18 Basit istatistiksel testler
Bu sayfa, base R, rstatix ve gtsummary kullanılarak basit istatistiksel testlerin nasıl gerçekleştirileceğini gösterir.
- t testi
- Shapiro-Wilk testi
- Wilcoxon sıra toplamı testi
- Kruskal-Wallis testi
- Ki-kare testi
- Sayısal değişkenler arasındaki korelasyonlar
…başka birçok test yapılabilir, ancak biz sadece bu yaygın testleri göstermekteyiz ve daha fazla belgeye bağlantı vermekteyiz.
Yukarıdaki paketlerin her biri belirli avantajlar ve dezavantajlar getirir:
- İstatistiksel çıktıları R Konsoluna yazdırmak için base R fonksiyonlarını kullanın
- Sonuçları bir veri çerçevesinde döndürmek için veya testlerin gruplara göre yapılmasını istiyorsanız rstatix fonksiyonlarını kullanın
- Yayına hazır tabloları hızlı bir şekilde yazdırmak istiyorsanız gtsummary kullanın
18.1 Hazırlık
Paketleri yükleyin
Bu kod parçası, analizler için gerekli olan paketlerin yüklenmesini gösterir. Bu el kitabında, gerekirse paketi kuran ve kullanım için yükleyen pacman’dan p_load() vurgusunu yapıyoruz. base R’dan library() ile kurulu paketleri de yükleyebilirsiniz. R paketleri hakkında daha fazla bilgi için [R basics] sayfasına bakın.
pacman::p_load(
rio, # Dosyayı içe aktarma
here, # Dosyayı konumlama
skimr, # Veriye göz atma
tidyverse, # veri yönetimi + ggplot2 grafikleri,
gtsummary, # özet istatistikler ve testler
rstatix, # istatistikler
corrr, # Sayısal değişkenler için Korelasyon analizi
janitor, # Tablolara toplamı ve yüzdeleri ekleme
flextable # Tabloları HTML formatına dönüştürme
)Verileri içe aktar
Simüle edilmiş bir Ebola salgınından vakaların veri setini içe aktarıyoruz. Takip etmek isterseniz, “temiz” vaka listesini indirmek için tıklayınız(.rds dosyası olarak). Verilerinizi rio paketinden import() fonksiyonuyla içe aktarın (.xlsx, .rds, .csv gibi birçok dosya türünü kabul eder - ayrıntılar için [İçe aktarma ve dışa aktarma] sayfasına bakın).
# Vaka listesini içe aktarma
linelist <- import("linelist_cleaned.rds")Vaka listesinin ilk 50 satırı aşağıda görüntülenmektedir.
base (temel) R {}
İstatistiksel testler yapmak için base R fonksiyonlarını kullanabilirsiniz. Komutlar nispeten basittir ve sonuçlar basit görüntüleme için R Konsoluna yazdırılacaktır. Bununla birlikte, çıktılar genellikle listelerdir ve bu nedenle sonuçları sonraki işlemlerde kullanmak istiyorsanız manipüle edilmesi daha zordur.
T testleri
“Student’s t-Test” olarak da adlandırılan bir t-testi, genellikle iki grup arasındaki bazı sayısal değişkenlerin ortalamaları arasında önemli bir fark olup olmadığını belirlemek için kullanılır. Burada, sütunların aynı veri çerçevesinde olup olmadığına bağlı olarak bu testi yapmak için sözdizimini göstereceğiz.
Sözdizimi 1: Bu, sayısal ve kategorik sütunlarınız aynı veri çerçevesinde olduğundaki sözdizimidir. Denklemin sol tarafında sayısal sütunu ve sağ tarafında kategorik sütunu sağlayın. Veri kümesini data = olarak belirtin. İsteğe bağlı olarak, paired = TRUE, ve conf.level = (0.95 default), vealternative =(“iki taraflı”, “daha az” veya “daha büyük”) olarak ayarlayın. Daha fazla ayrıntı için ?t.test girin.
## T-testi ile grupların yaş ortalamalarını karşılaştırma
t.test(age_years ~ gender, data = linelist)##
## Welch Two Sample t-test
##
## data: age_years by gender
## t = -21.344, df = 4902.3, p-value < 2.2e-16
## alternative hypothesis: true difference in means between group f and group m is not equal to 0
## 95 percent confidence interval:
## -7.571920 -6.297975
## sample estimates:
## mean in group f mean in group m
## 12.60207 19.53701Sözdizimi 2: Bu alternatif sözdizimini kullanarak iki ayrı sayısal vektörü karşılaştırabilirsiniz. Örneğin, iki sütun farklı veri kümelerindeyse.
t.test(df1$age_years, df2$age_years)Örneklerin ortalamasının belirli bir değerden önemli ölçüde farklı olup olmadığını belirlemek için bir t testi de kullanabilirsiniz. Burada, mu = olarak bilinen/varsayımsal popülasyon ortalaması ile tek örnekli bir t-testi yapıyoruz:
t.test(linelist$age_years, mu = 45)Shapiro-Wilk testi
Shapiro-Wilk testi bir örneğin normal dağılıma sahip bir popülasyondan gelip gelmediğini belirlemek için kullanılabilir (diğer birçok testin varsayımı ve analizinde olduğu gibi, örneğin t-testi). Ancak, bu yalnızca 3 ila 5000 gözlem arasındaki bir örnek üzerinde kullanılabilir. Daha büyük numuneler için bir quantile-quantile (Q-Q) grafiği yardımcı olabilir.
shapiro.test(linelist$age_years)Wilcoxon sıralama toplamı testi
Mann–Whitney U testi olarak da adlandırılan Wilcoxon sıralama toplamı testi, genellikle iki sayısal örneğin popülasyonları normal dağılmadığında veya eşit olmayan varyansa sahip olduğunda kullanılır.
## Wilcox testi ile grupların yaş dağılımını karşılaştırma
wilcox.test(age_years ~ outcome, data = linelist)##
## Wilcoxon rank sum test with continuity correction
##
## data: age_years by outcome
## W = 2501868, p-value = 0.8308
## alternative hypothesis: true location shift is not equal to 0Kruskal-Wallis testi
Kruskal-Wallis testi, ikiden fazla örneklemin dağılımdaki farklılıklarını test etmek için kullanılabilecek Wilcoxon testinin bir uzantısıdır. Yalnızca iki örnek kullanıldığında, Wilcoxon testiyle aynı sonuçları verir.
## Kruskal-Wallis testi ile grupların yaş dağılımını karşılaştırma
kruskal.test(age_years ~ outcome, linelist)##
## Kruskal-Wallis rank sum test
##
## data: age_years by outcome
## Kruskal-Wallis chi-squared = 0.045675, df = 1, p-value = 0.8308Ki-kare testi
Pearson Ki-kare testi kategorik gruplar arasındaki önemli farklılıkları test etmek için kullanılır.
## Ki-kare testi ile her grubun oranlarını karşılaşırma
chisq.test(linelist$gender, linelist$outcome)##
## Pearson's Chi-squared test with Yates' continuity correction
##
## data: linelist$gender and linelist$outcome
## X-squared = 0.0011841, df = 1, p-value = 0.972518.2 rstatix paketi
rstatix paketi, istatistiksel testlerin çalıştırılmasını ve sonuçlarını “tünel dostu” bir çerçevede alma olanağı sunar. Sonuçlar üzerinde işlemleri gerçekleştirebilmeniz için sonuçlar, otomatik olarak bir veri çerçevesindedir. İstatistiklerin her grup için çalıştırılması ve fonksiyonlara geçirilen verileri gruplamak kolaydır.
Özet istatistikler
get_summary_stats() fonksiyonu, özet istatistikleri döndürmenin hızlı bir yoludur. Veri kümenizi bu fonksiyona aktarmanız ve analiz edilecek sütunları sağlamanız yeterlidir. Hiçbir sütun belirtilmemişse, istatistikler tüm sütunlar için hesaplanır.
Varsayılan olarak, tam bir özet istatistik aralığı döndürülür: n, maks, min, medyan, %25 ile, %75 ile, IQR, medyan mutlak sapma (mad), ortalama, standart sapma, standart hata ve güven aralığı.
linelist %>%
rstatix::get_summary_stats(age, temp)## # A tibble: 2 × 13
## variable n min max median q1 q3 iqr mad mean sd se ci
## <fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 age 5802 0 84 13 6 23 17 11.9 16.1 12.6 0.166 0.325
## 2 temp 5739 35.2 40.8 38.8 38.2 39.2 1 0.741 38.6 0.977 0.013 0.025type = için şu değerlerden birini sağlayarak döndürülecek özet istatistiklerin bir alt kümesini belirtebilirsiniz: “full”, “common”, “robust”, “five_number”, “mean_sd”, “mean_se”, “mean_ci” , “median_iqr”, “median_mad”, “quantile”, “mean”, “median”, “min”, “max”.
Her gruplama değişkeni için bir satır döndürülecek şekilde gruplandırılmış verilerle de kullanılabilir:
linelist %>%
group_by(hospital) %>%
rstatix::get_summary_stats(age, temp, type = "common")## # A tibble: 12 × 11
## hospital varia…¹ n min max median iqr mean sd se ci
## <chr> <fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 Central Hospital age 445 0 58 12 15 15.7 12.5 0.591 1.16
## 2 Central Hospital temp 450 35.2 40.4 38.8 1 38.5 0.964 0.045 0.089
## 3 Military Hospital age 884 0 72 14 18 16.1 12.4 0.417 0.818
## 4 Military Hospital temp 873 35.3 40.5 38.8 1 38.6 0.952 0.032 0.063
## 5 Missing age 1441 0 76 13 17 16.0 12.9 0.339 0.665
## 6 Missing temp 1431 35.8 40.6 38.9 1 38.6 0.97 0.026 0.05
## 7 Other age 873 0 69 13 17 16.0 12.5 0.422 0.828
## 8 Other temp 862 35.7 40.8 38.8 1.1 38.5 1.01 0.034 0.067
## 9 Port Hospital age 1739 0 68 14 18 16.3 12.7 0.305 0.598
## 10 Port Hospital temp 1713 35.5 40.6 38.8 1.1 38.6 0.981 0.024 0.046
## 11 St. Mark's Materni… age 420 0 84 12 15 15.7 12.4 0.606 1.19
## 12 St. Mark's Materni… temp 410 35.9 40.6 38.8 1.1 38.5 0.983 0.049 0.095
## # … with abbreviated variable name ¹variableİstatistiksel testler yapmak için rstatix’i de kullanabilirsiniz:
T-testi
Sayısal ve kategorik sütunları belirtmek için bir formül sözdizimi kullanın:
linelist %>%
t_test(age_years ~ gender)## # A tibble: 1 × 10
## .y. group1 group2 n1 n2 statistic df p p.adj p.adj.signif
## * <chr> <chr> <chr> <int> <int> <dbl> <dbl> <dbl> <dbl> <chr>
## 1 age_years f m 2807 2803 -21.3 4902. 9.89e-97 9.89e-97 ****Veya ~ 1 kullanın ve tek örnekli bir T-testi için mu = belirtin. Bu grup tarafından da yapılabilir.
linelist %>%
t_test(age_years ~ 1, mu = 30)## # A tibble: 1 × 7
## .y. group1 group2 n statistic df p
## * <chr> <chr> <chr> <int> <dbl> <dbl> <dbl>
## 1 age_years 1 null model 5802 -84.2 5801 0Uygulanabilirse, istatistiksel testler aşağıda gösterildiği gibi grup bazında yapılabilir:
## # A tibble: 3 × 8
## gender .y. group1 group2 n statistic df p
## * <chr> <chr> <chr> <chr> <int> <dbl> <dbl> <dbl>
## 1 f age_years 1 null model 2807 -29.8 2806 7.52e-170
## 2 m age_years 1 null model 2803 5.70 2802 1.34e- 8
## 3 <NA> age_years 1 null model 192 -3.80 191 1.96e- 4Shapiro-Wilk testi
Yukarıda belirtildiği gibi, örneklem büyüklüğü 3 ile 5000 arasında olmalıdır.
linelist %>%
head(500) %>% # Vaka listesinin ilk 500 satırı, sadece örnek için
shapiro_test(age_years)## # A tibble: 1 × 3
## variable statistic p
## <chr> <dbl> <dbl>
## 1 age_years 0.917 6.67e-16Wilcoxon sıralama toplamı testi
linelist %>%
wilcox_test(age_years ~ gender)## # A tibble: 1 × 9
## .y. group1 group2 n1 n2 statistic p p.adj p.adj.signif
## * <chr> <chr> <chr> <int> <int> <dbl> <dbl> <dbl> <chr>
## 1 age_years f m 2807 2803 2829274 3.47e-74 3.47e-74 ****Kruskal-Wallis testi
Mann-Whitney U testi olarak da bilinir.
linelist %>%
kruskal_test(age_years ~ outcome)## # A tibble: 1 × 6
## .y. n statistic df p method
## * <chr> <int> <dbl> <int> <dbl> <chr>
## 1 age_years 5888 0.0457 1 0.831 Kruskal-WallisKi-kare testi
Ki-kare test fonksiyonu bir tablo kabul eder, bu nedenle önce bir çapraz tablo oluştururuz. Çapraz tablo oluşturmanın birçok yolu vardır (bkz. Tanımlayıcı tablolar) ancak burada janitor ‘den ’tabyl()’ kullanıyoruz ve ’chisq_test()’e geçmeden önce en soldaki değer etiketleri sütununu kaldırıyoruz.
## # A tibble: 1 × 6
## n statistic p df method p.signif
## * <dbl> <dbl> <dbl> <int> <chr> <chr>
## 1 5888 3.53 0.473 4 Chi-square test nsrstatix fonksiyonları ile daha birçok fonksiyon ve istatistiksel test çalıştırılabilir. rstatix belgelerine buradan çevrimiçi veya ?rstatix girerek inceleyebilirsiniz.
18.3 gtsummary paketi
Bu paketle oluşturulmuş güzel bir tabloya istatistiksel bir testin sonuçlarını eklemek istiyorsanız gtsummary kullanın (Açıklayıcı tablolar sayfasının gtsummary bölümünde açıklandığı gibi) ).
‘tbl_summary’ ile karşılaştırmanın istatistiksel testlerinin yapılması,
Bir tabloya add_p fonskiyonu ve hangi testin kullanılacağını belirtir. kullanarak çoklu test için p değerlerinin düzeltilmesi mümkündür.
‘add_q’ işlevi. Ayrıntılar için ?tbl_summary çalıştırın.
Ki-kare testi
Kategorik bir değişkenin oranlarını iki grupta karşılaştırın. Kategorik bir değişkene uygulandığında ‘add_p()’ için varsayılan istatistiksel test, süreklilik düzeltmeli ki-kare bağımsızlık testi yapmaktır, ancak herhangi bir beklenen değer sayısı 5’in altındaysa, o zaman Fisher’ın kesin testi kullanılır.
linelist %>%
select(gender, outcome) %>% # ilgilenilen değişkenleri tutma
tbl_summary(by = outcome) %>% # özet tablo oluştur ve gruplama değişkenini belirle
add_p() # hangi testin gerçekleştirileceğini belirtin## 1323 observations missing `outcome` have been removed. To include these observations, use `forcats::fct_explicit_na()` on `outcome` column before passing to `tbl_summary()`.| Characteristic | Death, N = 2,5821 | Recover, N = 1,9831 | p-value2 |
|---|---|---|---|
| gender | >0.9 | ||
| f | 1,227 (50%) | 953 (50%) | |
| m | 1,228 (50%) | 950 (50%) | |
| Unknown | 127 | 80 | |
| 1 n (%) | |||
| 2 Pearson's Chi-squared test | |||
T testleri
İki grupta sürekli bir değişken için ortalamalardaki farkı karşılaştırın. Örneğin, ortalama yaşı hasta sonucuna göre karşılaştırın.
linelist %>%
select(age_years, outcome) %>% # ilgilenilen değişkenleri tutma
tbl_summary( # özet tablo üretme
statistic = age_years ~ "{mean} ({sd})", # hangi istatistiklerin gösterileceğini belirtin
by = outcome) %>% # gruplama değişkenini belirtin
add_p(age_years ~ "t.test") # hangi testlerin gerçekleştirileceğini belirtin## 1323 observations missing `outcome` have been removed. To include these observations, use `forcats::fct_explicit_na()` on `outcome` column before passing to `tbl_summary()`.| Characteristic | Death, N = 2,5821 | Recover, N = 1,9831 | p-value2 |
|---|---|---|---|
| age_years | 16 (12) | 16 (13) | 0.6 |
| Unknown | 32 | 28 | |
| 1 Mean (SD) | |||
| 2 Welch Two Sample t-test | |||
Wilcoxon sıralama toplamı testi
Sürekli bir değişkenin dağılımını iki grupta karşılaştırın. Varsayılan ayar, iki grubu karşılaştırırken Wilcoxon sıra toplamı testi ve medyanı (IQR) kullanmaktır. Ancak normal dağılmayan veriler veya çoklu grupların karşılaştırılması için Kruskal-wallis testi daha uygundur.
linelist %>%
select(age_years, outcome) %>% # ilgilenilen değişkenleri tutma
tbl_summary( # özet tablo üretme
statistic = age_years ~ "{median} ({p25}, {p75})", # hangi istatistiğin gösterileceğini belirtin (bu varsayılandır, bu nedenle kaldırılabilir)
by = outcome) %>% # gruplama değişkenini belirtin
add_p(age_years ~ "wilcox.test") # hangi testin gerçekleştirileceğini belirtin (bu varsayılandır, bu nedenle parantezler boş bırakılabilir)## 1323 observations missing `outcome` have been removed. To include these observations, use `forcats::fct_explicit_na()` on `outcome` column before passing to `tbl_summary()`.| Characteristic | Death, N = 2,5821 | Recover, N = 1,9831 | p-value2 |
|---|---|---|---|
| age_years | 13 (6, 23) | 13 (6, 23) | 0.8 |
| Unknown | 32 | 28 | |
| 1 Median (IQR) | |||
| 2 Wilcoxon rank sum test | |||
18.3.1 Kruskal-wallis testi
Verilerin normal dağılıp dağılmadığına bakılmaksızın, sürekli bir değişkenin iki veya daha fazla gruptaki dağılımını karşılaştırın.
linelist %>%
select(age_years, outcome) %>% # ilgilenilen değişkenleri tutma
tbl_summary( # özet tablo üretme
statistic = age_years ~ "{median} ({p25}, {p75})", # hangi istatistiğin gösterileceğini belirtin (bu varsayılandır, bu nedenle kaldırılabilir)
by = outcome) %>% # gruplama değişkenini belirtin
add_p(age_years ~ "kruskal.test") # hangi testin gerçekleştirileceğini belirtin## 1323 observations missing `outcome` have been removed. To include these observations, use `forcats::fct_explicit_na()` on `outcome` column before passing to `tbl_summary()`.| Characteristic | Death, N = 2,5821 | Recover, N = 1,9831 | p-value2 |
|---|---|---|---|
| age_years | 13 (6, 23) | 13 (6, 23) | 0.8 |
| Unknown | 32 | 28 | |
| 1 Median (IQR) | |||
| 2 Kruskal-Wallis rank sum test | |||
18.4 Korelasyonlar
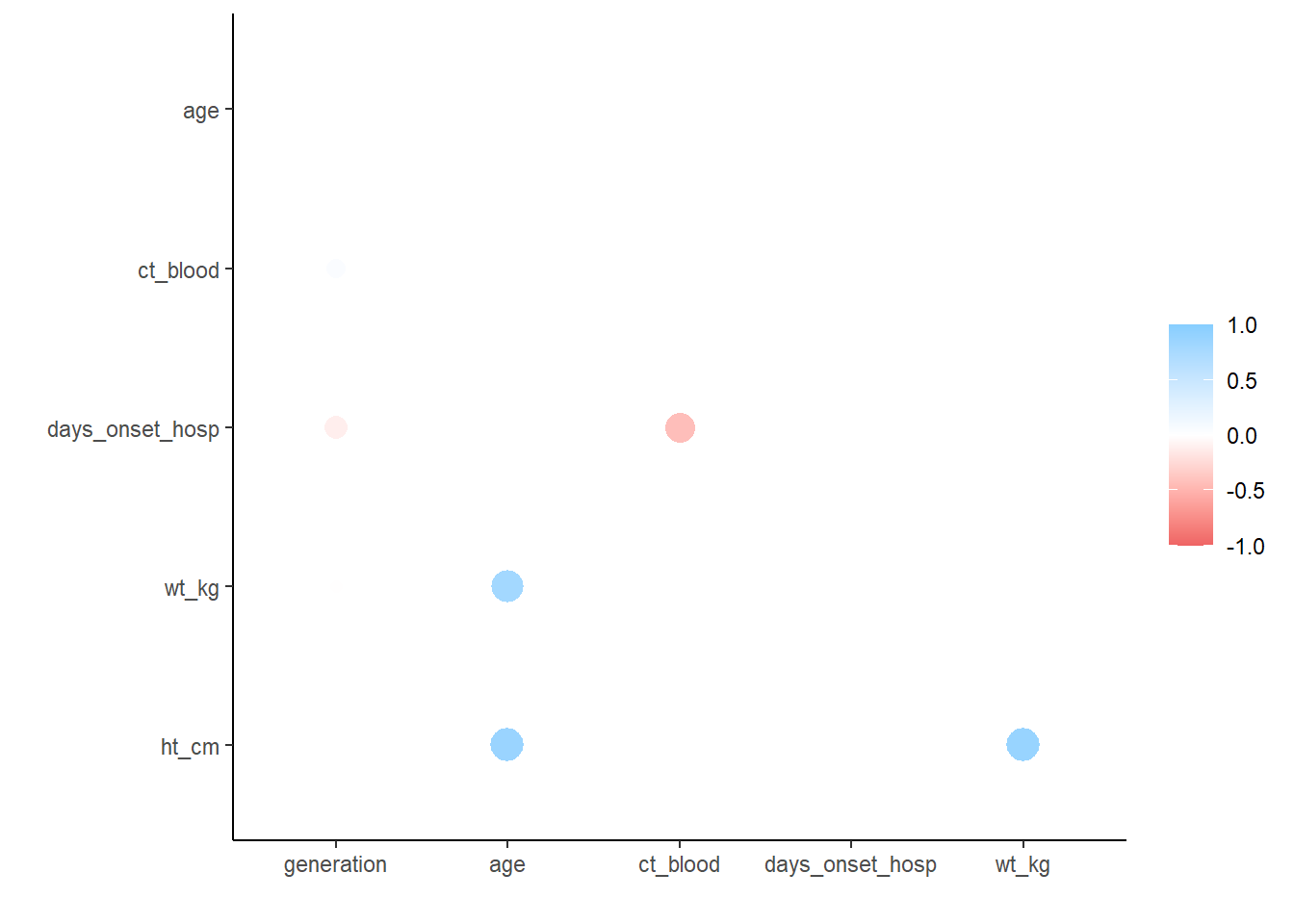
Sayısal değişkenler arasındaki korelasyon tidyverse kullanılarak araştırılabilir. corrr paketi, Pearson Kendall kullanarak korelasyonları hesaplamanıza izin verir. tau veya Spearman rho, Paket bir tablo oluşturur ve ayrıca değerleri otomatik olarak çizer.
correlation_tab <- linelist %>%
select(generation, age, ct_blood, days_onset_hosp, wt_kg, ht_cm) %>% # ilgilenilen sayısal değişkenleri tutma
correlate() # korelasyon tablosu oluşturma (varsayılan pearson kullanılarak)
correlation_tab # yazdır## # A tibble: 6 × 7
## term generation age ct_blood days_onset_hosp wt_kg ht_cm
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 generation NA -0.0222 0.179 -0.288 -0.0302 -0.00942
## 2 age -0.0222 NA 0.00849 -0.000635 0.833 0.877
## 3 ct_blood 0.179 0.00849 NA -0.600 -0.00636 0.0181
## 4 days_onset_hosp -0.288 -0.000635 -0.600 NA 0.0153 -0.00953
## 5 wt_kg -0.0302 0.833 -0.00636 0.0153 NA 0.884
## 6 ht_cm -0.00942 0.877 0.0181 -0.00953 0.884 NA
## Duplike girdileri kaldırma (üstteki tablo yansıtılır)
correlation_tab <- correlation_tab %>%
shave()
## Korelasyon tablosunu gösterme
correlation_tab## # A tibble: 6 × 7
## term generation age ct_blood days_onset_hosp wt_kg ht_cm
## <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 generation NA NA NA NA NA NA
## 2 age -0.0222 NA NA NA NA NA
## 3 ct_blood 0.179 0.00849 NA NA NA NA
## 4 days_onset_hosp -0.288 -0.000635 -0.600 NA NA NA
## 5 wt_kg -0.0302 0.833 -0.00636 0.0153 NA NA
## 6 ht_cm -0.00942 0.877 0.0181 -0.00953 0.884 NA
## korelasyon grafikleri
rplot(correlation_tab)