7 İçe ve dışa aktar

Bu sayfada dosyaları bulmanın, içe aktarmanın ve dışa aktarmanın yollarını açıklıyoruz:
- Birçok dosya türünü esnek bir şekilde
import()veexport()işlemi için rio paketinin kullanımını - Bir R proje köküyle ilişkili dosyaları bulmak için here paketinin kullanılması - bir bilgisayara özgü dosya yollarından kaynaklanan komplikasyonları önlemek için
- Aşağıdakiler gibi belirli içe aktarma senaryoları:
- Spesifik Excel sayfaları
- Dağınık başlıklar ve satır atlama
- Google sayfalarından
- Web sitelerine gönderilen verilerden
- API’ler ile
- En son dosyayı içe aktarma
- Manuel veri girişi
- RDS ve RData gibi R’a özgü dosya türleri
- Dosyaları ve grafikleri dışa aktarma/kaydetme
7.1 Genel Bakış
Bir “veri kümesini” R’ı içe aktardığınızda, genellikle R ortamınızda yeni bir veri çerçevesi nesnesi yaratır ve onu klasör dizinlerinizde bulunan içe aktarılmış bir dosya (örn. Excel, CSV, TSV, RDS) olarak belirli bir dosya yolu/adresini tanımlamış olursunuz.
Diğer istatistiksel programlar (SAS, STATA, SPSS) tarafından oluşturulanlar da dahil olmak üzere birçok dosya türünü içe/dışa aktarabilirsiniz. Ayrıca ilişkisel veritabanlarına da bağlanabilirsiniz.
R’ın kendi veri biçimleri bile vardır:
- Bir RDS dosyası (.rds), veri çerçevesi gibi tek bir R nesnesini depolar. Bunlar, R sütun sınıflarını korudukları için temizlenmiş verileri depolamak için kullanışlıdır. Bu bölümde daha fazlasını okuyabilirsiniz.
- Bir RData dosyası (.Rdata), birden çok nesneyi veya hatta eksiksiz bir R çalışma alanını depolamak için kullanılabilir. Bu bölümde daha fazlasını okuyabilirsiniz.
7.2 rio paketi
Önerdiğimiz R paketi: rio. “Rio” adı, “R I/O” (girdi-input/çıktı-output) ifadesinin kısaltmasıdır.
import() ve export() fonksiyonları birçok farklı dosya türünü (örneğin .xlsx, .csv, .rds, .tsv) işleyebilir. Bu fonksiyonlardan herhangi birine (“.csv” gibi dosya uzantısı dahil) bir dosya yolu sağladığınızda, rio uzantıyı okuyacak ve dosyayı içe veya dışa aktarmak için doğru aracı kullanacaktır.
rio kullanmanın alternatifi, her biri bir dosya türüne özgü olan diğer birçok paketin fonksiyonunu kullanmaktır. Örneğin, ‘read.csv()’ (base R), ‘read.xlsx()’ (openxlsx paketi) ve ‘write_csv()’ (readr paketi), vb. Bu alternatifleri hatırlamak zor olabilir, oysa rio’dan import() ve export() kullanmak kolaydır.
rio’nun import() ve export() fonksiyonları, dosya uzantısına bağlı olarak belirli bir dosya için uygun paketi ve fonksiyonu kullanır. rio’nun arka planda kullandığı paketlerin/fonksiyonların tam bir tablosu için bu sayfanın sonuna bakabilirsiiniz. Düzinelerce başka dosya türü arasından STATA, SAS ve SPSS dosyalarını içe aktarmak için de kullanılabilir.
Şekil dosyalarının içe/dışa aktarımı, [GIS temelleri] sayfasında ayrıntılı olarak açıklandığı gibi başka paketler gerektirir.
7.3 here paketi
here paketi ve ‘here()’ fonksiyonu, R’a dosyalarınızı nerede bulacağını ve kaydedeceğini söylemeyi kolaylaştırır - özünde, dosya yolları oluşturur.
Bir R projesiyle birlikte kullanıldığında here, R projenizdeki dosyaların konumunu R projesinin kök dizini (en üst düzey klasör) ile ilişkili olarak tanımlamanıza olanak tanır. Bu, R projesinin birden fazla kişi/bilgisayar tarafından paylaşılabildiği veya erişilebildiği durumlarda kullanışlıdır. Dosya yolunu tüm kullanıcılar için ortak bir yerde (R proje kökü) “başlatarak”, farklı bilgisayarlardaki benzersiz dosya yollarından (ör. “C:/Users/Laura/Documents…”) kaynaklanan komplikasyonları önler.
Bir R projesinde “here()” şu şekilde çalışır:
- here paketi R projesine ilk yüklendiğinde, “.here” adlı küçük bir dosyayı R projenizin kök klasörüne “benchmark” veya “anchor” olarak yerleştirir.
- Komut dosyalarınızda, R projesinin alt klasörlerindeki bir dosyaya referans vermek için, dosya yolunu oluşturmak için ‘here()’ fonksiyonunu kullanırsınız bu bağlantıya göre
- Dosya yolunu oluşturmak için, klasör adlarını kökün ötesinde, tırnak işaretleri içinde, virgülle ayırarak ve son olarak aşağıda gösterildiği gibi dosya adı ve dosya uzantısı ile bitecek şekilde yazın.
-
here()dosya yolları hem içe hem dışa aktarma için kullanılabilir
Örneğin, aşağıda, “import()” fonksiyonuna “here()” ile oluşturulmuş bir dosya yolu sağlanmaktadır.
here("data", "linelists", "ebola_linelist.xlsx") komutu aslında kullanıcının bilgisayarına özgü olan tam dosya yolunu sağlar*:
"C:/Users/Laura/Documents/my_R_project/data/linelists/ebola_linelist.xlsx"İşin güzel yanı, ‘here()’ kullanan R komutunun, R projesine erişen herhangi bir bilgisayarda başarılı bir şekilde çalıştırılabilmesidir.
TIP: “.here” kökünün nereye ayarlandığından emin değilseniz, boş parantezlerle ‘here()’ fonksiyonunu çalıştırın.
here paketi hakkında bu bağlantıdan daha fazlasını okuyabilirsiniz.
7.4 Dosya yolları
Verileri içe veya dışa aktarırken bir dosya yolu sağlamanız gerekir. Bunu üç yoldan biriyle yapabilirsiniz:
- Önerilen: here paketiyle “ilişkili” bir dosya yolu sağlayın
- “tam” / “mutlak” dosya yolunu sağlayın
- Manuel dosya seçimi
“İlişkili” dosya yolları
R’da, “ilişkili” dosya yolları, bir R projesinin köküne ilişkili olan dosya yolundan oluşur. Farklı bilgisayarlarda çalışabilen daha basit dosya yollarına izin verirler (örneğin, R projesi paylaşılan bir sürücüdeyse veya e-postayla gönderiliyorsa). Yukarıda açıklandığı gibi, göreli dosya yolları here paketi kullanılarak kolaylaştırılır.
‘here()’ ile oluşturulmuş ilişkili bir dosya yolu örneği aşağıdadır. Çalışmanın, bir “veri” alt klasörü içeren bir R projesinde olduğunu ve bunun içinde, .xlsx dosyasının bulunduğu bir “çizgi listeleri” alt klasöründe olduğunu varsayıyoruz.
“Mutlak” dosya yolları
import() gibi fonksiyonlar için mutlak veya “tam” dosya yolları sağlanabilir, ancak bunlar kullanıcının özel bilgisayarına özgü olduğundan “kırılgandır” ve bu nedenle önerilmez.
Aşağıda, Laura’nın bilgisayarında bir “analiz” klasörü, bir “veri” alt klasörü ve bunun içinde, ilgilenilen .xlsx dosyasının bulunduğu bir alt klasör “satır listeleri” bulunan bir mutlak dosya yolu örneği verilmiştir. .
linelist <- import("C:/Users/Laura/Documents/analysis/data/linelists/ebola_linelist.xlsx")Mutlak dosya yolları hakkında dikkat edilmesi gereken birkaç nokta:
- Mutlak dosya yollarını kullanmaktan kaçının çünkü komut dosyası farklı bir bilgisayarda çalıştırılırsa bozulurlar
- Yukarıdaki örnekte olduğu gibi ileri eğik çizgi (
/) kullanın (not: bu, Windows dosya yolları için varsayılan DEĞİLDİR) - Çift eğik çizgiyle başlayan dosya yolları (ör. “//…”) büyük olasılıkla R tarafından tanınmayacak ve bir hata üretecektir. Çalışmanızı bir harfle başlayan “adlandırılmış” veya “harfli” bir sürücüye taşımayı düşünün (ör. “J:” veya “C:”). Bu sorunla ilgili daha fazla ayrıntı için Dizin etkileşimleri hakkındaki sayfaya bakabilirsiniz.
Mutlak dosya yollarının uygun olabileceği bir senaryo, tüm kullanıcılar için aynı tam dosya yoluna sahip bir paylaşılan sürücüden bir dosyayı içe aktarmak istediğiniz zamandır.
İPUCU: Tüm \ işaretlerini / biçimine hızlı bir şekilde dönüştürmek için ilgili kodu vurgulayın, Ctrl+f (Windows’ta) kullanın, “In selection” seçenek kutusunu işaretleyin ve ardından bunları dönüştürmek için değiştirme fonksiyonunu kullanın.
Dosyayı manuel olarak seçin
Aşağıdaki yöntemlerden birini kullanarak verileri manuel olarak içe aktarabilirsiniz:
- Ortam RStudio Bölmesi, “Veri Kümesini İçe Aktar”a tıklayın ve veri türünü seçin
- Dosya / Veri Kümesini İçe Aktar / (veri türünü seçin) öğesine tıklayın.
- Manuel seçimi sabit kodlamak amacıyla, kullanıcının manuel olarak bilgisayarından dosya seçmesine izin veren bir açılır pencere görünümünü tetiklemek için temel R
file.choose()komutunu (parantezleri boş bırakarak) kullanın. Örneğin:
# Bir dosyanın manuel seçimi. Bu komut çalıştırıldığında bir POP-UP penceresi görünecektir.
# Seçilen dosya yolu import() komutunu sağlayacaktır.
my_data <- import(file.choose())İPUCU: Açılır pencere RStudio pencerenizin ARDINDA görünebilir.
7.5 Verileri içe aktar
Bir veri kümesini içe aktarmak için import() kullanmak oldukça basittir. Dosyanın yolunu (dosya adı ve dosya uzantısı dahil) tırnak içinde belirtmeniz yeterlidir. Dosya yolunu oluşturmak için “here()” kullanılıyorsa, yukarıdaki talimatları izleyebilirsiniz. Aşağıda birkaç örnek verilmiştir:
“Çalışma dizininizde” veya R projesi kök klasöründe bulunan bir csv dosyasını içe aktarma:
linelist <- import("linelist_cleaned.csv")R projesinin (here() kullanılarak oluşturulan dosya yolu) “veri” ve “çizgi listeleri” alt klasörlerinde bulunan bir Excel çalışma kitabının ilk sayfasını içe aktarma:
Mutlak bir dosya yolu kullanarak bir veri çerçevesini (bir .rds dosyası) içe aktarma:
linelist <- import("C:/Users/Laura/Documents/tuberculosis/data/linelists/linelist_cleaned.rds")Belirli Excel sayfaları
Varsayılan olarak, import() dosyasına bir Excel çalışma kitabı (.xlsx) sağlarsanız, çalışma kitabının ilk sayfası içe aktarılacaktır. Belirli bir sayfayı içe aktarmak istiyorsanız, sayfa adını which = değişkenine ekleyin. Örneğin:
my_data <- import("my_excel_file.xlsx", which = "Sheetname")“import()” ile ilişkili bir yol sağlamak için “here()” yöntemini kullanıyorsanız, “here()” fonksiyonunu kapanış parantezlerinden sonra “which =” değişkenine ekleyerek belirli bir sayfayı yine de belirtebilirsiniz.
# Gösteri: 'here' paketiyle ilgili yolları kullanırken belirli bir Excel sayfasını içe aktarma
linelist_raw <- import(here("data", "linelist.xlsx"), which = "Sheet1")` Bir veri çerçevesini R’dan belirli bir Excel sayfasına dışa aktarmak ve Excel çalışma kitabının geri kalanının değişmeden kalmasını sağlamak için, bu amaca yönelik openxlsx gibi alternatif bir paketle içe aktarmanız, düzenlemeniz ve dışa aktarmanız gerekir. . Dizin etkileşimleri sayfasındaki veya bu github sayfasındaki daha fazla bilgiye bakabilirsiniz.
Excel çalışma kitabınız .xlsb (ikili biçimli Excel çalışma kitabı) ise rio kullanarak içe aktaramayabilirsiniz. .xlsx olarak yeniden kaydetmeyi veya [bu amaç için] oluşturulmuş readxlsb gibi bir paket kullanmayı düşünebilirsiniz(https://cran.r-project.org/web/packages/readxlsb/vignettes/read- xlsb-workbook.html).
Eksik değerler
Veri kümenizdeki hangi değer(ler)in eksik olarak kabul edilmesi gerektiğini belirlemek isteyebilirsiniz. Eksik veri sayfasında açıklandığı gibi, R’daki eksik veriler için değer `NA’dır, ancak belki de içe aktarmak istediğiniz veri kümesi bunun yerine 99, “Eksik” veya yalnızca boş karakter alanı “” kullanır.
‘import()’ için ‘na =’ bağımsız değişkenini kullanın ve değer(ler)i tırnak işaretleri içinde sağlayın (sayı olsalar bile). Aşağıda gösterildiği gibi c() kullanarak bunları bir vektöre dahil ederek birden çok değer belirtebilirsiniz.
Burada, içe aktarılan veri kümesindeki “99” değeri eksik olarak kabul edilir ve R’da “NA”ya dönüştürülür.
Burada, içe aktarılan veri kümesindeki “Eksik”, “” (boş hücre) veya ” ” (tek boşluk) değerlerinden herhangi biri R’da “NA”ya dönüştürülür.
Satırları atla
Bazen bir veri satırını içe aktarmaktan kaçınmak isteyebilirsiniz. Bir .xlsx veya .csv dosyasında rio’dan import() kullanıyorsanız bunu skip = değişkeniyle yapabilirsiniz. Atlamak istediğiniz satır sayısını belirtin.
linelist_raw <- import("linelist_raw.xlsx", skip = 1) # does not import header rowNe yazık ki skip= yalnızca bir tamsayı değeri kabul eder, bir aralık kabul etmez (ör. “2:10” çalışmaz). Üstten ardışık olmayan belirli satırların içe aktarımını atlamak için, birden çok kez içe aktarmayı ve dplyr’den bind_rows() kullanmayı düşünün. Yalnızca 2. satırı atlamayla ilgili aşağıdaki örneğe bakın.
İkinci bir başlık satırını yönetin
Bazen, aşağıda gösterildiği gibi bir “veri sözlüğü” satırıysa verileriniz bir saniye satırı olabilir. Bu durum sorunlu olabilir, çünkü tüm sütunların “karakter” sınıfı olarak içe aktarılmasına neden olabilir.
Aşağıda bu tür bir veri kümesi örneği verilmiştir (ilk satır veri sözlüğüdür).
İkinci başlık satırını kaldırın
İkinci başlık satırını bırakmak için büyük olasılıkla verileri iki kez içe aktarmanız gerekecektir.
- Doğru sütun adlarını saklamak için verileri içe aktarın
- İlk iki satırı (başlık ve ikinci satır) atlayarak verileri tekrar içe aktarın
- Doğru adları azaltılmış veri çerçevesine bağlayın
Doğru sütun adlarını bağlamak için kullanılan tam bağımsız değişken, veri dosyasının türüne (.csv, .tsv, .xlsx, vb.) bağlıdır. Bunun nedeni, rio’nun farklı dosya türleri için farklı bir fonksiyon kullanmasıdır (yukarıdaki tabloya bakın).
Excel dosyaları için: (col_names =)
# ilk kez içe aktarma; sütun adlarını sakla
linelist_raw_names <- import("linelist_raw.xlsx") %>% names() # gerçek sütun adlarını kaydet
# ikinci kez içe aktar; 2. satırı atlayın ve sütun adlarını col_names = değişkenine atayın
linelist_raw <- import("linelist_raw.xlsx",
skip = 2,
col_names = linelist_raw_names
) CSV dosyaları için: (col.names =)
# ilk kez içe aktarma; sütun adlarını depola
linelist_raw_names <- import("linelist_raw.csv") %>% names() # gerçek sütun adlarını kaydet
# csv dosyaları için not değişkeni 'col.names =' şeklindedir
linelist_raw <- import("linelist_raw.csv",
skip = 2,
col.names = linelist_raw_names
) Yedekleme seçeneği - sütun adlarını ayrı bir komut olarak değiştirme
# temel 'colnames()' fonksiyonunu kullanarak başlıkları ata/üzerine yaz
colnames(linelist_raw) <- linelist_raw_namesVeri sözlüğü oluşturun
Bonus! Veri sözlüğü olan ikinci bir satırınız varsa, ondan kolayca uygun bir veri sözlüğü oluşturabilirsiniz. Bu ipucu bu post’dan uyarlanmıştır.
dict <- linelist_2headers %>% # başla: ilk satır olarak sözlük içeren satır listesi
head(1) %>% # yalnızca sütun adlarını ve ilk sözlük satırını tut
pivot_longer(cols = everything(), # tüm sütunları uzun biçime döndür
names_to = "Column", # yeni sütun adları atayın
values_to = "Description")İki başlık satırını birleştirin
Bazı durumlarda, ham veri kümenizde iki başlık satırı varsa (veya daha spesifik olarak, 2. veri satırı ikincil bir başlıktır), bunları “birleştirmek” veya ikinci başlık satırındaki değerleri ilk başlığa eklemek isteyebilirsiniz.
Aşağıdaki komut, veri çerçevesinin sütun adlarını, hemen altındaki (ilk satırdaki) değerle ilk (doğru) başlıkların birleşimi (birlikte yapıştırarak) olarak tanımlayacaktır.
Google sayfaları
googlesheet4 paketiyle ve e-tabloya erişiminizi doğrulayarak çevrimiçi bir Google e-tablosundan veri aktarabilirsiniz.
pacman::p_load("googlesheets4")Aşağıda, bir demo Google sayfası içe aktarılır ve kaydedilir. Bu komut, Google hesabınızın kimlik doğrulamasının onaylanmasını isteyebilir. Tidyverse API paketlerine Google Drive’da e-tablolarınızı düzenleme, oluşturma ve silme izinleri vermek için internet tarayıcınızdaki istemleri ve açılır pencereleri izleyin.
Aşağıdaki sayfa “bağlantıya sahip olan herkes tarafından görüntülenebilir” ve onu içe aktarmayı deneyebilirsiniz.
Gsheets_demo <- read_sheet("https://docs.google.com/spreadsheets/d/1scgtzkVLLHAe5a6_eFQEwkZcc14yFUx1KgOMZ4AKUfY/edit#gid=0")Sayfa, yalnızca URL’nin daha kısa bir parçası olan sayfa kimliği kullanılarak da içe aktarılabilir:
Gsheets_demo <- read_sheet("1scgtzkVLLHAe5a6_eFQEwkZcc14yFUx1KgOMZ4AKUfY")Başka bir paket olan googledrive, Google sayfalarını yazmak, düzenlemek ve silmek için kullanışlı fonksiyonlar sunar. Örneğin, bu pakette bulunan gs4_create() ve sheet_write() fonksiyonları kullanılabilir.
İşte diğer bazı yararlı çevrimiçi eğitimler: temel Google sayfaları içe aktarma öğreticisi daha ayrıntılı eğitim googlesheets4 ve tidyverse arasındaki etkileşim
7.6 Birden çok dosya - içe aktarma, dışa aktarma, bölme, birleştirme
Birden çok dosyanın veya birden çok Excel çalışma kitabı dosyasının nasıl içe aktarılacağına ve birleştirileceğine ilişkin örnekler için Yineleme, döngüler ve listeler hakkındaki sayfaya bakın. Bu sayfada ayrıca bir veri çerçevesinin parçalara nasıl bölüneceği ve her birinin ayrı ayrı veya bir Excel çalışma kitabında adlandırılmış sayfalar olarak nasıl dışa aktarılacağına ilişkin örnekler de vardır.
7.7 Github’dan içe aktar
Verileri doğrudan Github’dan R’a aktarmak çok kolay olabilir veya dosya türüne bağlı olarak birkaç adım gerektirebilir. Aşağıda bazı yaklaşımlar yer almaktadır:
CSV dosyaları
Bir .csv dosyasını bir R komutuyla doğrudan Github’dan R’a aktarmak kolay olabilir.
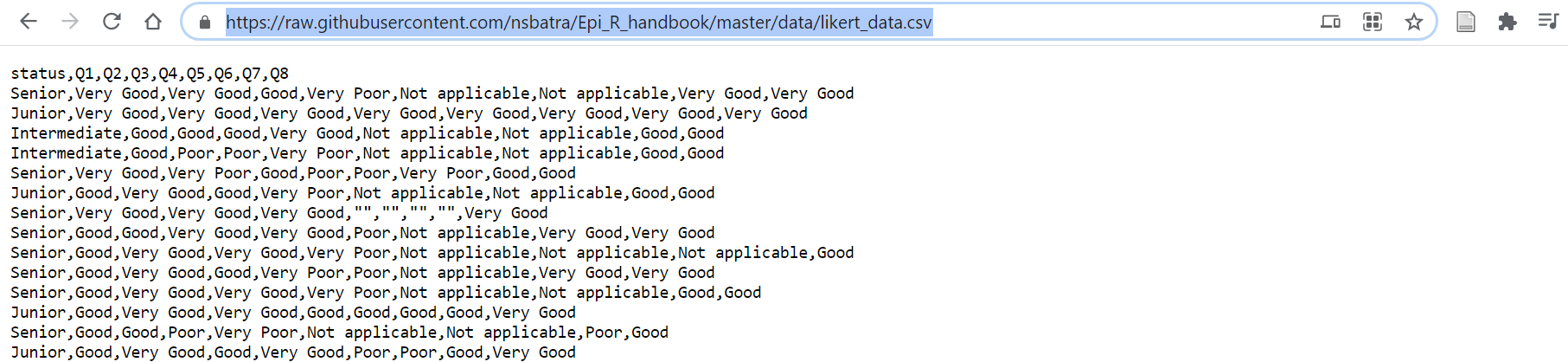
- Github deposuna gidin, ilgilendiğiniz dosyayı bulun ve üzerine tıklayın.
- “Raw” düğmesine tıklayın (daha sonra aşağıda gösterildiği gibi “ham” csv verilerini göreceksiniz)
- URL’yi kopyalayın (web adresi)
- URL’yi
import()R komutu içinde tırnak içine alın
XLSX dosyaları
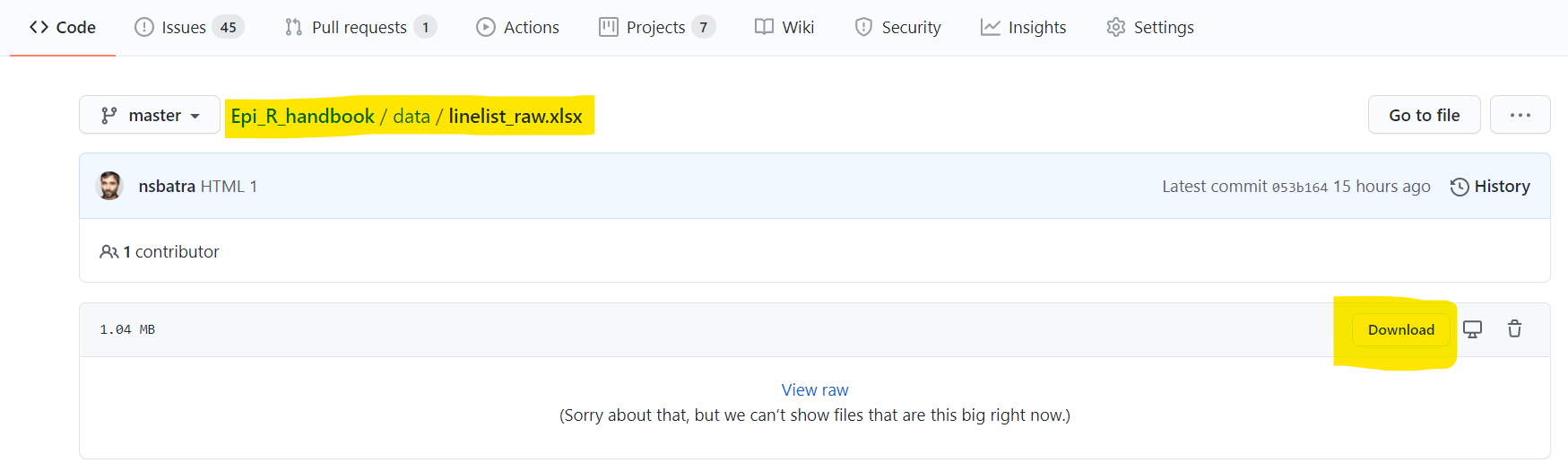
Bazı dosyalar için “Ham” verileri görüntüleyemeyebilirsiniz (ör. .xlsx, .rds, .nwk, .shp)
- Github deposuna gidin, ilgilendiğiniz dosyayı bulun ve üzerine tıklayın.
- Aşağıda gösterildiği gibi “İndir” düğmesini tıklayın
- Dosyayı bilgisayarınıza kaydedin ve R’a alın
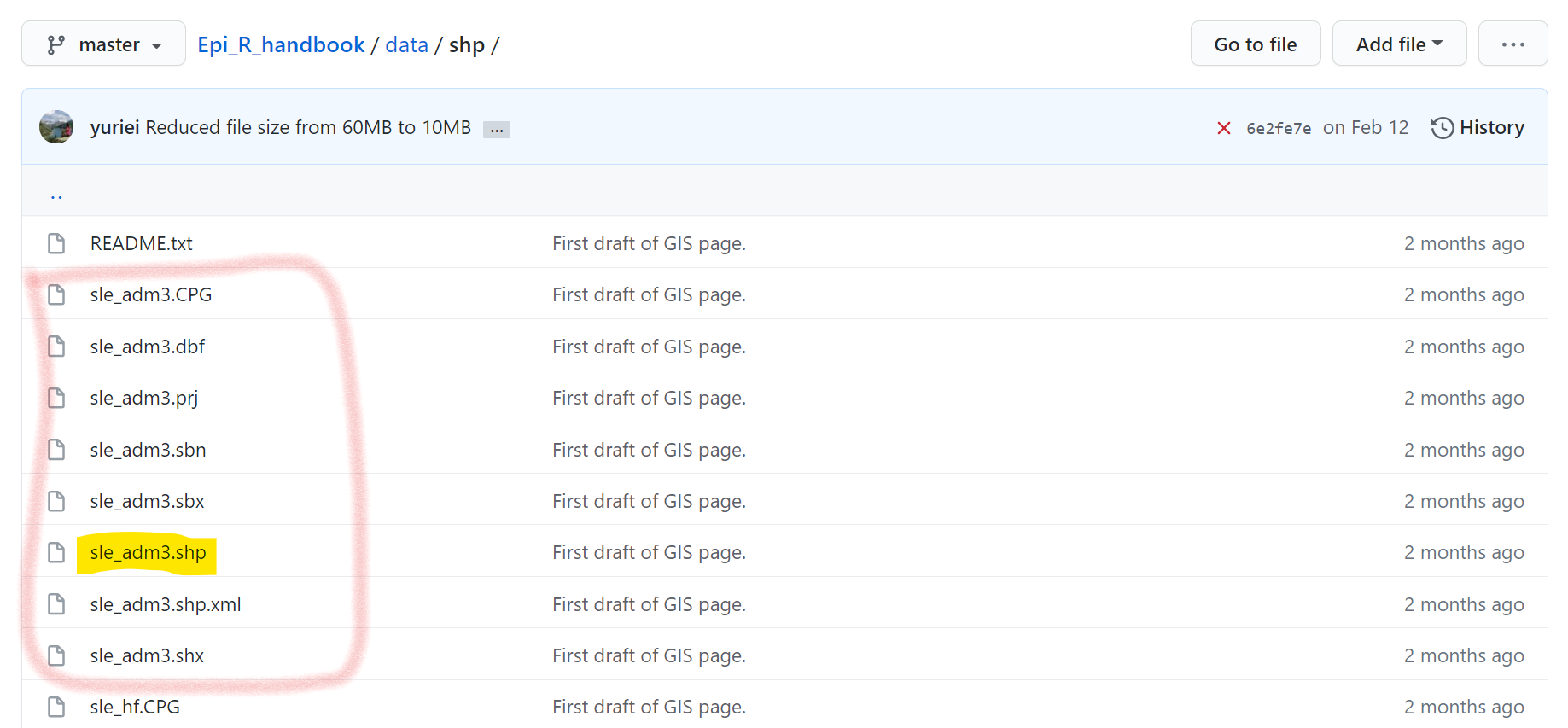
Şekil dosyaları (Shapefiles)
Şekil dosyaları, her biri farklı bir dosya uzantısına sahip birçok alt bileşen dosyasına sahiptir. Bir dosya “.shp” uzantısına sahip olacaktır, ancak diğerleri “.dbf”, “.prj” vb. uzantılara sahip olabilir. Github’dan bir şekil dosyası indirmek için, alt bileşen dosyalarının her birini ayrı ayrı indirmeniz ve kaydetmeniz gerekir. bunları bilgisayarınızdaki aynı klasöre yerleştirin. Github’da her dosyaya tek tek tıklayın ve “İndir” butonuna tıklayarak indirin.
Bilgisayarınıza kaydettikten sonra, sf paketinden st_read() kullanarak şekil dosyasını [GIS temel bilgileri] sayfasında gösterildiği gibi içe aktarabilirsiniz. Diğer ilgili dosyalar bilgisayarınızda aynı klasörde olduğu sürece yalnızca “.shp” dosyasının dosya yolunu ve adını sağlamanız gerekir.
Aşağıda, “sle_adm3” şekil dosyasının her biri Github’dan indirilmesi gereken birçok dosyadan nasıl oluştuğunu görebilirsiniz.
7.8 Manuel veri girişi
Satırlara göre giriş
tidyverse’deki tibble paketindeki ‘tribble’ fonksiyonunu kullanın (çevrimiçi tibble referansı).
Sütun başlıklarının nasıl tilde (~) ile başladığına dikkat edin. Ayrıca her sütunun yalnızca bir veri sınıfı (karakter, sayısal vb.) içermesi gerektiğini unutmayın. Veri girişini daha sezgisel ve okunabilir hale getirmek için sekmeleri, boşlukları ve yeni satırları kullanabilirsiniz. Değerler arasında boşluklar önemli değildir, ancak her satır yeni bir kod satırı ile temsil edilir. Örneğin:
# veri kümesini satıra göre manuel olarak oluşturun
manual_entry_rows <- tibble::tribble(
~colA, ~colB,
"a", 1,
"b", 2,
"c", 3
)Ve şimdi yeni veri setini görüntülüyoruz:
Sütunlara göre giriş
Bir veri çerçevesi vektörlerden (dikey sütunlardan) oluştuğu için, R’da manuel veri çerçevesi oluşturmaya yönelik temel yaklaşım, her sütunu tanımlamanızı ve ardından bunları birbirine bağlamanızı bekler. Bu, genellikle verilerimizi satırlar halinde düşündüğümüzden (yukarıdaki gibi) epidemiyolojide mantıksız olabilir.
# her vektörü (dikey sütun) ayrı ayrı tanımlayın, her biri kendi adıyla
PatientID <- c(235, 452, 778, 111)
Treatment <- c("Yes", "No", "Yes", "Yes")
Death <- c(1, 0, 1, 0)UYARI: Tüm vektörler aynı uzunlukta olmalıdır (aynı sayıda değer).
Vektörler daha sonra “data.frame()” fonksiyonu kullanılarak birbirine bağlanabilir:
# vektör adlarına başvurarak sütunları bir veri çerçevesinde birleştirin
manual_entry_cols <- data.frame(PatientID, Treatment, Death)Ve şimdi yeni veri setini görüntülüyoruz.
Panodan yapıştırma
Verileri başka bir yerden kopyalar ve panonuzda bulundurursanız, aşağıdaki iki yoldan birini deneyebilirsiniz:
clipr paketinden, veri çerçevesi olarak içe aktarmak için ‘read_clip_tbl()’ veya bir karakter vektörü olarak içe aktarmak için sadece ‘read_clip()’ kullanabilirsiniz. Her iki durumda da parantezleri boş bırakın.
linelist <- clipr::read_clip_tbl() # mevcut panoyu veri çerçevesi olarak içe aktarır
linelist <- clipr::read_clip() # karakter vektörü olarak içe aktarAyrıca clipr ile sisteminizin panosuna kolayca aktarabilirsiniz. Aşağıdaki dışa aktarma bölümüne bakın.
Alternatif olarak, veri çerçevesi olarak içe aktarmak için base R’dan file = "clipboard") read.table() fonksiyonunu kullanabilirsiniz:
df_from_clipboard <- read.table(
file = "clipboard", # bunu "pano" olarak belirtin
sep = "t", # ayırıcı sekme veya virgül vb. olabilir.
header=TRUE) # bir başlık satırı varsa7.9 En son dosyayı içe aktar
Genellikle veri kümeleriniz için günlük güncellemeler alabilirsiniz. Bu durumda, en son dosyayı içe aktaran bir kod yazmak isteyeceksiniz. Aşağıda buna yaklaşmanın iki yolunu sunuyoruz:
- Dosya adındaki tarihe göre dosya seçimi
- Dosya meta verilerine göre dosya seçimi (son değişiklik)
Dosya adındaki tarihler
Bu yaklaşım üç öncüle bağlıdır:
- Dosya adlarındaki tarihlere güveniyorsunuz
- Tarihler sayısaldır ve genellikle aynı biçimde görünür (ör. yıl sonra ay sonra gün)
- Dosya adında başka numara yok
Her adımı açıklayacağız ve sonunda size bunların birleştirilmiş halini göstereceğiz.
İlk olarak, ilgilenilen klasördeki her dosya için yalnızca dosya adlarını çıkarmak için base R’dan dir() kullanın. ‘dir()’ hakkında daha fazla ayrıntı için Dizin etkileşimleri sayfasına bakın. Bu örnekte, ilgilenilen klasör, R projesi içindeki “data” içindeki “example” klasörü içindeki “linelists” klasörüdür.
linelist_filenames <- dir(here("data", "example", "linelists")) # klasörden dosya isimlerini al
linelist_filenames # yazdır## [1] "20201007linelist.csv" "case_linelist_2020-10-02.csv"
## [3] "case_linelist_2020-10-03.csv" "case_linelist_2020-10-04.csv"
## [5] "case_linelist_2020-10-05.csv" "case_linelist_2020-10-08.xlsx"
## [7] "case_linelist20201006.csv"Bu ad vektörüne sahip olduğunuzda, bu normal ifadeyi kullanarak stringr’den str_extract() uygulayarak tarihleri çıkarabilirsiniz. Dosya adındaki herhangi bir sayıyı çıkarır (ortadaki tire veya eğik çizgi gibi diğer karakterler dahil). [Dizeler ve karakterler] sayfasında stringr hakkında daha fazla bilgi edinebilirsiniz.
linelist_dates_raw <- stringr::str_extract(linelist_filenames, "[0-9].*[0-9]") # sayıları ve aradaki karakterleri ayıklayın
linelist_dates_raw # yazdır## [1] "20201007" "2020-10-02" "2020-10-03" "2020-10-04" "2020-10-05" "2020-10-08"
## [7] "20201006"Tarihlerin genellikle aynı tarih formatında yazıldığını (örneğin Yıl sonra Ay sonra Gün) ve yılların 4 basamaklı olduğunu varsayarsak, lubridate’nin esnek dönüştürme fonksiyonlarını (ymd(), dmy() kullanabilirsiniz. ) veya mdy()) tarihlere dönüştürmek için. Bu fonksiyonlar için tireler, boşluklar veya eğik çizgiler önemli değildir, yalnızca sayıların sırası önemlidir. Tarihlerle çalışma sayfasında daha fazlasını okuyun.
linelist_dates_clean <- lubridate::ymd(linelist_dates_raw)
linelist_dates_clean## [1] "2020-10-07" "2020-10-02" "2020-10-03" "2020-10-04" "2020-10-05" "2020-10-08"
## [7] "2020-10-06"base R fonksiyonu which.max() daha sonra maksimum tarih değerinin dizin konumunu (ör. 1., 2., 3., …) döndürmek için kullanılabilir. En son dosya, 6. dosya olarak doğru bir şekilde tanımlandı - “case_linelist_2020-10-08.xlsx”.
index_latest_file <- which.max(linelist_dates_clean)
index_latest_file## [1] 6Tüm bu komutları yoğunlaştırırsak, kodun tamamı aşağıdaki gibi görünebilir. Son satırdaki . öğesinin, tünel dizisindeki o noktada tünellenen nesne için bir yer tutucu olduğuna dikkat edin. Bu noktada değer basitçe 6 sayısıdır. Bu, ‘dir()’ tarafından üretilen dosya adları vektörünün 6. öğesini çıkarmak için çift parantez içine yerleştirilir.
# paketleri yükle
pacman::p_load(
tidyverse, # veri yönetimi
stringr, # dizeler/karakterlerle çalışmak
lubridate, # tarihlerle çalışmak
rio, # içe aktar / dışa aktar
here, # ilişkili dosya yolları
fs) # dizin etkileşimleri
# en son dosyanın dosya adını çıkar
latest_file <- dir(here("data", "example", "linelists")) %>% # "linelists" alt klasöründeki dosya adları
str_extract("[0-9].*[0-9]") %>% # tarihleri çıkar (sayılar)
ymd() %>% # sayıları tarihlere dönüştür (yıl-ay-gün biçimini varsayarak)
which.max() %>% # maksimum tarihin dizinini al (en son dosya)
dir(here("data", "example", "linelists"))[[.]] # en son satır listesinin dosya adını döndür
latest_file # en son dosyanın adını yazdır## [1] "case_linelist_2020-10-08.xlsx"Artık bu adı, ilişkili dosya yolunu “here()” ile bitirmek için kullanabilirsiniz:
here("data", "example", "linelists", latest_file) Ve şimdi en son dosyayı içe aktarabilirsiniz:
Dosya bilgisini kullanın
Dosyalarınızın adlarında tarih yoksa (veya bu tarihlere güvenmiyorsanız), dosya meta verilerinden son değişiklik tarihini çıkarmayı deneyebilirsiniz. Her dosya için son değişiklik zamanını ve dosya yolunu içeren meta veri bilgilerini incelemek için fs paketindeki fonksiyonları kullanın.
Aşağıda, fs’nin dir_info() dosyasının ilgilendiği klasörü sunuyoruz. Bu durumda, ilgilenilen klasör “data” klasöründeki R projesinde, “example” alt klasöründe ve alt klasörü “linelists”tedir. Sonuç, dosya başına bir satır ve “modification_time”, “path” vb. için sütunlar içeren bir veri çerçevesidir. Bunun görsel bir örneğini Dizin etkileşimleri sayfasında görebilirsiniz.
Dosyaların bu veri çerçevesini ‘modification_time’ sütununa göre sıralayabiliriz ve ardından base R’ın ‘head()’ ile yalnızca en üstteki/en son satırı (dosyayı) tutabiliriz. Daha sonra bu en son dosyanın dosya yolunu sadece ‘path’ sütunundaki dplyr fonksiyonu ‘pull()’ ile ayıklayabiliriz. Sonunda bu dosya yolunu import()a geçirebiliriz. İçe aktarılan dosya “latest_file” olarak kaydedilir.
latest_file <- dir_info(here("data", "example", "linelists")) %>% # dizindeki tüm dosyalarda dosya bilgilerini topla
arrange(desc(modification_time)) %>% # değişiklik zamanına göre sırala
head(1) %>% # sadece en üstteki (en son) dosyayı tut
pull(path) %>% # yalnızca dosya yolunu çıkar
import() # dosyayı içe aktar7.10 API’ler
Bir web sitesinden doğrudan veri istemek için bir “Otomatik Programlama Arayüzü” (API) kullanılabilir. API’ler, bir yazılım uygulamasının diğeriyle etkileşime girmesine izin veren bir dizi kuraldır. İstemci (siz) bir “istek” gönderir ve içerik içeren bir “yanıt” alır. httr ve jsonlite R paketleri bu süreci kolaylaştırabilir.
API’nin etkin olduğu her web sitesi, aşina olmak için kendi belgelerine ve özelliklerine sahip olacaktır. Bazı siteler herkese açıktır ve herkes tarafından erişilebilir. Kullanıcı kimliklerine ve kimlik bilgilerine sahip platformlar gibi diğerleri, verilerine erişmek için kimlik doğrulama gerektirir.
API aracılığıyla verileri içe aktarmak için internet bağlantınızın olması gerektiğini söylemeye gerek yok. Verileri içe aktarmak için API’lerin kullanımına ilişkin örnekler vereceğiz ve sizi daha fazla kaynağa bağlayacağız.
Not: Verilerin API içermeyen bir web sitesinde yayınlanabileceğini* ve bunun alınmasının daha kolay olabileceğini unutmayın. Örneğin, yayınlanan bir CSV dosyasına, Github’dan içe aktarma bölümünde açıklandığı gibi site URL’sini “import()”a sağlayarak kolayca erişilebilir.*
HTTP isteği
API değişimi en yaygın olarak bir HTTP isteği aracılığıyla yapılır. HTTP, Köprü Metni Aktarım Protokolüdür ve bir istemci ile bir sunucu arasındaki bir istek/yanıtın temel biçimidir. Tam girdi ve çıktı, API türüne bağlı olarak değişebilir, ancak süreç aynıdır - genellikle bir sorgu içeren, kullanıcıdan gelen bir “Talep” (genellikle HTTP İsteği), ardından durum bilgilerini içeren bir “Yanıt”.
İşte bir HTTP isteğinin birkaç bileşeni:
- API uç noktasının URL’si
- “Yöntem” (veya “Fiil”)
- Başlıklar
- Vücut
HTTP isteği “yöntemi”, gerçekleştirmek istediğiniz eylemdir. En yaygın iki HTTP yöntemi ‘GET’ ve ‘POST’tur, ancak diğerleri ’PUT’, ‘DELETE’, ‘PATCH’ vb. içerebilir. Verileri R’a aktarırken büyük olasılıkla ‘GET’ kullanacaksınız.
İsteğinizden sonra bilgisayarınız, URL, HTTP durumu (İstediğiniz Durum 200’dür!), dosya türü, boyutu ve istenen içerik dahil olmak üzere gönderdiğinize benzer bir biçimde bir “yanıt” alacaktır. Daha sonra bu yanıtı ayrıştırmanız ve R ortamınızda uygulanabilir bir veri çerçevesine dönüştürmeniz gerekecektir.
Paketler
httr paketi, R’da HTTP isteklerini işlemek için iyi çalışır. Web API’leri hakkında çok az ön bilgi gerektirir ve yazılım geliştirme terminolojisine daha az aşina olan kişiler tarafından kullanılabilir. Ayrıca, HTTP yanıtı .json ise yanıtı ayrıştırmak için jsonlite kullanabilirsiniz.
# paketleri yüklemek
pacman::p_load(httr, jsonlite, tidyverse)Herkese açık veriler
Aşağıda, Trafford Data Lab bir eğiticiden ödünç alınan bir HTTP isteği örneği verilmiştir. Bu sitede öğrenilecek başka kaynaklar ve API alıştırmaları var.
Senaryo: İngiltere’nin Trafford şehrinde bulunan fast food satış noktalarının bir listesini içe aktarmak istiyoruz. Verilere, Birleşik Krallık için gıda hijyeni derecelendirme verileri sağlayan Gıda Standartları Ajansı API’sinden erişilebilir.
İşte talebimiz için parametreler:
- HTTP fiili: GET
- API uç noktası URL’si: http://api.ratings.food.gov.uk/Establishments
- Seçilen parametreler: ad, adres, boylam, enlem, businessTypeId, ratingKey, localAuthorityId
- Başlıklar: “x-api-version”, 2
- Veri biçimleri: JSON, XML
- Belgeler: http://api.ratings.food.gov.uk/help
R kodu aşağıdaki gibi olacaktır:
# talebi hazırlamak
path <- "http://api.ratings.food.gov.uk/Establishments"
request <- GET(url = path,
query = list(
localAuthorityId = 188,
BusinessTypeId = 7844,
pageNumber = 1,
pageSize = 5000),
add_headers("x-api-version" = "2"))
# herhangi bir sunucu hatası olup olmadığını kontrol edin ("200" iyidir!)
request$status_code
# isteği gönderin, yanıtı ayrıştırın ve bir veri çerçevesine dönüştürün
response <- content(request, as = "text", encoding = "UTF-8") %>%
fromJSON(flatten = TRUE) %>%
pluck("establishments") %>%
as_tibble()Artık her fast food tesisi için bir satır içeren “yanıt” veri çerçevesini temizleyebilir ve kullanabilirsiniz.
Kimlik doğrulama gerekli
Bazı API’ler kimlik doğrulaması gerektirir - kim olduğunuzu kanıtlamanız halinde kısıtlı verilere erişebilirsiniz. Bu verileri içe aktarmak için önce bir kullanıcı adı, parola veya kod sağlamak üzere bir POST yöntemi kullanmanız gerekebilir. Bu, istenen verileri almak için sonraki GET yöntemi istekleri için kullanılabilecek bir erişim belirteci döndürür.
Aşağıda, bir salgın araştırma aracı olan Go.Data’dan veri sorgulama örneği verilmiştir. Go.Data, veri toplama için kullanılan web ön uç ve akıllı telefon uygulamaları arasındaki tüm etkileşimler için bir API kullanır. Go.Data tüm dünyada kullanılmaktadır. Salgın verileri hassas olduğundan ve yalnızca salgınınız için verilere erişebilmeniz gerektiğinden, kimlik doğrulama gereklidir.
Aşağıda, salgınınızdan kişi takibine ilişkin verileri içe aktarmak için Go.Data API’sine bağlanmak için httr ve jsonlite kullanan bazı örnek R kodları verilmiştir.
# yetkilendirme için kimlik bilgilerini ayarla
url <- "https://godatasampleURL.int/" # geçerli Go.Data url örneği
username <- "username" # geçerli Go.Data kullanıcı adı
password <- "password" # geçerli Go.Data parolası
outbreak_id <- "xxxxxx-xxxx-xxxx-xxxx-xxxxxxx" # geçerli Go.Data salgın kimliği
# erişim izni almak
url_request <- paste0(url,"api/oauth/token?access_token=123") # temel url isteğini tanımla
# istek hazırlamak
response <- POST(
url = url_request,
body = list(
username = username, # yetkilendirmek için yukarıdan kaydedilmiş kullanıcı adını/şifreyi kullanın
password = password),
encode = "json")
# isteği yürüt ve yanıtı ayrıştır
content <-
content(response, as = "text") %>%
fromJSON(flatten = TRUE) %>% # düzleştirilmiş iç içe JSON
glimpse()
# Yanıttan erişim belirtecini kaydet
access_token <- content$access_token # aşağıdaki API çağrılarına izin vermek için erişim belirtecini kaydedin
# Salgın temaslılarını içe aktar
# Erişim belirtecini kullanın
response_contacts <- GET(
paste0(url,"api/outbreaks/",outbreak_id,"/contacts"), # GET talebi
add_headers(
Authorization = paste("Bearer", access_token, sep = " ")))
json_contacts <- content(response_contacts, as = "text") # Metni JSON'a dönüştür
contacts <- as_tibble(fromJSON(json_contacts, flatten = TRUE)) # JSON'u tibble için düzleştirin UYARI: Kimlik doğrulama gerektiren bir API’den büyük miktarda veri içe aktarıyorsanız, zaman aşımına uğrayabilir. Bunu önlemek için, her API GET isteğinden önce access_token’i tekrar alın ve sorguda filtreleri veya sınırları kullanmayı deneyin.
İPUCU: jsonlite paketindeki fromJSON() fonksiyonu, ilk çalıştırıldığında yuvayı tamamen açmaz, bu nedenle muhtemelen yine de sonuçta ortaya çıkan tibble’ınızda liste öğeleri vardır. .json dosyanızın ne kadar iç içe olduğuna bağlı olarak belirli değişkenler için daha fazla yuva açmanız gerekecektir. Bununla ilgili daha fazla bilgi görüntülemek için, flatten() fonksiyonu gibi jsonlite paketinin belgelerine bakabilirsiniz.
Daha fazla ayrıntı için LoopBack Explorer, [Kişi İzleme] sayfası veya Go.Data Github deposundaki API ipuçları hakkındaki belgeleri görüntüleyin.
httr paketi hakkında daha fazla bilgiyi buradan okuyabilirsiniz.
Bu bölümde ayrıca bu ders ve bu ders metinlerinden de yararlanıldı.
7.11 Dışa aktarma
rio paketiyle
rio ile, ‘export()’ fonksiyonunu ‘import()’ fonksiyonuna çok benzer bir şekilde kullanabilirsiniz. Önce kaydetmek istediğiniz R nesnesinin adını verin (örn. Örneğin:
Bu, “linelist” veri çerçevesini bir Excel çalışma kitabı olarak çalışma dizini/R proje kök klasörüne kaydeder:
export(linelist, "my_linelist.xlsx") # çalışma dizinine kaydedecekUzantıyı değiştirerek aynı veri çerçevesini bir csv dosyası olarak kaydedebilirsiniz. Örneğin, onu “here()” ile oluşturulmuş bir dosya yoluna da kaydederiz:
export(linelist, here("data","clean", "my_linelist.csv")Panoya
Bir veri çerçevesini bilgisayarınızın “panosuna” aktarmak için (daha sonra Excel, Google E-Tablolar, vb. gibi başka bir yazılıma yapıştırmak için) clipr paketinden write_clip() kullanabilirsiniz.
# satır listesi veri çerçevesini sisteminizin panosuna aktarın
clipr::write_clip(linelist)7.12 RDS dosyaları
.csv, .xlsx vb. ile birlikte R veri çerçevelerini .rds dosyaları olarak dışa aktarabilir/kaydedebilirsiniz. Bu, R’a özgü bir dosya biçimidir ve dışa aktarılan verilerle tekrar R’da çalışacağınızı biliyorsanız çok kullanışlıdır.
Sütun sınıfları depolanır, bu nedenle içe aktarıldığında tekrar temizlemeniz gerekmez (bir Excel veya hatta bir CSV dosyası ile bu bir baş ağrısı olabilir!). Ayrıca, veri kümeniz büyükse dışa ve içe aktarma için kullanışlı olan daha küçük bir dosya üzerinden işlemi yapar.
Örneğin, bir Epidemiyoloji ekibinde çalışıyorsanız ve haritalama için bir CBS ekibine dosya göndermeniz gerekiyorsa ve onlar da R kullanıyorsa, onlara .rds dosyasını göndermeniz yeterlidir! Daha sonra tüm sütun sınıfları korunur ve yapacak daha az işleri olur.
export(linelist, here("data","clean", "my_linelist.rds")7.13 Rdata dosyaları ve listeleri
‘.Rdata’ dosyaları birden çok R nesnesini depolayabilir - örneğin birden çok veri çerçevesi, model sonuçları, listeler, vb. Bu, belirli bir proje için çok sayıda verinizi birleştirmek veya paylaşmak için çok yararlı olabilir.
Aşağıdaki örnekte, dışa aktarılan “my_objects.Rdata” dosyasında birden çok R nesnesi depolanır:
rio::export(my_list, my_dataframe, my_vector, "my_objects.Rdata")Not: Bir listeyi içe aktarmaya çalışıyorsanız, tam orijinal yapı ve içerikle içe aktarmak için rio’dan import_list() kullanın.
rio::import_list("my_list.Rdata")7.14 Grafikleri kaydetme
“ggplot()” tarafından oluşturulanlar gibi grafiklerin nasıl kaydedileceğine ilişkin talimatlar ggplot temelleri sayfasında ayrıntılı olarak tartışılmaktadır.
Özetle, grafiğinizi yazdırdıktan sonra ggsave("my_plot_filepath_and_name.png") komutunu çalıştırın. plot = değişkenine kaydedilmiş bir çizim nesnesi sağlayabilir veya en son görüntülenen grafiği kaydetmek için yalnızca hedef dosya yolunu (dosya uzantısıyla) belirtebilirsiniz. Ayrıca ‘width =’, ‘height =’, ‘units =’ ve ‘dpi =’ değerlerini de kontrol edebilirsiniz.
İletim ağacı gibi bir ağ grafiğinin nasıl kaydedileceği İletim zincirleri sayfasında açıklanmıştır.
7.15 Kaynaklar
R Verilerini İçe/Dışa Aktarma Kılavuzu Veri içe aktarma hakkında R 4 Veri Bilimi bölümü ggsave() belgeleri
Aşağıda rio çevrimiçi vinyet’den alınmış bir tablo bulunmaktadır. Gösterilen her veri türü için: beklenen dosya uzantısı, rio paketinin verileri içe veya dışa aktarmak için kullandığı ve bu fonksiyonun rio’nun varsayılan yüklü sürümüne dahil edilip edilmediğini gösterir.
| Biçim | Tipik Uzantı | İçe Aktarma Paketi | Dışa Aktarma Paketi | Varsayılan Olarak Yüklenir Mi? |
|---|---|---|---|---|
| Comma-separated data | .csv | data.table fread()
|
data.table | Evet |
| Pipe-separated data | .psv | data.table fread()
|
data.table | Evet |
| Tab-separated data | .tsv | data.table fread()
|
data.table | Evet |
| SAS | .sas7bdat | haven | haven | Evet |
| SPSS | .sav | haven | haven | Evet |
| Stata | .dta | haven | haven | Evet |
| SAS | XPORT | .xpt | haven | haven |
| SPSS Portable | .por | haven | Evet | |
| Excel | .xls | readxl | Evet | |
| Excel | .xlsx | readxl | openxlsx | Evet |
| R syntax | .R | base | base | Evet |
| Saved R objects | .RData, .rda | base | base | Evet |
| Serialized R objects | .rds | base | base | Evet |
| Epiinfo | .rec | foreign | Evet | |
| Minitab | .mtp | foreign | Evet | |
| Systat | .syd | foreign | Evet | |
| “XBASE” | database files | .dbf | foreign | foreign |
| Weka Attribute-Relation File Format | .arff | foreign | foreign | Evet |
| Data Interchange Format | .dif | utils | Evet | |
| Fortran data | no recognized extension | utils | Evet | |
| Fixed-width format data | .fwf | utils | utils | Evet |
| gzip comma-separated data | .csv.gz | utils | utils | Evet |
| CSVY (CSV + YAML metadata header) | .csvy | csvy | csvy | Hayır |
| EViews | .wf1 | hexView | Hayır | |
| Feather R/Python interchange format | .feather | feather | feather | Hayır |
| Fast Storage | .fst | fst | fst | Hayır |
| JSON | .json | jsonlite | jsonlite | Hayır |
| Matlab | .mat | rmatio | rmatio | Hayır |
| OpenDocument Spreadsheet | .ods | readODS | readODS | Hayır |
| HTML Tables | .html | xml2 | xml2 | Hayır |
| Shallow XML documents | .xml | xml2 | xml2 | Hayır |
| YAML | .yml | yaml | yaml | Hayır |
| Clipboard default is tsv | clipr | clipr | Hayır |