## загрузка пакетов из CRAN
pacman::p_load(rio, # импорт файлов
here, # поиск пути к файлу
tidyverse, # управление данными + графики ggplot2
tsibble, # работа с наборами данных с временными рядами
survey, # для функций опровос
srvyr, # надстройка dplyr для пакета survey
gtsummary, # надстройка для пакета survey для создания таблиц
apyramid, # пакет, предназначенный для создания возрастных пирамид
patchwork, # для объединения графиков ggplots
ggforce # для аллювиальных графиков/диаграмм Санкей
)
## загружаем пакеты из github
pacman::p_load_gh(
"R4EPI/sitrep" # для времени наблюдения/функций взвешивания
)26 Анализ опросов
26.1 Обзор
На этой странице мы демонстрируем использование нескольких пакетов для анализа опросов.
Большинство пакетов для опросов R полагаются на пакет survey для проведения взвешенного анализа. Мы используем survey, а также srvyr (надстройка для survey, позволяющая кодировать в стиле tidyverse) и gtsummary (надстройка для survey, позволяющая создавать готовые к публикации таблицы). Хотя оригинальный пакет survey не позволяет кодировать в стиле tidyverse, у него есть дополнительные преимущества в том, что он позволяет создавать взвешенные по опросу обобщенные линейные модели модели (которые будут добавлены на эту страницу позже). Мы также продемонстрируем использование функции из пакета sitrep, чтобы создать веса выборки (примечание этого пакета пока нет в CRAN, но его можно установить из github).
Большая часть этой страницы основана на работе, сделанной для проекта “R4Epis”; для получения деталей кода и шаблонов R-markdown см. эту страницу “R4Epis”. Некоторая часть кода на основе пакета survey основана на более ранних версиях кейсов EPIET.
В настоящее время на этой странице не рассматриваются вопросы расчета размера выборки или процессы выборки. Простой калькулятор размера выборки можно найти в OpenEpi. На странице Основы ГИС руководства позднее появится раздел по пространственной случайной выборке, а на этой странице позднее будет раздел по основам для построения выборки, а также расчету размера выборки.
- Данные опроса
- Время наблюдения
- Веса
- Объекты дизайна опроса
- Описательный анализ
- Взвешенные доли
- Взвешенные коэффициенты
26.2 Подготовка
Пакеты
Данный фрагмент кода показывает загрузку пакетов, необходимых для анализа. В данном руководстве мы фокусируемся на использовании p_load() из пакета pacman, которая устанавливает пакет, если необходимо, и загружает его для использования. Вы можете также загрузить установленные пакеты с помощью library() из базового R. См. страницу [Основы R] для получения дополнительной информации о пакетах R. Здесь мы также демонстрируем использование функции p_load_gh() из пакета pacman, чтобы установить и загрузить пакет из github, который еще не опубликован в CRAN.
Загрузка данных
Пример набора данных, используемый в данном разделе:
- выдуманные данные по исследованию смертности
- выдуманные данные о населении по обследуемому району
- словарь данных для выдуманных данных по исследованию смертности.
Это основано на предварительно одобренном этическим советом MSF OCA исследовании. Выдуманный набор данных был подготовлен в рамках проекта “R4Epis”. Это все основано на данных, собранных с помощью KoboToolbox, которая является программой для сбора данных на основе Open Data Kit.
Kobo позволяет вам экспортировать и собранные данные, и словарь данных для этого набора данных. Мы настоятельно это рекомендуем, так как это упрощает вычистку данных и полезно для поиска переменных/вопросов.
СОВЕТ: Словарь данных в Kobo содержит имена переменных в столбце “name” на листе survey (опрос). Возможные значения для каждой переменной уточняются на листе choices (варианты). Во вкладке “choices” имя “name” имеет сокращенную версию и столбцы “label::english” и “label::french” с соответствующими длинными версиями. Использование функции msf_dict_survey() из пакета epidict для импорта
файла excel со словарем из Kobo переформатирует его, чтобы его было легко использовать для перекодирования.
ВНИМАНИЕ: Пример набора данных не совпадает с экспортом (так как в Kobo вы экспортируете разные уровни вопросов отдельно) - см. раздел данные опросов ниже, чтобы объединить разные уровни.
Импортируем набор данных с помощью функции import() из пакета rio. См. страницу Импорт и экспорт, где описаны разные способы импорта данных.
# импортируем данные опроса
survey_data <- rio::import("survey_data.xlsx")
# импортируем словарь в R
survey_dict <- rio::import("survey_dict.xlsx") Первые 10 строк опроса отображены ниже.
Мы также хотим импортировать данные о выборочной совокупности, чтобы мы могли создать соответствующие веса. Эти данные могут быть в разных форматах, однако мы предлагаем иметь их в формате, показанном ниже (это можно просто напечатать в excel).
# импорт данныхы о населении
population <- rio::import("population.xlsx")Первые 10 строк опроса отображены ниже.
Для кластерных опросов вам может потребоваться добавить веса опроса на уровне кластера. Вы можете прочитать эти данные в программу, как указано выше. Альтернативно, если количество небольшое, их можно ввести в таблицу tibble, как это сделано ниже. В любом случае вам потребуется один столбец с идентификатором кластера, который совпадает с вашими данными опроса, и еще один столбец с количеством домохозяйств в каждом кластере.
## определяем количество домохозяйств в каждом кластере
cluster_counts <- tibble(cluster = c("village_1", "village_2", "village_3", "village_4",
"village_5", "village_6", "village_7", "village_8",
"village_9", "village_10"),
households = c(700, 400, 600, 500, 300,
800, 700, 400, 500, 500))Вычистка данных
Ниже мы проверяем, что столбец даты находится в правильном формате. Существует еще несколько способов это сделать (см. детали на странице Работа с датами), однако использование словаря для определения дат является быстрым и легким способом.
Мы также создаем переменную возрастной группы, используя функцию age_categories() из epikit - см. детали в разделе руководства Вычистка данных. Кроме того, мы создаем текстовую переменную, определяющую каждый район, в котором находятся разные кластеры.
Наконец мы перекодируем все переменные yes/no (да/нет) в переменные TRUE/FALSE (ИСТИНА/ЛОЖЬ) - иначе их нельзя будет применить в долевых функциях survey.
## выбираем имена переменной даты из словаря
DATEVARS <- survey_dict %>%
filter(type == "date") %>%
filter(name %in% names(survey_data)) %>%
## фильтруем, чтобы сопоставить с именами столбцов в ваших данных
pull(name) # выбираем переменные дат
## меняем на даты
survey_data <- survey_data %>%
mutate(across(all_of(DATEVARS), as.Date))
## добавляем тех, у кого возраст только в месяцах, к переменной года (делим на 12)
survey_data <- survey_data %>%
mutate(age_years = if_else(is.na(age_years),
age_months / 12,
age_years))
## определяем переменную возрастной группы
survey_data <- survey_data %>%
mutate(age_group = age_categories(age_years,
breakers = c(0, 3, 15, 30, 45)
))
## создаем текстовую переменную на основе групп другой переменной
survey_data <- survey_data %>%
mutate(health_district = case_when(
cluster_number %in% c(1:5) ~ "district_a",
TRUE ~ "district_b"
))
## выбираем имена переменных с да/нет (yes/no) из словаря
YNVARS <- survey_dict %>%
filter(type == "yn") %>%
filter(name %in% names(survey_data)) %>%
## фильтруем, чтобы сопоставить с именами столбцов ваших данных
pull(name) # выбираем переменные да/нет
## меняем на даты
survey_data <- survey_data %>%
mutate(across(all_of(YNVARS),
str_detect,
pattern = "yes"))Warning: There was 1 warning in `mutate()`.
ℹ In argument: `across(all_of(YNVARS), str_detect, pattern = "yes")`.
Caused by warning:
! The `...` argument of `across()` is deprecated as of dplyr 1.1.0.
Supply arguments directly to `.fns` through an anonymous function instead.
# Previously
across(a:b, mean, na.rm = TRUE)
# Now
across(a:b, \(x) mean(x, na.rm = TRUE))26.3 Данные опроса
Существует ряд разных дизайнов выборки для опроса. Здесь мы продемонстрируем код для: - стратифицированной - кластерной - стратифицированной и кластерной
Как описано выше (в зависимости от того, как вы составите анкету), данные для каждого уровня будут экспортированы в виде отдельного набора данных из Kobo. В нашем примере есть один уровень для домохозяйств и один уровень для отдельных лиц в этих домохозяйствах.
Эти два уровня связаны уникальным идентификатором. Для набора данных Kobo этой переменной является “_index” на уровне домохозяйства, который соответствует “_parent_index” на индивидуальном уровне. Это создаст новые строки для домохозяйства с соответствующим индивидом, см. детали в разделе руководства Соединение данных.
## соединяем индивидуальные данные и домохозяйства для получения полного набора данных
survey_data <- left_join(survey_data_hh,
survey_data_indiv,
by = c("_index" = "_parent_index"))
## создаем уникальный идентификатор, объединяя индексы двух уровней
survey_data <- survey_data %>%
mutate(uid = str_glue("{index}_{index_y}"))26.4 Время наблюдения
Для исследований смертности нам нужно знать, как долго каждый человек присутствовал в этом месте, чтобы рассчитать соответствующий коэффицент смертности для интересующего нас периода. Это важно не для всех исследований, но очень важно для исследований смертности, поскольку они часто проводятся среди мобильного или вынужденно переселенного населения.
Чтобы это сделать, мы сначала определяем интересующий период, также известный как период оценки/памяти (т.е. время, которое участники вспоминают при ответе на вопросы). Мы можем использовать этот период, чтобы задать неподходящие даты, как отсутствующие, т.е. если смерти зарегистрированы за пределами интересующего периода.
## задаем дату начала/окончания периода оценки
## можно изменить на переменную даты из набора данных
## (т.е. дата прибытия и дата вопросника)
survey_data <- survey_data %>%
mutate(recall_start = as.Date("2018-01-01"),
recall_end = as.Date("2018-05-01")
)
# задаем неподходящие даты как NA на основе правил
## например, прибытие до начала, отбытие после окончания
survey_data <- survey_data %>%
mutate(
arrived_date = if_else(arrived_date < recall_start,
as.Date(NA),
arrived_date),
birthday_date = if_else(birthday_date < recall_start,
as.Date(NA),
birthday_date),
left_date = if_else(left_date > recall_end,
as.Date(NA),
left_date),
death_date = if_else(death_date > recall_end,
as.Date(NA),
death_date)
)Мы можем затем использовать наши переменные даты, чтобы задать даты начала и окончания для каждого лица. Мы можем использовать функцию find_start_date() из sitrep, чтобы найти причины для дат и затем использовать их, чтобы рассчитать разницу между днями (человеко-время).
дата начала: Самое раннее подходящее событие прибытия в периоде оценки Либо начало вашего периода оценки (которое вы определяете заранее), либо дата после начала периода оценки, если применимо (например, прибытие или рождение)
дата окончания: Самая ранняя подходящее событие выбытия в вашем периоде оценки Либо окончание периода оценки, либо дата до окончания периода оценки, если применимо (например, отбытие, смерть)
## создаем новые переменные для дат начала и окончания/причин
survey_data <- survey_data %>%
## выбираем самую раннюю дату, введенную в опрос
## из рождения, прибытия в домохозяйство, прибытия в лагерь
find_start_date("birthday_date",
"arrived_date",
period_start = "recall_start",
period_end = "recall_end",
datecol = "startdate",
datereason = "startcause"
) %>%
## выбираем самую раннюю дату, введенную в опрос
## из отбытия из лагеря, смерти, окончания исследования
find_end_date("left_date",
"death_date",
period_start = "recall_start",
period_end = "recall_end",
datecol = "enddate",
datereason = "endcause"
)
## подпишите те, которые присутствовали в начале/конце (кроме рождения/смерти)
survey_data <- survey_data %>%
mutate(
## заполним дату начала как начало периода оценки (для пустых полей)
startdate = if_else(is.na(startdate), recall_start, startdate),
## задаем стартовую причину для представления в начале, если она равна периоду оценки
## кроме случаев, когда она равна дате рождения
startcause = if_else(startdate == recall_start & startcause != "birthday_date",
"Present at start", startcause),
## заполняем дату окончания как окончание периода оценки (для пустых полей)
enddate = if_else(is.na(enddate), recall_end, enddate),
## задаем причину окончания для представления в конце, если равна периоду оценки
## кроме случаев, когда она равна дате смерти
endcause = if_else(enddate == recall_end & endcause != "death_date",
"Present at end", endcause))
## Определяем время наблюдения в днях
survey_data <- survey_data %>%
mutate(obstime = as.numeric(enddate - startdate))26.5 Взвешивание
Важно отбросить ошибочные наблюдения до добавления весов в опрос. Например, если у вас есть наблюдения с отрицательным временем наблюдения, вам нужно их проверить (вы можете это сделать с помощью функции assert_positive_timespan() из пакета sitrep). Другой вопрос, если вы хотите отбросить пустые строки (например, с помощью drop_na(uid)) или удалить дубликаты (см. детали в разделе руководства [Дедупликация]). Тех, кто не дал согласие, также нужно отбросить.
В данном примере мы фильтруем случаи, которые мы хотим удалить, и сохраняем их в отдельном датафрейме - таким образом мы можем описать тех, кто был исключен из исследования. Затем мы используем функцию anti_join() из dplyr, чтобы удалить эти отброшенные случаи из данных опроса.
ВНИМАНИЕ: Не допускается наличие отсутствующих значений в переменной веса или в любой другой переменной, относящейся к дизайну исследования (например, возраст, пол, стратовые или кластерные переменные).
## сохраняем случаи, которые вы отбросили, чтобы вы могли их описать (например, не давшие согласия,
## или из неправильной деревни/кластера)
dropped <- survey_data %>%
filter(!consent | is.na(startdate) | is.na(enddate) | village_name == "other")
## используем отброшенные случаи, чтобы удалить неиспользуемые строки из набора данных опроса
survey_data <- anti_join(survey_data, dropped, by = names(dropped))Как уже было сказано выше, мы демонстрируем, как добавлять веса для трех различных дизайнов исследования (стратифицированного, кластерного и стратифицированного кластерного). Для этого требуется информация об исходной популяции и/или обследованных кластерах. В данном примере мы будем использовать код стратифицированного кластера, но используйте тот вариант, который является наиболее подходящим для вашего дизайна исследования.
# стратифицированный ------------------------------------------------------------------
# создаем переменную под названием "surv_weight_strata"
# содержит веса для каждого индивида - по возрастной группе, полу и медицинскому району
survey_data <- add_weights_strata(x = survey_data,
p = population,
surv_weight = "surv_weight_strata",
surv_weight_ID = "surv_weight_ID_strata",
age_group, sex, health_district)
## кластерный ---------------------------------------------------------------------
# получите количество лиц, проинтервьюированных в каждом домохозяйстве
# добвляет переменную с подсчетом переменной индекса домохозяйства (родителя)
survey_data <- survey_data %>%
add_count(index, name = "interviewed")
## создаем веса для кластера
survey_data <- add_weights_cluster(x = survey_data,
cl = cluster_counts,
eligible = member_number,
interviewed = interviewed,
cluster_x = village_name,
cluster_cl = cluster,
household_x = index,
household_cl = households,
surv_weight = "surv_weight_cluster",
surv_weight_ID = "surv_weight_ID_cluster",
ignore_cluster = FALSE,
ignore_household = FALSE)
# стратифицированный и кластерный ------------------------------------------------------
# создаем вес опроса для кластера и страт
survey_data <- survey_data %>%
mutate(surv_weight_cluster_strata = surv_weight_strata * surv_weight_cluster)26.6 Объекты дизайна опроса
Создаем объект исследования согласно вашему дизайну исследования. Используется таким же образом, как датафреймы для рассчета весовых долей и т.п. Убедитесь, что до этого созданы все необходимые переменные.
Существует 4 опции, выделите как комментарии те, которые вы не используете: - простая случайная - стратифицированная - кластерная - стратифицированная кластерная
Для данного шаблона мы представим, что мы кластеризовали опросы по двум отдельным стратам (медицинские районы A и B). Чтобы получить общие оценки, нам нужны скомбинированные веса кластера и страт.
Как упоминалось ранее, для этого есть два пакета. Классический пакет - survey, а также есть пакет-надстройка под названием srvyr, которые создает подходящие для tidyverse объекты и функции. Мы продемонстрируем оба варианта, но обратите внимание, что большая часть кода в этой главе будет использовать объекты на основе srvyr. Единственное исключение - пакет gtsummary принимает только объекты survey.
26.6.1 Пакет Survey
Пакет survey по сути использует кодирование из базового R, поэтому невозможно использовать операторы канала (%>%) или другой синтаксис dplyr. С пакетом survey мы используем функцию svydesign() для определения объекта опроса с соответствующими кластерами, весами и стратами.
ПРИМЕЧАНИЕ: нам нужно использовать тильду (~) перед переменным, поскольку пакет использует синтаксис базового R с присвоением переменных на основе формул.
# простая случайная ---------------------------------------------------------------
base_survey_design_simple <- svydesign(ids = ~1, # 1 для отсутствия кластерных ids
weights = NULL, # не добавляются веса
strata = NULL, # выборка была простой (без страт)
data = survey_data # нужно уточнить набор данных
)
## стратифицированная ------------------------------------------------------------------
base_survey_design_strata <- svydesign(ids = ~1, # 1 для отсутствия кластерных ids
weights = ~surv_weight_strata, # переменная веса, созданная выше
strata = ~health_district, # выборка была стратифицирована по районам
data = survey_data # нужно уточнить набор данных
)
# кластерная ---------------------------------------------------------------------
base_survey_design_cluster <- svydesign(ids = ~village_name, # ids кластера
weights = ~surv_weight_cluster, # переменная веса, созданная выше
strata = NULL, # выборка была простой (без страт)
data = survey_data # нужно уточнить набор данных
)
# стратифицированная кластерная ----------------------------------------------------------
base_survey_design <- svydesign(ids = ~village_name, # ids кластера
weights = ~surv_weight_cluster_strata, # переменная веса, созданная выше
strata = ~health_district, # выборка стратифицирована по району
data = survey_data # нужно уточнить набор данных
)26.6.2 Пакет Srvyr
С пакетом srvyr мы можем использовать функцию as_survey_design(), у которой имеются все те же аргументы, что и выше, но она допускает операторы канала (%>%), и тогда нам не нужно использовать тильду (~).
## простая случайная ---------------------------------------------------------------
survey_design_simple <- survey_data %>%
as_survey_design(ids = 1, # 1 для отсутствия кластерных ids
weights = NULL, # без добавления весов
strata = NULL # выборка простая (без страт)
)
## стратифицированная ------------------------------------------------------------------
survey_design_strata <- survey_data %>%
as_survey_design(ids = 1, # 1 для отсутствия кластерных ids
weights = surv_weight_strata, # переменная веса, созданная выше
strata = health_district # выборка была стратифицирована по району
)
## кластерная ---------------------------------------------------------------------
survey_design_cluster <- survey_data %>%
as_survey_design(ids = village_name, # ids кластеров
weights = surv_weight_cluster, # переменная веса, созданная выше
strata = NULL # выборка простая (без страт)
)
## стратифицированная кластерная ----------------------------------------------------------
survey_design <- survey_data %>%
as_survey_design(ids = village_name, # cluster ids
weights = surv_weight_cluster_strata, # переменная веса, созданная выше
strata = health_district # выборка была стратифицирована по району
)26.7 Описательный анализ
Основы описательного анализа и визуализация рассматриваются детально в других главах руководства, поэтому мы не будем на них здесь останавливаться. Детали можно найти в главах Описательные таблицы, Статистические тесты, Таблицы для презентации, Основы ggplot and Отчеты с помощью R markdown.
В этом разделе мы сосредоточимся на том, как исследовать ошибки в выборке и визуализировать их. Мы также рассмотрим визуализацию потоков населения в условиях исследования с помощью аллювиальных диаграмм/диаграмм Санки.
В целом, следует рассмотреть возможность включения нижеследующих видов описательного анализа:
- Итоговое количество включенных кластеров, домохозяйств и лиц
- Количество исключенных лиц и причины исключения
- Медианное (диапазон) значение домохозяйств на кластер и индивидов на домохозяйство
26.7.1 Систематическая ошибка выборки
Сравните доли в каждой возрастной группе между вашей выборкой и исходной популяцией. Это важно для выявления возможной систематической ошибки выборки. Аналогичным образом можно повторить этот процесс, рассматривая распределение по полу.
Обратите внимание, что эти p-значения являются лишь ориентировочными, а описательное обсуждение (или визуализация с помощью возрастных пирамид ниже) распределений в исследуемой выборке по сравнению с исходной популяцией более важна, чем сам биномиальный тест. Это связано с тем, что увеличение размера выборки чаще всего приводит к различиям, которые могут оказаться неважными после взвешивания данных.
## количество и доли в исследуемой популяции
ag <- survey_data %>%
group_by(age_group) %>%
drop_na(age_group) %>%
tally() %>%
mutate(proportion = n / sum(n),
n_total = sum(n))
## количество и доли в исходной популяции
propcount <- population %>%
group_by(age_group) %>%
tally(population) %>%
mutate(proportion = n / sum(n))
## свяжите столбцы двух таблиц, сгруппируйте по возрасту и проведите
## биномиальный тест, чтобы увидеть, значительно ли отличается n/итого от доли в популяции.
## суффикс добавляется к тексту в конце столбцов в каждом из двух наборов данных
left_join(ag, propcount, by = "age_group", suffix = c("", "_pop")) %>%
group_by(age_group) %>%
## broom::tidy(binom.test()) создает датафрейм из биномиального теста и
## добавит переменные p.value (p значение), parameter (параметр), conf.low (дов.ниж), conf.high (дов.верх), method (метод), и
## альтернативы. Мы здесь используем только p.value. Вы можете включить други столбцы,
## если вы хотите показать доверительные интервалы
mutate(binom = list(broom::tidy(binom.test(n, n_total, proportion_pop)))) %>%
unnest(cols = c(binom)) %>% # важно для расширения датафрейма биномиального теста
mutate(proportion_pop = proportion_pop * 100) %>%
## корректируем p-значенияы, чтобы скорректировать ложно-положительные
## (поскольку тестируются несколько возрастных групп). Это будет что-то менять, только если у вас
## много возрастных категорий
mutate(p.value = p.adjust(p.value, method = "holm")) %>%
## Показываем только p-значения больше 0.001 (те, которые меньше, показываем как <0.001)
mutate(p.value = ifelse(p.value < 0.001,
"<0.001",
as.character(round(p.value, 3)))) %>%
## переименовываем столбцы соответствующим образом
select(
"Age group" = age_group,
"Study population (n)" = n,
"Study population (%)" = proportion,
"Source population (n)" = n_pop,
"Source population (%)" = proportion_pop,
"P-value" = p.value
)# A tibble: 5 × 6
# Groups: Age group [5]
`Age group` `Study population (n)` `Study population (%)`
<chr> <int> <dbl>
1 0-2 12 0.0256
2 3-14 42 0.0896
3 15-29 64 0.136
4 30-44 52 0.111
5 45+ 299 0.638
# ℹ 3 more variables: `Source population (n)` <dbl>,
# `Source population (%)` <dbl>, `P-value` <chr>26.7.2 Демографические пирамиды
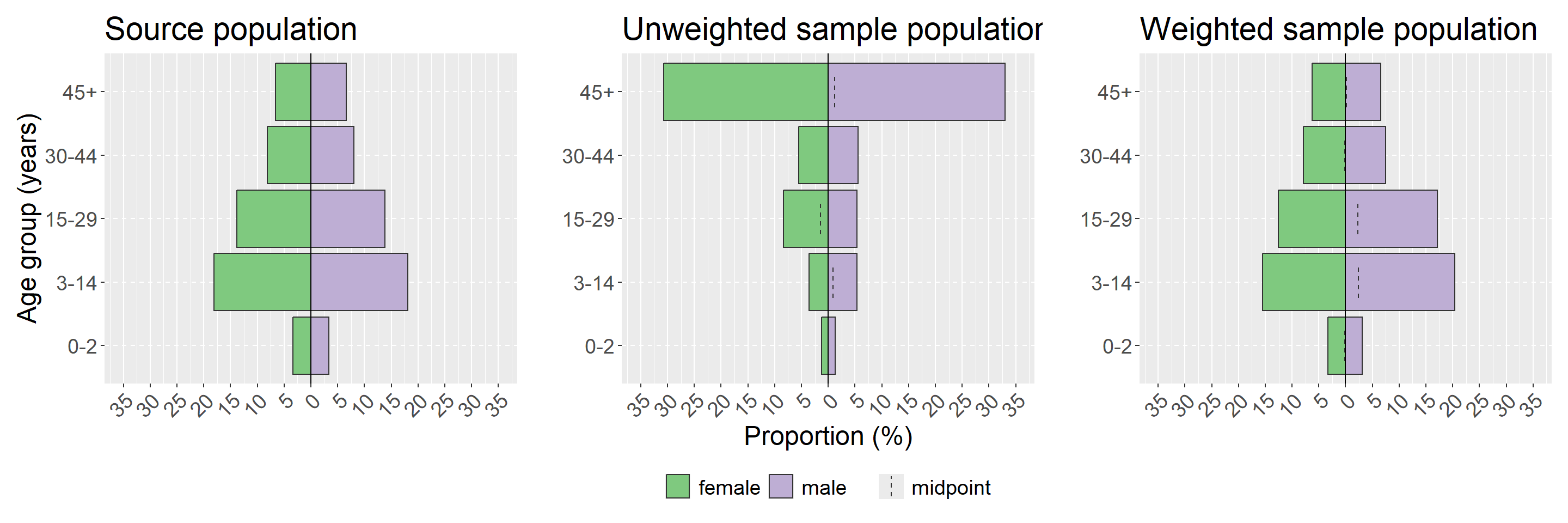
Демографические (или половозрастные) пирамиды являются простым способом визуализации распределения в вашей исследуемой популяции. Также рассмотрите возможность создания описательных таблиц возраста и пола по стратам опроса. Мы продемонстрируем использование пакета apyramid, так как он допускает взвешенные доли, используя объект дизайна опроса, созданный выше. Другие опции создания демографических пирамид детально рассматриваются в этой главе руководства. Мы также используем функцию-надстройку из apyramid под названием age_pyramid(), которая сохраняет несколько строк кода для создания графика с долями.
Как и в случае с формальным биномиальным тестом на разницу, рассмотренным выше в разделе о систематической ошибке выборки, здесь нас интересует визуализация того, существенно ли наша выборочная совокупность отличается от исходной и корректирует ли взвешивание эту разницу. Чтобы это сделать, нам нужно использовать пакет patchwork, чтобы показать наши визуализации ggplot рядом; дополнительную информацию см. в разделе по объединению графиков в главе руководства Советы по использованию ggplot. Мы будем визуализировать нашу исходную популяцию, нашу невзвешенную исследуемую популяцию и нашу взвешенную исследуемую популяцию. Вы можете также рассмотреть возможность визуализации каждой страты вашего опроса - в нашем примере это будет сделано с помощью аргумента stack_by = "health_district" (см. детали в ?plot_age_pyramid).
ПРИМЕЧАНИЕ: В пирамидах оси x и y меняются местами
## определяем пределы и подписи оси x ---------------------------------------------
## (обновляем эти цифры так, чтобы они были значениям для вашего графика)
max_prop <- 35 # выбираем самую высокую долю, которую вы хотите показать
step <- 5 # выбираем пространство между подписями, которое вам нужно
## эта часть определяет вектор, используя указанные выше цифры, с разрывами оси
breaks <- c(
seq(max_prop/100 * -1, 0 - step/100, step/100),
0,
seq(0 + step / 100, max_prop/100, step/100)
)
## эта часть определяет вектор, используя указанные выше цифры, с пределами оси
limits <- c(max_prop/100 * -1, max_prop/100)
## эта часть определяет вектор, используя указанные выше цифры, с подписями осей
labels <- c(
seq(max_prop, step, -step),
0,
seq(step, max_prop, step)
)
## создаем графики отдельно --------------------------------------------------
## строим график исходной популяции
## примечание: этот показатель должен быть рассчитан для всего населения (т.е. удаляем медицинские районы)
source_population <- population %>%
## проверяем, что возраст и пол заданы как факторы
mutate(age_group = factor(age_group,
levels = c("0-2",
"3-14",
"15-29",
"30-44",
"45+")),
sex = factor(sex)) %>%
group_by(age_group, sex) %>%
## складываем количества для каждого медицинского округа
summarise(population = sum(population)) %>%
## удаляем группирование, чтобы можно было рассчитать общую долю
ungroup() %>%
mutate(proportion = population / sum(population)) %>%
## строим пирамиду
age_pyramid(
age_group = age_group,
split_by = sex,
count = proportion,
proportional = TRUE) +
## показываем только подпись оси y (иначе будет повторена на всех трех графиках)
labs(title = "Source population",
y = "",
x = "Age group (years)") +
## делаем ось x одинаковой для всех графиков
scale_y_continuous(breaks = breaks,
limits = limits,
labels = labels)
## строим график выборочной совокупности без весов
sample_population <- age_pyramid(survey_data,
age_group = "age_group",
split_by = "sex",
proportion = TRUE) +
## показываем только подпись оси x (иначе будет повторена на всех трех графиках)
labs(title = "Unweighted sample population",
y = "Proportion (%)",
x = "") +
## делаем ось x одинаковой для всех графиков
scale_y_continuous(breaks = breaks,
limits = limits,
labels = labels)
## строим график выборочной совокупности с весами
weighted_population <- survey_design %>%
## убедитесь, что переменные - факторы
mutate(age_group = factor(age_group),
sex = factor(sex)) %>%
age_pyramid(
age_group = "age_group",
split_by = "sex",
proportion = TRUE) +
## показываем только подпись оси x (иначе будет повторена на всех трех графиках)
labs(title = "Weighted sample population",
y = "",
x = "") +
## делаем ось x одинаковой для всех графиков
scale_y_continuous(breaks = breaks,
limits = limits,
labels = labels)
## объединяем все три графика ----------------------------------------------------
## комбинируем три графика друг рядом с друга, используя +
source_population + sample_population + weighted_population +
## показываем только одну легенду и задаем тему
## обратите внимание на использование & для объединения темы с plot_layout()
plot_layout(guides = "collect") &
theme(legend.position = "bottom", # перемещаем легенду вниз
legend.title = element_blank(), # убираем заголовок
text = element_text(size = 18), # меняем размер текста
axis.text.x = element_text(angle = 45, hjust = 1, vjust = 1) # поворачиваем текст на оси x
)
26.7.3 Аллювиальный график/диаграмма Санкей
Визуализация начальных точек и результатов для отдельных людей может быть очень полезной для получения общей картины. Вполне очевидным является их применение для мобильных популяций, Однако существует множество других применений, например, в когортах или в любой другой ситуации. где существуют переходы между состояниями индивидуумов. Эти диаграммы имеют несколько различных названий, включая аллювиальные, Санкей и параллельные множества - подробности приведены в главе руководства Диаграммы и схемы.
## обобщаем данные
flow_table <- survey_data %>%
count(startcause, endcause, sex) %>% # получаем подсчет
gather_set_data(x = c("startcause", "endcause")) # меняем формат для создания диаграммы
## создаем график для набора данных
## на оси x - причины начала и окончания
## gather_set_data генерирует ID для каждой возможной комбинации
## разделение по y дает возможные комбинации начала/окончания
## value (значение) как n представляет в виде количества (можно также изменить на долю)
ggplot(flow_table, aes(x, id = id, split = y, value = n)) +
## цвета линий по полу
geom_parallel_sets(aes(fill = sex), alpha = 0.5, axis.width = 0.2) +
## заливка прямоугольников с подписями серым
geom_parallel_sets_axes(axis.width = 0.15, fill = "grey80", color = "grey80") +
## меняем цвет и угол текста (необходимо корректировать)
geom_parallel_sets_labels(color = "black", angle = 0, size = 5) +
## удаляем подписи осей
theme_void()+
## перемещаем легенду вниз
theme(legend.position = "bottom") 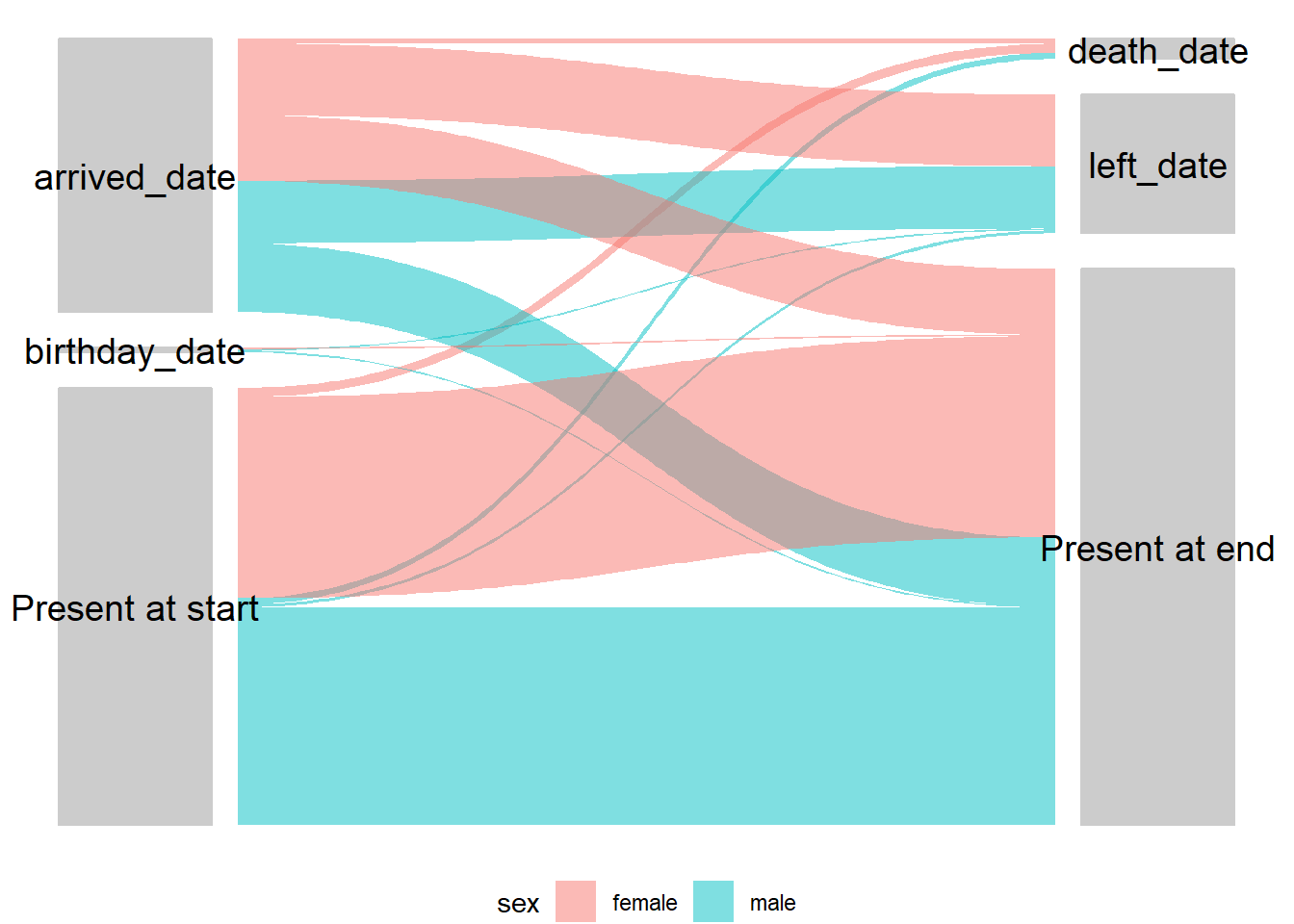
26.8 Взвешенные доли
В этом разделе мы подробно рассмотрим, как создавать таблицы для взвешенных подсчетов и долей, с соответствующими доверительными интервалами и дизайн-эффектом. Существует четыре варианта, использующих функции из следующих пакетов: survey, srvyr, sitrep и gtsummary. Чтобы с минимальным кодированием создать таблицу в стандартном для эпидемиологии стиле,
мы бы рекомендовали функцию sitrep - которая является надстройкой для кода srvyr; обратите внимание, однако, что ее еще нет в CRAN, и она может измениться в будущем. В противном случае наиболее стабильным в долгосрочной перспективе, скорее всего, будет код survey, а srvyr лучше всего встроится в рабочие потоки в tidyverse. Хотя у функций gtsummary есть большой потенциал, они кажутся экспериментальными и неполными на момент написания руководства.
26.8.1 Пакет Survey
Мы можем использовать функцию svyciprop() из survey, чтобы получить взвешенные доли и соответствующие 95% доверительные интервалы. Соответствующий дизайн-эффект можно извлечь, используя функцию svymean() вместо svyprop(). Необходимо отметить, что, как представляется, svyprop() допускает только значения между 0 и 1 (или TRUE/FALSE - ИСТИНА/ЛОЖЬ), так что категориальные переменные не сработают.
ПРИМЕЧАНИЕ: Функции из survey также принимают объекты дизайна srvyr, но здесь мы для последовательности использовали объект дизайна survey
## создаем взвешенный подсчет
svytable(~died, base_survey_design)died
FALSE TRUE
1406244.43 76213.01 ## создаем взвешенные доли
svyciprop(~died, base_survey_design, na.rm = T) 2.5% 97.5%
died 0.0514 0.0208 0.12## получаем дизайн-эффект
svymean(~died, base_survey_design, na.rm = T, deff = T) %>%
deff()diedFALSE diedTRUE
3.755508 3.755508 Мы можем объединить функции из survey, показанные выше, в функцию, которую мы сами определим ниже под названием svy_prop; и мы можем затем использовать эту функцию вместе с map() из пакета purrr для итерации по нескольким переменным и создания таблицы. См. главу руководства по итерациям для получения дополнительной информации о purrr.
# определим функцию для расчета взвешенного количества, долей, ДИ и дизайн-эффекта
# x - переменная в кавычках
# design - ваш объект дизайна опроса
svy_prop <- function(design, x) {
## поместим интересующую переменную в формулу
form <- as.formula(paste0( "~" , x))
## сохраним только столбец подсчета из svytable с TRUE
weighted_counts <- svytable(form, design)[[2]]
## рассчитаем доли (умножим на 100 для получения процентов)
weighted_props <- svyciprop(form, design, na.rm = TRUE) * 100
## извлекаем доверительные интервалы и умножаем, чтобы получить проценты
weighted_confint <- confint(weighted_props) * 100
## используем svymean для расчета дизайн-эффекта и сохраняем только столбец с TRUE
design_eff <- deff(svymean(form, design, na.rm = TRUE, deff = TRUE))[[TRUE]]
## объединяем в один датафрейм
full_table <- cbind(
"Variable" = x,
"Count" = weighted_counts,
"Proportion" = weighted_props,
weighted_confint,
"Design effect" = design_eff
)
## выдаем таблицу в виде датафрейма
full_table <- data.frame(full_table,
## удаляем имена переменных из строк (теперь отдельный столбец)
row.names = NULL)
## меняем числа на числовые
full_table[ , 2:6] <- as.numeric(full_table[, 2:6])
## выдаем датафрейм
full_table
}
## проводим итерацию по нескольким переменным, чтобы создать таблицу
purrr::map(
## определяем интересующую переменную
c("left", "died", "arrived"),
## указываем функцию, используя аргументы для данной функции (дизайн)
svy_prop, design = base_survey_design) %>%
## преобразовываем список в один датафрейм
bind_rows() %>%
## округляем
mutate(across(where(is.numeric), round, digits = 1)) Variable Count Proportion X2.5. X97.5. Design.effect
1 left 701199.1 47.3 39.2 55.5 2.4
2 died 76213.0 5.1 2.1 12.1 3.8
3 arrived 761799.0 51.4 40.9 61.7 3.926.8.2 Пакет Srvyr
В srvyr мы можем использовать синтаксис dplyr, чтобы создать таблицу. Обратите внимание, что используется функция survey_mean() и уточняется аргумент доли, а также та же функция используется для расчета дизайн-эффекта. Это происходит потому, что srvyr является надстройкой для обеих функций пакета survey svyciprop() и svymean(), которые используются в разделе выше.
ПРИМЕЧАНИЕ: Кажется, невозможно получить доли из категориальных переменных, используя и srvyr, если вам они нужны, посмотрите раздел ниже по использованию sitrep
## используем объект дизайна srvyr
survey_design %>%
summarise(
## получаем взвешенное количество
counts = survey_total(died),
## получаем взвешенные доли и доверительные интервалы
## умножаем на 100, чтобы получить проценты
props = survey_mean(died,
proportion = TRUE,
vartype = "ci") * 100,
## получаем дизайн-эффект
deff = survey_mean(died, deff = TRUE)) %>%
## сохраняем только интересующие строки
## (отбрасываем стандартные ошибки и повторяем расчет долей)
select(counts, props, props_low, props_upp, deff_deff)# A tibble: 1 × 5
counts props props_low props_upp deff_deff
<dbl> <dbl> <dbl> <dbl> <dbl>
1 76213. 5.14 2.08 12.1 3.76Здесь мы также можем написать функцию для проведения итераций по нескольким переменным, используя пакет purrr. См. руководство, главу итерации для получения детальной информации о purrr.
# Определяем функцию для расчета взвешенного количества, долей, ДИ и дизайн-эффекта
# design - ваш объект дизайна опроса
# x - переменная в кавычках
srvyr_prop <- function(design, x) {
summarise(
## используя объект дизайна опроса
design,
## получаем взвешенное количество
counts = survey_total(.data[[x]]),
## получаем взвешенные доли и доверительные интервалы
## умножаем на 100, чтобы получить процент
props = survey_mean(.data[[x]],
proportion = TRUE,
vartype = "ci") * 100,
## получаем дизайн-эффект
deff = survey_mean(.data[[x]], deff = TRUE)) %>%
## добавляем имя переменной
mutate(variable = x) %>%
## сохраняем только интересующие строки
## (отбрасываем стандартные ошибки и повторяем расчет долей)
select(variable, counts, props, props_low, props_upp, deff_deff)
}
## проводим итерацию по нескольким переменным, чтобы создать таблицу
purrr::map(
## определяем интересующие переменные
c("left", "died", "arrived"),
## указываем функцию, используя аргументы для этой функции (дизайн)
~srvyr_prop(.x, design = survey_design)) %>%
## трансформируем список в один датафрейм
bind_rows()# A tibble: 3 × 6
variable counts props props_low props_upp deff_deff
<chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 left 701199. 47.3 39.2 55.5 2.38
2 died 76213. 5.14 2.08 12.1 3.76
3 arrived 761799. 51.4 40.9 61.7 3.9326.8.3 Пакет Sitrep
Функция tab_survey() из sitrep является надстройкой для srvyr, которая позволяет вам создавать взвешенные таблицы с минимальным кодом. Она также позволяет вам рассчитывать взвешенные доли для категориальных переменных.
## используем объект дизайна опроса
survey_design %>%
## передаем имена интересующих переменных без кавычек
tab_survey(arrived, left, died, education_level,
deff = TRUE, # рассчитываем дизайн-эффект
pretty = TRUE # объединяем долю и 95% ДИ
)Warning: removing 257 missing value(s) from `education_level`# A tibble: 9 × 5
variable value n deff ci
<chr> <chr> <dbl> <dbl> <chr>
1 arrived TRUE 761799. 3.93 51.4% (40.9-61.7)
2 arrived FALSE 720658. 3.93 48.6% (38.3-59.1)
3 left TRUE 701199. 2.38 47.3% (39.2-55.5)
4 left FALSE 781258. 2.38 52.7% (44.5-60.8)
5 died TRUE 76213. 3.76 5.1% (2.1-12.1)
6 died FALSE 1406244. 3.76 94.9% (87.9-97.9)
7 education_level higher 171644. 4.70 42.4% (26.9-59.7)
8 education_level primary 102609. 2.37 25.4% (16.2-37.3)
9 education_level secondary 130201. 6.68 32.2% (16.5-53.3)26.8.4 Пакет Gtsummary
В gtsummary нет еще встроенных функций для добавления доверительных интервалов или дизайн-эффекта. Здесь мы покажем, как определить функцию для добавления доверительных интервалов, затем добавим доверительные интервалы в таблицу gtsummary, используя функцию tbl_svysummary().
confidence_intervals <- function(data, variable, by, ...) {
## извлекаем доверительные интервалы и умножаем, чтобы получить проценты
props <- svyciprop(as.formula(paste0( "~" , variable)),
data, na.rm = TRUE)
## извлекаем доверительные интервалы
as.numeric(confint(props) * 100) %>% ## делаем числовым и умножаем для получения процентов
round(., digits = 1) %>% ## округляем до одного знака
c(.) %>% ## извлекаем числа из матрицы
paste0(., collapse = "-") ## объединяем в один символ
}
## используем объект дизайна пакета survey
tbl_svysummary(base_survey_design,
include = c(arrived, left, died), ## определяем переменные, которые хотим включить
statistic = list(everything() ~ c("{n} ({p}%)"))) %>% ## определяем интересующую статистику
add_n() %>% ## добавляем взвешенный итог
add_stat(fns = everything() ~ confidence_intervals) %>% ## добавляем ДИ
## изменяем заголовки столбцов
modify_header(
list(
n ~ "**Weighted total (N)**",
stat_0 ~ "**Weighted Count**",
add_stat_1 ~ "**95%CI**"
)
)| Characteristic | Weighted total (N) | Weighted Count1 | 95%CI |
|---|---|---|---|
| arrived | 1,482,457 | 761,799 (51%) | 40.9-61.7 |
| left | 1,482,457 | 701,199 (47%) | 39.2-55.5 |
| died | 1,482,457 | 76,213 (5.1%) | 2.1-12.1 |
| 1 n (%) | |||
26.9 Взвешенные коэффициенты
Аналогично, для взвешенных коэффициентов (например, коэффициентов смертности), вы можете использовать пакет survey или srvyr. Вы могли бы аналогичным образом написать функции (похожие на представленные выше), чтобы провести итерацию по нескольким переменным. Вы также могли бы создать функцию для gtsummary, как выше, но пока нет встроенного функционала.
26.9.1 Пакет Survey
ratio <- svyratio(~died,
denominator = ~obstime,
design = base_survey_design)
ci <- confint(ratio)
cbind(
ratio$ratio * 10000,
ci * 10000
) obstime 2.5 % 97.5 %
died 5.981922 1.194294 10.7695526.9.2 Пакет Srvyr
survey_design %>%
## коэффициент survey ratio используется, чтобы учесть время наблюдения
summarise(
mortality = survey_ratio(
as.numeric(died) * 10000,
obstime,
vartype = "ci")
)# A tibble: 1 × 3
mortality mortality_low mortality_upp
<dbl> <dbl> <dbl>
1 5.98 0.349 11.6