![]()
4 Переход к R
Ниже представлены некоторые советы и ресурсы, если вы переходите к работе с R.
R был представлен в конце 1990-х и с тех пор значительно вырос по своему охвату. Его возможности столь широки, что коммерческие аналоги отреагировали на развитие R, чтобы сохранить конкурентоспособность! (прочитайте эту статью, где сравниваются R, SPSS, SAS, STATA и Python).
Более того, R гораздо легче учить, чем 10 лет назад. Раньше R считался сложным для новичков. Сейчас он стал гораздо легче с появлением удобных для пользователя интерфейсов, таких как RStudio, интуитивно понятного кодирования, такого как tidyverse, и множеством обучающих ресурсов.
Не пугайтесь - приходите изучать мир R!
4.1 Из Excel
Переход от Excel напрямую к R является очень достижимой целью. Это может показаться сложным, но вы справитесь!
Действительно, человек с хорошими навыками Excel может делать очень продвинутые вещи сразу в Excel - даже использовать инструменты написания скрипта, такие как VBA. Excel используется по всему миру и является важным для эпидемиологов инструментом. Однако, если вы добавите к нему R, это может существенно улучшить и расширить ваши потоки работы.
Преимущества
Вы заметите, что использование R дает существенные выгоды в плане экономии времени, обеспечения более последовательного и точного анализа, воспроизводимости, возможности поделиться файлом, а также более быстрого исправления ошибок. Как с любой новой программой, требуется некоторое время для обучения. Выгоды при этом будут значительными, и для вас откроются широкие новые возможности использования R.
Excel - хорошо известная программа, которой очень легко пользоваться новичкам для простого анализа и визуализации по принципу “указания и щелчка”. Для сравнения, чтобы почувствовать себя комфортно с функциями и интерфейсом R может потребоваться пара недель. Однако за последние годы R стал гораздо более удобным для новичков.
Многие потоки работы в Excel полагаются на память и на повторение - таким образом, возникает множество моментов, где могут быть допущены ошибки. Более того, в целом, вычистка данных, методология анализа и уравнения скрыты из вида. Для нового коллеги может потребоваться значительное время, чтобы узнать, что делает рабочая книга Excel, и как искать и устранять проблемы. В R все шаги четко записаны в скрипте, их легко просматривать, редактировать, исправлять и применять к другим наборам данных.
Чтобы начать переход от Excel к R вы должны немного поменять мышление:
Аккуратные данные
Используйте машиночитаемые “аккуратные” данные вместо “хаотичных, читаемых человеком” данных. Для “аккуратных” данных существует три основных требования, как объясняется в самоучителе по “аккуратным” данным в R:
- У каждой переменной должен быть свой столбец
- У каждого наблюдения должна быть своя строка
- У каждого значения должна быть своя ячейка
Для пользователей Excel - представьте себе, какую роль играют “таблицы” Excel в стандартизации данных и обеспечении предсказуемости формата.
Примером “аккуратных” данных может быть построчный список случаев, используемый в данном руководстве - каждая переменная содержится в одном столбце, у каждого наблюдения (одного случая) есть своя строка, а каждое значение занимает только одну ячейку. Ниже вы можете увидеть первые 50 строк построчного списка:
Основная причина того, почему мы видим неаккуратные данные, состоит в том, что таблицы Excel разработаны таким образом, чтобы их было удобно читать человеку, а не для легкости прочтения машинами/программами.
Чтобы проиллюстрировать отличия, ниже представлены некоторые выдуманные примеры неаккуратных данных, которые отдают приоритет читаемости для человека, а не читаемости для машины:

Проблемы: В указанной выше электронной таблице есть объединенные ячейки, которые R сложно воспринимать. Непонятно, какую строку считать “заголовком”. Цветовая кодировка представлена справа, а значения ячеек представлены цветами - R это сложно интерпретировать (и сложно будет людям с цветослепотой!). Более того, в одной ячейке объединены разные элементы информации (несколько партнерских организаций, работающих в одном районе, либо статус “требует уточнения” (“TBC”) в той же ячейке, что “Part112ner D”).

Проблемы: В приведенной выше электронной таблице существует несколько дополнительных пустых строк и столбцов в наборе данных - это будет вызывать проблемы при вычистке в R. Более того, GPS координаты растянуты на две строки для отдельной медицинской организации. Дополнительно следует указать, что координаты GPS представлены в двух разных форматах!
“Аккуратные” наборы данных могут быть более сложны для восприятия человеку, но они существенно облегчают вычистку и анализ данных! Аккуратные данные можно хранить в разных форматах, например “длинном” (вертикальном) и “широком” (горизонтальным) (см. страницу Поворот данных), но указанные выше принципы все равно соблюдаются.
Функции
Слово “функция” в R может быть новым, но концепция существует и в Excel в виде формул. Формулы в Excel также требуют строгого синтаксиса (например, размещение точек с запятой и скобок). Вам нужно лишь выучить несколько новых функций и понять, как они совместно работают в R.
Скрипты
Вместо того, чтобы кликать на кнопки и протягивать ячейки, вы будете записывать каждый шаг и процедуру в “скрипт”. Пользователям Excel могут быть знакомы “макросы VBA”, которые также используют подход написания скриптов.
Скрипт R состоит из пошаговых инструкций. Это позволит любому вашему коллеге прочитать скрипт и легко понять, какие шаги вы выполнили. Это также помогает проводить дебаггинг ошибок или неправильных расчетов. См. раздел Основы R по скриптам для изучения примеров.
Ниже представлен пример скрипта R:
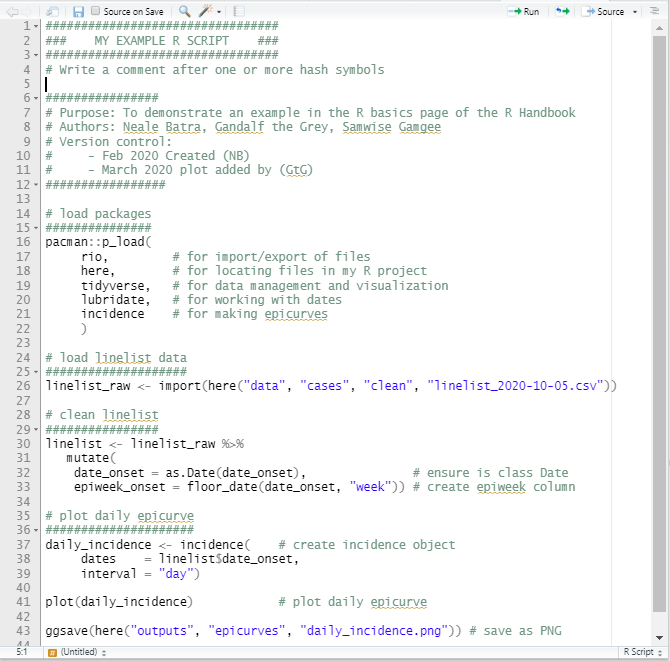
Ресурсы для перехода из Excel в R
Ниже представлены ссылки на самоучители, которые помогут вам перейти к R из Excel:
Взаимодействие R и Excel
В R есть хорошие инструменты для импорта рабочих книг Excel, работы с данными, экспорта/сохранения Excel файлов, а также для работы с нюансами листов Excel.
Действительно, некоторая эстетика форматирования Excel может быть потеряна при переносе (например, курсив, боковой текст и т.п.). Если ваша работа требует постоянного переноса файлов между R и Excel при сохранении оригинального форматирования Excel, попробуйте такие пакеты, как openxlsx.
4.2 Из Stata
Переход в R из Stata
Многих эпидемиологов изначально учили пользоваться Stata, и им может казаться сложным переход к R. Однако если вы уверенно пользуетесь Stata, переход к R может оказаться проще, чем вы думаете. Хотя и существуют некоторые ключевые различия между Stata и R в том, как можно создавать и изменять данные, а также в том, как реализуются функции анализа - изучив эти ключевые различия, вы сможете адаптировать свои навыки.
Ниже представлены некоторые ключевые особенности Stata и R, которые могут быть вам полезны при изучении данного руководства.
Общие комментарии
| STATA | R |
|---|---|
| Вы можете просматривать и изменять только один набор данных за раз | Вы можете просматривать и работать с несколькими наборами данных одновременно, поэтому вам часто нужно будет уточнять набор данных в коде |
| Доступно онлайн сообщество в https://www.statalist.org/ | Доступно онлайн сообщество в RStudio, StackOverFlow, а также R-bloggers |
| Опция функционала “указать и щелкнуть” | Минимальный функционал “указать и щелкнуть” |
Справка по коммандам доступна с помощью help [command] |
Справка доступна с помощью [function]? или поиска в панели Help (справка) |
| Комментирование кода с помощью * или /// или /* TEXT */ | Комментирование кода с помощью # |
| Почти все команды встроены в Stata. Новые/написанные пользователем функции могут быть установлены как ado файлы, используя ssc install [пакет] | R устанавливается с базовыми функциями, но, как правило, для его использования требуется установка других пакетов из CRAN (см. страницу Основы R) |
| Анализ, как правило, записывается как файлы do | Анализ записывается в виде скрипта R в панели RStudio source (источник). Альтернативой являются скрипты R markdown. |
Рабочая директория
| STATA | R |
|---|---|
| Рабочие директории требуют абсолютного пути к файлу (например, “C:/usename/documents/projects/data/”) | Рабочие директории могут иметь абсолютный или относительный путь к корневой папке проекта, используя пакет here (см. Импорт и экспорт) |
| Просмотр текущей директории с помощью pwd | Используется getwd() или here() (при использовании пакета here), с пустыми скобками |
| Рабочая директория задается с помощью cd “место расположения папки” | Используется setwd(“место расположения папки”), или set_here("место расположения папки) (при использовании пакета here) |
Импорт и просмотр данных
| STATA | R |
|---|---|
| Специфичные команды по типам файлов | Используется import() из пакета rio почти для всех типов файлов. Специфичные функции существуют в качестве альтернатив (см. Импорт и экспорт) |
| Чтение csv файлов осуществляется через import delimited “filename.csv” | Используйте import("filename.csv") |
| Чтение xslx файлов осуществляется через import excel “filename.xlsx” | Используйте import("filename.xlsx") |
| Просмотр ваших данных в новом окне с помощью команды browse | Просмотр набора данных на панели source (источник) RStudio с помощью View(dataset). Вам нужно уточнить название вашего набора данных для функции в R, поскольку в нем может содержаться несколько наборов данных одновременно. Обратите внимание на заглавную “V” в этой функции |
| Получение краткого обзора вашего набора данных с помощью summarize, которая даст названия переменных и основную информацию | Получение краткого обзора вашего набора данных с помощью summary(dataset) |
Простые манипуляции с данными
| STATA | R |
|---|---|
| Столбцы набора данных часто называют “переменные” | Чаще называют “столбцы” или иногда “векторы” или “переменные” |
| Нет необходимости указывать название набора данных | В каждой из указанных ниже команд вам необходимо указывать набор данных - см. примеры на странице Вычистка данных и ключевые функции |
| Новые переменные создаются с помощью команды generate varname = | Новые переменные создаются с помощью функции mutate(varname = ). См. детальную информацию по всем указанным ниже функциям dplyr на странице Вычистка данных и ключевые функции. |
| Переменные переименовываются с помощью rename old_name new_name | Столбцы можно переименовать с помощью функции rename(new_name = old_name) |
| Переменные выбрасываются с помощью drop varname | Столбцы можно удалить, используя функцию select() с названием столбца в скобках после знака минус |
| Переменные факторы можно подписать, используя серию команд, таких как label define | Переменные подписываются путем конвертации столбца в класс фактор и уточнения уровней. См. страницу Факторы. Названия столбцов, как правило, не подписываются так, как в Stata. |
Описательный анализ
| STATA | R |
|---|---|
| Подсчет количества по переменной с помощью tab varname | Укажите название набора данных и столбца в table(), например, table(dataset$colname). Либо используйте count(varname) из пакета dplyr, как указано в разделе Группирование данных |
| Перекрестная табуляция по двум переменным в таблице 2x2 проводится с помощью tab varname1 varname2 | Используйте table(dataset$varname1, dataset$varname2 или count(varname1, varname2) |
Хотя в этом списке представлен обзор того, как основные команды из Stata выглядят в R, он не является исчерпывающим. Существует множество других замечательных ресурсов для пользователей Stata по переходу к использованию R, которые могут быть вам интересны:
- https://dss.princeton.edu/training/RStata.pdf
- https://clanfear.github.io/Stata_R_Equivalency/docs/r_stata_commands.html
- http://r4stats.com/books/r4stata/
4.3 Из SAS
Переход от SAS к R
SAS часто используется органами общественного здравоохранения и академическими исследователями. Хотя переход к новому языку редко является простым процессом, понимание ключевых различий между SAS и R поможет вам начать разбираться в новом языке, использовав привычный для вас язык. Ниже представлены ключевые моменты по управлению данными и описательному анализу при переходе от SAS к R.
Общие комментарии
| SAS | R |
|---|---|
| Доступно онлайн сообщество через Клиентскую поддержку SAS | Доступно онлайн сообщество через RStudio, StackOverFlow, и R-bloggers |
Справка по командам доступна через help [command] |
Справка доступна через [function]? или через поиск на панели Help (Справка) |
Комментирование кода с помощью * TEXT ; или /* TEXT */ |
Комментирование кода с помощью # |
Почти все команды встроены. Пользователи могут писать новые функции с помощью SAS macro, SAS/IML, SAS Component Language (SCL), и в последнее время через процедуры Proc Fcmp и Proc Proto |
R устанавливается с базовыми функциями, но при использовании, как правило, требуется установка других пакетов из CRAN (см. страницу Основы R) |
| Анализ, как правило, проводится с помощью написания программы SAS в окне Editor. | Анализ записывается в виде скрипта R на панели source (источник) в RStudio. Альтернативой являются скрипты R markdown. |
Рабочая директория
| SAS | R |
|---|---|
Рабочие директории могут иметь абсолютный или относительный путь к корневой папке проекта, используя %let rootdir=/root path; %include “&rootdir/subfoldername/filename” |
Рабочие директории могут иметь абсолютный или относительный путь к корневой папке проекта, используя пакет here (см. Импорт и экспорт) |
Просмотр текущей рабочей директории с помощью %put %sysfunc(getoption(work)); |
Используется getwd() или here() (при использовании пакета here), с пустыми скобками |
Рабочая директория задается с помощью libname “folder location” |
Используется setwd(“место расположения папки”), или set_here("место расположения папки) (при использовании пакета here) |
Импорт и просмотр данных
| SAS | R |
|---|---|
Используйте процедуру Proc Import или утверждение Data Step Infile. |
Используйте import() из пакета rio почти для всех типов файлов. Существуют специфические функции в качестве альтернатив (см. Импорт и экспорт) |
Чтение csv файлов осуществляется с помощью Proc Import datafile=”filename.csv” out=work.filename dbms=CSV; run; ИЛИ с помощью Утверждения Data Step Infile |
Use import("filename.csv") |
Чтение xslx файлов осуществляется с помощью Proc Import datafile=”filename.xlsx” out=work.filename dbms=xlsx; run; ИЛИ с помощью Утверждения Data Step Infile |
Use import(“filename.xlsx”) |
| Просмотр данных в новом окне с помощью открытия окна Explorer и выбора нужной библиотеки и набора данных | Просмотр набора данных на панели source (источник) RStudio с помощью View(dataset). Вам нужно уточнить название вашего набора данных для функции в R, поскольку в нем может содержаться несколько наборов данных одновременно. Обратите внимание на заглавную “V” в этой функции |
Простые манипуляции с данными
| SAS | R |
|---|---|
| Столбцы набора данных часто называют “переменными” | Более часто называют “столбцы”, иногда “векторы” или “переменные” |
| Не требуются особые процедуры для создания переменной. Новые переменные создаются просто путем впечатывания названия новой переменной, после которой ставится знак равно, а затем выражение для определения значения | Новые переменные создаются с помощью функции mutate(varname = ). См. детальную информацию по всем указанным ниже функциям dplyr на странице Вычистка данных и ключевые функции. |
Переменные переименовываются с помощью rename *old_name=new_name* |
Столбцы можно переименовасть с помощью функции rename(new_name = old_name) |
Переменные сохраняются с помощью **keep**=varname |
Переменные можно выбрать с помощью функции select() с названием столбца в скобках |
Переменные можно удалить с помощью **drop**=varname |
Столбцы можно удалить с помощью функции select() с названием столбца в скобках после знака минус |
Переменные факторы можно подписать на этапе данных, используя утверждение Label |
Подпись переменных можно осуществить через конвертацию столбца в класс факторов, уточнив уровни. См. страницу Факторы. Названия столбцов, как правило, не подписываются. |
Записи можно выбрать с помощью утверждений Where или If на этапе данных. Несколько условий выбора отделяются с помощью команды “and”. |
Записи выбирают с помощью функции filter(), а несколько условий выбора отделяются оператором AND (&) или запятой. |
Наборы данных объединяются с помощью утверждения Merge на этапе данных. Наборы данных, которые нужно объединить, должны быть сначала отсортированы с помощью процедуры Proc Sort. |
Пакет dplyr предлагает новые функции для объединения наборов данных. См. детали на странице Объединение данных. |
Описательный анализ
| SAS | R |
|---|---|
Общий обзор вашего набора данных можно получить с помощью процедуры Proc Summary, которая дает названия переменных и описательную статистику |
Получить общий обзор вашего набора данных можно с помощью summary(dataset) или skim(dataset) из пакета skimr |
Подсчитать количество по переменной можно с помощью proc freq data=Dataset; Tables varname; Run; |
См. страницу Описательные таблицы. Опции, среди прочего, включают table() из базового R, и tabyl() из пакета janitor. Обратите внимание, что вам нужно будет уточнить название набора данных и столбца, так как R содержит несколько наборов данных. |
Перекрестная табуляция двух переменных в таблице 2x2 выполняется с помощью proc freq data=Dataset; Tables rowvar*colvar; Run; |
Опять же, вы можете использовать table(), tabyl() или другие варианты, как описано на странице Описательные таблицы. |
Некоторые полезные ресурсы:
4.4 Совместимость данных
См. страницу [Импорт и экспорт] для получения детальной информации о том, как пакет R rio может импортировать и экспортировать такие файлы, как файлы STATA .dta, файлы SAS .xpt и .sas7bdat, файлы SPSS .por и .sav, а также многие другие.