
30 Основы ggplot
ggplot2 - самый популярный пакет R для визуализации данных. В основе этого пакета лежит функция ggplot(), а весь подход в целом известен как “ggplot”, а получаемые рисунки иногда ласково называют “ggplots”. Буквы “gg” в этих названиях означают “gграмматику gграфики”, используемую для построения рисунков. В ggplot2 используется большое количество дополнительных пакетов R, которые расширяют его функциональность.
Синтаксис значительно отличается от синтаксиса построения графиков в базовом R и требует определенного обучения. Использование ggplot2, как правило, требует от пользователя форматирования данных с высокой степенью совместимости с tidyverse, что в конечном итоге делает совместное использование этих пакетов очень эффективным.
На этой странице мы рассмотрим основы построения графиков с помощью ggplot2. Предложения и дополнительные приемы, позволяющие сделать графики действительно красивыми, см. на странице [Советы по использованию ggplot].
В разделе “Ресурсы” есть несколько подробных учебных пособий по ggplot2. Вы также можете скачать материал Шпаргалка по визуализации данных с помощью ggplot с сайта RStudio. Если вы хотите найти вдохновение для творческого подхода к визуализации данных, мы рекомендуем обратиться к таким сайтам, как галерея графиков R и от данных к визуализации.
30.1 Подготовка
Загрузка пакетов
В этом фрагменте кода показана загрузка пакетов, необходимых для проведения анализа. В данном руководстве мы делаем акцент на p_load() из pacman, которая при необходимости устанавливает пакет и загружает его для использования. Установленные пакеты можно также загрузить с помощью library() из базового R. Более подробную информацию о пакетах R см. на странице [Основы R].
pacman::p_load(
tidyverse, # включает ggplot2 и другие средства управления данными
janitor, # чистящие и сводные таблицы
ggforce, # Дополнения к ggplot
rio, # импорт/экспорт
here, # локатор файлов
stringr # работа с символами
)Импорт данных
Импортируем набор данных случаев из смоделированной эпидемии лихорадки Эбола. Если вы хотите выполнять действия параллельно, щелкните мышью, чтобы загрузить “чистый” построчный список (в виде файла .rds). Импортируйте данные с помощью функции import() из пакета rio (она принимает множество типов файлов, таких как .xlsx, .rds, .csv - подробности см. на странице [Импорт и экспорт]).
linelist <- rio::import("linelist_cleaned.rds")Ниже представлены первые 50 строк построчного списка. Мы сосредоточимся на непрерывных переменных age(возраст), wt_kg (вес в килограммах), ct_blood(значения CT) и days_onset_hosp (разница между датой начала заболевания и госпитализацией).
Общая вычистка
При подготовке данных к построению графиков лучше всего сделать так, чтобы они максимально соответствовали понятию стандарты “аккуратных” данных. О том, как этого добиться, рассказывается на страницах этого руководства, посвященных управлению данными, например, в разделе [Вычистка данных и ключевые функции].
Некоторые простые способы подготовки данных для построения графиков могут включать в себя улучшение качества отображения содержимого данных, что не обязательно означает улучшение качества работы с данными. Например:
- Заменить значения
NAв текстовом столбце на последовательность символов “Неизвестно”.
- Рассмотреть возможность преобразования столбца в класс фактор, чтобы его значения имели предписанные порядковые уровни
- Вычистка некоторых столбцов с заменой “дружественных к данным” значений с подчеркиваниями и т.п. на обычный текстовый или заглавный регистр (см. [Текст и последовательности])
Приведем несколько примеров этого в действии:
# сделать версию отображения столбцов с более удобными названиями
linelist <- linelist %>%
mutate(
gender_disp = case_when(gender == "m" ~ "Male", # м на Муж
gender == "f" ~ "Female", # ж на Жен,
is.na(gender) ~ "Unknown"), # NA на неизвестно
outcome_disp = replace_na(outcome, "Unknown") # заменить исход NA на "неизвестно"
)Поворот в длину
С точки зрения структуры данных, для ggplot2 мы часто также хотим разворачивать данные в более длинные форматы. Подробнее об этом можно прочитать на странице [Поворот данных].

Например, мы хотим построить график данных в “широком” формате, например, для каждого случая в построчном спискеlinelist и его симптомов. Ниже мы создадим мини построчный список с названием symptoms_data, содержащий только столбцы case_id и симптомы.
symptoms_data <- linelist %>%
select(c(case_id, fever, chills, cough, aches, vomit))Вот как выглядят первые 50 строк этого мини построчного списка - посмотрите, как они отформатированы “в ширину” с каждым симптомом в виде столбца:
Если бы мы хотели построить график количества случаев с определенными симптомами, мы были бы ограничены тем, что каждый симптом - это отдельный столбец. Однако мы можем повернуть столбцы симптомов в более длинный формат, например, так:
symptoms_data_long <- symptoms_data %>% # начать с "мини" построчного списка под названием symptoms_data
pivot_longer(
cols = -case_id, # повернуть все столбцы, кроме case_id (все столбцы симптомов)
names_to = "symptom_name", # присвоить название новому столбцу, в котором будут содержаться симптомы
values_to = "symptom_is_present") %>% # присвоить название новому столбцу, в котором будут находиться значения (да/нет)
mutate(symptom_is_present = replace_na(symptom_is_present, "unknown")) # преобразовать NA в "неизвестно"Здесь представлены первые 50 строк. Обратите внимание на то, что случай имеет 5 строк - по одной для каждого возможного симптома. Новые столбцы symptom_name и symptom_is_present являются результатом поворота. Заметим, что этот формат может быть не очень удобен для других операций, но полезен для построения графиков.
30.2 Основы ggplot
“Грамматика графики” - ggplot2
Построение графиков с помощью ggplot2 основано на “наложении” друг на друга слоев и элементов оформления, причем каждая команда добавляется к предыдущим с помощью символа плюса (+). В результате получается многослойный графический объект, который можно сохранять, изменять, распечатывать, экспортировать и т.д.
Объекты ggplot могут быть очень сложными, но основной порядок слоев обычно выглядит следующим образом:
- Начните с базовой команды
ggplot()- она “открывает” ggplot и позволяет добавлять последующие функции с помощью+. Как правило, в этой команде также указывается набор данных
- Добавьте слои “geom” - эти функции визуализируют данные в виде геометрии (фигуры), например, в виде гистограммы, линейного графика, диаграммы рассеяния, гистограммы (или их комбинации!). Все эти функции начинаются с префикса
geom_.
- Добавьте элементы оформления графика, такие как метки осей, заголовок, шрифты, размеры, цветовые схемы, легенды или поворот осей.
Простой пример скелетного кода приведен ниже. Пояснения к каждому компоненту будут даны в следующих разделах.
# построить график данных из столбца my_data в виде красных точек
ggplot(data = my_data)+ # использование набора данных "my_data"
geom_point( # добавить слой точек
mapping = aes(x = col1, y = col2), # "привязка" столбца данных к осям
color = "red")+ # другая спецификация для геом
labs()+ # здесь добавляются заголовки, метки осей и т.д.
theme() # Здесь настраиваются цвет, шрифт, размер и т.д. элементов графика, не относящихся к данным (оси, заголовок и т.д.) 30.3 ggplot()
Открывающей командой любого графика ggplot2 является команда ggplot(). Эта команда просто создает чистый холст, на который можно добавлять слои. Она “открывает” путь для добавления последующих слоев с помощью символа +.
Обычно команда ggplot() включает аргумент data = для построения графика. Это задает набор данных по умолчанию, который будет использоваться для последующих слоев графика.
Команда завершается символом + после закрывающих круглых скобок. Таким образом, команда остается “открытой”. ggplot будет выполняться/появляться только в том случае, если полная команда включает последний слой без + в конце.
# Это позволит создать график, представляющий собой чистый холст
ggplot(data = linelist)30.4 Геомы
Чистого холста, конечно, недостаточно - необходимо создать геометрию (фигуры) из наших данных (например, столбчатые диаграммы, гистограммы, диаграммы рассеяния, коробчатой диаграммы).
Это делается путем добавления слоев “геомов” к исходной команде ggplot(). Существует множество функций ggplot2, создающих “геомы”. Каждая из этих функций начинается с символа “geom_”, поэтому мы будем называть их обобщенно geom_XXXX(). В ggplot2 существует более 40 геомов и множество других, созданных поклонниками. Ознакомиться с ними можно на сайте галерея ggplot2. Ниже перечислены некоторые распространенные геомы:
- Гистограммы -
geom_histogram()
- Столбчатые диаграммы -
geom_bar()orgeom_col()(see “Bar plot” section)
- Бокс-диаграммы -
geom_boxplot()
- Точки (н-р диаграммы рассеивания) -
geom_point()
- Линейные графики -
geom_line()orgeom_path()
- Графики трендов -
geom_smooth()
На одном графике можно отобразить один или несколько геомов. Каждый из них добавляется к предыдущим командам ggplot2 с помощью знака +, и они строятся последовательно, так что последующие геомы строятся поверх предыдущих.
30.5 Сопоставление данных с графиком
Большинству функций геомов необходимо указать, что использовать для создания фигур, поэтому вы должны указать им, как сопоставить (назначить) столбцы ваших данных с компонентами графика, такими как оси, цвета фигур, размеры фигур и т.д. Для большинства геомов основными компонентами, которые должны быть сопоставлены со столбцами данных, являются ось x и (при необходимости) ось y.
Это ” сопоставление” происходит с помощью аргумента mapping =. Сопоставления, которые вы передаете в mapping, должны быть обернуты в функцию aes(), поэтому вы напишете что-то вроде mapping = aes(x = col1, y = col2), как показано ниже.
Ниже, в команде ggplot(), данные задаются в виде построчного списка linelist. В аргументе mapping = aes() столбец age возраст отображается на ось x, а столбец wt_kg - на ось y.
После + продолжаются команды построения графика. Фигура создается с помощью функции ” геом” geom_point(). Этот геом наследует отображения из команды ggplot(), описанной выше, - он знает назначение осей и столбцов и визуализирует эти отношения в виде точек на холсте.
ggplot(data = linelist, mapping = aes(x = age, y = wt_kg))+
geom_point()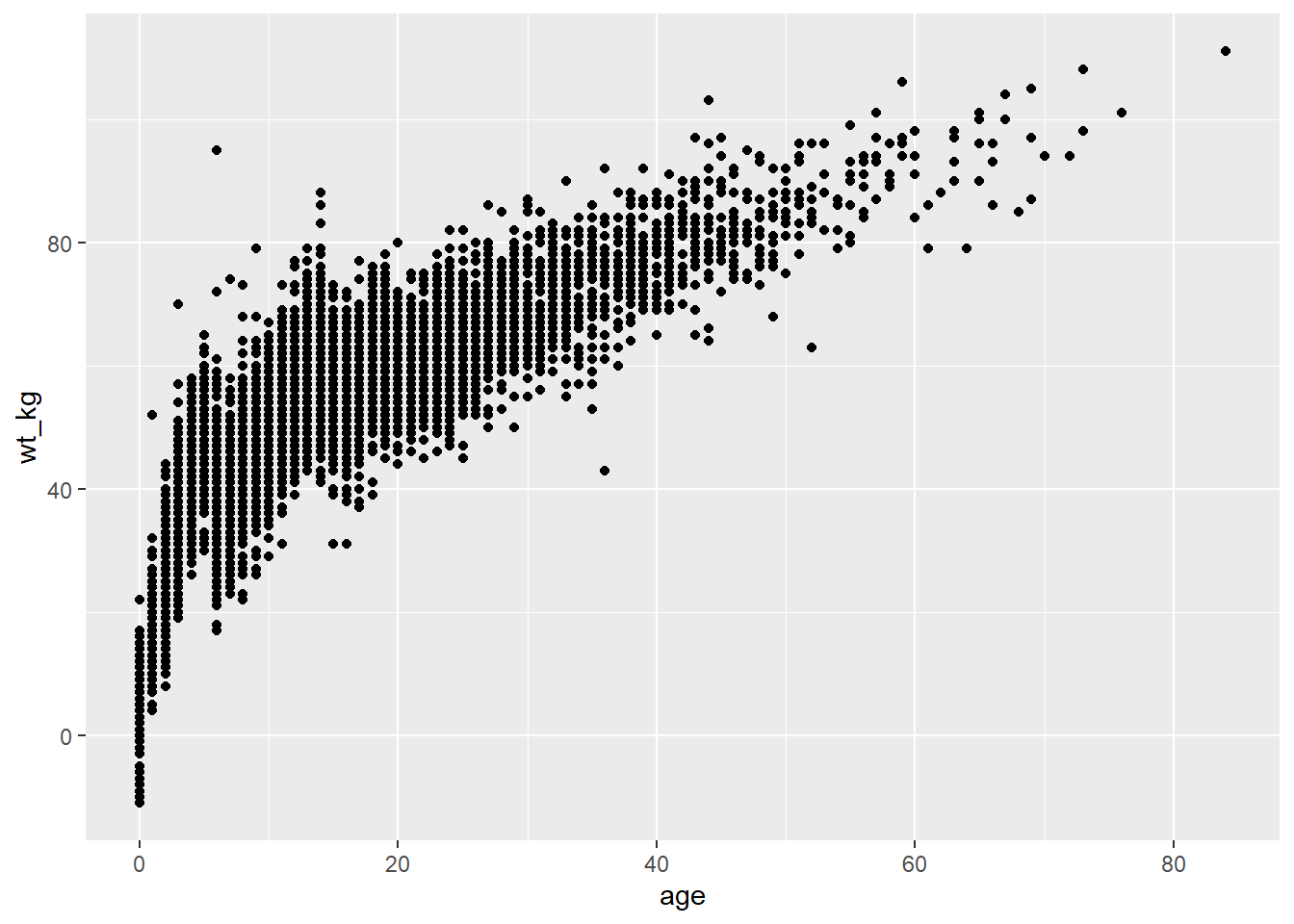
В качестве другого примера можно привести следующие команды, использующие те же данные, несколько иное отображение и другой геом. Для функции geom_histogram() требуется только столбец, сопоставленный с осью x, так как ось y генерируется автоматически.
ggplot(data = linelist, mapping = aes(x = age))+
geom_histogram()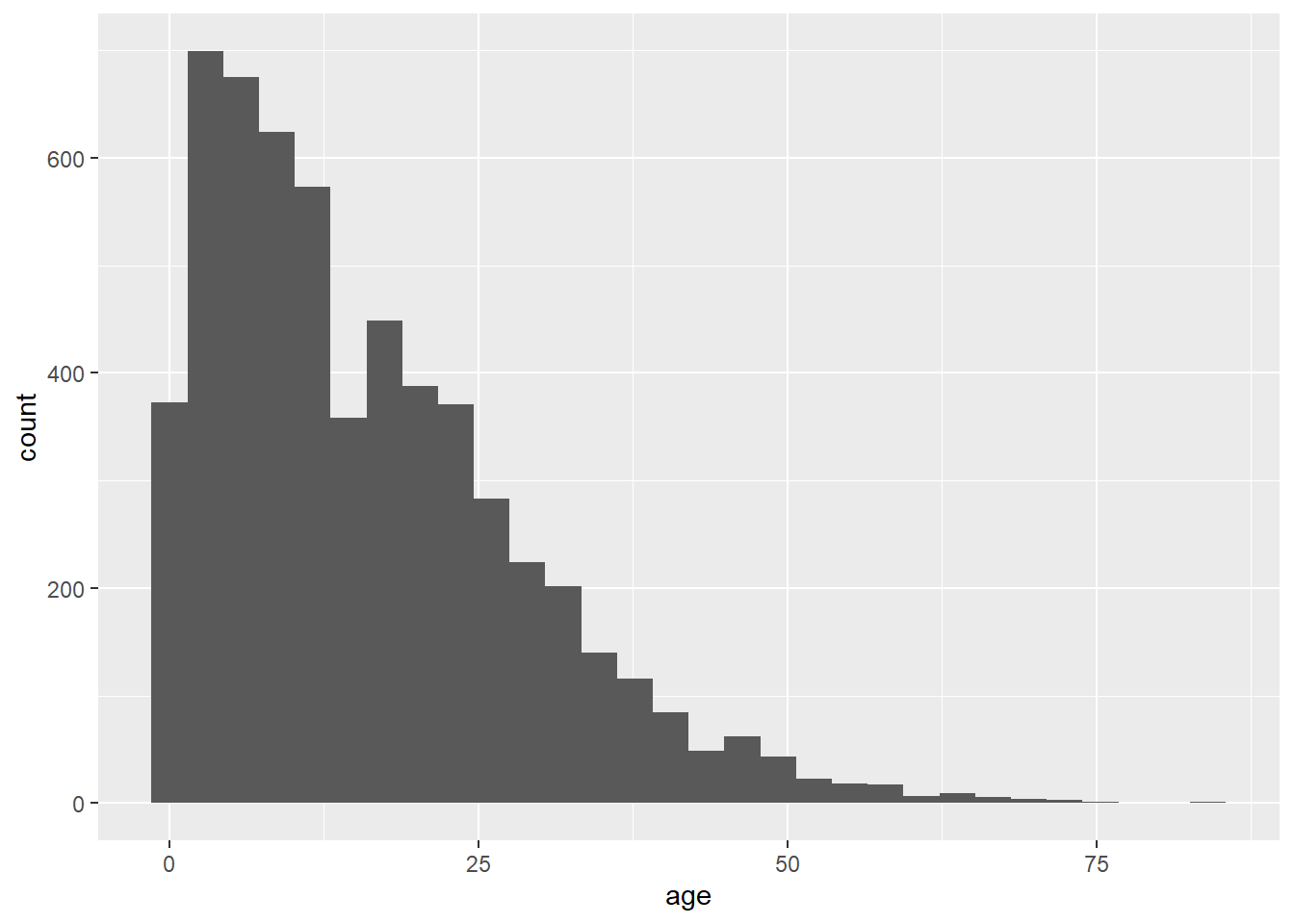
Эстетика графика
В терминологии ggplot ““эстетика”” графика имеет специфическое значение. Она относится к визуальному свойству данных графика. Заметим, что “эстетика” здесь относится к данным, отображаемым в геомах/фигурах, а не к окружающему отображению, такому как заголовки, метки осей, цвет фона, которые можно ассоциировать со словом “эстетика” в обычном понимании. В ggplot эти детали называются “темами” и настраиваются в рамках команды theme() (см. этот раздел).
Поэтому эстетикой объектов графика могут быть цвета, размеры, прозрачность, расположение и т.д. относительно данных на графике. Не все геомы будут иметь одинаковые эстетические возможности, но многие из них могут быть использованы большинством геомов. Вот некоторые примеры:
shape =Отображение точки с помощьюgeom_point()в виде точки, звезды, треугольника или квадрата…
fill =Внутренний цвет (например, столбчатой или коробчатой диаграммы)
color =Внешняя линия столбца, диаграммы и т.д., или цвет точки при использованииgeom_point().
size =Размер (например, толщина линии, размер точки)
alpha =Прозрачность (1 = непрозрачный, 0 = невидимый)
binwidth =Ширина корзин гистограммы
width =Ширина столбцов ” столбчатой диаграммы”
linetype =Тип линии (например, сплошная, пунктирная, точечная)
Этим эстетическим характеристикам объектов могут быть присвоены значения двумя способами:
- Присвоить статическое значение (например,
color = "blue"), которое будет применяться ко всем изображениям на графике
- Присваивается одному из столбцов данных (например,
color = hospital) так, что отображение каждого изображения зависит от его значения в этом столбце
Установить статистическое значение
Если вы хотите, чтобы эстетика объекта графика была статичной, т.е. одинаковой для каждого объекта, вы пишете его назначение внутри геома, но вне любого утверждения mapping = aes(). Эти привязки могут выглядеть как size = 1 или color = "blue". Приведем два примера:
- В первом примере в команде
ggplot()заданоmapping = aes(), и оси сопоставлены со столбцами возраста и веса в данных. Эстетические параметры графикаcolor =,size =иalpha =(прозрачность) присваиваются статическим значениям. Для наглядности это сделано в функцииgeom_point(), так как впоследствии можно добавить другие геомы, которые будут принимать другие значения для эстетики графика.
- Во втором примере для гистограммы требуется только ось x, отображенная на столбец. Параметры гистограммы
binwidth =,color =,fill =(внутренний цвет) иalpha =снова устанавливаются в геоме в статические значения.
# диаграмма рассеяния
ggplot(data = linelist, mapping = aes(x = age, y = wt_kg))+ # задать данные и отображение осей
geom_point(color = "darkgreen", size = 0.5, alpha = 0.2) # задать эстетику статической точки
# гистограмма
ggplot(data = linelist, mapping = aes(x = age))+ # задать данные и оси
geom_histogram( # отобразить гистограмму
binwidth = 7, # ширина корзин гистаграмм
color = "red", # цвет линии корзины
fill = "blue", # внутренний цвет корзины
alpha = 0.1) # прозрачность корзины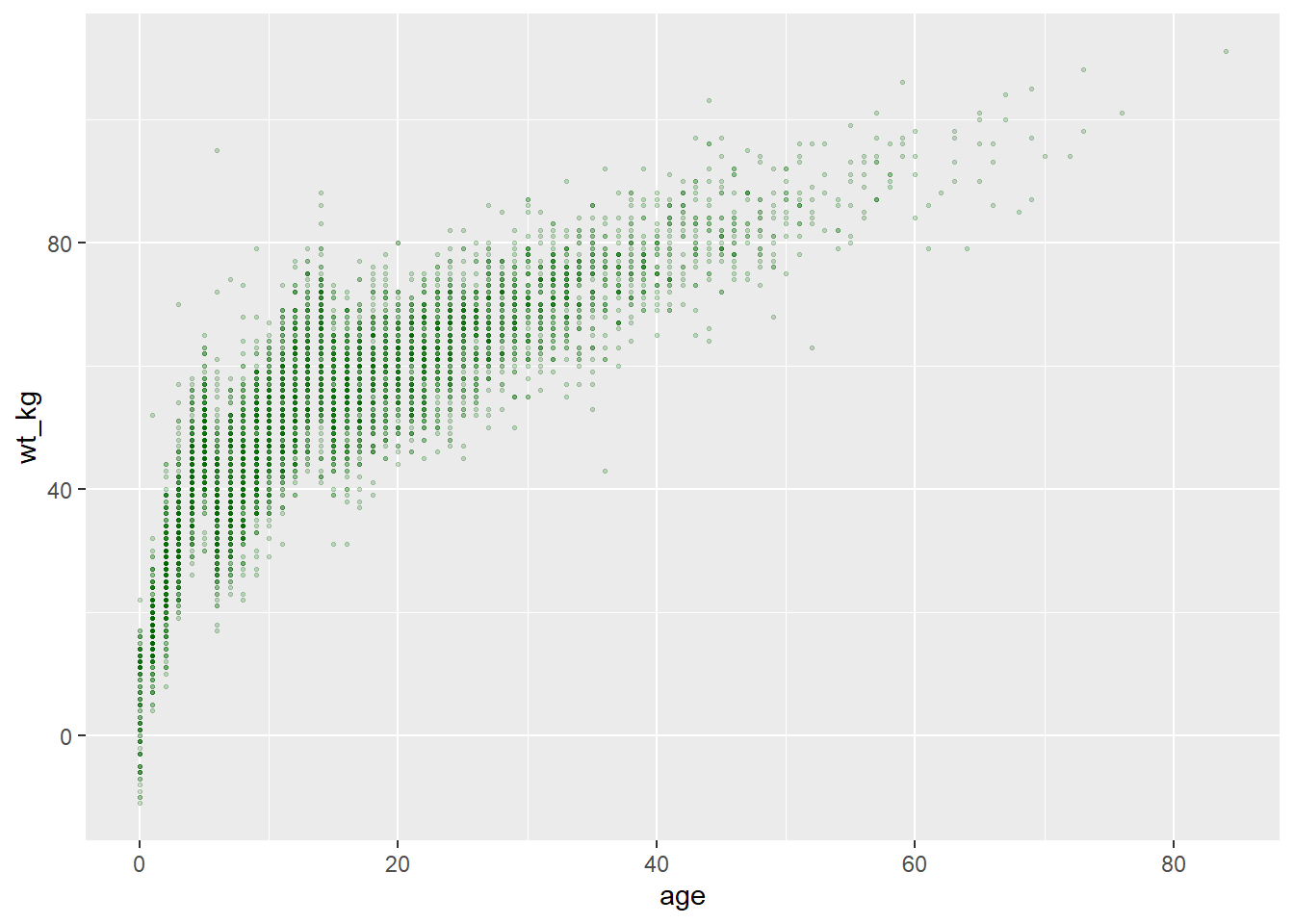

Масштабирование по значениям столбца
Альтернативным вариантом является масштабирование эстетики объекта графика по значениям в столбце. При таком подходе отображение эстетики зависит от значения в этом столбце данных. Если значения столбца непрерывны, то и шкала отображения (легенда) для этой эстетики будет непрерывной. Если значения столбца дискретны, то в легенде будет отображаться каждое значение, а данные на графике будут выглядеть как четко “сгруппированные” (подробнее об этом читайте в разделе группирование на этой странице).
Для этого необходимо сопоставить эстетику графика с названием столбца (не в кавычках). Это должно быть сделано *в функции mapping = aes() (примечание: в коде есть несколько мест, где можно задать это сопоставление, о чем говорится ниже).
Ниже приведены два примера.
- В первом примере эстетика
color =(каждой точки) сопоставлена со столбцомage- и в легенде появилась шкала! Пока просто отметим, что шкала существует - в последующих разделах мы покажем, как ее модифицировать.
- Во втором примере два новых эстетических свойства графика также сопоставлены столбцам (
color =иSize =), в то время как эстетические свойства графикаshape =иalpha =сопоставлены статическим значениям вне какой-либо функцииmapping = aes().
# диаграмма рассеяния
ggplot(data = linelist, # задать данные
mapping = aes( # сопоставление эстетических характеристик со значениями столбцов
x = age, # сопоставить ось x с осью возраста
y = wt_kg, # сопоставить ось y с весом
color = age)
)+ # сопоставить цвет с возрастом
geom_point() # отобразить данные в виде точек
# диаграмма рассеяния
ggplot(data = linelist, # задать данные
mapping = aes( # сопоставление эстетических характеристик со значениями столбцов
x = age, # сопоставить ось x с осью возраста
y = wt_kg, # сопоставить ось y с весом
color = age, # сопоставить цвет с возрастом
size = age))+ # сопоставить размер с возрастом
geom_point( # отобразить данные в виде точек
shape = "diamond", # отображение точек в виде ромбиков
alpha = 0.3) # прозрачность точек на уровне 30%

Примечание: Назначения осей всегда привязываются к столбцам данных (а не к статическим значениям), и это всегда делается в рамках mapping = aes().
При построении более сложных графиков, например, графиков с несколькими геомами, важно следить за слоями и эстетикой графиков. В приведенном ниже примере эстетика size = присваивается дважды - один раз для geom_point() и один раз для geom_smooth() - оба раза как статическое значение.
ggplot(data = linelist,
mapping = aes( # сопоставить эстетику со столбцами
x = age,
y = wt_kg,
color = age_years)
) +
geom_point( # добавить точки для каждой строки данных
size = 1,
alpha = 0.5) +
geom_smooth( # добавить линию тенденции
method = "lm", # линейным методом
size = 2) # размер (ширина строки) 2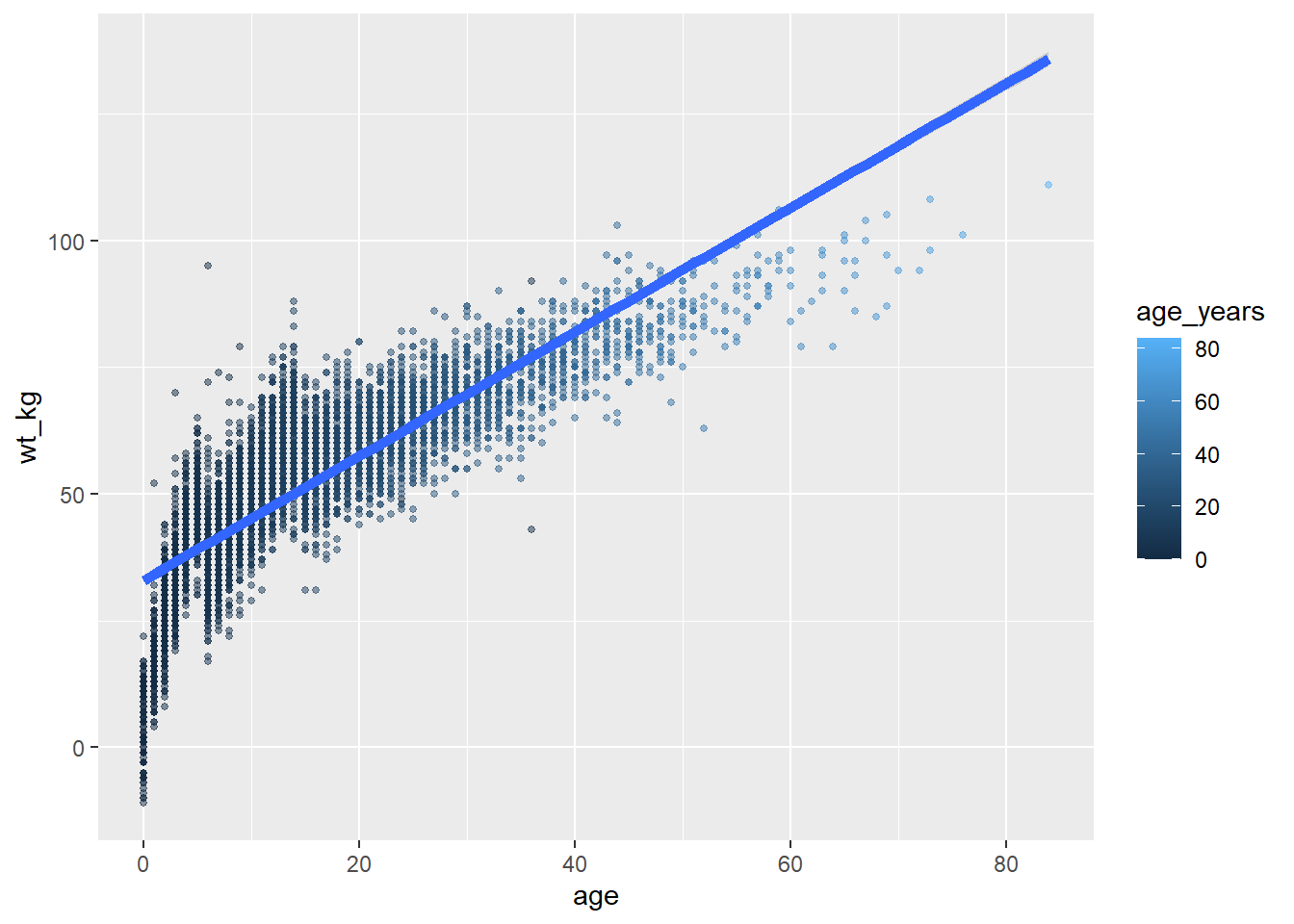
Где делать назначения по сопоставлению
Эстетическое сопоставление в рамках mapping = aes() может быть записано в нескольких местах в ваших командах построения графиков и даже может быть записано более одного раза. Его можно записать в верхней команде ggplot(), и/или для каждого отдельного геома под ним. К тонкостям относятся:
- Назначения сопоставления, сделанные в верхней команде
ggplot(), будут наследоваться по умолчанию для всех нижележащих геомов, подобно тому, как наследуются значенияx =иy =. - Назначения сопоставления, сделанные в пределах одного геома, применяются только к этому геому.
Аналогично, data =, указанные в верхней команде ggplot(), будут применяться по умолчанию ко всем нижележащим геомам, но можно также указать данные для каждого геома (но это сложнее).
Таким образом, каждая из следующих команд создаст один и тот же график:
# В результате выполнения этих команд будет получен один и тот же график
ggplot(data = linelist, mapping = aes(x = age))+
geom_histogram()
ggplot(data = linelist)+
geom_histogram(mapping = aes(x = age))
ggplot()+
geom_histogram(data = linelist, mapping = aes(x = age))Группы
Вы можете легко сгруппировать данные и построить “график по группам”. Фактически, вы уже это сделали!
Назначьте столбец “группирование” соответствующей эстетике графика в рамках mapping = aes(). Выше мы продемонстрировали это на примере непрерывных величин, когда присвоили точке size = столбец age. Однако это работает и для дискретных/категориальных столбцов.
Например, если необходимо отобразить точки по полу, то задайте mapping = aes(color = gender). При этом автоматически появляется легенда. Это назначение может быть сделано внутри команды mapping = aes() в верхней команде ggplot() (и наследоваться геомом), либо задано в отдельной команде mapping = aes() внутри геома. Оба подхода показаны ниже:
ggplot(data = linelist,
mapping = aes(x = age, y = wt_kg, color = gender))+
geom_point(alpha = 0.5)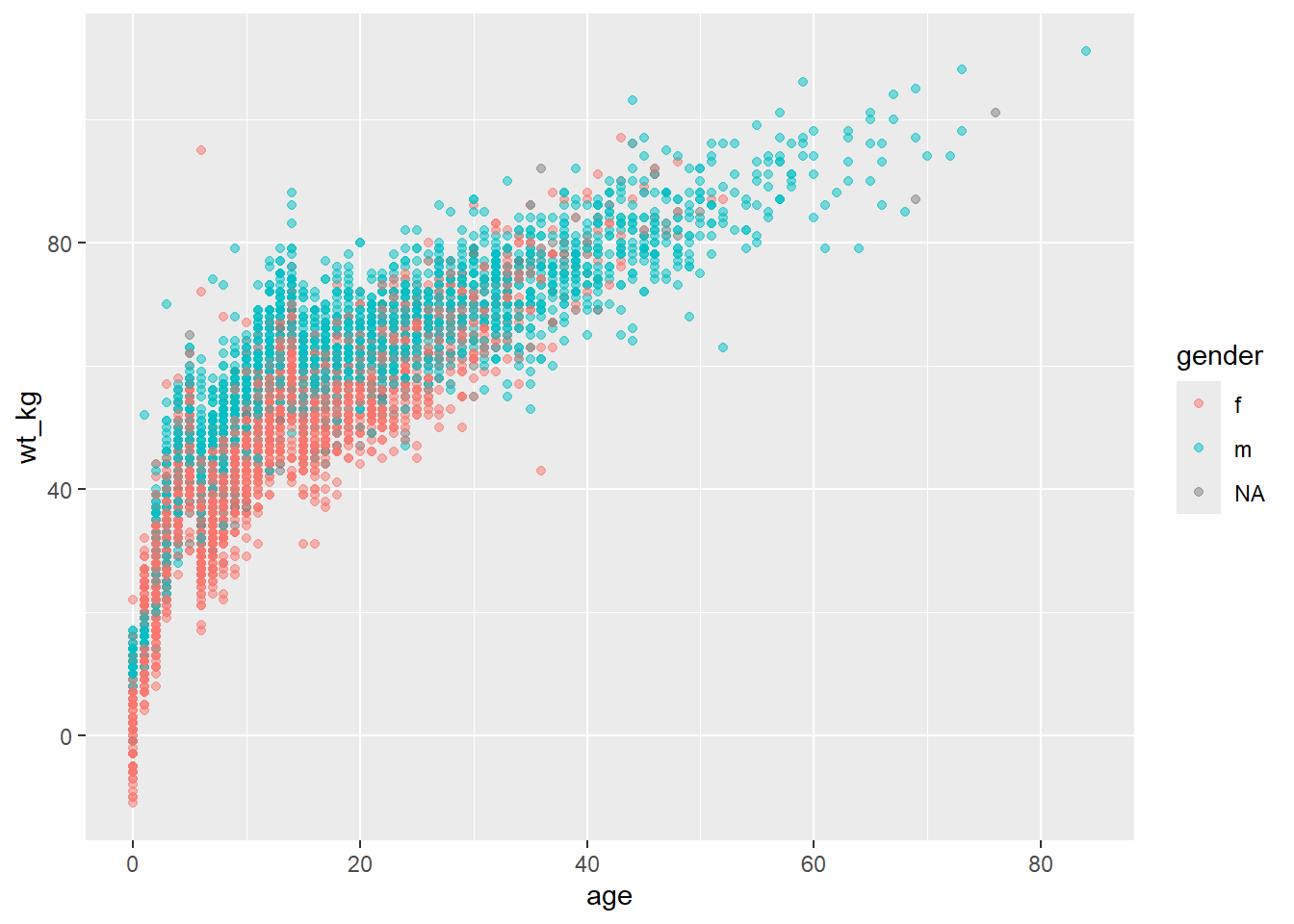
# Этот альтернативный код дает тот же самый график
ggplot(data = linelist,
mapping = aes(x = age, y = wt_kg))+
geom_point(
mapping = aes(color = gender),
alpha = 0.5)Обратите внимание, что в зависимости от геома для группировки данных необходимо использовать различные аргументы. Для geom_point() вы, скорее всего, будете использовать color =, shape = или `size =. В то время как для geom_bar(), скорее всего, будет использоваться fill =. Это зависит только от геома и от того, какой эстетикой графика вы хотите отразить группирование.
Для справки - самый простой способ группирования данных - это использование только аргумента group = в mapping = aes(). Однако это само по себе не изменит ни цвета, ни заливки, ни формы. Также не будет создана легенда. Тем не менее, данные группируются, что может повлиять на отображение статистики.
Чтобы изменить порядок групп на графике, см. страницу [советы по использованию ggplot] или страницу [Факторы]. В приведенных ниже разделах, посвященных построению непрерывных и категориальных данных, можно найти множество примеров сгруппированных графиков.
30.6 Фасеты/малые множества
Для разбиения одного графика на многопанельные фигуры используются фасеты или “малые множества”, причем на каждую группу данных приходится одна панель (“фасет”). Один и тот же вид графика создается несколько раз, каждый раз с использованием подгруппы одного и того же набора данных.
Разбиение на фасеты - это функциональность, заложенная в ggplot2, поэтому легенды и оси “панелей” фасетов автоматически выравниваются. Существуют и другие пакеты, обсуждаемые на странице [советы по использованию ggplot], которые используются для объединения совершенно разных графиков (cowplot и patchwork) в один рисунок.
Разбиение на фасеты выполняется с помощью одной из следующих функций ggplot2:
facet_wrap()Для отображения различных панелей для каждого уровня одной переменной. Примером может служить показ различных эпидемических кривых для каждой больницы в регионе. Фасеты упорядочиваются в алфавитном порядке, если только переменная не является фактором с другим порядком следования.
Вы можете использовать некоторые опции для определения расположения фасет, например,
nrow = 1илиncol = 1для управления количеством строк или столбцов, в которых располагаются графики с фасетами.facet_grid()Используется в тех случаях, когда необходимо ввести вторую переменную в схему разбиения на фасеты. Здесь каждая панель сетки показывает пересечение значений в двух столбцах. Например, эпидемические кривые для каждой комбинации больница-возрастная группа с больницами сверху (столбцы) и возрастными группами по бокам (строки).
nrowиncolне имеют значения, так как подгруппы представлены в виде сетки
Каждая из этих функций принимает синтаксис формулы, задающей столбец (столбцы) для разбиения на фасеты. Обе принимают до двух столбцов, по одному с каждой стороны тильды ~.
Для
facet_wrap()чаще всего пишется только один столбец, которому предшествует тильда~, напримерfacet_wrap(~hospital). Однако можно написать и два столбцаfacet_wrap( outcome ~ hospital)- каждая уникальная комбинация будет отображаться на отдельной панели, но они не будут расположены в виде сетки. В заголовках будут отображаться комбинированные термины, и они не будут иметь специфической логики для столбцов и строк. Если задается только одна переменная разбиения на фасеты, то точка.используется в качестве заполнителя на другой стороне формулы - см. примеры кода.Для
facet_grid()можно также указать в формуле одну или две строки (сеткаrows ~ columns). Если требуется указать только один столбец, можно поставить точку.по другую сторону тильды, например,facet_grid(. ~ hospital)илиfacet_grid(hospital ~ .).
В фасетах может быстро оказаться слишком много информации, поэтому следует убедиться, что у вас не слишком много уровней каждой переменной, по которой вы решили построить фасет. Приведем несколько быстрых примеров с набором данных по малярии (см. [Скачивание руководства и данных]), который состоит из ежедневных подсчетов случаев заболевания малярией в учреждениях с разбивкой по возрастным группам.
Ниже мы импортируем данные и сделаем несколько быстрых модификаций для простоты:
# Эти данные представляют собой ежедневные подсчеты случаев заболевания малярией с разбивкой по дням пребывания в учреждении.
malaria_data <- import(here("data", "malaria_facility_count_data.rds")) %>% # импорт
select(-submitted_date, -Province, -newid) # удалить ненужные столбцыНиже приведены первые 50 строк данных по малярии. Обратите внимание на наличие столбца malaria_tot, а также столбцов для подсчетов по возрастным группам (они будут использованы во втором примере facet_grid()).
facet_wrap()
Пока остановимся на столбцах malaria_tot и District. Столбцы с возрастными показателями пока проигнорируем. Мы построим эпидемические кривые с помощью функции geom_col(), которая создает столбец для каждого дня на заданной высоте оси y, указанной в столбце malaria_tot (данные уже являются ежедневными подсчетами, поэтому мы используем geom_col() - см. раздел ” Столбчатая диаграмма” ниже).
При добавлении команды facet_wrap() мы указываем тильду, а затем столбец для создания фасет (в данном случае District). Вы можете поместить еще один столбец слева от тильды - это создаст по одному фасету для каждой комбинации, - но мы рекомендуем вместо этого использовать команду facet_grid(). В данном случае для каждого уникального значения District создается один фасет.
# График с фасетами по районам
ggplot(malaria_data, aes(x = data_date, y = malaria_tot)) +
geom_col(width = 1, fill = "darkred") + # построить график данных подсчета в виде столбцов
theme_minimal()+ # упростить фоновые панели
labs( # добавить метки графика, заголовок и т.д.
x = "Date of report",
y = "Malaria cases",
title = "Malaria cases by district") +
facet_wrap(~District) # создаются фасеты
facet_grid()
Для пересечения двух переменных мы можем использовать подход facet_grid(). Допустим, мы хотим пересечь District и возраст. Тогда нам необходимо выполнить некоторые преобразования данных в столбцах возраста, чтобы привести эти данные к предпочтительному для ggplot “длинному” формату. У возрастных групп есть свои собственные столбцы - мы хотим, чтобы они были в одном столбце age_group и в другом num_cases. Подробнее об этом см. на странице [Поворот данных].
malaria_age <- malaria_data %>%
select(-malaria_tot) %>%
pivot_longer(
cols = c(starts_with("malaria_rdt_")), # выбрать столбцы для поворота в длину
names_to = "age_group", # названия столбцов становятся возрастными группами
values_to = "num_cases" # значения в один столбец (num_cases)
) %>%
mutate(
age_group = str_replace(age_group, "malaria_rdt_", ""),
age_group = forcats::fct_relevel(age_group, "5-14", after = 1))Теперь первые 50 строк данных выглядят следующим образом:
При передаче двух переменных в facet_grid() проще всего использовать формулу(например, x ~ y), где x - это строки, а y - столбцы. Вот график, использующий facet_grid() для отображения графиков для каждой комбинации столбцов age_group и District.
ggplot(malaria_age, aes(x = data_date, y = num_cases)) +
geom_col(fill = "darkred", width = 1) +
theme_minimal()+
labs(
x = "Date of report",
y = "Malaria cases",
title = "Malaria cases by district and age group"
) +
facet_grid(District ~ age_group)
Свободные или фиксированные оси
Масштабы осей, отображаемые при делении на фасеты, по умолчанию одинаковы (фиксированы) для всех фасет. Это полезно для перекрестного сравнения, но не всегда уместно.
При использовании facet_wrap() или facet_grid() можно добавить scales = "free_y", чтобы “освободить” или отпустить оси y панелей для масштабирования в соответствии с их подмножеством данных. Это особенно полезно, если фактические значения для одной из подкатегорий невелики и тенденции трудно заметить. Вместо “free_y” можно также написать “free_x”, чтобы сделать то же самое для оси x (например, для дат), или “free” для обеих осей. Обратите внимание на то, что в facet_grid масштабы y будут одинаковыми для фасет в одной строке, а масштабы x - для фасет в одном столбце.
При использовании только facet_grid можно добавить space = "free_y" или space = "free_x", чтобы фактическая высота или ширина фасета взвешивалась по отношению к значениям фигур внутри нее. Это работает только в том случае, если уже применено scales = "free" (y или x).
# Свободная ось y
ggplot(malaria_data, aes(x = data_date, y = malaria_tot)) +
geom_col(width = 1, fill = "darkred") + # построить график данных подсчета в виде столбцов
theme_minimal()+ # упростить фоновые панели
labs( # добавить метки графика, заголовок и т.д.
x = "Date of report",
y = "Malaria cases",
title = "Malaria cases by district - 'free' x and y axes") +
facet_wrap(~District, scales = "free") # создаются фасеты
Порядок уровней факторов в фасетах
О том, как переупорядочить уровни факторов внутри фасетов, см. этот пост.
30.7 Хранение графиков
Сохранение графиков
По умолчанию при выполнении команды ggplot() график выводится на панель Plots RStudio. Однако можно сохранить график как объект, используя оператор присваивания <- и задав ему название. Тогда он не будет печататься, пока не будет запущено само название объекта. Можно также вывести его на печать, обернув название графика в print(), но это необходимо только в некоторых случаях, например, если график создается внутри цикла, используемого для печати нескольких графиков одновременно (см. страницу [Итерации, циклы и списки]).
# определить график
age_by_wt <- ggplot(data = linelist, mapping = aes(x = age_years, y = wt_kg, color = age_years))+
geom_point(alpha = 0.1)
# печать
age_by_wt 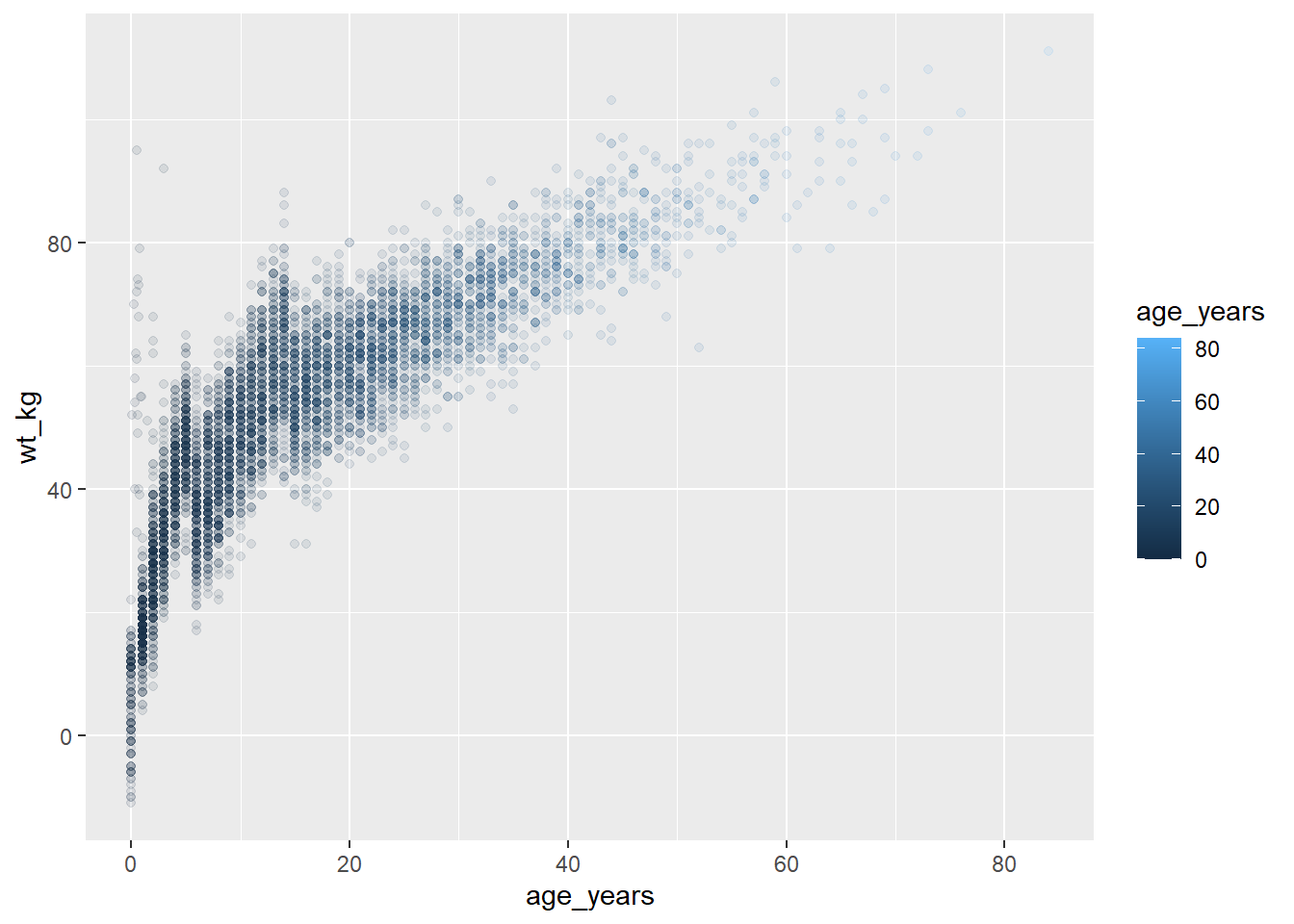
Изменение сохраненных графиков
Удобство работы с ggplot2 заключается в том, что вы можете определить график (как описано выше), а затем добавить к нему слои, начиная с его названия. При этом не нужно повторять все команды, создавшие исходный график!
Например, чтобы изменить график age_by_wt, который был определен выше, и включить в него вертикальную линию в возрасте 50 лет, достаточно добавить + и начать добавлять дополнительные слои к графику.
age_by_wt+
geom_vline(xintercept = 50)
Экспорт графиков
Экспорт ggplots упрощается с помощью функции ggsave() из ggplot2. Она может работать двумя способами:
- Укажите имя объекта графика, затем путь к файлу и его название с расширением
- Например:
ggsave(my_plot, here("plots", "my_plot.png")).
- Например:
- Выполните команду, указав только путь к файлу, чтобы сохранить последний распечатанный график
- Например:
ggsave(here("plots", "my_plot.png"))
- Например:
Можно экспортировать в png, pdf, jpeg, tiff, bmp, svg или в несколько других типах файлов, указав расширение файла в пути к нему.
Также можно указать аргументы width =, height = и units = (либо ” дюйм”, либо “см”, либо “мм”). Также можно указать dpi = с числом для разрешения графика (например, 300). Подробнее о функции можно узнать, введя ?ggsave или прочитав документацию онлайн.
Помните, что для указания нужного пути к файлу можно использовать синтаксис here(). Более подробную информацию см. на странице [Импорт и экспорт].
30.8 Метки
Наверняка вы захотите добавить или скорректировать метки графика. Это проще всего сделать в функции labs(), которая добавляется к графику с помощью + так же, как и геомы.
В функции labs() можно указать последовательность символов для этих аргументов:
x =иy =Заголовок (метки) оси x и оси y
title =Основной заголовок графика
subtitle =Подзаголовок графика, более мелким шрифтом под заголовком
caption =Подпись к графику, по умолчанию в правом нижнем углу
Вот график, который мы сделали ранее, но с более красивыми метками:
age_by_wt <- ggplot(
data = linelist, # задать данные
mapping = aes( # сопоставить эстетические характеристики со значениями столбцов
x = age, # сопоставить ось x с возрастом
y = wt_kg, # сопоставить ось y с весом
color = age))+ # сопоставить цвет с возрастом
geom_point()+ # отобразить данные в виде точек
labs(
title = "Age and weight distribution",
subtitle = "Fictional Ebola outbreak, 2014",
x = "Age in years",
y = "Weight in kilos",
color = "Age",
caption = stringr::str_glue("Data as of {max(linelist$date_hospitalisation, na.rm=T)}"))
age_by_wt
Обратите внимание на то, как в задании по созданию подписи мы использовали str_glue() из пакета stringr для встраивания динамического кода R в текст строки. В подписи будет отображаться дата “Данные по состоянию на:”, которая отражает максимальную дату госпитализации в построчном списке. Подробнее об этом читайте на странице [текст и последовательности].
Относительно указания названия легенды: Не существует единого аргумента “название легенды”, поскольку в легенде может быть несколько шкал. Внутри labs() можно написать аргумент для эстетики графика, используемой для создания легенды, и таким образом указать название. Например, выше мы назначили color = age для создания легенды. Следовательно, мы указываем color = to labs() и присваиваем легенде желаемый заголовок (“Возраст” с большой буквы). Если вы создаете легенду с помощью aes(fill = COLUMN), то в labs() вы напишете fill =, чтобы настроить заголовок этой легенды. Раздел о цветовых шкалах на странице [советы по использованию ggplot] содержит более подробную информацию о редактировании легенд, а также альтернативный подход с использованием функций scales_().
30.9 Темы
Одним из преимуществ ggplot2 является возможность контроля над графиком - вы можете определить все, что угодно! Как уже говорилось выше, дизайн графика, который не связан с формами/геометриями данных, настраивается в рамках функции theme(). Например, цвет фона графика, наличие/отсутствие линий сетки, шрифт/размер/цвет/выравнивание текста (заголовки, подзаголовки, подписи, текст осей…). Эти настройки могут быть выполнены одним из двух способов:
- Добавить настройку полная тема
theme_()для выполнения комплексных изменений - например,theme_classic(),theme_minimal(),theme_dark(),theme_light(),theme_grey(),theme_bw()и др.
- Настроить каждый мельчайший аспект графика индивидуально в рамках
theme()
Полные темы
Поскольку они достаточно просты, мы продемонстрируем функции полной темы ниже и не будем описывать их здесь. Обратите внимание, что любые микрокорректировки с помощью theme() должны производиться после использования полной темы.
Записывайте их с пустыми круглыми скобками.
ggplot(data = linelist, mapping = aes(x = age, y = wt_kg))+
geom_point(color = "darkgreen", size = 0.5, alpha = 0.2)+
labs(title = "Theme classic")+
theme_classic()
ggplot(data = linelist, mapping = aes(x = age, y = wt_kg))+
geom_point(color = "darkgreen", size = 0.5, alpha = 0.2)+
labs(title = "Theme bw")+
theme_bw()
ggplot(data = linelist, mapping = aes(x = age, y = wt_kg))+
geom_point(color = "darkgreen", size = 0.5, alpha = 0.2)+
labs(title = "Theme minimal")+
theme_minimal()
ggplot(data = linelist, mapping = aes(x = age, y = wt_kg))+
geom_point(color = "darkgreen", size = 0.5, alpha = 0.2)+
labs(title = "Theme gray")+
theme_gray()

Изменение темы
Функция theme() может принимать большое количество аргументов, каждый из которых изменяет очень специфический аспект графика. Мы не сможем рассказать обо всех аргументах, но опишем их общий вид и покажем, как найти название нужного аргумента. Основной синтаксис выглядит следующим образом:
- Внутри
theme()запишите название аргумента для редактируемого элемента графика, например,plot.title =.
- Присвойте аргументу функцию
element_().- Чаще всего используется
element_text(), но можно использовать и другие функции, напримерelement_rect()для цвета фона полотна илиelement_blank()для удаления элементов графика
- Чаще всего используется
- Внутри функции
element_()напишите назначения аргументов, чтобы выполнить желаемые настройки
Итак, это описание было достаточно абстрактным, поэтому приведем несколько примеров.
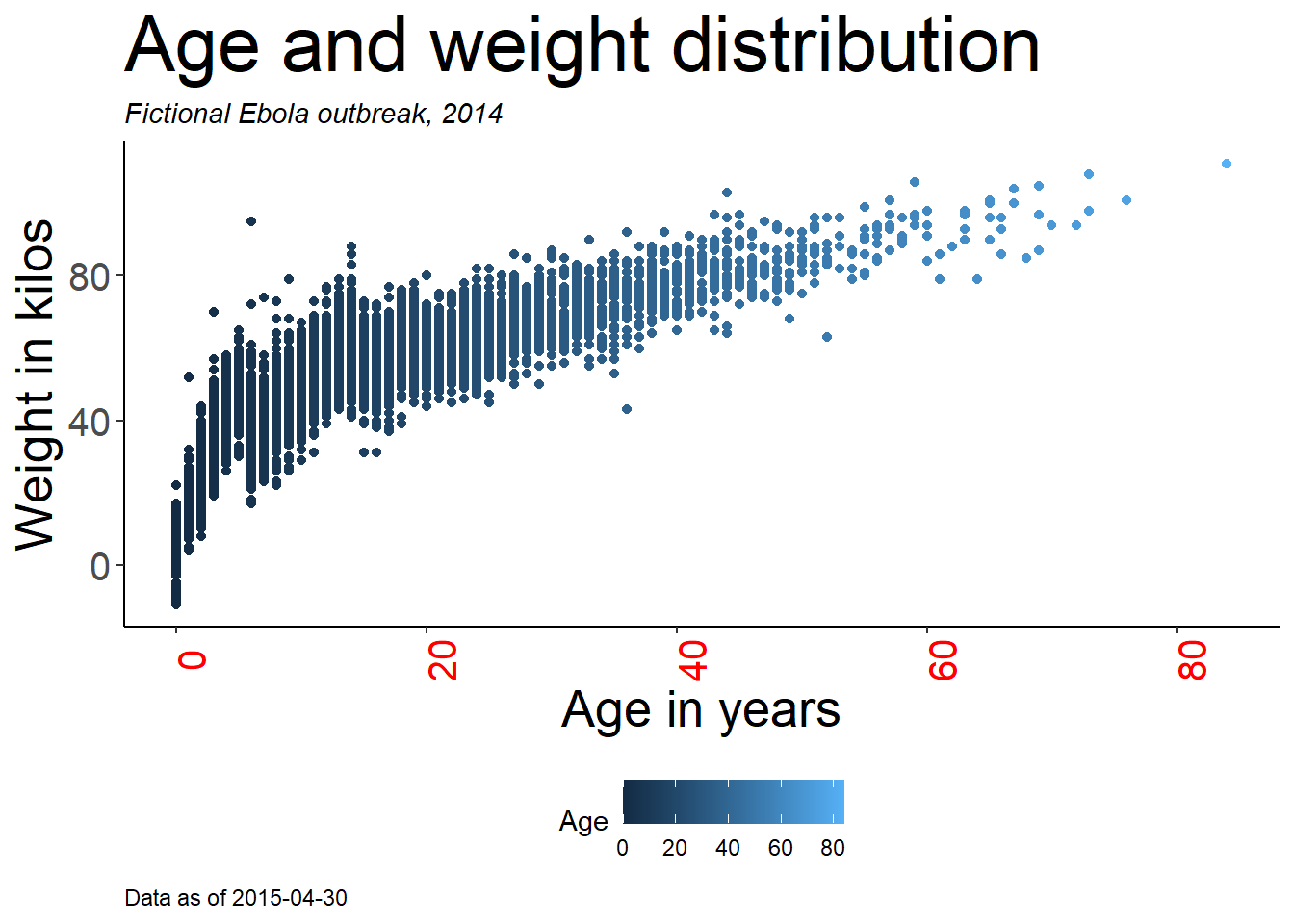
Приведенный ниже график выглядит довольно глупо, но он служит для того, чтобы показать разнообразие способов настройки графика.
- Мы начинаем с графика
age_by_wt, определенного чуть выше, и добавляемtheme_classic().
- Для более детальной настройки мы добавляем
theme()и включаем по одному аргументу для каждого элемента графика, который необходимо настроить.
Не лишним будет организовать аргументы в логические секции. Ниже описаны лишь некоторые из них:
legend.position =уникален тем, что принимает такие простые значения, как ““низ”“,”верх”“,”лево”” и “право”“. Но обычно аргументы, связанные с текстом, требуют размещения деталей в пределахelement_text().
- Размер заголовка меняется с помощью
element_text(size = 30)
- Выравнивание заголовка по горизонтали - с помощью
element_text(hjust = 0)(справа налево)
- Подзаголовок выделяется курсивом с помощью
element_text(face = "italic")
age_by_wt +
theme_classic()+ # предварительно заданные настройки темы
theme(
legend.position = "bottom", # перенести легенду в нижнюю часть
plot.title = element_text(size = 30), # размер заголовка до 30
plot.caption = element_text(hjust = 0), # надпись с выравниванием по левому краю
plot.subtitle = element_text(face = "italic"), # выделение подзаголовка курсивом
axis.text.x = element_text(color = "red", size = 15, angle = 90), # корректирует только текст по оси x
axis.text.y = element_text(size = 15), # корректирует только текст по оси y
axis.title = element_text(size = 20) # корректирует заголовки обеих осей
) 
Вот некоторые особенно часто встречающиеся аргументы theme(). Вы узнаете некоторые закономерности, например, добавление .x или .y для применения изменения только к одной оси.
аргумент theme() |
Что он корректирует |
|---|---|
plot.title = element_text() |
Заголовок |
plot.subtitle = element_text() |
Подзаголовок |
plot.caption = element_text() |
Подпись (обводка, цвет, размер, угол, vjust, hjust…) |
axis.title = element_text() |
Заголовки осей (как x, так и y) ( размер, обводка, угол, цвет…) |
axis.title.x = element_text() |
Заголовок оси только по оси x ( используйте .y только для оси y) |
axis.text = element_text() |
Текст оси (как по оси x, так и по оси y) |
axis.text.x = element_text() |
Текст оси только по оси x (используйте .y только для оси y) |
axis.ticks = element_blank() |
Удаление отметок оси |
axis.line = element_line() |
Линии оси (цвет, размер, тип линии: сплошная пунктирная и т.д.) |
strip.text = element_text() |
Текст полосы фасета (цвет, обводка, размер, угол наклона…) |
strip.background = element_rect() |
Полоса фасета (заливка, цвет, размер…) |
Но ведь аргументов тем так много! Как же их запомнить? Не волнуйтесь - запомнить их все невозможно. К счастью, есть ряд инструментов, которые вам помогут:
Существует документация tidyverse по вопросу изменение темы, в которой приведен полный список.
СОВЕТ: Запустите theme_get() из ggplot2, чтобы вывести на консоль список всех 90+ аргументов theme().
СОВЕТ: При необходимости удалить элемент графика это можно сделать и через theme(). Достаточно передать в качестве аргумента element_blank(), чтобы он полностью исчез. Для легенд задайте legend.position = "none"..
30.10 Цвета
Посмотрите этот раздел о цветовых шкалах страницы советы по использованию ggplot.
30.11 Привязывание к ggplot2
При использовании каналов для вычистки и преобразования данных можно легко передать преобразованные данные в функцию ggplot().
Каналы, передающие набор данных от функции к функции, перейдут в + после вызова функции ggplot(). Обратите внимание на то, что в этом случае нет необходимости указывать аргумент data =, так как он автоматически определяется как передаваемый по каналу набор данных.
Вот как это может выглядеть:
linelist %>% # начать с построчного списка
select(c(case_id, fever, chills, cough, aches, vomit)) %>% # выбрать столбцы
pivot_longer( # повернуть в длину
cols = -case_id,
names_to = "symptom_name",
values_to = "symptom_is_present") %>%
mutate( # заменить отсутствующие значения
symptom_is_present = replace_na(symptom_is_present, "unknown")) %>%
ggplot( # начать ggplot!
mapping = aes(x = symptom_name, fill = symptom_is_present))+
geom_bar(position = "fill", col = "black") +
theme_classic() +
labs(
x = "Symptom",
y = "Symptom status (proportion)"
)
30.12 Построение графика непрерывных данных
На этой странице вы уже видели множество примеров построения графиков непрерывных данных. Здесь мы кратко обобщим их и представим несколько вариантов.
Здесь рассматриваются такие виды визуализации, как:
- Графики для одной непрерывной переменной:
- Гистограмма - классический график для представления распределения непрерывной переменной.
- Коробчатая диаграмма (также называемая “ящиком с усами”) позволяет показать 25-й, 50-й и 75-й процентили, хвостовые части распределения и выбивающиеся значения (важные ограничения).
- График с функцией дрожания - отображение всех значений в виде точек, которые “дрожат”, так что все они (в основном) видны, даже если два из них имеют одинаковое значение.
- Скрипичный график, показывает распределение непрерывной переменной на основе симметричной ширины “скрипки”.
- График Sinaplot - комбинация графиков с функцией джиттера и скрипичного графика, где отдельные точки отображаются, но в симметричной форме распределения (с помощью пакета ggforce).
- График рассеяния для двух непрерывных переменных.
- Тепловые графики для трех непрерывных переменных (ссылка на страницу [Тепловые графики])
Гистограммы
Гистограммы похожи на столбчатые диаграммы, но отличаются от них тем, что измеряют распределение непрерывной переменной. Пробелы между “столбиками” отсутствуют, и в geom_histogram() передается только один столбец.
Ниже приведен код для создания гистограмм, которые группируют непрерывные данные по диапазонам и отображают в виде смежных столбиков разной высоты. Для этого используется функция geom_histogram(). Разницу между geom_histogram(), geom_bar() и geom_col() см. в разделе ” Столбчатые диаграммы” на странице Основы ggplot.
Мы покажем распределение возрастов случаев. В mapping = aes() укажите, по какому столбцу вы хотите видеть распределение. Этот столбец можно отнести как к оси x, так и к оси y.
Строки будут распределены по “корзинам” в зависимости от их числового возраста, и эти корзины будут графически представлены в виде столбцов. Если задать число корзин с помощью параметра bins =, то точки разрыва будут равномерно распределены между минимальными и максимальными значениями гистограммы. Если bins = не задано, то будет предложено соответствующее количество корзин, и после построения графика будет выведено соответствующее сообщение:
## `stat_bin()`, используя `bins = 30`. Подберите лучшее значение с помощью `binwidth`.Если вы не хотите указывать число корзин в bins =, то в качестве альтернативы можно указать binwidth = в единицах измерения оси. Приведем несколько примеров, демонстрирующих различные корзины и ширину корзин:
# A) Обычная гистограмма
ggplot(data = linelist, aes(x = age))+ # предоставить переменную x
geom_histogram()+
labs(title = "A) Default histogram (30 bins)")
# B) Больше корзин
ggplot(data = linelist, aes(x = age))+ # предоставить переменную x
geom_histogram(bins = 50)+
labs(title = "B) Set to 50 bins")
# C) Меньше корзин
ggplot(data = linelist, aes(x = age))+ # предоставить переменную x
geom_histogram(bins = 5)+
labs(title = "C) Set to 5 bins")
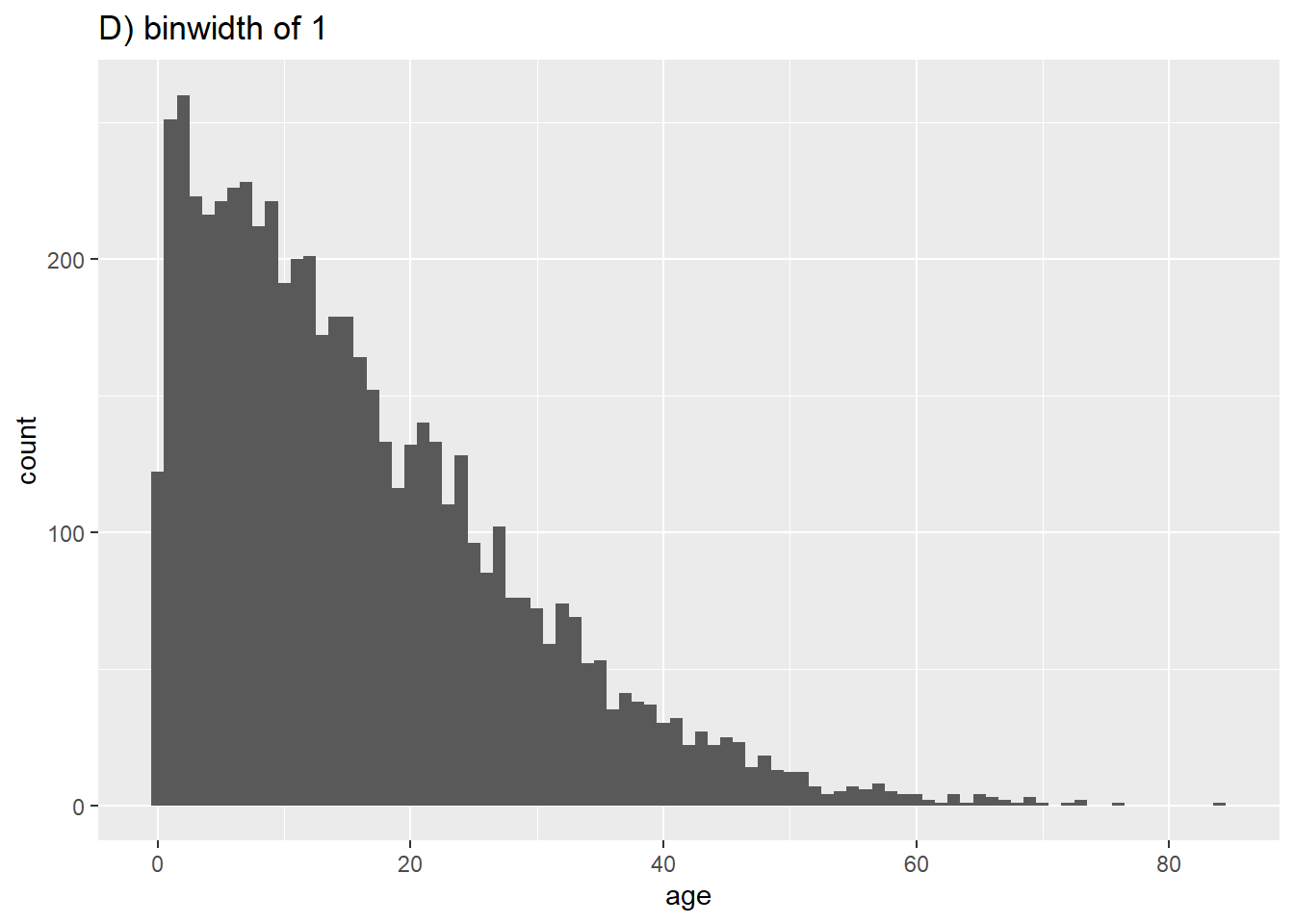
# D) Больше корзин
ggplot(data = linelist, aes(x = age))+ # предоставить переменную x
geom_histogram(binwidth = 1)+
labs(title = "D) binwidth of 1")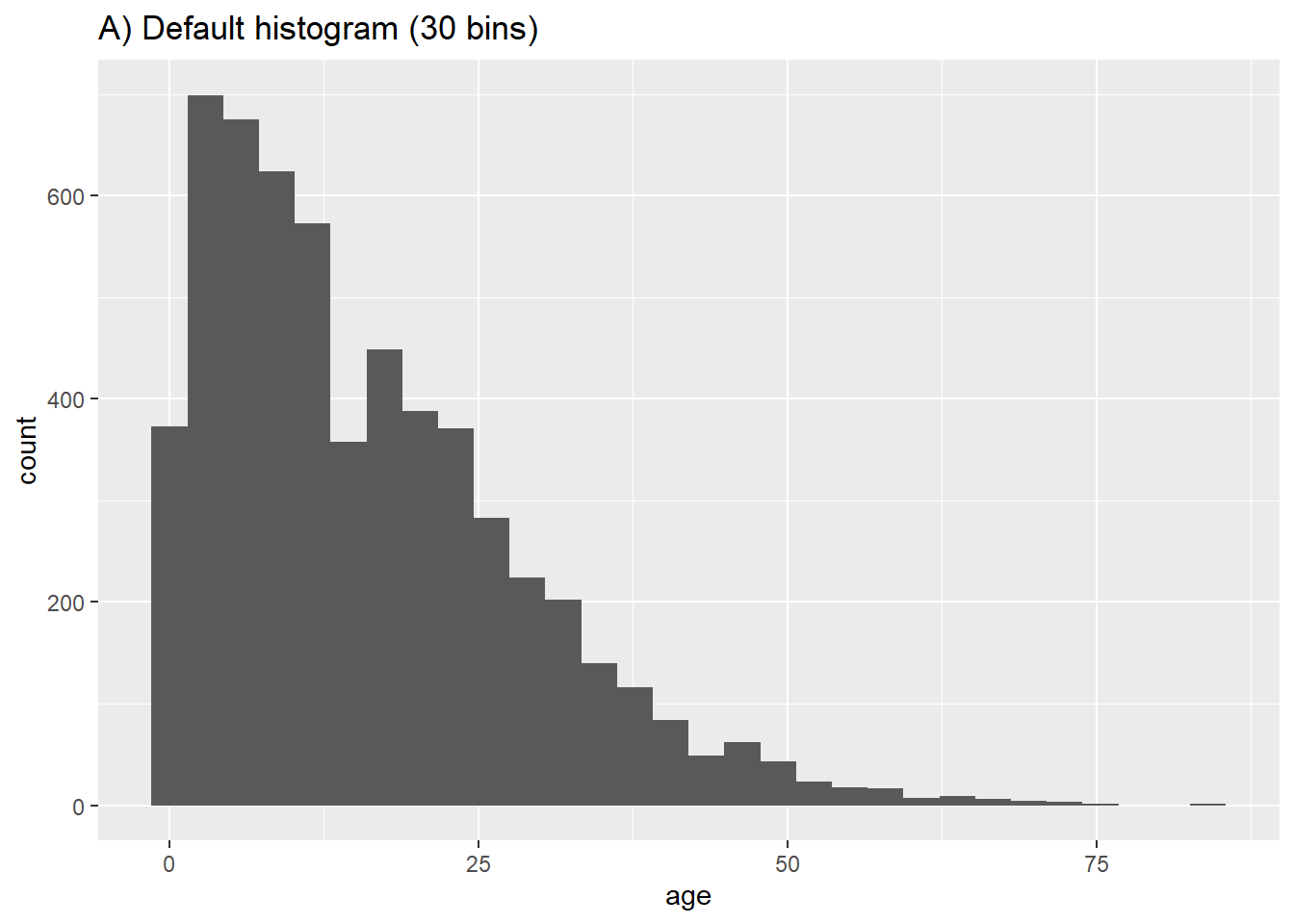


Для получения сглаженных пропорций можно использовать geom_density():
# Частота с осью пропорций, сглаженных
ggplot(data = linelist, mapping = aes(x = age)) +
geom_density(size = 2, alpha = 0.2)+
labs(title = "Proportional density")
# Сложенные частоты с осью пропорций, сглаженных
ggplot(data = linelist, mapping = aes(x = age, fill = gender)) +
geom_density(size = 2, alpha = 0.2, position = "stack")+
labs(title = "'Stacked' proportional densities")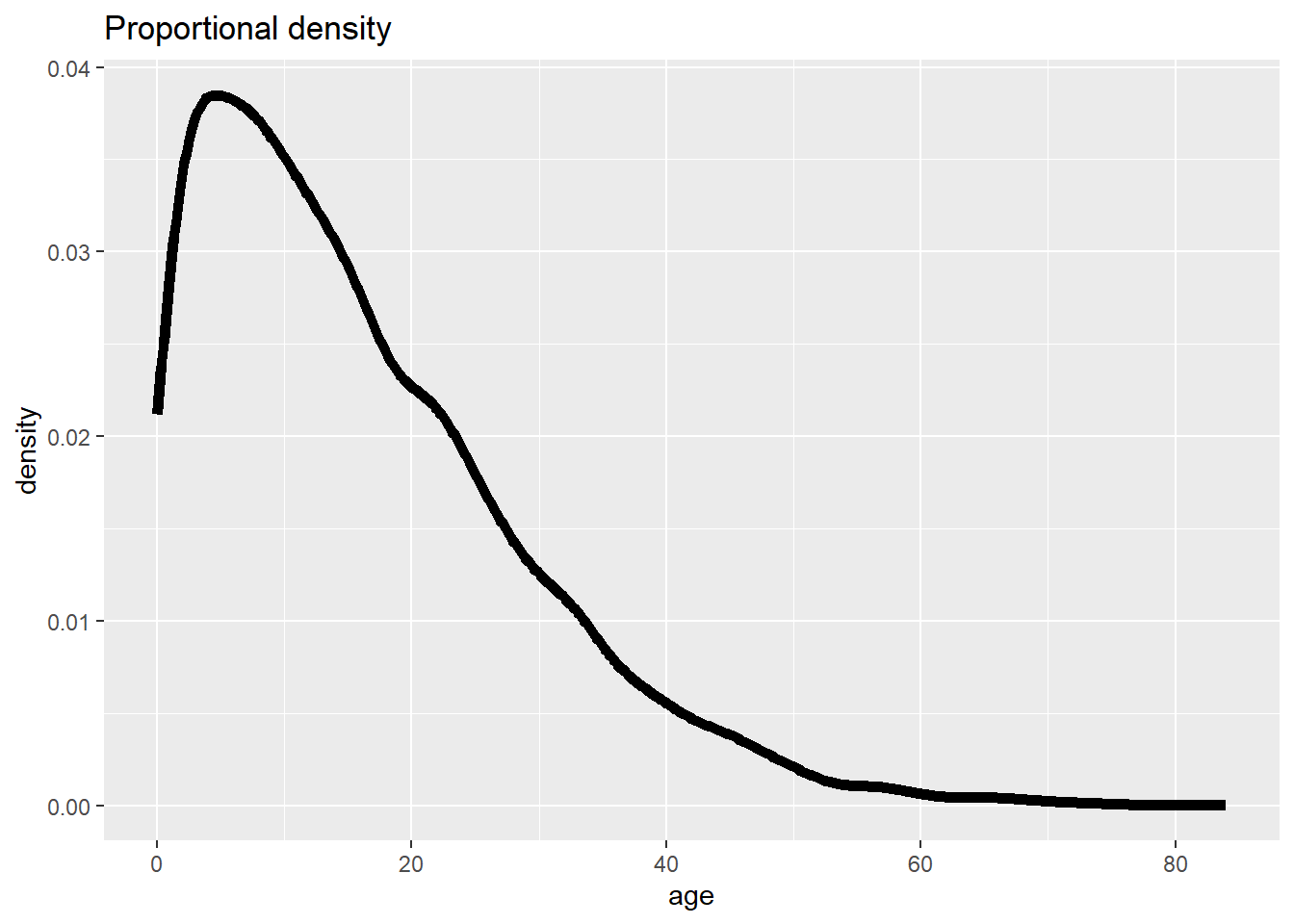

Чтобы получить гистограмму “с накоплением” (непрерывного столбца данных), можно выполнить одно из следующих действий:
- Использовать
geom_histogram()с аргументомfill =внутриaes()и назначением столбца группировки, или
- Использовать функцию
geom_freqpoly(), которая, скорее всего, будет более удобной для чтения (при этом можно задатьbinwidth =)
- Чтобы увидеть пропорции всех значений, задайте
y = after_stat(density)(используйте именно этот синтаксис - он не изменен для ваших данных). Примечание: эти пропорции будут показаны для каждой группы.
Ниже показан каждый вариант (*обратите внимание на использование color = по сравнению с fill = в каждом случае):
# Гистограмма с накоплением
ggplot(data = linelist, mapping = aes(x = age, fill = gender)) +
geom_histogram(binwidth = 2)+
labs(title = "'Stacked' histogram")
# Частота
ggplot(data = linelist, mapping = aes(x = age, color = gender)) +
geom_freqpoly(binwidth = 2, size = 2)+
labs(title = "Freqpoly")
# Частота с осью пропорций
ggplot(data = linelist, mapping = aes(x = age, y = after_stat(density), color = gender)) +
geom_freqpoly(binwidth = 5, size = 2)+
labs(title = "Proportional freqpoly")
# Частота с осью пропорций, сглаженных
ggplot(data = linelist, mapping = aes(x = age, y = after_stat(density), fill = gender)) +
geom_density(size = 2, alpha = 0.2)+
labs(title = "Proportional, smoothed with geom_density()")



Если вы хотите немного развлечься, попробуйте geom_density_ridges из пакета ggridges (виньетка здесь.
Более подробно о гистограммах можно прочитать на tidyverse страница geom_histogram().
Коробчатые диаграммы
Коробчатые диаграммы широко распространены, но имеют существенные ограничения. Они могут скрывать реальное распределение - например, бимодальное распределение. Подробнее об этом см. здесь галерея R graph и здесь статья “От данных к визуализации”. Однако они хорошо отображают интерквартильный диапазон и выпадающие значения, поэтому их можно накладывать поверх других типов графиков, которые показывают распределение более подробно.
Ниже мы напомним вам о различных компонентах коробочной диаграммы:
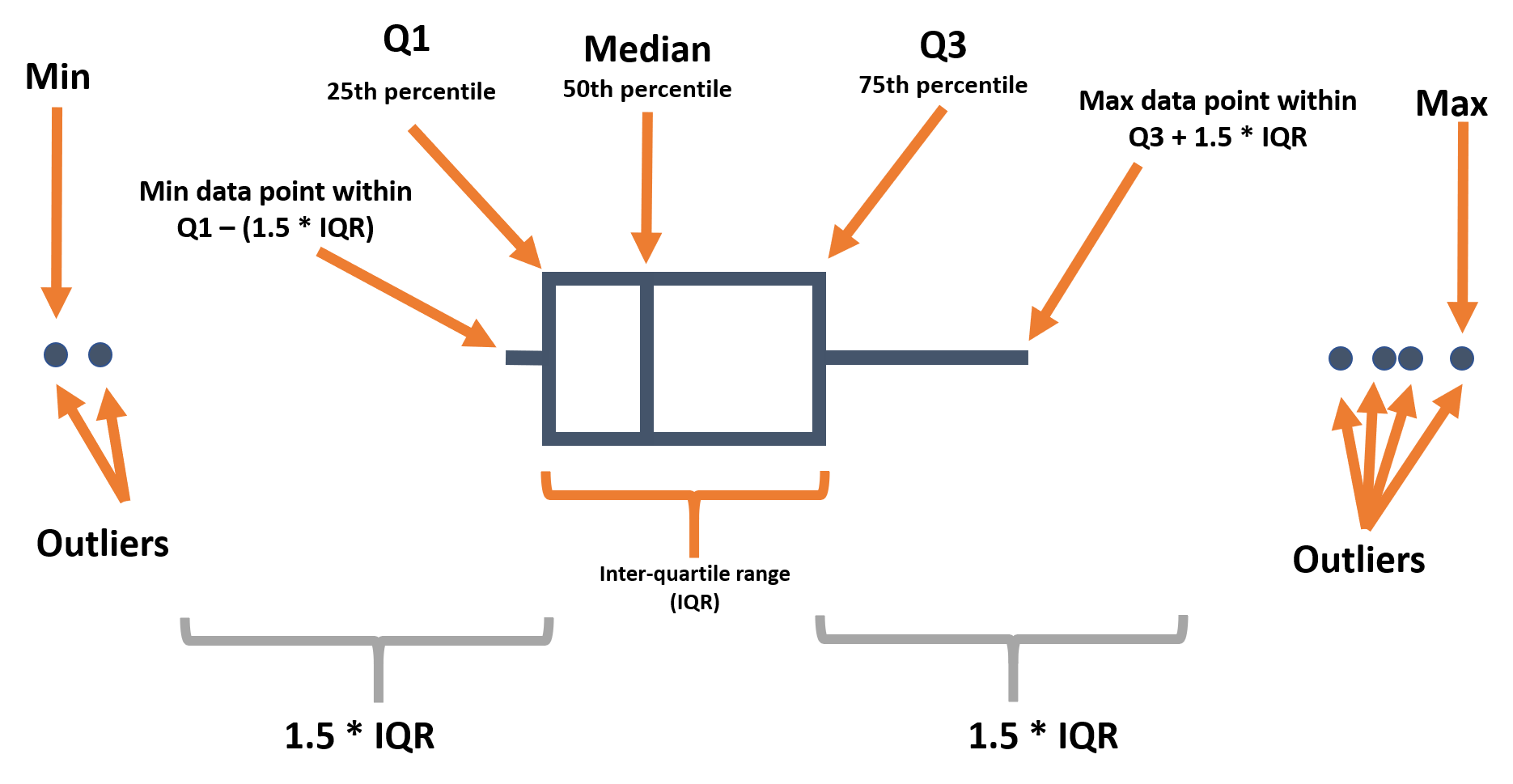
При использовании geom_boxplot() для создания коробчатой диаграммы обычно задается только одна ось (x или y) в рамках aes(). Указанная ось определяет, будут ли графики горизонтальными или вертикальными.
В большинстве геомов график для каждой группы создается путем привязки эстетики типа color = или fill = к столбцу в aes(). Однако для коробчатых диаграмм это достигается путем назначения столбца группировки на неназначенную ось (x или y). Ниже приведен код для построения коробчатой диаграммы всех значений возраста в наборе данных, а второй код - для отображения одной коробчатой диаграммы для каждого (не пропущенного) пола в наборе данных. Обратите внимание, что значения NA (“отсутствующие”) будут отображаться в виде отдельной коробчатой диаграммы, если их не удалить. В этом примере мы также установили fill для столбца outcome, чтобы каждый график был разного цвета - но это не обязательно.
# A) вся коробчатая диаграмма
ggplot(data = linelist)+
geom_boxplot(mapping = aes(y = age))+ # сопоставлена только ось y (не x)
labs(title = "A) Overall boxplot")
# B) Коробчатая диаграмма по группам
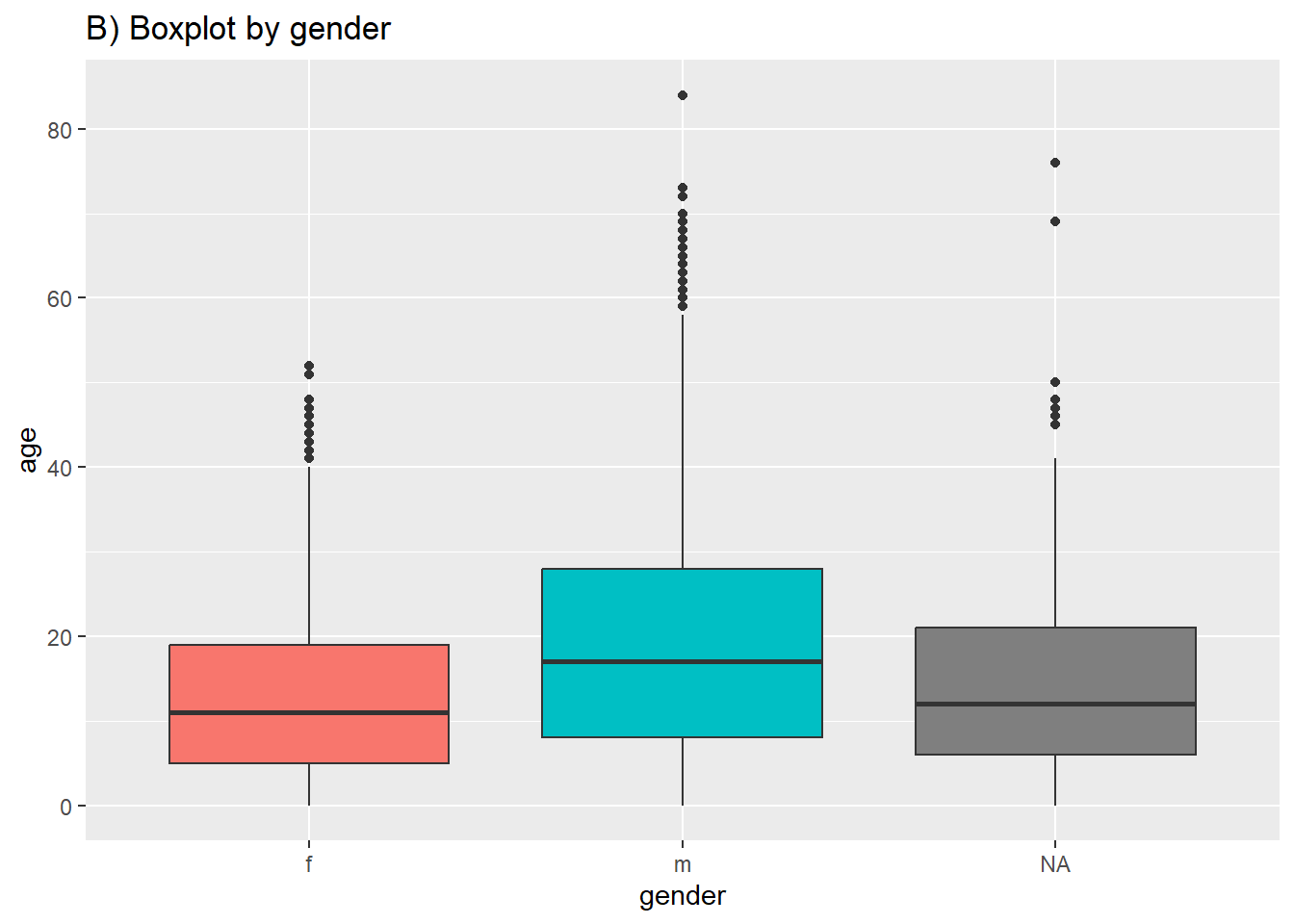
ggplot(data = linelist, mapping = aes(y = age, x = gender, fill = gender)) +
geom_boxplot()+
theme(legend.position = "none")+ # удалить легенду (лишняя)
labs(title = "B) Boxplot by gender") 
Код для добавления коробчатой диаграммы к краям диаграммы рассеяния (“маргинальные” графики) приведен на странице [советы по использованию ggplot].
Скрипичный график, графис с “дрожанием” и график sina
Ниже приведен код для построения скрипичных графиков (geom_violin) и графиков с фугкцией дрожания (geom_jitter) для отображения распределений. Вы можете указать, что заливка или цвет также определяются данными, вставив эти опции в aes().
# A) График с функцией дрожания по группам
ggplot(data = linelist %>% drop_na(outcome), # удаление отсутствующих значений
mapping = aes(y = age, # Непрерывная переменная
x = outcome, # Переменная группировки
color = outcome))+ # Переменная цвета
geom_jitter()+ # Создание скрипичного графика
labs(title = "A) jitter plot by gender")
# B) Скрипичный график по группам
ggplot(data = linelist %>% drop_na(outcome), # удаление отсутствующих значений
mapping = aes(y = age, # Непрерывная переменная
x = outcome, # Переменная группировки
fill = outcome))+ # Переменная заливки (цвета)
geom_violin()+ # Создание скрипичного графика
labs(title = "B) violin plot by gender") 

Их можно объединить с помощью функции geom_sina() из пакета ggforce. Функция sina строит графики точек дрожания в форме скрипичного графика. При наложении на скрипичный график (регулируя прозрачность) это может быть легче визуально интерпретировать.
# A) График Sina по группам
ggplot(
data = linelist %>% drop_na(outcome),
aes(y = age, # числовая переменная
x = outcome)) + # переменная группы
geom_violin(
aes(fill = outcome), # заливка (цвет фона скрипки)
color = "white", # белый контур
alpha = 0.2)+ # прозрачность
geom_sina(
size=1, # Изменение величины дрожания
aes(color = outcome))+ # цвет (цвет точек)
scale_fill_manual( # Определить заливку для фона скрипки по смерти/выздоровлению
values = c("Death" = "#bf5300",
"Recover" = "#11118c")) +
scale_color_manual( # Определение цветов для точек по смерти/выздоровлению
values = c("Death" = "#bf5300",
"Recover" = "#11118c")) +
theme_minimal() + # удалить серый фон
theme(legend.position = "none") + # Удалить ненужную легенду
labs(title = "B) violin and sina plot by gender, with extra formatting") 
Две непрерывные переменные
Используя аналогичный синтаксис, функция geom_point() позволяет построить график рассеивания двух непрерывных переменных относительно друг друга. Это удобно для отображения фактических значений, а не их распределений. Базовый график рассеивания возраста и веса показан в (A). В (B) мы снова используем facet_grid(), чтобы показать связь между двумя непрерывными переменными в построчном списке.
# Базовый график рассеяния веса и возраста
ggplot(data = linelist,
mapping = aes(y = wt_kg, x = age))+
geom_point() +
labs(title = "A) Scatter plot of weight and age")
# График рассеивания веса и возраста в зависимости от пола и исхода болезни Эбола
ggplot(data = linelist %>% drop_na(gender, outcome), # фильтр сохраняет непропущенные пол/результат
mapping = aes(y = wt_kg, x = age))+
geom_point() +
labs(title = "B) Scatter plot of weight and age faceted by gender and outcome")+
facet_grid(gender ~ outcome) 

Три непрерывные переменные
С помощью аргумента fill = можно отобразить три непрерывные переменные, создав тепловой график. Цвет каждой “ячейки” будет отражать значение третьего непрерывного столбца данных. Более подробную информацию и несколько примеров см. на странице [советы по использованию ggplot] и на странице [Тепловые графики].
Существуют способы построения трехмерных графиков в R, но для прикладной эпидемиологии они часто трудно интерпретируемы и поэтому менее полезны для принятия решений.
30.13 Построение графиков категориальных данных
Категориальные данные могут представлять собой символьные значения, могут быть логическими (“ИСТИНА/ЛОЖЬ”) или факторами (см. страницу [Факторы]).
Подготовка
Структура данных
Прежде всего, необходимо понять, в каком виде существуют категориальные данные: в виде необработанных наблюдений, например, в виде построчного списка случаев, или в виде сводного или агрегированного датафрейма, содержащего подсчеты или пропорции. Состояние данных будет влиять на то, какую функцию построения графиков вы будете использовать:
- Если данные представляют собой необработанные наблюдения с одной строкой на наблюдение, то, скорее всего, будет использована функция
geom_bar().
- Если данные уже агрегированы в виде подсчетов или пропорций, то, скорее всего, используется
geom_col().
Класс столбца и упорядочение значений
Далее исследуйте класс столбцов, которые вы хотите построить. Мы рассматриваем hospital, сначала с помощью class() из базового R, а затем с помощью tabyl() из janitor.
# Посмотрите на класс столбца больницы - мы видим, что это символ
class(linelist$hospital)[1] "character"# Рассмотрите значения и пропорции в столбце больниц
linelist %>%
tabyl(hospital) hospital n percent
Central Hospital 454 0.07710598
Military Hospital 896 0.15217391
Missing 1469 0.24949049
Other 885 0.15030571
Port Hospital 1762 0.29925272
St. Mark's Maternity Hospital (SMMH) 422 0.07167120Мы видим, что значения внутри являются символами, так как это названия больниц, и по умолчанию они упорядочены в алфавитном порядке. Имеются значения “прочие” и “отсутствующие”, которые мы предпочли бы видеть последними подкатегориями при представлении разбивки. Поэтому мы меняем этот столбец на фактор и переупорядочиваем его. Более подробно это рассматривается на странице [Факторы].
# Преобразование в фактор и определение порядка уровней, чтобы "Прочие" и "Отсутствующие" были последними
linelist <- linelist %>%
mutate(
hospital = fct_relevel(hospital,
"St. Mark's Maternity Hospital (SMMH)",
"Port Hospital",
"Central Hospital",
"Military Hospital",
"Other",
"Missing"))levels(linelist$hospital)[1] "St. Mark's Maternity Hospital (SMMH)"
[2] "Port Hospital"
[3] "Central Hospital"
[4] "Military Hospital"
[5] "Other"
[6] "Missing" geom_bar()
Используйте geom_bar(), если хотите, чтобы высота столбцов (или высота компонентов сложенных столбцов) отражала количество соответствующих строк в данных. Между этими столбиками будут оставаться промежутки, если только не будет настроена эстетика графика width =.
- Укажите только один столбец оси (обычно ось x). Если указать x и y, то будет получено сообщение
Error: stat_count() can only have an x or y aesthetic..
- Вы можете создать сложенные столбцы, добавив назначение столбца
fill =внутриmapping = aes().
- Противоположная ось по умолчанию будет называться ” подсчет”, поскольку она представляет собой количество строк
Ниже мы отнесли исходы к оси y, но с тем же успехом их можно отнести и к оси x. Если у вас есть длинные символьные значения, то иногда лучше перевернуть столбики на бок и поместить легенду внизу. Это может повлиять на порядок расположения уровней факторов - в данном случае мы меняем их местами с помощью fct_rev(), чтобы поместить отсутствующие и другие в нижнюю часть.
# A) Исходы во всех случаях
ggplot(linelist %>% drop_na(outcome)) +
geom_bar(aes(y = fct_rev(hospital)), width = 0.7) +
theme_minimal()+
labs(title = "A) Number of cases by hospital",
y = "Hospital")
# B) Исходы во всех случаях с разбивкой по больницам
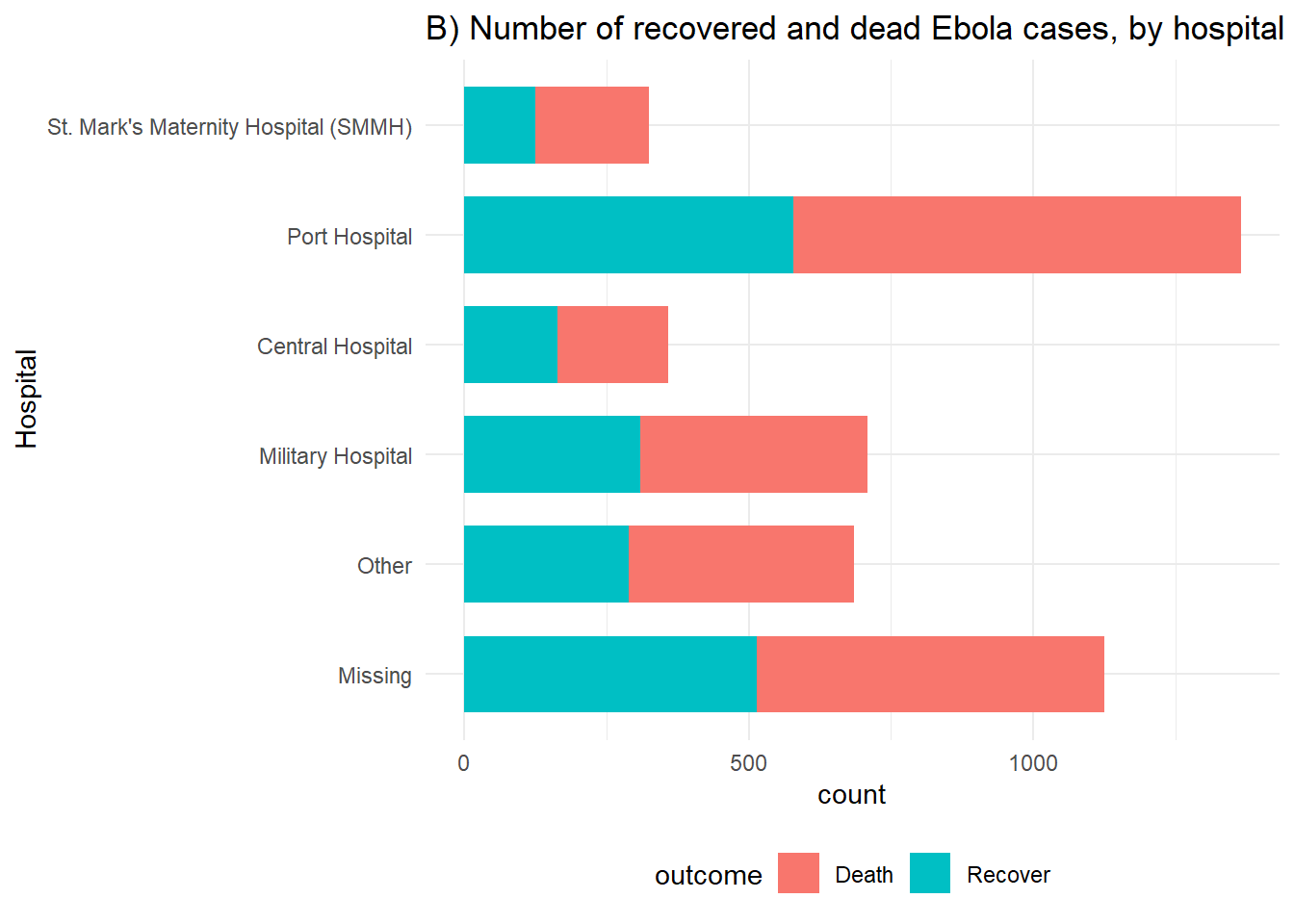
ggplot(linelist %>% drop_na(outcome)) +
geom_bar(aes(y = fct_rev(hospital), fill = outcome), width = 0.7) +
theme_minimal()+
theme(legend.position = "bottom") +
labs(title = "B) Number of recovered and dead Ebola cases, by hospital",
y = "Hospital")
geom_col()
Используйте geom_col(), если хотите, чтобы высота столбиков (или высота компонентов сложенных столбиков) отражала предварительно вычисленные значения, имеющиеся в данных. Часто это суммарные или “агрегированные” подсчеты, или пропорции.
Задайте в geom_col() назначение столбцов для обеих осей. Обычно столбец оси x является дискретным, а столбец оси y - числовым.
Допустим, у нас есть набор данных outcomes:
# A tibble: 2 × 3
outcome n proportion
<chr> <int> <dbl>
1 Death 1022 56.2
2 Recover 796 43.8Ниже приведен код с использованием geom_col для создания простых столбчатых диаграмм, отображающих распределение исходов у пациентов с лихорадкой Эбола. При использовании функции geom_col необходимо указать как x, так и y. Здесь x - категориальная переменная по оси x, а y - сгенерированный столбец пропорций proportion.
# Исходы во всех случаях
ggplot(outcomes) +
geom_col(aes(x=outcome, y = proportion)) +
labs(subtitle = "Number of recovered and dead Ebola cases")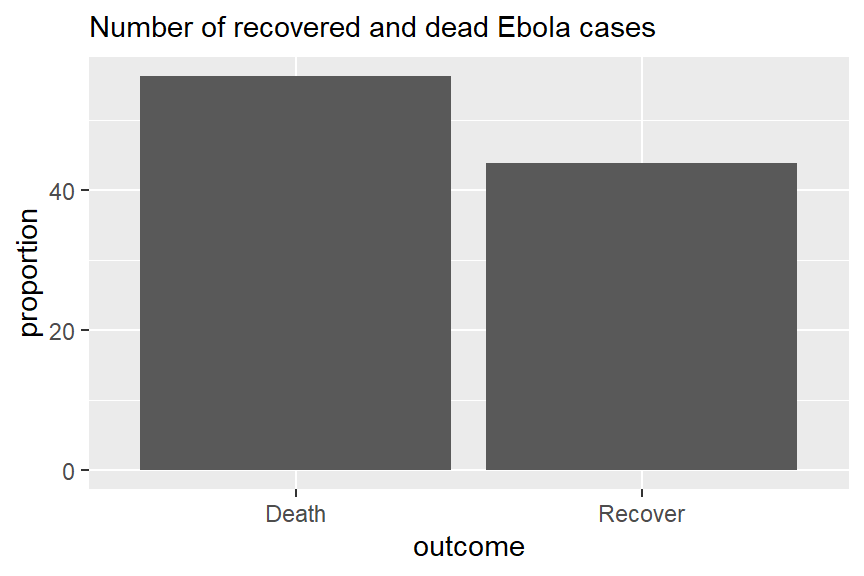
Для того чтобы показать разбивку по больницам, необходимо, чтобы таблица содержала больше информации и имела “длинный” формат. Мы создаем эту таблицу с частотами комбинированных категорий outcome и hospital (советы по группировке см. на странице [Группирование данных]).
outcomes2 <- linelist %>%
drop_na(outcome) %>%
count(hospital, outcome) %>% # получить подсчеты по больницам и исходам
group_by(hospital) %>% # Сгруппировать таким образом, чтобы пропорции были вне общего значения по больнице
mutate(proportion = n/sum(n)*100) # рассчитать пропорции от общего значения по больнице
head(outcomes2) # Предварительный просмотр данных# A tibble: 6 × 4
# Groups: hospital [3]
hospital outcome n proportion
<fct> <chr> <int> <dbl>
1 St. Mark's Maternity Hospital (SMMH) Death 199 61.2
2 St. Mark's Maternity Hospital (SMMH) Recover 126 38.8
3 Port Hospital Death 785 57.6
4 Port Hospital Recover 579 42.4
5 Central Hospital Death 193 53.9
6 Central Hospital Recover 165 46.1Затем мы создаем ggplot с некоторым дополнительным форматированием:
- Переворот оси: Поменяли оси местами с помощью
coord_flip(), чтобы можно было читать названия больниц. - Столбцы бок о бок: Добавлен аргумент
position = "dodge", чтобы столбцы для смерти и выздоровления были представлены рядом, а не сложенными. Обратите внимание, что по умолчанию столбцы представлены в виде сложенных столбиков. - Ширина столбца: Указано значение ‘width’, поэтому столбцы будут вдвое тоньше, чем при полной возможной ширине.
- Порядок столбцов: Изменили порядок категорий на оси y так, чтобы “Другое” и “Отсутствующие” оказались внизу, с помощью
scale_x_discrete(limits=rev). Обратите внимание, что мы использовали именно этот метод, а неscale_y_discrete, поскольку больница указывается в аргументеxвaes(), даже если визуально она находится на оси y. Мы делаем это потому, что Ggplot, по-видимому, представляет категории в обратном порядке, если мы не запрещаем ему это делать.
- Другие сведения: Добавлены метки/названия и цвета в
labsиscale_fill_colorсоответственно.
# Исходы во всех случаях в разбивке по больницам
ggplot(outcomes2) +
geom_col(
mapping = aes(
x = proportion, # показать предварительно рассчитанные значения пропорций
y = fct_rev(hospital), # обратный порядок уровней, чтобы отсутствующие/другие находились внизу
fill = outcome), # сложенные по результатам
width = 0.5)+ # более тонкие столбики (из 1)
theme_minimal() + # Минимальная тема
theme(legend.position = "bottom")+
labs(subtitle = "Number of recovered and dead Ebola cases, by hospital",
fill = "Outcome", # заголовок легенды
y = "Count", # заголовок оси y
x = "Hospital of admission")+ # Заголовок оси x
scale_fill_manual( # добавление цветов вручную
values = c("Death"= "#3B1c8C",
"Recover" = "#21908D" )) 
Обратите внимание на то, что пропорции являются бинарными, поэтому мы можем предпочесть опустить слово “выздоровление” и показать только долю умерших. Это просто для наглядности.
При использовании geom_col() с данными о датах (например, эпикривая из агрегированных данных) необходимо настроить аргумент width =, чтобы убрать “промежуточные” линии между столбиками. При использовании ежедневных данных задайте width = 1. Если данные еженедельные, то width = 7. Использование месяцев невозможно, поскольку каждый месяц имеет разное количество дней.
geom_histogram()
Гистограммы похожи на столбчатые диаграммы, но отличаются от них тем, что измеряют распределение непрерывной переменной. Пробелы между “столбиками” отсутствуют, и в geom_histogram() передается только один столбец. Существуют такие специфические для гистограмм аргументы, как bin_width = и breaks = для указания способа разбиения данных на столбцы. Дополнительную информацию можно найти в приведенном выше разделе о непрерывных данных и на странице [Эпидемические кривые].
30.14 Ресурсы
В Интернете имеется огромное количество справочной информации, особенно по ggplot. См: