pacman::p_load(
rio, # pour importation des fichiers
here, # chemins de fichiers
skimr, # obtenir un aperçu des données
tidyverse, # gestion des données + graphiques ggplot2,
gtsummary, # statistiques et tests sommaires
rstatix, # statistiques
corrr, # analyse de corrélation pour les variables numériques
janitor, # ajouter des totaux et des pourcentages à des tableaux
flextable # transformer les tableaux en HTML
)18 Tests statistiques simples
Cette page décrit comment réaliser des tests statistiques simples en utilisant base R, rstatix et gtsummary.
- Test T
- Test de Shapiro-Wilk
- Test de la somme des rangs de Wilcoxon
- Test de Kruskal-Wallis
- Test du khi carré
- Corrélations entre variables numériques
… plusieurs d’autres tests peuvent être effectués, mais nous ne présentons que ceux qui sont les plus utilisés et nous fournissons des liens vers plus de documentation.
Chacun des packages susmentionnés a des avantages et des désavantages :
- Utilisez les fonctions de base R pour afficher les résultats statistiques dans la Console R.
- Utilisez les fonctions de rstatix package pour afficher les résultats dans un tableau de données, ou si vous voulez que les tests soient effectués par groupe.
- Utilisez gtsummary package si vous souhaitez produire des tableaux prêts à être publiés.
18.1 Préparation
Importation des packages
Ce bloc de code montre l’importation des packages nécessaires pour les analyses. Dans ce manuel, nous soulignons la fonction p_load() de pacman, qui installe le package si nécessaire et l’importe pour utilisation. Vous pouvez aussi importer les packages déjà installés avec library() de base R. Voir la page sur bases de R pour plus d’informations sur les packages R.
Importation des données
Nous importons les données des cas d’une épidémie d’Ebola simulée. Si vous souhaitez suivre, cliquez pour télécharger le “clean” linelist (as .rds file). Importez les données avec la fonction import() du package rio (cette fonction supporte de nombreux types de fichiers comme .xlsx, .csv, .rds - voir la page Importation et exportation pour plus de détails).
# importez linelist
linelist <- import("linelist_cleaned.rds")Les 50 premières lignes de la liste des lignes sont affichées ci-dessous.
18.2 Base R
Vous pouvez utiliser les fonctions de base R pour effectuer des tests statistiques. Les commandes sont relativement simples et les résultats sont affichés dans la Console R pour une visualisation simple. Cependant, les résultats sont généralement des listes et sont donc plus difficiles à manipuler si vous souhaitez utiliser les résultats dans des opérations ultérieures.
Test T
Un t-test, aussi appelé “test t de Student”, est généralement utilisé pour déterminer s’il existe une différence significative entre les moyennes d’une variable numérique entre deux groupes. Nous allons montrer ici quelle syntaxe utiliser pour effectuer ce test selon si les colonnes se trouvent dans le même tableau de données.
Syntaxe 1: Voici la syntaxe à utiliser lorsque les colonnes numériques et catégorielles se trouvent dans le même tableau de données. Fournissez la colonne numérique sur la gauche de l’équation et la colonne catégorielle sur la droite. Précisez le tableau de données à data =. Optionnellement, définissezpaired = TRUE, et conf.level = (0.95 par défaut), et alternative = (soit “two.sided”, “less”, or “greater”). Entrez ?t.test pour plus de détails.
## comparer l'âge moyen par groupe avec un test t.
t.test(age_years ~ gender, data = linelist)
Welch Two Sample t-test
data: age_years by gender
t = -21.344, df = 4902.3, p-value < 2.2e-16
alternative hypothesis: true difference in means between group f and group m is not equal to 0
95 percent confidence interval:
-7.571920 -6.297975
sample estimates:
mean in group f mean in group m
12.60207 19.53701 Syntaxe 2: Vous pouvez comparer deux vecteurs numériques distincts en utilisant cette syntaxe alternative. Par exemple, si les deux colonnes se trouvent dans des tableau de données différents.
t.test(df1$age_years, df2$age_years)Vous pouvez aussi utiliser un test t pour déterminer si la moyenne d’un échantillon est significativement différente d’une valeur spécifique. Ici, nous effectuons un one-sample t-test avec une moyenne de population connue/hypothétique mu = :
t.test(linelist$age_years, mu = 45)Test de Shapiro-Wilk
Le Shapiro-Wilk test peut être utilisé pour déterminer si un échantillon provient d’une population normalement distribuée (une hypothèse de nombreux autres tests et analyses, tels que le test t). Cependant, il ne peut être utilisé que sur un échantillon de 3 à 5000 observations. Pour des échantillons plus importants, un quantile-quantile plot peut être utile.
shapiro.test(linelist$age_years)Test de la somme des rangs de Wilcoxon
Le test de la somme des rangs de Wilcoxon, aussi appelé test U de Mann-Whitney, est souvent utilisé pour déterminer si deux échantillons numériques proviennent de la même distribution lorsque leurs populations ne sont pas normalement distribuées ou présentent une variance inégale.
## comparer la distribution des âges par groupe de résultats avec un test de Wilcox.
wilcox.test(age_years ~ outcome, data = linelist)
Wilcoxon rank sum test with continuity correction
data: age_years by outcome
W = 2501868, p-value = 0.8308
alternative hypothesis: true location shift is not equal to 0Test de Kruskal-Wallis
Le test de Kruskal-Wallis est une extension du test de la somme des rangs de Wilcoxon qui peut être utilisé pour tester les différences dans la distribution de plus de deux échantillons. Lorsque deux échantillons sont utilisés, ce test donne des résultats identiques à ceux du test de la somme des rangs de Wilcoxon.
## comparer la distribution des âges par groupe de résultats avec un test de Kruskal-Wallis.
kruskal.test(age_years ~ outcome, linelist)
Kruskal-Wallis rank sum test
data: age_years by outcome
Kruskal-Wallis chi-squared = 0.045675, df = 1, p-value = 0.8308Test du khi carré
Pearson’s Chi-squared test est utilisé pour tester des différences significatives entre des groupes catégorielles.
## comparer les proportions dans chaque groupe avec un test de chi-carré
chisq.test(linelist$gender, linelist$outcome)
Pearson's Chi-squared test with Yates' continuity correction
data: linelist$gender and linelist$outcome
X-squared = 0.0011841, df = 1, p-value = 0.972518.3 Le rstatix package
Le package rstatix offre la possibilité d’exécuter des tests statistiques et de recueillir les résultats dans un cadre “pipe-friendly”. Les résultats sont automatiquement intégrés dans un tableau de données afin que vous puissiez effectuer des opérations ultérieures sur les résultats. Il est aussi facile de regrouper les données transmises dans les fonctions, afin que les statistiques soient exécutées pour chaque groupe.
Statistiques sommaires
La fonction get_summary_stats() est un moyen rapide de retourner des statistiques sommaires. Il suffit de passer vos données à cette fonction et de préciser les colonnes à analyser. Si aucune colonne n’est précisée, les statistiques sont calculées pour toutes les colonnes.
Par défaut, une gamme complète de statistiques sommaires est retournée : n, max, min, médiane, 25%ile, 75%ile, IQR, écart absolu médian (mad), moyenne, écart-type, erreur-type, et un intervalle de confiance de la moyenne.
linelist %>%
rstatix::get_summary_stats(age, temp)# A tibble: 2 × 13
variable n min max median q1 q3 iqr mad mean sd se
<fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 age 5802 0 84 13 6 23 17 11.9 16.1 12.6 0.166
2 temp 5739 35.2 40.8 38.8 38.2 39.2 1 0.741 38.6 0.977 0.013
# ℹ 1 more variable: ci <dbl>Vous pouvez préciser un sous-groupe de statistiques sommaires à retourner en fournissant l’une des valeurs suivantes à type = : “full”, “common”, “robust”, “five_number”, “mean_sd”, “mean_se”, “mean_ci”, “median_iqr”, “median_mad”, “quantile”, “mean”, “median”, “min”, “max”.
Elle peut également être utilisée avec des données groupées, de sorte qu’une ligne est renvoyée pour chaque variable de groupement :
linelist %>%
group_by(hospital) %>%
rstatix::get_summary_stats(age, temp, type = "common")# A tibble: 12 × 11
hospital variable n min max median iqr mean sd se ci
<chr> <fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Central Hos… age 445 0 58 12 15 15.7 12.5 0.591 1.16
2 Central Hos… temp 450 35.2 40.4 38.8 1 38.5 0.964 0.045 0.089
3 Military Ho… age 884 0 72 14 18 16.1 12.4 0.417 0.818
4 Military Ho… temp 873 35.3 40.5 38.8 1 38.6 0.952 0.032 0.063
5 Missing age 1441 0 76 13 17 16.0 12.9 0.339 0.665
6 Missing temp 1431 35.8 40.6 38.9 1 38.6 0.97 0.026 0.05
7 Other age 873 0 69 13 17 16.0 12.5 0.422 0.828
8 Other temp 862 35.7 40.8 38.8 1.1 38.5 1.01 0.034 0.067
9 Port Hospit… age 1739 0 68 14 18 16.3 12.7 0.305 0.598
10 Port Hospit… temp 1713 35.5 40.6 38.8 1.1 38.6 0.981 0.024 0.046
11 St. Mark's … age 420 0 84 12 15 15.7 12.4 0.606 1.19
12 St. Mark's … temp 410 35.9 40.6 38.8 1.1 38.5 0.983 0.049 0.095Vous pouvez aussi utiliser rstatix pour effectuer des tests statistiques :
Test T
Utilisez une syntaxe de formule pour préciser les colonnes numériques et catégorielles :
linelist %>%
t_test(age_years ~ gender)# A tibble: 1 × 10
.y. group1 group2 n1 n2 statistic df p p.adj p.adj.signif
* <chr> <chr> <chr> <int> <int> <dbl> <dbl> <dbl> <dbl> <chr>
1 age_… f m 2807 2803 -21.3 4902. 9.89e-97 9.89e-97 **** Ou utilisez ~ 1 et spécifiez mu = pour un one-sample T-test. Cela peut aussi être fait par groupe.
linelist %>%
t_test(age_years ~ 1, mu = 30)# A tibble: 1 × 7
.y. group1 group2 n statistic df p
* <chr> <chr> <chr> <int> <dbl> <dbl> <dbl>
1 age_years 1 null model 5802 -84.2 5801 0Si applicable, les tests statistiques peuvent être effectués par groupe, comme illustré ci-dessous :
linelist %>%
group_by(gender) %>%
t_test(age_years ~ 1, mu = 18)# A tibble: 3 × 8
gender .y. group1 group2 n statistic df p
* <chr> <chr> <chr> <chr> <int> <dbl> <dbl> <dbl>
1 f age_years 1 null model 2807 -29.8 2806 7.52e-170
2 m age_years 1 null model 2803 5.70 2802 1.34e- 8
3 <NA> age_years 1 null model 192 -3.80 191 1.96e- 4Test de Shapiro-Wilk
Comme indiqué précédemment, la taille de l’échantillon doit être entre 3 et 5000.
linelist %>%
head(500) %>% # les 500 premières lignes du case linelist, pour illustration seulement
shapiro_test(age_years)# A tibble: 1 × 3
variable statistic p
<chr> <dbl> <dbl>
1 age_years 0.917 6.67e-16Test de la somme des rangs de Wilcoxon
linelist %>%
wilcox_test(age_years ~ gender)# A tibble: 1 × 9
.y. group1 group2 n1 n2 statistic p p.adj p.adj.signif
* <chr> <chr> <chr> <int> <int> <dbl> <dbl> <dbl> <chr>
1 age_years f m 2807 2803 2829274 3.47e-74 3.47e-74 **** Test de Kruskal-Wallis
Aussi appelé le test U de Mann-Whitney.
linelist %>%
kruskal_test(age_years ~ outcome)# A tibble: 1 × 6
.y. n statistic df p method
* <chr> <int> <dbl> <int> <dbl> <chr>
1 age_years 5888 0.0457 1 0.831 Kruskal-WallisTest du khi carré
La fonction de khi carré peut accepter un tableau, donc nous allons d’abord créer un tableau croisé. Il existe de plusieurs méthodes de créer un tableau croisé (voir Tableaux descriptifs) mais ici nous utilisons tabyl() de janitor et nous supprimons la colonne la plus à gauche des labels de valeur avant de passer à chisq_test().
linelist %>%
tabyl(gender, outcome) %>%
select(-1) %>%
chisq_test()# A tibble: 1 × 6
n statistic p df method p.signif
* <dbl> <dbl> <dbl> <int> <chr> <chr>
1 5888 3.53 0.473 4 Chi-square test ns De nombreuses autres fonctions et tests statistiques peuvent être exécutés avec les fonctions de rstatix. Consultez la documentation de rstatix online here ou en entrant ?rstatix.
18.4 Le gtsummary package
Utilisez gtsummary si vous cherchez à ajouter les résultats d’un test statistique à un beau tableau qui a été créé avec ce package (comme décrit dans la section gtsummary de la page Tableaux descriptifs).
Effectuer des tests statistiques de comparaison avec tbl_summary se fait en ajoutant la fonction add_p à une table et en précisant le test à utiliser. Il est possible d’obtenir des valeurs p ajustées pour multiples tests en utilisant la fonction add_q. Exécutez ?tbl_summary pour plus de détails.
Test du khi carré
Comparez les proportions d’une variable catégorielle dans deux groupes. Le test statistique par défaut pour add_p() lorsqu’il est appliqué à une variable catégorielle est d’effectuer un test d’indépendance du khi-carré avec correction de continuité, mais si le nombre d’appels attendus est inférieur à 5, alors un test exact de Fisher est utilisé.
linelist %>%
select(gender, outcome) %>% # garder les variables d'intérêt
tbl_summary(by = outcome) %>% # produire un tableau sommaire et préciser la variable de groupement
add_p() # préciser le test à effectuer1323 observations missing `outcome` have been removed. To include these observations, use `forcats::fct_na_value_to_level()` on `outcome` column before passing to `tbl_summary()`.| Characteristic | Death, N = 2,5821 | Recover, N = 1,9831 | p-value2 |
|---|---|---|---|
| gender | >0.9 | ||
| f | 1,227 (50%) | 953 (50%) | |
| m | 1,228 (50%) | 950 (50%) | |
| Unknown | 127 | 80 | |
| 1 n (%) | |||
| 2 Pearson’s Chi-squared test | |||
Test T
Comparez la différence de moyennes entre deux groupes de variables continues. Par exemple, comparez l’âge moyen selon le statut du patient.
linelist %>%
select(age_years, outcome) %>% # garder les variables d'intérêt
tbl_summary( # produire un tableau sommaire
statistic = age_years ~ "{mean} ({sd})", # préciser quel statistique a afficher
by = outcome) %>% # préciser la variable de groupement
add_p(age_years ~ "t.test") # préciser le test à effectuer1323 observations missing `outcome` have been removed. To include these observations, use `forcats::fct_na_value_to_level()` on `outcome` column before passing to `tbl_summary()`.| Characteristic | Death, N = 2,5821 | Recover, N = 1,9831 | p-value2 |
|---|---|---|---|
| age_years | 16 (12) | 16 (13) | 0.6 |
| Unknown | 32 | 28 | |
| 1 Mean (SD) | |||
| 2 Welch Two Sample t-test | |||
Test de la somme des rangs de Wilcoxon
Comparez la distribution d’une variable continue dans deux groupes. La méthode par défaut est d’utiliser le test de la somme des rangs de Wilcoxon et la médiane (IQR) pour comparer deux groupes. Cependant, pour les données de distribution non normale ou la comparaison de plusieurs groupes, le test de Kruskal-wallis est plus approprié.
linelist %>%
select(age_years, outcome) %>% # garder les variables d'intérêt
tbl_summary( # produire un tableau sommaire
statistic = age_years ~ "{median} ({p25}, {p75})", # préciser quel statistique a afficher (ceci est par défaut et peut donc être supprimé)
by = outcome) %>% # préciser la variable de groupement
add_p(age_years ~ "wilcox.test") # préciser le test à effectuer1323 observations missing `outcome` have been removed. To include these observations, use `forcats::fct_na_value_to_level()` on `outcome` column before passing to `tbl_summary()`.| Characteristic | Death, N = 2,5821 | Recover, N = 1,9831 | p-value2 |
|---|---|---|---|
| age_years | 13 (6, 23) | 13 (6, 23) | 0.8 |
| Unknown | 32 | 28 | |
| 1 Median (IQR) | |||
| 2 Wilcoxon rank sum test | |||
Test de Kruskal-Wallis
Comparer la distribution d’une variable continue dans deux ou plusieurs groupes, peu importe si les données sont normalement distribuées ou pas.
linelist %>%
select(age_years, outcome) %>% # garder les variables d'intérêt
tbl_summary( # produire un tableau sommaire
statistic = age_years ~ "{median} ({p25}, {p75})", # préciser quel statistique a afficher (ceci est par défaut et peut donc être supprimé)
by = outcome) %>% # préciser la variable de groupement
add_p(age_years ~ "kruskal.test") # préciser le test à effectuer1323 observations missing `outcome` have been removed. To include these observations, use `forcats::fct_na_value_to_level()` on `outcome` column before passing to `tbl_summary()`.| Characteristic | Death, N = 2,5821 | Recover, N = 1,9831 | p-value2 |
|---|---|---|---|
| age_years | 13 (6, 23) | 13 (6, 23) | 0.8 |
| Unknown | 32 | 28 | |
| 1 Median (IQR) | |||
| 2 Kruskal-Wallis rank sum test | |||
18.5 Corrélations
La corrélation entre les variables numériques peut être étudiée en utilisant le package tidyverse
corrr. Il vous permet de calculer les corrélations en utilisant Pearson, Kendall tau ou Spearman rho. Le package crée un tableau et dispose également d’une fonction pour pour tracer automatiquement les valeurs.
correlation_tab <- linelist %>%
select(generation, age, ct_blood, days_onset_hosp, wt_kg, ht_cm) %>% # garder les variables numeriques d'intérêt
correlate() # créer une table de corrélation (en utilisant le pearson par défaut)
correlation_tab # afficher# A tibble: 6 × 7
term generation age ct_blood days_onset_hosp wt_kg ht_cm
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 generation NA -2.22e-2 0.179 -0.288 -0.0302 -0.00942
2 age -0.0222 NA 0.00849 -0.000635 0.833 0.877
3 ct_blood 0.179 8.49e-3 NA -0.600 -0.00636 0.0181
4 days_onset_hosp -0.288 -6.35e-4 -0.600 NA 0.0153 -0.00953
5 wt_kg -0.0302 8.33e-1 -0.00636 0.0153 NA 0.884
6 ht_cm -0.00942 8.77e-1 0.0181 -0.00953 0.884 NA ## supprimer les entrées dupliquées (le tableau précédent est dupliqué)
correlation_tab <- correlation_tab %>%
shave()
## voir le tableau de corrélation
correlation_tab# A tibble: 6 × 7
term generation age ct_blood days_onset_hosp wt_kg ht_cm
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 generation NA NA NA NA NA NA
2 age -0.0222 NA NA NA NA NA
3 ct_blood 0.179 0.00849 NA NA NA NA
4 days_onset_hosp -0.288 -0.000635 -0.600 NA NA NA
5 wt_kg -0.0302 0.833 -0.00636 0.0153 NA NA
6 ht_cm -0.00942 0.877 0.0181 -0.00953 0.884 NA## graphique des corrélations
rplot(correlation_tab)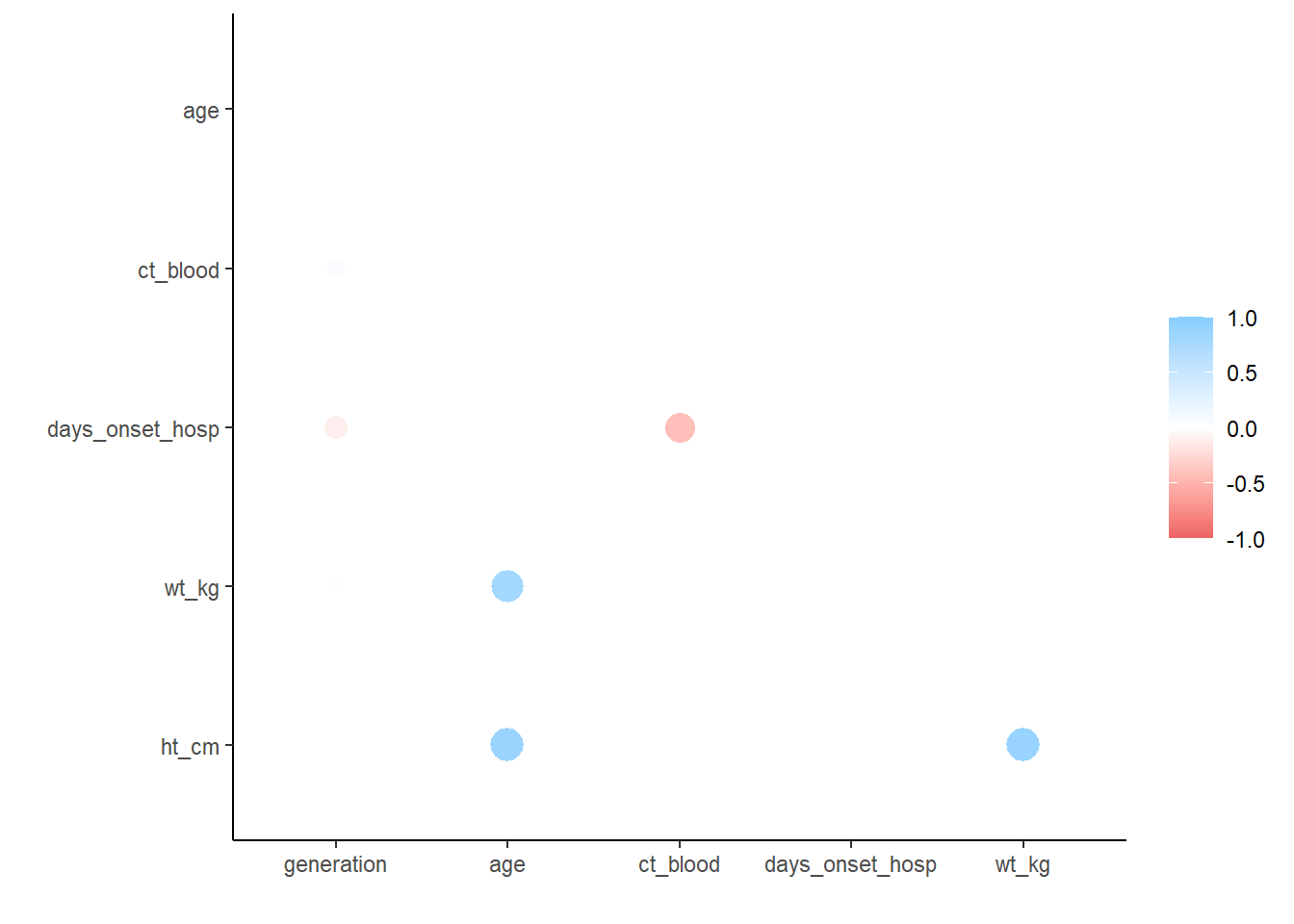
18.6 Ressources
La plupart des informations contenues dans cette page sont adaptées de ces ressources et vignettes disponibles en ligne :