
На этой странице представлен код для создания:
В этом фрагменте кода показана загрузка пакетов, необходимых для проведения анализа. В данном руководстве мы делаем акцент на функции p_load() из pacman, которая при необходимости устанавливает пакет и загружает его для использования. Установленные пакеты можно также загрузить с помощью library() из базового R. Более подробную информацию о пакетах R см. на странице Основы R.
pacman::p_load(
DiagrammeR, # для блок-схем
networkD3, # Для аллювиальных диаграмм/диаграмм Санкей
tidyverse) # управление данными и их визуализацияБольшая часть материалов этой страницы не требует набора данных. Однако в разделе, посвященном диаграмме Санкея, мы будем использовать построчный список случаев, полученных при моделировании эпидемии лихорадки Эбола. Если вы хотите проследить за этой частью, нажмите кнопку, чтобы загрузить “чистый” построчный список (в виде файла .rds). Импортируйте данные с помощью функции import() из пакета rio (она работает со многими типами файлов, такими как .xlsx, .csv, .rds - подробности см. на странице Импорт и экспорт).
# импорт построчного списка
linelist <- import("linelist_cleaned.rds")Ниже отображаются первые 50 строк построчного списка.
Для создания графиков/диаграмм можно использовать пакет R DiagrammeR. Они могут быть статичными или динамически изменяться в зависимости от изменений в наборе данных.
Инструменты
Функция grViz() используется для создания диаграммы “Graphviz”. Для создания диаграммы эта функция принимает последовательность символов, содержащую инструкции. Внутри этой строки инструкции написаны на другом языке, который называется DOT - его основы достаточно легко освоить.
Базовая структура
grViz(").digraph my_flow_chart {}")Ниже приведены два простых примера
Очень минимальный пример:
# минимальный график
DiagrammeR::grViz("digraph {
graph[layout = dot, rankdir = LR]
a
b
c
a -> b -> c
}")Пример, возможно, с более прикладным контекстом общественного здравоохранения:
grViz(" # Все инструкции находятся внутри большой последовательности символов,
digraph surveillance_diagram { # 'digraph' означает 'directional graph', а затем название графика,
# оператор графика
#################
graph [layout = dot,
rankdir = TB,
overlap = true,
fontsize = 10]
# узлы
#######
node [shape = circle, # форма = круг
fixedsize = true
width = 1.3] # ширина кругов
Primary # название узлов
Secondary
Tertiary
# ребра
#######
Primary -> Secondary [label = ' case transfer']
Secondary -> Tertiary [label = ' case transfer']
}
")Базовый синтаксис
Названия узлов, или выражения ребер, могут разделяться пробелами, точками с запятой или новой строкой.
Направление ранжирования
График может быть переориентирован для перемещения слева направо путем изменения аргумента rankdir в операторе графика. По умолчанию используется значение TB (сверху вниз), но может быть установлено значение LR (слева направо), RL или BT.
Названия узлов
Названия узлов могут состоять из одних слов, как в простом примере выше. Чтобы использовать многословные названия или специальные символы (например, круглые скобки, тире), заключите название узла в одинарные кавычки (’ ’). Возможно, проще иметь короткое название узла и назначить ему метку, как показано ниже в скобках [ ]. Если в названии узла требуется поставить новую строку, то это нужно сделать через метку - используйте \n в метке узла в одинарных кавычках, как показано ниже.
Подгруппы
Внутри выражений ребер можно создавать подгруппы по обе стороны от ребра с помощью фигурных скобок ({ }). В этом случае ребро применяется ко всем узлам в скобках - это сокращение.
Расположение
rankdir в значение TB, LR, RL, BT, )Узлы - редактируемые атрибуты
label (текст, в одинарных кавычках, если многословный)fillcolor (множество возможных цветов)fontcoloralpha (прозрачность 0-1)shape (эллипс, овал, ромб, яйцо, простой текст, точка, квадрат, треугольник)stylesidesperipheriesfixedsize (h x w)heightwidthdistortionpenwidth (ширина границы фигуры)x (смещение влево/вправо)y (смещение вверх/вниз)fontnamefontsizeiconРебра - редактируемые атрибуты.
arrowsizearrowhead (нормальный, коробка, ворона, кривая, алмаз, точка, inv, никакой, tee, vee)arrowtaildir (направление, )style (пунктир, …)coloralphaheadport (текст перед стрелкой)tailport (текст за хвостом стрелки)fontnamefontsizefontcolor(ширина стрелки)minlen (минимальная длина)Названия цветов: шестнадцатеричные значения или названия цветов ‘X11’, см. подробно о X11
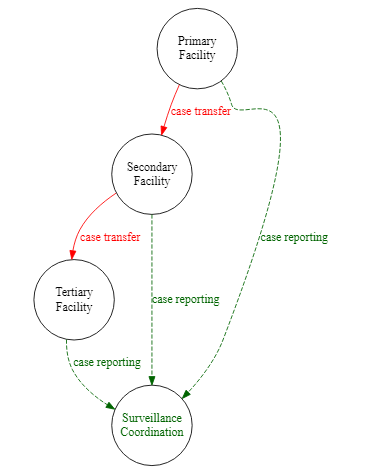
Приведенный ниже пример описывает диаграмму surveillance_diagram, добавляя сложные названия узлов, сгруппированные ребра, цвета и стилистику
DiagrammeR::grViz(" # Все инструкции находятся внутри большой последовательности символов
digraph surveillance_diagram { # 'digraph' означает 'directional graph', после него название графика
# выражения графика
#################
graph [layout = dot,
rankdir = TB, # расположение сверху вниз
fontsize = 10]
# узлы (круги)
#################
node [shape = circle, # форма = круг
fixedsize = true
width = 1.3]
Primary [label = 'Primary\nFacility']
Secondary [label = 'Secondary\nFacility']
Tertiary [label = 'Tertiary\nFacility']
SC [label = 'Surveillance\nCoordination',
fontcolor = darkgreen]
# ребра
#######
Primary -> Secondary [label = ' case transfer',
fontcolor = red,
color = red]
Secondary -> Tertiary [label = ' case transfer',
fontcolor = red,
color = red]
# сгруппированные ребра
{Primary Secondary Tertiary} -> SC [label = 'case reporting',
fontcolor = darkgreen,
color = darkgreen,
style = dashed]
}
")Кластеры подграфика
Чтобы сгруппировать узлы в кластеры с рамками, поместите их в подграфик с одинаковым названием (subgraph name {}). Для того чтобы каждый подграфик был идентифицирован в пределах ограничительной рамки, начните название подграфика с “cluster”, как показано на 4 блоках ниже.
DiagrammeR::grViz(" # Все инструкции находятся внутри большой последовательности символов
digraph surveillance_diagram { # 'digraph' означает 'directional graph', после него название графика
# выражения графика
#################
graph [layout = dot,
rankdir = TB,
overlap = true,
fontsize = 10]
# узлы (круги)
#################
node [shape = circle, # форма = круг
fixedsize = true
width = 1.3] # ширина кругов
subgraph cluster_passive {
Primary [label = 'Primary\nFacility']
Secondary [label = 'Secondary\nFacility']
Tertiary [label = 'Tertiary\nFacility']
SC [label = 'Surveillance\nCoordination',
fontcolor = darkgreen]
}
# узлы (квадраты)
###############
node [shape = box, # форма узла
fontname = Helvetica] # шрифт текста в узле
subgraph cluster_active {
Active [label = 'Active\nSurveillance']
HCF_active [label = 'HCF\nActive Search']
}
subgraph cluster_EBD {
EBS [label = 'Event-Based\nSurveillance (EBS)']
'Social Media'
Radio
}
subgraph cluster_CBS {
CBS [label = 'Community-Based\nSurveillance (CBS)']
RECOs
}
# ребра
#######
{Primary Secondary Tertiary} -> SC [label = 'case reporting']
Primary -> Secondary [label = 'case transfer',
fontcolor = red]
Secondary -> Tertiary [label = 'case transfer',
fontcolor = red]
HCF_active -> Active
{'Social Media' Radio} -> EBS
RECOs -> CBS
}
")
Формы узлов
В приведенном ниже примере, заимствованном из этого пособия, показаны применяемые формы узлов и сокращенное обозначение последовательных соединений ребер
DiagrammeR::grViz("digraph {
graph [layout = dot, rankdir = LR]
# определить глобальные стили узлов. При желании мы можем изменить их в блоке
node [shape = rectangle, style = filled, fillcolor = Linen]
data1 [label = 'Dataset 1', shape = folder, fillcolor = Beige]
data2 [label = 'Dataset 2', shape = folder, fillcolor = Beige]
process [label = 'Process \n Data']
statistical [label = 'Statistical \n Analysis']
results [label= 'Results']
# определения ребер с идентификаторами узлов
{data1 data2} -> process -> statistical -> results
}")Как работать с выходными данными и сохранять их
Вот цитата из этого учебника: https://mikeyharper.uk/flowcharts-in-r-using-diagrammer/
“Параметризованные рисунки: Большим преимуществом проектирования рисунков в R является то, что мы можем напрямую связать рисунки с нашим анализом, считывая значения R непосредственно в наши блок-схемы. Например, если вы создали процесс фильтрации, который удаляет значения после каждого этапа процесса, вы можете показать на рисунке количество значений, оставшихся в наборе данных после каждого этапа вашего процесса. Для этого можно использовать символ @@X непосредственно в рисунке, а затем сослаться на него в нижнем колонтитуле графика, используя [X]:, где X - уникальный числовой индекс.”
Мы рекомендуем вам ознакомиться с этим учебным пособием, если параметризация представляет для вас интерес.
В этом фрагменте кода показана загрузка пакетов, необходимых для проведения анализа. В данном руководстве мы делаем акцент на функции p_load() из pacman, которая при необходимости устанавливает пакет и загружает его для использования. Установленные пакеты можно также загрузить с помощью library() из базового R. Более подробную информацию о пакетах R см. на странице [Основы R].
Мы загружаем пакет networkD3 для создания диаграммы, а также пакет tidyverse для подготовки данных.
pacman::p_load(
networkD3,
tidyverse)Построение графика связей в наборе данных. Ниже мы продемонстрируем использование этого пакета на примере linelist. Вот [онлайн-учебник] (https://www.r-graph-gallery.com/321-introduction-to-interactive-sankey-diagram-2.html).
Начнем с того, что получим количество случаев для каждой уникальной комбинации возрастной категории и больницы. Для наглядности мы удалили значения с отсутствующей возрастной категорией. Мы также переименовали столбцы hospital и age_cat в источник и цель соответственно. Это будут две стороны аллювиальной диаграммы.
# подсчеты по больницам и возрастным категориям
links <- linelist %>%
drop_na(age_cat) %>%
select(hospital, age_cat) %>%
count(hospital, age_cat) %>%
rename(source = hospital,
target = age_cat)Теперь набор данных выглядит следующим образом:
Теперь мы создаем датафрейм из всех узлов диаграммы по столбцу name. Он состоит из всех значений для hospital и age_cat. Обратите внимание, что перед объединением мы убеждаемся в том, что все они относятся к классу Символы. и настраиваем столбцы ID так, чтобы они были числами, а не метками:
# Уникальные названия узлов
nodes <- data.frame(
name=c(as.character(links$source), as.character(links$target)) %>%
unique()
)
nodes # печать name
1 Central Hospital
2 Military Hospital
3 Missing
4 Other
5 Port Hospital
6 St. Mark's Maternity Hospital (SMMH)
7 0-4
8 5-9
9 10-14
10 15-19
11 20-29
12 30-49
13 50-69
14 70+Далее мы редактируем датафрейм links, который мы создали выше с помощью count(). Добавим два числовых столбца IDsource и IDtarget, которые, собственно, и будут отражать/создавать связи между узлами. В этих столбцах будут храниться номера строк (позиции) исходного и целевого узлов. Чтобы номера позиций начинались с 0 (а не с 1), из них вычитается 1.
# сопоставлять с числами, а не с именами
links$IDsource <- match(links$source, nodes$name)-1
links$IDtarget <- match(links$target, nodes$name)-1Теперь набор данных связей выглядит следующим образом:
Теперь постройте диаграмму Санкей с помощью функции sankeyNetwork(). Подробнее о каждом аргументе можно узнать, выполнив команду ?sankeyNetwork в консоли. Обратите внимание, что если не задать iterations = 0, то порядок следования узлов может быть не таким, как ожидалось.
# график
######
p <- sankeyNetwork(
Links = links,
Nodes = nodes,
Source = "IDsource",
Target = "IDtarget",
Value = "n",
NodeID = "name",
units = "TWh",
fontSize = 12,
nodeWidth = 30,
iterations = 0) # обеспечить порядок расположения узлов в соответствии с данными
pПриведем пример, в котором также включен исход пациента. Обратите внимание, что на этапе подготовки данных нам необходимо подсчитать количество случаев по возрасту и больнице, а также отдельно по больнице и исходу, а затем связать все эти подсчеты вместе с помощью bind_rows().
# подсчеты по больницам и возрастным категориям
age_hosp_links <- linelist %>%
drop_na(age_cat) %>%
select(hospital, age_cat) %>%
count(hospital, age_cat) %>%
rename(source = age_cat, # переименовать
target = hospital)
hosp_out_links <- linelist %>%
drop_na(age_cat) %>%
select(hospital, outcome) %>%
count(hospital, outcome) %>%
rename(source = hospital, # переименовать
target = outcome)
# объединить связи
links <- bind_rows(age_hosp_links, hosp_out_links)
# Уникальные названия узлов
nodes <- data.frame(
name=c(as.character(links$source), as.character(links$target)) %>%
unique()
)
# Создание идентификаторов
links$IDsource <- match(links$source, nodes$name)-1
links$IDtarget <- match(links$target, nodes$name)-1
# график
######
p <- sankeyNetwork(Links = links,
Nodes = nodes,
Source = "IDsource",
Target = "IDtarget",
Value = "n",
NodeID = "name",
units = "TWh",
fontSize = 12,
nodeWidth = 30,
iterations = 0)
phttps://www.displayr.com/sankey-diagrams-r/
Для создания временной шкалы, показывающей конкретные события, можно использовать пакет vistime.
См. виньетка
# загрузка пакета
pacman::p_load(vistime, # создать временную шкалу
plotly # для интерактивной визуализации
)Вот набор данных событий, с которого мы начинаем:
p <- vistime(data) # применить vistime
library(plotly)
# шаг 1: преобразование в список
pp <- plotly_build(p)
# шаг 2: Размер маркера
for(i in 1:length(pp$x$data)){
if(pp$x$data[[i]]$mode == "markers") pp$x$data[[i]]$marker$size <- 10
}
# шаг 3: размер текста
for(i in 1:length(pp$x$data)){
if(pp$x$data[[i]]$mode == "text") pp$x$data[[i]]$textfont$size <- 10
}
# шаг 4: расположение текста
for(i in 1:length(pp$x$data)){
if(pp$x$data[[i]]$mode == "text") pp$x$data[[i]]$textposition <- "right"
}
#печать
ppВы можете построить DAG вручную, используя пакет DiagammeR и язык DOT, как описано выше.
В качестве альтернативы существуют такие пакеты, как ggdag и daggity.
Введение в DAGs ggdag vignette
[Причинно-следственные выводы с использованием dags в R].(https://www.r-bloggers.com/2019/08/causal-inference-with-dags-in-r/#:~:text=In%20a%20DAG%20all%20the,for%20drawing%20and%20analyzing%20DAGs.)
Многое из изложенного выше по языку DOT взято из учебника сайт.
Другой, более подробный учебник по диаграммам
Эта страница, посвященная вопросу диаграмма Санкей