
17 Описательные таблицы
На данной странице демонстрируется использование janitor, dplyr, gtsummary, rstatix и базового R для обобщения данных и создания таблиц с описательной статистикой.
Эта страница рассматривает, как создавать* базовые таблицы, а страница Таблицы для презентации рассматривает, как их красиво форматировать и печатать.*
У каждого из этих пакетов есть преимущества и недостатки в плане простоты кода, доступности выходных данных, качества печати выходных данных. С помощью информации на этой странице вы можете решить, какой подход работает в вашем сценарии.
У вас есть несколько вариантов при проведении табуляции и кросс-табуляции с помощью обобщающих таблиц. Некоторые из факторов, которые нужно принять во внимание, включают простоту кода, его адаптируемость, желаемые выходные данные (печать в консоли R, как датафрейм, либо “красивые” изображения .png/.jpeg/.html), а также простоту последующей обработки. При выборе инструмента для своей ситуации рассмотрите указанные ниже аспекты.
- Используйте
tabyl()из janitor для подготовки и “оформления” таблиц табуляциии и кросс-табуляции
- Используйте
get_summary_stats()из rstatix, чтобы легко сгенерировать датафреймы числовой сводной статистики для нескольких столбцов и/или групп
- Используйте
summarise()иcount()из dplyr для более сложной статистики, получения выходных данных в формате аккуратных данных, либо подготовки данных дляggplot()
- Используйте
tbl_summary()из gtsummary для подготовки детальных готовых к публикации таблиц
- Используйте
table()из базового R, если у вас нет доступа к указанным выше пакетам
17.1 Подготовка
Загрузка пакетов
Этот фрагмент кода показывает загрузку пакетов для анализа. В этом руководстве мы подчеркиваем использование p_load() из pacman, которая устанавливает пакет, если необходимо, и загружает его для использования. Вы можете также загрузить установленные пакеты с помощью library() из базового R. См. страницу Основы R для получения более подробной информации о пакетах R.
pacman::p_load(
rio, # импорт файлов
here, # путь к файлу
skimr, # получение обзора данных
tidyverse, # управление данными + графика ggplot2
gtsummary, # сводная статистика и тесты
rstatix, # сводная статистика и статистические тесты
janitor, # добавление итогов и процентов к таблицам
scales, # простая конвертация долей в проценты
flextable # конвертация таблиц в красивые рисунки
)Импорт данных
Мы импортируем набор данных о случаях имитированной эпидемии Эболы. Если вы хотите выполнять действия параллельно, кликните, чтобы скачать “чистый” построчный список (как .rds файл). Импортируйте ваши данные с помощью функции import() из пакета rio (она работает с разными файлами, такими как .xlsx, .rds, .csv - см. детали на странице Импорт и экспорт).
# импорт построчного списка
linelist <- import("linelist_cleaned.rds")Первые 50 строк построчного списка отображены ниже.
17.2 Просмотр данных
пакет skimr
С помощью пакета skimr вы можете получить детальную информацию и эстетически приятный обзор по каждой переменной в вашем наборе данных. Более подробно о skimr можно прочитать на странице github.
Ниже функция skim() применяется ко всему датафрейму linelist. Создается обзор датафрейма и сводная информация по каждому столбцу (по классам).
## получаем информацию о каждой переменной в наборе данных
skim(linelist)| Name | linelist |
| Number of rows | 5888 |
| Number of columns | 30 |
| _______________________ | |
| Column type frequency: | |
| character | 13 |
| Date | 4 |
| factor | 2 |
| numeric | 11 |
| ________________________ | |
| Group variables | None |
Variable type: character
| skim_variable | n_missing | complete_rate | min | max | empty | n_unique | whitespace |
|---|---|---|---|---|---|---|---|
| case_id | 0 | 1.00 | 6 | 6 | 0 | 5888 | 0 |
| outcome | 1323 | 0.78 | 5 | 7 | 0 | 2 | 0 |
| gender | 278 | 0.95 | 1 | 1 | 0 | 2 | 0 |
| age_unit | 0 | 1.00 | 5 | 6 | 0 | 2 | 0 |
| hospital | 0 | 1.00 | 5 | 36 | 0 | 6 | 0 |
| infector | 2088 | 0.65 | 6 | 6 | 0 | 2697 | 0 |
| source | 2088 | 0.65 | 5 | 7 | 0 | 2 | 0 |
| fever | 249 | 0.96 | 2 | 3 | 0 | 2 | 0 |
| chills | 249 | 0.96 | 2 | 3 | 0 | 2 | 0 |
| cough | 249 | 0.96 | 2 | 3 | 0 | 2 | 0 |
| aches | 249 | 0.96 | 2 | 3 | 0 | 2 | 0 |
| vomit | 249 | 0.96 | 2 | 3 | 0 | 2 | 0 |
| time_admission | 765 | 0.87 | 5 | 5 | 0 | 1072 | 0 |
Variable type: Date
| skim_variable | n_missing | complete_rate | min | max | median | n_unique |
|---|---|---|---|---|---|---|
| date_infection | 2087 | 0.65 | 2014-03-19 | 2015-04-27 | 2014-10-11 | 359 |
| date_onset | 256 | 0.96 | 2014-04-07 | 2015-04-30 | 2014-10-23 | 367 |
| date_hospitalisation | 0 | 1.00 | 2014-04-17 | 2015-04-30 | 2014-10-23 | 363 |
| date_outcome | 936 | 0.84 | 2014-04-19 | 2015-06-04 | 2014-11-01 | 371 |
Variable type: factor
| skim_variable | n_missing | complete_rate | ordered | n_unique | top_counts |
|---|---|---|---|---|---|
| age_cat | 86 | 0.99 | FALSE | 8 | 0-4: 1095, 5-9: 1095, 20-: 1073, 10-: 941 |
| age_cat5 | 86 | 0.99 | FALSE | 17 | 0-4: 1095, 5-9: 1095, 10-: 941, 15-: 743 |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 |
|---|---|---|---|---|---|---|---|---|---|
| generation | 0 | 1.00 | 16.56 | 5.79 | 0.00 | 13.00 | 16.00 | 20.00 | 37.00 |
| age | 86 | 0.99 | 16.07 | 12.62 | 0.00 | 6.00 | 13.00 | 23.00 | 84.00 |
| age_years | 86 | 0.99 | 16.02 | 12.64 | 0.00 | 6.00 | 13.00 | 23.00 | 84.00 |
| lon | 0 | 1.00 | -13.23 | 0.02 | -13.27 | -13.25 | -13.23 | -13.22 | -13.21 |
| lat | 0 | 1.00 | 8.47 | 0.01 | 8.45 | 8.46 | 8.47 | 8.48 | 8.49 |
| wt_kg | 0 | 1.00 | 52.64 | 18.58 | -11.00 | 41.00 | 54.00 | 66.00 | 111.00 |
| ht_cm | 0 | 1.00 | 124.96 | 49.52 | 4.00 | 91.00 | 129.00 | 159.00 | 295.00 |
| ct_blood | 0 | 1.00 | 21.21 | 1.69 | 16.00 | 20.00 | 22.00 | 22.00 | 26.00 |
| temp | 149 | 0.97 | 38.56 | 0.98 | 35.20 | 38.20 | 38.80 | 39.20 | 40.80 |
| bmi | 0 | 1.00 | 46.89 | 55.39 | -1200.00 | 24.56 | 32.12 | 50.01 | 1250.00 |
| days_onset_hosp | 256 | 0.96 | 2.06 | 2.26 | 0.00 | 1.00 | 1.00 | 3.00 | 22.00 |
Вы можете также использовать функцию summary() из базового R, чтобы получить информацию о всем наборе данных, но такие выходные данные может быть сложнее прочитать, чем при использовании skimr. Поэтому выходной результат не приводится ниже в целях экономии пространства на странице.
## получаем информацию о каждом столбце в наборе данных
summary(linelist)Сводная статистика
Вы можете использовать функции базового R для получения сводной статистики по числовому столбцу. Вы можете получить наиболее важную сводную статистику для числового столбца, используя summary(), как показано ниже. Обратите внимание, что необходимо уточнять набор данных, как это сделано ниже.
summary(linelist$age_years) Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
0.00 6.00 13.00 16.02 23.00 84.00 86 Вы можете получить доступ и сохранить конкретную часть с помощью индексных квадратных скобок [ ]:
summary(linelist$age_years)[[2]] # выдать только 2-й элемент[1] 6# эквивалент, альтернатива указанному выше по имени элемента
# summary(linelist$age_years)[["1st Qu."]] Вы можете получить отдельные статистические показатели с помощью базовых функций R, таких как max() (максимум), min() (минимум), median() (медиана), mean() (среднее значение), quantile() (квантиль), sd() (стандартное отклонение) и range() (диапазон). См. полный список на странице Основы R.
ВНИМАНИЕ: Если ваши данные содержат отсутствующие значения, R хочет, чтобы вы это знали, поэтому выдаст NA, если только вы не укажете в указанных выше математических фукнциях, что вы хотите, чтобы R игнорировал отсутствующие значения, с помощью аргумента na.rm = TRUE.
Вы можете использовать функцию get_summary_stats() из rstatix, чтобы получить сводную статистику в формате датафрейма. Это может быть полезным для проведения последующих операций или составления графика с числами. См. страницу Простые статистические тесты для получения дополнительной информации о пакете rstatix и его функциях.
linelist %>%
get_summary_stats(
age, wt_kg, ht_cm, ct_blood, temp, # столбцы, для которых нужен расчет
type = "common") # получаемая сводная статистика# A tibble: 5 × 10
variable n min max median iqr mean sd se ci
<fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 age 5802 0 84 13 17 16.1 12.6 0.166 0.325
2 wt_kg 5888 -11 111 54 25 52.6 18.6 0.242 0.475
3 ht_cm 5888 4 295 129 68 125. 49.5 0.645 1.26
4 ct_blood 5888 16 26 22 2 21.2 1.69 0.022 0.043
5 temp 5739 35.2 40.8 38.8 1 38.6 0.977 0.013 0.02517.3 пакет janitor
Пакет janitor предлагает функцию tabyl() для создания табуляций и кросс-табуляций, которые могут быть “оформлены” или модифицированы с помощью функций-помощников, чтобы отображать проценты, доли, подсчет количества и т.п.
Ниже мы передаем датафрейм linelist в функции janitor и печатаем результат. Если нужно, вы можете также сохранить получившиеся в результате таблицы с помощью оператора присваивания <-.
Простая таблица tabyl
Использование tabyl() по умолчанию применительно к конретному столбцу создает уникальные значения, подсчеты и постолбцовые “проценты” (на самом деле доли). Доли могут иметь много десятичных знаков. Вы можете откорректировать количество знаков после запятой с помощью adorn_rounding(), как описано ниже.
linelist %>% tabyl(age_cat) age_cat n percent valid_percent
0-4 1095 0.185971467 0.188728025
5-9 1095 0.185971467 0.188728025
10-14 941 0.159816576 0.162185453
15-19 743 0.126188859 0.128059290
20-29 1073 0.182235054 0.184936229
30-49 754 0.128057065 0.129955188
50-69 95 0.016134511 0.016373664
70+ 6 0.001019022 0.001034126
<NA> 86 0.014605978 NAКак вы видите выше, если есть отсутствующие значения, они отображаются в строке, подписанной как <NA>. Вы можете их заблокировать с помощью show_na = FALSE. Если нет отсутствующих значений, эта строка не будет появляться. Если есть отсутствующие значения, все доли будут приведены как сырые (знаменатель включает количество NA) и “валидные” (знаменатель исключает количество NA).
Если столбец относится к классу Фактор и только некоторые уровни присутствуют в ваших данных, все уровни все равно будут отображены в таблице. Вы можете заблокировать этот параметр, уточнив show_missing_levels = FALSE. Более детально читайте об этом на странице Факторы.
Кросс-табуляция
Подсчет в кросс-табуляции достигается путем добавления одного или более дополнительных столбцов внутри tabyl(). Обратите внимание, чтор теперь будет выдан только подсчет, а проценты можно добавить с помощью дополнительных шагов, указанных ниже.
linelist %>% tabyl(age_cat, gender) age_cat f m NA_
0-4 640 416 39
5-9 641 412 42
10-14 518 383 40
15-19 359 364 20
20-29 468 575 30
30-49 179 557 18
50-69 2 91 2
70+ 0 5 1
<NA> 0 0 86“Оформление” таблицы tabyl
Используйте функции “adorn” (“оформление”) из janitor, чтобы добавить итого или конвертировать в доли, проценты, либо как-то иначе откорректировать отображение. Часто необходимо составить канал для таблицы tabyl и применить к ней несколько из этих функций.
| Функция | Результат |
|---|---|
adorn_totals() |
Добавляет итого (where = “row”, “col”, or “both”). Установите name = для “Total” (Итого). |
adorn_percentages() |
Конвертирует количество в доли, с знаменателем denominator = “row” (строка), “col” (столбец), или “all” (все) |
adorn_pct_formatting() |
Конвертирует доли в проценты. Укажите digits =. Удалите символ “%” с помощью affix_sign = FALSE. |
adorn_rounding() |
Чтобы округлить пропорции до нужного количества десятичных знаков digits =. Чтобы округлить проценты, используйте adorn_pct_formatting() с digits =. |
adorn_ns() |
Добавить подсчет абсолютного количества в таблицу долей или процентов. Укажите position = “rear”, чтобы показать абсолютное количество в скобках, либо “front”, чтобы проценты были в скобках. |
adorn_title() |
Добавить последовательность с помощью аргументов row_name =(имя строки) и/или col_name = (имя столбца) |
Обращайте внимание на порядок применения этих функций. Ниже приведены некоторые примеры.
Простая одновходовая таблица с процентами вместо долей по умолчанию.
linelist %>% # построчный список случаев
tabyl(age_cat) %>% # табуляция абсолютного количества и долей по возрастной категории
adorn_pct_formatting() # конвертация долей в проценты age_cat n percent valid_percent
0-4 1095 18.6% 18.9%
5-9 1095 18.6% 18.9%
10-14 941 16.0% 16.2%
15-19 743 12.6% 12.8%
20-29 1073 18.2% 18.5%
30-49 754 12.8% 13.0%
50-69 95 1.6% 1.6%
70+ 6 0.1% 0.1%
<NA> 86 1.5% -Кросс-табуляция со строкой итого и процентами по строке
linelist %>%
tabyl(age_cat, gender) %>% # подсчет по возрасту и полу
adorn_totals(where = "row") %>% # добавляем строку итого
adorn_percentages(denominator = "row") %>% # конвертируем количество в доли
adorn_pct_formatting(digits = 1) # конвертируем доли в проценты age_cat f m NA_
0-4 58.4% 38.0% 3.6%
5-9 58.5% 37.6% 3.8%
10-14 55.0% 40.7% 4.3%
15-19 48.3% 49.0% 2.7%
20-29 43.6% 53.6% 2.8%
30-49 23.7% 73.9% 2.4%
50-69 2.1% 95.8% 2.1%
70+ 0.0% 83.3% 16.7%
<NA> 0.0% 0.0% 100.0%
Total 47.7% 47.6% 4.7%Скорректированная кросс-табуляция, чтобы отобразить и абсолютное количество и проценты.
linelist %>% # построчный список случаев
tabyl(age_cat, gender) %>% # кросс-табуляция абсолютного количества
adorn_totals(where = "row") %>% # добавляем строку итого
adorn_percentages(denominator = "col") %>% # конвертируем в доли
adorn_pct_formatting() %>% # конвертируем в проценты
adorn_ns(position = "front") %>% # отображаем как: "абсолютное количество (процент)"
adorn_title( # корректируем заголовки
row_name = "Age Category",
col_name = "Gender") Gender
Age Category f m NA_
0-4 640 (22.8%) 416 (14.8%) 39 (14.0%)
5-9 641 (22.8%) 412 (14.7%) 42 (15.1%)
10-14 518 (18.5%) 383 (13.7%) 40 (14.4%)
15-19 359 (12.8%) 364 (13.0%) 20 (7.2%)
20-29 468 (16.7%) 575 (20.5%) 30 (10.8%)
30-49 179 (6.4%) 557 (19.9%) 18 (6.5%)
50-69 2 (0.1%) 91 (3.2%) 2 (0.7%)
70+ 0 (0.0%) 5 (0.2%) 1 (0.4%)
<NA> 0 (0.0%) 0 (0.0%) 86 (30.9%)
Total 2,807 (100.0%) 2,803 (100.0%) 278 (100.0%)Печать таблицы tabyl
По умолчанию таблица tabyl будет напечатана в сыром виде на вашей консоли R.
Альтернативно, вы можете передать таблицу tabyl в flextable или аналогичный пакет, чтобы распечатать “красивое” изображение на панели просмотра RStudio (Viewer), которое можно экспортировать как .png, .jpeg, .html, и т.п. Это обсуждается на странице Таблицы для презентации. Обратите внимание, что при печати таким образом и использовании adorn_titles(), вам нужно задать placement = "combined".
linelist %>%
tabyl(age_cat, gender) %>%
adorn_totals(where = "col") %>%
adorn_percentages(denominator = "col") %>%
adorn_pct_formatting() %>%
adorn_ns(position = "front") %>%
adorn_title(
row_name = "Age Category",
col_name = "Gender",
placement = "combined") %>% # необходимо для печати как картинки
flextable::flextable() %>% # конвертирует в красивую картинку
flextable::autofit() # формат на одну линию на строку Age Category/Gender | f | m | NA_ | Total |
|---|---|---|---|---|
0-4 | 640 (22.8%) | 416 (14.8%) | 39 (14.0%) | 1,095 (18.6%) |
5-9 | 641 (22.8%) | 412 (14.7%) | 42 (15.1%) | 1,095 (18.6%) |
10-14 | 518 (18.5%) | 383 (13.7%) | 40 (14.4%) | 941 (16.0%) |
15-19 | 359 (12.8%) | 364 (13.0%) | 20 (7.2%) | 743 (12.6%) |
20-29 | 468 (16.7%) | 575 (20.5%) | 30 (10.8%) | 1,073 (18.2%) |
30-49 | 179 (6.4%) | 557 (19.9%) | 18 (6.5%) | 754 (12.8%) |
50-69 | 2 (0.1%) | 91 (3.2%) | 2 (0.7%) | 95 (1.6%) |
70+ | 0 (0.0%) | 5 (0.2%) | 1 (0.4%) | 6 (0.1%) |
0 (0.0%) | 0 (0.0%) | 86 (30.9%) | 86 (1.5%) |
Применение к другим таблицам
Вы можете использовать функции adorn_*() из janitor для других таблиц, например, созданных с помощью summarise() и count() из dplyr, либо table() из базового R. Просто передайте таблицу в соответствующую функцию из janitor. Например:
linelist %>%
count(hospital) %>% # функция dplyr
adorn_totals() # функция janitor hospital n
Central Hospital 454
Military Hospital 896
Missing 1469
Other 885
Port Hospital 1762
St. Mark's Maternity Hospital (SMMH) 422
Total 5888Сохранение таблицы tabyl
Если вы конвертируете таблицу в “красивый” рисунок с помощью такого пакета, как flextable, вы можете ее сохранить с помощью функций из этого пакета - например, save_as_html(), save_as_word(), save_as_ppt() и save_as_image() из flextable (более подробно объясняется на странице Таблицы для презентации). Ниже таблица сохраняется как документ Word, в котором ее можно дополнительно редактировать вручную.
linelist %>%
tabyl(age_cat, gender) %>%
adorn_totals(where = "col") %>%
adorn_percentages(denominator = "col") %>%
adorn_pct_formatting() %>%
adorn_ns(position = "front") %>%
adorn_title(
row_name = "Age Category",
col_name = "Gender",
placement = "combined") %>%
flextable::flextable() %>% # конвертируем в изображение
flextable::autofit() %>% # проверяем, что только одна линия на строку
flextable::save_as_docx(path = "tabyl.docx") # сохраняем как документ Word по указанному пути к файлу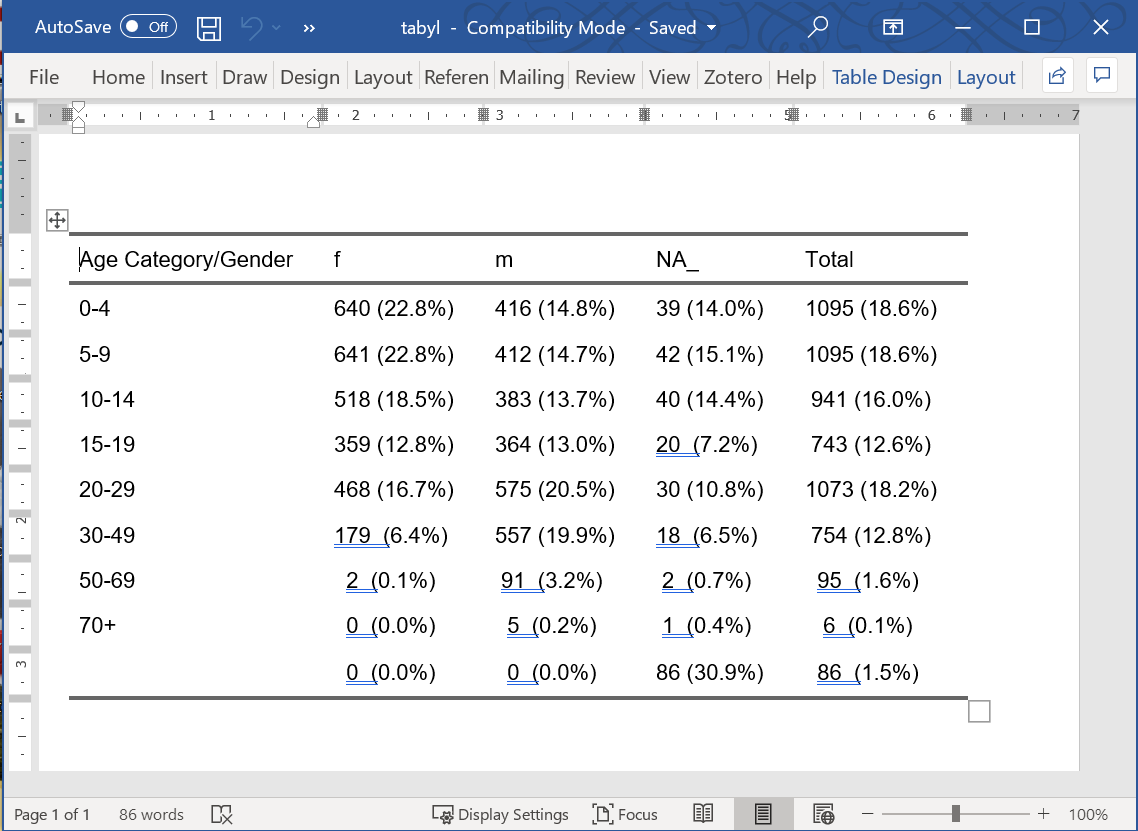
Статистика
Вы можете применять статистические тесты к таблицам tabyl, например, chisq.test() или fisher.test() из пакета stats, как показано ниже. Обратите внимание, что отсутствующие значения не разрешены, поэтому они исключены из таблицы tabyl с помощью show_na = FALSE.
age_by_outcome <- linelist %>%
tabyl(age_cat, outcome, show_na = FALSE)
chisq.test(age_by_outcome)
Pearson's Chi-squared test
data: age_by_outcome
X-squared = 6.4931, df = 7, p-value = 0.4835Дополнительные примеры кода и советы по статистике приведены на странице Простые статистические тесты.
Другие советы
- Включайте аргумент
na.rm = TRUE, чтобы исключить отсутствующие значения из любого указанного выше расчета.
- При применении любой функции-помощника
adorn_*()к таблицам, которые были созданы не с помощьюtabyl(), вы можете уточнить конкретные столбцы, к которым нужно применить, например,adorn_percentage(,,,c(cases,deaths))(уточните их в 4м неименованном аргументе). Синтаксис непростой. Рассмотрите возможность вместо этого использоватьsummarise().
- Более подробно вы можете прочитать на странице по janitor и в этой виньетке по tabyl.
17.4 пакет dplyr
dplyr является частью пакетов tidyverse и очень часто используемым инструментом управления данными. Создание таблиц с помощью функций из dplyr summarise() и count() является очень полезным подходом к рассчету сводной статистики, обобщения по группе или для передачи таблиц в ggplot().
summarise() создает новый сводный датафрейм. Если данные не группированы, она выдаст датафрейм с одной строкой с указанной сводной статистикой по всему датафрейму. Если данные сгруппированы, новый датафрейм будет содержать по одной строке на группу (см. страницу [Группирование данных])(grouping.ru.qmd).
Внутри скобок в summarise() вы задаете имена каждого нового сводного столбца, за которыми следует знак равно и статистическая функция, которую нужно применить.
СОВЕТ: Функция summarise (обобщить) работает и в британском и американском написании (summarise() и summarize()).
Сделать подсчет количества
Самая простая функция, которую можно применить в summarise() - это n(). Оставьте скобки пустыми, чтобы подсчитать количество строк.
linelist %>% # начинаем с построчного списка
summarise(n_rows = n()) # выдает новый сводный датафрейм со столбцом n_rows n_rows
1 5888Это становится более интересным, если у нас данные были до этого сгруппированы.
linelist %>%
group_by(age_cat) %>% # группируем данные по уникальным значениям в столбце age_cat
summarise(n_rows = n()) # выдает количество строк *в группе*# A tibble: 9 × 2
age_cat n_rows
<fct> <int>
1 0-4 1095
2 5-9 1095
3 10-14 941
4 15-19 743
5 20-29 1073
6 30-49 754
7 50-69 95
8 70+ 6
9 <NA> 86Указанную выше команду можно сократить, используя функцию count(). count() выполняет следующие действия:
- Группирует данные по заданным ей столбцам
- Обобщает их с помощью
n()(создает столбецn)
- Разгруппирует данные
linelist %>%
count(age_cat) age_cat n
1 0-4 1095
2 5-9 1095
3 10-14 941
4 15-19 743
5 20-29 1073
6 30-49 754
7 50-69 95
8 70+ 6
9 <NA> 86Вы можете изменить имя столбца с подсчетом со значения по умолчанию n на что-либо другое, задав это имя в аргумент name =.
Табуляция подсчетов по двум или более столбцам группирования выдается в “длинном” формате с количеством, указанным в столбце n. См. страницу Поворот данных , чтобы больше узнать о “длинном” и “широком” формате данных.
linelist %>%
count(age_cat, outcome) age_cat outcome n
1 0-4 Death 471
2 0-4 Recover 364
3 0-4 <NA> 260
4 5-9 Death 476
5 5-9 Recover 391
6 5-9 <NA> 228
7 10-14 Death 438
8 10-14 Recover 303
9 10-14 <NA> 200
10 15-19 Death 323
11 15-19 Recover 251
12 15-19 <NA> 169
13 20-29 Death 477
14 20-29 Recover 367
15 20-29 <NA> 229
16 30-49 Death 329
17 30-49 Recover 238
18 30-49 <NA> 187
19 50-69 Death 33
20 50-69 Recover 38
21 50-69 <NA> 24
22 70+ Death 3
23 70+ Recover 3
24 <NA> Death 32
25 <NA> Recover 28
26 <NA> <NA> 26Показать все уровни
Если вы делаете табуляцию по столбцу с классом фактор, вы можете убедиться, что показаны все уровни (а не только уровни со значениями в данных), добавив .drop = FALSE в команду summarise() или count().
Этот прием полезен для стандартизации ваших таблиц/графиков. Например, если вы создаете рисунки по нескольким подгруппам, либо постоянно создаете рисунок для рутинных отчетов. В каждом случае наличие значения в данных может колебаться, но вы можете определить уровни, которые будут оставаться постоянными.
См. дополнительную информацию на странице Факторы.
Доли
Доли могут быть добавлены с помощью передачи таблицы в функцию mutate(), чтобы создать новый столбец. Определите новый столбец как столбец с подсчетом (n по умолчанию), разделенный на сумму столбца подсчета количества sum() (это выдаст вам долю).
Обратите внимание, что в этом случае sum() в команде mutate() выдаст сумму всего столбца n для использования в качестве знаменателя при расчете доли. Как объяснялось на странице Группирование данных, если используется sum() для группированных данных (например, если mutate() идет непосредственно после команды group_by()), она выдаст суммы по группам. Как указано чуть выше, count() завершает свои действия разгруппированием. Таким образом, в этом сценарии мы получим доли по полным столбцам.
Чтобы легко отобразить проценты, вы можете обернуть долю в функцию percent() из пакета scales (обратите внимание, что это конвертирует в текстовый класс).
age_summary <- linelist %>%
count(age_cat) %>% # группируем и считаем по полу (создает столбец "n")
mutate( # создаем процент столбца - обратите внимание на знаменатель
percent = scales::percent(n / sum(n)))
# печать
age_summary age_cat n percent
1 0-4 1095 18.60%
2 5-9 1095 18.60%
3 10-14 941 15.98%
4 15-19 743 12.62%
5 20-29 1073 18.22%
6 30-49 754 12.81%
7 50-69 95 1.61%
8 70+ 6 0.10%
9 <NA> 86 1.46%Ниже приведен метод расчета долей внутри групп. Он полагается на разные уровни группирования данных, которые селективно применяются и снимаются. Сначала данные группируются по исходу outcome с помощью group_by(). Затем применяется count(). Эта функция далее группирует данные по age_cat и выдает подсчет для каждой комбинации исхода-возрастной категории outcome-age-cat. Что важно - после того как процесс завершен, count() также разгруппирует группирование по возрастным категориям age_cat, так что единственным оставшимся группированием будет оригинальное группирование по исходам outcome. Таким образом, последний шаг расчета долей (знаменатель sum(n)) все еще имеет группирование по исходу outcome.
age_by_outcome <- linelist %>% # начинаем с построчного списка
group_by(outcome) %>% # группируем по исходу
count(age_cat) %>% # группируем и считаем по age_cat, а затем снимаем группировку age_cat
mutate(percent = scales::percent(n / sum(n))) # рассчитываем процент - обратите внимание, что знаменатель по группе исходаПостроение графика
Отобразить “длинную” выходную таблицу, как показано выше, с помощью ggplot() достаточно просто. Данные естественным образом находятся в “длинном” формате, который естественно воспринимается ggplot(). См. дополнительные примепры на страницах Основы ggplot и Советы по использованию ggplot.
linelist %>% # начинаем с построчного списка
count(age_cat, outcome) %>% # группируем и считаем количество по двум столбцам
ggplot()+ # передаем новый датафрейм в ggplot
geom_col( # создаем столбчатую диаграмму
mapping = aes(
x = outcome, # строим исход по оси x
fill = age_cat, # age_cat отражаем в заливке
y = n)) # строим столбец подсчета `n` по высоте
Сводная статистика
Одним из важных преимуществ dplyr и summarise() является способность выдать более продвинутые статистические сводные данные, такие как median() (медиана), mean() (среднее), max() (максимум), min() (минимум), sd() (стандартное отклонение) и процентили. Вы также можете использовать sum(), чтобы получить количество строк, которые соответствуют определенным логическим критериям. Как указано выше, эти выходные данные мы можем получить по всему датафрейму или по группам.
Синтаксис тот же - внутри скобок summarise() вы задаете имена каждого нового сводного столбца, после чего идет знак равно и статистическая функция, которую нужно применить. Внутри статистической функции задайте столбец(столбцы), с которыми нужно проделать операцию и любые необходимые аргументы (например, na.rm = TRUE для большинства математических функций).
Вы также можете использовать sum(), чтобы выдать количество строк, которые соответствуют логическим критериям. Выражение внутри считается, если оно оценено как TRUE (ИСТИНА). Например:
sum(age_years < 18, na.rm=T)
sum(gender == "male", na.rm=T)
sum(response %in% c("Likely", "Very Likely"))
Ниже данные linelist обобщаются, чтобы описать дни задержки от появления симптомов до госпитализации (столбец days_onset_hosp), по больницам.
summary_table <- linelist %>% # начинаем с построчного списка, сохраняем как новый объект
group_by(hospital) %>% # группируем все расчеты по больницам
summarise( # выдаются только указанные ниже сводные столбцы
cases = n(), # количество строк на группу
delay_max = max(days_onset_hosp, na.rm = T), # максимальная задержка
delay_mean = round(mean(days_onset_hosp, na.rm=T), digits = 1), # средняя задержка, округленная
delay_sd = round(sd(days_onset_hosp, na.rm = T), digits = 1), # стандартное отклонение задержек, округленное
delay_3 = sum(days_onset_hosp >= 3, na.rm = T), # количество строк с задержкой 3 или более дня
pct_delay_3 = scales::percent(delay_3 / cases) # конвертирует ранее установленный столбец задержки в проценты
)
summary_table # печать# A tibble: 6 × 7
hospital cases delay_max delay_mean delay_sd delay_3 pct_delay_3
<chr> <int> <dbl> <dbl> <dbl> <int> <chr>
1 Central Hospital 454 12 1.9 1.9 108 24%
2 Military Hospital 896 15 2.1 2.4 253 28%
3 Missing 1469 22 2.1 2.3 399 27%
4 Other 885 18 2 2.2 234 26%
5 Port Hospital 1762 16 2.1 2.2 470 27%
6 St. Mark's Maternity … 422 18 2.1 2.3 116 27% Некоторые советы:
- Используйте
sum()с логическим утверждением, чтобы “посчитать” строки, которые соответствуют определенным критериям (==)
- Обратите внимание на использование аргумента
na.rm = TRUEвнутри математических функций, таких какsum(), иначеNAбудут выданы, если есть отсутствующие значения
- Используйте функцию
percent()из пакета scales, чтобы легко конвертировать в проценты- Установите точность
accuracy =на 0.1 или 0.01, чтобы было 1 или два знака после запятой, соответственно
- Установите точность
- Используйте
round()из базового R, чтобы уточнить количество десятичных знаков
- Чтобы рассчитать эти статистические показатели для всего набора данных, используйте
summarise()безgroup_by()
- Вы можете создать столбцы в целях расчетов позднее (например, знаменатели), которые вы в конечном идее удалите из датафрейма с помощью
select().
Статистика по условиям
Вам может потребоваться статистика по условиям - например, максимум строк, которые соответствуют определенным критериям. Это можно сделать, определив подмножество столбца с помощью квадратных скобок [ ]. Пример ниже выдает максимальную температуру для пациентов, классифицированных как имеющих и не имеющих повышенную температуру. Однако имейте ввиду, что может быть лучше добавить еще один столбец в команду group_by() и pivot_wider() (как показано ниже).
linelist %>%
group_by(hospital) %>%
summarise(
max_temp_fvr = max(temp[fever == "yes"], na.rm = T),
max_temp_no = max(temp[fever == "no"], na.rm = T)
)# A tibble: 6 × 3
hospital max_temp_fvr max_temp_no
<chr> <dbl> <dbl>
1 Central Hospital 40.4 38
2 Military Hospital 40.5 38
3 Missing 40.6 38
4 Other 40.8 37.9
5 Port Hospital 40.6 38
6 St. Mark's Maternity Hospital (SMMH) 40.6 37.9Склеивание
Функция str_glue() из stringr является полезной для объединения значений из нескольких столбцов в один новый столбец. В этом контексте она, как правило, используется после команды summarise().
На странице Текст и последовательности обсуждаются разные спомобы объединения столбцов, включая unite() и paste0(). В данном применении мы предлагаем использовать str_glue(), поскольку она более гибкая, чем unite(), и имеет более простой синтаксис, чем paste0().
Ниже датафрейм summary_table (созданный выше) изменяется таким образом, что столбцы delay_mean и delay_sd объединяются, добавляется форматирование со скобками для нового столбца, а соответствующие старые столбцы удаляются.
Затем, чтобы сделать таблицу более презентабельной, добавляется строка итого с помощью adorn_totals() из janitor (которая игнорирует нечисловые столбцы). Наконец, мы используем select() из dplyr, чтобы изменить порядок и сменить имена столбцов на более хорошие.
Теперь вы можете передать в flextable и напечататьт таблицу в Word, .png, .jpeg, .html, Powerpoint, RMarkdown и т.п.! (См. страницу Таблицы для презентации).
summary_table %>%
mutate(delay = str_glue("{delay_mean} ({delay_sd})")) %>% # объединяем и форматируем другие значения
select(-c(delay_mean, delay_sd)) %>% # удаляем два старых столбца
adorn_totals(where = "row") %>% # добавляем строку итого
select( # упорядочиваем и переименовываем столбцы
"Hospital Name" = hospital,
"Cases" = cases,
"Max delay" = delay_max,
"Mean (sd)" = delay,
"Delay 3+ days" = delay_3,
"% delay 3+ days" = pct_delay_3
) Hospital Name Cases Max delay Mean (sd) Delay 3+ days
Central Hospital 454 12 1.9 (1.9) 108
Military Hospital 896 15 2.1 (2.4) 253
Missing 1469 22 2.1 (2.3) 399
Other 885 18 2 (2.2) 234
Port Hospital 1762 16 2.1 (2.2) 470
St. Mark's Maternity Hospital (SMMH) 422 18 2.1 (2.3) 116
Total 5888 101 - 1580
% delay 3+ days
24%
28%
27%
26%
27%
27%
-Процентили
Процентили и квантили в dplyr заслуживают отдельного упоминания. Чтобы получить квантили, используйте quantile() с аргументами по умолчанию, либо уточните значение(я), которое(ые) вы хотите с помощью probs =.
# получаем значения процентилей возраста по умолчанию (0%, 25%, 50%, 75%, 100%)
linelist %>%
summarise(age_percentiles = quantile(age_years, na.rm = TRUE))Warning: Returning more (or less) than 1 row per `summarise()` group was deprecated in
dplyr 1.1.0.
ℹ Please use `reframe()` instead.
ℹ When switching from `summarise()` to `reframe()`, remember that `reframe()`
always returns an ungrouped data frame and adjust accordingly. age_percentiles
1 0
2 6
3 13
4 23
5 84# получаем уточненные вручную значения процентилей возраста (5%, 50%, 75%, 98%)
linelist %>%
summarise(
age_percentiles = quantile(
age_years,
probs = c(.05, 0.5, 0.75, 0.98),
na.rm=TRUE)
)Warning: Returning more (or less) than 1 row per `summarise()` group was deprecated in
dplyr 1.1.0.
ℹ Please use `reframe()` instead.
ℹ When switching from `summarise()` to `reframe()`, remember that `reframe()`
always returns an ungrouped data frame and adjust accordingly. age_percentiles
1 1
2 13
3 23
4 48Если вы хотите получить квантили по группе, вы можете получить длинные и менее полезные выходные данные, если вы просто добавите еще один столбец в group_by(). Поэтому вместо этого попробуйте такой подход - создайте столбец для каждого нужного уровня квантиля.
# получите уточненные вручную значения процентилей возраста (5%, 50%, 75%, 98%)
linelist %>%
group_by(hospital) %>%
summarise(
p05 = quantile(age_years, probs = 0.05, na.rm=T),
p50 = quantile(age_years, probs = 0.5, na.rm=T),
p75 = quantile(age_years, probs = 0.75, na.rm=T),
p98 = quantile(age_years, probs = 0.98, na.rm=T)
)# A tibble: 6 × 5
hospital p05 p50 p75 p98
<chr> <dbl> <dbl> <dbl> <dbl>
1 Central Hospital 1 12 21 48
2 Military Hospital 1 13 24 45
3 Missing 1 13 23 48.2
4 Other 1 13 23 50
5 Port Hospital 1 14 24 49
6 St. Mark's Maternity Hospital (SMMH) 2 12 22 50.2Хотя функция summarise() из dplyr однозначно предлагает более детальный контроль, вы можете увидеть, что необходимую вам статистику можно подготовить и с помощью get_summary_stat() из пакета rstatix. При работе с сгруппированными данными, она выдаст 0%, 25%, 50%, 75% и 100%. При применении к негруппированным данным, вы можете уточнить процентили с помощью probs = c(.05, .5, .75, .98).
linelist %>%
group_by(hospital) %>%
rstatix::get_summary_stats(age, type = "quantile")# A tibble: 6 × 8
hospital variable n `0%` `25%` `50%` `75%` `100%`
<chr> <fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Central Hospital age 445 0 6 12 21 58
2 Military Hospital age 884 0 6 14 24 72
3 Missing age 1441 0 6 13 23 76
4 Other age 873 0 6 13 23 69
5 Port Hospital age 1739 0 6 14 24 68
6 St. Mark's Maternity Hospital (… age 420 0 7 12 22 84linelist %>%
rstatix::get_summary_stats(age, type = "quantile")# A tibble: 1 × 7
variable n `0%` `25%` `50%` `75%` `100%`
<fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 age 5802 0 6 13 23 84Обобщение агрегированных данных
Если вы начинаете с агрегированных данных, использование n() выдаст количество строк, а не сумму агрегированных подсчетов. Чтобы получить суммы, примените sum() к столбцу с подсчетом в данных.
Например, представим, что вы начинаете с датафреймом подсчета ниже, который называется linelist_agg - он отображает в “длинном” формате подсчет случаев по исходу и полу.
Ниже мы создаем этот пример датафрейма с подсчетом случаев из linelist по исходу и полу (для ясности отсутствующие значения удаляются).
linelist_agg <- linelist %>%
drop_na(gender, outcome) %>%
count(outcome, gender)
linelist_agg outcome gender n
1 Death f 1227
2 Death m 1228
3 Recover f 953
4 Recover m 950Чтобы сложить количества (в столбце n) по группам, вы можете использовать summarise(), но установить новый столбец равным sum(n, na.rm=T). Чтобы добавить элемент условия к операции суммы, вы можете использовать синтаксис квадратных скобок подмножества [ ] для столбца с подсчетом.
linelist_agg %>%
group_by(outcome) %>%
summarise(
total_cases = sum(n, na.rm=T),
male_cases = sum(n[gender == "m"], na.rm=T),
female_cases = sum(n[gender == "f"], na.rm=T))# A tibble: 2 × 4
outcome total_cases male_cases female_cases
<chr> <int> <int> <int>
1 Death 2455 1228 1227
2 Recover 1903 950 953across() по нескольким столбцам
Вы можете применить summarise() к нескольким столбцам, используя across(). Это упростит жизнь, если вы хотите рассчитать одинаковые статистические показатели для нескольких столбцов. Поставьте across() внутри summarise() и уточните следующее:
.cols =как либо вектор имен столбцовc()или функции-помощники “tidyselect” (объясняется ниже)
.fns =выполняемая функция (без скобок) - вы можете указать несколько внутриlist()
Ниже среднее значение mean() применяется к нескольким числовым столбцам. Вектор столбцов записывается в .cols =, а одна функция mean (среднее значение) указывается (без скобок) в .fns =. Любые дополнительные аргументы для функции (например, na.rm=TRUE) задаются после .fns =, отделенные запятой.
При использовании across() может быть сложно указать скобки и запятые в правильном порядке. Помните, что внутри across() вы должны включить столбцы, функции, а также дополнительные аргументы, необходимые функциям.
linelist %>%
group_by(outcome) %>%
summarise(across(.cols = c(age_years, temp, wt_kg, ht_cm), # столбцы
.fns = mean, # функция
na.rm=T)) # дополнительные аргументыWarning: There was 1 warning in `summarise()`.
ℹ In argument: `across(...)`.
ℹ In group 1: `outcome = "Death"`.
Caused by warning:
! The `...` argument of `across()` is deprecated as of dplyr 1.1.0.
Supply arguments directly to `.fns` through an anonymous function instead.
# Previously
across(a:b, mean, na.rm = TRUE)
# Now
across(a:b, \(x) mean(x, na.rm = TRUE))# A tibble: 3 × 5
outcome age_years temp wt_kg ht_cm
<chr> <dbl> <dbl> <dbl> <dbl>
1 Death 15.9 38.6 52.6 125.
2 Recover 16.1 38.6 52.5 125.
3 <NA> 16.2 38.6 53.0 125.Несколько функций можно выполнять одновременно. Ниже в .fns = указываются функции mean (среднее) и sd (стандартное отклонение) внутри list(). У вас есть возможность задать текстовые имена (например, “mean” и “sd”), которые будут добавлены к новым названиям столбцов.
linelist %>%
group_by(outcome) %>%
summarise(across(.cols = c(age_years, temp, wt_kg, ht_cm), # столбцы
.fns = list("mean" = mean, "sd" = sd), # несколько функций
na.rm=T)) # дополнительные аргументы# A tibble: 3 × 9
outcome age_years_mean age_years_sd temp_mean temp_sd wt_kg_mean wt_kg_sd
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Death 15.9 12.3 38.6 0.962 52.6 18.4
2 Recover 16.1 13.0 38.6 0.997 52.5 18.6
3 <NA> 16.2 12.8 38.6 0.976 53.0 18.9
# ℹ 2 more variables: ht_cm_mean <dbl>, ht_cm_sd <dbl>Вот функции-помощники “tidyselect”, которые вы можете указать в .cols =, чтобы выбрать столбцы:
everything()- все остальные не упомянутые столбцы
last_col()- последний столбец
where()- применяет функцию ко всем столбцам и выбирает те, которые оценены как TRUE (ИСТИНА)
starts_with()- ищет совпадение с установленным префиксом. Пример:starts_with("date")ends_with()- ищет совпадение с установленным суффиксом. Пример:ends_with("_end")
contains()- столбцы, содержащие текстовую последовательностоь. Пример:contains("time")matches()- чтобы применить регулярное выражение (regex). Пример:contains("[pt]al")
num_range()-any_of()- ищет совпадение, если столбец именованный. Полезно, если имя не существует. Пример:any_of(date_onset, date_death, cardiac_arrest)
Например, чтобы выдать среднее значение каждого числового столбца, используйте where() и задайте функцию as.numeric() (без скобок). Все это остается внутри команды across().
linelist %>%
group_by(outcome) %>%
summarise(across(
.cols = where(is.numeric), # все числовые столбцы в датафрейме
.fns = mean,
na.rm=T))# A tibble: 3 × 12
outcome generation age age_years lon lat wt_kg ht_cm ct_blood temp
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Death 16.7 15.9 15.9 -13.2 8.47 52.6 125. 21.3 38.6
2 Recover 16.4 16.2 16.1 -13.2 8.47 52.5 125. 21.1 38.6
3 <NA> 16.5 16.3 16.2 -13.2 8.47 53.0 125. 21.2 38.6
# ℹ 2 more variables: bmi <dbl>, days_onset_hosp <dbl>Поворот горизонтально
Если вы предпочитаете таблицу в “широком” формате, вы можете ее преобразовать, используя функцию pivot_wider() изtidyr. Вам, скорее всего, нужно будет переименовать столбцы с помощью rename(). Дополнительную информацию см. на странице [Поворот данных].
Пример ниже начинается с “длинной” таблицы age_by_outcome из раздела доли. Мы создаем ее снова и печатаем, для ясности:
age_by_outcome <- linelist %>% # начинаем с построчного списка
group_by(outcome) %>% # группируем по исходу
count(age_cat) %>% # группируем и считаем по age_cat, а затем снимаем группировку age_cat
mutate(percent = scales::percent(n / sum(n))) # рассчитываем процент - обратите внимание, что знаменатель по группе исходовЧтобы повернуть горизонтально, мы создаем новые столбцы из значений в существующем столбце age_cat (установив names_from = age_cat). Мы также уточняем, что новые значения таблицы будут взяты из существующего столбца n, с values_from = n. Столбцы, не упомянутые в нашей команде поворота (outcome) останутся неизменными в левой стороне.
age_by_outcome %>%
select(-percent) %>% # сохраняем только подсчет количества для простоты
pivot_wider(names_from = age_cat, values_from = n) # A tibble: 3 × 10
# Groups: outcome [3]
outcome `0-4` `5-9` `10-14` `15-19` `20-29` `30-49` `50-69` `70+` `NA`
<chr> <int> <int> <int> <int> <int> <int> <int> <int> <int>
1 Death 471 476 438 323 477 329 33 3 32
2 Recover 364 391 303 251 367 238 38 3 28
3 <NA> 260 228 200 169 229 187 24 NA 26Строки Итого
Когда summarise() применяется к группированным данным, она не создает автоматически статистические показатели “итого”. Ниже представлены два подхода к добавлению строки “итого”:
adorn_totals() из janitor
Если ваша таблица состоит только из абсолютного количества или долей/процентов, которые могут быть суммированы в “итого”, тогда вы можете добавить сложение итогов, используя функцию adorn_totals() из janitor, как описано в разделе выше. Обратите внимание, что эта функция может выдавать сумму только по числовым столбцам - если вы хотите посчитать другую итоговую сводную статистику, см. следующий подход с использованием dplyr.
Ниже linelist группируется по полу и обобщается в таблицу, которая описывает количество случаев с известным исходом, смертью и выздоровлением. Передав таблицу в adorn_totals(), мы добавляем строку итого внузи, отражающую сумму каждого столбца. Дальнейшие функции adorn_*() корректируют отображение, как указывают примечания к коду.
linelist %>%
group_by(gender) %>%
summarise(
known_outcome = sum(!is.na(outcome)), # Количество строк в группе, где исход не отсутствует
n_death = sum(outcome == "Death", na.rm=T), # Количество строк в группе, где исход - смерть
n_recover = sum(outcome == "Recover", na.rm=T), # Количество строк в группе, где исход - выздоровление
) %>%
adorn_totals() %>% # оформаляем строку итого (сумма каждого числового столбца)
adorn_percentages("col") %>% # получаем доли по столбцам
adorn_pct_formatting() %>% # конвертируем доли в проценты
adorn_ns(position = "front") # отображаем % и абсолютное количество (с абсолютным количеством сначала) gender known_outcome n_death n_recover
f 2,180 (47.8%) 1,227 (47.5%) 953 (48.1%)
m 2,178 (47.7%) 1,228 (47.6%) 950 (47.9%)
<NA> 207 (4.5%) 127 (4.9%) 80 (4.0%)
Total 4,565 (100.0%) 2,582 (100.0%) 1,983 (100.0%)summarise() к данным “итого” и затем связывание строк bind_rows()
Если ваша таблица состоит из сводной статистики, такой как median(), mean() и т.п., подход adorn_totals(), показанный выше, не будет достаточным. Вместо этого, чтобы получить сводную статистику для всего набора данных, вам нужно рассчитать их с помощью отдельной команды summarise() и затем привязать результаты к оригинальной сгруппированной суммарной таблице. Чтобы сделать это связывание, вы можете использовать bind_rows() из dplyr, как описано на странице [Объединение данных]. Ниже приведен пример:
Вы делаете суммарную таблицу исходов по больнице с помощью group_by() и summarise() следующим образом:
by_hospital <- linelist %>%
filter(!is.na(outcome) & hospital != "Missing") %>% # удаляем случаи с отсутствующим исходом или больницей
group_by(hospital, outcome) %>% # группируем данные
summarise( # создаем новые сводные столбцы интересующих индикаторов
N = n(), # количество строк на группу больница-исход
ct_value = median(ct_blood, na.rm=T)) # медианное значение CT на группу
by_hospital # печать таблицы# A tibble: 10 × 4
# Groups: hospital [5]
hospital outcome N ct_value
<chr> <chr> <int> <dbl>
1 Central Hospital Death 193 22
2 Central Hospital Recover 165 22
3 Military Hospital Death 399 21
4 Military Hospital Recover 309 22
5 Other Death 395 22
6 Other Recover 290 21
7 Port Hospital Death 785 22
8 Port Hospital Recover 579 21
9 St. Mark's Maternity Hospital (SMMH) Death 199 22
10 St. Mark's Maternity Hospital (SMMH) Recover 126 22Чтобы получить итого, выполните ту же команду summarise(), но сгруппируйте данные только по исходу (не по больнице), следующим образом:
totals <- linelist %>%
filter(!is.na(outcome) & hospital != "Missing") %>%
group_by(outcome) %>% # группируем только по исходу, не по больнице
summarise(
N = n(), # Эти статистические показатели теперь представлены только по исходу
ct_value = median(ct_blood, na.rm=T))
totals # печать таблицы# A tibble: 2 × 3
outcome N ct_value
<chr> <int> <dbl>
1 Death 1971 22
2 Recover 1469 22Мы можем связать эти два датафрейма вместе. Обратите внимание, что у by_hospital 4 столбца, а у totals 3 столбца. Используя bind_rows(), столбцы связываются по имени, а любое лишнее пространство заполняется NA (например, значения столбца hospital для двух новых строк итого totals). После связывания строк мы конвертируем эти пустые места в итого “Total”, используя replace_na() (см. страницу [Вычистка данных и ключевые функции]).
table_long <- bind_rows(by_hospital, totals) %>%
mutate(hospital = replace_na(hospital, "Total"))Вот новая таблица со строками “Итого” внизу.
Эта таблица представлена в “длинном” формате, который может вам подходить. Опционально, вы можете повернуть эту таблицу горизонтально, чтобы сделать ее более читабельной. См. раздел по повороту горизонтально выше, а также страницу [Поворот данных]. Вы можете также добавить дополнительные столбцы и красиво их упорядочить. Код приведен ниже.
table_long %>%
# Поворот горизонтально и форматирование
########################
mutate(hospital = replace_na(hospital, "Total")) %>%
pivot_wider( # Поворот из длинной в широкую
values_from = c(ct_value, N), # новые значения из столбцов ct и подсчет
names_from = outcome) %>% # новые имена столбцов из исходов (outcomes)
mutate( # добавляем новые столбцы
N_Known = N_Death + N_Recover, # количество с известным исходом
Pct_Death = scales::percent(N_Death / N_Known, 0.1), # процент умерших случаев (1 знак после запятой)
Pct_Recover = scales::percent(N_Recover / N_Known, 0.1)) %>% # процент выздоровевших (1 знак после запятой)
select( # Переупорядочиваем столбцы
hospital, N_Known, # вводные столбцы
N_Recover, Pct_Recover, ct_value_Recover, # столбцы выздоровевших
N_Death, Pct_Death, ct_value_Death) %>% # столбцы смерти
arrange(N_Known) # Упорядочиваем строки от наименьшего к наибольшему (строка Итого внизу)# A tibble: 6 × 8
# Groups: hospital [6]
hospital N_Known N_Recover Pct_Recover ct_value_Recover N_Death Pct_Death
<chr> <int> <int> <chr> <dbl> <int> <chr>
1 St. Mark's M… 325 126 38.8% 22 199 61.2%
2 Central Hosp… 358 165 46.1% 22 193 53.9%
3 Other 685 290 42.3% 21 395 57.7%
4 Military Hos… 708 309 43.6% 22 399 56.4%
5 Port Hospital 1364 579 42.4% 21 785 57.6%
6 Total 3440 1469 42.7% 22 1971 57.3%
# ℹ 1 more variable: ct_value_Death <dbl>Затем вы можете это красиво напечатать в виде изображения - ниже представлены выходные данные с помощью flextable. Вы можете более детально прочитать об этом примере и о том, как делать такую “красивую” таблицу на странице [Таблицы для презентации].
Hospital | Total cases with known outcome | Recovered | Died | ||||
|---|---|---|---|---|---|---|---|
Total | % of cases | Median CT values | Total | % of cases | Median CT values | ||
St. Mark's Maternity Hospital (SMMH) | 325 | 126 | 38.8% | 22 | 199 | 61.2% | 22 |
Central Hospital | 358 | 165 | 46.1% | 22 | 193 | 53.9% | 22 |
Other | 685 | 290 | 42.3% | 21 | 395 | 57.7% | 22 |
Military Hospital | 708 | 309 | 43.6% | 22 | 399 | 56.4% | 21 |
Missing | 1,125 | 514 | 45.7% | 21 | 611 | 54.3% | 21 |
Port Hospital | 1,364 | 579 | 42.4% | 21 | 785 | 57.6% | 22 |
Total | 3,440 | 1,469 | 42.7% | 22 | 1,971 | 57.3% | 22 |
17.5 Пакет gtsummary
Если вы хотите распечатать свою сводную статистику в виде красивой и готовой к публикации графики, вы можете использовать пакет gtsummary и его функцию tbl_summary(). Код может сначала показаться сложным, но выходные данные выглядят очень красиво и печатаются в вашей панели просмотра RStudio Viewer в виде изображения HTML. Прочитайте виньетку тут.
Вы можете также добавить результаты статистических тестов в таблицы gtsummary. Этот процесс описывается в разделе gtsummary на странице Простые статистические тесты.
Чтобы представить tbl_summary() мы сначала покажем наиболее базовое поведение, которое на самом деле создает большую и красивую таблицу. Затем мы детально рассмотрим, как вносить корректировки и делать более адаптированные под потребности таблицы.
Суммарная таблица
Поведение tbl_summary() по умолчанию на самом деле весьма невероятное - она берет заданные вами столбцы и создает суммарную таблицу в рамках одной команды. Функция печатает статистические показатели, подходящие для класса столбца: медиану и межквартильный диапазон (IQR) для числовых столбцов, и абсолютное количество (%) для категориальных столбцов. Отсутствующие значения конвертируются в “Unknown”. Внизу добавляются примечания, объясняющие статистику, а итого N показывается наверху.
linelist %>%
select(age_years, gender, outcome, fever, temp, hospital) %>% # сохраняем только интересующие столбцы
tbl_summary() # по умолчанию| Characteristic | N = 5,8881 |
|---|---|
| age_years | 13 (6, 23) |
| Unknown | 86 |
| gender | |
| f | 2,807 (50%) |
| m | 2,803 (50%) |
| Unknown | 278 |
| outcome | |
| Death | 2,582 (57%) |
| Recover | 1,983 (43%) |
| Unknown | 1,323 |
| fever | 4,549 (81%) |
| Unknown | 249 |
| temp | 38.80 (38.20, 39.20) |
| Unknown | 149 |
| hospital | |
| Central Hospital | 454 (7.7%) |
| Military Hospital | 896 (15%) |
| Missing | 1,469 (25%) |
| Other | 885 (15%) |
| Port Hospital | 1,762 (30%) |
| St. Mark's Maternity Hospital (SMMH) | 422 (7.2%) |
| 1 Median (IQR); n (%) | |
Корректировки
Теперь мы объясним, как работает функция и как вносить корректировки. Ключевые аргументы представлены ниже:
by =
Вы можете стратифицировать свою таблицу по столбцу (например, по outcome), создав двухвходовую таблицу.
statistic =
Используйте уравнения, чтобы уточнить, какие статистические показатели показать и как их отобразить. В уравнении две стороны, разделенные тильдой ~. Справа в кавычках представлено желаемое статистическое отображение, а слева - столбцы, к которым будет применяться это отображение.
- Правая сторона уравнения использует синтаксис
str_glue()из stringr (см. [Текст и последовательности]), где желаемое отображение последовательности представлено в кавычках, а сами статистические показатели в фигурных скобках. Вы можете включить такие статистические показатели, как “n” (для подсчета количества), “N” (для знаменателя), “mean” (среднее), “median” (медиана), “sd” (стандартное отклонение), “max” (максимум), “min” (минимум), процентили в виде “p##”, например, “p25”, или процент от общего как “p”. См. детали в?tbl_summary.
- Для левой стороны уравнения вы можете указать столбцы по имени (например,
ageилиc(age, gender)), либо использовать функции-помощники, такие какall_continuous(),all_categorical(),contains(),starts_with()и т.п.
Простой пример уравнения statistic = может выглядеть следующим образом, он печатает только среднее значение по столбцу age_years:
linelist %>%
select(age_years) %>% # сохраняем только интересующие столбцы
tbl_summary( # создаем суммарную таблицу
statistic = age_years ~ "{mean}") # печать среднего значения по возрасту| Characteristic | N = 5,8881 |
|---|---|
| age_years | 16 |
| Unknown | 86 |
| 1 Mean | |
Чуть более сложное уравнение может выглядеть как "({min}, {max})", включая максимальное и минимальное значения внутри скобок, разделенное запятой:
linelist %>%
select(age_years) %>% # сохраняем только интересующие столбцы
tbl_summary( # создаем суммарную таблицу
statistic = age_years ~ "({min}, {max})") # печать минимума и максимума по возрасту| Characteristic | N = 5,8881 |
|---|---|
| age_years | (0, 84) |
| Unknown | 86 |
| 1 (Range) | |
Вы можете также дифференцировать синтаксис для отдельных столбцов или типов столбцов. В более сложном примере ниже, значение, указанное в statistc =, является списком, указывающим, что для всех непрерывных столбцов таблица должна напечатать среднее значение со стандартным отклонением в скобках, а для категориальных столбцов - напечатать n, знаменатель и процент.
digits =
Корректирует количество знаков и округление. Опционально, можно задать только для непрерывных столбцов (как ниже).
label =
Корректирует то, как должно отображаться имя столбца. Задайте имя столбца и желаемую подпись через тильду. По умолчанию будет имя столбца.
missing_text =
Корректирует, как отображаются отсутствующие значения. По умолчанию - “Unknown”.
type =
Используется для корректирования того, сколько уровней статистических показателей показывать. Синтаксис похож на statistic = в том, что вы задаете уравнение со столбцами слева и значением справа. Два частых сценария включают:
type = all_categorical() ~ "categorical"заставляет бинарные столбцы (например,feverда/нет) показывать все уровни, а не только строки “yes” (да)
type = all_continuous() ~ "continuous2"разрешает статистические показатели на несколько строк для переменной, как показано в более позднем разделе
В примере ниже каждый из этих аргументов используется для модификации оригинальной суммарной таблицы:
linelist %>%
select(age_years, gender, outcome, fever, temp, hospital) %>% # сохраняем только интересующие столбцы
tbl_summary(
by = outcome, # стратифицируем всю таблицу по исходам
statistic = list(all_continuous() ~ "{mean} ({sd})", # статистика и формат для непрерывных столбцов
all_categorical() ~ "{n} / {N} ({p}%)"), # статистика и формат для категориальных столбцов
digits = all_continuous() ~ 1, # округление для непрерывных столбцов
type = all_categorical() ~ "categorical", # заставляет отображать все категориальные уровни
label = list( # отображает подписи для имен столбцов
outcome ~ "Outcome",
age_years ~ "Age (years)",
gender ~ "Gender",
temp ~ "Temperature",
hospital ~ "Hospital"),
missing_text = "Missing" # как должны отображаться отсутствующие значения
)1323 observations missing `outcome` have been removed. To include these observations, use `forcats::fct_na_value_to_level()` on `outcome` column before passing to `tbl_summary()`.| Characteristic | Death, N = 2,5821 | Recover, N = 1,9831 |
|---|---|---|
| Age (years) | 15.9 (12.3) | 16.1 (13.0) |
| Missing | 32 | 28 |
| Gender | ||
| f | 1,227 / 2,455 (50%) | 953 / 1,903 (50%) |
| m | 1,228 / 2,455 (50%) | 950 / 1,903 (50%) |
| Missing | 127 | 80 |
| fever | ||
| no | 458 / 2,460 (19%) | 361 / 1,904 (19%) |
| yes | 2,002 / 2,460 (81%) | 1,543 / 1,904 (81%) |
| Missing | 122 | 79 |
| Temperature | 38.6 (1.0) | 38.6 (1.0) |
| Missing | 60 | 55 |
| Hospital | ||
| Central Hospital | 193 / 2,582 (7.5%) | 165 / 1,983 (8.3%) |
| Military Hospital | 399 / 2,582 (15%) | 309 / 1,983 (16%) |
| Missing | 611 / 2,582 (24%) | 514 / 1,983 (26%) |
| Other | 395 / 2,582 (15%) | 290 / 1,983 (15%) |
| Port Hospital | 785 / 2,582 (30%) | 579 / 1,983 (29%) |
| St. Mark's Maternity Hospital (SMMH) | 199 / 2,582 (7.7%) | 126 / 1,983 (6.4%) |
| 1 Mean (SD); n / N (%) | ||
Статистические показатели на нескольких строках для непрерывных переменных
Если вы хотите напечатать несколько строк статистики для непрерывных переменных, вы можете это указать путем установки type = на “continuous2”. Вы можете объединить все ранее показанные элементы в одну таблицу, выбрав, какие статистические показатели вы хотите показать. Чтобы это сделать, вам нужно сказать функции, что вы хотите получить назад таблицу, введя тип как “continuous2”. Количество отсутствующих значений показано как “Unknown”.
linelist %>%
select(age_years, temp) %>% # сохраняем только интересующие столбцы
tbl_summary( # создаем суммарную таблицу
type = all_continuous() ~ "continuous2", # указываем, что мы хотим напечатать несколько статистических показателей
statistic = all_continuous() ~ c(
"{mean} ({sd})", # строка 1: среднее и стандартное отклонение
"{median} ({p25}, {p75})", # строка 2: медиана и межквартильный диапазон IQR
"{min}, {max}") # строка 3: минимум и максимум
)| Characteristic | N = 5,888 |
|---|---|
| age_years | |
| Mean (SD) | 16 (13) |
| Median (IQR) | 13 (6, 23) |
| Range | 0, 84 |
| Unknown | 86 |
| temp | |
| Mean (SD) | 38.56 (0.98) |
| Median (IQR) | 38.80 (38.20, 39.20) |
| Range | 35.20, 40.80 |
| Unknown | 149 |
Существует множество другие способов для модификации этих таблиц, включая добавление p-значений, корректировку цвета и заголовков и т.п. Многие из них описаны в документации (введите ?tbl_summary в консоли), а некоторые приведены в разделе статистические тесты.
17.6 базовый R
Вы можете использовать функцию table(), чтобы выполнить табуляцию и кросс-табуляцию столбцов. В отличие от указанных выше вариантов, здесь нужно уточнять датафрейм каждый раз, когда вы ссылаетесь на имя столбца, как показано ниже.
ВНИМАНИЕ: NA (отсутствующие) значения не будут подсчитаны в табуляции, если вы не включите аргумент useNA = "always" (который может также быть задан как “no” или “ifany”).
СОВЕТ: Вы можете использовать %$% из magrittr, чтобы снять необходимость постоянного указания датафрейма в базовых функциях. Например, представленный ниже код можно записать как linelist %$% table(outcome, useNA = "always")
table(linelist$outcome, useNA = "always")
Death Recover <NA>
2582 1983 1323 Кросс-табуляцию нескольких столбцов можно сделать, указав их один за другим, отделив запятыми. Опционально вы можете также присвоить каждому столбцу “имя”, как Outcome = linelist$outcome.
age_by_outcome <- table(linelist$age_cat, linelist$outcome, useNA = "always") # сохраняем таблицу как объект
age_by_outcome # печать таблицы
Death Recover <NA>
0-4 471 364 260
5-9 476 391 228
10-14 438 303 200
15-19 323 251 169
20-29 477 367 229
30-49 329 238 187
50-69 33 38 24
70+ 3 3 0
<NA> 32 28 26Доли
Чтобы получить доли, передайте указанную выше таблицу в функцию prop.table(). Используйте аргумент margins = для уточнения того, хотите ли вы доли от строк (1), столбцов (2), либо всей таблицы (3). Для ясности мы передаем таблицу в функцию round() из базового R, уточнив 2 знака.
# получаем доли по определенной выше таблице по строкам, округленно
prop.table(age_by_outcome, 1) %>% round(2)
Death Recover <NA>
0-4 0.43 0.33 0.24
5-9 0.43 0.36 0.21
10-14 0.47 0.32 0.21
15-19 0.43 0.34 0.23
20-29 0.44 0.34 0.21
30-49 0.44 0.32 0.25
50-69 0.35 0.40 0.25
70+ 0.50 0.50 0.00
<NA> 0.37 0.33 0.30Итого
Чтобы добавить строки и таблицы “итого”, передайте таблицу в addmargins(). Это работает и для абсолютного количества, и для долей.
addmargins(age_by_outcome)
Death Recover <NA> Sum
0-4 471 364 260 1095
5-9 476 391 228 1095
10-14 438 303 200 941
15-19 323 251 169 743
20-29 477 367 229 1073
30-49 329 238 187 754
50-69 33 38 24 95
70+ 3 3 0 6
<NA> 32 28 26 86
Sum 2582 1983 1323 5888Конвертация в датафрейм
Конвертация объекта table() напрямую в датафрейм не такая простая. Один из подходов продемонстрирован ниже:
- Создаем таблицу без использования
useNA = "always". Вместо этого конвертируем значенияNAв “(Missing)” с помощьюfct_explicit_na()из forcats.
- Добавляем итого (опционально), передав в
addmargins()
- Передаем в функцию базового R
as.data.frame.matrix()
- Передаем таблицу в функцию из tibble
rownames_to_column(), уточнив имя для первого столбца
- Печатаем, просматриваем или экспортируем по желанию. В этом примере мы используем
flextable()из пакета flextable, как описано на странице [Таблицы для презентации]. Это напечатает в панели просмотра RStudio viewer красивое изображение в формате HTML.
table(fct_explicit_na(linelist$age_cat), fct_explicit_na(linelist$outcome)) %>%
addmargins() %>%
as.data.frame.matrix() %>%
tibble::rownames_to_column(var = "Age Category") %>%
flextable::flextable()Age Category | Death | Recover | (Missing) | Sum |
|---|---|---|---|---|
0-4 | 471 | 364 | 260 | 1,095 |
5-9 | 476 | 391 | 228 | 1,095 |
10-14 | 438 | 303 | 200 | 941 |
15-19 | 323 | 251 | 169 | 743 |
20-29 | 477 | 367 | 229 | 1,073 |
30-49 | 329 | 238 | 187 | 754 |
50-69 | 33 | 38 | 24 | 95 |
70+ | 3 | 3 | 0 | 6 |
(Missing) | 32 | 28 | 26 | 86 |
Sum | 2,582 | 1,983 | 1,323 | 5,888 |
17.7 Ресурсы
Значительная часть информации на данной странице взята из следующих онлайн ресурсов и виньеток: