![]()

Тепловые диаграммы, также известные как “тепловые карты” или “тепловые плитки”, могут быть полезными средствами визуализации при попытке отобразить 3 переменные (ось x, ось y и заливка). Ниже мы демонстрируем два примера:
![]()
В этом фрагменте кода показана загрузка пакетов, необходимых для проведения анализа. В данном руководстве мы делаем акцент на функции p_load() из pacman, которая при необходимости устанавливает пакет и загружает его для использования. Установленные пакеты можно также загрузить с помощью library() из базового R. Более подробную информацию о пакетах R см. на странице Основы R.
pacman::p_load(
tidyverse, # управление данными и их визуализация
rio, # импорт данных
lubridate # работа с датами
)Наборы данных
На этой странице для раздела Матрица передачи используется линейный список случаев моделируемой вспышки, а для раздела Отслеживание показателей - отдельный набор данных о ежедневном количестве случаев малярии по учреждениям. Они загружаются и очищаются в отдельных разделах.
Тепловые плитки могут быть полезны для визуализации матриц. Одним из примеров является отображение “кто заразил кого” во вспышке заболевания. При этом предполагается, что у вас есть информация о событиях передачи.
Обратите внимание на то, что на странице [Отслеживание контактов] приведен другой пример создания матрицы контактов на основе тепловой плитки, использующий другой (возможно, более простой) набор данных, в котором возраст случаев и их источники аккуратно выровнены в одной строке датафрейма. Эти же данные используются для построения карты плотности на странице [Советы по использованию ggplot]. Приведенный ниже пример начинается с построчного списка случаев и поэтому требует значительных манипуляций с данными, прежде чем будет получен датафрейм, пригодный для построения графика. Таким образом, можно выбрать множество сценариев…
Мы начнем с построчного списка случаев моделирования эпидемии лихорадки Эбола. Если вы хотите выполнять действия параллельно, щелкните мышью, чтобы загрузить “чистый” построчный список /a> (в виде файла .rds). Импортируйте данные с помощью функции import() из пакета rio (она принимает множество типов файлов, таких как .xlsx, .rds, .csv - подробности см. на странице Импорт и экспорт).
Ниже для демонстрации показаны первые 50 строк построчного списка:
linelist <- import("linelist_cleaned.rds")В этом построчном списке:
case_id.infector, содержащий case_id infector, который также является случаем в построчном спискеЦель: Нам необходимо получить “длинный” датафрейм, содержащий одну строку для каждого возможного пути передачи от одной возрастной группы другой, с числовым столбцом, содержащим долю этой строки от всех наблюдаемых событий передачи в построчном списке.
Для этого потребуется несколько шагов по управлению данными:
Для начала создадим датафрейм, содержащий все случаи заболевания, их возраст и людей, которые их заразили - назовем этот датафрейм case_ages. Ниже показаны первые 50 строк.
case_ages <- linelist %>%
select(case_id, infector, age_cat) %>%
rename("case_age_cat" = "age_cat")Далее мы создаем датафрейм лиц, заразивших других - на данный момент он состоит из одного столбца. Это идентификаторы лиц, заразивших других, из построчного списка. Не в каждом случае известно лицо, заразившее его, поэтому мы удаляем пропущенные значения. Ниже показаны первые 50 строк.
infectors <- linelist %>%
select(infector) %>%
drop_na(infector)Далее с помощью объединений мы получаем возраст заразивших лиц. Это не так просто, поскольку в linelist возраст заразивших лиц как таковой не указан. Мы достигаем этого результата, присоединяя случай linelist к заразившим лицам. Начнем с заразивших лиц и left_join() (добавим) к ним построчный список так, чтобы столбец id infector левой части “базового” датафрейма соединился со столбцом case_id в правом датафрейме linelist.
Таким образом, данные из построчного списка заразивших лиц (включая возраст) добавляются к строке заразившего лица. Ниже показаны 50 первых строк.
infector_ages <- infectors %>% # начать с заразившего лица
left_join( # добавить данные построчного списка к каждому заразившему лицу
linelist,
by = c("infector" = "case_id")) %>% # сопоставить заразившее лицо с информацией о нем как о случае
select(infector, age_cat) %>% # сохранять только столбцы, представляющие интерес
rename("infector_age_cat" = "age_cat") # переименовать для ясностиЗатем мы объединяем случаи заболевания и их возраст с заразившим лицом и его возрастом. В каждом из этих датафреймов есть столбец infector, который и используется для объединения. Первые строки показаны ниже:
ages_complete <- case_ages %>%
left_join(
infector_ages,
by = "infector") %>% # в каждом из них имеется столбец заразившее лицо
drop_na() # отбрасывать строки с отсутствующими даннымиWarning in left_join(., infector_ages, by = "infector"): Detected an unexpected many-to-many relationship between `x` and `y`.
ℹ Row 1 of `x` matches multiple rows in `y`.
ℹ Row 6 of `y` matches multiple rows in `x`.
ℹ If a many-to-many relationship is expected, set `relationship =
"many-to-many"` to silence this warning.Ниже приведена простая перекрестная табуляция подсчетов между возрастными группами случаев и тех, кто их заразил. Для наглядности добавлены метки.
table(cases = ages_complete$case_age_cat,
infectors = ages_complete$infector_age_cat) infectors
cases 0-4 5-9 10-14 15-19 20-29 30-49 50-69 70+
0-4 105 156 105 114 143 117 13 0
5-9 102 132 110 102 117 96 12 5
10-14 104 109 91 79 120 80 12 4
15-19 85 105 82 39 75 69 7 5
20-29 101 127 109 80 143 107 22 4
30-49 72 97 56 54 98 61 4 5
50-69 5 6 15 9 7 5 2 0
70+ 1 0 2 0 0 0 0 0Мы можем преобразовать эту таблицу в датафрейм с помощью data.frame() из базового R, который также автоматически преобразует ее в “длинный” формат, необходимый для работы ggplot(). Первые строки показаны ниже.
long_counts <- data.frame(table(
cases = ages_complete$case_age_cat,
infectors = ages_complete$infector_age_cat))Теперь сделаем то же самое, но применим к таблице prop.table() из базового R, чтобы вместо подсчетов получить доли от общего числа. Первые 50 строк показаны ниже.
long_prop <- data.frame(prop.table(table(
cases = ages_complete$case_age_cat,
infectors = ages_complete$infector_age_cat)))Теперь, наконец, мы можем построить тепловую диаграмму с помощью пакета ggplot2, используя функцию geom_tile(). Более подробно о шкалах цвета/заливки, в частности о функции scale_fill_gradient(), см. страницу [Советы по использованию ggplot].
aes() функции geom_tile() задайте x и y как возраст случая и возраст заразившего лица.aes() установите аргумент fill = для столбца Freq - это значение будет преобразовано в цвет плиткиscale_fill_gradient() - вы можете указать высокий/низкий цвет
scale_color_gradient() отличается! В данном случае вам нужна заливка.fill = в labs().ggplot(data = long_prop)+ # использовать длинные данные, с пропорциями в качестве Freq
geom_tile( # визуализировать в виде плиток
aes(
x = cases, # Ось x - возраст случая
y = infectors, # Ось y - возраст заразившего лица
fill = Freq))+ # цвет плитки - это столбец Freq в данных
scale_fill_gradient( # настройка цвета заливки плиток
low = "blue",
high = "orange")+
labs( # метки
x = "Case age",
y = "Infector age",
title = "Who infected whom",
subtitle = "Frequency matrix of transmission events",
fill = "Proportion of all\ntranmsission events" # заголовок легенды
)
Часто в здравоохранении одной из задач является оценка тенденций во времени для многих объектов (учреждений, юрисдикций и т.д.). Одним из способов визуализации таких тенденций во времени является тепловая диаграмма, где по оси x откладывается время, а по оси y - множество объектов.
Вначале мы импортируем набор данных ежедневных отчетов по малярии из многих учреждений. Отчеты содержат дату, провинцию, район и количество заболевших малярией. Информацию о том, как загрузить эти данные, см. на странице [Скачивание руководства и данных]. Ниже приведены первые 30 строк:
facility_count_data <- import("malaria_facility_count_data.rds")Цель данного примера - преобразовать ежедневные данные о количестве случаев заболевания малярией в учреждениях (см. предыдущую вкладку) в сводную статистику эффективности отчетности учреждений за неделю - в данном случае долю дней в неделю, когда учреждение сообщало какие-либо данные. В данном примере мы покажем данные только по Весеннему району.
Для этого мы выполним следующие действия по управлению данными:
floor_date() из пакета lubridate.
summarise() создает новые столбцы для отражения сводной статистики по группе ” учреждение-неделя”:
right_join() с полным списком всех возможных комбинаций ” учреждение-неделя”, чтобы сделать набор данных полным. Матрица всех возможных комбинаций создается путем применения функции expand() к тем двум столбцам датафрейма, в которых он находится в данный момент в цепочке оператора (обозначается символом .). Поскольку используется right_join(), все строки в датафрейме expand() сохраняются и при необходимости добавляются в agg_weeks. Эти новые строки появляются с суммарными значениями NA (отсутствующие).Ниже приводится пошаговая демонстрация:
# Создание сводного набора данных за неделю
agg_weeks <- facility_count_data %>%
# отфильтровать данные по мере необходимости
filter(
District == "Spring",
data_date < as.Date("2020-08-01")) Теперь набор данных содержит строки nrow(agg_weeks), в то время как ранее он содержал nrow(facility_count_data).
Далее создадим столбец week, отражающий дату начала недели для каждой записи. Для этого используется пакет lubridate и функция floor_date(), которая устанавливается в значение “неделя” и для того, чтобы недели начинались по понедельникам (1-й день недели - воскресенье будет 7-м). Верхние строки показаны ниже.
agg_weeks <- agg_weeks %>%
# Создание столбца недели из data_date
mutate(
week = lubridate::floor_date( # создать новый столбец недель
data_date, # столбец даты
unit = "week", # задать начало недели
week_start = 1)) # недели начинаются по понедельникам Новый столбец недели можно увидеть в крайней правой части датафрейма
Теперь сгруппируем данные по учреждениям-неделям и обобщим их, чтобы получить статистику по учреждениям-неделям. Советы см. на странице [Описательные таблицы]. Сама по себе группировка не меняет датафрейм, но она влияет на то, как рассчитывается последующая сводная статистика.
Верхние строки показаны ниже. Обратите внимание на то, как полностью изменились столбцы, чтобы отразить желаемую сводную статистику. Каждая строка отражает одно учреждение-неделю.
agg_weeks <- agg_weeks %>%
# Группировка по учреждениям-неделям
group_by(location_name, week) %>%
# Создание столбцов сводной статистики по сгруппированным данным
summarize(
n_days = 7, # 7 дней в неделю
n_reports = dplyr::n(), # количество полученных отчетов в неделю (может быть >7)
malaria_tot = sum(malaria_tot, na.rm = T), # общее число зарегистрированных случаев заболевания малярией
n_days_reported = length(unique(data_date)), # количество уникальных дней отчета в неделю
p_days_reported = round(100*(n_days_reported / n_days))) %>% # процент дней отчетности
ungroup(location_name, week) # разгруппировать, чтобы функция expand() работала на следующем шагеНаконец, мы выполняем приведенную ниже команду, чтобы убедиться, что ВСЕ возможные учреждения-недели присутствуют в данных, даже если до этого они отсутствовали.
Мы используем функцию right_join() на самом себе (набор данных представлен через “.”), но при этом эта функция была расширена, чтобы включить все возможные комбинации столбцов week и location_name. См. документацию по функции expand() на странице [Поворот]. Перед выполнением этого кода набор данных содержит строки nrow(agg_weeks).
# Создать датафрейм всех возможных учреждений-недель
expanded_weeks <- agg_weeks %>%
tidyr::expand(location_name, week) # расширить датафрейм, включив в него все возможные комбинации учреждений-недельВот expanded_weeks с 180 строками:
Перед выполнением кода agg_weeks содержала 107 строк.
# Используйте правое соединение с расширенным списком учреждений-недель для заполнения недостающих пробелов в данных
agg_weeks <- agg_weeks %>%
right_join(expanded_weeks) %>% # Убедитесь, что все возможные комбинации учреждений-недель присутствуют в данных
mutate(p_days_reported = replace_na(p_days_reported, 0)) # преобразование отсутствующих значений в 0 Joining with `by = join_by(location_name, week)`После выполнения этого кода agg_weeks содержит строки nrow(agg_weeks).
Для построения ggplot() используется geom_tile() из пакета ggplot2:
scale_x_date().location_name, где отображаются названия всех учреждений.fill - это p_days_reported, результативность для данного учреждения за неделю (числовое значение)scale_fill_gradient() используется для числовой заливки, задавая цвета для высокого, низкого и NA.scale_x_date() используется для оси x, задавая метки каждые 2 недели и их формат.Ниже приведена базовая тепловая диаграмма, использующая цвета, шкалы и т.д. по умолчанию. Как объяснялось выше, внутри aes() для geom_tile() необходимо указать столбец оси x, столбец оси y, и столбец для fill=. Заливка - это числовое значение, которое представляет собой цвет плитки.
ggplot(data = agg_weeks)+
geom_tile(
aes(x = week,
y = location_name,
fill = p_days_reported))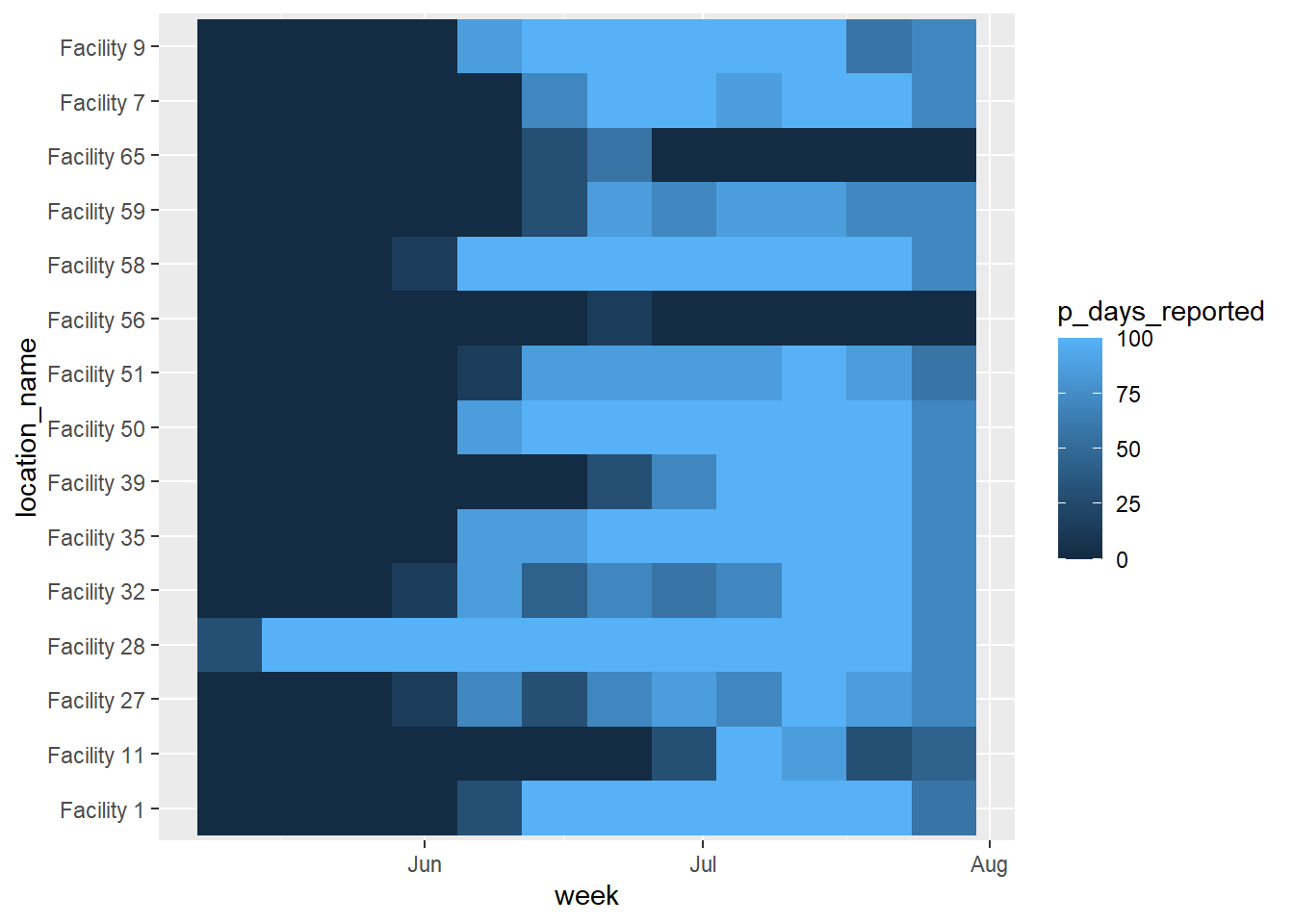
Мы можем сделать эту диаграмму более красивой, добавив дополнительные функции ggplot2, как показано ниже. Подробности см. на странице [Советы по использованию ggplot].
ggplot(data = agg_weeks)+
# отображение данных в виде плиток
geom_tile(
aes(x = week,
y = location_name,
fill = p_days_reported),
color = "white")+ # белые линии сетки
scale_fill_gradient(
low = "orange",
high = "darkgreen",
na.value = "grey80")+
# ось дат
scale_x_date(
expand = c(0,0), # удалить лишнее пространство по бокам
date_breaks = "2 weeks", # метки каждые 2 недели
date_labels = "%d\n%b")+ # Формат - день за месяцем (\n через новую строку)
# эстетические темы
theme_minimal()+ # упростить фон
theme(
legend.title = element_text(size=12, face="bold"),
legend.text = element_text(size=10, face="bold"),
legend.key.height = grid::unit(1,"cm"), # высота ключа легенды
legend.key.width = grid::unit(0.6,"cm"), # ширина ключа легенды
axis.text.x = element_text(size=12), # размер текста по оси
axis.text.y = element_text(vjust=0.2), # выравнивание текста по оси
axis.ticks = element_line(size=0.4),
axis.title = element_text(size=12, face="bold"), # размер заголовка оси и полужирный шрифт
plot.title = element_text(hjust=0,size=14,face="bold"), # Заголовок выровнен по правому краю, крупный, полужирный
plot.caption = element_text(hjust = 0, face = "italic") # Надпись, выровненная по правому краю и выделенная курсивом
)+
# метки диаграммы
labs(x = "Week",
y = "Facility name",
fill = "Reporting\nperformance (%)", # Заголовок легенды, так как легенда показывает заливку
title = "Percent of days per week that facility reported data",
subtitle = "District health facilities, May-July 2020",
caption = "7-day weeks beginning on Mondays.")
В настоящее время учреждения расположены в алфавитно-цифровом порядке снизу вверх. Если вы хотите изменить порядок учреждений по оси y, переведите их в коэффициент класса и укажите порядок. Советы см. на странице [Факторы].
Поскольку учреждений много и мы не хотим выписывать их все, попробуем другой подход - упорядочить учреждения в датафрейме и использовать полученный столбец названий в качестве порядка на уровне факторов. Ниже столбец location_name преобразуется в фактор, а порядок его уровней устанавливается в зависимости от общего количества отчетных дней, поданных учреждением за весь временной интервал.
Для этого мы создаем датафрейм, представляющий собой общее количество отчетов по каждому объекту, расположенных в порядке возрастания. Этот вектор мы можем использовать для упорядочивания уровней фактора на графике.
facility_order <- agg_weeks %>%
group_by(location_name) %>%
summarize(tot_reports = sum(n_days_reported, na.rm=T)) %>%
arrange(tot_reports) # возрастающий порядокСм. датафрейм ниже:
Теперь используйте столбец из приведенного выше датафрейма (facility_order$location_name) в качестве порядка следования уровней фактора location_name в датафрейме agg_weeks:
# загрузка пакета
pacman::p_load(forcats)
# создание коэффициентов и определение уровней вручную
agg_weeks <- agg_weeks %>%
mutate(location_name = fct_relevel(
location_name, facility_order$location_name)
)А теперь данные повторно построены на графике, причем location_name является упорядоченным фактором:
ggplot(data = agg_weeks)+
# отображение данных в виде плиток
geom_tile(
aes(x = week,
y = location_name,
fill = p_days_reported),
color = "white")+ # белые линии сетки
scale_fill_gradient(
low = "orange",
high = "darkgreen",
na.value = "grey80")+
# ось даты
scale_x_date(
expand = c(0,0), # удалить лишнее пространство по бокам
date_breaks = "2 weeks", # метки каждые 2 недели
date_labels = "%d\n%b")+ # Формат - день за месяцем (\n через новую строку)
# эстетические темы
theme_minimal()+ # упростить фон
theme(
legend.title = element_text(size=12, face="bold"),
legend.text = element_text(size=10, face="bold"),
legend.key.height = grid::unit(1,"cm"), # высота ключа легенды
legend.key.width = grid::unit(0.6,"cm"), # ширина ключа легенды
axis.text.x = element_text(size=12), # размер текста по оси
axis.text.y = element_text(vjust=0.2), # выравнивание текста по оси
axis.ticks = element_line(size=0.4),
axis.title = element_text(size=12, face="bold"), # размер заголовка по оси и полужирный шрифт
plot.title = element_text(hjust=0,size=14,face="bold"), # Заголовок выровнен по правому краю, крупный, полужирный
plot.caption = element_text(hjust = 0, face = "italic") # Надпись, выровненная по правому краю и выделенная курсивом
)+
# метки диаграммы
labs(x = "Week",
y = "Facility name",
fill = "Reporting\nperformance (%)", # Заголовок легенды, так как легенда показывает заливку
title = "Percent of days per week that facility reported data",
subtitle = "District health facilities, May-July 2020",
caption = "7-day weeks beginning on Mondays.")
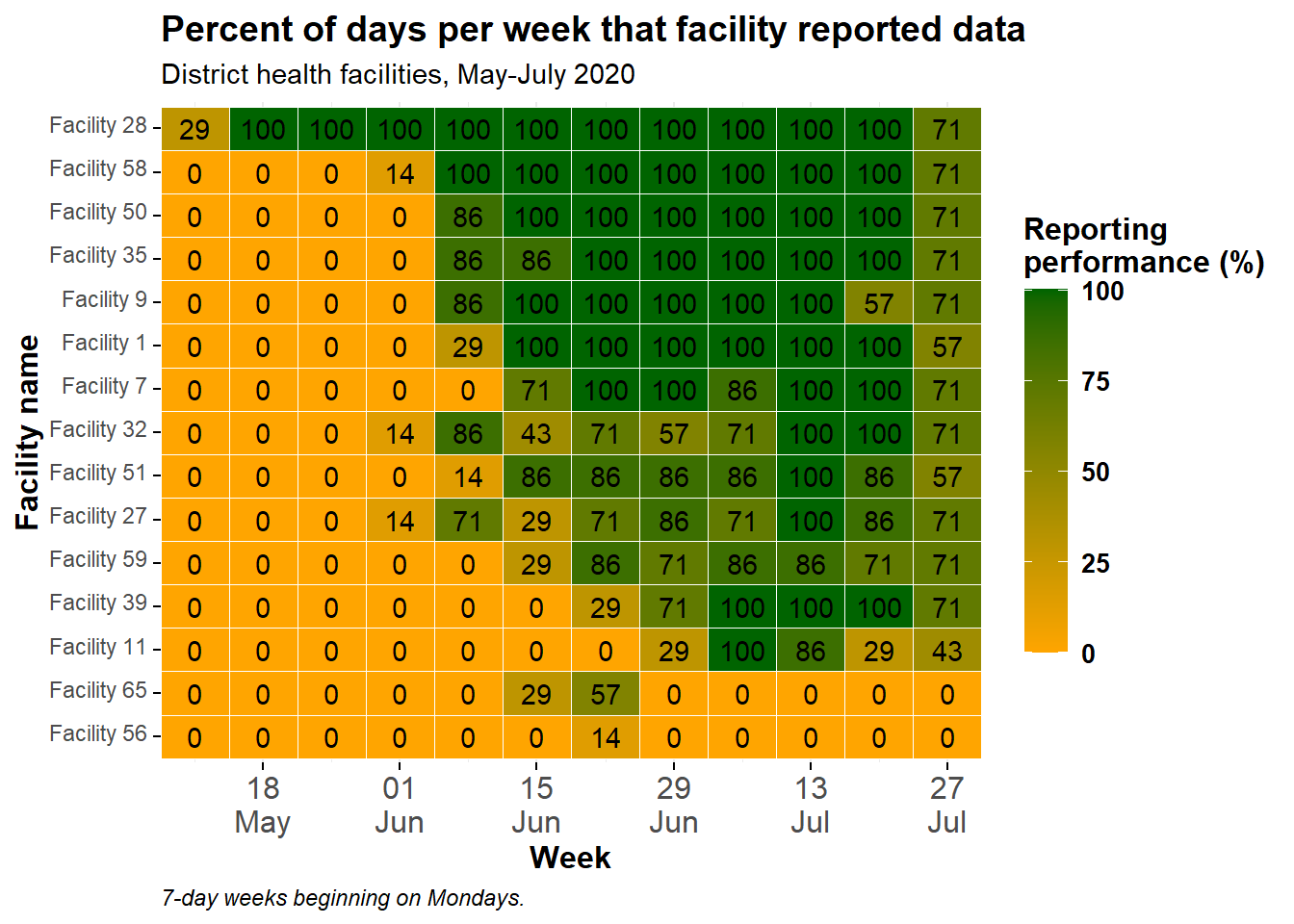
Поверх плиток можно добавить слой geom_text(), чтобы отобразить фактические номера каждой плитки. Имейте в виду, что это может выглядеть не очень красиво, если у вас много маленьких плиток!
Был добавлен следующий код: geom_text(aes(label = p_days_reported)). Этот код добавляет текст на каждую плитку. Отображаемый текст представляет собой значение, присвоенное аргументу label =, который в данном случае был задан для того же числового столбца p_days_reported, который также используется для создания цветового градиента.
ggplot(data = agg_weeks)+
# отображение данных в виде плиток
geom_tile(
aes(x = week,
y = location_name,
fill = p_days_reported),
color = "white")+ # белые линии сетки
# текст
geom_text(
aes(
x = week,
y = location_name,
label = p_days_reported))+ # добавление текста поверх плитки
# шкала заливки
scale_fill_gradient(
low = "orange",
high = "darkgreen",
na.value = "grey80")+
# ось дат
scale_x_date(
expand = c(0,0), # удалить лишнее пространство по бокам
date_breaks = "2 weeks", # метки каждые 2 недели
date_labels = "%d\n%b")+ # Формат - день за месяцем (\n через новую строку)
# эстетические темы
theme_minimal()+ # упростить фон
theme(
legend.title = element_text(size=12, face="bold"),
legend.text = element_text(size=10, face="bold"),
legend.key.height = grid::unit(1,"cm"), # высота ключа легенды
legend.key.width = grid::unit(0.6,"cm"), # ширина ключа легенды
axis.text.x = element_text(size=12), # размер текста по оси
axis.text.y = element_text(vjust=0.2), # выравнивание текста по оси
axis.ticks = element_line(size=0.4),
axis.title = element_text(size=12, face="bold"), # размер заголовка по оси и полужирный шрифт
plot.title = element_text(hjust=0,size=14,face="bold"), # Заголовок выровнен по правому краю, крупный, полужирный
plot.caption = element_text(hjust = 0, face = "italic") # Надпись, выровненная по правому краю и выделенная курсивом
)+
# метки диаграммы
labs(x = "Week",
y = "Facility name",
fill = "Reporting\nperformance (%)", # Заголовок легенды, так как легенда показывает заливку
title = "Percent of days per week that facility reported data",
subtitle = "District health facilities, May-July 2020",
caption = "7-day weeks beginning on Mondays.")