça karmaşık analizleri minimum çabayla yapmamızı sağlayan, büyüyen bir araç grubu vardır. Bu bölüm, bu araçların aşağıdaki amaçlarla nasıl kullanılacağına ilişkin bir genel bakış sağlayacaktır:
- etkin üreme sayısı Rt ve iki katına çıkma süresi gibi ilgili istatistikleri tahmin etme
- gelecekteki insidansın kısa vadeli projeksiyonlarını üretme
Bu bölüm araçların altında yatan metodolojilere ve istatistiksel yöntemlere genel bir bakış değildir, bu nedenle bu konuyu kapsayan bazı makalelere bağlantılar için lütfen Kaynaklar sekmesine bakınız. Bu araçları kullanmadan önce yöntemleri anladığınızdan emin olun; bu, sonuçlarını doğru bir şekilde yorumlayabilmenizi sağlayacaktır.
Aşağıda, bu bölümde üreteceğimiz çıktılardan birine bir örnek verilmiştir.
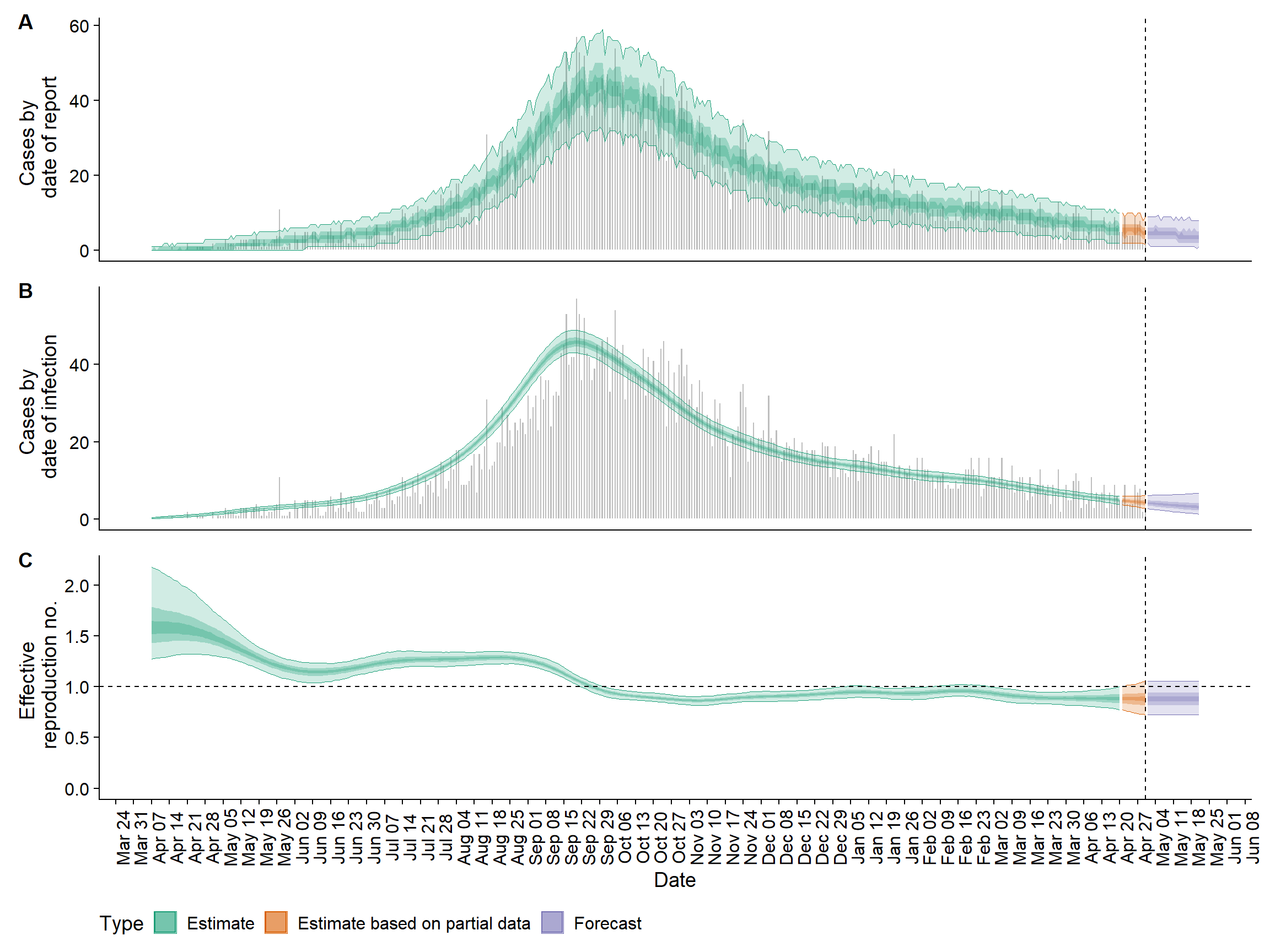
24.2 Hazırlık
Rt tahmini için EpiNow ve EpiEstim olmak üzere iki farklı yöntem ve paketin yanı sıra vaka insidansını tahmin etmek için projections paketini kullanacağız.
Bu kod parçası, analizler için gereken paketlerin yüklenmesini gösterir.
Bu el kitabında, gerekirse paketi kuran ve kullanım için yükleyen pacman’dan p_load() vurgusunu yapıyoruz.
base R’dan library() ile kurulu paketleri de yükleyebilirsiniz. R paketleri hakkında daha fazla bilgi için [R basics] sayfasına bakın.
pacman::p_load(
rio, # dosya içe aktarma
here, # dosya konumlama
tidyverse, # Veri yönetimi + ggplot2 grafikleri
epicontacts, # bulaş ağlarının analizi
EpiNow2, # Rt tahminleme
EpiEstim, # Rt tahminleme
projections, # İnsidans öngörme
incidence2, # İnsidans verilerini işleme
epitrix, # Faydalı epi fonksiyonları
distcrete # Ayrık gecikme dağılımları
)Bu bölümdeki tüm analizler için temizlenmiş vaka satır listesini kullanacağız. Takip etmek isterseniz, “clean” dosyasını indirmek için tıklayın. ” (.rds dosyası olarak). Bu el kitabında kullanılan tüm örnek verileri indirmek için [El kitabı ve verileri indir] sayfasına bakınız.
# temizlenmiş satır listesini içe aktarma
linelist <- import("linelist_cleaned.rds")24.3 Rt Tahmini
EpiNow2 vs. EpiEstim
Üreme sayısı R, bir hastalığın bulaşıcılığının bir ölçüsüdür ve enfekte vaka başına beklenen ikincil vaka sayısı olarak tanımlanır. Tamamen duyarlı bir popülasyonda bu değer, R0 (Rnought) temel üreme sayısını temsil eder. Bununla birlikte, bir salgın veya pandemi sırasında bir popülasyondaki duyarlı bireylerin sayısı değiştikçe ve çeşitli müdahale önlemleri uygulandıkça, en yaygın olarak kullanılan ölçüm aktarılabilirlik, etkili üreme sayısıdır Rt; bu, belirli bir t zamanında virüslü vaka başına beklenen ikincil vaka sayısı olarak tanımlanır.
EpiNow2 paketi, Rt tahmini için en gelişmiş çerçeveyi sağlar. Diğer yaygın olarak kullanılan paket olan EpiEstim’e göre iki önemli avantajı vardır:
- Raporlamadaki gecikmeleri hesaba katar ve bu nedenle son veriler eksik olsa bile Rt tahminini yapabilir.
- Rt’yi raporlamanın başlangıç tarihlerinden ziyade enfeksiyon tarihlerinde tahmin eder; bu, bir müdahalenin etkisinin Rt’deki bir değişikliğe gecikme ile değil hemen yansıtılacağı anlamına gelir.
Bununla birlikte, aynı zamanda iki önemli dezavantajı vardır:
- Bulaş süresi dağılımı (yani birincil ve ikincil vakaların enfeksiyonu arasındaki gecikmelerin dağılımı), kuluçka dönemi dağılımı (yani enfeksiyon ve semptom başlangıcı arasındaki gecikmelerin dağılımı) ve verilerinizle ilgili herhangi bir başka gecikme dağılımı (ör. raporlama tarihleriniz varsa, semptomların başlangıcından raporlamaya kadar olan gecikmelerin dağılımına ihtiyaç duyarsınız). Bu, Rt’nin daha doğru bir şekilde tahmin edilmesini sağlayacak olsa da, EpiEstim yalnızca seri aralık dağılımını (yani, birincil ve ikincil vakanın semptom başlangıcı arasındaki gecikmelerin dağılımına) ihtiyaç duyar. Elinizdeki tek veri bu olduğunda çok kıymetlidir.
EpiNow2, EpiEstim’den önemli ölçüde daha yavaştır, anekdot olarak yaklaşık 100-1000 kat! Örneğin, bu bölümde ele alınan örnek salgın için Rt tahmini yaklaşık dört saat sürer (bu, yüksek doğruluk sağlamak için çok sayıda yineleme için çalıştırılmasındandır. Gerekirse muhtemelen azaltılabilir, ancak ifade edilmek istenen algoritmanın genel olarak yavaş çalıştığıdır). Rt tahminlerinizi düzenli olarak güncelliyorsanız, kullanışlı olmayabilir.
Bu nedenle hangi paketi kullanmayı seçeceğiniz, size sunulan verilere, zamana ve hesaplama kaynaklarına bağlı olacaktır.
EpiNow2
Tahmini gecikme dağılımları
EpiNow2’yi çalıştırmak için gereken gecikme dağılımları, sahip olduğunuz verilere bağlıdır. Esasen, Rt tahmininde kullanmak istediğiniz bulaşma tarihinden olay tarihine kadar olan gecikmeyi tanımlayabilmeniz gerekir. Başlangıç tarihlerini kullanıyorsanız, bu sadece kuluçka dönemi dağılımı olacaktır. Raporlama tarihlerini kullanıyorsanız, enfeksiyondan raporlamaya kadar olan gecikmeye ihtiyacınız vardır. Bu dağıtımın doğrudan bilinmesi pek mümkün olmadığından, EpiNow2 birden çok gecikme dağıtımını birlikte zincirlemenize olanak tanır. Bu durumda, enfeksiyondan semptom başlangıcına (örneğin, muhtemelen bilinen kuluçka dönemi) ve semptom başlangıcından raporlamaya (genellikle verilerden tahmin edebileceğiniz) gecikmeyi bilmelisiniz.
Örnek satır listesindeki tüm vakalarımız için başlangıç tarihlerine sahip olduğumuzdan, verilerimizi (örn. semptom başlangıç tarihleri) enfeksiyon tarihine bağlamak için yalnızca kuluçka dönemi dağılımına ihtiyaç duyacağız. Bu dağılımı verilerden tahmin edebilir veya literatürdeki değerleri kullanabiliriz.
Ebola’nın kuluçka dönemine ilişkin bir literatür tahmini (bu makaleden alınmıştır) ortalama 9.1, standart sapma 7.3 ve maksimum değer 30 aşağıdaki gibi belirtilecektir:
incubation_period_lit <- list(
mean = log(9.1),
mean_sd = log(0.1),
sd = log(7.3),
sd_sd = log(0.1),
max = 30
)EpiNow2 bu gecikme dağılımlarının bir log ölçeğinde sağlanmasını gerektirdiğini unutmayın, bu nedenle “log” her değerin etrafında çağrılır (kafa karıştırıcı bir şekilde doğal bir değerde sağlanması gereken “max” parametresi hariç). “mean_sd” ve “sd_sd”, ortalamanın standart sapması ve standart sapmasının tahminlerini tanımlamaktadır. Bu durumda bunlar bilinmediğinden, oldukça gelişigüzel 0,1 değerini seçiyoruz.
Bu analizde, kuluçka dönemi dağılımını tahmin etmemiz gibi değil, satır listesinde enfeksiyon ve başlangıç arasında gözlemlenen gecikmelere uyacak bir lognormal dağılımı ‘bootstrapped_dist_fit’ fonksiyonu ile tahminliyoruz.
## inkübasyon süresini tahminleme
incubation_period <- bootstrapped_dist_fit(
linelist$date_onset - linelist$date_infection,
dist = "lognormal",
max_value = 100,
bootstraps = 1
)İhtiyacımız olan diğer dağılım ise üreme süresidir. Bulaşma zamanları ve iletim bağlantılarına ilişkin verilerimiz olduğundan, bu dağılımı, bulaşan-bulaşan çiftlerinin bulaşma süreleri arasındaki gecikmeyi hesaplayarak satır listesinden tahmin edebiliriz. Bunu yapmak için, epicontacts paketindeki kullanışlı get_pairwise fonksiyonunu kullanıyoruz. Bu, iletim çiftleri arasındaki satır listesi özelliklerinin ikili farklılıklarını hesaplamamıza izin veriyor. Önce bir epicontacts nesnesi oluşturuyoruz (daha fazla ayrıntı için İletim zincirleri sayfasına bakabilirsiniz):
## kişileri oluştur
contacts <- linelist %>%
transmute(
from = infector,
to = case_id
) %>%
drop_na()
## temaslı kişileri oluştur
epic <- make_epicontacts(
linelist = linelist,
contacts = contacts,
directed = TRUE
)Daha sonra, “get_pairwise” kullanılarak hesaplanan iletim çiftleri arasındaki enfeksiyon sürelerindeki farkı bir gama dağılımına uydururuz:
## gama oluşturma süresini tahmin et
generation_time <- bootstrapped_dist_fit(
get_pairwise(epic, "date_infection"),
dist = "gamma",
max_value = 20,
bootstraps = 1
)EpiNow2 Çalıştırmak
Şimdi sadece dplyr group_by() ve n() fonskiyonlarıyla kolayca yapabileceğimiz satır listesinden günlük insidansı hesaplamamız gerekiyor. EpiNow2 sütun adlarının “date” ve “confirm” olmasını gerektirdiğini unutmayın.
## başlangıç tarihlerinden insidans almak
cases <- linelist %>%
group_by(date = date_onset) %>%
summarise(confirm = n())Daha sonra ‘epinow’ fonksiyonunu kullanarak Rt değerini tahmin edebiliriz. Girişlerle ilgili bazı notlar:
- ‘delays’ değişkenine herhangi bir sayıda ‘zincirleme’ gecikme dağılımı sağlayabiliriz; onları sadece ‘delay_opts’ işlevi içindeki incubation_period’ nesnesinin yanına ekleyebiliriz.
- “return_output”, çıktının yalnızca bir dosyaya kaydedilmesini değil, R içinde döndürülmesini sağlar.
- “verbose” ilerlemenin bir okumasını istediğimizi belirtir.
- “horizon”, gelecekteki insidansı kaç gün için tahmin etmek istediğimizi gösterir.
- Çıkarımı ne kadar süreyle çalıştırmak istediğimizi belirtmek için ‘stan’ değişkenine ek seçenekler iletiyoruz. Artan “örnekler” ve “zincirler”, belirsizliği daha iyi karakterize eden daha doğru bir tahmin verecektir, ancak çalışması daha uzun sürecektir..
## epinow çalıştır
epinow_res <- epinow(
reported_cases = cases,
generation_time = generation_time,
delays = delay_opts(incubation_period),
return_output = TRUE,
verbose = TRUE,
horizon = 21,
stan = stan_opts(samples = 750, chains = 4)
)Çıktıları analiz etme
Kodun çalışması bittiğinde, aşağıdaki gibi çok kolay bir şekilde bir özet çizebiliriz. Resmin tamamını görmek için kaydırınız.
## özet grafiği çiz
plot(epinow_res)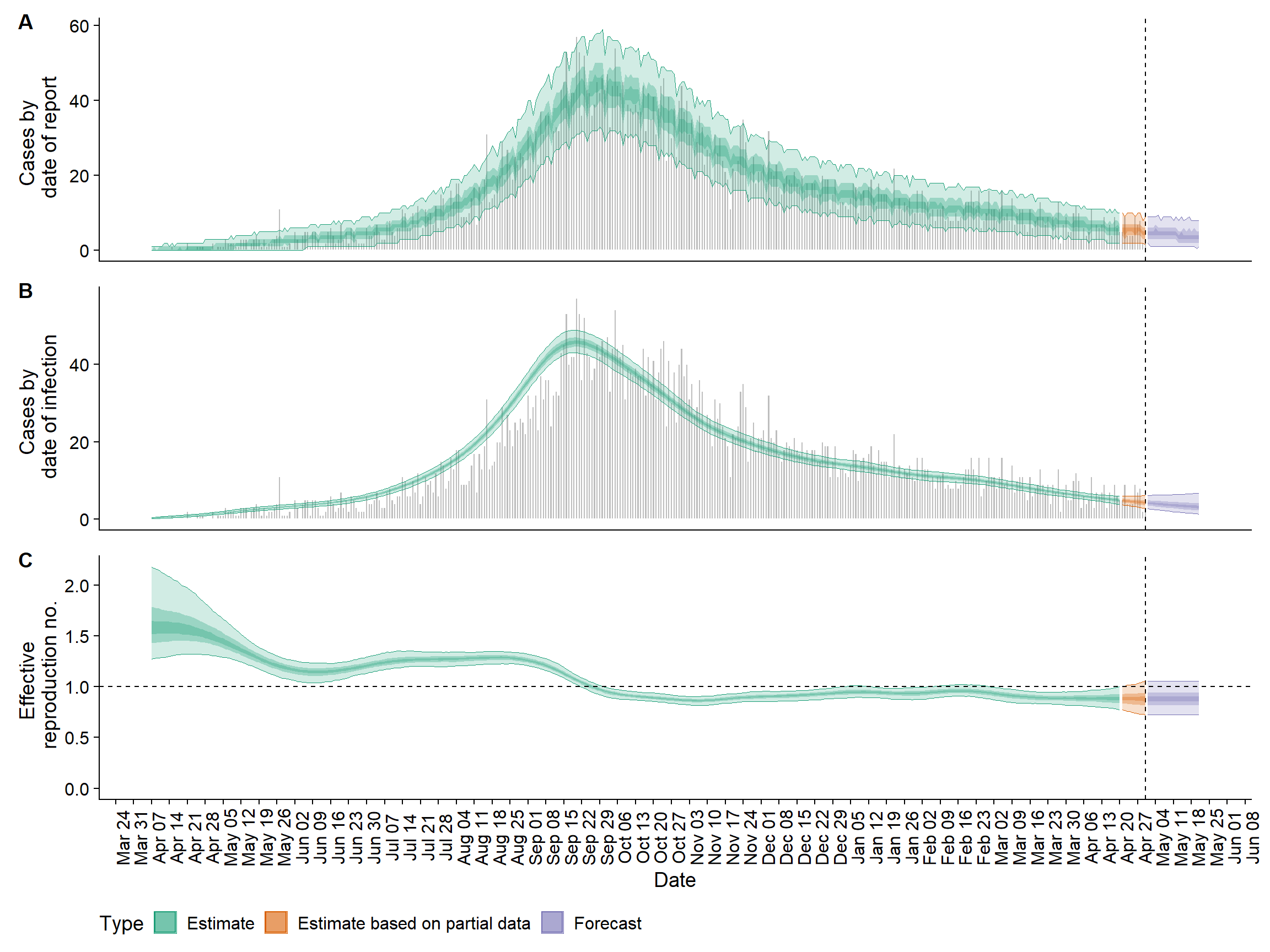
Ayrıca çeşitli özet istatistiklere de bakabiliriz:
## özet tablo
epinow_res$summary## measure estimate numeric_estimate
## 1: New confirmed cases by infection date 4 (2 -- 6) <data.table[1x9]>
## 2: Expected change in daily cases Unsure 0.56
## 3: Effective reproduction no. 0.88 (0.73 -- 1.1) <data.table[1x9]>
## 4: Rate of growth -0.012 (-0.028 -- 0.0052) <data.table[1x9]>
## 5: Doubling/halving time (days) -60 (130 -- -25) <data.table[1x9]>Daha fazla analiz ve özel çizim için, $estimates$summarised üzerinden özetlenen günlük tahminlere erişebilirsiniz. dplyr ile kullanım kolaylığı için bunu varsayılan ’veri.tablosu’ndan ’tibble’a çevireceğiz.
## özeti çıkar ve tibble'a dönüştür
estimates <- as_tibble(epinow_res$estimates$summarised)
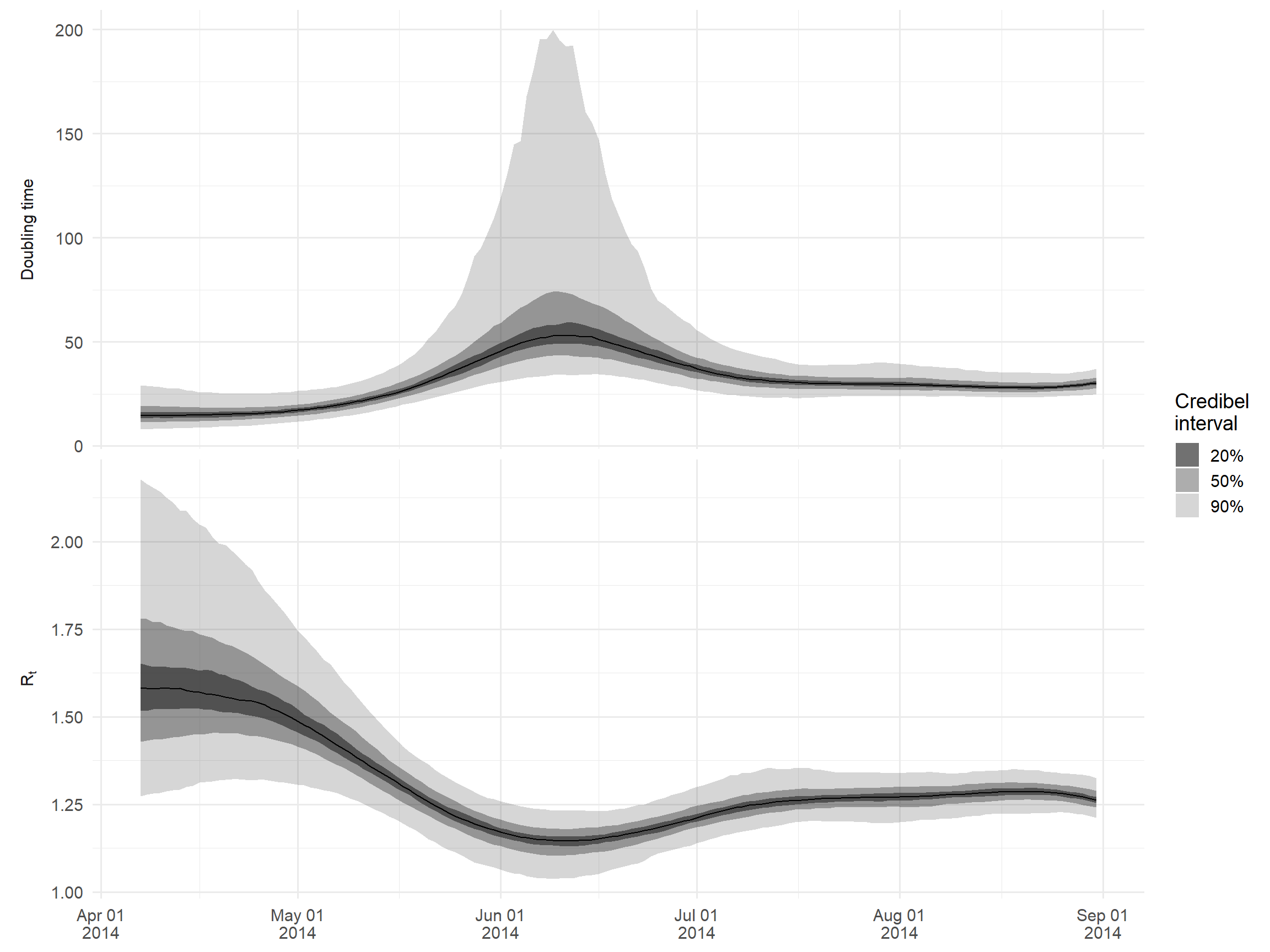
estimatesÖrnek olarak, ikiye katlama süresinin ve Rt’nin bir grafiğini yapalım. Aşırı yüksek katlama zamanlarını planlamaktan kaçınmak için, Rt birin çok üzerinde olduğunda, salgının yalnızca ilk birkaç ayına bakacağız.
Tahmini büyüme oranından iki katına çıkma süresini hesaplamak için “log(2)/growth_rate” formülünü kullanırız.
## medyan çizim için geniş df yapın
df_wide <- estimates %>%
filter(
variable %in% c("growth_rate", "R"),
date < as.Date("2014-09-01")
) %>%
## büyüme oranlarını ikiye katlama sürelerine dönüştürme
mutate(
across(
c(median, lower_90:upper_90),
~ case_when(
variable == "growth_rate" ~ log(2)/.x,
TRUE ~ .x
)
),
## dönüşümü yansıtmak için değişkeni yeniden adlandırın
variable = replace(variable, variable == "growth_rate", "doubling_time")
)
## nicel çizim için uzun df yapın
df_long <- df_wide %>%
## burada eşleşen nicelikleri eşleştiriyoruz (örneğin, alt_90 ila üst_90)
pivot_longer(
lower_90:upper_90,
names_to = c(".value", "quantile"),
names_pattern = "(.+)_(.+)"
)
## grafik yapın
ggplot() +
geom_ribbon(
data = df_long,
aes(x = date, ymin = lower, ymax = upper, alpha = quantile),
color = NA
) +
geom_line(
data = df_wide,
aes(x = date, y = median)
) +
## alt simge etiketine izin vermek için label_parsed kullanın
facet_wrap(
~ variable,
ncol = 1,
scales = "free_y",
labeller = as_labeller(c(R = "R[t]", doubling_time = "Doubling~time"), label_parsed),
strip.position = 'left'
) +
## nicel şeffaflığı manuel olarak tanımla
scale_alpha_manual(
values = c(`20` = 0.7, `50` = 0.4, `90` = 0.2),
labels = function(x) paste0(x, "%")
) +
labs(
x = NULL,
y = NULL,
alpha = "Credibel\ninterval"
) +
scale_x_date(
date_breaks = "1 month",
date_labels = "%b %d\n%Y"
) +
theme_minimal(base_size = 14) +
theme(
strip.background = element_blank(),
strip.placement = 'outside'
)
EpiEstim
EpiEstim’i çalıştırmak için günlük insidans hakkında veri sağlamamız ve seri aralığı (yani semptomların başlangıcı arasındaki gecikmelerin dağılımını (birincil ve ikincil vakalar) belirtmemiz gerekir).
İnsidans verileri EpiEstim’e bir vektör, veri çerçevesi veya orijinal insidans paketinden bir “insidans” nesnesi olarak sağlanabilir. İçe aktamalar ve yerel olarak edinilen enfeksiyonlar arasında bile ayrım yapabilirsiniz. Daha fazla detay için ?estimate_R adresindeki belgelere bakabilirsiniz.
Girdiyi incidence2 kullanarak oluşturacağız. incidence2 paketiyle ilgili daha fazla örnek için Salgın eğrileri ile ilgili sayfaya bakabilirsiniz. incidence2 paketinde, “estimateR()”nin beklenen girdisiyle tam olarak uyuşmayan güncellemeler olduğundan, gerekli bazı küçük ek adımlar vardır. İnsidans nesnesi, tarihlerin ve ilgili vaka sayılarının bulunduğu bir tibble’dan oluşur. Tüm tarihlerin dahil edildiğinden emin olmak için tidyr’den ‘complete()’ kullanırız. Daha sonra sonraki bir adımda ‘estimate_R()’ tarafından beklenenle hizalanacak şekilde sütunları ‘yeniden adlandırın()’.
## başlangıç tarihinden itibaren insidansı almak
cases <- incidence2::incidence(linelist, date_index = date_onset) %>% # günlere göre vaka sayılarını al
tidyr::complete(date_index = seq.Date( # tüm tarihlerin temsil edildiğinden emin olun
from = min(date_index, na.rm = T),
to = max(date_index, na.rm=T),
by = "day"),
fill = list(count = 0)) %>% # NA sayılarını 0'a çevir
rename(I = count, # EstimateR'a göre beklenen adlarla yeniden adlandırın
dates = date_index)Paket, ayrıntıları “?estimate_R” adresindeki belgelerde sağlanan seri aralığı belirtmek için çeşitli seçenekler sunar. Biz burada bunlardan ikisini ele alacağız.
Literatürden seri aralık tahminlerini kullanma
method = "parametric_si" seçeneğini kullanarak, make_configfonksiyonu kullanılarak oluşturulan birconfig` nesnesindeki seri aralığın ortalamasını ve standart sapmasını manuel olarak belirtebiliriz. [Bu belgede] https://bmcmedicine.biomedcentral.com/articles/10.1186/s12916-014-0196-0'da tanımlanan sırasıyla 12,0 ve 5,2’lik bir ortalama ve standart sapma kullanıyoruz:
## make config
config_lit <- make_config(
mean_si = 12.0,
std_si = 5.2
)Daha sonra estimate_R fonksiyonuyla Rt değerini tahmin edebiliriz:
epiestim_res_lit <- estimate_R(
incid = cases,
method = "parametric_si",
config = config_lit
)## Default config will estimate R on weekly sliding windows.
## To change this change the t_start and t_end arguments.ve çıktıların bir özetini çizin:
plot(epiestim_res_lit)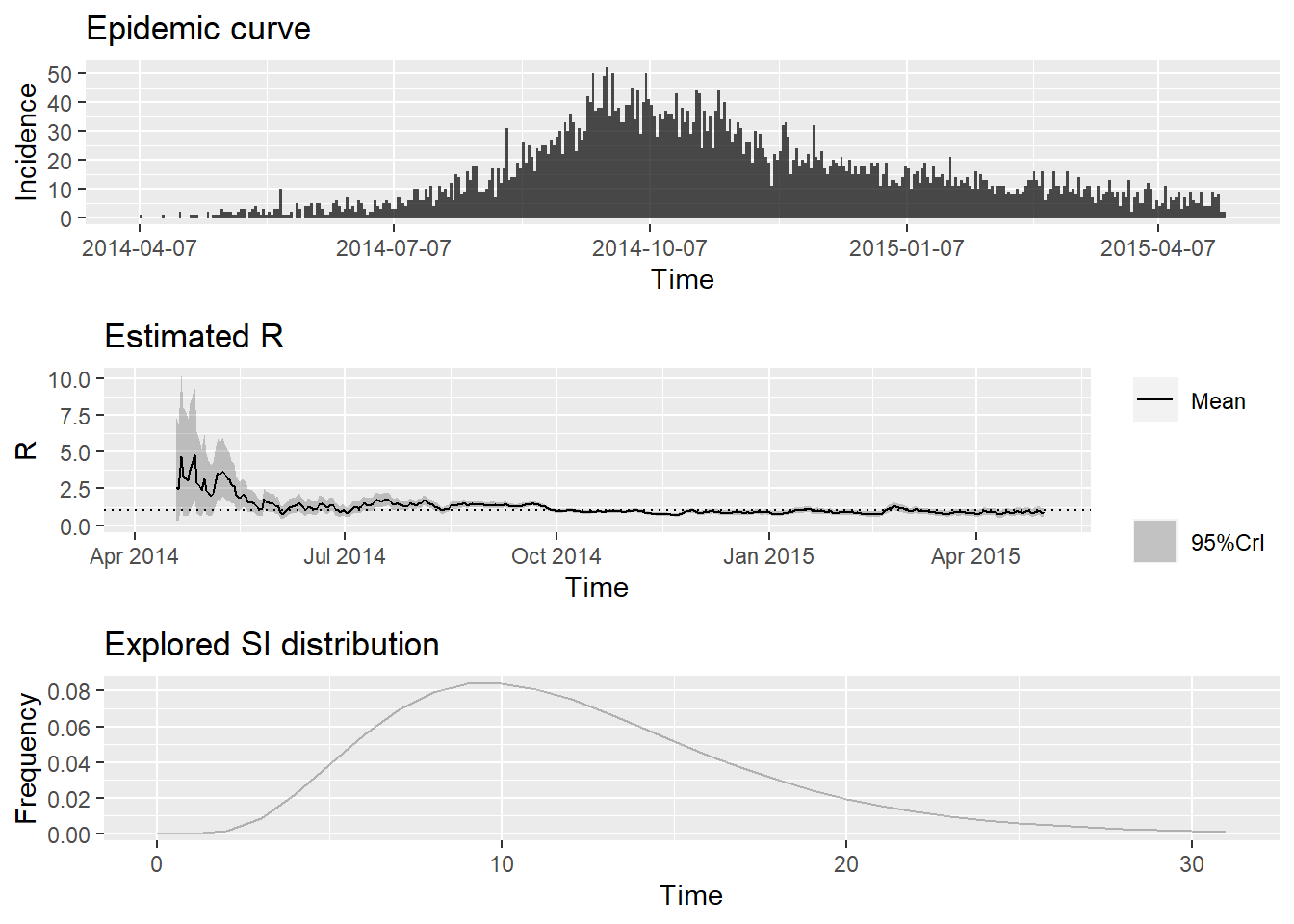
Verilerden seri aralık tahminlerini kullanma
Semptom başlangıç tarihlerine ve iletim bağlantılarına ilişkin verilere sahip olduğumuz için, bulaştırıcı-enfekte çiftlerinin başlangıç tarihleri arasındaki gecikmeyi hesaplayarak satır listesinden seri aralığı da tahmin edebiliriz. EpiNow2 bölümünde yaptığımız gibi, epicontacts paketindeki get_pairwise fonksiyonunu kullanacağız, bu da iletim çiftleri arasındaki satır listesi özelliklerinin ikili farklarını hesaplamamızı sağlar. Önce bir epicontacts nesnesi oluşturuyoruz (daha fazla ayrıntı için İletim zincirleri sayfasına bakın):
## kişileri oluştur
contacts <- linelist %>%
transmute(
from = infector,
to = case_id
) %>%
drop_na()
## temaslıları oluştur
epic <- make_epicontacts(
linelist = linelist,
contacts = contacts,
directed = TRUE
)Daha sonra, “get_pairwise” kullanılarak hesaplanan iletim çiftleri arasındaki başlangıç tarihlerindeki farkı bir gama dağılımına uydururuz. Bu yerleştirme prosedürü için epitrix paketindeki kullanışlı ’fit_disc_gamma’yı kullanıyoruz, çünkü bir ayrıştırılmış dağıtıma ihtiyacımız var.
## gama seri aralığını tahmin et
serial_interval <- fit_disc_gamma(get_pairwise(epic, "date_onset"))Daha sonra bu bilgiyi config nesnesine iletiyoruz, EpiEstim’i tekrar çalıştırıyoruz ve sonuçları çiziyoruz:
## yapılandırma yap
config_emp <- make_config(
mean_si = serial_interval$mu,
std_si = serial_interval$sd
)
## epiestim çalıştır
epiestim_res_emp <- estimate_R(
incid = cases,
method = "parametric_si",
config = config_emp
)## Default config will estimate R on weekly sliding windows.
## To change this change the t_start and t_end arguments.
## grafik çıktısı al
plot(epiestim_res_emp)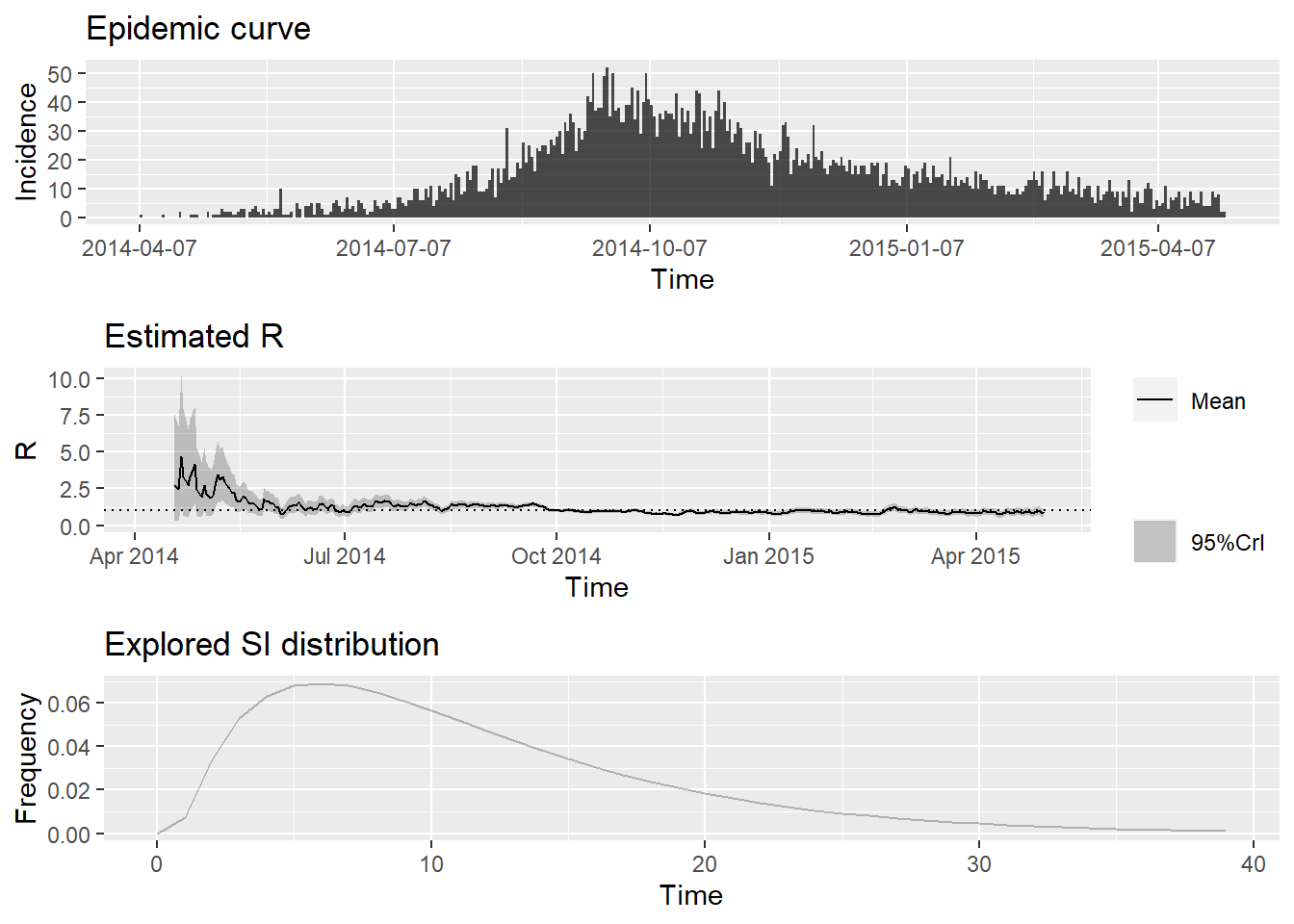
Tahmin zaman pencerelerini belirtme
Bu varsayılan seçenekler, haftalık kayan bir tahmin sağlar ve kesin bir tahmin için Rt’ı salgında çok erken tahmin ettiğinize dair bir uyarı görevi görebilir. Aşağıda gösterildiği gibi tahmin için daha ileri bir başlangıç tarihi ayarlayarak bunu değiştirebilirsiniz. Ne yazık ki, EpiEstim, her zaman penceresi için başlangıç ve bitiş tarihlerine atıfta bulunan bir tam sayı vektörü sağlamanız gerektiğinden, bu tahmin sürelerini belirtmek için yalnızca çok hantal bir yol sağlar.
## 1 Haziran'da başlayan bir tarih vektörü tanımlayın
start_dates <- seq.Date(
as.Date("2014-06-01"),
max(cases$dates) - 7,
by = 1
) %>%
## sayısala dönüştürmek için başlangıç tarihini çıkarın
`-`(min(cases$dates)) %>%
## tam sayıya çevirin
as.integer()
## bir haftalık sürgülü pencere protokolüne altı gün ekleyin
end_dates <- start_dates + 6
## yapılandırma yap
config_partial <- make_config(
mean_si = 12.0,
std_si = 5.2,
t_start = start_dates,
t_end = end_dates
)Şimdi EpiEstim’i yeniden çalıştırıyoruz ve tahminlerin yalnızca Haziran’dan itibaren başladığını görebiliyoruz:
## epiestim'i çalıştır
epiestim_res_partial <- estimate_R(
incid = cases,
method = "parametric_si",
config = config_partial
)
## çıktıları grafikleştir
plot(epiestim_res_partial)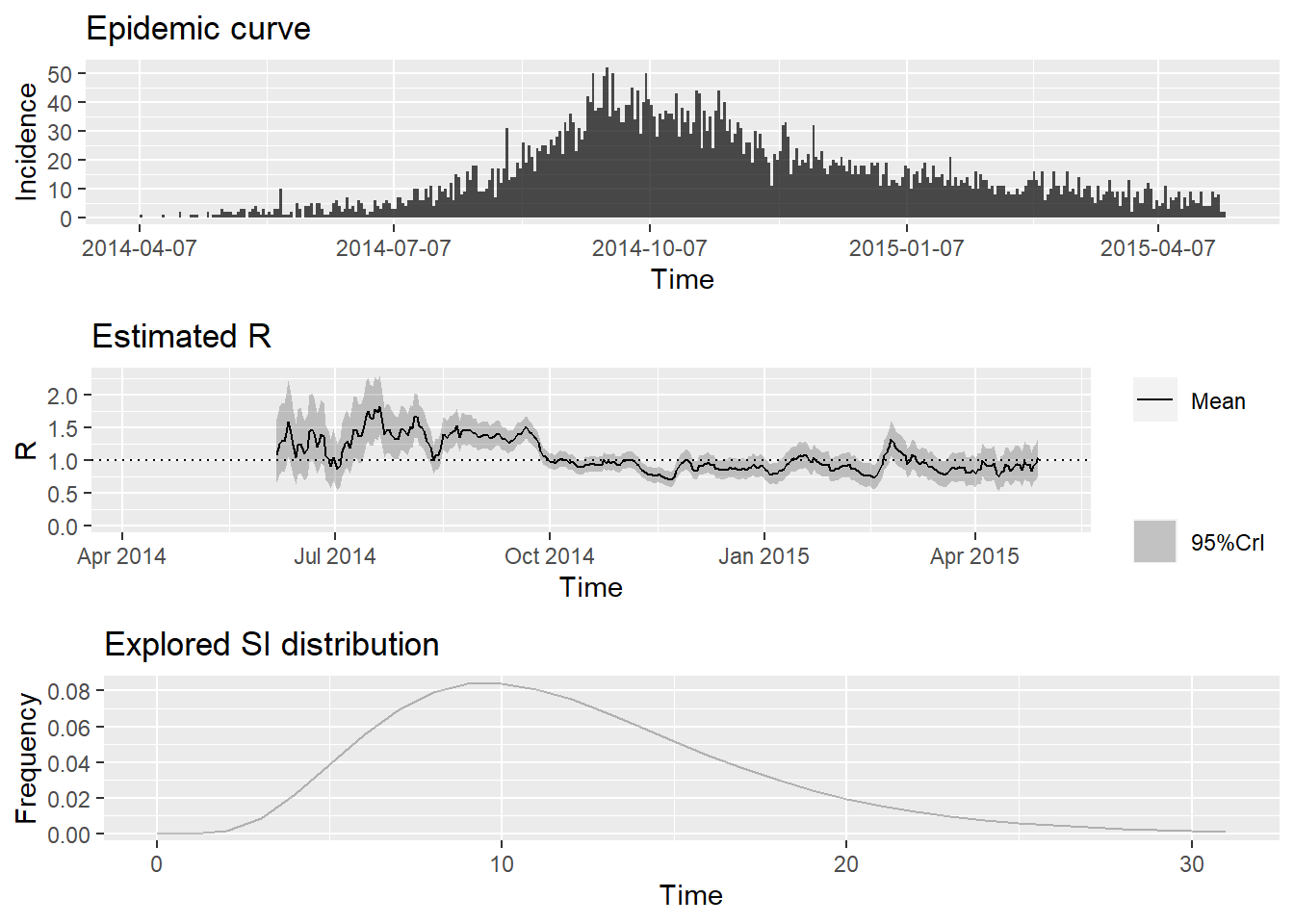
Çıktıları analiz etme
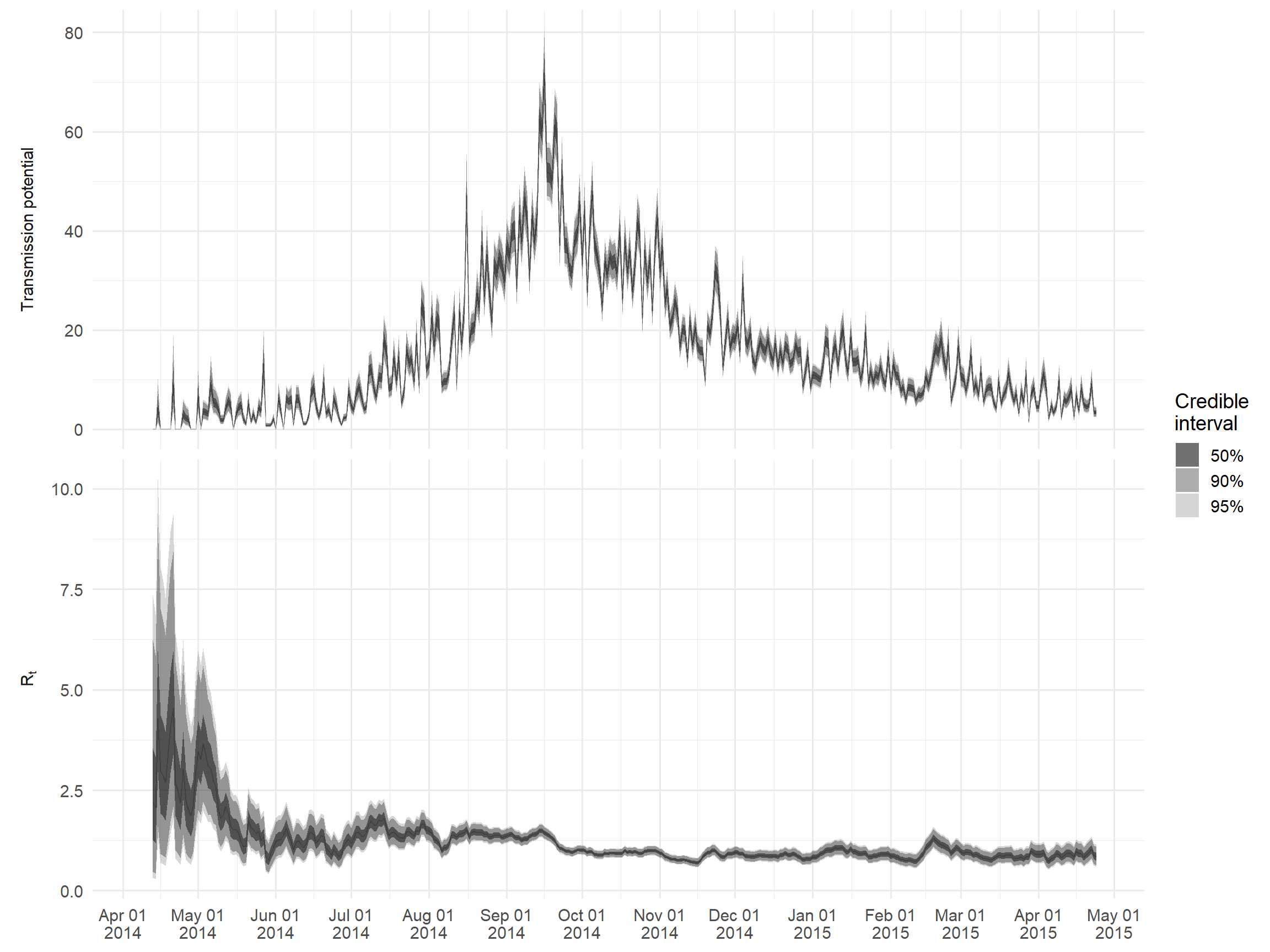
Ana çıkışlara $R üzerinden erişilebilir. Örnek olarak, bir Rt grafiği ve Rt çarpımı ve o gün rapor edilen vaka sayısı tarafından verilen bir “iletim potansiyeli” ölçüsü oluşturacağız. Bu, yeni nesil enfeksiyonda beklenen vaka sayısını temsil eder.
## medyan için geniş veri çerçevesi yapın
df_wide <- epiestim_res_lit$R %>%
rename_all(clean_labels) %>%
rename(
lower_95_r = quantile_0_025_r,
lower_90_r = quantile_0_05_r,
lower_50_r = quantile_0_25_r,
upper_50_r = quantile_0_75_r,
upper_90_r = quantile_0_95_r,
upper_95_r = quantile_0_975_r,
) %>%
mutate(
## medyan tarihini t_start ve t_end'den çıkarın
dates = epiestim_res_emp$dates[round(map2_dbl(t_start, t_end, median))],
var = "R[t]"
) %>%
## günlük insidans verilerinde birleştirme
left_join(cases, "dates") %>%
## tüm r tahminlerinde riski hesapla
mutate(
across(
lower_95_r:upper_95_r,
~ .x*I,
.names = "{str_replace(.col, '_r', '_risk')}"
)
) %>%
## ayrı r tahminleri ve risk tahminleri
pivot_longer(
contains("median"),
names_to = c(".value", "variable"),
names_pattern = "(.+)_(.+)"
) %>%
## faktör seviyeleri atamak
mutate(variable = factor(variable, c("risk", "r")))
## niceliklerden uzun veri çerçevesi yapmak
df_long <- df_wide %>%
select(-variable, -median) %>%
## seperate r/risk estimates and quantile levels
pivot_longer(
contains(c("lower", "upper")),
names_to = c(".value", "quantile", "variable"),
names_pattern = "(.+)_(.+)_(.+)"
) %>%
mutate(variable = factor(variable, c("risk", "r")))
## grafik yapmak
ggplot() +
geom_ribbon(
data = df_long,
aes(x = dates, ymin = lower, ymax = upper, alpha = quantile),
color = NA
) +
geom_line(
data = df_wide,
aes(x = dates, y = median),
alpha = 0.2
) +
## alt simge etiketine izin vermek için label_parsed kullanın
facet_wrap(
~ variable,
ncol = 1,
scales = "free_y",
labeller = as_labeller(c(r = "R[t]", risk = "Transmission~potential"), label_parsed),
strip.position = 'left'
) +
## nicel şeffaflığı manuel olarak tanımla
scale_alpha_manual(
values = c(`50` = 0.7, `90` = 0.4, `95` = 0.2),
labels = function(x) paste0(x, "%")
) +
labs(
x = NULL,
y = NULL,
alpha = "Credible\ninterval"
) +
scale_x_date(
date_breaks = "1 month",
date_labels = "%b %d\n%Y"
) +
theme_minimal(base_size = 14) +
theme(
strip.background = element_blank(),
strip.placement = 'outside'
)
24.4 Tahmini insidans
EpiNow2
EpiNow2, Rt tahmininin yanı sıra, başlık altındaki EpiSoon paketi ile entegrasyon yoluyla Rt tahminini ve vaka sayılarının projeksiyonlarını da destekler. Tek yapmanız gereken, ‘epinow’ fonksiyon çağrınızda, geleceğe kaç gün yansıtmak istediğinizi belirten ‘horizon’ değişkenini belirtmek; EpiNow2’nin nasıl kurulup çalıştırılacağına ilişkin ayrıntılar için “Rt Tahmini” altındaki EpiNow2 bölümüne bakabilirsiniz. Bu bölümde, “epinow_res” nesnesinde saklanan bu analizin çıktılarını çizeceğiz.
## grafik için minimum tarihi belirleyin
min_date <- as.Date("2015-03-01")
## özetlenmiş tahminleri çıkar
estimates <- as_tibble(epinow_res$estimates$summarised)
## vaka insidansı hakkında ham verileri ayıklayın
observations <- as_tibble(epinow_res$estimates$observations) %>%
filter(date > min_date)
## vaka sayılarının öngörülen tahminlerini çıkarın
df_wide <- estimates %>%
filter(
variable == "reported_cases",
type == "forecast",
date > min_date
)
## nicel çizim için daha da uzun formata dönüştürün
df_long <- df_wide %>%
## burada eşleşen nicelikleri eşleştiriyoruz (örneğin, alt_90 ila üst_90)
pivot_longer(
lower_90:upper_90,
names_to = c(".value", "quantile"),
names_pattern = "(.+)_(.+)"
)
## çizimi yapın
ggplot() +
geom_histogram(
data = observations,
aes(x = date, y = confirm),
stat = 'identity',
binwidth = 1
) +
geom_ribbon(
data = df_long,
aes(x = date, ymin = lower, ymax = upper, alpha = quantile),
color = NA
) +
geom_line(
data = df_wide,
aes(x = date, y = median)
) +
geom_vline(xintercept = min(df_long$date), linetype = 2) +
## nicel şeffaflığı manuel olarak tanımla
scale_alpha_manual(
values = c(`20` = 0.7, `50` = 0.4, `90` = 0.2),
labels = function(x) paste0(x, "%")
) +
labs(
x = NULL,
y = "Daily reported cases",
alpha = "Credible\ninterval"
) +
scale_x_date(
date_breaks = "1 month",
date_labels = "%b %d\n%Y"
) +
theme_minimal(base_size = 14)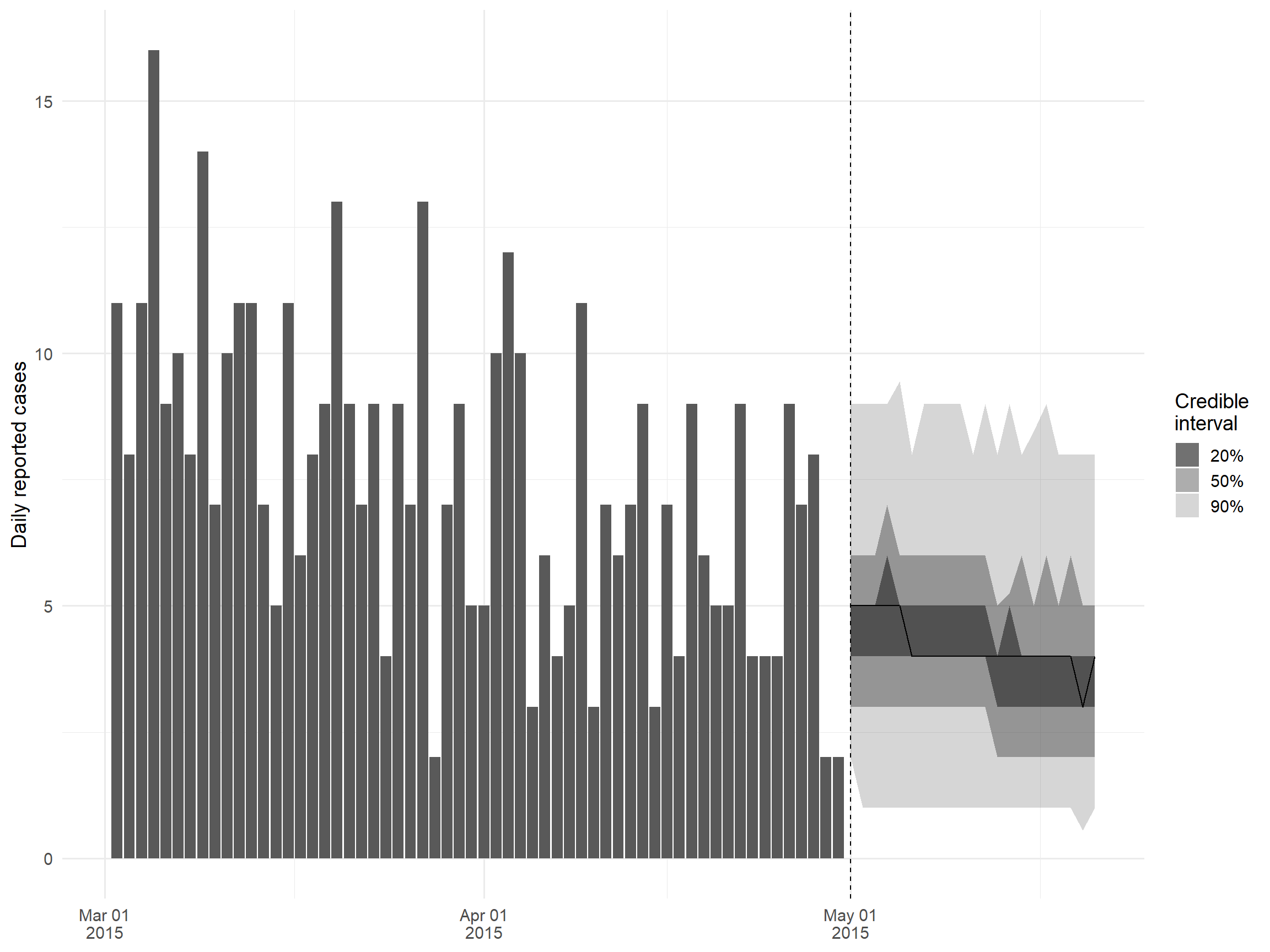
Projeksiyonlar
RECON tarafından geliştirilen projeksiyonlar paketi, etkin üreme sayısı Rt ve seri aralığı hakkında bilgi gerektiren kısa vadeli insidans tahminleri yapmayı çok kolaylaştırır. Burada literatürden seri aralık tahminlerinin nasıl kullanılacağını ve satır listesinden kendi tahminlerimizin nasıl kullanılacağını ele alacağız.
Literatürden seri aralık tahminlerini kullanma
projeksiyonlar, discrete paketinden ‘discrete’ sınıfının ayrık bir seri aralık dağılımını gerektirir. Bu yazıda tanımlanan ortalama 12.0 ve standart sapması 5.2 olan bir gama dağılımı kullanacağız. Bu değerleri bir gama dağılımı için gereken şekil ve ölçek parametrelerine dönüştürmek için, epitrix paketindeki ‘gamma_mucv2shapescale’ fonkdiyonunu kullanacağız.
## ortalama mu ve katsayısından şekil ve ölçek parametreleri alın
## varyasyon (ör. standart sapmanın ortalamaya oranı)
shapescale <- epitrix::gamma_mucv2shapescale(mu = 12.0, cv = 5.2/12)
## ayrık nesne yapmak
serial_interval_lit <- distcrete::distcrete(
name = "gamma",
interval = 1,
shape = shapescale$shape,
scale = shapescale$scale
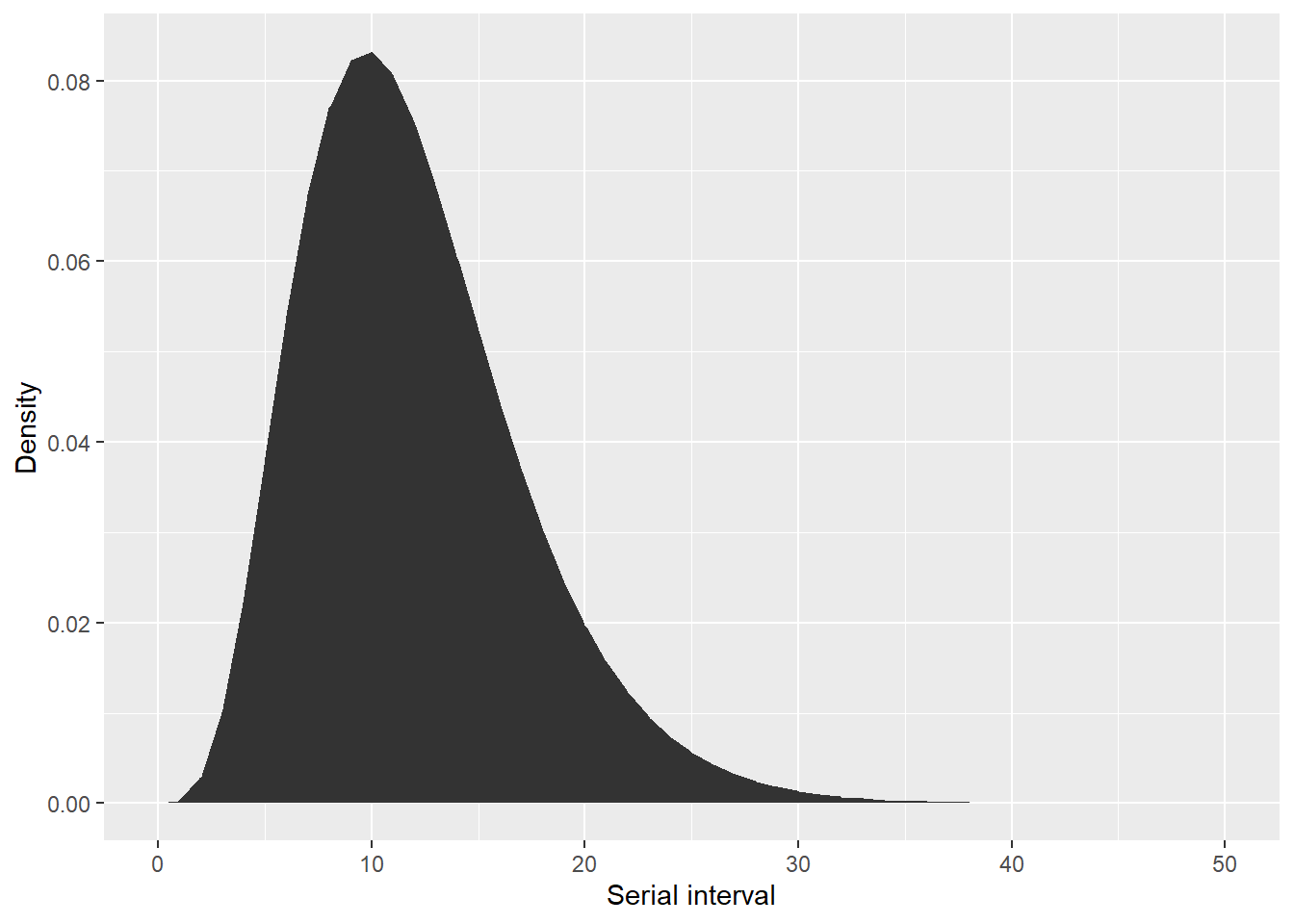
)İşte seri aralığın doğru göründüğünden emin olmak için hızlı bir kontrol. Az önce tanımladığımız gama dağılımının yoğunluğuna, ‘dgamma’ çağırmaya eşdeğer olan ‘$d’ ile erişiriz:
## seri aralığın doğru göründüğünden emin olmak için kontrol edin
qplot(
x = 0:50, y = serial_interval_lit$d(0:50), geom = "area",
xlab = "Serial interval", ylab = "Density"
)
Verilerinden seri aralık tahminlerini kullanma
Semptom başlangıç tarihlerine ve iletim bağlantılarına ilişkin verilere sahip olduğumuz için, bulaştırıcı-enfekte çiftlerinin başlangıç tarihleri arasındaki gecikmeyi hesaplayarak satır listesinden seri aralığı da tahmin edebiliriz. EpiNow2 bölümünde yaptığımız gibi, epicontacts paketindeki get_pairwise fonksiyonunu kullanacağız. Bu da iletim çiftleri arasındaki satır listesi özelliklerinin ikili farklarını hesaplamamıza izin verir. Önce bir epicontacts nesnesi oluşturuyoruz (daha fazla ayrıntı için İletim zincirleri sayfasına bakabilirsiniz:
## kişileri üretin
contacts <- linelist %>%
transmute(
from = infector,
to = case_id
) %>%
drop_na()
## temaslı kişileri üretin
epic <- make_epicontacts(
linelist = linelist,
contacts = contacts,
directed = TRUE
)Daha sonra iletim çiftleri arasındaki başlangıç tarihlerindeki farkı bir gama dağılımına uydururuz, “get_pairwise” kullanarak hesaplarız. Ayrık bir dağıtım gerektirdiğinden, bu yerleştirme prosedürü için epitrix paketindeki kullanışlı ’fit_disc_gamma’yı kullanıyoruz.
## gama seri aralığını tahmin et
serial_interval <- fit_disc_gamma(get_pairwise(epic, "date_onset"))
## tahmini inceleme
serial_interval[c("mu", "sd")]## $mu
## [1] 11.51242
##
## $sd
## [1] 7.700005Tahmini insidans
Gelecekteki vakaları tahmin etmek için, yine de bir “insidans” nesnesi şeklinde tarihsel vakayı ve ayrıca makul Rt değerleri örneğini sağlamamız gerekiyor. Bu değerleri, önceki bölümde (“Tahmini Rt” başlığı altında) EpiEstim tarafından oluşturulan ve ‘epiestim_res_emp’ nesnesi içinde depolanan Rt tahminlerini kullanarak üreteceğiz. Aşağıdaki kodda, Rt için ortalama ve standart sapma tahminlerini çıkarıyoruz. Salgının son zaman penceresi (bir vektördeki son öğeye erişmek için “tail” fonksiyonunu kullanarak) ve “rgamma” kullanarak bir gama dağılımından 1000 değeri simüle edin. İleriye dönük projeksiyonlar için kullanmak istediğiniz kendi Rt değerleri vektörünüzü de sağlayabilirsiniz.
## başlangıç tarihlerinden insidans nesnesi oluşturun
inc <- incidence::incidence(linelist$date_onset)## 256 missing observations were removed.
## en son tahminden makul r değerleri çıkar
mean_r <- tail(epiestim_res_emp$R$`Mean(R)`, 1)
sd_r <- tail(epiestim_res_emp$R$`Std(R)`, 1)
shapescale <- gamma_mucv2shapescale(mu = mean_r, cv = sd_r/mean_r)
plausible_r <- rgamma(1000, shape = shapescale$shape, scale = shapescale$scale)
## dağıtımı kontrol et
qplot(x = plausible_r, geom = "histogram", xlab = expression(R[t]), ylab = "Counts")## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.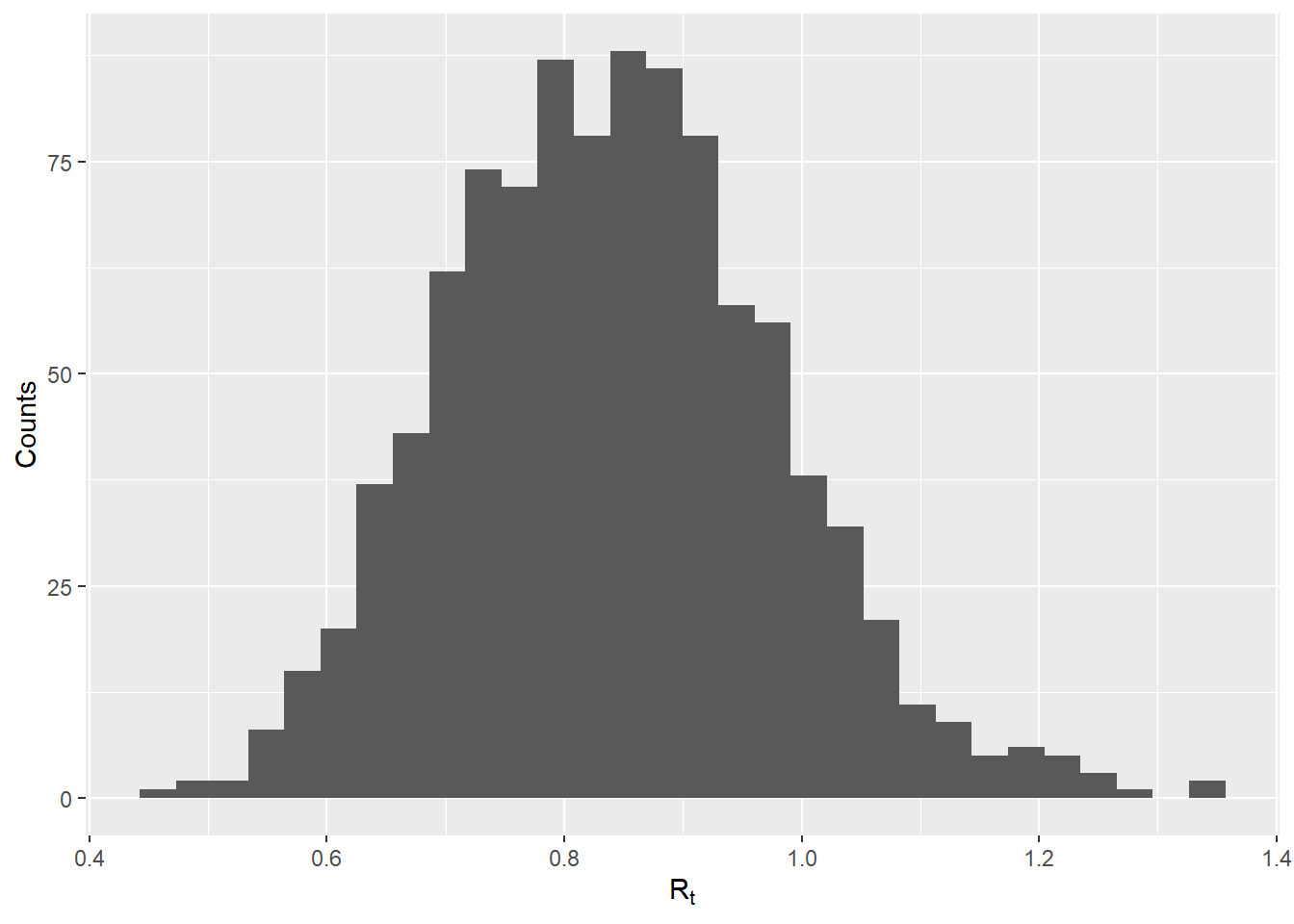
Daha sonra gerçek tahmini yapmak için project() fonksiyonunu kullanırız. ‘n_days’ değişkenleri ile kaç gün için projeksiyon yapmak istediğimizi ve ‘n_sim’ değişkeni kullanarak simülasyonların sayısını belirliyoruz.
## projeksiyon yapma
proj <- project(
x = inc,
R = plausible_r,
si = serial_interval$distribution,
n_days = 21,
n_sim = 1000
)Daha sonra ‘plot()’ ve ‘add_projections()’ fonksiyonlarını kullanarak insidansı ve projeksiyonları kolayca çizebiliriz. Köşeli parantez operatörünü kullanarak yalnızca en son durumları göstermek için ‘insidans’ nesnesini kolayca alt kümeye koyabiliriz.
## insidans ve projeksiyon çizimi
plot(inc[inc$dates > as.Date("2015-03-01")]) %>%
add_projections(proj)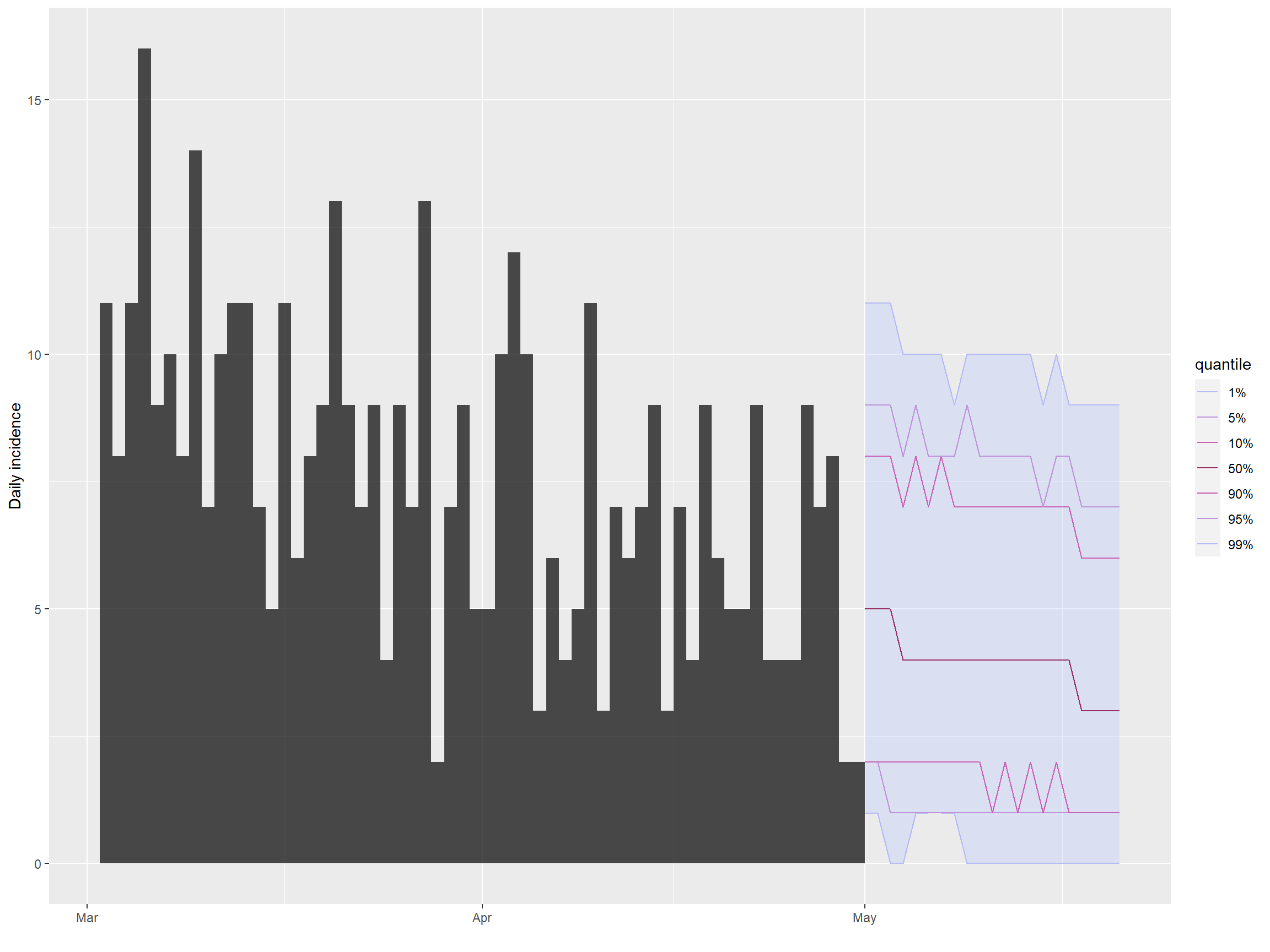
Çıktıyı bir veri çerçevesine dönüştürerek günlük vaka sayılarının ham tahminlerini de kolayca çıkarabilirsiniz.
## ham veriler için veri çerçevesine dönüştür
proj_df <- as.data.frame(proj)
proj_df