
11 Факторы
В R факторы - это класс данных, которые позволяют создавать упорядоченные категории с фиксированным набором приемлемых значений.
Как правило, вам нужно конвертировать столбец из текстового или числового класса в фактор, если вы хотите задать предопределенный порядок значений (“уровни”), чтобы они отображались не в алфавитном порядке в графиках и таблицах. Еще одно частое применение факторов - стандартизация легенд графиков, чтобы они не изменялись, если какие-то значения временно отсутствуют в данных.
На данной странице показано использование функций из пакета forcats (сокращение от “For categorical variables” (для категориальных переменных)) и некоторых функций базового R. Мы также упомянем использование lubridate и aweek для особых случаев факторов, связанных с эпидемиологическими неделями.
Полный список функций forcats можно найти онлайн тут. Ниже мы продемонстрируем наиболее частые случаи применения.
11.1 Подготовка
Загрузка пакетов
Данный фрагмент кода показывает загрузку пакетов, необходимых для анализа. В данном руководстве мы фокусируемся на использовании p_load() из пакета pacman, которая устанавливает пакет, если необходимо, и загружает его для использования. Вы можете также загрузить установленные пакеты с помощью library() из базового R. См. страницу Основы R для получения дополнительной информации о пакетах R.
pacman::p_load(
rio, # импорт/экспорт
here, # пути к файлу
lubridate, # работа с датами
forcats, # факторы
aweek, # создание эпиднедель с автоматическими уровнями факторов
janitor, # таблицы
tidyverse # управление данными и визуализация
)Импорт данных
Мы импортируем набор данных о случаях из имитационной эпидемии Эболы. Если вы хотите выполнять шаги параллельно, кликните, чтобы скачать “чистый” построчный список (as .rds file). Импортируйте ваши данные с помощью функции import() из пакета rio (она работает с многими типами файлов, такими как .xlsx, .rds, .csv - см. страницу Импорт и экспорт для получения детальной информации).
# импорт вашего набора данных
linelist <- import("linelist_cleaned.rds")Новая категориальная переменная
Для демонстрации на этой странице мы будем использовать часто встречающийся сценарий - создание новой категориальной переменной.
Обратите внимание, что если вы конвертируете числовой столбец в класс фактор, вы не сможете рассчитывать числовую статистику по этому столбцу.
Создание столбца
Мы используем существующий столбец days_onset_hosp (дней с момента появления симптомов до госпитализации) и создаем новый столбец delay_cat путем классификации каждой строки в одну из нескольких категорий. Мы это делаем с помощью функции case_when() из dplyr, которая последовательно применяет логические критерии (правая сторона) к каждой строке и выдает соответствующее значение с левой стороны для нового столбца delay_cat. Более детально о case_when() вы можете почитать на странице Вычистка данных и ключевые функции.
linelist <- linelist %>%
mutate(delay_cat = case_when(
# критерии # новое значение, если TRUE (истина)
days_onset_hosp < 2 ~ "<2 days",
days_onset_hosp >= 2 & days_onset_hosp < 5 ~ "2-5 days",
days_onset_hosp >= 5 ~ ">5 days",
is.na(days_onset_hosp) ~ NA_character_,
TRUE ~ "Check me")) Порядок значений по умолчанию
Так как новый столбец delay_cat создан с помощью case_when(), он будет категориальным столбцом в текстовом классе - а не фактором. Таким образом, в частотной таблице мы увидим, что уникальные значения появляются в алфавитно-числовом порядке по умолчанию - этот порядок не имеет особого интуитивного смысла:
table(linelist$delay_cat, useNA = "always")
<2 days >5 days 2-5 days <NA>
2990 602 2040 256 Аналогично, если мы будем создавать столбчатую диаграмму, значения также появятся в этом порядке на оси x (см. страницу [основы ggplot] для получения более подробной информации о ggplot2 - наиболее часто используемом пакете для визуализации в R).
ggplot(data = linelist)+
geom_bar(mapping = aes(x = delay_cat))
11.2 Конвертация в фактор
Чтобы конвертировать текстовый или числовой столбец в класс фактор, вы можете использовать любую функцию из пакета forcats (многие детально рассматриваются ниже). Они конвертируют в класс фактор и затем также проводят или допускают определенное упорядочивание уровней - например, использование fct_relevel() позволяет вам вручную указать порядок уровней. Функция as_factor() просто конвертирует класс без дополнительных возможностей.
базовая функция R factor() конвертирует столбец в фактор и позволяет вам вручную указать порядок уровней, как текстовый вектор в аргументе levels =.
Ниже мы используем mutate() и fct_relevel(), чтобы конвертировать столбец delay_cat из текстового класса в фактор. Столбец delay_cat был создан в разделе Подготовка выше.
linelist <- linelist %>%
mutate(delay_cat = fct_relevel(delay_cat))Уникальные “значения” в данном столбце теперь считаются “уровнями” фактора. Уровни имеют порядок, который можно напечатать с помощью функции базового R levels(), либо альтернативно можно просмотреть в таблице подсчета через table() из базового R или tabyl() из janitor. По умолчанию порядок уровней будет алфавитно-числовым, как ранее. Обратите внимание, что NA не является уровнем фактора.
levels(linelist$delay_cat)[1] "<2 days" ">5 days" "2-5 days"Функция fct_relevel() имеет дополнительный функционал, поскольку позволяет вам вручную указать порядок уровней. Просто запишите значения уровня в нужном порядке в кавычках, разделенные запятыми, как показано ниже. Обратите внимание, что правописание должно быть идентичным значениям. Если вы хотите создать уровни, которые не существуют в данных, используйте вместо этого fct_expand()).
linelist <- linelist %>%
mutate(delay_cat = fct_relevel(delay_cat, "<2 days", "2-5 days", ">5 days"))Теперь мы видим, что уровни упорядочены, как указано в предыдущей команде, в понятном порядке.
levels(linelist$delay_cat)[1] "<2 days" "2-5 days" ">5 days" Теперь порядок в графике имеет более интуитивно-понятный смысл.
ggplot(data = linelist)+
geom_bar(mapping = aes(x = delay_cat))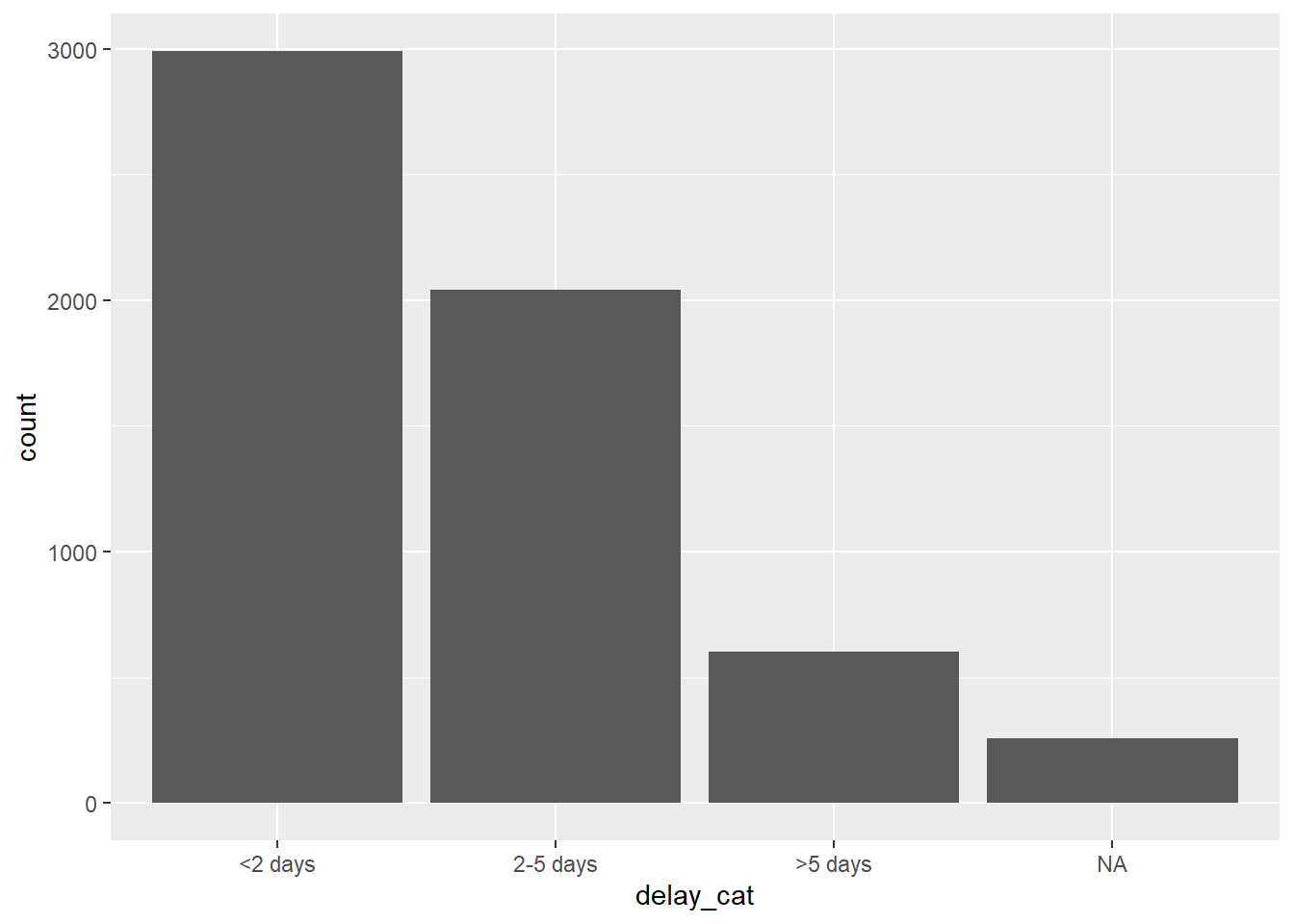
11.3 Добавление или удаление уровней
Добавление
Если вам нужно добавить уровни к фактору, вы это можете сделать с помощью fct_expand(). Просто напишите название столбца, после которого идут новые уровни (разделенные запятыми). С помощью табулирования значений мы можем увидеть новые уровни и количество ноль. Вы можете использовать table() из базового R, либо tabyl() из janitor:
linelist %>%
mutate(delay_cat = fct_expand(delay_cat, "Not admitted to hospital", "Transfer to other jurisdiction")) %>%
tabyl(delay_cat) # печать таблицы delay_cat n percent valid_percent
<2 days 2990 0.50781250 0.5308949
2-5 days 2040 0.34646739 0.3622159
>5 days 602 0.10224185 0.1068892
Not admitted to hospital 0 0.00000000 0.0000000
Transfer to other jurisdiction 0 0.00000000 0.0000000
<NA> 256 0.04347826 NAПримечание: существует специальная функция forcats, чтобы легко добавить отсутствующие значения (NA) в качестве уровня. См. раздел Отсутствующие значения ниже.
Удаление
Если вы используете fct_drop(), “неиспользованные” уровни с нулевым количеством будут удалены из набора уровней. Уровень, который мы добавили выше (“Not admitted to a hospital”), существует в качестве уровня, но ни в одной из строк на самом деле нет таких значений. Поэтому они будут удалены при применении fct_drop() к столбцу фактор:
linelist %>%
mutate(delay_cat = fct_drop(delay_cat)) %>%
tabyl(delay_cat) delay_cat n percent valid_percent
<2 days 2990 0.50781250 0.5308949
2-5 days 2040 0.34646739 0.3622159
>5 days 602 0.10224185 0.1068892
<NA> 256 0.04347826 NA11.4 Корректировка порядка уровней
Пакет forcats предлагает полезные функции, чтобы легко скорректировать порядок уровней фактора (после того, как столбец определен как класс фактор):
Эти функции можно применить к столбцу фактор в двух контекстах:
- К столбцу датафрейма, как обычно, чтобы трансформация была доступна при последующем использовании данных
- Внутри графика, чтобы это изменение применялось только к этому графику
Вручную
Эта функция используется, чтобы вручную упорядочить уровни факторов. При использовании для столбца, который не относится к классу фактор, столбец сначала нужно конвертировать в класс фактор.
В скобках сначала укажите имя столбца фактора, затем укажите:
- Либо все уровни в желаемом порядке (как текстовый вектор
c()),
- Либо один уровень и его правильное размещение, используя аргумент
after =
Вот пример переопределения столбца delay_cat (который уже в классе Фактор) и уточнения желаемого порядка всех уровней.
# переопределение порядка уровней
linelist <- linelist %>%
mutate(delay_cat = fct_relevel(delay_cat, c("<2 days", "2-5 days", ">5 days")))Если вы хотите передвинуть только один уровень, вы можете его уточнить с помощью fct_relevel() отдельно и задать цифру в аргументе after =, чтобы указать, где в порядке он должен быть. Например, команда ниже сдвигает “<2 days” на вторую позицию:
# переопределение порядка уровней
linelist %>%
mutate(delay_cat = fct_relevel(delay_cat, "<2 days", after = 1)) %>%
tabyl(delay_cat)В графике
Команды forcats могут быть использованы, чтобы задать порядок уровней в датафрейме, либо только на графике. Используя команду, чтобы “обернуть” имя столбца внутри команды построения графика ggplot(), вы можете поменять порядок/уровень и трансформация будет применена только на этом графике.
Ниже мы создаем два графика с помощью ggplot() (см. страницу [Основы ggplot]). В первом, столбец delay_cat откладывается на оси x графика, с порядком уровней по умолчанию, как в данных linelist. Во втором примере, он обернут в fct_relevel(), и порядок меняется на графике.
# Алфавитно-цифровой порядок по умолчанию - без корректировки в ggplot
ggplot(data = linelist)+
geom_bar(mapping = aes(x = delay_cat))
# Порядок уровней фактора корректируется в рамках ggplot
ggplot(data = linelist)+
geom_bar(mapping = aes(x = fct_relevel(delay_cat, c("<2 days", "2-5 days", ">5 days"))))

Обратите внимание, что подпись оси x по умолчанию теперь выглядит достаточно сложно - вы можете ее изменить с помощью аргумента labs() в ggplot2.
Обратный порядок
Достаточно часто вам может потребоваться обратный порядок уровней. Просто оберните фактор в fct_rev().
Обратите внимание, что если вы хотите получить обратный порядок только в легенде графика, но не хотите менять сами уровни фактора, вы можете это сделать с помощью guides() (см. [советы по использованию ggplot]).
По частоте
Чтобы упорядочить по частоте возникновения значения в данных, используйте fct_infreq(). Любые отсутствующие значения (NA) будут автоматически включены в конце, если только они не конвертированы в конкретный уровень (см. этот раздел). Вы можете создать обратный порядок, дополнительно обернув в fct_rev().
Эту функцию можно использовать в рамках ggplot(), как показано ниже.
# упорядочивание по частоте
ggplot(data = linelist, aes(x = fct_infreq(delay_cat)))+
geom_bar()+
labs(x = "Delay onset to admission (days)",
title = "Ordered by frequency")
# обратная частота
ggplot(data = linelist, aes(x = fct_rev(fct_infreq(delay_cat))))+
geom_bar()+
labs(x = "Delay onset to admission (days)",
title = "Reverse of order by frequency")
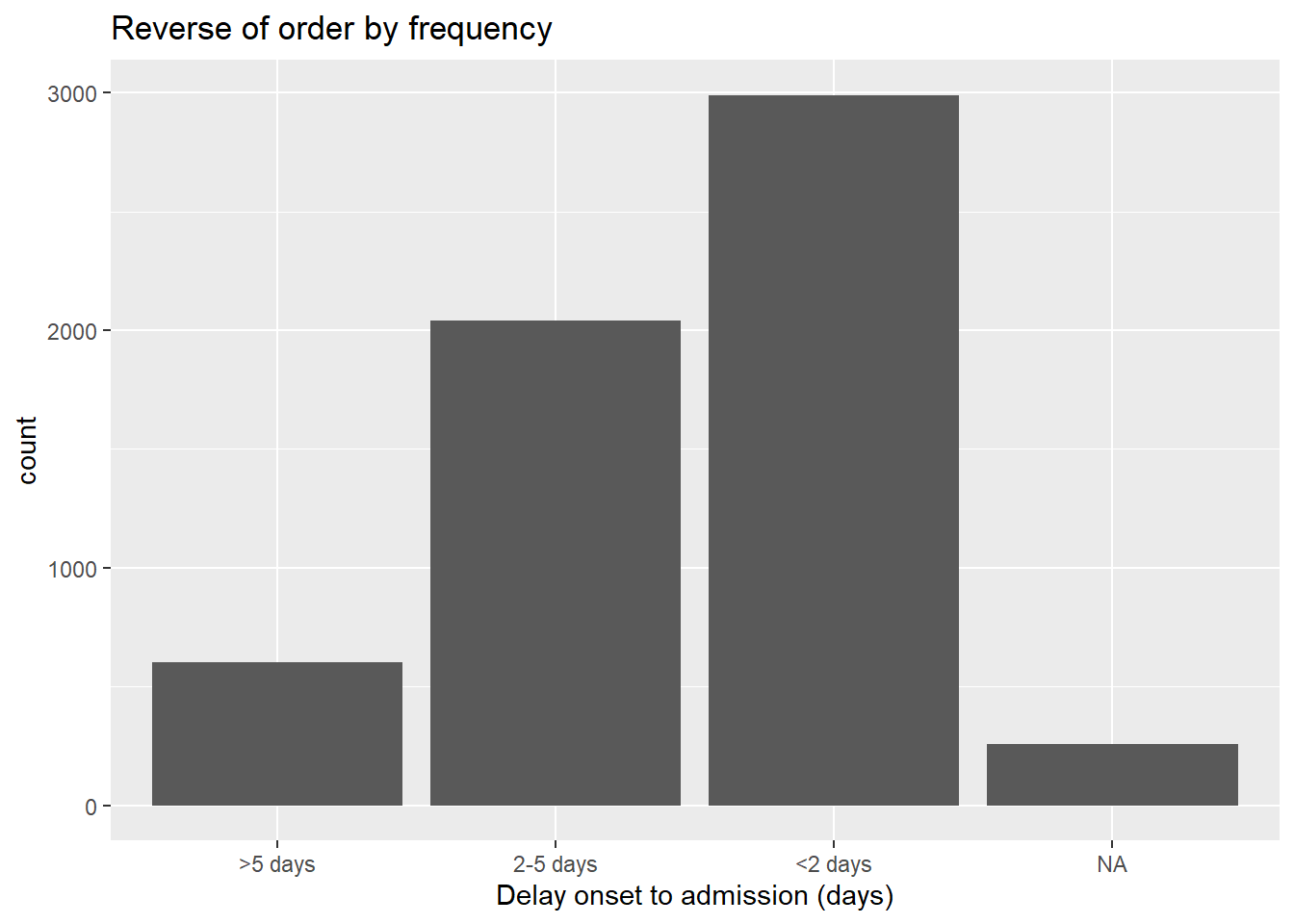
По порядку появления
Используйте fct_inorder(), чтобы установить порядок уровней в соответствии с порядком появления в данных, начиная с первой строки. Это может быть полезно, если вы сначала тщательно упорядочили данные в датафрейме с помощью arrange(), а затем используете это для определения порядка факторов.
По сводной статистике другого столбца
Вы можете использовать fct_reorder(), чтобы упорядочить уровни одного столбца по сводной статистике другого столбца. Визуально это может создать красивые графики, где столбцы/точки расположены в возрастающем или убывающем порядке на графике.
В примерах ниже ось х - это delay_cat, а ось y числовой столбец ct_blood (значение порогового цикла). Коробчатая диаграмма показывает распределение значения CT (порогового цикла) по группам delay_cat. Мы хотим упорядочить коробчатые диаграммы в возрастающем порядке по медианному значению CT в группе.
В первом примере ниже используется алфавитно-числовой порядок уровней по умолчанию. Вы можете видеть, что высота коробчатой диаграммы смешана, в ней нет определенного порядка. Во втором примере столбец delay_cat (отложенный на оси x) обернут в fct_reorder(), столбец ct_blood указан как второй аргумент, а “median” (медиана) задана в качестве третьего аргумента (вы можете также использовать “max” (максимум), “mean” (среднее), “min” (минимум) и т.п.). Таким образом порядок уровней delay_cat теперь будет отражать медиану значений CT в возрастающем порядке для медианных значений CT каждой группы delay_cat. Это отражается на втором графике - коробчатая диаграмма была упорядочена по возрастанию. Обратите внимание, что NA (отсутствующие значения) будут показаны в конце, если они не конвертированы в конкретный уровень.
# коробчатая диаграмма упорядочена по оригинальным уровням фактора
ggplot(data = linelist)+
geom_boxplot(
aes(x = delay_cat,
y = ct_blood,
fill = delay_cat))+
labs(x = "Delay onset to admission (days)",
title = "Ordered by original alpha-numeric levels")+
theme_classic()+
theme(legend.position = "none")
# коробчатая диаграмма упорядочена по медианному значению CT
ggplot(data = linelist)+
geom_boxplot(
aes(x = fct_reorder(delay_cat, ct_blood, "median"),
y = ct_blood,
fill = delay_cat))+
labs(x = "Delay onset to admission (days)",
title = "Ordered by median CT value in group")+
theme_classic()+
theme(legend.position = "none")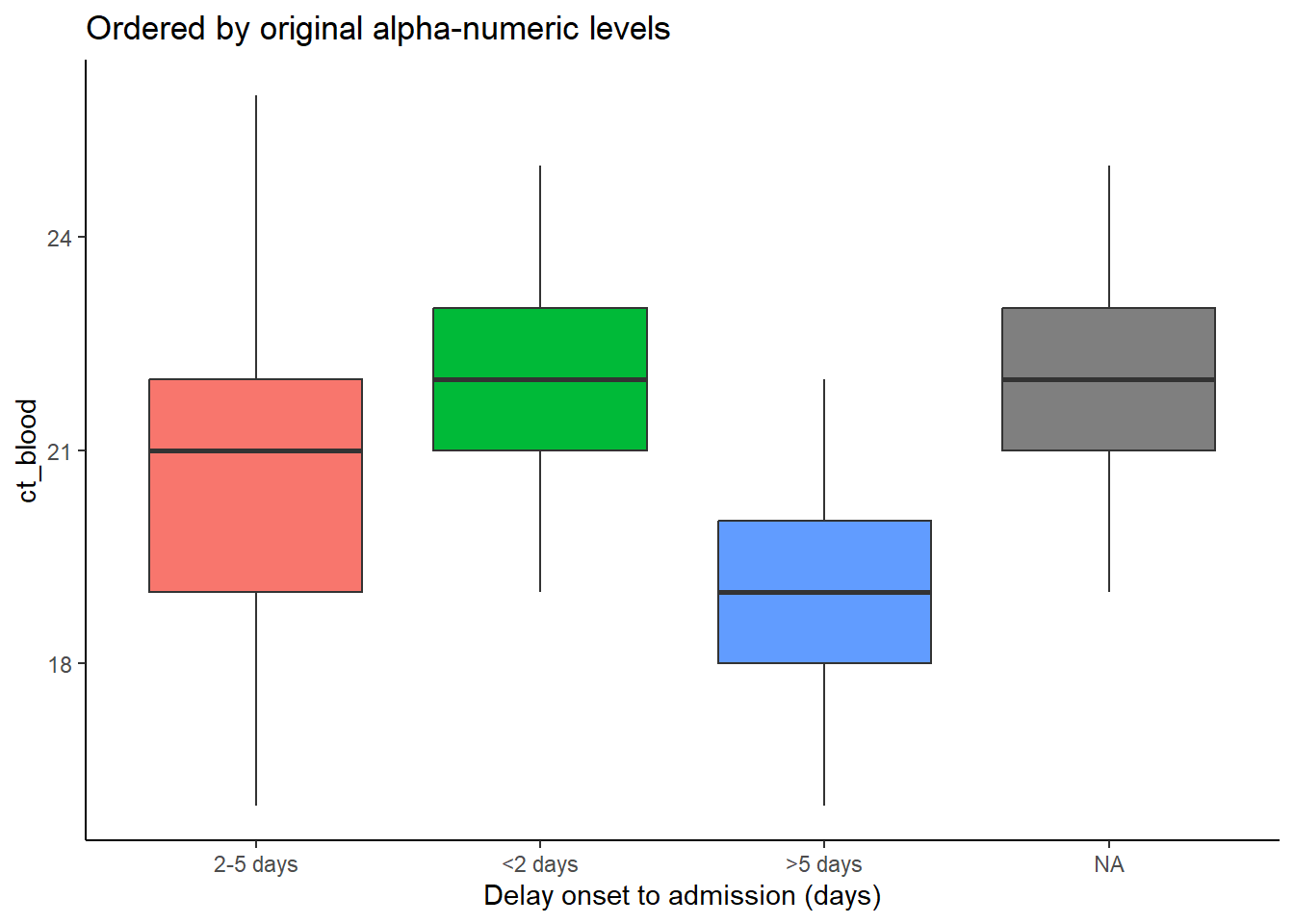

Обратите внимание, что не требуется шагов до ggplot() - группирование и расчеты делаются внутри команды ggplot.
По “конечному” значению
Используйте fct_reorder2() для сгруппированных линейных диаграмм. Она упорядочивает уровни (и следовательно, легенду) так, чтобы организовать вертикальный порядок линий в “конце” графика. Технически, “упорядочивание идет по значениям на оси y, связанным с самыми высокими значениями x.”
Например, если у вас линии показывают количество случаев по больницам по времени, вы можете применить fct_reorder2() к аргументу color = в рамках aes(), так чтобы вертикальный порядок больниц, появляющийся в легенде, совпадал с порядком линий в конце графика. Более детально читайте в онлайн документации.
epidemic_data <- linelist %>% # начинаем с построчного списка
filter(date_onset < as.Date("2014-09-21")) %>% # пороговая дата для визуальной ясности
count( # получаем количество случаев по неделям и по больницам
epiweek = lubridate::floor_date(date_onset, "week"),
hospital
)
ggplot(data = epidemic_data)+ # начинаем построение графика
geom_line( # создаем линии
aes(
x = epiweek, # ось x эпиднеделя
y = n, # высота - количество случаев в неделю
color = fct_reorder2(hospital, epiweek, n)))+ # данные группируются и окрашиваются по больницам, а фактор упорядочен по высоте в конце графика
labs(title = "Factor levels (and legend display) by line height at end of plot",
color = "Hospital") # изменяем заголовок легенды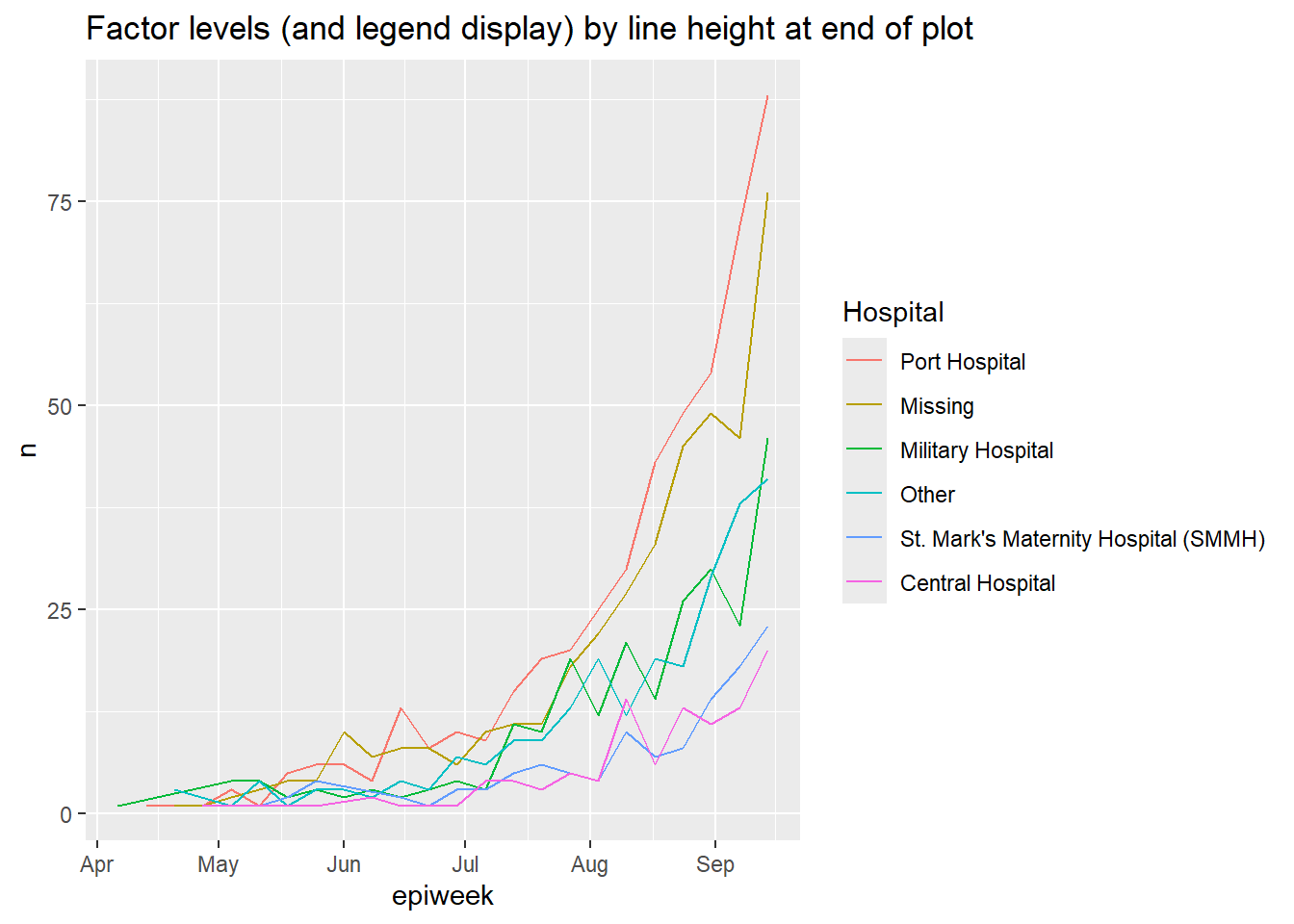
11.5 Отсутствующие значения
Если в вашем столбце фактора есть значения NA, вы с легкостью можете их конвертировать в именованный уровень, например, “Missing” с помощью fct_explicit_na(). Значения NA конвертируются в “(Missing)” в конце порядка уровней по умолчанию. Вы можете откорректировать имя уровня с помощью аргумента na_level =.
Ниже мы проводим эту операцию для столбца delay_cat и печатаем таблицу с помощью tabyl(), а NA конвертируются в “Missing delay”.
linelist %>%
mutate(delay_cat = fct_explicit_na(delay_cat, na_level = "Missing delay")) %>%
tabyl(delay_cat)Warning: There was 1 warning in `mutate()`.
ℹ In argument: `delay_cat = fct_explicit_na(delay_cat, na_level = "Missing
delay")`.
Caused by warning:
! `fct_explicit_na()` was deprecated in forcats 1.0.0.
ℹ Please use `fct_na_value_to_level()` instead. delay_cat n percent
2-5 days 2040 0.34646739
<2 days 2990 0.50781250
>5 days 602 0.10224185
Missing delay 256 0.0434782611.6 Объединение уровней
Вручную
Вы можете откорректировать отображения уровней вручную с помощью fct_recode(). Это похоже на функцию recode() в dplyr (см. страницу [Вычистка данных и ключевые функции]), но она позволяет создавать новые уровни факторов. Если вы используете просто recode() для фактора, новые перекодированные значения будут отклонены, если только они не заданы как разрешенные уровни.
Этот инструмент можно также использовать для “объединения” уровней, путем присваивания нескольким уровням одинакового перекодированного значения. Просто будьте осторожны, чтобы не потерять информацию! Попробуйте выполнить эти шаги объединения в новом столбце (вместо того, чтобы переделывать существующий столбец).
fct_recode() имеет иной синтаксис, чем recode(). recode() использует СТАРЫЙ = НОВЫЙ, а fct_recode() использует НОВЫЙ = СТАРЫЙ.
Текущие уровни delay_cat:
levels(linelist$delay_cat)[1] "<2 days" "2-5 days" ">5 days" Новые уровни создаются с помощью синтаксиса fct_recode(столбец, "новый" = "старый", "новый" = "старый", "новый" = "старый") и печатаются:
linelist %>%
mutate(delay_cat = fct_recode(
delay_cat,
"Less than 2 days" = "<2 days",
"2 to 5 days" = "2-5 days",
"More than 5 days" = ">5 days")) %>%
tabyl(delay_cat) delay_cat n percent valid_percent
Less than 2 days 2990 0.50781250 0.5308949
2 to 5 days 2040 0.34646739 0.3622159
More than 5 days 602 0.10224185 0.1068892
<NA> 256 0.04347826 NAЗдесь они вручную объединяются с помощью fct_recode(). Обратите внимание, что не возникает ошибки при создании нового уровня “Less than 5 days”.
linelist %>%
mutate(delay_cat = fct_recode(
delay_cat,
"Less than 5 days" = "<2 days",
"Less than 5 days" = "2-5 days",
"More than 5 days" = ">5 days")) %>%
tabyl(delay_cat) delay_cat n percent valid_percent
Less than 5 days 5030 0.85427989 0.8931108
More than 5 days 602 0.10224185 0.1068892
<NA> 256 0.04347826 NAСвертывание в “Прочие”
Вы можете использовать fct_other(), чтобы вручную присвоить уровни фактора к уровню “Other” (прочие). Ниже все уровни столбца hospital, кроме “Port Hospital” и “Central Hospital”, объединяются в “Other” (прочие). Вы можете задать вектор либо для keep =, либо drop =. Вы можете изменить отображение уровня “Other” с помощью other_level =.
linelist %>%
mutate(hospital = fct_other( # корректируем уровни
hospital,
keep = c("Port Hospital", "Central Hospital"), # эти оставляем отдельно
other_level = "Other Hospital")) %>% # все прочие идут в "Other Hospital"
tabyl(hospital) # печать таблицы hospital n percent
Central Hospital 454 0.07710598
Port Hospital 1762 0.29925272
Other Hospital 3672 0.62364130Свертывание по частоте
Вы можете объединять наименее часто встречающиеся уровни факторов автоматически, используя fct_lump().
Чтобы объединить несколько уровней с низкой частотой в группу “Other” (прочие), выполните одно из следующих действий:
- Задайте
n =как число групп, которые вы хотите сохранить. n количество наиболее часто встречающихся уровней будет сохранено, а все остальные будут объединены в “Other” (прочие).
- Задайте
prop =как порог доли частоты для уровней, выше которого вы хотите сохранить уровни. Все остальные значения будут объединены в “Other” (прочие).
Вы можете изменить отображение уровня “Other” с помощью other_level =. Ниже все больницы, кроме двух встречающихся наиболее часто, объединены в “Other Hospital” (прочие больницы).
linelist %>%
mutate(hospital = fct_lump( # корректируем уровни
hospital,
n = 2, # сохраняем 2 верхних уровня
other_level = "Other Hospital")) %>% # все другие идут в "Other Hospital"
tabyl(hospital) # печать таблицы hospital n percent
Missing 1469 0.2494905
Port Hospital 1762 0.2992527
Other Hospital 2657 0.4512568, warn ## Показать все уровни
Одно из преимуществ использования факторов - стандартизировать вид легенд графиков и таблиц, вне зависимости от того, какие значения собственно присутствуют в наборе данных.
Если вы готовите много рисунков (например, по множеству юрисдикций), вам нужно, чтобы легенды и таблицы выглядели идентично даже при разных уровнях полноты и состава данных.
На графиках
На рисунке ggplot() просто добавьте аргумент drop = FALSE в соответствующей функции scale_xxxx(). Все уровни факторов будут отображены, вне зависимости от того, присутствуют ли они в данных. Если ваши уровни столбца фактора отображены с помощью fill =, тогда в scale_fill_discrete() вам нужно включить drop = FALSE, как показано ниже. Если ваши уровни отображены с помощью x = (по оси x) color = или size = задайте этот аргумент в scale_color_discrete() или scale_size_discrete(), соответственно.
В данном примере мы строим столбчатую диаграмму с накоплением возрастных категорий по больницам. Добавление scale_fill_discrete(drop = FALSE) гарантирует, что все возрастные группы отобразятся в легенде, даже если их нет в данных.
ggplot(data = linelist)+
geom_bar(mapping = aes(x = hospital, fill = age_cat)) +
scale_fill_discrete(drop = FALSE)+ # покажет все возрастные группы в легенде, даже если их нет
labs(
title = "All age groups will appear in legend, even if not present in data")
В таблицах
Как функция table() из базового R, так и tabyl() из janitor покажет все уровни факторов (даже неиспользуемые уровни).
Если вы используете count() или summarise() из dplyr, чтобы создать таблицу, добавьте аргумент .drop = FALSE, чтобы включить подсчет количества всех уровней фактора, даже не используемых.
Читайте дополнительную информацию на странице [Описательные таблицы], либо документацию scale_discrete, либо документацию count(). См. еще один пример на странице [Отслеживание контактов].
11.7 Эпиднедели
Пожалуйста, см. детальное обсуждение того, как создавать эпидемиологические недели на странице [Группирование данных].
Также см. страницу [Работа с датами] для получения советов по тому, как создавать и форматировать эпидемиологические недели.
Эпиднедели на графике
Если ваша цель - создать эпиднедели для отображения на графике, вы можете это сделать с помощью floor_date() из lubridate, как объясняется на странице [Группирование данных]. Выданные значения будут в классе Дата в формате ГГГГ-ММ-ДД. Если вы используете этот столбец в графике, даты будут естественным образом отображены правильно, и вам нет необходимости переживать об уровнях или конвертации в класс Фактор. См. гистограмму ggplot() дат заболевания ниже.
В данном подходе вы можете откорректировать отображение дат на оси с помощью scale_x_date(). См. страницу [Эпидемические кривые] для получения более детальной информации. Вы можете уточнить формат отображения “strptime” в аргументе date_labels = в scale_x_date(). Эти форматы используют заполнители “%” и рассматриваются на странице [Работа с датами]. Используйте “%Y”, чтобы представить 4-значный год, и либо “%W”, либо “%U”, чтобы отобразить номер недели (недели с понедельника или воскресенья, соответственно).
linelist %>%
mutate(epiweek_date = floor_date(date_onset, "week")) %>% # создаем столбец недель (week)
ggplot()+ # начинаем ggplot
geom_histogram(mapping = aes(x = epiweek_date))+ # гистограмма по дате заболевания
scale_x_date(date_labels = "%Y-W%W") # корректируем отображение дат в формат ГГГГ-Ннн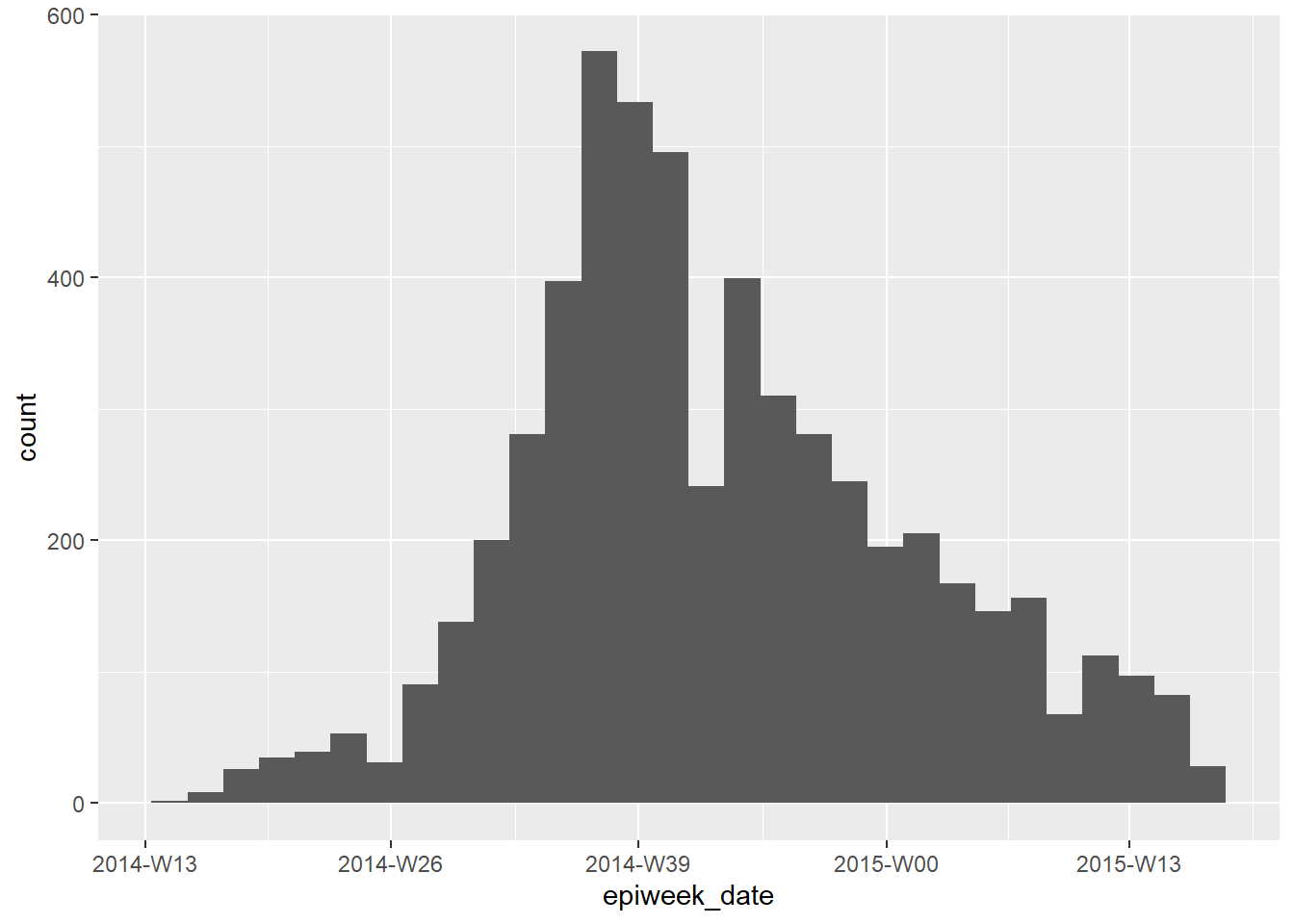
Эпиднедели в данных
Однако, если ваша цель использования факторов заключается не в построении графиков, вы можете подойти к этому одним из двух способов:
- Для детального контроля отображения, конвертируйте столбец эпиднедели lubridate (ГГГГ-ММ-ДД) в желаемый формат отображения (ГГГГ-Ннн) внутри самого датафрейма, а затем конвертируйте его в класс Фактор.
Во-первых, используйте format() из базового R для конвертации отображения даты из ГГГГ-ММ-ДД в ГГГГ-Ннн (см. страницу [Работа с датами]). В этом процессе класс будет конвертирован в текстовый. Затем конвертируйте из текстового класса в класс Фактор с помощью factor().
linelist <- linelist %>%
mutate(epiweek_date = floor_date(date_onset, "week"), # создаем эпиднедели (ГГГГ-ММ-ДД)
epiweek_formatted = format(epiweek_date, "%Y-W%W"), # Конвертируем для отображения (ГГГГ-Ннн)
epiweek_formatted = factor(epiweek_formatted)) # Конвертируем в фактор
# Отображаем уровни
levels(linelist$epiweek_formatted) [1] "2014-W13" "2014-W14" "2014-W15" "2014-W16" "2014-W17" "2014-W18"
[7] "2014-W19" "2014-W20" "2014-W21" "2014-W22" "2014-W23" "2014-W24"
[13] "2014-W25" "2014-W26" "2014-W27" "2014-W28" "2014-W29" "2014-W30"
[19] "2014-W31" "2014-W32" "2014-W33" "2014-W34" "2014-W35" "2014-W36"
[25] "2014-W37" "2014-W38" "2014-W39" "2014-W40" "2014-W41" "2014-W42"
[31] "2014-W43" "2014-W44" "2014-W45" "2014-W46" "2014-W47" "2014-W48"
[37] "2014-W49" "2014-W50" "2014-W51" "2015-W00" "2015-W01" "2015-W02"
[43] "2015-W03" "2015-W04" "2015-W05" "2015-W06" "2015-W07" "2015-W08"
[49] "2015-W09" "2015-W10" "2015-W11" "2015-W12" "2015-W13" "2015-W14"
[55] "2015-W15" "2015-W16"ВНИМАНИЕ: Если вы разместите недели перед годами (“Ннн-ГГГГ”) (“%W-%Y”), алфавитно-числовое упорядочивание по умолчанию будет неверным (например, 01-2015 будет стоять раньше 35-2014). Возможно, вам потребуется вручную откорректировать порядок, что будет долгим и сложным процессом.
- Для быстрого отображения по умолчанию используйте пакет aweek и его функцию
date2week(). Вы можете задать день начала неделиweek_start =, и если вы зададитеfactor = TRUE, тогда выходной столбец будет упорядоченным фактором. В качестве бонуса, фактор включает уровни для всех возможных недель в диапазоне - даже если нет случаев в эту неделю.
df <- linelist %>%
mutate(epiweek = date2week(date_onset, week_start = "Monday", factor = TRUE))
levels(df$epiweek)См. страницу [Работа с датами] для получения более детальной информации о aweek. На ней также предлагается обратная функция week2date().
11.8 Ресурсы
R for Data Science страница факторы
виньетка по пакету aweek