![]()
4 Transition vers R
Nous vous proposons ci-dessous quelques conseils et ressources si vous êtes en train de passer à R.
R a été introduit à la fin des années 1990 et a depuis pris une ampleur considérable. Ses capacités sont si étendues que les alternatives commerciales ont réagi aux développements de R afin de rester compétitives! (lire cet article comparant R, SPSS, SAS, STATA et Python).
En outre, R est beaucoup plus facile à apprendre qu’il y a dix ans. Auparavant, R avait la réputation d’être difficile pour les débutants. C’est désormais beaucoup plus facile grâce à des interfaces utilisateur conviviales comme RStudio, à un code intuitif comme le tidyverse et à de nombreuses ressources didactiques.
Ne vous sentez pas intimidé - venez découvrir le monde de R!
4.1 De Excel
Passer directement d’Excel à R est un objectif tout à fait réalisable. Cela peut sembler décourageant, mais vous pouvez le faire!
Il est vrai qu’une personne ayant de solides compétences en Excel peut effectuer des activités très avancées dans Excel seul - même en utilisant des outils de script comme VBA. Excel est utilisé dans le monde entier et constitue un outil essentiel pour un épidémiologiste. Cependant, le compléter avec R peut améliorer et étendre considérablement vos méthodes de travail.
Bénéfices
Vous constaterez que l’utilisation de R offre d’immenses avantages en termes de gain de temps, d’analyses plus cohérentes et plus précises, de reproductibilité, de partage et de correction plus rapide des erreurs. Comme tout nouveau logiciel, il y a une “courbe” d’apprentissage dans laquelle vous devez investir du temps pour vous familiariser. Les bénéfices seront significatifs et un immense champ de nouvelles possibilités s’ouvrira à vous avec R.
Excel est un logiciel bien connu qui peut être facile à utiliser pour un débutant afin de produire des analyses et des visualisations simples par “pointer-cliquer”. En comparaison, il faut parfois quelques semaines pour se familiariser avec les fonctions et l’interface de R. Cependant, R a évolué au cours des dernières années pour devenir beaucoup plus facile à utiliser pour les débutants.
De nombreux flux de travail Excel reposent sur la mémoire et la répétition - les risques d’erreur sont donc nombreux. En outre, le nettoyage des données, la méthodologie d’analyse et les équations utilisées sont généralement cachés. Un nouveau collègue peut avoir besoin de beaucoup de temps pour apprendre ce que fait un classeur Excel et comment le réparer. Avec R, toutes les étapes sont explicitement écrites dans le script et peuvent être facilement visualisées, modifiées, corrigées et appliquées à d’autres ensembles de données.
Pour commencer votre transition d’Excel à R, vous devez adapter votre état d’esprit sur quelques points importants:
Données ordonnées (“Tidy” data)
Utilisez des données “ordonnées” lisibles par une machine plutôt que des données désordonnées “lisibles par l’homme”. Il existe trois exigences principales pour les données “ordonnées”, comme l’explique ce tutoriel “tidy” data avec R:
- Chaque variable doit avoir sa propre colonne
- Chaque observation doit avoir sa propre ligne
- Chaque valeur doit avoir sa propre cellule
Aux utilisateurs d’Excel - pensez au rôle que les tableaux Excel jouent pour normaliser les données et rendre le format plus compréhensible.
Un exemple de données “ordonnées” serait la liste linéaire (linelist) utilisée dans ce manuel - chaque variable est contenue dans une colonne, chaque observation (un cas) a sa propre ligne, et chaque valeur est dans une seule cellule. Ci-dessous, vous pouvez visualiser les 50 premières lignes de la liste linéaire.:
La principale raison pour laquelle on rencontre des données non ordonnées est que de nombreuses feuilles de calcul Excel sont conçues pour être lues facilement par des humains et non par des machines/logiciels.
Pour vous aider à voir la différence, voici quelques exemples fictifs de données non ordonnées qui privilégient la lisibilité humaine à la lisibilité machine.:

Problèmes: Dans la feuille de calcul ci-dessus, il y a des cellules fusionnées qui ne sont pas facilement digérées par R. La ligne qui doit être considérée comme “l’en-tête” n’est pas claire. Un dictionnaire basé sur les couleurs se trouve à droite et les valeurs des cellules sont représentées par des couleurs - ce qui n’est pas non plus facilement interprété par R (ni par les humains atteints de daltonisme !). En outre, différents éléments d’information sont combinés dans une seule cellule (plusieurs organisations partenaires travaillant dans un même domaine, ou le statut ” à confirmer ” dans la même cellule que ” partenaire D “).
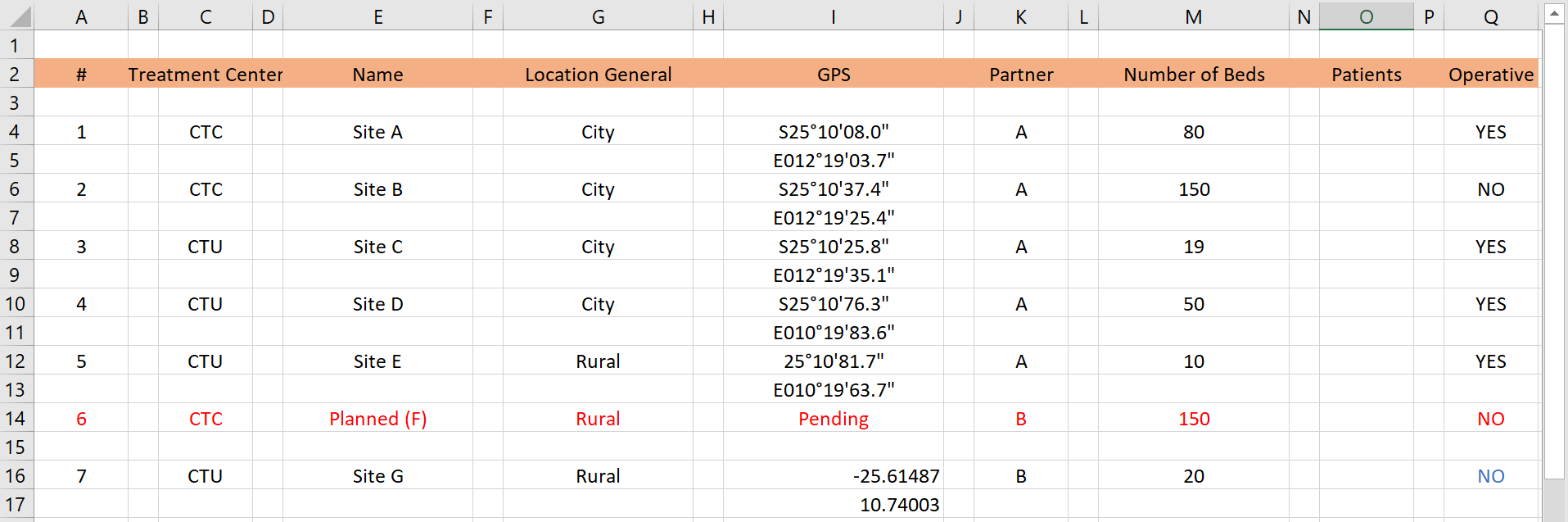
Problèmes: Dans la feuille de calcul ci-dessus, il y a de nombreuses lignes et colonnes vides supplémentaires dans l’ensemble de données - cela causera des problèmes de nettoyage dans R. De plus, les coordonnées GPS sont réparties sur deux lignes pour un centre de traitement donné. Par ailleurs, les coordonnées GPS sont dans deux formats différents!
Les ensembles de données “ordonnées” ne sont peut-être pas aussi lisibles à l’œil nu, mais ils facilitent grandement le nettoyage et l’analyse des données ! Les données ordonnées peuvent être stockées sous différents formats, par exemple “long” ou “large” (voir la page sur les Données pivotées), mais les principes ci-dessus sont toujours respectés.
Functions
Le mot “fonction” en R est peut-être nouveau, mais le concept existe aussi dans Excel sous la forme de formules. Les formules dans Excel requièrent également une syntaxe précise (par exemple, le placement des points-virgules et des parenthèses). Tout ce que vous avez à faire est d’apprendre quelques nouvelles fonctions et comment elles fonctionnent ensemble dans R.
Scripts
Au lieu de cliquer sur des boutons et de faire glisser des cellules, vous allez écrire chaque étape et procédure dans un “script”. Les utilisateurs d’Excel connaissent peut-être les “macros VBA” qui utilisent également une approche de script.
Le script R est constitué d’instructions étape par étape, ce qui permet à tout collègue de lire le script et de voir facilement les étapes que vous avez suivies. Cela permet également de corriger les erreurs ou les calculs imprécis. Voir la section Bases de R sur les scripts pour des exemples.
Voici un exemple de script R:
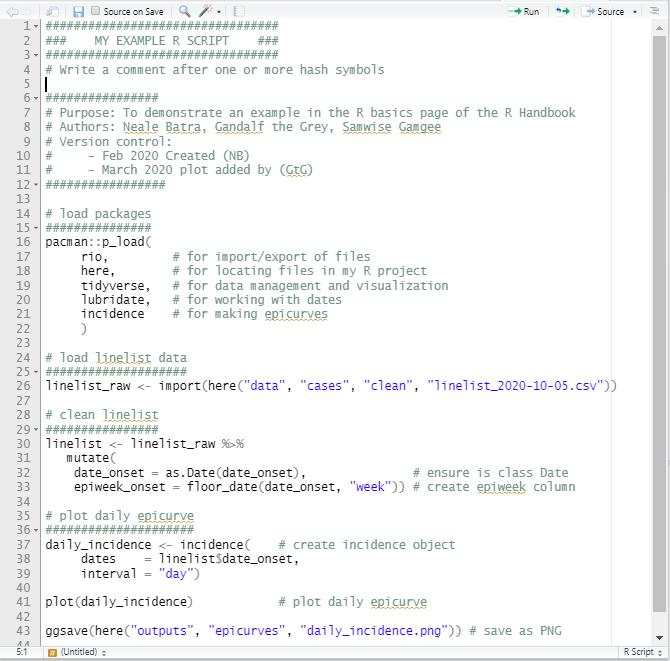
Ressources Excel à R
Voici quelques liens vers des tutoriels pour vous aider à passer d’Excel à R:
Intéraction R-Excel
R dispose de moyens robustes pour importer des classeurs Excel, travailler avec les données, exporter/enregistrer des fichiers Excel et travailler avec les nuances des feuilles Excel.
Il est vrai que certaines des mises en forme Excel les plus esthétiques peuvent se perdre dans la traduction (par exemple, l’italique, le texte latéral, etc.). Si votre flux de travail nécessite le passage de documents entre R et Excel tout en conservant le formatage Excel original, essayez des packages comme openxlsx.
4.2 De Stata
Passer de Stata à R
De nombreux épidémiologistes apprennent d’abord à utiliser Stata, et le passage à R peut sembler intimidant. Cependant, si vous êtes un utilisateur de Stata à l’aise, le passage à R est certainement plus facile à gérer que vous ne le pensez. Bien qu’il existe quelques différences essentielles entre Stata et R dans la façon dont les données peuvent être créées et modifiées, ainsi que dans la façon dont les fonctions d’analyse sont mises en œuvre - après avoir appris ces différences clés, vous serez en mesure de traduire vos compétences.
Vous trouverez ci-dessous quelques traductions clés entre Stata et R, qui pourront vous être utiles lors de la lecture de ce guide.
Notes générales
| STATA | R |
|---|---|
| Vous ne pouvez visualiser et manipuler qu’un seul ensemble de données à la fois | Vous pouvez visualiser et manipuler plusieurs ensembles de données en même temps, vous devrez donc fréquemment spécifier votre ensemble de données dans le code |
| Communauté en ligne disponible via https://www.statalist.org/ | Communauté en ligne disponible via RStudio, StackOverFlow, et R-bloggers |
| Fonctionnalité “pointer et cliquer” en option | Fonctionnalité minimale de type “pointer-cliquer” |
Aide pour les commandes disponibles avec help [command] |
Aide disponible avec [function]? ou effectuer une recherche dans le volet d’aide (Help) |
| Commenter le code avec * ou /// ou /* TEXTE */ | Commenter le code avec # |
| Presque toutes les commandes sont intégrées à Stata. Les fonctions nouvelles/écrites par l’utilisateur peuvent être installées en tant que fichiers ado en utilisant ssc install[package] | R s’installe avec les fonctions de base, mais l’utilisation typique implique l’installation d’autres packages à partir de CRAN (voir la page sur les bases de R). |
| L’analyse est généralement écrite dans un fichier do | Analyse écrite dans un script R dans le panneau source de RStudio. Les scripts R markdown sont une alternative. |
Le fichier d’accès au travail
| STATA | R |
|---|---|
| Les répertoires d’un travail impliquent des chemins d’accès aux fichiers absolus (e.x. “C:/utilisateur/documents/projets/data/”) | Les répertoires d’un travail peuvent être soit absolus, soit relatifs au dossier racine du projet en utilisant le package here (voir Import et export) |
| Voir le répertoire où se trouve le travail actuel avec pwd | Utilisez getwd() ou here() (si vous utilisez le package here), avec des parenthèses vides |
| Définir le répertoire de travail avec cd “emplacement du dossier” | Utilisez setwd(“emplacement du dossier”), ou set_here("emplacement du dossier) (si le package here est utilisé) |
Importation et visualisation des données
| STATA | R |
|---|---|
| Commandes spécifiques par type de fichier | Utilisez import() du package rio pour presque tous les types de fichiers. Des fonctions spécifiques existent comme alternatives (voir Import et export) |
| La lecture des fichiers csv se fait par import delimited “nomdufichier.csv” | Utilisez import("nomdufichier.csv") |
| La lecture des fichiers xslx se fait par import excel “nomdufichier.xlsx” | Utilisez import("nomdufichier.xlsx") |
| Parcourez vos données dans une nouvelle fenêtre en utilisant la commande browse | Visualisez un ensemble de données dans le volet source de RStudio en utilisant View(dataset). Vous devez spécifier le nom de votre ensemble de données à la fonction dans R car plusieurs ensembles de données peuvent être maintenus en même temps. Notez le “V” majuscule dans cette fonction |
| Obtenez une vue d’ensemble de votre ensemble de données à l’aide de summarize, qui fournit les noms des variables et les informations de base | Obtenez une vue d’ensemble de votre ensemble de données à l’aide de summary(dataset) |
Manipulation de données de base
| STATA | R |
|---|---|
| Les colonnes des ensembles de données sont fréquemment appelées “variables” | Plus souvent appelés “colonnes” ou parfois “vecteurs” ou “variables” |
| Il n’est pas nécessaire de spécifier l’ensemble de données | Dans chacune des commandes ci-dessous, vous devez spécifier l’ensemble de données - voir la page Nettoyage des données et des fonctions de base pour des exemples |
| Les nouvelles variables sont créées à l’aide de la commande generate varname = | Générez de nouvelles variables en utilisant la fonction mutate(varname = ). Voir la page Nettoyage des données et des fonctions de base pour des détails sur les fonctions dplyr. |
| Les variables sont renommées en utilisant rename nouveau_nom ancien_nom | Les colonnes peuvent être renommées à l’aide de la fonction rename(nouveau_nom = ancien_nom) |
| Les variables sont supprimées en utilisant drop nom_variable | Les colonnes peuvent être supprimées en utilisant la fonction select() avec le nom de la colonne dans les parenthèses suivant un signe moins |
| Les variables factorielles peuvent être étiquetées en utilisant une série de commandes telles que label define | L’étiquetage des valeurs peut se faire en convertissant la colonne en classe de facteurs et en spécifiant des niveaux. Voir la page sur Facteurs. Les noms de colonnes ne sont pas typiquement étiquetés comme ils le sont dans Stata. |
Analyse descriptive
| STATA | R |
|---|---|
| Mettre en tableau les effectifs d’une variable en utilisant tab nom_variable | Fournissez l’ensemble de données et le nom de la colonne à table() tel que table(ensemble_de_données$nomcolonne). Vous pouvez également utiliser count(nom_variable) du package dplyr, comme expliqué dans Regroupement des données. |
| Le tableau croisé de deux variables dans un tableau 2x2 se fait avec tab nom_variable1 nom_variable2 | Utilisez table(ensemble_de_données$nom_variable1, ensemble_de_données$nom_variable2 ou count(nom_variable1, nom_variable2) |
Bien que cette liste donne un aperçu des bases de la conversion des commandes Stata en R, elle n’est pas complète. Il existe de nombreuses autres ressources intéressantes pour les utilisateurs de Stata qui passent à R:
- https://dss.princeton.edu/training/RStata.pdf
- https://clanfear.github.io/Stata_R_Equivalency/docs/r_stata_commands.html
- http://r4stats.com/books/r4stata/
4.3 De SAS
Passer de SAS à R
SAS est couramment utilisé dans les agences de santé publique et les domaines de recherche universitaires. Bien que la transition vers une nouvelle langue soit rarement un processus simple, la compréhension des principales différences entre SAS et R peut vous aider à commencer à naviguer dans cette nouvelle langue en utilisant votre langue maternelle. Vous trouverez ci-dessous les principales traductions en matière de gestion des données et d’analyse descriptive entre SAS et R.
Notes générales
| SAS | R |
|---|---|
| Communauté en ligne disponible via SAS Support à la clientèle | Communauté en ligne disponible via RStudio, StackOverFlow et R-bloggers |
Aide pour les commandes disponibles par help [command] |
Aide disponible avec [function]? ou effectuer une recherche dans le volet d’aide |
Commenter le code en utilisant * TEXTE ; ou /* TEXTE */ |
Commenter le code en utilisant # |
Presque toutes les commandes sont intégrées. Les utilisateurs peuvent écrire de nouvelles fonctions en utilisant les macros SAS, SAS/IML, SAS Component Language (SCL) et, plus récemment, les procédures Proc Fcmp et Proc Proto |
R s’installe avec les fonctions base, mais l’utilisation typique implique l’installation d’autres packages de CRAN (voir page Les bases de R) |
| L’analyse est généralement effectuée en écrivant un programme SAS dans la fenêtre de l’éditeur. | Analyse écrite dans un script R dans le volet source de RStudio. Les scripts R markdown constituent une alternative. |
Le fichier d’accès au travail
| SAS | R |
|---|---|
Les répertoires de travail peuvent être soit absolus, soit relatifs au dossier racine d’un projet en définissant le dossier racine à l’aide de %let rootdir=/chemin d'accès; %include “&cheminracine/nomsousdossier/nomfichier” |
Les répertoires de travail peuvent être soit absolus, soit relatifs au dossier racine du projet en utilisant le package here (voir Import et export) |
Voir le répertoire de travail actuel avec %put %sysfunc(getoption(work)); |
Utilisez getwd() ou here() (si vous utilisez le package here), avec des parenthèses vides |
Définir le répertoire de travail avec libname “emplacement du dossier” |
Utilisez setwd(“emplacement du dossier”), ou set_here("emplacement du dossier) si vous utilisez le package here |
Importation et visualisation des données
| SAS | R |
|---|---|
Utilisez la procédure Proc Import ou l’instruction Data Step Infile. |
Utilisez import() du package rio pour presque tous les types de fichiers. Des fonctions spécifiques existent comme alternatives (voir Import et export) |
La lecture des fichiers csv se fait à l’aide de la fonction Proc Import datafile=”nom_fichier.csv” out=travail.nom_fichier dbms=CSV; run; OU en utilisant L’instruction Data Step Infile |
Utilisez import("nom_fichier.csv") |
La lecture des fichiers xlsx se fait à l’aide de la fonction Proc Import datafile=”nom_fichier.xlsx” out=travail.nom_fichier dbms=xlsx; run; OU en utilisant L’instruction Data Step Infile |
Utilisez import(“nom_fichier.xlsx”) |
| Parcourez vos données dans une nouvelle fenêtre en ouvrant la fenêtre de l’Explorateur et sélectionnez la bibliothèque souhaitée et l’ensemble de données | Visualiser un ensemble de données dans le panneau source de RStudio en utilisant View(dataset). Vous devez spécifier le nom de votre ensemble de données à la fonction dans R car plusieurs ensembles de données peuvent être conservés en même temps. Notez le “V” majuscule dans cette fonction |
Manipulation de données de base
| SAS | R |
|---|---|
| Les colonnes de l’ensemble de données sont souvent appelées “variables” | On parle plus souvent de “colonnes” ou parfois de “vecteurs” ou de “variables” |
| Aucune procédure spéciale n’est nécessaire pour créer une variable.Les nouvelles variables sont créées simplement en tapant le nom de la nouvelle variable, suivi d’un signe égal, puis d’une expression pour la valeur. | Générez de nouvelles variables en utilisant la fonction mutate(). Voir la page Nettoyage des données et fonctions de base pour plus de détails sur toutes les fonctions dplyr ci-dessous. |
Les variables sont renommées en utilisant rename *ancien_nom=nouveau_nom* |
Les colonnes peuvent être renommées à l’aide de la fonction rename(nouveau_nom = ancien_nom) |
Les variables sont conservées en utilisant **keep**=nom_variable |
Les colonnes peuvent être sélectionnées en utilisant la fonction select() avec le nom de la colonne entre parenthèses. |
Les variables sont supprimées à l’aide de la fonction **drop**=nom_variable |
Les colonnes peuvent être supprimées à l’aide de la fonction select() avec le nom de la colonne entre parenthèses après le signe moins. |
Les variables factorielles peuvent être étiquetées dans l’étape de données (Data Step) en utilisant l’instruction Label. |
L’étiquetage des valeurs peut être fait en convertissant la colonne en classe factorielle et en spécifiant les niveaux. Voir la page sur les Facteurs. Les noms de colonnes ne sont généralement pas étiquetés. |
Les enregistrements sont sélectionnés à l’aide des instructions Where ou If dans l’étape de données (Data Step). |
Les enregistrements sont sélectionnés à l’aide de la fonction filter() avec plusieurs conditions de sélection séparées soit par l’opérateur pour ET (en anglais AND,&), soit par une virgule. |
Les ensembles de données sont combinés en utilisant l’instruction Merge dans l’étape Data Step. Les jeux de données à fusionner doivent d’abord être triés à l’aide de la procédure Proc Sort. |
Le package `dplyr offre quelques fonctions pour fusionner les jeux de données. Voir la page Joindre des données pour plus de détails. |
Analyse descriptive
| SAS | R |
|---|---|
Obtenez un aperçu de votre ensemble de données en utilisant la procédure Proc Summary, qui fournit les noms des variables et les statistiques descriptives |
Obtenez un aperçu de votre ensemble de données en utilisant summary(dataset) ou skim(dataset) du package skimr |
Mettre en tableau les effectifs d’une variable en utilisant proc freq data=Dataset; Tables nom_variable; Run; |
Voir la page sur les Tableaux descriptifsLes options incluent table() de R de base, et tabyl() du package janitor, entre autres. Notez que vous devrez spécifier le jeu de données et le nom de la colonne, car R contient plusieurs jeux de données. |
Le tableau croisé de deux variables dans un tableau 2x2 est fait avec proc freq data=Dataset ; Tables rowvar*colvar ; Run; |
Aussi, vous pouvez utiliser table(), tabyl() ou d’autres options comme décrit dans la page Tableaux descriptifs. |
Quelques ressources utiles:
4.4 Interopérabilité des données
Voir la page Import et export pour des détails sur comment le package rio peut importer et experter des fichiers tels que des fichiers STATA .dta, des fichiers SAS .xpt et.sas7bdat, des fichiers SPSS .por et.sav, et plusieurs autres.