20 Eksik Veri
Bu sayfada aşağıdakilerin nasıl yapılacağı anlatılacaktır:
- Eksikliği değerlendirin
- Eksikliğe göre satırları filtreleyin
- Zaman içinde eksikleri çizin
- Grafiklerde “Boş Veri”nin nasıl görüntüleneceğini ele alın
- Eksik değer atamasını gerçekleştirin: MCAR, MAR, MNAR
20.1 Hazırlık
Paketleri yükleyin
Bu kod parçası, analizler için gerekli olan paketlerin yüklenmesini gösterir. Bu el kitabında, gerekirse paketi kuran ve kullanım için yükleyen pacman’dan p_load() vurgusunu yapıyoruz. base R’dan library() ile kurulu paketleri de yükleyebilirsiniz. R paketleri hakkında daha fazla bilgi için [R basics] sayfasına bakabilirsiniz.
pacman::p_load(
rio, # İçe aktar/Dışa aktar
tidyverse, # Veri yönetimi ve görselleştirme
naniar, # Eksikliği değerlendir ve görselleştir
mice # Eksik veri yerine aktarma
)Verileri içe aktar
Simüle edilmiş bir Ebola salgınından vakaların veri setini içe aktarıyoruz. Takip etmek isterseniz, “clean” satır listesi dosyasını indirmek için tıklayın (.rds dosyası olarak). Verilerinizi rio paketinden import() fonksiyonuyla içe aktarın (.xlsx, .rds, .csv gibi birçok dosya türünü kabul eder - ayrıntılar için [İçe aktarma ve dışa aktarma] sayfasına bakabilirsiniz).
# Satır listesini içe aktar
linelist <- import("linelist_cleaned.rds")Satır listesinin ilk 50 satırı aşağıda görüntülenmektedir.
İçe aktarma işleminde eksikliği dönüştürme
Verilerinizi içe aktarırken, eksik olarak sınıflandırılması gereken değerlerin farkında olun. Örneğin, 99, 999, “Eksik”, boş hücreler (““) veya boşluklu hücreler (” “). Veri içe aktarma komutu sırasında bunları ’NA’ya (R’ın eksik veri sürümü) dönüştürebilirsiniz. Tam sözdizimi dosya türüne göre değiştiğinden, ayrıntılar için Eksik veriler ile ilgili sayfanın içe aktarılmasıyla ilgili sayfaya bakın.
20.2 R’da eksik değerler
Aşağıda, bazı bitişik değerler ve fonksiyonlarla birlikte, R’da eksikliğin sunulma ve değerlendirilme yollarını araştırıyoruz.
“NA”
R’da, eksik değerler ‘NA’ ile temsil edilir. Bunun * tırnak işaretleri olmadan * yazıldığını unutmayın. “NA” farklıdır ve sadece normal bir karakter değeridir (aynı zamanda Beatles’ın Hey Jude şarkısından bir söz).
Verilerinizin “99” veya “Eksik” veya “Bilinmeyen” gibi eksikleri temsil etmenin başka yolları olabilir - “boş” görünen boş karakter değerini “” veya tek bir boşluk ” ” bile olabilir. Bunların farkında olun ve içe aktarma sırasında bunları ’NA’ya dönüştürün veya ‘na_if()’ ile veri temizleme sırasında yapabilirsiniz.
Veri temizleme işleminizde, tüm ‘NA’ları “Eksik” veya ’replace_na()’ya benzer şekilde veya faktörler için ’fct_explicit_na()’ ile de değiştirmek isteyebilirsiniz.
“NA” sürümleri
Çoğu zaman, “NA” eksik bir değeri temsil eder ve her şey yolunda gider. Ancak, bazı durumlarda, bir nesne sınıfına (karakter, sayısal, vb.) özgü “NA”nın varyasyonları gereksinimiyle karşılaşabilirsiniz. Bu nadiren olacak, ancak bilmenizde fayda vardır. Bunun için tipik senaryo, dplyr fonksiyonu “case_while()” ile yeni bir sütun oluştururken gerçekleşmektedir. Verileri ve temel fonksiyonları temizleme sayfasında açıklandığı gibi, bu fonksiyon veri çerçevesindeki her satırı değerlendirir, satırların belirtilen mantıksal ölçütlerini (kodun sağ tarafı) karşılayıp karşılamadığını değerlendirir ve doğru yeni değerini atar ( kodun sol tarafı). Önemli olan: sağ taraftaki tüm değerler aynı sınıf olmalıdır.
linelist <- linelist %>%
# "Yaş" sütunundan yeni "yaş_yıl" sütununu oluştur
mutate(age_years = case_when(
age_unit == "years" ~ age, # eğer yaş yıl şeklinde verildiyse, orijinal değeri atayın
age_unit == "months" ~ age/12, # eğer yaş ay şeklinde verildiyse, 12'ye bölün
is.na(age_unit) ~ age, # eğer yaş birimi eksikse, yılmış gibi kabul edin
TRUE ~ NA_real_)) # diğer durumlarda kayıp veri olarak atayınSağ tarafta ‘NA’ istiyorsanız, aşağıda listelenen özel ‘NA’ seçeneklerinden birini belirtmeniz gerekebilir. Diğer sağ taraftaki değerler karakter ise, bunun yerine “Missing” kullanmayı düşünün veya aksi takdirde “NA_character_” kullanın. Hepsi sayısal ise, ‘NA_real_’ kullanın. Hepsi tarih veya mantıklıysa, ‘NA’ kullanabilirsiniz.
-
NA- tarihler veya mantıksal DOĞRU/YANLIŞ için kullanın -
NA_character_- karakterler için kullanın -
NA_real_- sayısal değerler için kullanın
Yine, yeni bir sütun oluşturmak için case_while() kullanmıyorsanız bu varyasyonlarla karşılaşmanız pek olası değildir. Daha fazla bilgi için NA ile ilgili R belgelerine bakabilirsiniz.
‘NULL’
‘NULL’, R’dan ayrılmış başka bir değerdir. Bu, ne doğru ne de yanlış olan bir ifadenin mantıksal temsilidir. Değerleri tanımsız olan ifadeler veya fonksiyonlar tarafından döndürülür. Belirli senaryolarda “NULL” döndürmek için fonksiyon yazmadıkça veya belki de [shiny uygulaması][Shiny Panoları] yazmadıkça NULL değerini genellikle bir değer olarak atamayın.
Boşluk is.null() kullanılarak değerlendirilebilir ve as.null() ile dönüşüm yapılabilir.
“NULL” ve “NA” arasındaki farkla ilgili bu blog gönderisine bakabilirsiniz.
NaN
İmkansız değerler “NaN” özel değeri ile temsil edilir. Bunun bir örneği, R’ı 0’ı 0’a bölmeye zorlamanızdır. Bunu is.nan() ile değerlendirebilirsiniz. “is.infinite()” ve “is.finite()” gibi tamamlayıcı fonksiyonlarla da karşılaşabilirsiniz.
“Inf”
“Inf”, örneğin bir sayıyı 0’a böldüğünüzde olduğu gibi sonsuz bir değeri temsil eder.
Bunun işinizi nasıl etkileyebileceğine dair bir örnek olarak: Diyelim ki şu değerleri içeren bir “z” vektörünüz/sütununuz var: “z <- c(1, 22, NA, Inf, NaN, 5)”
En yüksek değeri bulmak için sütunda ‘max()’ kullanmak istiyorsanız, ‘NA’yı hesaplamadan çıkarmak için ’na.rm = TRUE’yu kullanabilirsiniz, ancak ’Inf’ ve ‘NaN’ arta kalacak ve Inf döndürülecektir. Bunu çözmek için, hesaplamada yalnızca sonlu değerlerin kullanılacağı şekilde alt kümeler için “[ ]” ve “is.finite()” köşeli parantezlerini kullanabilirsiniz: “max(z[is.finite(z)])”.
Örnekler
| R Komutları | Çıktısı |
|---|---|
5 / 0 |
Inf |
0 / 0 |
NaN |
5 / NA |
NA |
5 / Inf |0|NA|Inf| "logical"class(NaN)| "numeric"class(Inf)| "numeric"class(NULL)` |
“NULL” |
“Zorlamanın getirdiği NA’lar” yaygın bir uyarı mesajıdır. Bu, aksi takdirde sayısal olan bir vektöre karakter değeri eklemek gibi geçersiz bir dönüştürme yapmaya çalışırsanız olabilir.
as.numeric(c("10", "20", "thirty", "40"))## Warning: NAs introduced by coercion## [1] 10 20 NA 40Bir vektörde “NULL” yok sayılır.
my_vector <- c(25, NA, 10, NULL) # tanımla
my_vector # yazdır## [1] 25 NA 10Bir sayının varyansı “NA” ile sonuçlanır.
var(22)## [1] NA20.3 Faydalı fonksiyonları
Aşağıdakiler, eksik değerleri değerlendirirken veya işlerken yararlı base R fonksiyonlarıdır:
is.na() ve !is.na()
Eksik değerleri belirlemek için is.na() kullanın veya eksik olmayan değerleri belirlemek için tersini (önde ! ile) kullanın. Bunların her ikisi de mantıksal bir değer (“DOĞRU” veya “YANLIŞ”) döndürür. ‘DOĞRU’ sayısını saymak için elde edilen vektörü ‘sum()’ ile toplayabileceğinizi unutmayın, ör. sum(is.na(linelist$date_outcome)).
## [1] FALSE FALSE FALSE TRUE FALSE TRUE FALSE
!is.na(my_vector)## [1] TRUE TRUE TRUE FALSE TRUE FALSE TRUE## [1] 2
na.omit()
Bu fonksiyon, bir veri çerçevesine uygulanırsa, herhangi bir eksik değere sahip satırları kaldıracaktır. Aynı zamanda base R’dandır. Bir vektöre uygulanırsa, uygulandığı vektörden ‘NA’ değerlerini kaldıracaktır. Örneğin:
na.omit(my_vector)## [1] 1 4 56 5 22
## attr(,"na.action")
## [1] 4 6
## attr(,"class")
## [1] "omit"
drop_na()
Bu, [veri temizleme ardışık düzeninde][Verileri ve temel fonksiyonları temizleme] yararlı olan bir tidyr fonksiyonudur. Parantezler boş olarak çalıştırılırsa, herhangi bir eksik değeri olan satırları kaldırır. Sütun adları parantez içinde belirtilirse, bu sütunlarda eksik değerlere sahip satırlar atlanır. Sütunları belirtmek için “tidyselect” sözdizimini de kullanabilirsiniz.
na.rm = DOĞRU
‘max()’, ‘min()’, ‘sum()’ veya ‘mean()’ gibi bir matematiksel işlevi çalıştırdığınızda, herhangi bir ‘NA’ değeri mevcutsa, döndürülen değer ‘NA’ olacaktır. Bu varsayılan davranış kasıtlıdır, böylece verilerinizden herhangi biri eksikse uyarılırsınız.
Hesaplamadan eksik değerleri kaldırarak bunu önleyebilirsiniz. Bunu yapmak için “na.rm = TRUE” bağımsız değişkenini ekleyin (“na.rm”, “NA”yı kaldır” anlamına gelir).
## [1] NA
mean(my_vector, na.rm = TRUE)## [1] 17.620.4 Bir veri çerçevesindeki eksikliği değerlendir
naniar paketini, “linelist” veri çerçevesindeki eksiklikleri değerlendirmek ve görselleştirmek için kullanabilirsiniz.
# paketi kurun ve/veya yükleyin
pacman::p_load(naniar)Eksikliği ölçme
Eksik olan tüm değerlerin yüzdesini bulmak için pct_miss() kullanın. Eksik değerlerin sayısını almak için n_miss() kullanın.
# eksik TÜM veri çerçevesi değerlerinin yüzdesi
pct_miss(linelist)## [1] 6.688745Aşağıdaki iki fonksiyon, sırasıyla herhangi bir eksik değere sahip veya tamamen tamamlanmış satırların yüzdesini döndürür. “NA”nın eksik anlamına geldiğini ve `"" veya " " eksik olarak sayılamayacağını unutmayın.
# Herhangi bir değeri eksik olan satırların yüzdesi
pct_miss_case(linelist) # sayımlar için n_complete() kullanın## [1] 69.12364
# Tamamlanan satırların yüzdesi (eksik değer yok)
pct_complete_case(linelist) # sayımlar için n_complete() kullanın## [1] 30.87636Eksikliği görselleştirme
gg_miss_var() fonksiyonu size her sütundaki eksik değerlerin sayısını (veya %) gösterecektir. Birkaç nüans:
- Gruplara göre grafiği görmek için
facet =değişkenlerine bir sütun adı (tırnak içinde değil) ekleyebilirsiniz. - Varsayılan olarak, yüzdeler yerine sayılar gösterilir, bunu
show_pct = TRUEile değiştirin -
+ labs(...)ile normal birggplot()için olduğu gibi eksen ve başlık etiketleri ekleyebilirsiniz.
gg_miss_var(linelist, show_pct = TRUE)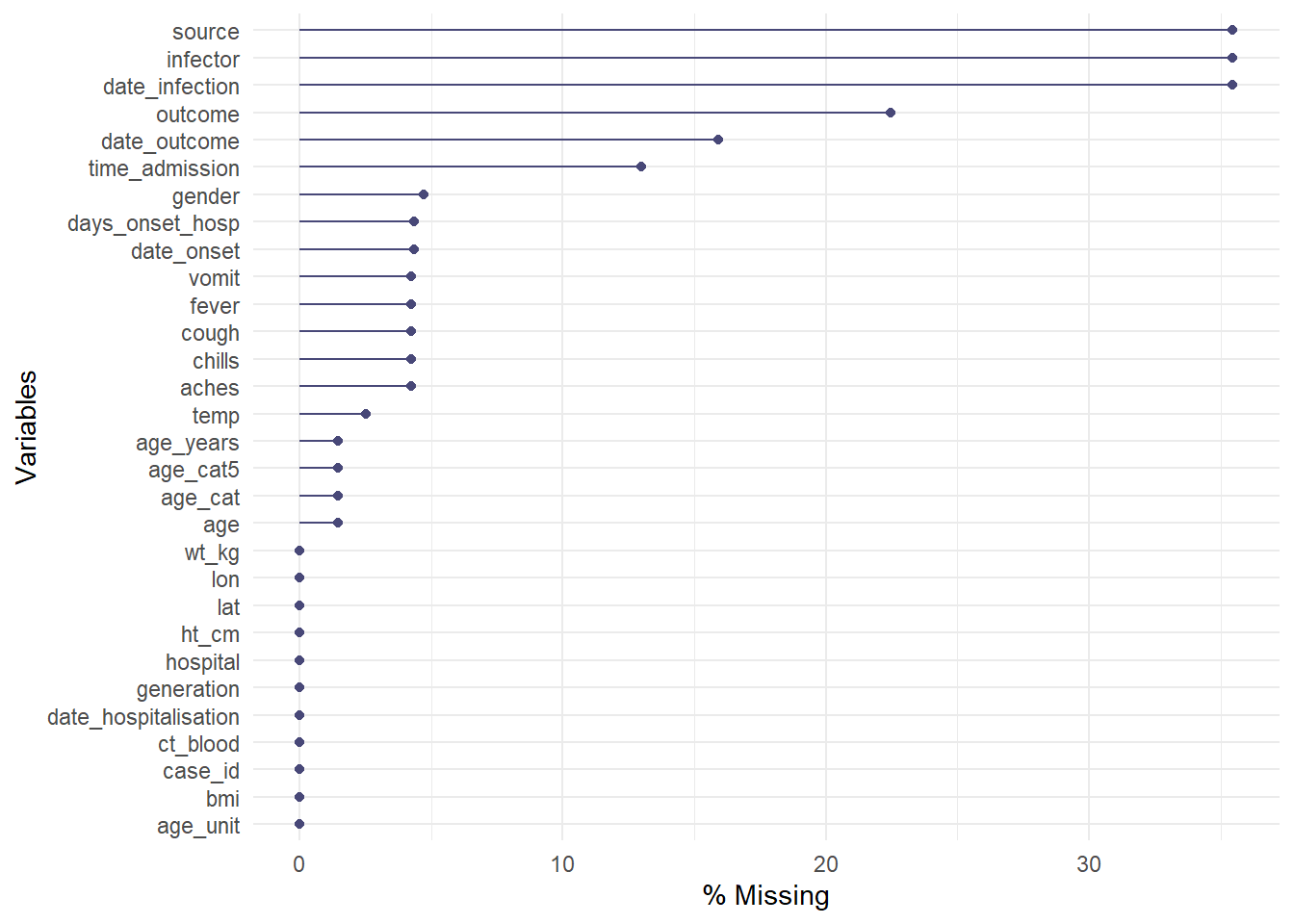
Burada veriler fonksiyona %>% yoluyla tünellenerek iletilir. facet = değişkeni ayrıca verileri bölmek için kullanılır.
linelist %>%
gg_miss_var(show_pct = TRUE, facet = outcome)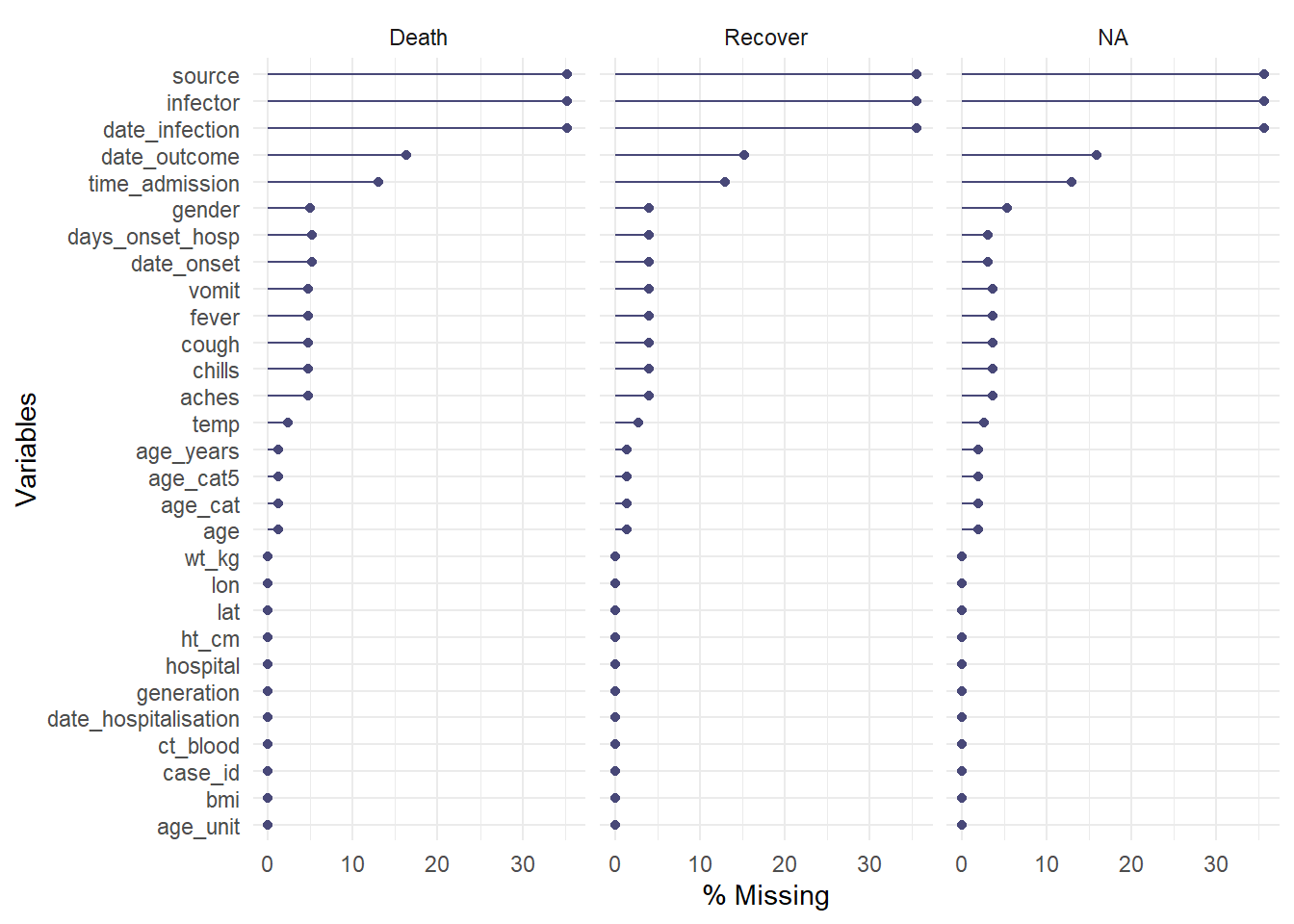
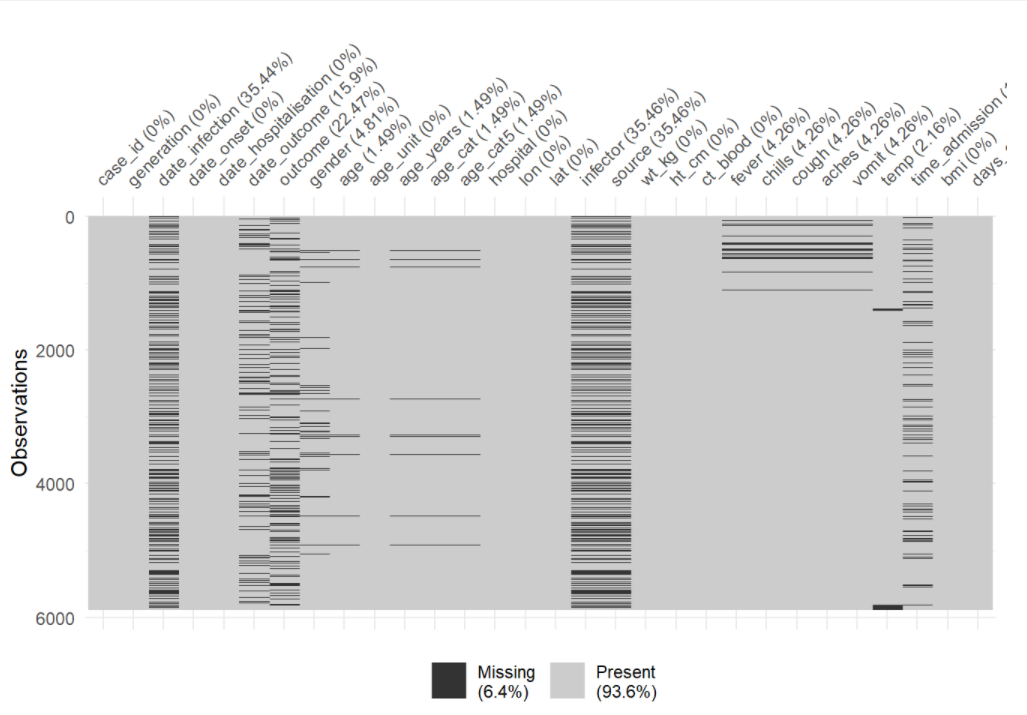
Veri çerçevesini her bir değerin eksik olup olmadığını gösteren bir ısı haritası olarak görselleştirmek için vis_miss()‘i kullanabilirsiniz. Ayrıca veri çerçevesinden belirli sütunları ’select()’ ile seçerek, yalnızca bu sütunların gösterilmesini sağlayabilirsiniz.
# Tüm veri çerçevesindeki eksikliğin ısı grafiği
vis_miss(linelist)
Eksiklik ilişkilerini keşfedin ve görselleştirin
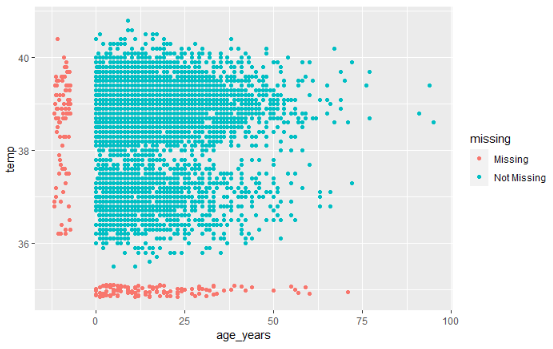
Olmayan bir şeyi nasıl görselleştirirsiniz??? Varsayılan olarak, “ggplot()” grafiklerden eksik değerlere sahip noktaları kaldırır.
naniar, geom_miss_point() aracılığıyla bir çözüm sunar. İki sütunlu bir dağılım grafiği oluştururken, değerlerden biri eksik, diğeri mevcut olan kayıtlar, eksik değerler sütundaki en düşük değerden %10 daha düşük olarak ayarlanarak ve belirgin bir şekilde renklendirilerek gösterilir.
Aşağıdaki dağılım grafiğinde kırmızı noktalar, bir sütunun değerinin mevcut olduğu ancak diğer sütunun değerinin eksik olduğu kayıtlardır. Bu, eksik değerlerin eksik olmayan değerlere göre dağılımını görmenizi sağlar.
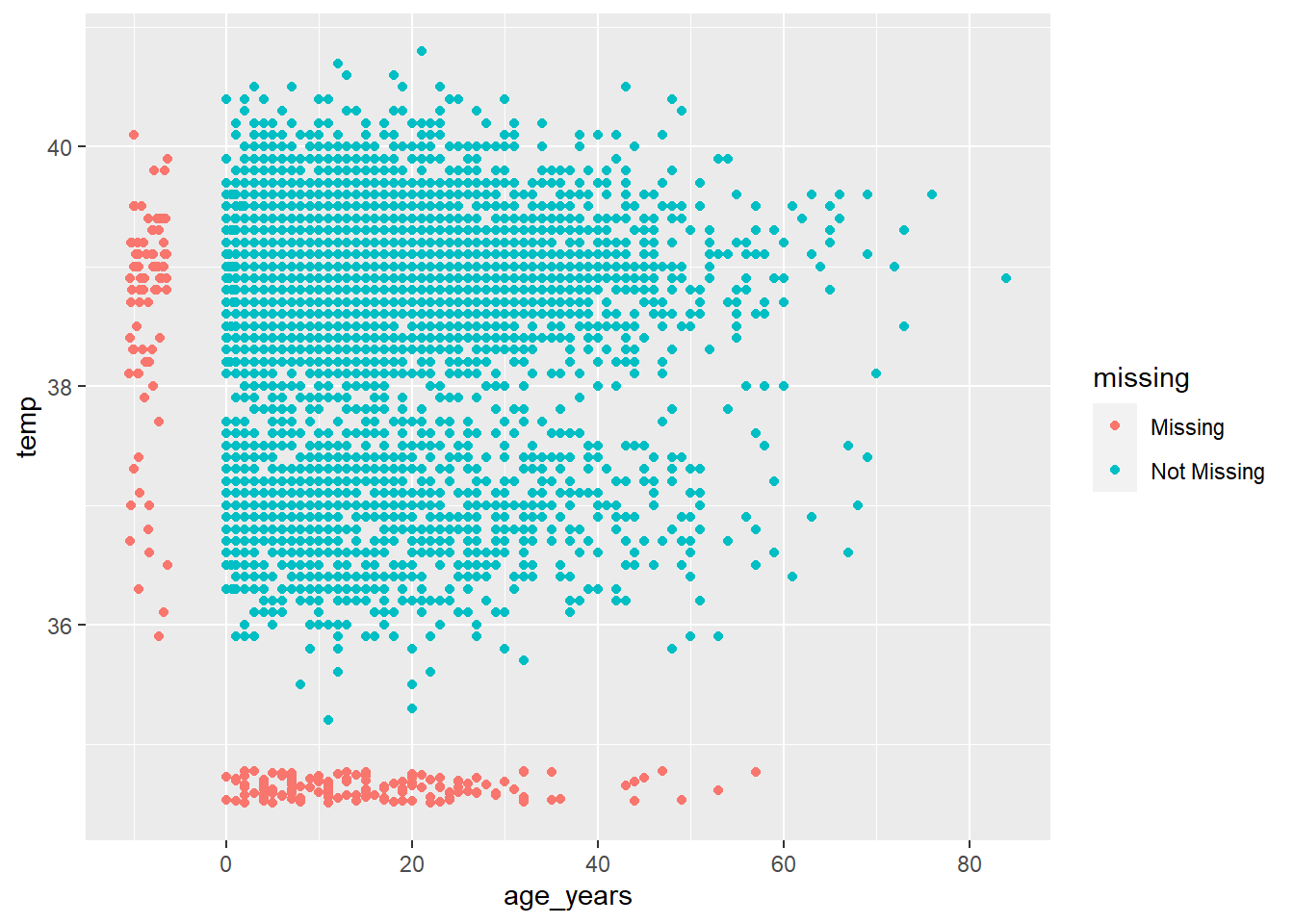
Veri çerçevesindeki başka bir sütun tarafından katmanlandırılmış eksiklikleri değerlendirmek için, veri çerçevesindeki bir yüzdelik ısı haritasını bir faktör/kategorik (veya tarih) sütun ile döndüren ‘gg_miss_fct()’ fonksiyonu ile sağlayın:
gg_miss_fct(linelist, age_cat5)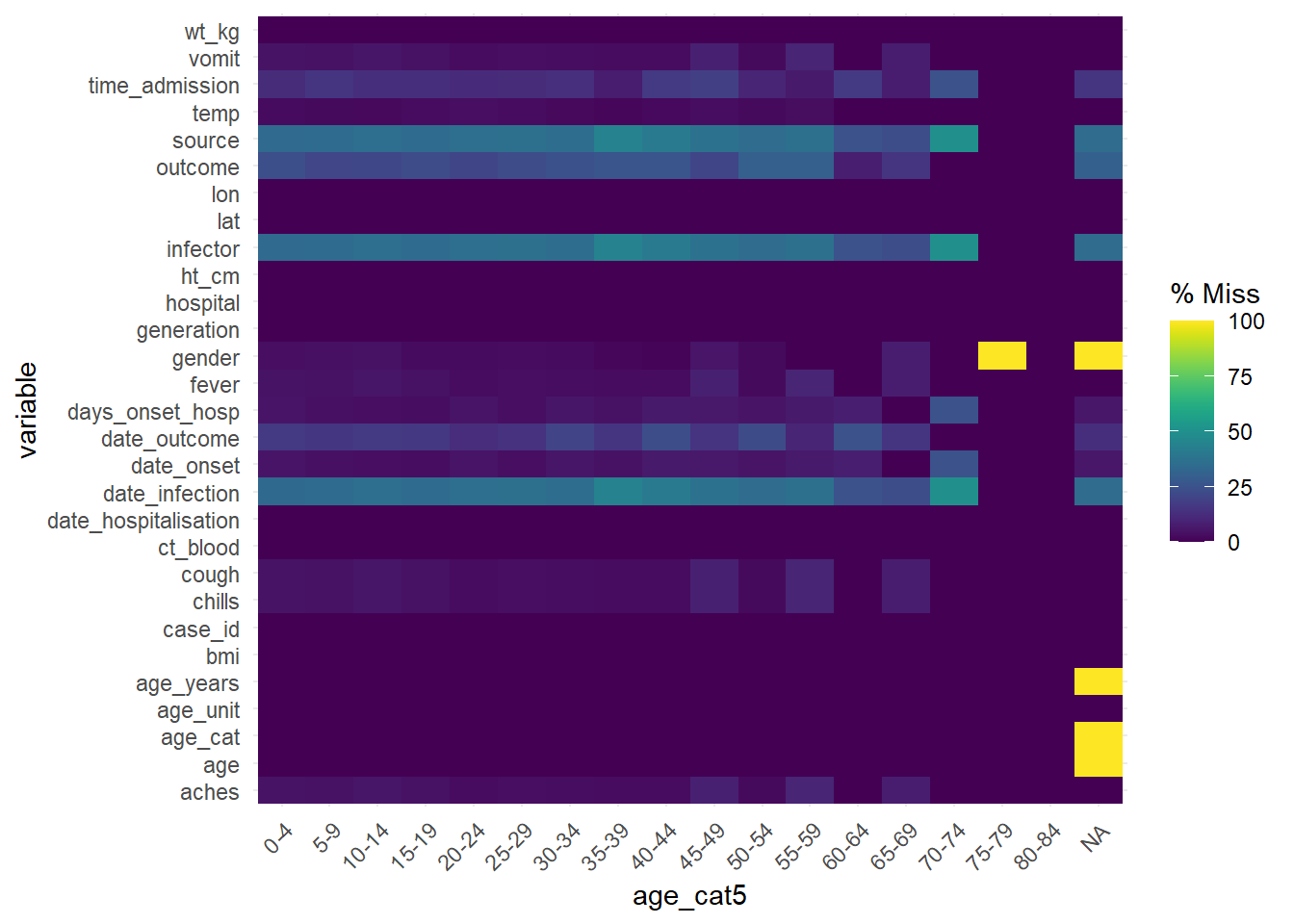
Bu fonksiyon, eksiklerin zaman içinde nasıl değiştiğini görmek için bir tarih sütunu ile de kullanılabilir:
gg_miss_fct(linelist, date_onset)## Warning: Removed 29 rows containing missing values (`geom_tile()`).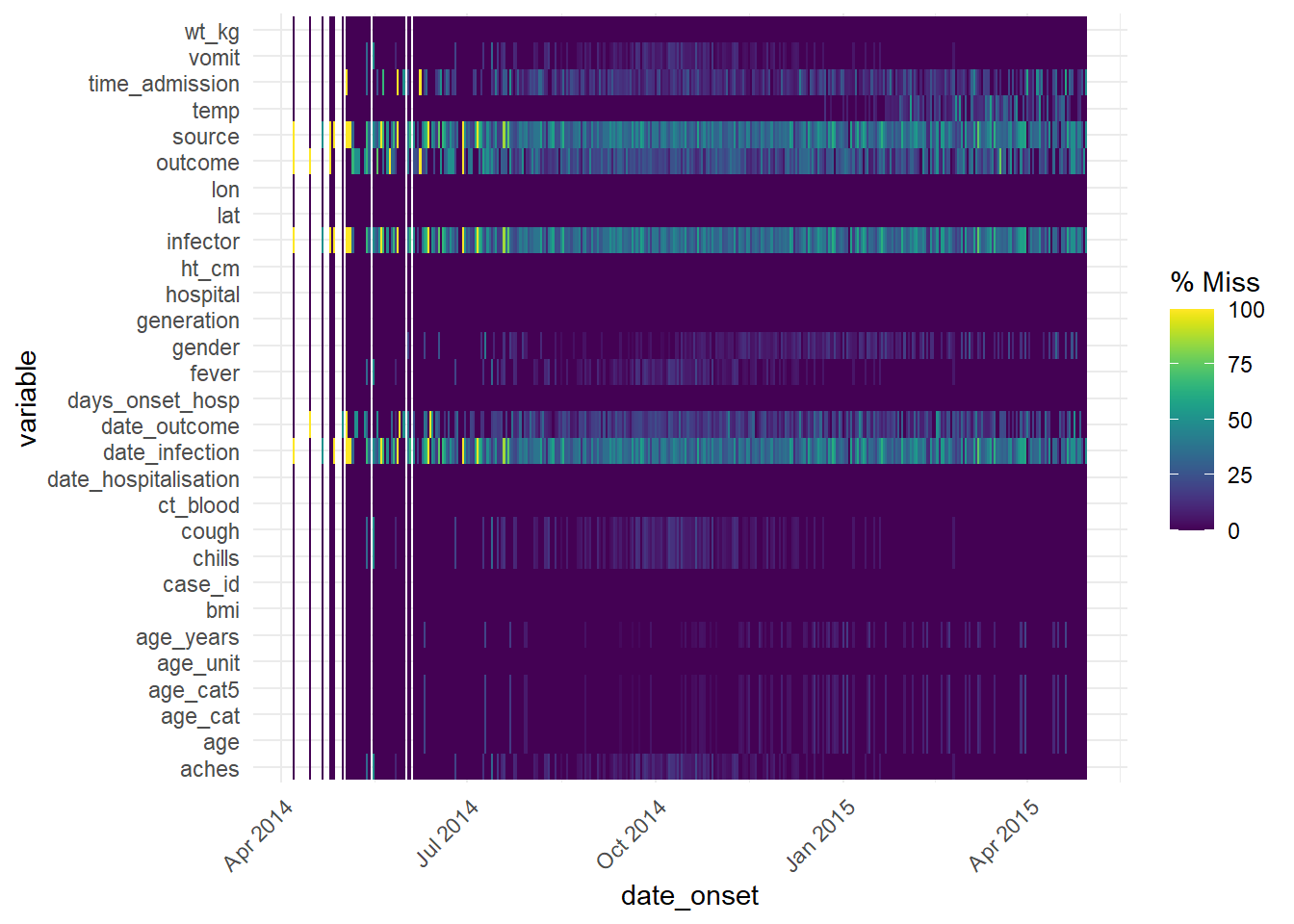
“Gölge” sütunları
Bir sütundaki eksikliği ikinci bir sütundaki değerlere göre görselleştirmenin başka bir yolu da naniar’ın oluşturabileceği “gölgeyi” kullanmaktır. bind_shadow() mevcut her sütun için bir ikili NA/`NA değil` sütunu oluşturur ve tüm bu yeni sütunları “_NA” ekiyle orijinal veri kümesine bağlar. Bu, sütun sayısını iki katına çıkarır - aşağıda göreceğiniz üzere:
## [1] "case_id" "generation" "date_infection"
## [4] "date_onset" "date_hospitalisation" "date_outcome"
## [7] "outcome" "gender" "age"
## [10] "age_unit" "age_years" "age_cat"
## [13] "age_cat5" "hospital" "lon"
## [16] "lat" "infector" "source"
## [19] "wt_kg" "ht_cm" "ct_blood"
## [22] "fever" "chills" "cough"
## [25] "aches" "vomit" "temp"
## [28] "time_admission" "bmi" "days_onset_hosp"
## [31] "case_id_NA" "generation_NA" "date_infection_NA"
## [34] "date_onset_NA" "date_hospitalisation_NA" "date_outcome_NA"
## [37] "outcome_NA" "gender_NA" "age_NA"
## [40] "age_unit_NA" "age_years_NA" "age_cat_NA"
## [43] "age_cat5_NA" "hospital_NA" "lon_NA"
## [46] "lat_NA" "infector_NA" "source_NA"
## [49] "wt_kg_NA" "ht_cm_NA" "ct_blood_NA"
## [52] "fever_NA" "chills_NA" "cough_NA"
## [55] "aches_NA" "vomit_NA" "temp_NA"
## [58] "time_admission_NA" "bmi_NA" "days_onset_hosp_NA"Bu “gölge” sütunlar, eksik değerlerin oranını başka bir sütuna göre çizmek için kullanılabilir.
Örneğin, aşağıdaki grafik, “days_onset_hosp” (semptom başlangıcından hastaneye yatışa kadar geçen gün sayısı) eksik kayıtların oranını, bu kaydın “tarih_hastaneye yatış” değerine göre gösterir. Esasen, x ekseni sütununun yoğunluğunu çiziyorsunuz, ancak sonuçları (‘renk =’) ilgilenilen bir gölge sütunu ile katmanlıyorsunuz. Bu analiz, x ekseni bir sayısal veya tarih sütunuysa en iyi sonucu verir.
ggplot(data = shadowed_linelist, # gölge sütunlu veri çerçevesi
mapping = aes(x = date_hospitalisation, # sayısal veya tarih sütunu
colour = age_years_NA)) + # ilgi alanı gölge sütunu
geom_density() # yoğunluk eğrilerini çizme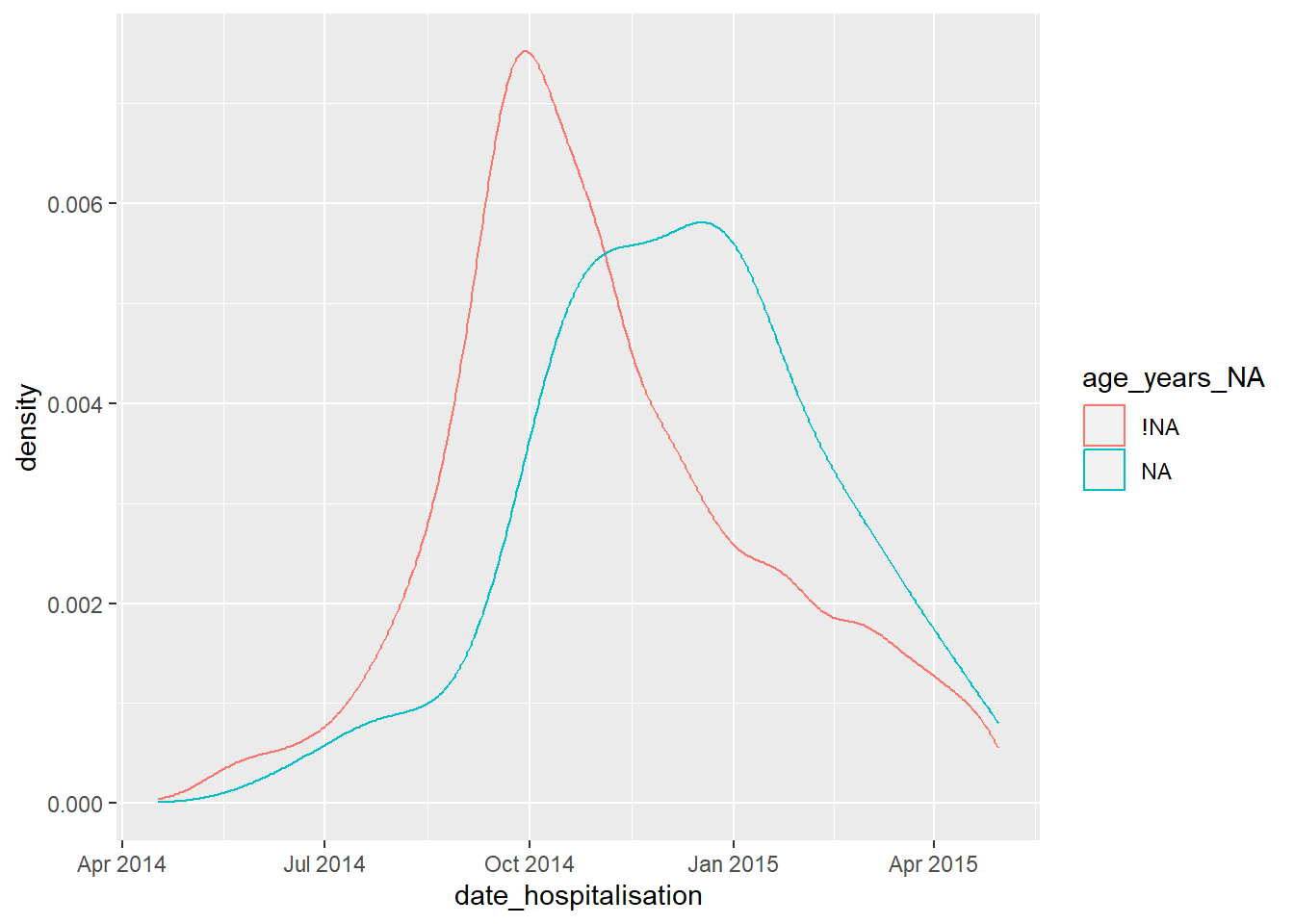
Bu “gölge” sütunları, aşağıda gösterildiği gibi istatistiksel bir özet oluşturmak için de kullanabilirsiniz:
linelist %>%
bind_shadow() %>% # gösteri sütunlarını oluştur
group_by(date_outcome_NA) %>% # katmanlama için gölge sütunları
summarise(across(
.cols = age_years, # hesaplamalar için ilgilenilen değişken
.fns = list("mean" = mean, # hesaplanacak istatistikler
"sd" = sd,
"var" = var,
"min" = min,
"max" = max),
na.rm = TRUE)) # stat hesaplamaları için diğer değişkenler## # A tibble: 2 × 6
## date_outcome_NA age_years_mean age_years_sd age_years_var age_years_min age_years_…¹
## <fct> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 !NA 16.0 12.6 158. 0 84
## 2 NA 16.2 12.9 167. 0 69
## # … with abbreviated variable name ¹age_years_maxBir sütunun zaman içinde eksik olan değerlerinin oranını çizmenin alternatif bir yolu aşağıda gösterilmiştir. naniar içermez. Bu örnek, eksik olan haftalık gözlemlerin yüzdesini gösterir.
- Verileri, gözlemlerin oranını “NA” (ve diğer ilgili değerler) ile özetleyerek yararlı bir zaman biriminde (günler, haftalar vb.) toplayın.
- Eksik oranı
ggplot()kullanarak bir çizgi olarak çizin.
Aşağıda, satır listesini alıyoruz, hafta için yeni bir sütun ekliyoruz, verileri haftaya göre gruplandırıyoruz ve ardından değerin eksik olduğu o haftanın kayıtlarının yüzdesini hesaplıyoruz. (not: 7 günün yüzdesini istiyorsanız, hesaplama biraz farklı olacaktır).
outcome_missing <- linelist %>%
mutate(week = lubridate::floor_date(date_onset, "week")) %>% # yeni hafta sütunu oluşturun
group_by(week) %>% # satırları haftaya göre gruplayın
summarise( # her haftayı özetleyin
n_obs = n(), # kayıtların sayısı
outcome_missing = sum(is.na(outcome) | outcome == ""), # değeri eksik olan kayıt sayısı
outcome_p_miss = outcome_missing / n_obs, # değeri eksik kayıtların oranı
outcome_dead = sum(outcome == "Death", na.rm=T), # ölü olarak kayıt sayısı
outcome_p_dead = outcome_dead / n_obs) %>% # ölü olarak kayıtların oranı
tidyr::pivot_longer(-week, names_to = "statistic") %>% # hafta dışındaki tüm sütunları ggplot için uzun biçime döndür
filter(stringr::str_detect(statistic, "_p_")) # sadece orantı değerlerini tutSonra eksik oranı haftaya göre bir çizgi olarak çizeriz. ggplot2 çizim paketine aşina değilseniz ggplot temelleri sayfasına bakabilirsiniz.
ggplot(data = outcome_missing)+
geom_line(
mapping = aes(x = week, y = value, group = statistic, color = statistic),
size = 2,
stat = "identity")+
labs(title = "Weekly outcomes",
x = "Week",
y = "Proportion of weekly records") +
scale_color_discrete(
name = "",
labels = c("Died", "Missing outcome"))+
scale_y_continuous(breaks = c(seq(0,1,0.1)))+
theme_minimal()+
theme(legend.position = "bottom")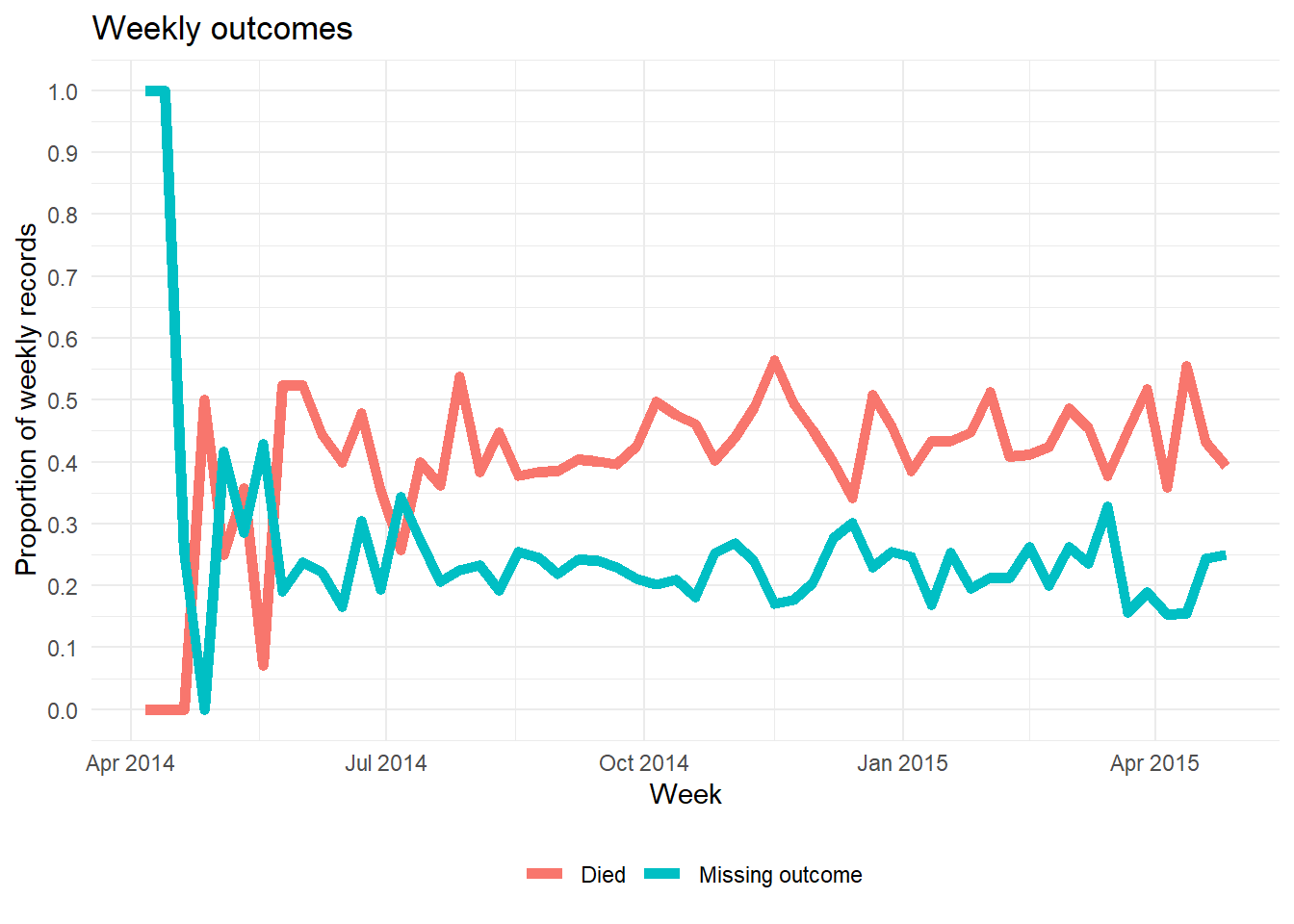
20.5 Eksik değerlere sahip verileri kullanma
Eksik değerlere sahip satırları filtreleyin
Eksik değerlere sahip satırları hızla kaldırmak için dplyr drop_na() fonksiyonunu kullanın.
Orijinal ‘linelist’, ‘nrow(linelist)’ satırlarına sahiptir. Ayarlanan satır sayısı aşağıda gösterilmiştir:
## [1] 1818Belirli sütunlarda eksik olan satırların bırakılmasını belirtebilirsiniz:
## [1] 5632Sütunları arka arkaya listeleyebilir veya “tidyselect” yardımcı işlevlerini kullanabilirsiniz:
linelist %>%
drop_na(contains("date")) %>% # herhangi bir "tarih" sütununda satır eksik değerleri kaldırın
nrow()## [1] 3029
ggplot() içindeki NAyı işleme
Bir başlıktaki bir çizimden hariç tutulan değerlerin sayısını bildirmek genellikle akıllıca olur. Aşağıda bir örnek verilmiştir:
‘ggplot()’ içinde, ‘labs()’ ve içine bir ‘caption =’ ekleyebilirsiniz. Altyazıda, değerleri bir cümleye dinamik olarak yapıştırmak için stringr paketinden str_glue() kullanabilirsiniz, böylece verilere uyum sağlarlar. Bir örnek aşağıdadır:
- Yeni bir satır için
\nkullanımına dikkat edin. - Birden fazla sütun, çizilmeyen değerlere katkıda bulunacaksa (örneğin, çizimde yaş veya cinsiyet yansıtılıyorsa), gösterilmeyen sayıyı doğru bir şekilde hesaplamak için bu sütunları da filtrelemeniz gerektiğini unutmayın.
labs(
title = "",
y = "",
x = "",
caption = stringr::str_glue(
"n = {nrow(central_data)} from Central Hospital;
{nrow(central_data %>% filter(is.na(date_onset)))} cases missing date of onset and not shown.")) Bazen, “ggplot()” komutundan önceki komutlarda dizeyi bir nesne olarak kaydetmek ve “str_glue()” içindeki adlandırılmış dize nesnesine başvurmak daha kolay olabilir.
Faktörlerde “NA”
İlgilendiğiniz sütun bir faktörse, “NA” değerlerini bir karakter değerine dönüştürmek için forcats paketinden “fct_explicit_na()” kullanın. Faktörler sayfasında daha fazla ayrıntıya bakabilirsiniz. Varsayılan olarak, yeni değer “(Eksik)” şeklindedir ancak bu, na_level = değişkeni ile ayarlanabilir.
pacman::p_load(forcats) # paketi yükle
linelist <- linelist %>%
mutate(gender = fct_explicit_na(gender, na_level = "Missing"))
levels(linelist$gender)## [1] "f" "m" "Missing"20.6 Atama
Bazen, verilerinizi analiz ederken, “boşlukları doldurmak” ve eksik verileri eklemek önemli olabilir. Tüm eksik değerleri çıkardıktan sonra bir veri kümesini her zaman basitçe analiz edebilirsiniz. Ancak bu, birçok yönden sorunlara neden olabilir. İşte iki örnek:
Eksik değerlere sahip tüm gözlemleri veya büyük miktarda eksik veriye sahip değişkenleri kaldırarak, bazı analiz türlerini yapma gücünüzü veya yeteneğinizi azaltabilirsiniz. Örneğin, daha önce keşfettiğimiz gibi, linelist veri kümemizdeki gözlemlerin yalnızca küçük bir kısmında tüm değişkenlerimizde eksik veri yoktur. Veri setimizin çoğunu kaldırırsak, çok fazla bilgi kaybederiz! Ve değişkenlerimizin çoğunda bir miktar eksik veri var - çoğu analiz için çok fazla verisi olan her değişkeni bırakmak da muhtemelen makul değildir.
Verilerinizin neden eksik olduğuna bağlı olarak, yalnızca eksik olmayan verilerin analizi yanlı veya yanıltıcı sonuçlara yol açabilir. Örneğin, daha önce öğrendiğimiz gibi, bazı hastaların ateş veya öksürük gibi bazı önemli semptomları olup olmadığına ilişkin verileri kaçırıyor olabiliriz. Ancak, bir olasılık olarak, belki de bu bilgi çok hasta olmayan insanlar için kaydedilmemiştir. Bu durumda, bu gözlemleri kaldırmış olsaydık, veri kümemizdeki en sağlıklı insanlardan bazılarını hariç tutmuş olurduk ve bu gerçekten herhangi bir sonucu saptırabilirdi.
Ne kadarının eksik olduğunu görmenin yanı sıra verilerinizin neden eksik olabileceğini düşünmek de önemlidir. Bunu yapmak, eksik verileri yüklemenin ne kadar önemli olabileceğine ve ayrıca sizin durumunuzda hangi eksik verileri yükleme yönteminin en iyi olabileceğine karar vermenize yardımcı olabilir.
Eksik veri türleri
İşte üç genel eksik veri türü:
Rastgele Tamamen Eksik (MCAR). Bu, verilerin eksik olma olasılığı ile verilerinizdeki diğer değişkenlerden herhangi biri arasında bir ilişki olmadığı anlamına gelir. Eksik olma olasılığı tüm durumlarda aynıdır. Bu nadir görülen bir durumdur. Ancak, verilerinizin MCAR olduğuna inanmak için güçlü bir nedeniniz varsa, yalnızca eksik olmayan verileri empoze etmeden analiz ediyorsa, sonuçlarınızı etkilemeyecektir (ancak biraz güç kaybedebilirsiniz). [TODO: MCAR için istatistiksel testleri tartışmayı düşünün]
Rastgele Eksik (MAR). Bu isim aslında biraz yanıltıcıdır, çünkü MAR, sahip olduğunuz diğer bilgilere dayanarak verilerinizin sistematik, öngörülebilir bir şekilde eksik olduğu anlamına gelir. Örneğin, belki de veri setimizde eksik bir ateş değeri olan her gözlem aslında kaydedilmemiştir çünkü üşüyen ve ağrıyan her hastanın sadece ateşi olduğu varsayıldığından ateşleri hiç ölçülmemiştir. Eğer doğruysa, titreme ve ağrılı her eksik gözlemin de bir ateşi olduğunu kolayca tahmin edebilir ve bu bilgiyi eksik verilerimizi değerlendirmek için kullanabiliriz. Uygulamada, bu daha çok bir spektrumdur. Belki bir hastada hem üşüme hem de ağrı varsa, ateşi ölçülmediyse de ateşi olma olasılığı daha yüksekti, ama her zaman değil. Mükemmel bir şekilde öngörülebilir olmasa bile yine de öngörülebilir. Yaygın bir eksik veri türüdür.
Rastgele Eksik Değil (MNAR veya NMAR). Bu, bir değerin eksik olma olasılığının sistematik OLMADIĞINI veya sahip olduğumuz diğer bilgiler kullanılarak öngörülebilir olmadığını, ancak rastgele olarak da eksik olmadığını varsayar. Bu durumda, bilinmeyen veya hakkında bilgi sahibi olmadığınız nedenlerden dolayı veriler eksiktir. Örneğin, veri setimizde yaşla ilgili bilgiler eksik olabilir, çünkü bazı çok yaşlı hastalar kaç yaşında olduklarını ya bilmiyorlar ya da söylemeyi reddediyorlardır. Bu durumda, yaşa ilişkin eksik veriler, değerin kendisiyle ilgilidir (ve dolayısıyla rastgele değildir) ve sahip olduğumuz diğer bilgilere dayanarak tahmin edilebilir değildir. MNAR karmaşıktır ve çoğu zaman bununla başa çıkmanın en iyi yolu, verilerin neden eksik olduğu hakkında daha fazla veri veya bilgi toplamaya çalışmaktır.
Genel olarak, MCAR verilerini empoze etmek genellikle oldukça basittir, MNAR ise imkansız değilse de çok zordur. Yaygın veri atama yöntemlerinin çoğu MAR’ı varsayar.
Faydalı paketler
Eksik verileri yüklemek için bazı yararlı paketler Mmisc, missForest (eksik verileri yüklemek için rastgele forestları kullanır) ve MICE’dir (Multivariate Imputation by Chained Equations- Zincirli Denklemlerle Çok Değişkenli Tahminleme). Bu bölüm için sadece çeşitli teknikleri uygulayan MICE paketini kullanacağız. MICE paketi üreticisi, burada daha fazla ayrıntıya giren eksik verilerin empoze edilmesi hakkında bir çevrimiçi kitap yayınlamıştır (https://stefvanbuuren.name/fimd/).
Fare paketini yüklemek için kod:
pacman::p_load(mice)Ortalama Atama
Bazen basit bir analiz yapıyorsanız veya MCAR’ı varsayabileceğinizi düşünmek için güçlü bir nedeniniz varsa, eksik sayısal değerleri o değişkenin ortalamasına kolayca ayarlayabilirsiniz. Belki de veri setimizde eksik olan sıcaklık ölçümlerinin ya MCAR olduğunu ya da sadece normal değerler olduğunu varsayabiliriz. Veri kümemizdeki eksik sıcaklık değerlerini ortalama sıcaklık değeriyle değiştiren yeni bir değişken oluşturma kodu burada. Bununla birlikte, birçok durumda verileri ortalamayla değiştirmek yanlılığa neden olabilir, bu nedenle kullanırken dikkatli olun.
linelist <- linelist %>%
mutate(temp_replace_na_with_mean = replace_na(temp, mean(temp, na.rm = T)))Kategorik verileri belirli bir değerle değiştirmek için de benzer bir işlem yapabilirsiniz. Tüm gözlemlerin çıktılarının eksik verili olmasına karşın (“Ölüm” veya “İyileşme” olabilir) ölümlerden oluştuğunu bildiğinizi farz edin (not: bu aslında bu veri kümesi için doğru değildir):
linelist <- linelist %>%
mutate(outcome_replace_na_with_death = replace_na(outcome, "Death"))Regresyon ataması
Biraz daha gelişmiş bir yöntem, eksik bir değerin ne olabileceğini tahmin etmek için bir tür istatistiksel model kullanmak ve bunu tahmin edilen değerle değiştirmektir. Burada, sıcaklığın eksik olduğu, ancak yaş ve ateşin olmadığı tüm gözlemler için, tahmin edici olarak ateş durumu ve yaş kullanılarak basit doğrusal regresyon kullanılarak tahmin değerleri oluşturmaya bir örnek verilmiştir. Pratikte bu tür basit yaklaşımlardan daha iyi bir model kullanmak istersiniz.
simple_temperature_model_fit <- lm(temp ~ fever + age_years, data = linelist)
#sadece sıcaklığın eksik olduğu gözlemler için değerleri tahmin etmek için basit sıcaklık modelimizi kullanma
predictions_for_missing_temps <- predict(simple_temperature_model_fit,
newdata = linelist %>% filter(is.na(temp))) Veya, eksik sıcaklık gözlemleri için emsal değerler oluşturmak üzere MICE paketi aracılığıyla aynı modelleme yaklaşımını kullanarak:
model_dataset <- linelist %>%
select(temp, fever, age_years)
temp_imputed <- mice(model_dataset,
method = "norm.predict",
seed = 1,
m = 1,
print = F)## Warning: Number of logged events: 1
temp_imputed_values <- temp_imputed$imp$tempBu, eksik verileri tahmin edilen değerlerle değiştirmek için missForest paketini kullanmak gibi bazı daha gelişmiş yöntemlerle aynı türde bir yaklaşımdır. Bu durumda, tahmin modeli doğrusal bir regresyon yerine random forest’tir. Bunu yapmak için diğer model türlerini de kullanabilirsiniz. Bununla birlikte, bu yaklaşım MCAR altında iyi çalışsa da, MAR veya MNAR’ın durumunuzu daha doğru tanımladığına inanıyorsanız biraz dikkatli olmalısınız. Tahmininizin kalitesi, tahmin modelinizin ne kadar iyi olduğuna bağlı olacaktır ve çok iyi bir modelde bile, empoze edilen verilerinizin değişkenliği iyi tahmin edilemeyebilir.
LOCF ve BOCF
İleriye taşınan son gözlem (Last observation carried forward- LOCF) ve ileriye taşınan temel gözlem (Baseline observation carried forward-BOCF), zaman serisi/boylamsal veriler için değerlendirme yöntemleridir. Buradaki fikir, eksik verilerin yerine önceki gözlenen değeri almaktır. Art arda birden fazla değer eksik olduğunda, yöntem en son gözlenen değeri arar.
tidyr paketindeki fill() fonksiyonu hem LOCF hem de BOCF ataması için kullanılabilir (ancak, HMISC, zoo ve data.table gibi diğer paketler ayrıca bunu yapmak için yöntemler içerir). fill() sözdizimini göstermek için 2000 ve 2001 yıllarının her çeyreği için bir hastalık vakalarının sayısını içeren basit bir zaman serisi veri seti oluşturacağız. Ancak, Q1’den sonraki çeyrekler için yıl değeri eksik olduğundan onları saymamız gerekecek. ‘fill()’ bağlantısı [Pivoting data] sayfasında da gösterilmektedir.
# basit veri setimizi oluşturmak
disease <- tibble::tribble(
~quarter, ~year, ~cases,
"Q1", 2000, 66013,
"Q2", NA, 69182,
"Q3", NA, 53175,
"Q4", NA, 21001,
"Q1", 2001, 46036,
"Q2", NA, 58842,
"Q3", NA, 44568,
"Q4", NA, 50197)
# eksik yıl değerlerinin ataması:
disease %>% fill(year)## # A tibble: 8 × 3
## quarter year cases
## <chr> <dbl> <dbl>
## 1 Q1 2000 66013
## 2 Q2 2000 69182
## 3 Q3 2000 53175
## 4 Q4 2000 21001
## 5 Q1 2001 46036
## 6 Q2 2001 58842
## 7 Q3 2001 44568
## 8 Q4 2001 50197Not: fill() fonskiyonunu kullanmadan önce verilerinizin doğru şekilde sıralandığından emin olun. fill() varsayılan olarak “aşağı” doldurma şeklindedir, ancak .direction parametresini değiştirerek değerleri farklı yönlere de uygulayabilirsiniz. Yıl değerinin yalnızca yılın sonunda kaydedildiği ve önceki çeyrekler için eksik olduğu benzer bir veri seti yapabiliriz:
# biraz farklı veri kümemizi oluşturmak
disease <- tibble::tribble(
~quarter, ~year, ~cases,
"Q1", NA, 66013,
"Q2", NA, 69182,
"Q3", NA, 53175,
"Q4", 2000, 21001,
"Q1", NA, 46036,
"Q2", NA, 58842,
"Q3", NA, 44568,
"Q4", 2001, 50197)
# eksik yıl değerlerini "yukarı" yönde atamak:
disease %>% fill(year, .direction = "up")## # A tibble: 8 × 3
## quarter year cases
## <chr> <dbl> <dbl>
## 1 Q1 2000 66013
## 2 Q2 2000 69182
## 3 Q3 2000 53175
## 4 Q4 2000 21001
## 5 Q1 2001 46036
## 6 Q2 2001 58842
## 7 Q3 2001 44568
## 8 Q4 2001 50197Bu örnekte, LOCF ve BOCF açıkça yapılması gereken doğru şeylerdir, ancak daha karmaşık durumlarda bu yöntemlerin uygun olup olmadığına karar vermek daha zor olabilir. Örneğin hastanede yatan bir hasta için ilk günden sonra eksik laboratuvar değerleriniz olabilir. Bazen bu, laboratuvar değerlerinin değişmediği anlamına gelebilir… ama aynı zamanda hastanın iyileştiği ve değerlerinin ilk günden sonra çok farklı olacağı anlamına da gelebilir! Bu yöntemleri dikkatli kullanın.
Çoklu Atama
MICE paketinin yazarı tarafından daha önce bahsettiğimiz çevrimiçi kitap (https://stefvanbuuren.name/fimd/), birden fazla değerlemenin ayrıntılı bir açıklamasını ve neden kullanmak isteyeceğinizi içermektedir. Ancak, işte yöntemin temel bir açıklaması:
Birden çok atama yaptığınızda, eksik değerlerin makul veri değerlerine atfedildiği birden çok veri kümesi oluşturursunuz (araştırma verilerinize bağlı olarak, bu atfedilen veri kümelerinden daha fazlasını veya daha azını oluşturmak isteyebilirsiniz, ancak MICE paketi varsayılan sayıyı 5’e ayarlar). Aradaki fark, her bir empoze edilen değerin tek, belirli bir değerden ziyade tahmini bir dağılımdan çekilmesidir (bu nedenle bir miktar rastgelelik içerir). Sonuç olarak, bu veri kümelerinin her biri biraz farklı emsal değerlere sahip olacaktır (ancak, eksik olmayan veriler bu empoze edilen veri kümelerinin her birinde aynı olacaktır). Bu yeni veri kümelerinin her birinde atama yapmak için hala bir tür tahmine dayalı model kullanıyorsunuz (MICE Tahmini Ortalama Eşleştirme, lojistik regresyon ve random forest dahil olmak üzere birçok tahmin yöntemi seçeneği vardır) ancak MICE paketinin modelleme detaylarına dikkat etmelisiniz.
Ardından, bu yeni atfedilen veri kümelerini oluşturduktan sonra, bu yeni empoze edilmiş veri kümelerinin her biri için yapmayı planladığınız istatistiksel modeli veya analizi uygulayabilir ve modellerin sonuçlarını bir araya toplayabilirsiniz. Bu, hem MCAR hem de birçok MAR ayarındaki yanlılığı azaltmak için çok iyi çalışır ve genellikle daha doğru standart hata tahminleriyle sonuçlanır.
Burada, bir yaş ve ateş durumu (yukarıdaki basitleştirilmiş model_veri kümemiz) kullanarak satır listesi veri kümemizdeki sıcaklığı tahmin etmek için Çoklu Atama işleminin uygulanmasına bir örnek verilmiştir:
# model_dataset'imizdeki tüm değişkenler için eksik değerler atamak ve 10 yeni atanmış veri kümesi oluşturmak
multiple_imputation = mice(
model_dataset,
seed = 1,
m = 10,
print = FALSE) ## Warning: Number of logged events: 1
model_fit <- with(multiple_imputation, lm(temp ~ age_years + fever))
base::summary(mice::pool(model_fit))## term estimate std.error statistic df p.value
## 1 (Intercept) 3.703143e+01 0.0270863456 1367.16240465 26.83673 1.583113e-66
## 2 age_years 3.867829e-05 0.0006090202 0.06350905 171.44363 9.494351e-01
## 3 feveryes 1.978044e+00 0.0193587115 102.17849544 176.51325 5.666771e-159Burada MICE’nin standart yöntemi Tahmini Ortalama Eşleştirme yöntemini kullandık. Daha sonra, bu veri kümelerinin her birinde basit doğrusal regresyonlardan elde edilen sonuçları ayrı ayrı tahmin etmek ve havuzlamak için bu emsal veri kümelerini kullandık. Üzerinde durduğumuz birçok ayrıntı ve MICE paketini kullanırken Çoklu Atama işlemi sırasında ayarlayabileceğiniz birçok ayar vardır. Örneğin, her zaman sayısal verileriniz olmaz ve başka atama yöntemlerini kullanmanız gerekebilir (diğer birçok veri ve yöntem türü için MICE paketini kullanmaya devam edebilirsiniz). Ancak, eksik veriler önemli bir sorun olduğunda daha sağlam bir analiz için, Çoklu Atama iyi bir çözümdür ancak, her zaman tam bir vaka analizi yapmaktan daha fazla işe yaramaz.
20.7 Kaynaklar
Kılavuz naniar package
Galeri missing value visualizations
Çevrimiçi kitap R’da birden fazla değer atama hakkında MICE paketi yaratıcısının kitabı