4 R’a geçiş
Aşağıda, R’a geçiş yapmanız adına bazı tavsiyeler ve kaynaklar sunuyoruz.
R, 1990’ların sonlarında ortaya çıktı ve o zamandan beri ciddi bir ölçüde büyüdü. O kadar gelişmiş ve geniş bir kapasiteye ulaştı ki ticari alternatifleri rekabeti koruyabilmek için R’ın gelişmelerine ayak uydurmaya çalıştılar! (R, SPSS, SAS, STATA ve Python’u karşılaştıran bu makaleyi okuyabilirsiniz).
Tüm bunlarla birlikte R’ı öğrenmek 10 yıl öncesine göre artık çok daha kolay. Daha önceleri, R, yeni başlayanlar için zor olarak kabul edilirdi. RStudio gibi kullanıcı dostu arayüzler, tidyverse gibi sezgisel kodlar ve birçok eğitim kaynakları ile R kullanımı kolaylaştırıldı.
Korkmayın - gelin R dünyasını keşfedin!
4.1 Excel’den geçiş
Excel’den doğrudan R’a geçiş yapmak artık çok daha ulaşılabilir bir hedeftir. Göz korkutucu görünebilir, ancak yapabilirsiniz!
Güçlü Excel becerilerine sahip birinin tek başına Excel’de çok gelişmiş analizler yapabileceği doğrudur. Hatta VBA gibi komut araçlarını kullanarak yapılabilecek faaliyetler daha da artabilecektir. Excel tüm dünyada kullanılmaktadır ve bir epidemiyolog için önemli bir araçtır. Bununla birlikte, onu R ile tamamlamak, iş akışlarınızı önemli ölçüde iyileştirip genişletebilir.
Faydaları
R’ın zamandan tasarruf, daha tutarlı ve doğru analiz, tekrarlanabilirlik, paylaşılabilirlik ve daha hızlı hata düzeltme açısından muazzam faydalar sunduğunu göreceksiniz. Her yeni yazılım gibi, ona aşina olmak için emek vermeniz gereken bir öğrenme “eğrisi” vardır. Birbirinden farklı kütüphaneleriyle R size yeni olasılıkların muazzam kapısını açacaktır.
Excel, “seç ve tıkla” özelliği ile basit analizler ve görselleştirmeler oluşturmak için yeni başlayanlar tarafından kolayca kullanılabilen ve iyi bilinen bir yazılımdır. R’a baktığınızda, fonksiyonlarına ve arayüzüne aşina olabilmeniz birkaç hafta sürebilir. Bununla birlikte, R, son yıllarda yeni başlayanlar için çok daha kolay hale gelmek adına önemli adımlar atmıştır.
Birçok Excel iş akışı hafıza ve tekrarlamaya dayanır. Bu nedenle hata olasılığı çoktur. Ayrıca, genellikle veri temizleme, analiz metodolojisi ve kullanılan denklemler görünümden gizlenir. Yeni bir iş arkadaşının bir Excel çalışma kitabının ne yaptığını ve olası hataların nasıl giderileceğini öğrenmesi için önemli ölçüde bir zamana ihtiyaç duyabilir. R ile tüm adımlar komut dosyasına açıkça yazılır ve kolayca görüntülenebilir, düzenlenebilir, düzeltilebilir ve diğer veri kümelerine uygulanabilir.
Excel’den R’a geçişinize başlamak için zihniyetinizi birkaç önemli yaklaşımla düzenlemeniz gerekir:
Düzenli veri
Dağınık “insan tarafından okunabilen” veriler yerine makine tarafından okunabilen “düzenli” verileri kullanın. R’deki “düzenli” veriler konusunda açıklandığı gibi, “düzenli” veriler için üç ana şart vardır:
- Her değişkenin kendi sütunu olmalıdır
- Her gözlemin kendi satırı olmalıdır
- Her değerin kendi hücresi olmalıdır
Excel kullanıcıları bu şartları Excel “tablolarının” verileri standartlaştırma ve daha tahmin edilebilir bir formata uyarlamada oynadığı rol gibi değerlendirebilir.
“Düzenli” verilere bir örnek, bu el kitabında kullanılan durum satır listesi olabilir. Her değişken bir sütunda yer alır, her gözlemin (bir vaka) kendine ait satırı vardır ve her değer yalnızca bir hücrededir. Aşağıda, linelistin ilk 50 satırını görüntüleyebilirsiniz:
Düzenli olmayan verilerle karşılaşmamızın ana nedeni, birçok Excel tablosunun makineler/yazılımlar tarafından değil, insanlar tarafından kolay okumaya öncelik verecek şekilde tasarlanmış olmasıdır.
Farkı görmenize yardımcı olmak için, aşağıda insan-okunabilirliğe öncelik veren düzensiz verilere ilişkin bazı kurgusal örnekler verilmiştir.:
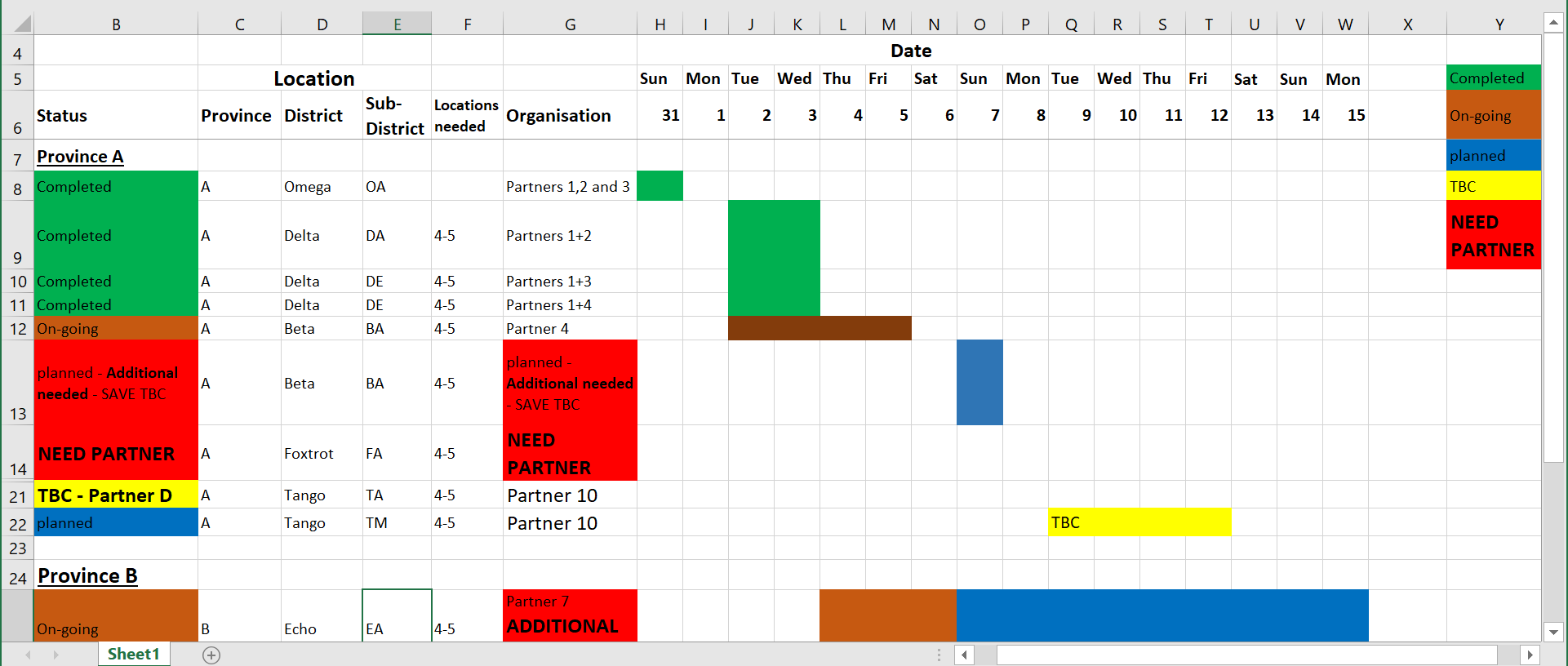
Sorunlar: Yukarıdaki tabloda, R tarafından kolayca anlaşılamayacak olan birleştirilmiş hücreler mevcuttur. Hangi satırın “başlık” olarak kabul edilmesi gerektiği açık değildir. Renk tabanlı bir sözlük sağ taraftadır ve hücre değerleri renklerle temsil edilir - bu da R tarafından kolayca yorumlanamaz (ayrıca renk körlüğü olan insanlar tarafından da!). Ayrıca, farklı bilgi parçaları tek bir hücrede birleştirmiştir (bir alanda çalışan birden fazla ortak kuruluş gibi).
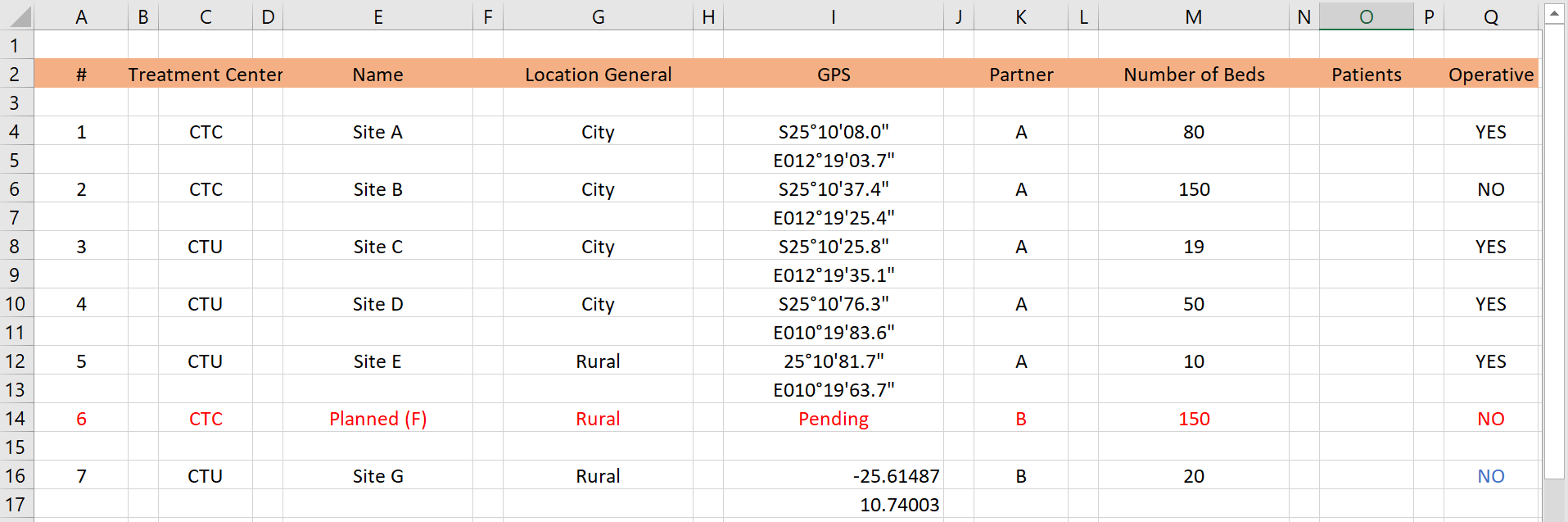
Sorunlar: Yukarıdaki tabloda, veri kümesi içinde çok sayıda fazladan boş satır ve sütun vardır - bu, R’de temizlik sorunlarına neden olur. Ayrıca, belirli bir tedavi merkezi için GPS koordinatları iki satıra yayılmaktadır. Bir yan not olarak - GPS koordinatları iki farklı biçimdedir!
“Düzenli” veri kümeleri insan gözüyle rahatça okunabilir olmayabilir, fakat veri temizleme ve analiz süreçlerini çok daha kolay hale getirirler! Düzenli veriler çeşitli biçimlerde saklanabilir, örneğin “uzun” veya “geniş”“(bkz.[Pivot verileri]). Ancak yukarıdaki ilkeler hala gözetilmektedir.
Fonksiyonlar
R terimi olan “fonksiyon” size yeni gelebilir, fakat bu kavram Excel’de formüller olarak mevcuttur. Excel’deki formüller ayrıca kesin sözdizimi gerektirir (örneğin, noktalı virgül ve parantez yerleştirilmesi). Tek yapmanız gereken birkaç yeni fonksiyonu ve bunların R’da nasıl birlikte çalıştıklarını öğrenmek.
Kodlar
Düğmelere tıklayıp hücreleri sürüklemek yerine her adımı ve prosedürü bir “komut dosyasına” yazacaksınız. Excel kullanıcıları, aynı zamanda bir komut dosyası oluşturma yaklaşımı kullanan “VBA makrolarına” aşina olabilir.
R komut dosyası adım adım talimatlardan oluşur. Bu, herhangi bir iş arkadaşınızın komut dosyasını okumasını ve attığınız adımları kolayca görmesini sağlar. Bu aynı zamanda hataların veya hatalı hesaplamaların giderilmesine de yardımcı olur. Örnekler için komut dosyalarıyla ilgili [R temelleri] bölümüne bakabilirsiniz.
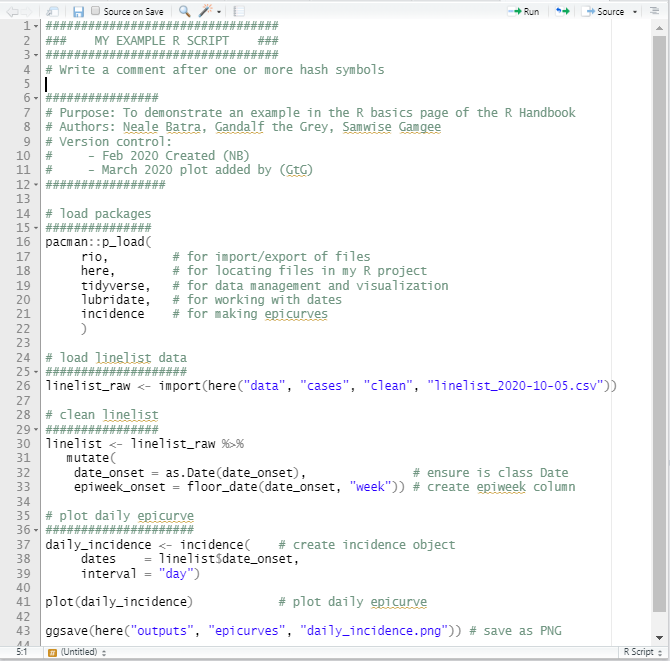
İşte bir R kodu örneği:
Excel’den R’a geçiş kaynakları
Excel’den R’ye geçiş yapmanıza yardımcı olacak rehberlere yönelik bazı bağlantılar:
R-Excel etkileşimi
R, Excel çalışma kitaplarını içe aktarmak, verilerle çalışmak, Excel dosyalarını dışa aktarmak/kaydetmek ve Excel sayfalarının nüanslarıyla çalışmak adına güçlü fonksiyonlara sahiptir.
Estetik bazı Excel biçimlendirmelerinin çeviri sırasında kaybolabileceği doğrudur (örneğin, italik, yan metin, vb.). İş akışınız, orijinal Excel biçimlendirmesini korurken belgeleri R ve Excel arasında ileri geri aktarmayı gerektiriyorsa, openxlsx gibi paketleri deneyebilirsiniz.
4.2 Stata’dan geçiş
Stata’dan R’a gelmek
İlk olarak Stata’yı kullanmayı öğrenen birçok epidemiyolog için R’a geçmek göz korkutucu görünebilir. Ancak, iyi bir Stata kullanıcısıysanız, R’a geçiş kesinlikle düşündüğünüzden daha kolay süreç olacaktır. Stata ve R arasında verilerin nasıl oluşturulabileceği, değiştirilebileceği ve ayrıca analizlerin nasıl yapılacağı konusunda bazı temel farklılıklar olsa bile bu temel farklılıkları öğrendikten sonra Stata becerilerinizi burada da kullabilirsiniz.
Aşağıda, bu kılavuzu incelerken kullanışlı olabilecek, Stata ve R arasındaki bazı önemli akışları bulabilirsiniz.
Genel notlar
| STATA | R |
|---|---|
| Bir seferde yalnızca bir veri kümesi görüntülenip değiştirebilir. | Aynı anda birden fazla veri kümesi görüntülenip değiştirebilir, bu nedenle sık sık kod içinde veri kümesinin belirtilmesi gerekmektedir. |
| Çevrimiçi topluluklara https://www.statalist.org/ sitesinden ulaşabilir. | Çevrimiçi topluluklara RStudio, StackOverFlow, ve R-bloggers sitelerinden ulaşabilir. |
| Seçenek olarak seç ve tıkla işlevi mevcut. | Minimal düzeyde seç ve tıkla işlevi mevcut. |
help [command] koduyla komutlar hakkında yardımcı bilgilere ulaşabilir. |
[function]? kodu veya Yardım sekmesi ile komutlar hakkında yardımcı bilgilere ulaşabilir. |
* veya /// veya /* METİN */ seçeneklerini kullanarak kod yoruma çevirebilir. |
# kullanarak kod yoruma çevirebilir. |
| Hemen hemen tüm komutlar Stata’da yerleşiktir. Yeni/kullanıcı tarafından yazılan işlevler, ssc install [paket] kullanılarak ado dosyaları olarak kurulabilir. | R, base fonksiyonlarla kurulur, ancak tipik kullanım, CRAN’dan diğer paketlerin kurulmasını içerir ([R temelleri]’ndeki sayfasına bakınız.) |
| Analizler genellikle bir do dosyasına yazılır | Analizler RStudio’daki kaynak bölmesine R dili ile yazılır. R markdown dili de alternatif olarak kullanılmaktadır. |
Çalışma dizini
| STATA | R |
|---|---|
| Çalışma dizinleri mutlak dosya yollarını içerir (örneğin, “C:/username/documents/projects/data/”). | Çalışma dizinleri, here paketi kullanılarak proje ana klasörüne veya başka alanlara aktarılabilir (bkz. [İçe aktarma ve dışa aktarma]). |
| pwd ile mevcut çalışma dizini görülebilir. | Boş parantezlerle “getwd()” veya “here()” (here paketi kullanılıyorsa) kullanılır. |
| Çalışma dizinini cd “klasör konumu” ile ayarlanabilir. |
setwd(“klasör konumu”) veya set_here("klasör konumu) (here paketi kullanılıyorsa) kullanabilir. |
Verinin içe aktarılması ve görüntülenmesi
| STATA | R |
|---|---|
| Dosya türüne göre belirli komutlar mevcuttur. | Hemen hemen tüm dosya türleri için rio paketinden import() fonksiyonu kullanabilir. Alternatif olarak belirli fonksiyonlar da mevcuttur (bkz. [İçe aktarma ve dışa aktarma]). |
| csv dosyalarını okuma, import delimitied “dosyaadı.csv” komutuyla sağlanır. |
import("filename.csv") kullanılır. |
| xlsx dosyalarını okuma, import excel “dosyaadı.xlsx” komutuyla sağlanır. |
import("filename.xlsx") kullanılır. |
| browse komutunu kullanarak veriler yeni bir pencerede incelenebilir. |
View(dataset) kullanarak RStudio kaynak bölmesinde veri seti görüntülenebilir. Aynı anda birden fazla veri seti tutulabileceğinden, R’daki fonksiyona veri seti adının belirtilmesi gerekir. Bu fonksiyondaki büyük “V” harfine dikkat edilmeli.
|
| Değişken adlarını ve temel bilgileri veren summarize kullanılarak veri kümesine ilişkin genel bir bakış elde edilebilir. |
summary(dataset) fonksiyonu kullanılarak veri kümesine ilişkin genel bir bakış elde edilebilir. |
Basit veri manipülasyonu
| STATA | R |
|---|---|
| Veri kümesi sütunlarına genellikle “değişkenler” denir. | Daha sıklıkla “sütunlar” veya bazen “vektörler” veya “değişkenler” olarak anılır. |
| Veri kümesini özellikle belirtmenize gerek yoktur. | Aşağıdaki komutların her birinde veri kümesinin belirtilmesi gerekir. Örnekler için [Verileri temizleme ve temel fonksiyonlar] sayfasına bakınız. |
| generate varname = komutu kullanılarak yeni değişkenler oluşturulabilir. |
mutate(varname = ) fonksiyonu kullanılarak yeni değişkenler oluşturabilir. Bütün dplyr fonksiyonlarıyla ilgili ayrıntılar için [Verileri temizleme ve temel fonksiyonlar] sayfasına bakınız. |
| Değişkenler rename eski_adı yeni_adı komutuyla yeniden adlandırılabilir. | Sütunlar, rename(new_name = old_name) fonksiyonu kullanılarak yeniden adlandırılabilir. |
| Değişkenler drop varname kullanılarak kaldırılabilir. | Sütunlar, bir eksi işaretinin ardından parantez içinde sütun adı ile select() işlevi kullanılarak kaldırılabilir. |
| Faktör değişkenleri, label define gibi bir dizi komut kullanılarak etiketlenebilir. | Değerleri etiketleme, sütunu Faktör sınıfına dönüştürerek ve seviyeler belirleyerek yapılabilir.(Faktörler ile ilgili sayfaya bakınız.) Sütun adları genellikle Stata’da olduğu gibi etiketlenmez. |
Tanımlayıcı analiz
| STATA | R |
|---|---|
| tab varname kullanarak bir değişkenin sayılarını tablo haline getirilebilir. |
table() fonksiyonu için table(dataset$colname) koduyla veri kümesi ve sütunun adının sağlanması gerekmektedir. Alternatif olarak, Verileri gruplama bölümünde açıklandığı gibi dplyr paketindeki count(varname) fonksiyonu kullanabilir. |
| 2x2’lik bir tabloda iki değişkenin çapraz tablosu tab varname1 varname2 kodlarıyla oluşturulur. |
table(dataset$varname1, dataset$varname2) veya count(varname1, varname2) fonksiyonları kullanabilir. |
Bu liste, Stata komutlarını R’a çevirmenin temelleri hakkında bir genel bakış sunmakla birlikte ayrıntılı değildir. R’a geçiş yapan Stata kullanıcıları için ilgi çekici olabilecek başka birçok harika kaynak mevcuttur:
4.3 SAS’dan geçiş
SAS’dan R’a gelmek
SAS, halk sağlığı kurumlarında ve akademik araştırma alanlarında yaygın olarak kullanılmaktadır. Yeni bir dile geçiş nadiren basit bir süreç olsa da, SAS ve R arasındaki temel farkları anlamak, ana dilinizde edindiğiniz tecrübeleri yeni dile aktarmakta yardımcı olabilir.
Aşağıda, SAS ve R arasındaki veri yönetimi ve tanımlayıcı analizdeki temel farklılıklar özetlenmektedir.
Genel notlar
| SAS | R |
|---|---|
| Çevrimiçi topluluklara SAS Müşteri Hizmetlerisitesinden ulaşabilir. | RStudio, StackOverFlow ve R-blogları aracılığıyla çevrimiçi topluluklara ulaşabilir. |
help [command] koduyla komutlar hakkında yardımcı bilgilere ulaşabilir. |
[function]? kodu veya Yardım sekmesi ile komutlar hakkında yardımcı bilgilere ulaşabilir. |
* METİN; /* veya /* METİN */ seçeneklerini kullanarak kodu yoruma çevirebilir. |
# kullanarak kodu yoruma çevirebilir. |
Hemen hemen tüm komutlar yerleşiktir. Yeni/kullanıcı tarafından yazılan işlevler, SAS macro, SAS/IML, SAS Component Language (SCL); Proc Fcmp ve Proc Proto prosedürleri kullanılarak kurulabilir. |
R, base fonksiyonlarla kurulur, ancak tipik kullanım, CRAN’dan diğer paketlerin kurulmasını içerir ([R temelleri]’ndeki sayfasına bakınız.). |
| Analiz genellikle Editör penceresinde bir SAS programı yazılarak yapılır. | Analizler RStudio’daki kaynak bölmesine R dili ile yazılır. R markdown dili de alternatif olarak kullanılmaktadır. |
Çalışma dizini
| SAS | R |
|---|---|
Çalışma dizinleri mutlak dosya yollarını içerir. Bunun dışında %let rootdir=/root path; %include “&rootdir/subfoldername/filename” kodu kullanarak başka alanlara kaydedilebilir. |
Çalışma dizinleri, here paketi kullanılarak proje ana klasörüne veya başka alanlara aktarılabilir (bkz. [İçe aktarma ve dışa aktarma]). |
%put %sysfunc(getoption(work)); ile mevcut çalışma dizinini görebilir. |
Boş parantezlerle “getwd()” veya “here()” (here paketi kullanılıyorsa) kullanılır. |
Çalışma dizinini libname “folder location” “klasör konumu” ile ayarlanabilir. |
setwd(“klasör konumu”) veya set_here("klasör konumu) (here paketi kullanılıyorsa) kullanabilir. |
Verinin içe aktarılması ve görüntülenmesi
| SAS | R |
|---|---|
Proc Import prosedürünü veya Data Step Infile ifadesini kullanılır. |
Hemen hemen tüm dosya türleri için rio paketinden import() fonksiyonu kullanabilir. Alternatif olarak belirli fonksiyonlar da mevcuttur (bkz. [İçe aktarma ve dışa aktarma]). |
csv dosyalarını okuma, Proc Import datafile=”filename.csv” out=work.filename dbms=CSV kullanılarak yapılır; run; VEYA Data Step Infile Açıklaması kullanılabilir. |
import("filename.csv") kullanılır. |
xlsx dosyalarını okuma, Proc Import datafile=”filename.xlsx” out=work.filename dbms=xlsx kullanılarak yapılır; run; VEYA Data Step Infile Açıklaması kullanılabilir. |
import("filename.xlsx") kullanılır. |
| Gezgin penceresi açılarak veriler yeni bir pencerede incelenebilir; istenilen kitaplık ve veri kümesi seçilebilir. |
View(dataset) kullanarak RStudio kaynak bölmesinde veri seti görüntülenebilir. Aynı anda birden fazla veri seti tutulabileceğinden, R’daki fonksiyona veri seti adının belirtilmesi gerekir. Bu fonksiyondaki büyük “V” harfine dikkat edilmeli.
|
Basit veri manipülasyonu
| SAS | R |
|---|---|
| Veri kümesi sütunlarına genellikle “değişkenler” denir. | Daha sıklıkla “sütunlar” veya bazen “vektörler” veya “değişkenler” olarak anılır. |
| Veri kümesini özellikle belirtmenize gerek yoktur. Yeni değişkenler, yalnızca yeni değişken adı, ardından eşittir işareti ve ardından değer için bir ifade yazılarak oluşturulur. |
mutate() fonksiyonu kullanılarak yeni değişkenler oluşturabilir. Bütün dplyr fonksiyonlarıyla ilgili ayrıntılar için [Verileri temizleme ve temel fonksiyonlar] sayfasına bakınız. |
Değişkenler rename *old_name=new_name* komutuyla yeniden adlandırılabilir. |
Sütunlar, rename(new_name = old_name) fonksiyonu kullanılarak yeniden adlandırılabilir. |
Değişkenler **keep**=varname kullanılarak kullanılabilir. |
Sütunlar, parantez içinde sütun adı ile select() işlevi kullanılarak seçilebilir. |
Değişkenler **drop**=varname kullanılarak kaldırılabilir. |
Sütunlar, bir eksi işaretinin ardından parantez içinde sütun adı ile select() işlevi kullanılarak kaldırılabilir. |
Faktör değişkenleri, Label ifadesi kullanılarak Veri Adımında etiketlenebilir. |
Değerleri etiketleme, sütunu Faktör sınıfına dönüştürerek ve seviyeler belirleyerek yapılabilir.(Faktörler ile ilgili sayfaya bakınız.) Sütun adları genellikle etiketlenmez. |
Kayıtlar, Veri Adımında Where veya If ifadesi kullanılarak seçilir. Çoklu seçim koşulları “and” komutu kullanılarak ayrılır. |
Kayıtlar, VE operatörü (&) veya virgülle ayrılmış çoklu seçim koşullarıyla filter() fonksiyonu kullanılarak seçilir. |
Veri kümeleri, Veri Adımında Merge ifadesi kullanılarak birleştirilir. Birleştirilecek veri kümelerinin önce Proc Sort prosedürü kullanılarak sıralanması gerekmektedir. |
dplyr paketi, veri kümelerini birleştirmek için birkaç işlev sunar. Ayrıntılar için [Verileri birleştirme] sayfasına bakınız. |
Tanımlayıcı analiz
| SAS | R |
|---|---|
| Değişken adları ve açıklayıcı istatistikler sağlayan “Proc Summary” prosedürü kullanılarak veri kümesi hakkında üst düzey bir genel bakış elde edilebilir. | skimr paketinden “summary(dataset)” veya “skim(dataset)” kullanılarak veri kümesine ilişkin üst düzey bir genel bakış elde edilebilir. |
proc freq data=Dataset; Tables varname; Run; komutu kullanılarak değişken sayıları tablo halinde özetlenebilir. |
Tanımlayıcı tablolar ile ilgili sayfaya bakınız. Seçenekler arasında base R’den ‘table()’ ve janitor paketinden ‘tabyl()’ bulunmaktadır. R birden fazla veri kümesi içerdiği için veri kümesi ve sütun adının belirtilmesi gerekmektedir.
2x2’lik bir tabloda iki değişkenin çapraz tablosu proc freq data=Dataset; Tables rowvar*colvar; Run; komutuyla oluşturulabilir. | table(), tabyl() veya Tanımlayıcı tablolar sayfasında açıklandığı gibi diğer seçenekler kullanabilir.
Birkaç değerli kaynak:
4.4 Veri formatları
R rio paketinin, STATA .dta dosyaları, SAS .xpt ve.sas7bdat dosyaları, SPSS .por ve.sav dosyaları gibi dosyaları gibi pek çok dosyanın nasıl içe ve dışa aktarabileceğiyle ilgili ayrıntılar için İçe ve dışa aktar sayfasına bakınız.