
40 Отчеты с помощью R Markdown
R Markdown - широко используемый инструмент для создания автоматизированных, воспроизводимых выходных данных, которыми можно делиться, таких как отчеты. Он генерирует статические или интерактивные выходные данные в Word, pdf, html, powerpoint и других форматах.
Скрипт R Markdown сочетает код R и текст таким образом, что скрипт становится вашим выходным документом. Вы можете создать полный отформатированный документ, включая описательную часть (может быть динамичной и меняться на основе ваших данных), таблицы, рисунки, маркированные списки, список использованной литературы и т.п.
Такие документы могут создаваться для регулярного предоставления обновленной информации (например, ежедневные отчеты по эпиднадзору) и/или могут выполняться для подмножества данных (например, отчеты для каждой юрисдикции).
Другие страницы настоящего руководства более подробно рассматривают эту тему:
- Страница Структурирование рутинных отчетов демонстрирует, как превратить создание автогенерируемых папок с временным штампом в рутину.
- Страница Информационные панели с R Markdown объясняет, как форматировать отчет R Markdown в виде информационной панели.
Следует отметить, что проект R4Epis создал шаблон скриптов R Markdown для наиболее часто встречающихся вспышек и сценариев исследований, с которыми сталкивались в местах проведения проекта MSF (врачи без границ).
40.1 Подготовка
Общая информация по R Markdown
Объясним некоторые необходимые концепции и пакеты:
- Markdown - это “язык”, который позволяет вам писать документ, используя простой текст, который можно конвертировать в html и другие форматы. Он не специфичен для R. Файлы, записанные с помощью разметки Markdown имеют расширение ‘.md’.
- R Markdown: это вариант markdown, который специфичен для R - он позволяет вам писать документ, используя разметку, чтобы создать текст и интегрировать код R и отображать его выходные данные. Файлы R Markdown имеют расширение ‘.Rmd’.
- rmarkdown - пакет: Он используется R, чтобы превратить файл .Rmd в желаемые выходные данные. Его фокус заключается в конвертации синтаксиса разметки (текста), поэтому нам нужны еще…
- knitr: Этот пакет R прочитает фрагменты кода, выполнит их и “свяжет” их с документом. Так можно включить таблицы и графики рядом с текстом.
- Pandoc: Наконец, pandoc собственно конвертирует выходные данные в word/pdf/powerpoint и т.п. Это также отдельная от R программа, но она устанавливается автоматически вместе с RStudio.
В целом, процесс, который осуществляется фоново (вам не нужно знать все эти шаги!) включает в себя передачу файла .Rmd в knitr, который выполняет фрагменты кода и создает новый файл .md (markdown), который включает в себя код R и выводимые данные. Файл .md затем обрабатывается в pandoc, чтобы создать итоговый продукт: документ Microsoft Word, файл HTML, документ powerpoint, pdf, и т.п.

(источник: https://rmarkdown.rstudio.com/authoring_quick_tour.html):
Установка
Чтобы создать выходной продукт в R Markdown, вам нужно установить следующее:
- Пакет rmarkdown (knitr также установится автоматически)
- Pandoc, который должен был установиться вместе с RStudio. Если вы не используете RStudio, вы можете скачать Pandoc тут: http://pandoc.org.
- Если вы хотите сгенерировать выходной продукт в формате PDF (это чуть сложнее), вам нужно будет установить LaTeX. Для пользователей R Markdown, которые не устанавливали LaTeX ранее, мы рекомендуем установить TinyTeX (https://yihui.name/tinytex/). Вы можете использовать следующие команды:
pacman::p_load(tinytex) # устанавливаем пакет tinytex
tinytex::install_tinytex() # команда R для установки программы TinyTeX40.2 Начало работы
Установка пакета rmarkdown R
Установите пакет R rmarkdown. В этом руководстве мы подчеркиваем использование p_load() из pacman, которая устанавливает пакет, если необходимо, и загружает его для использования. Вы можете также загрузить установленные пакеты с помощью library() из базового R. См. страницу Основы R для получения дополнительной информации о пакетах R.
pacman::p_load(rmarkdown)Создание нового файла Rmd
В RStudio откройте новый файл R markdown, начав с ‘File’ (файл), затем ‘New file’ (новый файл), затем ‘R markdown…’.
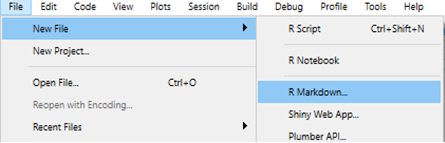
R Studio даст вам некоторые опции выходных данных на выбор. В примере ниже мы выбираем “HTML”, поскольку мы хотим создать документ html. Заголовок и имена авторов не столь важны. Если в этих опциях нет того типа выходного документа, который вам нужен, не волнуйтесь - вы можете выбрать любой вариант и потом изменить его в скрипте.

Это позволит открыть новый скрипт .Rmd.
Важно знать
Рабочая директория
Рабочая директория файла markdown - то, где сохраняется сам файл Rmd. Например, если R проект находится внутри ~/Documents/projectX, а сам файл Rmd - в подпапке ~/Documents/projectX/markdownfiles/markdown.Rmd, код read.csv(“data.csv”) внутри файла markdown будет искать csv файл в папке markdownfiles, а не в корневой папке проекта, где обычно осуществляют поиск скрипты в рамках проектов.
Чтобы сослаться на файлы в ином расположении, вам нужно либо использовать полный путь к файлу, либо пакет here. Пакет here задает рабочую директорию в корневой папкет проекта R, что детально объясняется на страницах Проекты R и Импорт и экспорт. Например, чтобы импортировать файл под названием “data.csv” из папки projectX, код будет выглядеть так: import(here(“data.csv”)).
Обратите внимание, что в скриптах R Markdown не рекомендуется использовать setwd() – она будет применяться только к фрагменту кода, в котором она записана.
Работа на сетевых дисках или на компьютере
Поскольку R Markdown может столкнуться с проблемами pandoc при работе с общего сетевого диска, рекомендуется, чтобы ваша папка была на локальной машине, то есьт в проекте в папке “Мои документы”. Если вы используте Git (очень рекомендуется!), это будет вам знакомо. Для получения дополнительной информации см. страницы R на сетевых дисках и Ошибки и справка.
40.3 Компоненты R Markdown
Документ R Markdown можно редактировать в RStudio как и стандартный скрипт R. Когда вы начинаете новый скрипт R Markdown, RStudio попробует помочь, показав шаблон, который объясняет разные разделы скрипта R Markdown.
Ниже вы видите то окно, которое появляется, когда вы начинаете новый скрипт Rmd, с помощью которого хотите создать выходной продукт в html (как мы определили в предыдущем разделе).
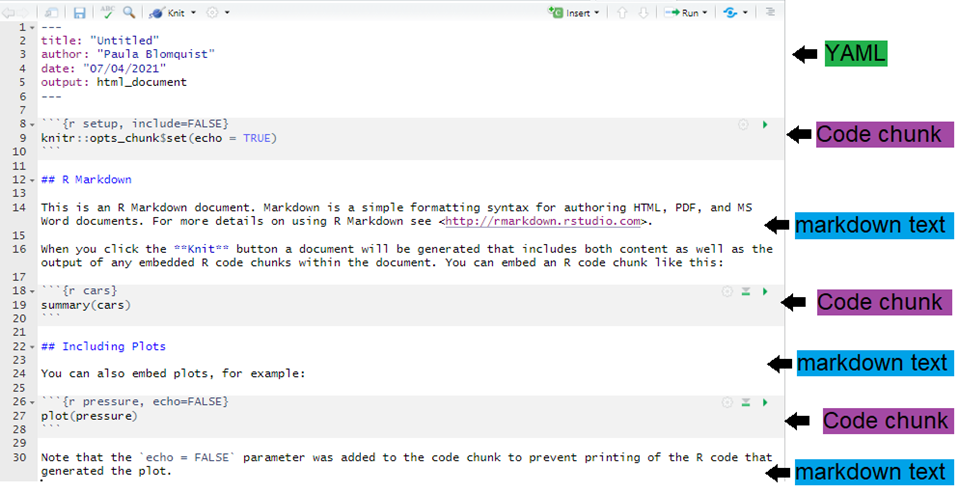
Как вы можете видеть, существует три основных компонента файла Rmd: YAML, текст Markdown, и фрагменты кода R
Они создадут и станут вашим выходным документом. См. схему ниже:
![]()
Метаданные YAML
Их называют ‘метаданные YAML’ или просто ‘YAML’, находятся в верхней части документа R Markdown. Этот раздел скрипта укажет вашему файлу Rmd, какого типа выходной результат создать, предпочтения в форматировании, а также другие метаданные, например, название документа, автор и дата. Существуют и другие способы применения, не упомянутые здесь (но на них есть отсылка в ‘Подготовка выходных результатов’). Обратите внимание, что важны отступы; tab не допускается, а пробелы - можно.
Этот раздел должен начинаться со строчки, содержащей три дефиса --- и должен закрываться строкой, содержащей три дефиса ---. Параметры YAML указываются в парах key:value. Размещение двоеточий в YAML очень важно - пары key:value разделяются двоеточиями (не знаки равно!).
YAML должны начинаться с метаданных для документа. Порядок этих первичных параметров YAML (без отступов) не важен. Например:
title: "My document"
author: "Me"
date: "2024-06-19"Вы можете использовать код R в значениях YAML, написав его как in-line code (в начале r внутри обратных одинарных кавычек), но также в кавычках (см. пример выше в строке date:).
На изображении выще, поскольку мы кликнули, что выходным результатом по умолчанию будет файл html, мы можем увидеть, что в YAML написано output: html_document. Однако мы также можем изменить этот пункт на powerpoint_presentation, word_document или даже pdf_document.
Текст
Это текстовая часть вашего документа, включая заголовки и подзаголовки. Она записана языком разметки “markdown”, который используется в разных программах.
Ниже приведены основные способы написания текста. См. более подробную документацию в “шпаргалке” по R Markdown на веб-сайте RStudio.
Новые строки
Уникально для R Markdown, чтобы начать новую строку, введите *два пробела** в конце предыдущей строки, затем нажмите Enter/Return.
Регистр
Поставьте вокруг текста следующие знаки, чтобы изменить его отображение.
- Нижние подчеркивания (
_text_) или одна звездочка (*text*) для курсива - Двойная звездочка (
**текст**) для жирного текста - Обратные одинарные кавычки (
text) для отображения текста как кода
Собственно вид шрифта можно установить, использовав конкретные шаблоны (задаются в метаданных YAML; см. примеры).
Цвет
Не существует простого механизма изменения цвета текста в R Markdown. Как вариант, ЕСЛИ вы на выходе получаете файл HTML, то можно добавить строку HTML в текст markdown. HTML код ниже напечатает строку текста жирным красным шрифтом.
<span style="color: red;">**_ВНИМАНИЕ:_** Это предупреждение.</span> ВНИМАНИЕ: Это предупреждение.
Заголовки и подзаголовки
Символ решетки в текстовой части скрипта R Markdown создает заголовок. Это отличается от фрагментов кода R в скрипте, где решетка используется для комментария/аннотации/де-активации.
Разные уровни заголовка создаются с помощью разного количества символов решетки в начале новой строки. Один знак решетки - основной заголовок. Два знака решетки - заголовок второго уровня. Заголовки третьего и четвертого уровня можно создать с помощью увеличения количества знаков решетки.
# Заголовок первого уровня
## Заголовок второго уровня
### Заголовок третьего уровняМаркированные списки
Используйте звездочки (*), чтобы создать маркированные списки. Завершите предыдущее предложение, введите два пробела, дважды нажмите Enter/Return, затем начинайте маркированный список. Включите пробел между звездочкой и текстом этого пункта списка. После каждого пункта списка введите два пробела, затем нажмите Enter/Return. Подпункты маркированного списка работают так же, но с отступом. Числа работают также, но вместо звездочки, пишите 1), 2), и т.п. Ниже пример того, как может выглядеть текст скрипта R Markdown.
Вот мой маркированный список (после этого двоеточия два пробела):
* Пункт 1 (после него два пробела и Enter/Return)
* Пункт 2 (после него два пробела и Enter/Return)
* Подпункт 1 (после него два пробела и Enter/Return)
* Подпункт 2 (после него два пробела и Enter/Return)
Выделение текста в комментарий
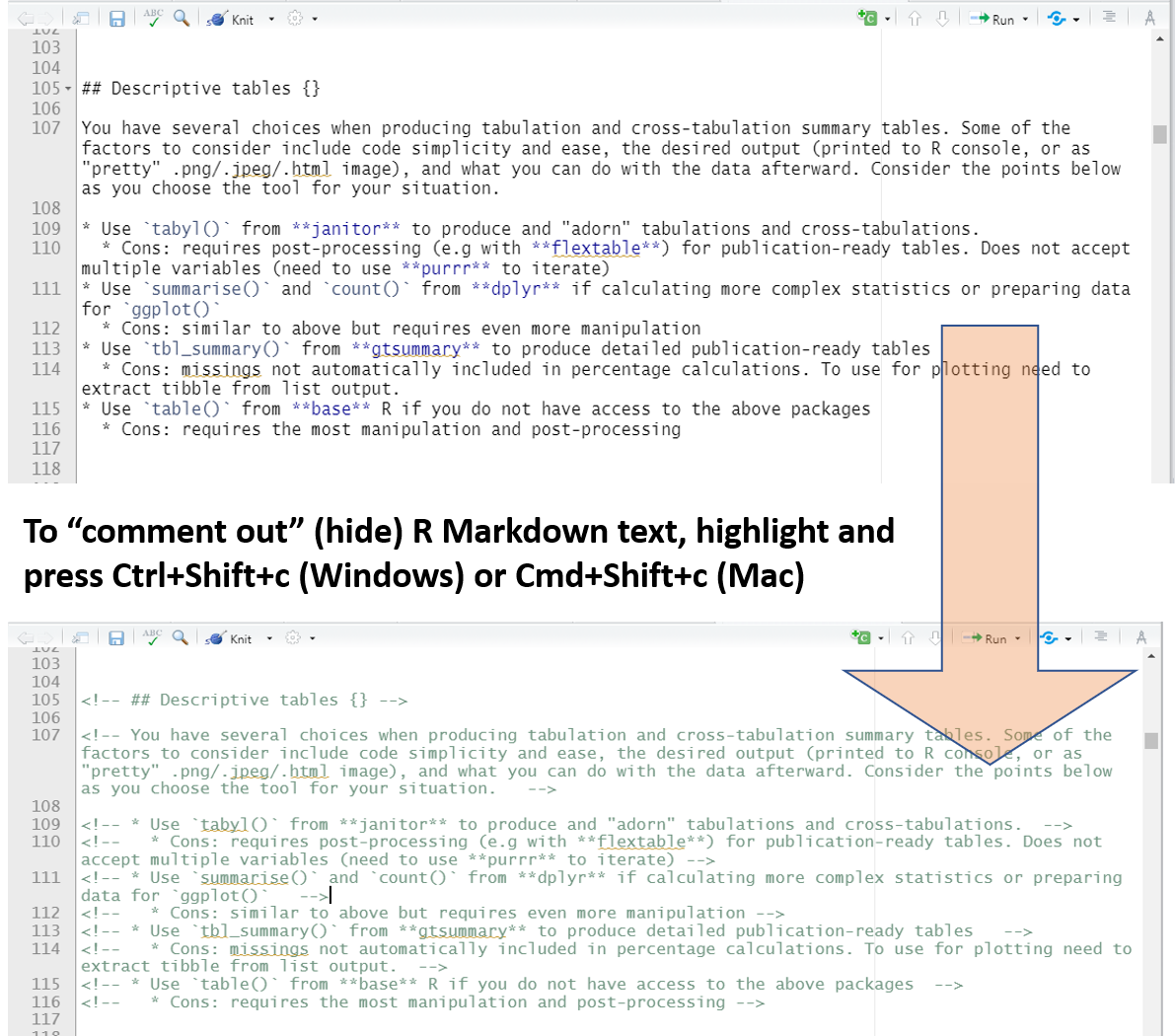
Вы можете выделить текст R Markdown в комментарий также как вы используете “#”, чтобы выделить строку кода R во фрагменте кода R в комментарий. Просто выделите текст и нажмите Ctrl+Shift+c (Cmd+Shift+c для Mac). Текст будет окружен стрелками и станет зеленым. Его не будет видно в выходном результате.
Фрагменты кода
Разделы скрипта, которые посвящены выполнению кода R, называют “фрагментами кода”. Здесь вы загружаете пакеты, импортируете данные и проводите уперавление данными и визуализацию. У вас может быть много фрагментов кода, они помогают вам организовать свой код R по частям, между которыми может быть текст. Необходимо отметить: Эти ‘фрагменты’ будут иметь чуть другой цвет фона по сравнению с текстовой частью документа.
Каждый фрагмент начинается со строки с тремя обратными одинарными кавычками и фигурными скобками, которые содержат параметры для фрагмента ({ }). Фрагмент оканчивается еще тремя обратными одинарными кавычками.
Вы можете создать новый фрагмент, напечатав его самостоятельно, используя горячие клавиши “Ctrl + Alt + i” (или Cmd + Shift + r в Mac), либо кликную зеленую иконку ‘insert a new code chunk’ (вставить новый фрагмент кода) в верхней части редактора скрипта.
Некоторые комментарии по содержимому фигурных скобок { }:
- Они начинаются с ‘r’, чтобы указать, что название используемого во фрагменте языка - R
- После r опционально вы можете написать “имя” фрагмента – оно не является обязательным, но может помочь организовать вашу работу. Обратите внимание, что если вы задаете имена фрагментам, вы должны ВСЕГДА использовать уникальные имена, иначе при обработке R будет выдавать предупреждения.
- Фигурные скобки могут включать другие опции, записанные как
tag=value, например:
eval = FALSEне выполнять код R
echo = FALSEне печатать исходный код фрагмента R в выходном документе
warning = FALSEне печатать предупреждения, выдаваемые кодом R
message = FALSEне печатать сообщения, созданные кодом R
include =TRUE/FALSE (ПРАВДА или ЛОЖЬ), включать ли выходные данные фрагмента (например, графики) в документеout.width =иout.height =- задает стильout.width = "75%"
fig.align = "center"корректирует, как рисунок выровнен на странице
fig.show='hold', если ваш фрагмент печатает несколько рисунков и вы их хотите напечатать рядом друг с другом (вместе сout.width = c("33%", "67%"). Можно также задать какfig.show='asis',чтобы показать их под тем кодом, который их генерирует,'hide'чтобы спрятать, либо'animate'для объединения нескольких в анимацию.
- заголовок фрагмента должен быть записан в одну строку
- Старайтесь избегать точек, нижних подчеркиваний и пробелов. Используйте вместо этого дефисы ( - ), если вам нужен разделитель.
Более детально об опциях knitr можно прочитать тут.
Некоторые вышеуказанные опции можно задать по принципу “наведи и кликни”, используя кнопки настройки в верхней правой части фрагмента. Здесь вы можете уточнить, какие части фрагмента вы хотите включить в готовый документ, в частности, код, выходные данные и предупреждения. Это будет выглядеть как записанные предпочтения внутри фигурных скобок, например, echo=FALSE, если вы хотите уточнить, что надо ‘показыватьт только выходной результат’.

Также в верхней части каждого фрагмента есть две стрелки, которые полезны, чтобы выполнить код внутри фрагмента, либо весь код в предыдущих фрагментах. Наведите на них, чтобы увидеть, что они делают.
Чтобы применить глобальные опции ко всем фрагментам скрипта, вы можете это задать в самом первом фрагменте кода R. Например, чтобы только выходные данные были показаны для каждого фрагмента кода, а не сам код, вы можете включить следующую команду во фрагмент кода R:
knitr::opts_chunk$set(echo = FALSE) Код R внутри текста
Вы также можете включить минимальный код R внутри обратных одинарных кавычек. Внутри одинарных обратных кавычек начните код с “r” и пробела, чтобы RStudio знал, что нужно оценивать код как код R. См. пример ниже.
Пример ниже показывает несколько уровней заголовков, маркированный список и использует код R для текущей даты (Sys.Date()), чтобы превратить ее в печатную дату.
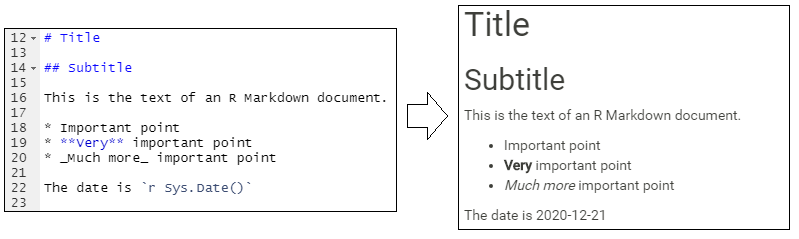
Приведенный пример является простым (отображение текущей даты), но с помощью того же синтаксиса можно отобразить значения, созданные более сложным кодом R (например, вычислить минимум, медиану, максимум для столбца). Также можно интегрировать в сценарий R-объекты или значения, созданные ранее в фрагментах R-кода.
В качестве примера скрипт ниже показывает долю случаев в возрасте младше 18 лет, используя функции tidyverse, и создает объекты less18, total, и less18prop. Это динамическое значение вставляется в последующий текст. Посмотрим, как это выглядит при связывании в документ word.
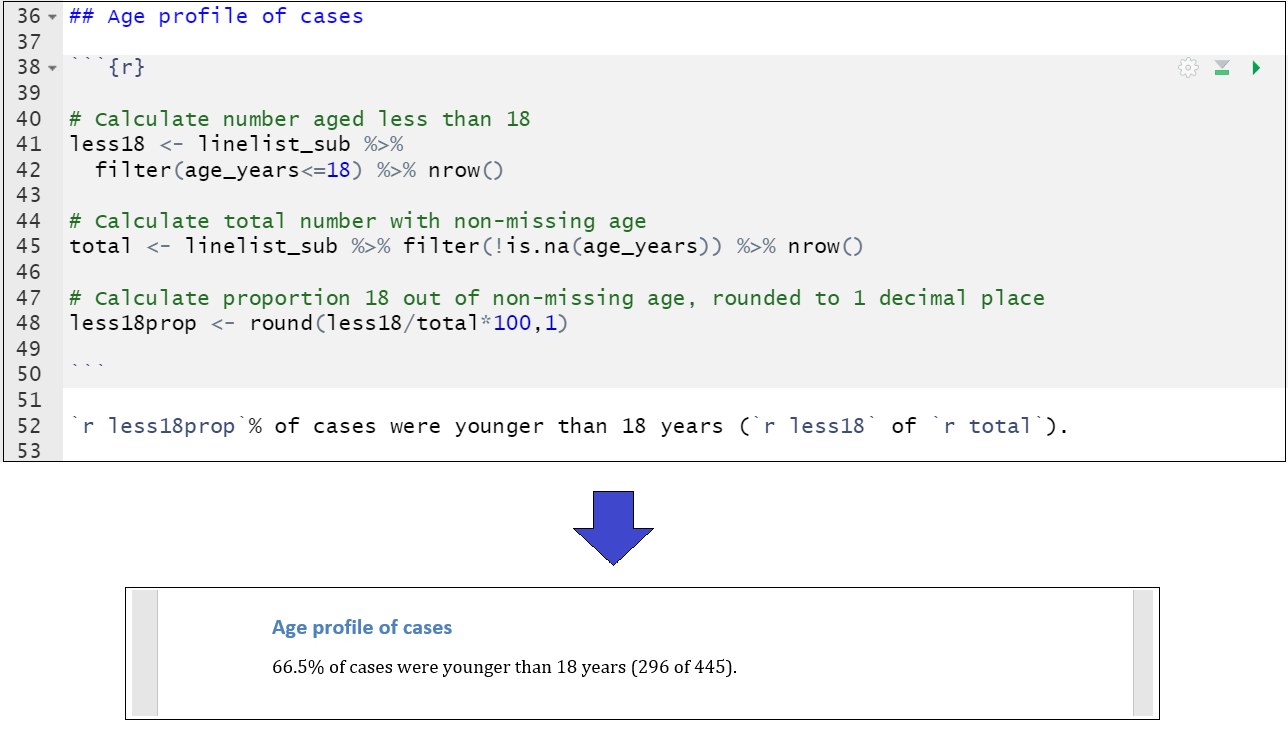
Рисунки
Вы можете включить рисунки в R Markdown одним из двух способов:
 Если указанный выше способ не работает, попробуйте использовать knitr::include_graphics()
knitr::include_graphics("path/to/image.png")(помните, путь к файлу можно записать, используя пакет here)
knitr::include_graphics(here::here("path", "to", "image.png"))Таблицы
Создавайте таблицы, используя дефисы ( - ) и вертикальные черточки ( | ). Количество дефисов до/между столбцами создает количество пробелов в ячейке до того, как начнется оборачивание текста.
Столбец 1 |Столбец 2 |Столбец 3
----------|-----------|--------
Ячейка A |Ячейка B |Ячейка C
Ячейка D |Ячейка E |Ячейка FУказанный выше код создаст ту таблицу, которую вы видите ниже:
| Столбец 1 | Столбец 2 | Столбец 3 |
|---|---|---|
| Ячейка A | Ячейка B | Ячейка C |
| Ячейка D | Ячейка E | Ячейка F |
разделы по вкладкам
Для результатов в виде HTML, вы можете организовать разделы по “вкладкам”. Просто добавьте .tabset в фигурные скобки { }, которые размещаются после заголовка. Любые подзаголовки под этим заголовком (до появления другого заголовка того же уровня) будут отображаться как вкладки, между которыми пользователей может переключаться. Дополнительную информацию читайте тут
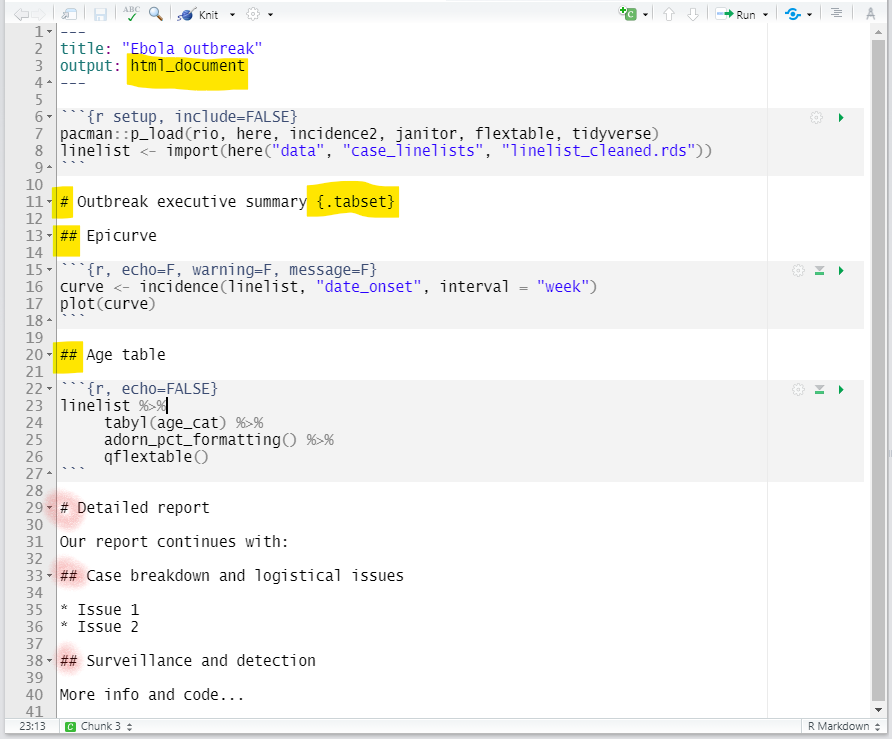
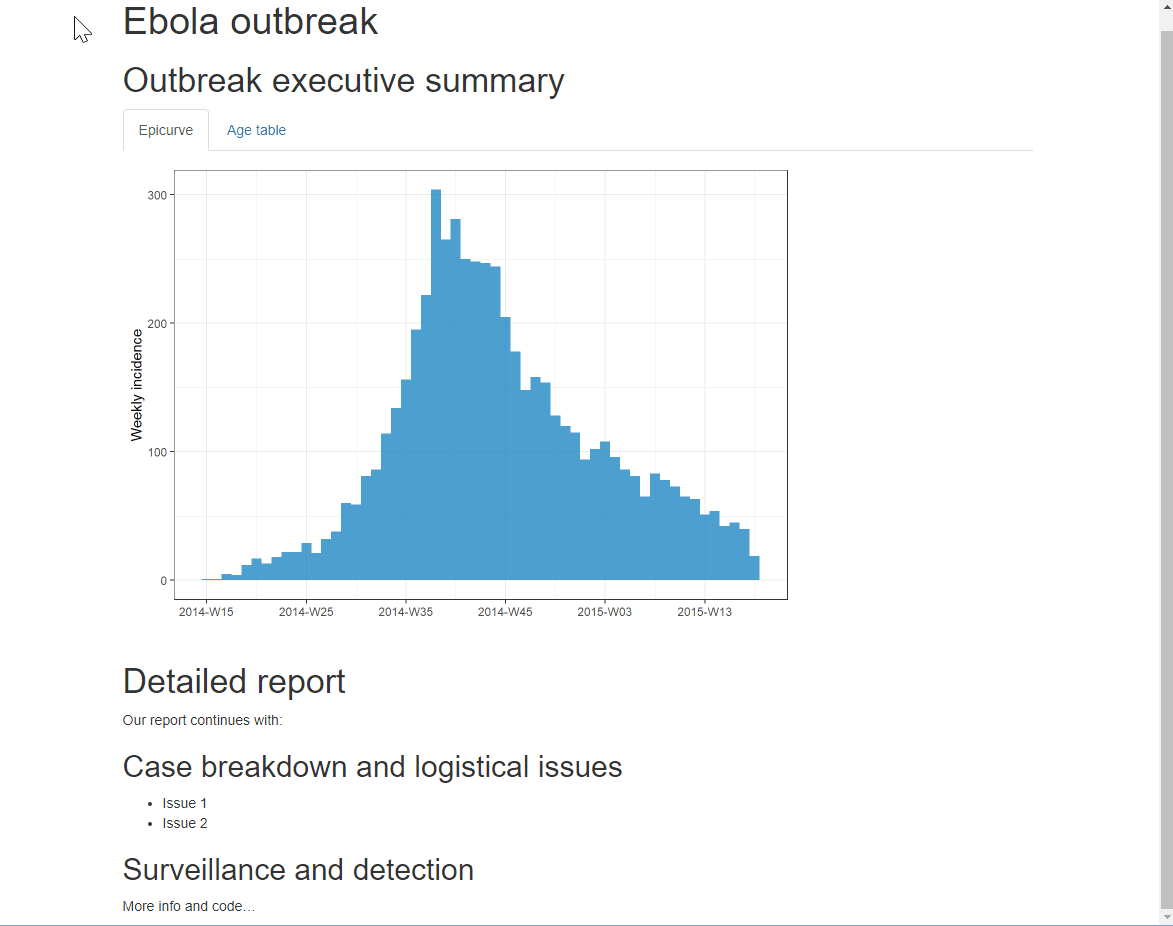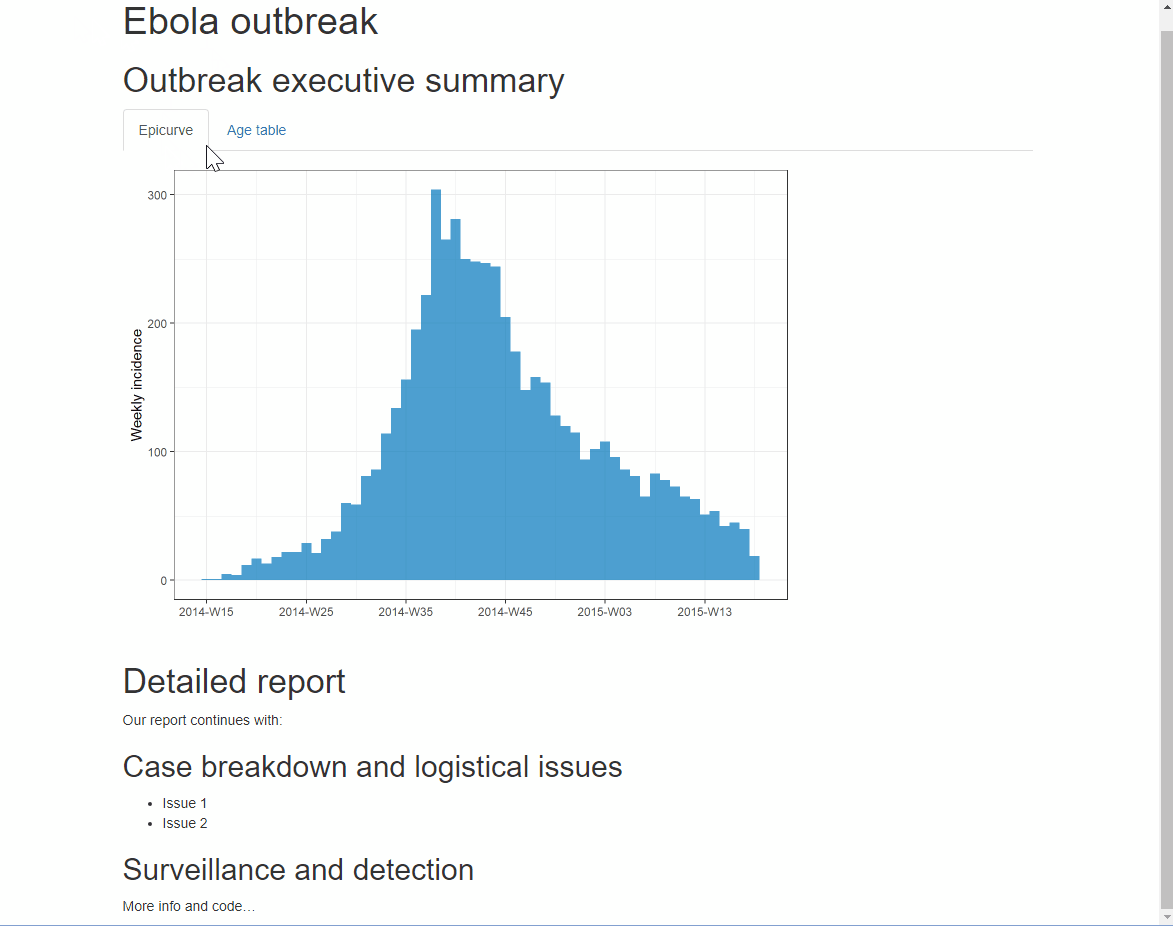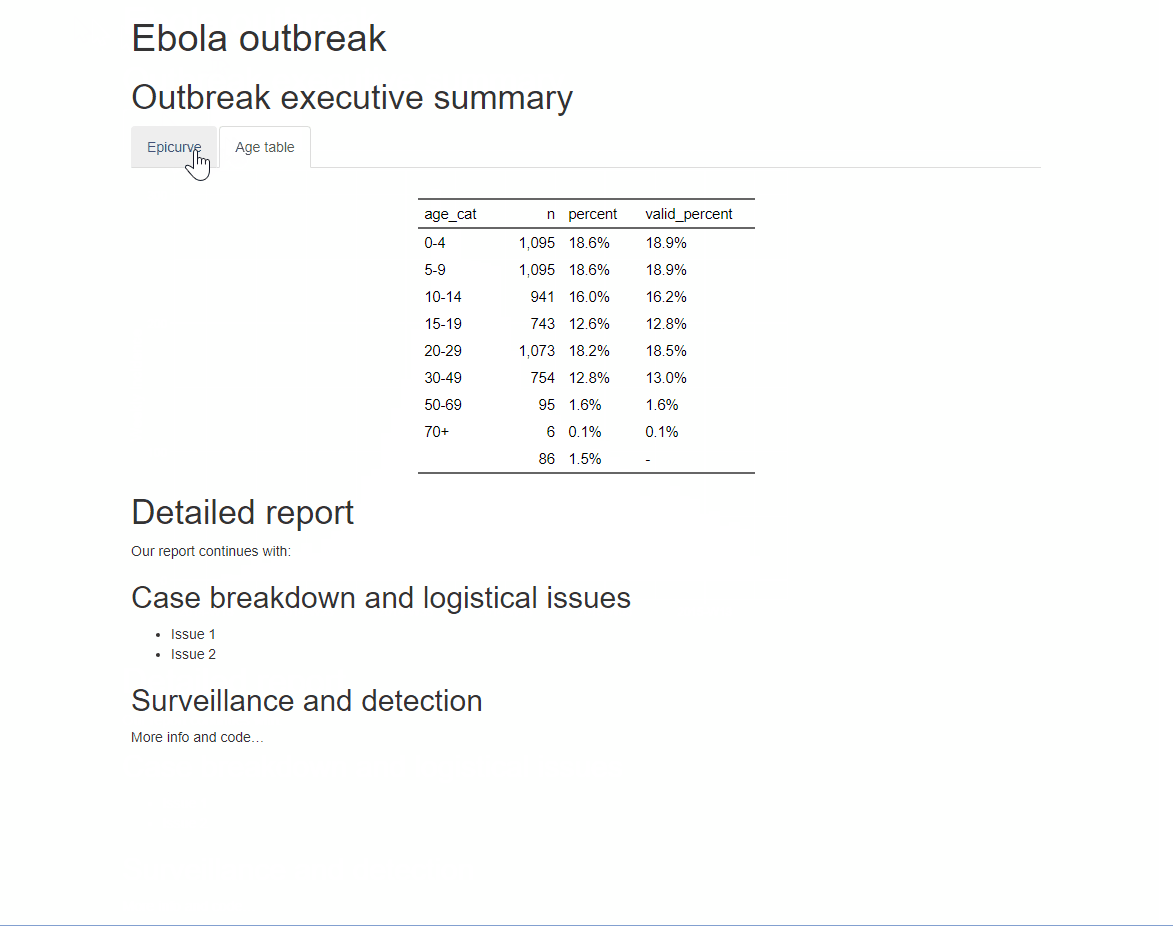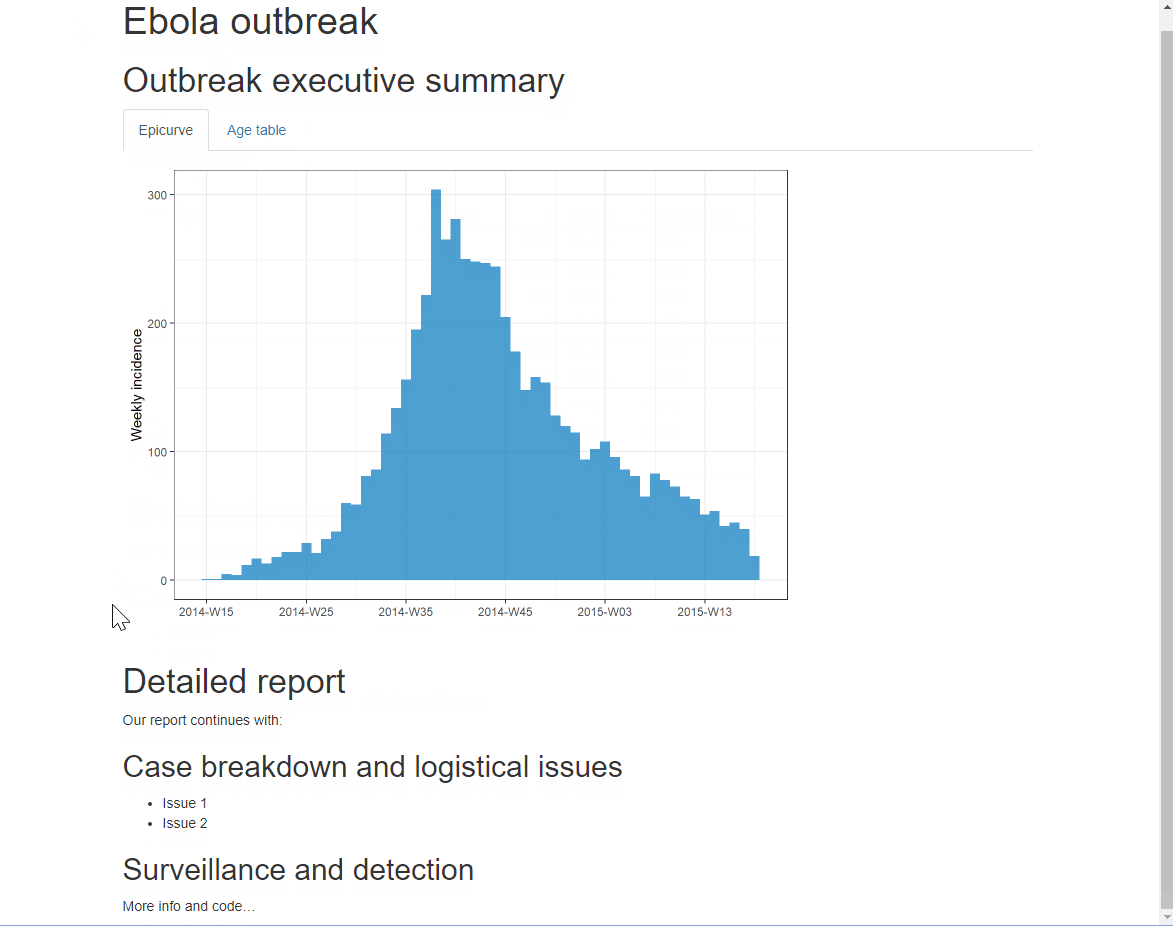
Вы можете добавить дополнительную опцию .tabset-pills после .tabset, чтобы у вкладок был “комбинированный” вид. Помните, что при рассмотрении выходных результатов в HTML с вкладками, функция поиска Ctrl+f будет искать только по “активной” вкладке, а не по скрытым вкладкам.
40.4 Структура файла
Существует несколько способов структурировать ваш R Markdown и связанные с ним скрипты R. У каждого есть свои преимущества и недостатки:
- Автономный R Markdown - все, что нужно для отчета, импортируется или создается внутри R Markdown
- Получение данных из других файлов - Вы можете выполнить внешние скрипты R с помощью команды
source()и использовать их выходные результаты в Rmd
- Дочерние скрипты - альтернативный механизм для
source()
- Получение данных из других файлов - Вы можете выполнить внешние скрипты R с помощью команды
- Использовать “файл выполнения” - Выполнять команды в скрипте R до построения R
Автономный Rmd
Для относительно простого отчета вы можете организовать свой скрипт R Markdown таким образом, чтобы он был “автономным” и не требовал других внешних скриптов.
Все, что необходимо для выполнения R Markdown, импортируется или создается в Rmd-файле, включая все фрагменты кода и загрузку пакетов. Такой “автономный” подход уместен, когда не требуется большой обработки данных (например, приводится чистый или полу-чистый файл данных) и формирование R Markdown не займет много времени.
В этом сценарии логичной организацией скрипта R Markdown может быть следующей:
- Задаются глобальные опции knitr
- Загрузка пакет
- Импорт данных
- Обработка данных
- Подготовка выходных данных (таблицы, графики и т.п.)
- Сохранение выходных данных, если нужно(.csv, .png, и т.п.)
Получение данных из других файлов
Одним из вариантов “автономного” подхода является использование фрагментов кода R Markdown в качестве “источника” (выполнения) других скриптов R. Это может сделать ваш сценарий R Markdown менее загроможденным, более простым и удобным для организации. Это также может помочь, если необходимо вывести итоговые цифры в начале отчета. При таком подходе конечный скрипт R Markdown просто объединяет предварительно обработанные результаты в документ.
Один из способов это сделать - задать скрипты R (путь к файлу и имя с разрешением) в команду базового R source().
source("your-script.R", local = knitr::knit_global())
# или sys.source("your-script.R", envir = knitr::knit_global())Обратите внимание, что при использовании source() внутри R Markdown, внешние файлы будут все еще выполняться в ходе формирования файла Rmd. Следовательно, каждый скрипт выполняется каждый раз, когда вы формируете отчет. Таким образом, наличие команд source() внутри R Markdown не ускоряет время выполнения, и не особо помогает с дебаггингом, так как созданные ошибки все еще будут напечатаны при подготовке R Markdown.
Альтернативой является использование опции child = knitr. НЕОХОДИМО ОБЪЯСНИТЬ ПОДРОБНЕЕ
Вы должны знать о разных средах R. Объекты, созданные внутри среды, не обязательно будут доступны для среды R Markdown.
Файл выполнения
Этот подход требует использования скрипта R, который содержит команду(ы) render() для предварительной обработки объектов, которые передаются в R markdown.
Например, вы можете загрузить пакеты, загрузить и вычистить данные и даже создать интересующие графики до функции render(). Эти шаги могут выполняться как в скрипте R, так и в других скриптах. Если эти команды выполняются в одной и той же сессии RStudio, а объекты сохраняются в среде, то их можно вызывать в содержимом Rmd. Тогда сам R markdown будет использоваться только на последнем этапе - для создания выходных данных со всеми предварительно обработанными объектами. Так гораздо проще отладить работу, если что-то пойдет не так.
Этот подход полезен по следующим причинам:
- Более информативные сообщения об ошибках - эти сообщения будут сгенерированы в скрипте R, а не в R Markdown. Ошибки R Markdown, как правило, сообщают, в каком фрагменте кода есть проблема, но не говорят - в какой строке.
- Если применимо, вы можете выполнить длинные шаги обработки до использования команды
render()- они будут выполнены только один раз.
В примере ниже мы отделили скрипт R, в котором мы предварительно обрабатываем объект data в среде R (Environment) и затем сформируем “create_output.Rmd”, используя render().
data <- import("datafile.csv") %>% # Загружаем данные и сохраняем в рабочую среду
select(age, hospital, weight) # выбираем ограниченное количество столбцов
rmarkdown::render(input = "create_output.Rmd") # Создаем файл RmdСтруктура папок
Рабочий поток также учитывает общую структуру папок, например, нужна папка ‘output’ для созданных документов и рисунков, папки ‘data’ или ‘inputs’ для вычищенных данных. Здесь мы не будем углубляться в детали, но проверьте страницу Структурирование рутинных отчетов.
40.5 Создание документа
Вы можете создать документ следующим образом:
- Вручную, нажав кнопку “Knit” наверху редактора скриптов RStudio (быстро и легко)
- Выполнить команду
render()(выполняется за пределами скрипта R Markdown)
Вариант 1: кнопка “Knit”
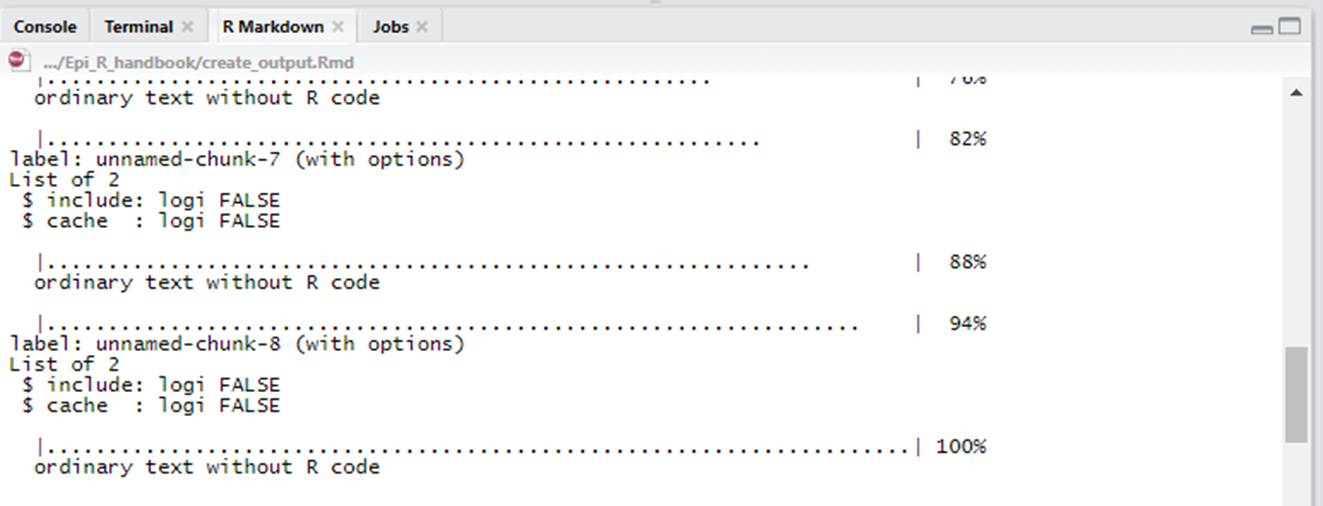
Когда у вас открыт файл Rmd, нажмите иконку/кнопку ‘Knit’ наверху файла.
R Studio покажет прогресс во вкладке ‘R Markdown’ возле консоли R. Документ автоматически откроется после завершения выполнения.
Документ будет сохранен в той же папке, что и ваш скрипт R markdown, и с тем же именем файла (кроме расширения). Это, конечно, не идеально для контроля версий (он будет перезаписываться каждый раз при формировании, если вы не переместите его вручную), поскольку вам, возможно, потребуется переименовывать файл самостоятельно (например, добавлять дату).
Это “горячая кнопка” RStudio для функции render() из rmarkdown. Этот подход совместим только с автономным R markdown, где существуют все необходимые компоненты, либо они могут быть запрошены в рамках файла.
Вариант 2: команда render()
Еще один способ создать выходные данные R Markdown - выполнить функцию render() (из пакета rmarkdown). Вы должны исполнить эту команду за пределами скрипта R Markdown - либо в отдельном R script (часто называется “файл выполнения”), либо как отдельную команду в консоли R.
rmarkdown::render(input = "my_report.Rmd")Как и с “knit”, настройки по умолчанию сохранят выходной результат в ту же папку, что скрипт Rmd, с тем же именем файла (кроме расширения файла). Например, “my_report.Rmd” при формировании создаст “my_report.docx”, если вы его формируете как документ word. Однако используя render() у вас есть опция использования разных настроек. render() может принимать аргументы, включая:
output_format =Это формат выходных данных для конвертации в (например,"html_document","pdf_document","word_document", либо"all"). Вы можете также указать это в YAML внутри скрипта R Markdown.
output_file =Это название выходного файла (и путь к файлу). Его можно создать через такие функции R, какhere()илиstr_glue()как показано ниже.
output_dir =Это выходная директория (папка) для сохранения файла. Это позволяет вам выбрать другую альтернативу, кроме директории, в которую сохраняется файл Rmd.
output_options =Вы можете задать список опций, которые будут превалировать над теми, которые записаны в YAML скрипта (например, )output_yaml =Вы можете задать путь к файлу .yml, который содержит спецификации YAML
params =См. раздел по параметрам ниже
- См. полный список тут
В качестве одного примера, чтобы улучшить контроль версий, следующая команда сохранит выходной файл в подпапке ‘outputs’ с текущей датой в имени файла. Чтобы создать имя файла, используется функция str_glue() из пакета stringr, которая ‘склеивает’ статические последовательности (написанные простым текстом) с динамическим кодом R (записанным в фигурных скобках). Например, если сегодня 10 апреля 2021, имя файла ниже будет “Report_2021-04-10.docx”. См. дополнительную информацию по str_glue() на странице Текст и последовательности.
rmarkdown::render(
input = "create_output.Rmd",
output_file = stringr::str_glue("outputs/Report_{Sys.Date()}.docx")) По мере того как файл формируется, на консоли RStudio будет показан прогресс формирвоания до 100%, а в итоговом сообщении будет написано, что формирование завершено.
Вариант 3: пакет reportfactory
Пакет R reportfactory предлагает альтернативный метод организации и формирования отчетов R Markdown, адаптированный для ситуаций, когда вам надо регулярно повторять формирование отчета (например, ежедневно, еженедельно…). Он облегчает формирование нескольких файлов R Markdown и организацию их выходных данных. По сути, он создает “фабрику”, из которой вы можете выполнить отчеты R Markdown, получить папки для выходных данных с автоматическими метками даты и времени, а также “легко” контролировать версии.
Более подробно о данном потоке работ читайте на странице Структурирование рутинных отчетов.
40.6 Параметризированные отчеты
Вы можете использовать параметризацию, чтобы сделать отчеты динамичными, чтобы их можно было выполнять с конкретными настройками (например, с конкретной датой или местом, либо с определенными вариантами формирования). Ниже мы фокусируемся на основных моментах, но имеется детальная информация онлайн о параметризированных отчетах.
Используя построчный список по Эболе в качестве примера, представим, что нам нужно выдавать стандартный отчет по эпиднадзору для каждой больницы каждый день. Мы покажем, как это можно сделать с использованием параметров.
Важно: динамические отчеты также возможны без официальной структуры параметров (без params:), используя простые объекты R в соседнем скрипте R. Это объясняется в конце данного раздела.
Установка параметров
У вас есть несколько вариантов уточнения значений параметров для выходных результатов R Markdown.
Вариант 1: Задать параметры внутри YAML
Редактируйте YAML, чтобы включить опцию params:, с утверждениями с отступом для каждого параметра, который вы хотите определить. В этом примере мы создаем параметры date (дата) и hospital (больница), для которых мы задаем значения. Эти значения будут меняться каждый раз, когда выполняется отчет. Если вы используете кнопку “Knit” для создания выходного результата, у параметров будут значения по умолчанию. Аналогично, если вы используете render(), у параметров будут эти значения по умолчанию, если в команде render() не указано иное.
---
title: Surveillance report
output: html_document
params:
date: 2021-04-10
hospital: Central Hospital
---Фоново значения этих параметров содержатся в списке только для чтения под названием params. Таким образом, вы можете вставить значения параметров в код R как вы это делаете с другим объектом/значением R в своей рабочей среде. Просто напечатайте params$, после чего укажите имя параметра. Например, params$hospital для представления названия больницы (“Central Hospital” по умолчанию).
Обратите внимание, что параметры могут также содержать значения true (истина) или false (ложь), поэтому они могут быть включены в ваши опции knitr для фрагмента R. Например, вы можете задать {r, eval=params$run} вместо {r, eval=FALSE}, и теперь то, будет ли выполняться фрагмент будет зависеть от значения параметра run:.
Обратите внимание, что параметры, которые являются датами, будут введены как последовательность. Например, чтобы params$date интерпретировался в коде R, его скорее всего нужно обернуть в as.Date() либо аналогичную функцию, чтобы конвертировать в класс Дата.
Вариант 2: задать параметры внутри render()
Как было указано выше, альтернативой использованию кнопки “Knit” для создания выходных результатов является выполнение функции render() из отдельного скрипта. В последнем случае вы можете уточнить параметры, которые должны использоваться при формировании, в аргументе params = в render().
Обратите внимание, что любые значения параметров, заданные тут, будут записаны поверх значений по умолчанию, если они записаны внутри YAML. Мы пишем значения в кавычках, так как в таком случае их следует определять как текстовые значения/последовательности.
Команда ниже формирует “surveillance_report.Rmd”, уточняет имя и папку для динамического файла-результата, а также задает список list() двух параметров и их значений в аргумент params =.
rmarkdown::render(
input = "surveillance_report.Rmd",
output_file = stringr::str_glue("outputs/Report_{Sys.Date()}.docx"),
params = list(date = "2021-04-10", hospital = "Central Hospital"))Вариант 3: задать параметры, используя графический интерфейс пользователя
Для большей интерактивности вы можете также использовать графический интерфейс пользователя, чтобы вручную установить значения параметров. Чтобы это сделать, мы можем кликнуть на выпадающее меню рядом с кнопкой ‘Knit’ и выбрать ‘Knit with parameters’.
Появится всплывающее окно, позволяющее вам впечатать значения для параметров, которые устанавливаются в YAML документа.

Вы можете добиться того же самого с помощью команды render(), указав params = "ask", как показано ниже.
rmarkdown::render(
input = "surveillance_report.Rmd",
output_file = stringr::str_glue("outputs/Report_{Sys.Date()}.docx"),
params = “ask”)Однако при вводе значений в это всплывающее окно возможны ошибки и опечатки. Возможно, вы предпочтете добавить ограничения на значения, которые можно вводить через выпадающие меню. Это можно сделать, добавив в YAML несколько спецификаций для ввода каждого параметра params:.
label:заголовок для конкретного выпадающего меню
value:значение по умолчанию (стартовое)
input:установитьselectдля выпадающего меню
choices:дать допустимые значения в выпадающем меню
Ниже эти спецификации записываются для параметра hospital.
---
title: Surveillance report
output: html_document
params:
date: 2021-04-10
hospital:
label: “Town:”
value: Central Hospital
input: select
choices: [Central Hospital, Military Hospital, Port Hospital, St. Mark's Maternity Hospital (SMMH)]
---При формировании (с помощью кнопки ‘knit with parameters’ или render()), во всплывающем окне будут выпадающие опции, из которых вы сможете выбрать.

Параметризованный пример
Следующий код создает параметры date (дата) и hospital (больница), которые используются в R Markdown как params$date и params$hospital, соответственно.
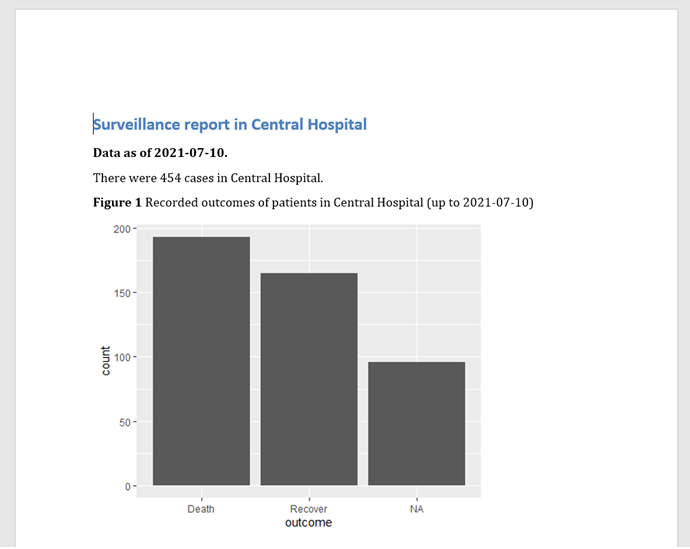
Посмотрите, как в получившемся в результате выходоном отчете данные отфильтрованы до конкретной больницы, а заголовок графика относится к правильной больнице и дате. Мы используем здесь файл “linelist_cleaned.rds”, но было бы особенно хорошо, если в самом построчном списке также был бы штамп даты, чтобы сопоставить его с параметризованной датой.

Формирование выдаст итоговый выходной результат со шрифтом и макетом по умолчанию.
Параметризация без params
Если вы формируете файл R Markdown с помощью render() из отдельного скрипта, вы можете создать действие параметризации без использования функционала params:.
Например, в скрипте R, который содержит команду render(), вы можете просто задать hospital и date как два объекта R (значения) до команды render(). В R Markdown вам не нужен раздел params: в YAML, и мы будем ссылаться на объект date, а не params$date, и hospital, а не params$hospital.
# Это скрипт R, который сделан отдельно от R Markdown
# определяем объекты R
hospital <- "Central Hospital"
date <- "2021-04-10"
# Формируем R markdown
rmarkdown::render(input = "create_output.Rmd") Если вы следуете этому подходу, вы не сможете использовать “knit with parameters”, использовать графический интерфейс пользователя или включать опции формирования (knitting) внутри параметров. Однако это облегчит код, что может иметь свои преимущества.
40.7 Зацикливаение отчетов
Нам может потребоваться выполнить отчет несколько раз, варьируя входные параметры, чтобы создавать отчет для каждой юрисдикции/единицы. Это можно сделать с помощью инструментов итерации, которые детально изучаются на странице [Итерации, циклы и списки]. Опции включают пакет purrr, либо использования циклов for, как объясняется ниже.
Ниже мы используем простой цикл for для создания отчета по эпиднадзору для всех интересующих больниц. Это делается с помощью одной команды (вместо изменения параметров больницы по одной вручную). Команда по формированию отчетов должна существовать в отдельном скрипте вне отчета Rmd. Этот скрипт будет также содержать определенные объекты для “прохождения цикла” - сегодняшнюю дату, а также вектор названий больниц, по которым должны пройти циклы.
hospitals <- c("Central Hospital",
"Military Hospital",
"Port Hospital",
"St. Mark's Maternity Hospital (SMMH)") Мы задаем эти значения по одному в команду render(), используя цикл, который выполняет команду один раз для каждого значения в векторе hospitals. Буква i представляет индексную позицию (от 1 до 4) больницы, которая в настоящий момент используется в этой итерации, так чтобы hospital_list[1] стал “Central Hospital”. Эта информация предоставляется в двух местах в команде render():
- в имя файла, чтобы имя файла первой итерации, если он создается 10 апреля 2021 года, было “Report_Central Hospital_2021-04-10.docx”, сохранялось в подпапке ‘output’ рабочей директории.
- в
params =, чтобы Rmd использовал имя больницы на внутреннем уровне, когда вызывается значениеparams$hospital(например, чтобы отфильтровать набор данных только до конкретных больниц). В этом примере создается 4 файла - по одному для каждой больницы.
for(i in 1:length(hospitals)){
rmarkdown::render(
input = "surveillance_report.Rmd",
output_file = str_glue("output/Report_{hospitals[i]}_{Sys.Date()}.docx"),
params = list(hospital = hospitals[i]))
} 40.8 Шаблоны
Используя шаблонный документ, содержащий любое желаемое форматирование, можно настроить эстетику внешнего вида выходного Rmd-файла. Например, можно создать файл MS Word или Powerpoint, содержащий страницы/слайды с нужными размерами, водяными знаками, фоном и шрифтами.
Документы Word
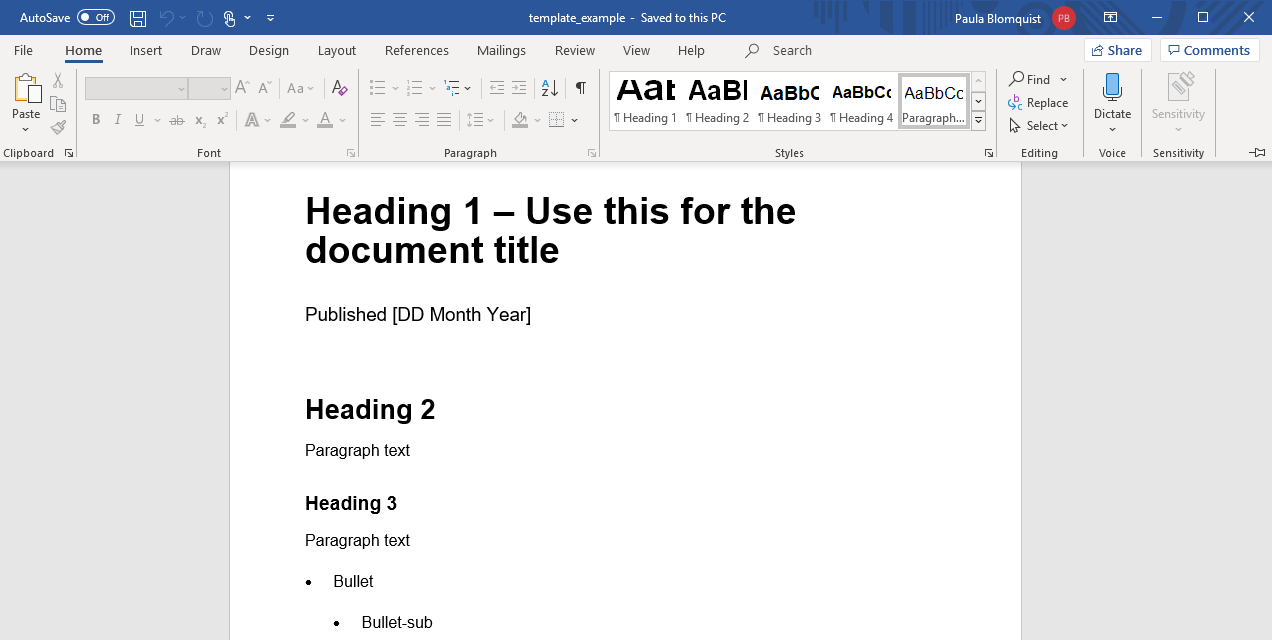
Чтобы создать шаблон, создаем новый документ word (или используем существующий выходной результат с подходящим форматированием) и редактируем шрифты, задав их в Стиле. В Стиле, заголовок 1, 2 и 3 относятся к разным уровням заголовков markdown (# Header 1, ## Header 2 и ### Header 3 соответственно). Правой кнопкой мыши кликните на стиль и кликните ‘изменить’, чтобы изменить форматирование шрифта и абзаца (например, вы можете ввести разрывы страниц перед определенным стилем, что поможет с наличием пространства). Другие аспекты документа word, такие как границы, размер страницы, заголовки и т.п. можно менять как в обычном документе word, в котором вы напрямую работаете.
Документы Powerpoint
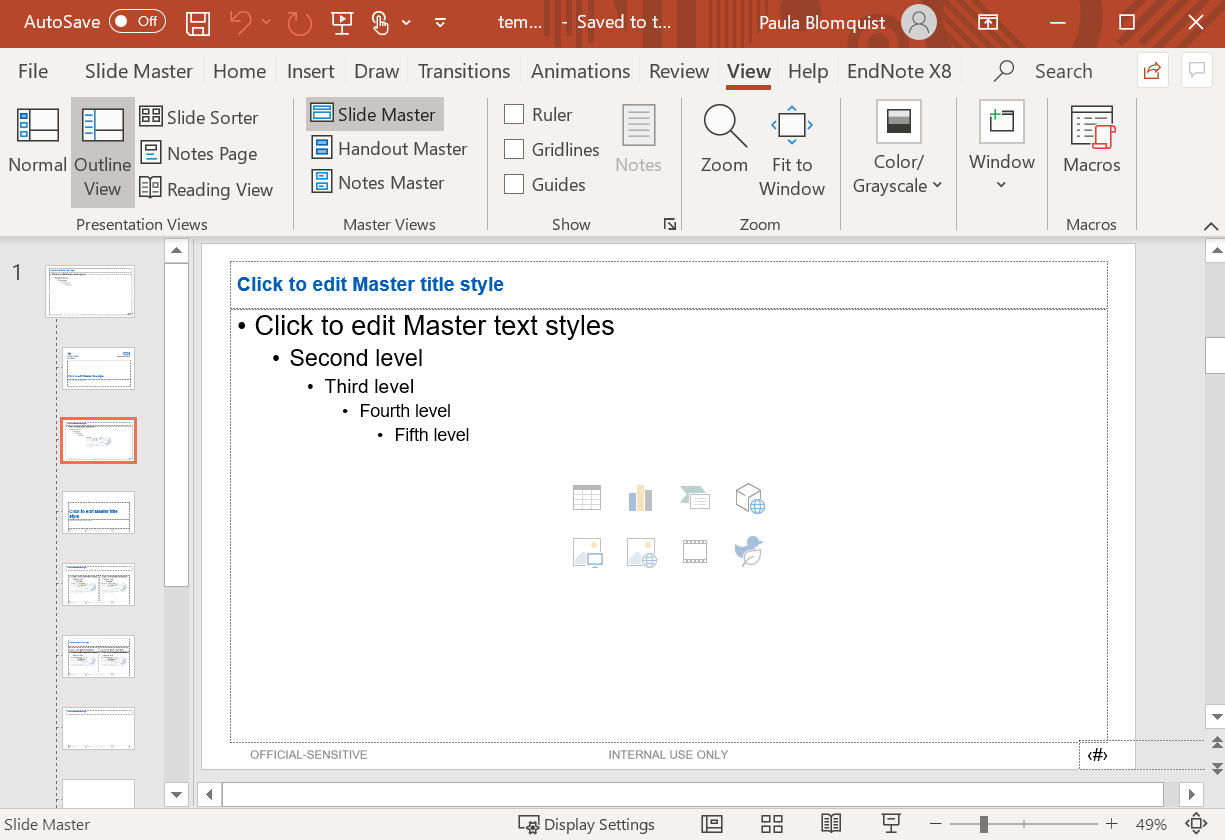
Как и выше, создаем новую презентацию или используем существующий файл powerpoint с нужным форматированием. Для дополнительного редактирования кликните на ‘Вид’ и ‘Образец слайдов’. Оттуда вы можете менять вид ‘мастер’ слайда, редактируя форматирование текста в текстовых полях, а также фон/размер страницы для всей страницы.
К сожалению редактировать файлы powerpoint можно менее гибким образом:
- Заголовок первого уровня (
# Header 1) автоматически станет заголовком нового слайда, - Текст
## Заголовка 2не будет отображен как подзаголовок, а будет текстом внутри основного текстового поля слайда (если вы только не найдете способ манипуляции с образцом слайдов). - Полученные выходные графики и таблицы автоматически перейдут на новые слайды. Вам нужно будет их объединять, например, с помощью функции patchwork по комбинированию ggplots, чтобы они отображались на одной странице. См. этот пост в блоге об использовании пакета patchwork для размещения нескольких картинок на одном слайде.
См. пакет officer, который является инструментом для более глубокой работы с презентациями powerpoint.
Интеграция шаблонов в YAML
Как только шаблон подготовлен, его детали можно добавить в YAML в Rmd под строкой ‘output’ и под указанием типа документа (который сам переходит на отдельную строку). Обратите внимание, что для шаблонов слайдов powerpoint можно использовать reference_doc.
Проще всего сохранить шаблон в той же папке, где находится файл Rmd (как в примере ниже), или внутри подпапки в ней.
---
title: Surveillance report
output:
word_document:
reference_docx: "template.docx"
params:
date: 2021-04-10
hospital: Central Hospital
template:
---Форматирование файлов HTML
Файлы HTML не используют шаблоны, но могут содержать конфигурацию стилей внутри YAML. HTML - интерактивные документы, они особенно гибкие. Здесь мы разберем некоторые основные опции.
Оглавление: Мы можем добавить оглавление с помощью
toc: trueниже, и также уточнить, что оно остается видимым (“плавает”), когда вы пролистываете, с помощьюtoc_float: true.Темы: Мы можем сослаться на некоторые предварительно разработанные темы, которые мы получаем из библиотеки тем Bootswatch. В примере ниже мы используем cerulean (синюю). Другие варианты включают: journal, flatly, darkly, readable, spacelab, united, cosmo, lumen, paper, sandstone, simplex и yeti.
Выделение: Эта конфигурация меняет вид выделенного текста (например, кода во фрагментах, которые показаны). Поддерживаемые стили включают default, tango, pygments, kate, monochrome, espresso, zenburn, haddock, breezedark, и textmate.
Вот пример того, как интегрировать указанные выше опции в YAML.
---
title: "HTML example"
output:
html_document:
toc: true
toc_float: true
theme: cerulean
highlight: kate
---Ниже приведены два примера выходных результатов в HTML, у обоих из которых плавающее оглавление, но разные темы и стили выделения:

40.9 Динамическое содержимое
В выходном результате в формате HTML ваше содержимое отчета может быть динамичным. Ниже приведены некоторые примеры:
Таблицы
В отчете в формате HTML вы можете печатать датафрейм/таблицы tibble таким образом, что содержимое будет динамическим с фильтрами и полосами прокрутки. Существует несколько пакетов, которые дают такие возможности.
Чтобы это сделать с помощью пакета DT, как это сделано в данном руководстве, вы можете вставить фрагмент кода следующим образом:

Функция datatable() напечатает заданный датафрейм как динамическую таблицу для читателя. Вы можете установить rownames = FALSE, чтобы упростить дальнюю левую сторону таблицы. filter = "top" создает фильтр над каждым столбцом. В аргументе option() задайте список других спецификаций. Ниже мы включаем две: pageLength = 5 устанавливает количество видимых строк на уровне 5 (остальные строки можно увидеть, перейдя по стрелкам на следующую страницу), а scrollX=TRUE активирует полосу прокрутки внизу таблицы (для столбцов, которые уходят вправо).
Если у вас очень большой набор данных, рассмотрите возможность показать только топ X строк, обернув датафрейм в head().
HTML виджеты
Виджеты HTML для R - особый класс пакетов R, который позволяет увеличить интерактивность с помощью использования библиотек JavaScript. Вы можете их интегрировать в выходной HTML файл R Markdown.
Некоторые частые примеры виджетов включают:
- Plotly (используется в данном руководстве на этой странице и странице Интерактивные графики)
- visNetwork (используется на странице руководства Цепочки распространения)
- Leaflet (используется на странице руководства Основы ГИС)
- dygraphs (полезен для интерактивного отображения данных временных рядов)
- DT (
datatable()) (используется, чтобы показать динамические таблицы с фильтром, сортировкой и т.п.)
Функцию ggplotly() из plotly особенно легко использовать. См. страницу Интерактивные графики.
40.10 Ресурсы
Дополнительная информация:
- https://bookdown.org/yihui/rmarkdown/
- https://rmarkdown.rstudio.com/articles_intro.html
Хорошее объяснение markdown в сравнении с knitr в сравнении с Rmarkdown есть тут: https://stackoverflow.com/questions/40563479/relationship-between-r-markdown-knitr-pandoc-and-bookdown