17 Tableaux descriptifs
Cette page montre l’utilisation de janitor, dplyr, gtsummary, rstatix et extension/package R base pour résumer des données et créer des tableaux avec des statistiques descriptives.
Cette page explique comment créer les tableaux de base, tandis que la page Tableaux pour la présentation explique comment les mettre en forme et les imprimer.
Chacun de ces packages présente des avantages et des inconvénients dans les domaines de la simplicité du code, de l’accessibilité des sorties, de la qualité des sorties imprimées. Utilisez cette page pour décider quelle approche convient à votre scénario.
Plusieurs choix s’offrent à vous lorsque vous produisez des tableaux de synthèse et des tableaux croisés. Parmi les facteurs à prendre en compte, la simplicité du code, les possibilités de personnalisation, la sortie que vous souhaitez obtenir ( affichée sur la console R, en tant que tableau de données, ou en tant que “bonne” image .png/.jpeg/.html), et la facilité de traitement ultérieur. Tenez compte des points ci-dessous pour choisir l’outil adapté à votre situation.
Utilisez la fonction
tabyl()de janitor pour produire et ” personnaliser ” des tableaux et des tableaux croisésUtilisez la fonction
get_summary_stats()de rstatix pour générer facilement des tableaux de données de synthèse de statistiques numériques pour plusieurs colonnes et/ou groupesUtilisez les fonctions
summarise()etcount()de dplyr pour des statistiques plus complexes, des sorties de tableaux de données ordonnées ou la préparation de données pourggplot()Utilisez la fonction
tbl_summary()de gtsummary pour produire des tableaux détaillés prêts à être publiésUtilisez la fonction
table()de extension/package R base si vous n’avez pas accès aux packages ci-dessus
17.1 Préparation
Chargement des packages
Ce bloc de code montre le chargement des packages nécessaires pour les analyses. Dans ce manuel, nous mettons l’accent sur p_load() de pacman, qui installe le package si nécessaire et le charge pour utilisation. Vous pouvez également charger les packages installés avec library() de extension/package R base. Voir la page sur Bases de R pour plus d’informations sur les packages R.
pacman::p_load(
rio, # importation de fichier
here, # répertoire de fichiers
skimr, # obtenir un aperçu des données
tidyverse, # gestion de données + ggplot2 graphiques
gtsummary, # sommaire des statistiques et tests
rstatix, # sommaire des statistiques et tests statistiques
janitor, # ajouter des totaux et des pourcentages à des tableaux
scales, # convertir facilement les proportions en pourcentages
flextable # convertir les tableaux en belles images
)Importer les données
Nous importons le jeu de données des cas d’une épidémie d’Ebola simulée. Si vous voulez suivre,cliquez pour télécharger la linelist ” nettoyé “.(as .rds file). Importez vos données avec la fonction import() du package rio (elle accepte de nombreux types de fichiers comme .xlsx, .rds, .csv - voir la page Importation et exportation pour plus de détails.
# import the linelist
linelist <- import("linelist_cleaned.rds")The first 50 rows of the linelist are displayed below.
17.2 Explorer les données
skimr package
En utilisant le package skimr, vous pouvez obtenir un aperçu détaillé et esthétique de chacune des variables de votre ensemble de données. Pour en savoir plus sur skimr, consultez sa page github.
Ci-dessous, la fonction skim() est appliquée à l’ensemble du tableau de données linelist. Un aperçu du tableau de données et un résumé de chaque colonne (par classe) est produit.
## obtenir des informations sur chaque variable d'un jeu de données
skim(linelist)| Name | linelist |
| Number of rows | 5888 |
| Number of columns | 30 |
| _______________________ | |
| Column type frequency: | |
| character | 13 |
| Date | 4 |
| factor | 2 |
| numeric | 11 |
| ________________________ | |
| Group variables | None |
Variable type: character
| skim_variable | n_missing | complete_rate | min | max | empty | n_unique | whitespace |
|---|---|---|---|---|---|---|---|
| case_id | 0 | 1.00 | 6 | 6 | 0 | 5888 | 0 |
| outcome | 1323 | 0.78 | 5 | 7 | 0 | 2 | 0 |
| gender | 278 | 0.95 | 1 | 1 | 0 | 2 | 0 |
| age_unit | 0 | 1.00 | 5 | 6 | 0 | 2 | 0 |
| hospital | 0 | 1.00 | 5 | 36 | 0 | 6 | 0 |
| infector | 2088 | 0.65 | 6 | 6 | 0 | 2697 | 0 |
| source | 2088 | 0.65 | 5 | 7 | 0 | 2 | 0 |
| fever | 249 | 0.96 | 2 | 3 | 0 | 2 | 0 |
| chills | 249 | 0.96 | 2 | 3 | 0 | 2 | 0 |
| cough | 249 | 0.96 | 2 | 3 | 0 | 2 | 0 |
| aches | 249 | 0.96 | 2 | 3 | 0 | 2 | 0 |
| vomit | 249 | 0.96 | 2 | 3 | 0 | 2 | 0 |
| time_admission | 765 | 0.87 | 5 | 5 | 0 | 1072 | 0 |
Variable type: Date
| skim_variable | n_missing | complete_rate | min | max | median | n_unique |
|---|---|---|---|---|---|---|
| date_infection | 2087 | 0.65 | 2014-03-19 | 2015-04-27 | 2014-10-11 | 359 |
| date_onset | 256 | 0.96 | 2014-04-07 | 2015-04-30 | 2014-10-23 | 367 |
| date_hospitalisation | 0 | 1.00 | 2014-04-17 | 2015-04-30 | 2014-10-23 | 363 |
| date_outcome | 936 | 0.84 | 2014-04-19 | 2015-06-04 | 2014-11-01 | 371 |
Variable type: factor
| skim_variable | n_missing | complete_rate | ordered | n_unique | top_counts |
|---|---|---|---|---|---|
| age_cat | 86 | 0.99 | FALSE | 8 | 0-4: 1095, 5-9: 1095, 20-: 1073, 10-: 941 |
| age_cat5 | 86 | 0.99 | FALSE | 17 | 0-4: 1095, 5-9: 1095, 10-: 941, 15-: 743 |
Variable type: numeric
| skim_variable | n_missing | complete_rate | mean | sd | p0 | p25 | p50 | p75 | p100 |
|---|---|---|---|---|---|---|---|---|---|
| generation | 0 | 1.00 | 16.56 | 5.79 | 0.00 | 13.00 | 16.00 | 20.00 | 37.00 |
| age | 86 | 0.99 | 16.07 | 12.62 | 0.00 | 6.00 | 13.00 | 23.00 | 84.00 |
| age_years | 86 | 0.99 | 16.02 | 12.64 | 0.00 | 6.00 | 13.00 | 23.00 | 84.00 |
| lon | 0 | 1.00 | -13.23 | 0.02 | -13.27 | -13.25 | -13.23 | -13.22 | -13.21 |
| lat | 0 | 1.00 | 8.47 | 0.01 | 8.45 | 8.46 | 8.47 | 8.48 | 8.49 |
| wt_kg | 0 | 1.00 | 52.64 | 18.58 | -11.00 | 41.00 | 54.00 | 66.00 | 111.00 |
| ht_cm | 0 | 1.00 | 124.96 | 49.52 | 4.00 | 91.00 | 129.00 | 159.00 | 295.00 |
| ct_blood | 0 | 1.00 | 21.21 | 1.69 | 16.00 | 20.00 | 22.00 | 22.00 | 26.00 |
| temp | 149 | 0.97 | 38.56 | 0.98 | 35.20 | 38.20 | 38.80 | 39.20 | 40.80 |
| bmi | 0 | 1.00 | 46.89 | 55.39 | -1200.00 | 24.56 | 32.12 | 50.01 | 1250.00 |
| days_onset_hosp | 256 | 0.96 | 2.06 | 2.26 | 0.00 | 1.00 | 1.00 | 3.00 | 22.00 |
Vous pouvez également utiliser la fonction summary()de extension/package R base, pour obtenir des informations sur un jeu de données entier, mais cette sortie peut être plus difficile à lire qu’en utilisant skimr. C’est pourquoi la sortie n’est pas montrée ci-dessous, afin de conserver de l’espace sur la page.
## obtenir des informations sur chaque colonne d'un jeu de données
summary(linelist)Statistiques sommaires
Vous pouvez utiliser les fonctions extension/package R base pour renvoyer des synthèses statistiques sur une colonne numérique. Vous pouvez retourner la plupart des synthèses statistiques utiles pour une colonne numérique en utilisant summary(), comme ci-dessous. Notez que le nom du tableau de données doit également être spécifié comme indiqué ci-dessous.
summary(linelist$age_years) Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
0.00 6.00 13.00 16.02 23.00 84.00 86 Vous pouvez accéder à une partie spécifique et l’enregistrer avec les crochets d’indexation [ ] :
summary(linelist$age_years)[[2]] # retourne uniquement le 2ème élément[1] 6# équivalent, alternative au précédent par nom d'élément
# summary(linelist$age_years)[["1st Qu."]] Vous pouvez renvoyer des statistiques individuelles avec des fonctions extension/package R base comme max(), min(), median(), mean(), quantile(), sd(), et range(). Consultez la page Bases de R pour obtenir une liste complète.
CAUTION: Si vos données contiennent des valeurs manquantes, R veut que vous le sachiez et retournera donc NA, sauf si vous spécifiez aux fonctions mathématiques ci-dessus que vous voulez que R ignore les valeurs manquantes, via l’argument na.rm = TRUE.
Vous pouvez utiliser la fonction get_summary_stats() de rstatix pour retourner des synthèses statistiques dans un format de tableau de données. Cela peut être utile pour effectuer des opérations ultérieures ou des tracés sur les chiffres. Consultez la page Tests statistiques simples pour plus de détails sur le package rstatix et ses fonctions.
linelist %>%
get_summary_stats(
age, wt_kg, ht_cm, ct_blood, temp, # colonnes à calculer pour
type = "common") # sommaire des statistiques à retourner# A tibble: 5 × 10
variable n min max median iqr mean sd se ci
<fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 age 5802 0 84 13 17 16.1 12.6 0.166 0.325
2 wt_kg 5888 -11 111 54 25 52.6 18.6 0.242 0.475
3 ht_cm 5888 4 295 129 68 125. 49.5 0.645 1.26
4 ct_blood 5888 16 26 22 2 21.2 1.69 0.022 0.043
5 temp 5739 35.2 40.8 38.8 1 38.6 0.977 0.013 0.02517.3 janitor package
Les packages janitor offrent la fonction tabyl() pour produire des tableaux et des tableaux croisés, qui peuvent être ” améliorés ” ou modifiés avec des fonctions d’aide pour afficher des pourcentages, des proportions, des comptes, etc.
Ci-dessous, nous envoyons le tableau de données linelist aux fonctions janitor et nous affichons le résultat. Si vous le souhaitez, vous pouvez également enregistrer les tableaux résultants avec l’opérateur d’affectation <-.
Simple tabyl
L’utilisation par défaut de tabyl() sur une colonne spécifique produit les valeurs uniques, les nombres, et les “pourcentages” par colonne ( proportion en fait). Les proportions peuvent avoir plusieurs chiffres. Vous pouvez ajuster le nombre de décimales avec adorn_rounding() comme décrit ci-dessous.
linelist %>% tabyl(age_cat) age_cat n percent valid_percent
0-4 1095 0.185971467 0.188728025
5-9 1095 0.185971467 0.188728025
10-14 941 0.159816576 0.162185453
15-19 743 0.126188859 0.128059290
20-29 1073 0.182235054 0.184936229
30-49 754 0.128057065 0.129955188
50-69 95 0.016134511 0.016373664
70+ 6 0.001019022 0.001034126
<NA> 86 0.014605978 NAComme vous pouvez le voir ci-dessus, s’il y a des valeurs manquantes, elles s’affichent dans une ligne étiquetée <NA>. Vous pouvez les supprimer avec show_na = FALSE. S’il n’y a pas de valeurs manquantes, cette ligne n’apparaîtra pas. S’il y a des valeurs manquantes, toutes les proportions sont données à la fois brutes (dénominateur incluant les comptes NA) et “valide” (dénominateur excluant les comptes NA).
Si la colonne est un facteur de classe et que seuls certains niveaux sont présents dans vos données, tous les niveaux apparaîtront quand même dans le tableau. Vous pouvez supprimer cette fonctionnalité en spécifiant show_missing_levels = FALSE. Pour en savoir plus, consultez la page Facteurs.
Tableau croisé
Les chiffres des tableaux croisés sont obtenus en ajoutant une ou plusieurs colonnes supplémentaires dans tabyl(). Notez que maintenant, seuls les chiffres sont retournés - les proportions et les pourcentages peuvent être ajoutés avec les étapes supplémentaires montrées ci-dessous.
linelist %>% tabyl(age_cat, gender) age_cat f m NA_
0-4 640 416 39
5-9 641 412 42
10-14 518 383 40
15-19 359 364 20
20-29 468 575 30
30-49 179 557 18
50-69 2 91 2
70+ 0 5 1
<NA> 0 0 86“Habillage” du tabyl
Utilisez les fonctions “adorn” de janitor pour ajouter des totaux ou convertir en proportions, en pourcentages, ou ajuster l’affichage. Souvent, vous ferez passer le tabyle par plusieurs de ces fonctions.
| Fonction | Résultat |
|---|---|
adorn_totals() |
Ajoute les totaux (où = ” ligne “,” colonne “, ou” les deux “). Définissez nom = pour”Total”. |
adorn_percentages() |
Convertir les nombres en proportions, avec denominateur = ” ligne “,” colonne “, ou” tout “. |
adorn_pct_formatting() |
Convertit les proportions en pourcentages. Spécifiez digits =. Supprimez le symbole “%” avec affix_sign = FALSE. |
adorn_rounding() |
Pour arrondir les proportions à des positions digits =. Pour arrondir les pourcentages, utilisez adorn_pct_formatting() with digits =. |
adorn_ns() |
Ajoutez des nombres à un tableau de proportions ou de pourcentages. Indiquez position = “arrière” pour montrer les nombres entre parenthèses, ou “avant” pour mettre les pourcentages entre parenthèses. |
adorn_title() |
Ajouter une chaîne via les arguments row_name = et/ou col_name =. |
Faites attention à l’ordre dans lequel vous appliquez les fonctions ci-dessus. Voici quelques exemples.
Un simple tableau à sens unique avec des pourcentages au lieu des proportions par défaut.
linelist %>% # cas linelist
tabyl(age_cat) %>% # calculer les effectifs et les proportions par catégorie d'âge
adorn_pct_formatting() # convertir les proportions en pourcentages age_cat n percent valid_percent
0-4 1095 18.6% 18.9%
5-9 1095 18.6% 18.9%
10-14 941 16.0% 16.2%
15-19 743 12.6% 12.8%
20-29 1073 18.2% 18.5%
30-49 754 12.8% 13.0%
50-69 95 1.6% 1.6%
70+ 6 0.1% 0.1%
<NA> 86 1.5% -Un tableau croisé avec une ligne totale et des pourcentages de ligne.
linelist %>%
tabyl(age_cat, gender) %>% # comptage par âge et par sexe
adorn_totals(where = "row") %>% # ajouter une ligne totale
adorn_percentages(denominator = "row") %>% # convertir les comptages en proportions
adorn_pct_formatting(digits = 1) # convertir les proportions en pourcentages age_cat f m NA_
0-4 58.4% 38.0% 3.6%
5-9 58.5% 37.6% 3.8%
10-14 55.0% 40.7% 4.3%
15-19 48.3% 49.0% 2.7%
20-29 43.6% 53.6% 2.8%
30-49 23.7% 73.9% 2.4%
50-69 2.1% 95.8% 2.1%
70+ 0.0% 83.3% 16.7%
<NA> 0.0% 0.0% 100.0%
Total 47.7% 47.6% 4.7%Un tableau croisé ajusté de façon à ce que les nombres et les pourcentages soient affichés.
linelist %>% # cas linelist
tabyl(age_cat, gender) %>% # croiser les comptages
adorn_totals(where = "row") %>% # ajouter une ligne de total
adorn_percentages(denominator = "col") %>% # convertir en proportions
adorn_pct_formatting() %>% # convertir en pourcentages
adorn_ns(position = "front") %>% # afficher comme: "count (percent)"
adorn_title( # ajuster les titres
row_name = "Age Category",
col_name = "Gender") Gender
Age Category f m NA_
0-4 640 (22.8%) 416 (14.8%) 39 (14.0%)
5-9 641 (22.8%) 412 (14.7%) 42 (15.1%)
10-14 518 (18.5%) 383 (13.7%) 40 (14.4%)
15-19 359 (12.8%) 364 (13.0%) 20 (7.2%)
20-29 468 (16.7%) 575 (20.5%) 30 (10.8%)
30-49 179 (6.4%) 557 (19.9%) 18 (6.5%)
50-69 2 (0.1%) 91 (3.2%) 2 (0.7%)
70+ 0 (0.0%) 5 (0.2%) 1 (0.4%)
<NA> 0 (0.0%) 0 (0.0%) 86 (30.9%)
Total 2,807 (100.0%) 2,803 (100.0%) 278 (100.0%)Impression du tableau
Par défaut, le tableau s’affichera brute sur votre console R.
Vous pouvez également passer le tableau à flextable ou à un package similaire pour qu’il s’imprime comme une “jolie” image dans la visionneuse RStudio, qui peut être exportée en .png, .jpeg, .html, etc. Ce sujet est abordé à la page Tableaux pour la présentation. Notez que si vous imprimez de cette manière en utilisant adorn_titles(), vous devez spécifier placement = "combined".
linelist %>%
tabyl(age_cat, gender) %>%
adorn_totals(where = "col") %>%
adorn_percentages(denominator = "col") %>%
adorn_pct_formatting() %>%
adorn_ns(position = "front") %>%
adorn_title(
row_name = "Age Category",
col_name = "Gender",
placement = "combined") %>% # c'est nécessaire pour afficher comme image
flextable::flextable() %>% # convertir en une belle image
flextable::autofit() # format à une ligne par rangée Age Category/Gender | f | m | NA_ | Total |
|---|---|---|---|---|
0-4 | 640 (22.8%) | 416 (14.8%) | 39 (14.0%) | 1,095 (18.6%) |
5-9 | 641 (22.8%) | 412 (14.7%) | 42 (15.1%) | 1,095 (18.6%) |
10-14 | 518 (18.5%) | 383 (13.7%) | 40 (14.4%) | 941 (16.0%) |
15-19 | 359 (12.8%) | 364 (13.0%) | 20 (7.2%) | 743 (12.6%) |
20-29 | 468 (16.7%) | 575 (20.5%) | 30 (10.8%) | 1,073 (18.2%) |
30-49 | 179 (6.4%) | 557 (19.9%) | 18 (6.5%) | 754 (12.8%) |
50-69 | 2 (0.1%) | 91 (3.2%) | 2 (0.7%) | 95 (1.6%) |
70+ | 0 (0.0%) | 5 (0.2%) | 1 (0.4%) | 6 (0.1%) |
0 (0.0%) | 0 (0.0%) | 86 (30.9%) | 86 (1.5%) |
Utiliser sur d’autres tables
Vous pouvez utiliser les fonctions adorn_*() de janitor sur d’autres tables, comme celles crées par summarise() et count() de dplyr, ou table() de extension/package R base. Il suffit de passer la table à la fonction janitor désirée. Par exemple :
linelist %>%
count(hospital) %>% # dplyr fonction
adorn_totals() # janitor fonction hospital n
Central Hospital 454
Military Hospital 896
Missing 1469
Other 885
Port Hospital 1762
St. Mark's Maternity Hospital (SMMH) 422
Total 5888Enregistrer le tableau
Si vous convertissez le tableau en une ” jolie ” image avec un package comme flextable, vous pouvez l’enregistrer avec les fonctions de ce package - comme save_as_html(), save_as_word(), save_as_ppt(), et save_as_image() de flextable (comme discuté plus en détail dans la page Tableaux de présentation). Ci-dessous, le tableau est enregistré sous forme de document Word, dans lequel il peut être modifié manuellement.
linelist %>%
tabyl(age_cat, gender) %>%
adorn_totals(where = "col") %>%
adorn_percentages(denominator = "col") %>%
adorn_pct_formatting() %>%
adorn_ns(position = "front") %>%
adorn_title(
row_name = "Age Category",
col_name = "Gender",
placement = "combined") %>%
flextable::flextable() %>% # convertir en image
flextable::autofit() %>% # assurer une seule ligne par rangée
flextable::save_as_docx(path = "tabyl.docx") # enregistrer en tant que document Word dans le chemin de fichier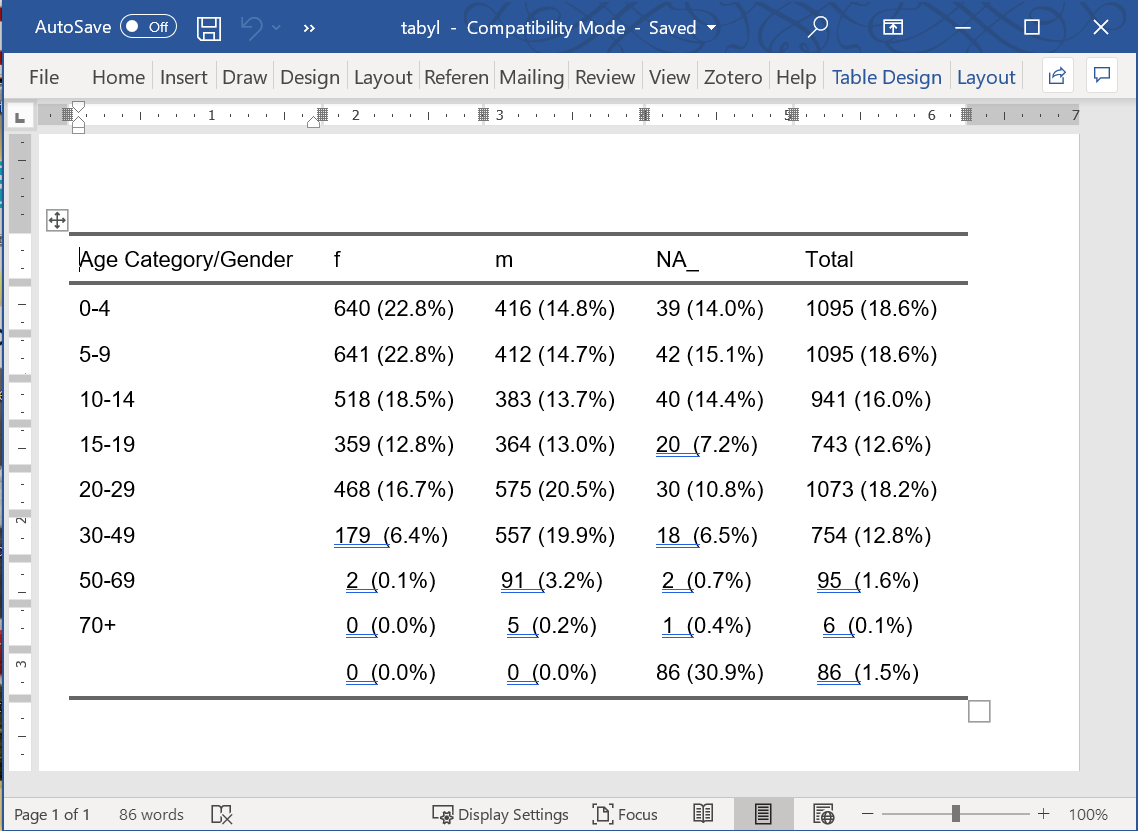
Statistiques
Vous pouvez appliquer des tests statistiques sur les tableaux, comme chisq.test() ou fisher.test() du package stats, comme indiqué ci-dessous. Notez que les valeurs manquantes ne sont pas autorisées, elles sont donc exclues du tableau avec show_na = FALSE
age_by_outcome <- linelist %>%
tabyl(age_cat, outcome, show_na = FALSE)
chisq.test(age_by_outcome)
Pearson's Chi-squared test
data: age_by_outcome
X-squared = 6.4931, df = 7, p-value = 0.4835Consultez la page sur les Tests statistiques simples pour obtenir plus de code et de conseils sur les statistiques.
Autres conseils
- Incluez l’argument
na.rm = TRUEpour exclure les valeurs manquantes de tous les calculs ci-dessus. - Si vous appliquez des fonctions d’aide
adorn_*()à des tables qui n’ont pas été crées partabyl(), vous pouvez spécifier une ou plusieurs colonnes particulières auxquelles les appliquer commeadorn_percentage(,,,c(cas,décès))(spécifiez-les au 4ème argument non nommé). La syntaxe n’est pas simple. Pensez à utilisersummarise()à la place. - Vous pouvez obtenir plus de détails dans le janitor page et ce tabyl vignette.
17.4 dplyr package
dplyr fait partie des packages tidyverse et est un outil de gestion de données très courant. Créer des tableaux avec les fonctions dplyr summarise() et count() est une méthode très utile pour calculer des statistiques sommaires, résumer par groupe, ou passer des tableaux à ggplot().
summarise() crée un nouveau tableau de données récapitulatif. Si les données sont non groupées, il renvoie un tableau de données à une ligne avec les statistiques récapitulatives spécifiées pour l’ensemble du tableau de données. Si les données sont groupées, le nouveau tableau de données aura une ligne par groupe (voir la page Regroupement de données).
Entre les parenthèses de summarise(), vous indiquez le nom de chaque nouvelle colonne du résumé, suivi d’un signe égal et d’une fonction statistique à appliquer.
TIP: La fonction summarise fonctionne avec les orthographes britannique et américaine (summarise() et summarize()).
Obtenir des nombres
La fonction la plus simple à appliquer dans summarise() est n(). Laissez les parenthèses vides pour compter le nombre de lignes.
linelist %>% # commencer par une liste de lignes
summarise(n_rows = n()) # retourne un nouveau tableau de données avec la colonne n_rows n_rows
1 5888Cela devient plus intéressant si nous avons regroupé les données au préalable.
linelist %>%
group_by(age_cat) %>% # regrouper les données par valeurs uniques dans une colonne age_cat
summarise(n_rows = n()) # retourne le nombre de lignes *per group*# A tibble: 9 × 2
age_cat n_rows
<fct> <int>
1 0-4 1095
2 5-9 1095
3 10-14 941
4 15-19 743
5 20-29 1073
6 30-49 754
7 50-69 95
8 70+ 6
9 <NA> 86La commande ci-dessus peut être réduite en utilisant la fonction count() à la place. La fonction count() effectue les opérations suivantes :
- Regroupe les données selon les colonnes qui lui sont fournies.
- Les résume avec
n()(en créant la colonnen). - Dé-grouper les données
linelist %>%
count(age_cat) age_cat n
1 0-4 1095
2 5-9 1095
3 10-14 941
4 15-19 743
5 20-29 1073
6 30-49 754
7 50-69 95
8 70+ 6
9 <NA> 86Vous pouvez changer le nom de la colonne des comptages de la valeur par défaut n à quelque chose d’autre en le spécifiant à name =.
Les résultats de la mise en tableau de deux colonnes de regroupement ou plus sont toujours renvoyés au format “long”, avec les effectifs dans la colonne n. Consultez la page Pivoter les données pour en savoir plus sur les formats de données “long” et “large”.
linelist %>%
count(age_cat, outcome) age_cat outcome n
1 0-4 Death 471
2 0-4 Recover 364
3 0-4 <NA> 260
4 5-9 Death 476
5 5-9 Recover 391
6 5-9 <NA> 228
7 10-14 Death 438
8 10-14 Recover 303
9 10-14 <NA> 200
10 15-19 Death 323
11 15-19 Recover 251
12 15-19 <NA> 169
13 20-29 Death 477
14 20-29 Recover 367
15 20-29 <NA> 229
16 30-49 Death 329
17 30-49 Recover 238
18 30-49 <NA> 187
19 50-69 Death 33
20 50-69 Recover 38
21 50-69 <NA> 24
22 70+ Death 3
23 70+ Recover 3
24 <NA> Death 32
25 <NA> Recover 28
26 <NA> <NA> 26Voir tous les niveaux
Si vous mettez en tableau une colonne de classe facteur, vous pouvez vous assurer que tous les niveaux sont affichés (et pas seulement les niveaux avec des valeurs dans les données) en ajoutant .drop = FALSE dans la commande summarise() ou count().
Cette technique est utile pour standardiser vos tableaux/graphiques. Par exemple, si vous créez des chiffres pour plusieurs sous-groupes, ou si vous créez plusieurs fois le même chiffre pour des rapports de routine. Dans chacune de ces circonstances, la présence de valeurs dans les données peut fluctuer, mais vous pouvez définir des niveaux qui restent constants.
Consultez la page sur les Facteurs pour plus d’informations.
Proportions
Les proportions peuvent être ajoutées en passant le tableau à mutate() pour créer une nouvelle colonne. Définissez la nouvelle colonne comme la colonne des comptages (n par défaut) divisée par la sum() de la colonne des comptages (ceci retournera une proportion).
Notez que dans ce cas, sum() dans la commande mutate() retournera la somme de la colonne entière n pour l’utiliser comme dénominateur de la proportion. Comme expliqué dans la page Regroupement des données, si sum() est utilisé dans des données groupées (par exemple, si la commande mutate() suit immédiatement une commande group_by()), il retournera les sommes par groupe. Comme indiqué juste au-dessus, count() termine ses actions en dégroupant. Ainsi, dans ce scénario, nous obtenons les proportions de la colonne entière.
Pour afficher facilement les pourcentages, vous pouvez inclure la proportion dans la fonction percent() du package scales (notez cette conversion en caractère de classe).
age_summary <- linelist %>%
count(age_cat) %>% # grouper et compter par sexe (produit la colonne "n")
mutate( # créer le pourcentage de la colonne - noter le dénominateur
percent = scales::percent(n / sum(n)))
# print
age_summary age_cat n percent
1 0-4 1095 18.60%
2 5-9 1095 18.60%
3 10-14 941 15.98%
4 15-19 743 12.62%
5 20-29 1073 18.22%
6 30-49 754 12.81%
7 50-69 95 1.61%
8 70+ 6 0.10%
9 <NA> 86 1.46%Vous trouverez ci-dessous une méthode permettant de calculer les proportions dans les groupes. Elle repose sur l’application et la suppression sélectives de différents niveaux de regroupement des données. Tout d’abord, les données sont regroupées en fonction du résultat via group_by(). Ensuite, la fonction count() est appliquée. Cette fonction regroupe à nouveau les données par age_cat et retourne les résultats pour chaque combinaison outcome-age-cat. Il est important de noter qu’en terminant son processus, count() a également dégroupé le regroupement par age_cat, de sorte que le seul regroupement de données restant est le regroupement original par outcome. Ainsi, l’étape finale du calcul des proportions (dénominateur sum(n)) est toujours groupée par outcome.
age_by_outcome <- linelist %>% # commencer par la linelist
group_by(outcome) %>% # groupe par résultats
count(age_cat) %>% # regrouper et compter par age_cat, puis supprimer le regroupement age_cat
mutate(percent = scales::percent(n / sum(n))) # calculer le pourcentage - noter que le dénominateur est par groupe de résultatsPlotting
Afficher un tableau “long” comme celui ci-dessus avec ggplot() est relativement simple. Les données sont naturellement au format “long”, qui est naturellement accepté par ggplot(). Voir d’autres exemples dans les pages ggplot basics et Astuces de ggplot.
linelist %>% # commencer par la linelist
count(age_cat, outcome) %>% # regrouper et présenter les comptages par deux colonnes
ggplot()+ # passer le nouveau tableau de données à ggplot
geom_col( # créer un bar plot
mapping = aes(
x = outcome, # mappez le résultat sur l'axe des x
fill = age_cat, # mappe age_cat au remplissage
y = n)) # associer la colonne de comptage `n` à la hauteur
Synthèse des statistiques
Un avantage majeur de dplyr et de summarise() est la possibilité de retourner des résumés statistiques plus avancés comme median(), mean(), max(), min(), sd() (écart-type), et les percentiles. Vous pouvez également utiliser sum() pour retourner le nombre de lignes qui répondent à certains critères logiques. Comme ci-dessus, ces sorties peuvent être produites pour l’ensemble du cadre de données, ou par groupe.
La syntaxe est la même - entre les parenthèses de summarise(), vous fournissez les noms de chaque nouvelle colonne de résumé, suivis d’un signe égal et d’une fonction statistique à appliquer. Dans la fonction statistique, donnez la ou les colonnes sur lesquelles vous voulez travailler et tous les arguments pertinents (par exemple na.rm = TRUE pour la plupart des fonctions mathématiques).
Vous pouvez également utiliser sum() pour retourner le nombre de lignes qui répondent à un critère logique. L’expression qu’il contient est comptée si elle vaut TRUE. Par exemple :
sum(age_years < 18, na.rm=T)sum(gender == "male", na.rm=T)sum(response %in% c("Likely", "Very Likely"))
Ci-dessous, les données linelist sont résumées pour décrire le délai en jours entre l’apparition des symptômes et l’admission à l’hôpital (colonne days_onset_hosp), par hôpital.
summary_table <- linelist %>% # commencez avec la linelist, enregistrez comme un nouvel objet
group_by(hospital) %>% # regrouper tous les calculs par hopital
summarise( # seules les colonnes de résumé ci-dessous seront retournées
cases = n(), # nombre de lignes par groupe
delay_max = max(days_onset_hosp, na.rm = T), # délai max
delay_mean = round(mean(days_onset_hosp, na.rm=T), digits = 1), # délai moyen, arrondi
delay_sd = round(sd(days_onset_hosp, na.rm = T), digits = 1), # Déviation standard des délais, arrondie
delay_3 = sum(days_onset_hosp >= 3, na.rm = T), # nombre de lignes avec un délai de 3 jours ou plus
pct_delay_3 = scales::percent(delay_3 / cases) # convertir en pourcentage une colonne de délai précédemment définie
)
summary_table # Afficher# A tibble: 6 × 7
hospital cases delay_max delay_mean delay_sd delay_3 pct_delay_3
<chr> <int> <dbl> <dbl> <dbl> <int> <chr>
1 Central Hospital 454 12 1.9 1.9 108 24%
2 Military Hospital 896 15 2.1 2.4 253 28%
3 Missing 1469 22 2.1 2.3 399 27%
4 Other 885 18 2 2.2 234 26%
5 Port Hospital 1762 16 2.1 2.2 470 27%
6 St. Mark's Maternity … 422 18 2.1 2.3 116 27% Quelques conseils :
Utilisez
sum()avec une instruction logique pour “compter” les lignes qui répondent à certains critères (==).Notez l’utilisation de
na.rm = TRUEdans les fonctions mathématiques commesum(), sinonNAsera retourné s’il y a des valeurs manquantes.Utilisez la fonction
percent()du package scales pour convertir facilement en pourcentages.- Définissez
accuracy =à 0,1 ou 0,01 pour garantir respectivement 1 ou 2 décimales.
- Définissez
Utilisez la fonction
round()de extension/package R base pour spécifier les décimales.Pour calculer ces statistiques sur l’ensemble des données, utilisez
summarise()sansgroup_by().Vous pouvez créer des colonnes pour les besoins de calculs ultérieurs (par exemple, les dénominateurs) que vous supprimez éventuellement de votre cadre de données avec
select().
Statistiques conditionnelles
Vous pouvez souhaiter renvoyer des statistiques conditionnelles - par exemple, le maximum de lignes qui répondent à certains critères. Pour ce faire, il suffit de subdiviser la colonne avec des parenthèses [ ]. L’exemple ci-dessous renvoie la température maximale pour les patients classés comme ayant ou n’ayant pas de fièvre. Attention cependant - il peut être plus approprié d’ajouter une autre colonne à la commandegroup_by()etpivot_wider() (comme démontré ci-dessous).
linelist %>%
group_by(hospital) %>%
summarise(
max_temp_fvr = max(temp[fever == "yes"], na.rm = T),
max_temp_no = max(temp[fever == "no"], na.rm = T)
)# A tibble: 6 × 3
hospital max_temp_fvr max_temp_no
<chr> <dbl> <dbl>
1 Central Hospital 40.4 38
2 Military Hospital 40.5 38
3 Missing 40.6 38
4 Other 40.8 37.9
5 Port Hospital 40.6 38
6 St. Mark's Maternity Hospital (SMMH) 40.6 37.9Coller ensemble
La fonction str_glue() de stringr est utile pour combiner les valeurs de plusieurs colonnes en une nouvelle colonne. Dans ce contexte, elle est généralement utilisée après la commande summarise().
Dans la page Caractères et chaînes de caractères, diverses options pour combiner des colonnes sont discutées, notamment unite(), et paste0(). Dans ce cas d’utilisation, nous préconisons str_glue() parce qu’il est plus flexible que unite() et a une syntaxe plus simple que paste0().
Ci-dessous, le tableau de données summary_table (créé plus haut) est modifié de telle sorte que les colonnes delay_mean et delay_sd sont combinées, la mise en forme entre parenthèses est ajoutée à la nouvelle colonne, et leurs anciennes colonnes respectives sont supprimées.
Ensuite, pour rendre le tableau plus présentable, une ligne de total est ajoutée avec adorn_totals() de janitor (qui ignore les colonnes non-numériques). Enfin, nous utilisons select() de dplyr pour réordonner et renommer les colonnes avec des noms plus appropriés.
Maintenant, vous pouvez passer à flextable et imprimer le tableau dans Word, .png, .jpeg, .html, Powerpoint, RMarkdown, etc. ! (voir la page Tableaux pour la présentation).
summary_table %>%
mutate(delay = str_glue("{delay_mean} ({delay_sd})")) %>% # fusionner et formater d'autres valeurs
select(-c(delay_mean, delay_sd)) %>% # supprimer deux anciennes colonnes
adorn_totals(where = "row") %>% # ajouter la ligne totale
select( # ordonner et renommer les colonnes
"Hospital Name" = hospital,
"Cases" = cases,
"Max delay" = delay_max,
"Mean (sd)" = delay,
"Delay 3+ days" = delay_3,
"% delay 3+ days" = pct_delay_3
) Hospital Name Cases Max delay Mean (sd) Delay 3+ days
Central Hospital 454 12 1.9 (1.9) 108
Military Hospital 896 15 2.1 (2.4) 253
Missing 1469 22 2.1 (2.3) 399
Other 885 18 2 (2.2) 234
Port Hospital 1762 16 2.1 (2.2) 470
St. Mark's Maternity Hospital (SMMH) 422 18 2.1 (2.3) 116
Total 5888 101 - 1580
% delay 3+ days
24%
28%
27%
26%
27%
27%
-Percentiles
Les percentiles et les quantiles dans dplyr méritent une mention spéciale. Pour retourner les quantiles, utilisez quantile() avec les valeurs par défaut ou spécifiez la ou les valeurs que vous souhaitez avec probs =.
# obtenir les valeurs percentile par défaut de l'âge (0%, 25%, 50%, 75%, 100%)
linelist %>%
summarise(age_percentiles = quantile(age_years, na.rm = TRUE))Warning: Returning more (or less) than 1 row per `summarise()` group was deprecated in
dplyr 1.1.0.
ℹ Please use `reframe()` instead.
ℹ When switching from `summarise()` to `reframe()`, remember that `reframe()`
always returns an ungrouped data frame and adjust accordingly. age_percentiles
1 0
2 6
3 13
4 23
5 84# obtenir des valeurs percentiles d'âge spécifiées manuellement (5%, 50%, 75%, 98%)
linelist %>%
summarise(
age_percentiles = quantile(
age_years,
probs = c(.05, 0.5, 0.75, 0.98),
na.rm=TRUE)
)Warning: Returning more (or less) than 1 row per `summarise()` group was deprecated in
dplyr 1.1.0.
ℹ Please use `reframe()` instead.
ℹ When switching from `summarise()` to `reframe()`, remember that `reframe()`
always returns an ungrouped data frame and adjust accordingly. age_percentiles
1 1
2 13
3 23
4 48Si vous voulez retourner les quantiles par groupe, vous pouvez rencontrer des sorties longues et moins utiles si vous ajoutez simplement une autre colonne à group_by(). Donc, essayez plutôt cette approche - créez une colonne pour chaque niveau de quantile désiré.
# obtenir des valeurs percentiles d'âge spécifiées manuellement (5%, 50%, 75%, 98%)
linelist %>%
group_by(hospital) %>%
summarise(
p05 = quantile(age_years, probs = 0.05, na.rm=T),
p50 = quantile(age_years, probs = 0.5, na.rm=T),
p75 = quantile(age_years, probs = 0.75, na.rm=T),
p98 = quantile(age_years, probs = 0.98, na.rm=T)
)# A tibble: 6 × 5
hospital p05 p50 p75 p98
<chr> <dbl> <dbl> <dbl> <dbl>
1 Central Hospital 1 12 21 48
2 Military Hospital 1 13 24 45
3 Missing 1 13 23 48.2
4 Other 1 13 23 50
5 Port Hospital 1 14 24 49
6 St. Mark's Maternity Hospital (SMMH) 2 12 22 50.2Bien que dplyr summarise() offre certainement un contrôle plus précis, vous trouverez peut-être que toutes les synthèses statistiques dont vous avez besoin peuvent être produites avec get_summary_stat() du package rstatix. Si l’on opère sur des données groupées, if retournera 0%, 25%, 50%, 75%, et 100%. Si elle est appliquée à des données non groupées, vous pouvez spécifier les percentiles avec probs = c(.05, .5, .75, .98).
linelist %>%
group_by(hospital) %>%
rstatix::get_summary_stats(age, type = "quantile")# A tibble: 6 × 8
hospital variable n `0%` `25%` `50%` `75%` `100%`
<chr> <fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Central Hospital age 445 0 6 12 21 58
2 Military Hospital age 884 0 6 14 24 72
3 Missing age 1441 0 6 13 23 76
4 Other age 873 0 6 13 23 69
5 Port Hospital age 1739 0 6 14 24 68
6 St. Mark's Maternity Hospital (… age 420 0 7 12 22 84linelist %>%
rstatix::get_summary_stats(age, type = "quantile")# A tibble: 1 × 7
variable n `0%` `25%` `50%` `75%` `100%`
<fct> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 age 5802 0 6 13 23 84Synthèse des données agrégées
Si vous commencez avec des données agrégées, l’utilisation de n() renvoie le nombre de lignes, et non la somme des comptes agrégés. Pour obtenir la somme, utilisez sum() sur la colonne des comptages des données.
Par exemple, disons que vous commencez avec le tableau de données de comptage ci-dessous, appelé linelist_agg - il montre en format “long” le nombre de cas par résultat et par sexe.
Ci-dessous, nous créons cet exemple de tableau de données de comptage de linelist par résultat et par sexe (les valeurs manquantes sont supprimées pour plus de clarté).
linelist_agg <- linelist %>%
drop_na(gender, outcome) %>%
count(outcome, gender)
linelist_agg outcome gender n
1 Death f 1227
2 Death m 1228
3 Recover f 953
4 Recover m 950Pour additionner les valeurs (dans la colonne n) par groupe, vous pouvez utiliser summarise() mais définissez la nouvelle colonne égale à sum(n, na.rm=T). Pour ajouter un élément de condition à l’opération de somme, vous pouvez utiliser la syntaxe des sous-ensembles [ ] sur la colonne des comptages.
linelist_agg %>%
group_by(outcome) %>%
summarise(
total_cases = sum(n, na.rm=T),
male_cases = sum(n[gender == "m"], na.rm=T),
female_cases = sum(n[gender == "f"], na.rm=T))# A tibble: 2 × 4
outcome total_cases male_cases female_cases
<chr> <int> <int> <int>
1 Death 2455 1228 1227
2 Recover 1903 950 953across() multiples colonnes
Vous pouvez utiliser summarise() sur plusieurs colonnes en utilisant across(). Cela vous facilite la tâche lorsque vous voulez calculer les mêmes statistiques pour plusieurs colonnes. Placez across() dans summarise() et spécifiez ce qui suit :
.cols =comme un vecteur de noms de colonnesc()ou des fonctions d’aide “tidyselect” (expliquées ci-dessous).fns =la fonction à exécuter (sans parenthèses) - vous pouvez en fournir plusieurs dans unelist().
Ci-dessous, la fonction mean() est appliquée à plusieurs colonnes numériques. Un vecteur de colonnes est nommé explicitement dans .cols = et une seule fonction mean est spécifiée (sans parenthèses) dans .fns =. Tout argument supplémentaire pour la fonction (par exemple na.rm=TRUE) est fourni après .fns =, séparé par une virgule.
Il peut être difficile de respecter l’ordre des parenthèses et des virgules lorsqu’on utilise across(). N’oubliez pas qu’à l’intérieur de across(), vous devez inclure les colonnes, les fonctions et tous les arguments supplémentaires nécessaires aux fonctions.
linelist %>%
group_by(outcome) %>%
summarise(across(.cols = c(age_years, temp, wt_kg, ht_cm), # colonnes
.fns = mean, # fonction
na.rm=T)) # arguments supplémentairesWarning: There was 1 warning in `summarise()`.
ℹ In argument: `across(...)`.
ℹ In group 1: `outcome = "Death"`.
Caused by warning:
! The `...` argument of `across()` is deprecated as of dplyr 1.1.0.
Supply arguments directly to `.fns` through an anonymous function instead.
# Previously
across(a:b, mean, na.rm = TRUE)
# Now
across(a:b, \(x) mean(x, na.rm = TRUE))# A tibble: 3 × 5
outcome age_years temp wt_kg ht_cm
<chr> <dbl> <dbl> <dbl> <dbl>
1 Death 15.9 38.6 52.6 125.
2 Recover 16.1 38.6 52.5 125.
3 <NA> 16.2 38.6 53.0 125.Plusieurs fonctions peuvent être exécutées en même temps. Ci-dessous, les fonctions mean et sd sont fournies à .fns = dans une list(). Vous avez la possibilité de fournir des noms de caractères (par exemple “mean” et “sd”) qui sont ajoutés dans les nouveaux noms de colonnes.
linelist %>%
group_by(outcome) %>%
summarise(across(.cols = c(age_years, temp, wt_kg, ht_cm), # colonnes
.fns = list("mean" = mean, "sd" = sd), # fonctions multiples
na.rm=T)) # arguments supplémentaires# A tibble: 3 × 9
outcome age_years_mean age_years_sd temp_mean temp_sd wt_kg_mean wt_kg_sd
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Death 15.9 12.3 38.6 0.962 52.6 18.4
2 Recover 16.1 13.0 38.6 0.997 52.5 18.6
3 <NA> 16.2 12.8 38.6 0.976 53.0 18.9
# ℹ 2 more variables: ht_cm_mean <dbl>, ht_cm_sd <dbl>Voici les fonctions d’aide “tidyselect” que vous pouvez fournir à .cols = pour sélectionner des colonnes :
everything()- toutes les autres colonnes non mentionnéeslast_col()- la dernière colonnewhere()- applique une fonction à toutes les colonnes et sélectionne celles qui sont VRAIESstarts_with()- correspond à un préfixe spécifié. Exemple :starts_with("date")ends_with()- correspond à un suffixe spécifié. Exemple : `ends_with(“_end”)contains()- colonnes contenant une chaîne de caractères. Exemple :contains("time")matches()- pour appliquer une expression régulière (regex). Exemple :contains("[pt]al")num_range()-any_of()- correspond si la colonne est nommée. Utile si le nom peut ne pas exister. Exemple :any_of(date_onset, date_death, cardiac_arrest)
Par exemple, pour retourner la moyenne de chaque colonne numérique, utilisez where() et fournissez la fonction as.numeric() (sans parenthèses). Tout cela reste dans la commande across().
linelist %>%
group_by(outcome) %>%
summarise(across(
.cols = where(is.numeric), # toutes les colonnes numériques dans le tableau de données
.fns = mean,
na.rm=T))# A tibble: 3 × 12
outcome generation age age_years lon lat wt_kg ht_cm ct_blood temp
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Death 16.7 15.9 15.9 -13.2 8.47 52.6 125. 21.3 38.6
2 Recover 16.4 16.2 16.1 -13.2 8.47 52.5 125. 21.1 38.6
3 <NA> 16.5 16.3 16.2 -13.2 8.47 53.0 125. 21.2 38.6
# ℹ 2 more variables: bmi <dbl>, days_onset_hosp <dbl>Pivot élargi
Si vous préférez votre tableau en format “large”, vous pouvez le transformer en utilisant la fonction tidyr pivot_wider(). Vous devrez probablement renommer les colonnes avec rename(). Pour plus d’informations, consultez la page sur le pivotement des données.
L’exemple ci-dessous commence avec la table “longue” age_by_outcome de la section proportions. Nous le créons à nouveau et le présentons à l’impression, pour plus de clarté :
age_by_outcome <- linelist %>% # commencez par la linelist
group_by(outcome) %>% # groupe par outcome
count(age_cat) %>% # regrouper et compter par age_cat, puis supprimer le regroupement age_cat
mutate(percent = scales::percent(n / sum(n))) # calculer le pourcentage - noter que le dénominateur est par groupe de outcomePour effectuer un pivot plus large, nous créons les nouvelles colonnes à partir des valeurs de la colonne existante age_cat (en définissant names_from = age_cat). Nous spécifions également que les nouvelles valeurs de la table proviendront de la colonne existante n, avec values_from = n. Les colonnes non mentionnées dans notre commande de pivotement (outcome) resteront inchangées à l’extrême gauche.
age_by_outcome %>%
select(-percent) %>% # maintenir seulement compte pour la simplicité
pivot_wider(names_from = age_cat, values_from = n) # A tibble: 3 × 10
# Groups: outcome [3]
outcome `0-4` `5-9` `10-14` `15-19` `20-29` `30-49` `50-69` `70+` `NA`
<chr> <int> <int> <int> <int> <int> <int> <int> <int> <int>
1 Death 471 476 438 323 477 329 33 3 32
2 Recover 364 391 303 251 367 238 38 3 28
3 <NA> 260 228 200 169 229 187 24 NA 26Total de lignes
Lorsque summarise() opère sur des données groupées, il ne produit pas automatiquement des statistiques “totales”. Ci-dessous, deux approches pour ajouter une ligne de total sont présentées :
janitor’s adorn_totals()
Si votre table consiste uniquement en des nombres ou des proportions/pourcentages qui peuvent être additionnés en un total, alors vous pouvez ajouter des totaux sum en utilisant adorn_totals() de janitor comme décrit dans la section ci-dessus. Notez que cette fonction ne peut additionner que les colonnes numériques - si vous voulez calculer d’autres statistiques totales, voyez l’approche suivante avec dplyr.
Ci-dessous, linelist est groupé par sexe et résumé dans un tableau qui décrit le nombre de cas dont l’issue est connue, les décès et les guéris. En passant le tableau à adorn_totals(), on ajoute une ligne de total en bas reflétant la somme de chaque colonne. Les autres fonctions adorn_*() ajustent l’affichage comme indiqué dans le code.
linelist %>%
group_by(gender) %>%
summarise(
known_outcome = sum(!is.na(outcome)), # Nombre de lignes dans le groupe où le outcome n'est pas manquant
n_death = sum(outcome == "Death", na.rm=T), # Nombre de lignes dans le groupe où outcome est égale a Death.
n_recover = sum(outcome == "Recover", na.rm=T), # Nombre de lignes dans le groupe où outcome est egale à Recovered.
) %>%
adorn_totals() %>% # Adorn total ligne (somme de chaque colonne numérique)
adorn_percentages("col") %>% # Obtenir les proportions des colonnes
adorn_pct_formatting() %>% # Convertir les proportions en pourcentages
adorn_ns(position = "front") # Afficher les % et les comptes (avec les comptes en avant) gender known_outcome n_death n_recover
f 2,180 (47.8%) 1,227 (47.5%) 953 (48.1%)
m 2,178 (47.7%) 1,228 (47.6%) 950 (47.9%)
<NA> 207 (4.5%) 127 (4.9%) 80 (4.0%)
Total 4,565 (100.0%) 2,582 (100.0%) 1,983 (100.0%)summarise() Sur “total” des données et ensuite bind_rows()
Si votre tableau est composé de données de synthèse statistiques telles que median(), mean(), etc, l’approche adorn_totals() présentée ci-dessus ne sera pas suffisante. Pour obtenir des données de synthèse pour l’ensemble des données, vous devez les calculer avec une commande séparée summarise() et ensuite lier les résultats au tableau de synthèse original. Pour faire la liaison, vous pouvez utiliser bind_rows() de dplyr comme décrit dans la page Joining data. Vous trouverez ci-dessous un exemple :
Vous pouvez faire un tableau de synthèse des résultats par hôpital avec group_by() et summarise() comme ceci :
by_hospital <- linelist %>%
filter(!is.na(outcome) & hospital != "Missing") %>% # Supprimez les cas avec outcome ou hôpital manquant
group_by(hospital, outcome) %>% # Données du groupe
summarise( # Créer de nouvelles colonnes de résumé des indicateurs intéressants
N = n(), # Nombre de lignes par groupe d'hôpitaux et outcome
ct_value = median(ct_blood, na.rm=T)) # Valeur médiane du CT par groupe
by_hospital # Afficher la table# A tibble: 10 × 4
# Groups: hospital [5]
hospital outcome N ct_value
<chr> <chr> <int> <dbl>
1 Central Hospital Death 193 22
2 Central Hospital Recover 165 22
3 Military Hospital Death 399 21
4 Military Hospital Recover 309 22
5 Other Death 395 22
6 Other Recover 290 21
7 Port Hospital Death 785 22
8 Port Hospital Recover 579 21
9 St. Mark's Maternity Hospital (SMMH) Death 199 22
10 St. Mark's Maternity Hospital (SMMH) Recover 126 22Pour obtenir les totaux, exécutez la même commande summarise() mais regroupez les données uniquement par résultat (et non par hôpital), comme ceci :
totals <- linelist %>%
filter(!is.na(outcome) & hospital != "Missing") %>%
group_by(outcome) %>% # Regroupés uniquement par outcome, et non par hôpital
summarise(
N = n(), # Ces statistiques sont maintenant par outcome seulement
ct_value = median(ct_blood, na.rm=T))
totals # print table# A tibble: 2 × 3
outcome N ct_value
<chr> <int> <dbl>
1 Death 1971 22
2 Recover 1469 22Nous pouvons lier ces deux tableaux ensemble. Notez que by_hospital a 4 colonnes alors que totals a 3 colonnes. En utilisant bind_rows(), les colonnes sont combinées par nom, et tout espace supplémentaire est rempli avec NA (par exemple les valeurs de la colonne hospital pour les deux nouvelles lignes totals). Après avoir lié les lignes, nous convertissons ces espaces vides en “Total” en utilisant replace_na() (voir la page Nettoyage des données et des fonctions de base).
table_long <- bind_rows(by_hospital, totals) %>%
mutate(hospital = replace_na(hospital, "Total"))Voici le nouveau tableau avec les lignes “Total” en bas.
Ce tableau est dans un format “long”, ce qui peut correspondre à ce que vous souhaitez. En option, vous pouvez pivoter ce tableau plus large pour le rendre plus lisible. Consultez la section sur le pivotement plus large ci-dessus, ainsi que la page Pivoter les données. Vous pouvez également ajouter plus de colonnes, et les arranger joliment. Ce code se trouve ci-dessous.
table_long %>%
# Pivot wider and format
########################
mutate(hospital = replace_na(hospital, "Total")) %>%
pivot_wider( # Passer du long au large
values_from = c(ct_value, N), # les nouvelles valeurs proviennent des colonnes ct et count
names_from = outcome) %>% # les nouveaux noms de colonnes proviennent des outcomes
mutate( # Ajouter de nouvelles colonnes
N_Known = N_Death + N_Recover, # nombre avec résultat connu
Pct_Death = scales::percent(N_Death / N_Known, 0.1), # Pourcentage des cas qui sont morts (à une décimale près)
Pct_Recover = scales::percent(N_Recover / N_Known, 0.1)) %>% # Pourcentage de guérison (à une décimale près)
select( # Réorganiser les colonnes
hospital, N_Known, # Introduction de colonnes
N_Recover, Pct_Recover, ct_value_Recover, # Colonnes récupérées
N_Death, Pct_Death, ct_value_Death) %>% # Colonnes de décès
arrange(N_Known) # Ranger les rangées du plus bas au plus haut (rangée totale en bas)# A tibble: 6 × 8
# Groups: hospital [6]
hospital N_Known N_Recover Pct_Recover ct_value_Recover N_Death Pct_Death
<chr> <int> <int> <chr> <dbl> <int> <chr>
1 St. Mark's M… 325 126 38.8% 22 199 61.2%
2 Central Hosp… 358 165 46.1% 22 193 53.9%
3 Other 685 290 42.3% 21 395 57.7%
4 Military Hos… 708 309 43.6% 22 399 56.4%
5 Port Hospital 1364 579 42.4% 21 785 57.6%
6 Total 3440 1469 42.7% 22 1971 57.3%
# ℹ 1 more variable: ct_value_Death <dbl>Et vous pouvez ensuite afficher ce tableau sous la forme d’une image. Vous trouverez ci-dessous le résultat imprimé avec flextable. Vous pouvez lire plus en détail cet exemple et la façon d’obtenir ce “joli” tableau sur la page Tableaux pour la présentation.
Hospital | Total cases with known outcome | Recovered | Died | ||||
|---|---|---|---|---|---|---|---|
Total | % of cases | Median CT values | Total | % of cases | Median CT values | ||
St. Mark's Maternity Hospital (SMMH) | 325 | 126 | 38.8% | 22 | 199 | 61.2% | 22 |
Central Hospital | 358 | 165 | 46.1% | 22 | 193 | 53.9% | 22 |
Other | 685 | 290 | 42.3% | 21 | 395 | 57.7% | 22 |
Military Hospital | 708 | 309 | 43.6% | 22 | 399 | 56.4% | 21 |
Missing | 1,125 | 514 | 45.7% | 21 | 611 | 54.3% | 21 |
Port Hospital | 1,364 | 579 | 42.4% | 21 | 785 | 57.6% | 22 |
Total | 3,440 | 1,469 | 42.7% | 22 | 1,971 | 57.3% | 22 |
17.5 gtsummary package
Si vous voulez afficher vos synthèses statistiques dans un joli graphique, vous pouvez utiliser le package gtsummary et sa fonction tbl_summary(). Le code peut sembler complexe au début, mais les résultats sont très jolis et apparaissent dans votre panneau de visualisation RStudio sous forme d’image HTML. Lire une vignette ici.
Vous pouvez également ajouter les résultats des tests statistiques aux tableaux gtsummary. Ce processus est décrit dans la section gtsummary de la page Tests statistiques simples.
Pour présenter tbl_summary(), nous allons d’abord montrer le comportement le plus basique, qui produit effectivement un grand et beau tableau. Ensuite, nous examinerons en détail comment faire des ajustements et des tableaux plus adaptés.
Tableau de synthèse
Le comportement par défaut de tbl_summary() est assez incroyable - il prend les colonnes que vous fournissez et crée un tableau de synthèse en une seule commande. La fonction affiche les statistiques appropriées à la classe de la colonne : la médiane et l’écart inter-quartile (IQR) pour les colonnes numériques, et le nombre (%) pour les colonnes catégorielles. Les valeurs manquantes sont converties en “Inconnu”. Des notes de bas de page sont ajoutées en bas de page pour expliquer les statistiques, tandis que le N total est affiché en haut de page.
linelist %>%
select(age_years, gender, outcome, fever, temp, hospital) %>% # ne gardez que les colonnes d'intérêt
tbl_summary() # defaut| Characteristic | N = 5,8881 |
|---|---|
| age_years | 13 (6, 23) |
| Unknown | 86 |
| gender | |
| f | 2,807 (50%) |
| m | 2,803 (50%) |
| Unknown | 278 |
| outcome | |
| Death | 2,582 (57%) |
| Recover | 1,983 (43%) |
| Unknown | 1,323 |
| fever | 4,549 (81%) |
| Unknown | 249 |
| temp | 38.80 (38.20, 39.20) |
| Unknown | 149 |
| hospital | |
| Central Hospital | 454 (7.7%) |
| Military Hospital | 896 (15%) |
| Missing | 1,469 (25%) |
| Other | 885 (15%) |
| Port Hospital | 1,762 (30%) |
| St. Mark's Maternity Hospital (SMMH) | 422 (7.2%) |
| 1 Median (IQR); n (%) | |
Ajustements
Nous allons maintenant expliquer le fonctionnement de la fonction et la manière de procéder aux ajustements. Les principaux arguments sont détaillés ci-dessous :
by = Vous pouvez stratifier votre tableau par une colonne (par exemple par outcome), créant ainsi un tableau à 2 dimensions.
statistic = Utilisez une équation pour spécifier les statistiques à afficher et comment les afficher. L’équation comporte deux côtés, séparés par un tilde ~. Sur le côté droit, entre guillemets, se trouve l’affichage statistique souhaité, et sur la gauche se trouvent les colonnes auxquelles cet affichage s’appliquera.
- Le côté droit de l’équation utilise la syntaxe de
str_glue()de stringr (voir Caractères et chaînes de caractères), avec la chaîne d’affichage souhaitée entre guillemets et les statistiques elles-mêmes entre crochets. Vous pouvez inclure des statistiques comme “n” (pour les comptes), “N” (pour le dénominateur), “mean”, “median”, “sd”, “max”, “min”, les percentiles comme “p##” comme “p25”, ou le pourcentage du total comme “p”. Voir?tbl_summarypour plus de détails. - Pour le côté gauche de l’équation, vous pouvez spécifier les colonnes par leur nom (par exemple,
ageouc(age, gender)) ou en utilisant des aides telles queall_continuous(),all_categorical(),contains(),starts_with(), etc.
Un exemple simple d’équation statistic = pourrait ressembler à ce qui suit, pour afficher uniquement la moyenne de la colonne age_years :
linelist %>%
select(age_years) %>% # Ne gardez que les colonnes d'intérêt
tbl_summary( # créer un tableau récapitulatif
statistic = age_years ~ "{mean}") # Impression de la moyenne d'âge| Characteristic | N = 5,8881 |
|---|---|
| age_years | 16 |
| Unknown | 86 |
| 1 Mean | |
Une équation un peu plus complexe pourrait ressembler à "({min}, {max})", incorporant les valeurs max et min entre parenthèses et séparées par une virgule :
linelist %>%
select(age_years) %>% # Ne gardez que les colonnes d'intérêt
tbl_summary( # créer un tableau résumé
statistic = age_years ~ "({min}, {max})") # Impression des valeurs minimale et maximale de l'âge| Characteristic | N = 5,8881 |
|---|---|
| age_years | (0, 84) |
| Unknown | 86 |
| 1 (Range) | |
Vous pouvez également différencier la syntaxe pour des colonnes ou des types de colonnes distincts. Dans l’exemple plus complexe ci-dessous, la valeur fournie à statistc = est une liste indiquant que pour toutes les colonnes continues, le tableau doit afficher la moyenne avec l’écart-type entre parenthèses, tandis que pour toutes les colonnes catégorielles, il doit afficher le n, le dénominateur et le pourcentage.
digits = Ajuste les chiffres et les arrondis. En option, il est possible de spécifier que cela ne concerne que les colonnes continues (comme ci-dessous).
label = Ajustez la façon dont le nom de la colonne doit être affiché. Fournissez le nom de la colonne et son étiquette souhaitée, séparés par un tilde. La valeur par défaut est le nom de la colonne.
missing_text = Ajustez la façon dont les valeurs manquantes sont affichées. La valeur par défaut est “Inconnu”.
type = Permet de régler le nombre de niveaux de statistiques à afficher. La syntaxe est similaire à statistic = en ce sens que vous fournissez une équation avec des colonnes à gauche et une valeur à droite. Voici deux scénarios courants :
type = all_categorical() ~ "categorical"Force les colonnes dichotomiques (par exemple,fièvreoui/non) à montrer tous les niveaux au lieu de ne montrer que la ligne “oui”type = all_continuous() ~ "continuous2"Permet des statistiques multi-lignes par variable, comme indiqué dans une section ultérieure.
Dans l’exemple ci-dessous, chacun de ces arguments est utilisé pour modifier le tableau de synthèse original :
linelist %>%
select(age_years, gender, outcome, fever, temp, hospital) %>% # Ne gardez que les colonnes d'intérêt
tbl_summary(
by = outcome, # stratifier le tableau entier par résultat
statistic = list(all_continuous() ~ "{mean} ({sd})", # stats et format pour les colonnes continues
all_categorical() ~ "{n} / {N} ({p}%)"), # stats et format pour les colonnes catégorielles
digits = all_continuous() ~ 1, # arrondi pour les colonnes continues
type = all_categorical() ~ "categorical", # force l'affichage de tous les niveaux catégoriels
label = list( # affichage des étiquettes pour les noms de colonnes
outcome ~ "Outcome",
age_years ~ "Age (years)",
gender ~ "Gender",
temp ~ "Temperature",
hospital ~ "Hospital"),
missing_text = "Missing" # comment les valeurs manquantes doivent être affichées
)1323 observations missing `outcome` have been removed. To include these observations, use `forcats::fct_na_value_to_level()` on `outcome` column before passing to `tbl_summary()`.| Characteristic | Death, N = 2,5821 | Recover, N = 1,9831 |
|---|---|---|
| Age (years) | 15.9 (12.3) | 16.1 (13.0) |
| Missing | 32 | 28 |
| Gender | ||
| f | 1,227 / 2,455 (50%) | 953 / 1,903 (50%) |
| m | 1,228 / 2,455 (50%) | 950 / 1,903 (50%) |
| Missing | 127 | 80 |
| fever | ||
| no | 458 / 2,460 (19%) | 361 / 1,904 (19%) |
| yes | 2,002 / 2,460 (81%) | 1,543 / 1,904 (81%) |
| Missing | 122 | 79 |
| Temperature | 38.6 (1.0) | 38.6 (1.0) |
| Missing | 60 | 55 |
| Hospital | ||
| Central Hospital | 193 / 2,582 (7.5%) | 165 / 1,983 (8.3%) |
| Military Hospital | 399 / 2,582 (15%) | 309 / 1,983 (16%) |
| Missing | 611 / 2,582 (24%) | 514 / 1,983 (26%) |
| Other | 395 / 2,582 (15%) | 290 / 1,983 (15%) |
| Port Hospital | 785 / 2,582 (30%) | 579 / 1,983 (29%) |
| St. Mark's Maternity Hospital (SMMH) | 199 / 2,582 (7.7%) | 126 / 1,983 (6.4%) |
| 1 Mean (SD); n / N (%) | ||
Statistiques multi-lignes pour les variables continues
Si vous souhaitez afficher plusieurs lignes statistiques pour des variables continues, vous pouvez l’indiquer en définissant le type = à “continuous2”. Vous pouvez combiner tous les éléments présentés précédemment dans un seul tableau en choisissant les statistiques que vous voulez afficher. Pour cela, vous devez indiquer à la fonction que vous voulez récupérer un tableau en entrant le type comme “continuous2”. Le nombre de valeurs manquantes est indiqué comme “Inconnu”.
linelist %>%
select(age_years, temp) %>% # Ne garder que les colonnes d'intérêt
tbl_summary( # # créer un tableau résume
type = all_continuous() ~ "continuous2", # indique que vous voulez imprimer plusieurs statistiques
statistic = all_continuous() ~ c(
"{mean} ({sd})", # ligne 1 : moyenne et SD
"{median} ({p25}, {p75})", # ligne 2 : médiane et IQR
"{min}, {max}") # ligne 3: min et max
)| Characteristic | N = 5,888 |
|---|---|
| age_years | |
| Mean (SD) | 16 (13) |
| Median (IQR) | 13 (6, 23) |
| Range | 0, 84 |
| Unknown | 86 |
| temp | |
| Mean (SD) | 38.56 (0.98) |
| Median (IQR) | 38.80 (38.20, 39.20) |
| Range | 35.20, 40.80 |
| Unknown | 149 |
Il existe de nombreuses autres façons de modifier ces tableaux, notamment en ajoutant des valeurs p, en ajustant la couleur et les titres, etc. La plupart sont décrites dans la documentation (entrez ?tbl_summary dans Console), et certaines sont données dans la section sur les tests statistiques.
17.6 extension/package R base
Vous pouvez utiliser la fonction table() pour faire des tableaux et des tableaux croisés de colonnes. Contrairement aux options ci-dessus, vous devez spécifier le tableau de données chaque fois que vous faites référence à un nom de colonne, comme indiqué ci-dessous.
CAUTION: Les valeurs NA(manquantes) ne seront pas affichées en tableau, à moins que vous n’incluiez l’argument useNA = "always" (qui peut également être défini sur “no” ou “ifany”).
TIP: Vous pouvez utiliser le %$% de magrittr pour supprimer la répétition des enregistrements de données du tableaux dans les fonctions base. Par exemple, on pourrait écrire linelist %$% table(outcome, useNA = "always").
table(linelist$outcome, useNA = "always")
Death Recover <NA>
2582 1983 1323 Plusieurs colonnes peuvent être croisées en les listant l’une après l’autre, séparées par des virgules. En option, vous pouvez attribuer à chaque colonne un “nom” comme Outcome = linelist$outcome.
age_by_outcome <- table(linelist$age_cat, linelist$outcome, useNA = "always") # sauvegarder le tableau comme objet
age_by_outcome # imprimer le tableau
Death Recover <NA>
0-4 471 364 260
5-9 476 391 228
10-14 438 303 200
15-19 323 251 169
20-29 477 367 229
30-49 329 238 187
50-69 33 38 24
70+ 3 3 0
<NA> 32 28 26Proportions
Pour retourner les proportions, passez le tableau ci-dessus à la fonction prop.table(). Utilisez l’argument margins = pour spécifier si vous voulez que les proportions soient des lignes (1), des colonnes (2), ou du tableau entier (3). Pour plus de précisions, nous envoyons le tableau à la fonction round() de base R, en spécifiant 2 chiffres.
# obtenir les proportions du tableau défini ci-dessus, par lignes, arrondies
prop.table(age_by_outcome, 1) %>% round(2)
Death Recover <NA>
0-4 0.43 0.33 0.24
5-9 0.43 0.36 0.21
10-14 0.47 0.32 0.21
15-19 0.43 0.34 0.23
20-29 0.44 0.34 0.21
30-49 0.44 0.32 0.25
50-69 0.35 0.40 0.25
70+ 0.50 0.50 0.00
<NA> 0.37 0.33 0.30Totals
Pour ajouter les totaux des lignes et des colonnes, passez le tableau à addmargins(). Cela fonctionne à la fois pour les nombres et les proportions.
addmargins(age_by_outcome)
Death Recover <NA> Sum
0-4 471 364 260 1095
5-9 476 391 228 1095
10-14 438 303 200 941
15-19 323 251 169 743
20-29 477 367 229 1073
30-49 329 238 187 754
50-69 33 38 24 95
70+ 3 3 0 6
<NA> 32 28 26 86
Sum 2582 1983 1323 5888Convertir en tableau de données
Convertir un objet table() directement en tableau de données n’est pas simple. Une approche est démontrée ci-dessous :
- Créez la table, sans utiliser
useNA = "always". A la place, convertissez les valeursNAen “(Missing)” avecfct_explicit_na()de forcats. - Ajoutez les totaux (facultatif) en utilisant
addmargins(). - Passez le tableau dans la fonction R base
as.data.frame.matrix(). - Passez le tableau dans la fonction tibble
rownames_to_column(), en spécifiant le nom de la première colonne. - Affichez, visualisez ou exportez comme vous le souhaitez. Dans cet exemple, nous utilisons
flextable()du package flextable comme décrit dans la page Tableaux pour la présentation. Cela permettra d’afficher dans le volet de visualisation de RStudio une jolie image HTML.
table(fct_explicit_na(linelist$age_cat), fct_explicit_na(linelist$outcome)) %>%
addmargins() %>%
as.data.frame.matrix() %>%
tibble::rownames_to_column(var = "Age Category") %>%
flextable::flextable()Age Category | Death | Recover | (Missing) | Sum |
|---|---|---|---|---|
0-4 | 471 | 364 | 260 | 1,095 |
5-9 | 476 | 391 | 228 | 1,095 |
10-14 | 438 | 303 | 200 | 941 |
15-19 | 323 | 251 | 169 | 743 |
20-29 | 477 | 367 | 229 | 1,073 |
30-49 | 329 | 238 | 187 | 754 |
50-69 | 33 | 38 | 24 | 95 |
70+ | 3 | 3 | 0 | 6 |
(Missing) | 32 | 28 | 26 | 86 |
Sum | 2,582 | 1,983 | 1,323 | 5,888 |
17.7 Ressources
La plupart des informations contenues dans cette page sont issues de ces ressources et des sites Internet :