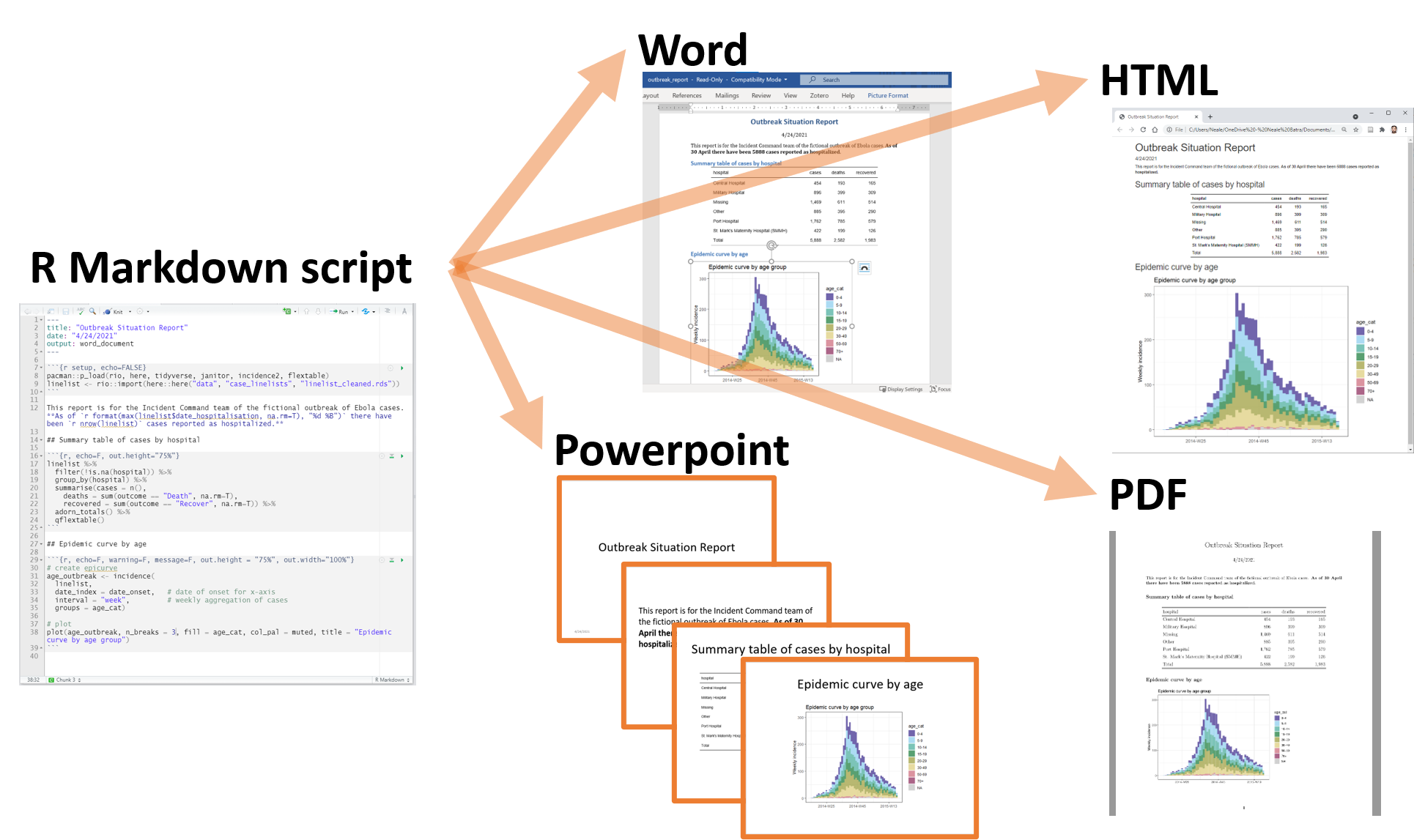
40 Informes con R Markdown
R Markdown es una herramienta ampliamente utilizada para crear documentos de salida automatizados, reproducibles y dignos de compartir, como por ejemplo, informes. Podés generar resultados estáticos o interactivos en Word, pdf, html, powerpoint y otros formatos.
Un script de R Markdown intercala código R y texto de tal manera que el script se convierte en tu documento de salida. Puedes crear un documento completo con formato, incluyendo texto narrativo (el texto puede ser dinámico y cambiar en función de sus datos), tablas, figuras, viñetas/números, bibliografías, etc.
Estos documentos pueden producirse para ser actualizados de forma rutinaria (por ejemplo, informes de vigilancia diarios) y/o ejecutarse sobre subconjuntos de datos (por ejemplo, informes para cada jurisdicción).
Otras páginas de este manual amplían este tema:
- La página Organización de informes rutinarios muestra cómo “rutinizar” la producción de informes con carpetas autogeneradas con marca de tiempo.
- La página Dashboards con R Markdown explica cómo formatear un informe de R Markdown como un cuadro de mando o tablero de control.
Cabe destacar que el proyecto R4Epis ha desarrollado plantillas de scripts R Markdown para los escenarios de brotes y encuestas de uso frcuente en lugares en donde MSF maneja proyectos.
40.1 Preparación
Antecedentes de R Markdown
Explicamos algunos de los conceptos y paquetes involucrados:
- Markdown es un “lenguaje” que permite escribir un documento en texto plano, que se puede convertir a html y otros formatos. No es específico de R. Los archivos escritos en Markdown tienen una extensión ‘.md’.
- R Markdown: es una variación de markdown que es específica de R - te permite escribir un documento usando markdown para producir texto y para integrar código R y mostrar sus resultados. Los archivos R Markdown tienen la extensión ‘.Rmd’.
- rmarkdown - el paquete: Usado por R para convertir el archivo .Rmd en el tipo de documento de salida deseado. Su objetivo es convertir la sintaxis markdown (texto), por lo que también necesitamos…
- knitr: Este paquete de R leerá los trozos de código, los ejecutará y los “tejerá” dentro del documento. Así es como se incluyen las tablas y los gráficos junto al texto.
- Pandoc: Por último, pandoc convierte el documento de salida en word/pdf/powerpoint, etc. Es un software independiente de R, y viene instalado automáticamente con RStudio.
En resumen, el proceso que ocurre en segundo plano (¡no es necesario que conozcas todos estos pasos!) consiste en alimentar el archivo .Rmd a knitr, que ejecuta los trozos de código R y crea un nuevo archivo .md (markdown) que incluye el código R y su salida renderizada. El archivo .md es entonces procesado por pandoc para crear el producto final: un documento de Microsoft Word, un archivo HTML, un documento powerpoint, un pdf, etc.

(fuente: https://rmarkdown.rstudio.com/authoring_quick_tour.html):
Instalación
Para crear una salida de R Markdown, necesitas tener instalado lo siguiente:
- El paquete rmarkdown (knitr también se instalará automáticamente)
- Pandoc, que debería venir instalado con RStudio. Si no utilizas RStudio, podés descargar Pandoc aquí: http://pandoc.org .
- Si querés generar una salida en PDF (un poco más complicado), necesitarás instalar LaTeX. Para los usuarios de R Markdown que no hayan instalado LaTeX antes, recomendamos que instalen TinyTeX (https://yihui.name/tinytex/)https://yihui.name/tinytex/). Puedes utilizar los siguientes comandos:
pacman::p_load(tinytex) # instala el paquete tinytex
tinytex::install_tinytex() # Comando de R para instalar el software TinyTeX40.2 Cómo empezar
Instalar el paquete R rmarkdown
Instalá el paquete R rmarkdown. En este manual destacamos p_load() de pacman, que instala el paquete si es necesario y ademas lo carga para su uso. También podés cargar los paquetes instalados con library() de R base. Consultá la página sobre fundamentos de R para obtener más información sobre los paquetes de R.
pacman::p_load(rmarkdown)Iniciar un nuevo archivo Rmd
En RStudio, abrí un nuevo archivo R markdown, comenzando con ‘File’, luego ‘New file’ luego ‘R markdown…’.
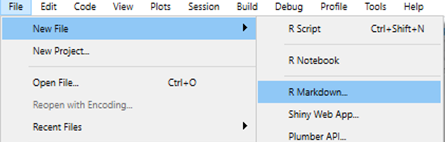
R Studio te dará algunas opciones de salida para elegir. En el ejemplo siguiente seleccionamos “HTML” porque queremos crear un documento html. El título y los nombres de los autores no son importantes. Si el tipo de documento de salida que desea no es uno de estos, no te preocupes - podés elegir cualquiera y cambiarlo en el script más tarde.
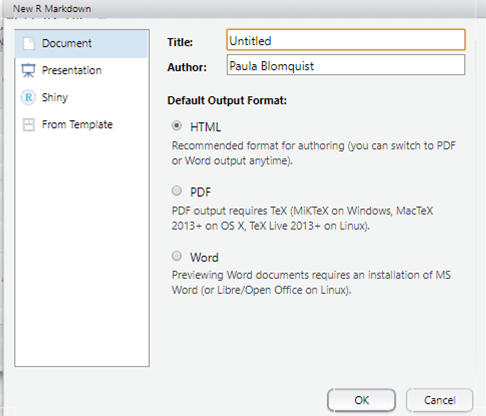
Esto abrirá un nuevo script .Rmd.
Es importante saber
El directorio de trabajo
El directorio de trabajo de un archivo markdown es el lugar donde se guarda el propio archivo Rmd. Por ejemplo, si el proyecto R está dentro de ~/Documents/projectX y el archivo Rmd en sí está en una subcarpeta ~/Documents/projectX/markdownfiles/markdown.Rmd, el código read.csv("data.csv") dentro del markdown buscará un archivo csv en la carpeta markdownfiles, y no en la carpeta raíz del proyecto donde los scripts dentro de los proyectos normalmente buscarían archivos de manera automática.
Para referirse a archivos en otro lugar, tendrá que utilizar la ruta completa del archivo o utilizar el paquete here. El paquete here establece el directorio de trabajo en la carpeta raíz del proyecto R y se explica en detalle en las páginas de proyectos R e importación y exportación de este manual. Por ejemplo, para importar un archivo llamado “data.csv” desde la carpeta projectX, el código sería import(here("data.csv")).
Ten en cuenta que no se recomienda el uso de setwd() en los scripts de R Markdown - sólo se aplica al trozo de código en el que está escrito.
Trabajar en una unidad versus tu ordenador
Debido a que R Markdown puede tener problemas con pandoc cuando se ejecuta en una unidad de red compartida, se recomienda que la carpeta esté ubicada en tu máquina local, por ejemplo, en un proyecto dentro de ‘Mis Documentos’. Si utilizas Git (¡super recomendable!), esto te resultará familiar. Para más detalles, consulta las páginas del manual sobre R en unidades de red y Errores y ayuda.
40.3 Componentes de R Markdown
Un documento R Markdown puede ser editado en RStudio igual que un script estándar de R. Cuando se inicia un nuevo script de R Markdown, RStudio intenta ayudarnos mostrando una plantilla que explica las diferentes secciones de un script de R Markdown.
Lo que aparece a continuación es lo que veremos al iniciar un nuevo script Rmd destinado a producir un documento de salida en html (según la sección anterior).
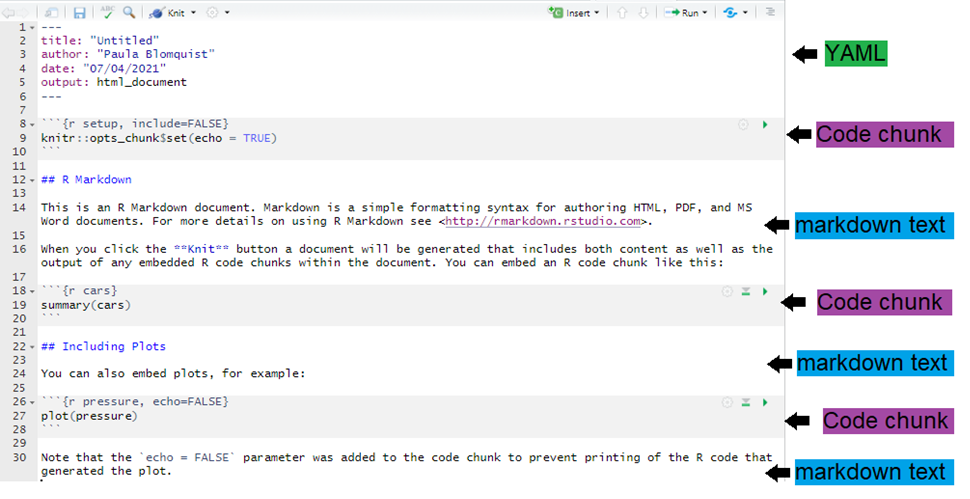
Como puedes ver, hay tres componentes básicos en un archivo Rmd: YAML, texto Markdown y trozos de código R.
Estos crearán y se convertirán en la salida de su documento. Consulta el siguiente diagrama:
![]()
Metadatos YAML
Denominado ‘metadatos YAML’ o simplemente ‘YAML’, se encuentra en la parte superior del documento R Markdown. Esta sección del script le dirá a su archivo Rmd qué tipo de salida producir, preferencias de formato y otros metadatos como el título del documento, el autor y la fecha. Hay otros usos que no se mencionan aquí (pero a los que se hace referencia en ‘Producción del documento de salida’). Ten en cuenta que la sangría es importante; los tabuladores no se aceptan, pero los espacios sí.
Esta sección debe comenzar con una línea que contenga sólo tres guiones --- y debe cerrar con una línea que contenga sólo tres guiones ---. Los parámetros YAML vienen en pares key:value. La colocación de los dos puntos en YAML es importante - los pares key:value están separados por dos puntos (¡no por signos de igualdad!).
El YAML debe comenzar con los metadatos del documento. El orden de estos parámetros YAML primarios (sin sangría) no importa. Por ejemplo:
title: "My document"
author: "Me"
date: "2024-06-19"Puedes utilizar código R en valores YAML escribiéndolo como código en línea (precedido por r entre comillas) pero también entre comillas (véase el ejemplo anterior para date:).
En la imagen de arriba, porque hemos seleccionado el tipo de documento de salida como html, podemos ver que el YAML dice output: html_document. Sin embargo, también podemos cambiar esto escribir powerpoint_presentation o word_document o incluso pdf_document.
Texto
Esta es la narrativa de t u documento, incluyendo los títulos y encabezados. Está escrito en el lenguaje “markdown”, que se utiliza en muchos otros programas.
A continuación se presentan las formas principales de escribir este texto. Podés consultar material de referencia más detallado disponible en R Markdown “cheatsheet” en el sitio web de RStudio.
Nuevas líneas
En R Markdown, para iniciar una nueva línea, introducí *dos espacios** al final de la línea anterior y luego Enter/Return. Esto es una particularidad de R Markdown.
Formato de texto
Rodea el texto normal con estos caracteres para cambiar su apariencia en la salida.
- Guiones bajos (
_texto_) o un asterisco simple (*texto*) para poner en cursiva (itálica) - Doble asterisco (
**texto**) para el texto en negrita - Comillas invertidas
(texto)para mostrar el texto como código
El aspecto real de la fuente puede establecerse utilizando plantillas específicas (especificadas en los metadatos YAML; ver sub-secciones de este capitulo).
Color
No existe un mecanismo sencillo para cambiar el color del texto en R Markdown. Como solución, si tu salida es un archivo HTML, es añadir una línea de codigo HTML en el texto de Markdown. El siguiente código HTML imprimirá una línea de texto en negrita roja.
<span style="color: red;">**_PELIGRO:_** Esto es una advertencia.</span> PELIGRO: Esto es una advertencia.
Títulos y encabezamientos
Un símbolo de almohadilla (hash #) delante de un texto en un script de R Markdown crea un encabezado. Esto es diferente que en un trozo de código R en el script, en el que un símbolo de almohadilla permite comentar/anotar/desactivar, como en un script normal de R.
Los distintos niveles de encabezamiento se establecen con diferentes números de símbolos de almohadilla al comienzo de una nueva línea. Un solo símbolo de almohadilla genera un título o encabezamiento primario. Dos símbolos hash generan un encabezamiento de segundo nivel. Los encabezamientos de tercer y cuarto nivel pueden hacerse con más símbolos hash sucesivamente.
# Encabezamiento / título de primer nivel
## Encabezamiento de segundo nivel
### Encabezamiento de tercer nivelViñetas y numeración
Utilizá asteriscos (*) para crear una lista de viñetas. Completá la frase anterior, introducí dos espacios, presioná Enter/Return dos veces, y luego comenzá tus viñetas. Incluí un espacio entre el asterisco y el texto de tu viñeta. Después de cada viñeta, introducí dos espacios y luego presioná Enter/Return. Las sub-viñetas funcionan de la misma manera pero con sangría. Los números funcionan de la misma manera, pero en lugar de un asterisco, escribí 1), 2), etc. El texto de tu script de R Markdown se vería como mostramos a continuación.
Aquí están mis viñetas (hay dos espacios después de los dos puntos):
* Viñeta 1 (seguida de dos espacios y Enter/Return)
* Viñeta 2 (seguida de dos espacios y Enter/Return)
* Sub-viñeta 1 (seguida de dos espacios y Enter/Return)
* Sub-viñeta 2 (seguida de dos espacios y Enter/Return)
* Subbalanceo 2 (seguido de dos espacios y Enter/Return)Comentar el texto
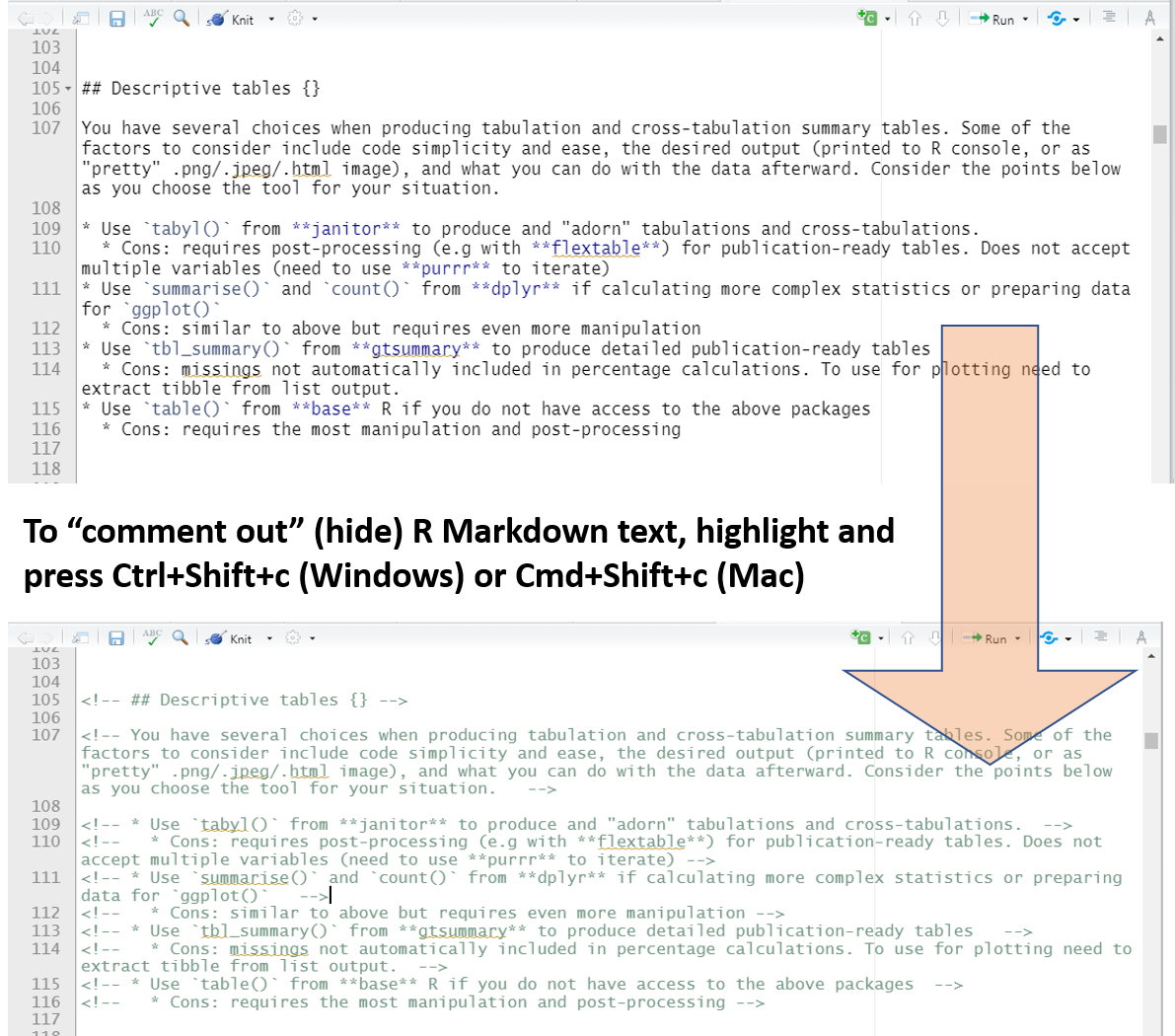
Puedes desactivar o “esconder” el texto de R Markdown del mismo modo que puede utilizar el “#” para desactivar una línea de código en un chunk de R. Simplemente resalta el texto y clica Ctrl+Mayús+c (Cmd+Mayús+c para Mac). El texto aparecerá rodeado de flechas y se volverá verde. No aparecerá en tu salida.
Trozos de código (chunks)
Las secciones del script que se dedican a ejecutar el código R se denominan “chunks” o trozos. Aquí es donde se pueden cargar paquetes, importar datos y realizar la gestión y visualización de datos propiamente dicha. Puede haber muchos trozos de código, por lo que puede ser de ayuda organizar tu código R en partes, quizás intercaladas con texto. Para tener en cuenta: estos trozos tendrán un color de fondo ligeramente diferente al de la parte narrativa del documento.
Cada trozo se abre con una línea que comienza con tres comillas invertidas y corchetes que contienen parámetros para el trozo ({ }). El trozo termina con otras tres comillas invertidas.
Puedes crear un nuevo fragmento escribiendo tú mismo las marcas, utilizando el atajo de teclado “Ctrl + Alt + i” (o Cmd + Shift + r en Mac), o clicando en el icono verde ‘insert a new code chunk’ en la parte superior de tu editor de scripts.
Algunas notas sobre el contenido de las corchetes { }:
- Empiezan con una “r” para indicar que el nombre del idioma dentro del chunk es R
- Después de la r puedes asignarle un “nombre” al chunk - no es necesario pero puede ayudarte a organizar tu trabajo. Ten en cuenta que si nombras tus chunks, debes usar SIEMPRE nombres únicos o de lo contrario R se quejará cuando intentes procesarlos.
- Los corchetes pueden incluir también otras opciones, escritas como
tag=value, como por ejemplo eval = FALSEpara no ejecutar el código Recho = FALSEpara no imprimir o esconder el código fuente de R del chunk en el documento de salidawarning = FALSEpara no imprimir las advertencias producidas por el código Rmessage = FALSEpara no imprimir ningún mensaje producido por el código Rinclude = TRUE/FALSEpara incluir (o no) los resultados generados por los trozos (por ejemplo, los gráficos) en el documento de salidaout.width =yout.height =- asigna proporciones de ancho y largo, por ejemploout.width = "75%"fig.align = "center"ajusta cómo se alinea una figura en la páginafig.show = 'hold'si tu chunk imprime múltiples figuras y querés imprimirlas una al lado de la otra usá también la funciónout.width = c("33%", "67%"). También podés establecer comofig.show='asis'para mostrarlas debajo del código que las genera,'hide'para ocultarlas, o'animate'para concatenar varias figuras en una animación.
- La cabecera de un trozo debe escribirse en una sola línea
- Intentá evitar puntos, barras bajas y espacios. Utiliza guiones ( - ) en su lugar si necesitas un separador.
Leé más extensamente sobre las opciones de knitr aquí.
Algunas de estas opciones pueden configurarse usando los botones de configuración situados en la parte superior derecha del chunk. Aquí puedes especificar qué partes del chunk quieres incluir en el documento renderizado, es decir, el código, las salidas generadas y las advertencias. Estas preferencias aparecerán escritas como código dentro de los corchetes, por ejemplo, si especificás que querés mostrar sólo la salida (‘Show output only’) aparecerá echo=FALSE entre los corchetes.

También hay dos flechas en la parte superior derecha de cada trozo, que son útiles para ejecutar el código dentro de un trozo, o todo el código en trozos anteriores. Pasa el cursor por encima de estos iconos para ver lo que hacen.
Para que las opciones globales se apliquen a todos los chunks del script, podés configurar esto dentro del primer chunk de código R en el script. Por ejemplo, para sólo muestrar las salidas generadas por cada trozo de código y no el propio código, podés incluir este comando en el trozo de código R:
knitr::opts_chunk$set(echo = FALSE) Código R en el texto
También se puede insertar un mínimo de código R entre comillas invertidas (back ticks) intercalado entre el texto narrativo. Dentro de las comillas invertidas, comenzá el código con la letra “r” y un espacio, para que RStudio sepa que debe evaluar el código como código R. Ver el siguiente ejemplo.
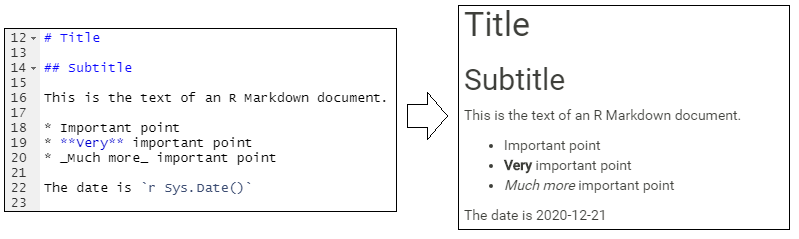
El ejemplo siguiente muestra múltiples niveles de encabezamiento, viñetas, y utiliza el código (Sys.Date()) para obtener y mostrar la fecha actual.
El ejemplo anterior es sencillo (muestra la fecha actual), pero utilizando la misma sintaxis puede mostrar valores producidos por un código R más complejo (por ejemplo, para calcular el mínimo, la mediana o el máximo de una columna). También podés integrar objetos R o valores que han sido creados en trozos de código R anteriores.
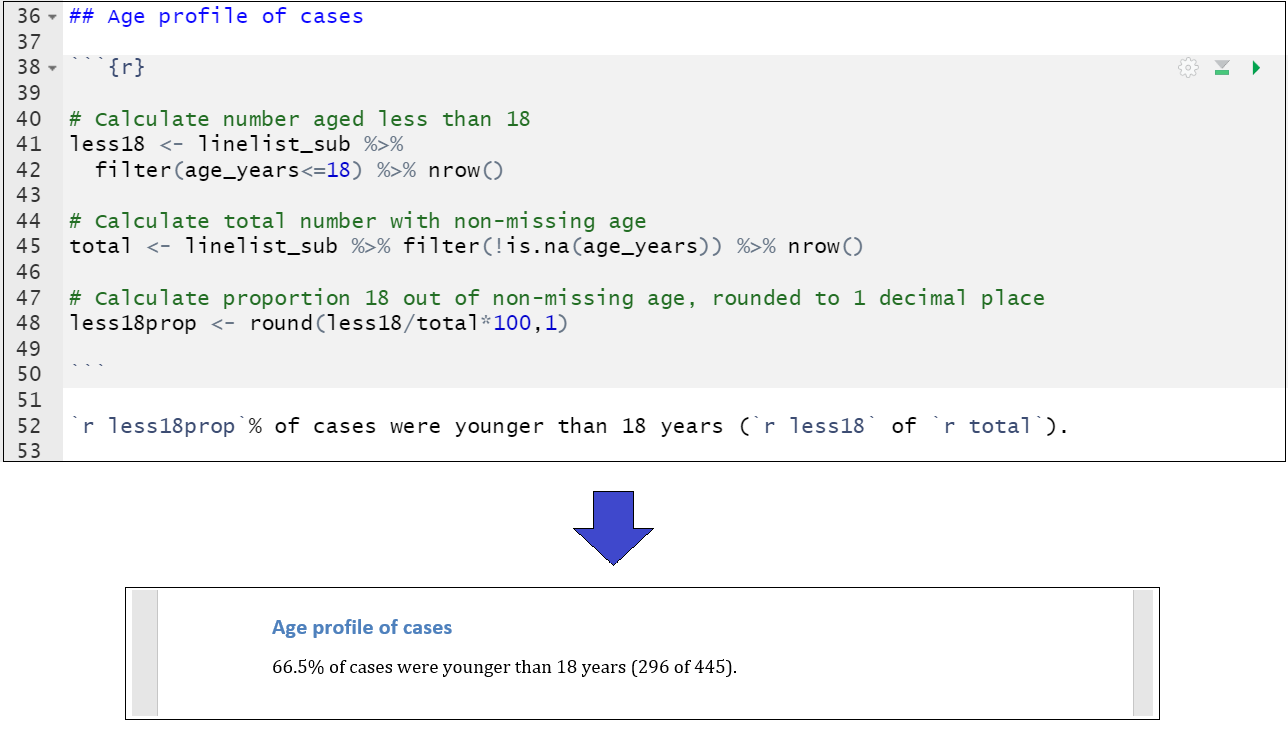
Como ejemplo, el siguiente script calcula la proporción de casos que tienen menos de 18 años, utilizando funciones tidyverse, y crea los objetos less18, total y less18prop. Este valor dinámico se inserta en el texto narrativo. Vemos cómo queda cuando se teje en un documento de Word.
Imágenes
Hay dos maneras de incluir imágenes en R Markdown:
 Si el código anterior no funciona, probá utilizar knitr::include_graphics()
knitr::include_graphics("path/to/image.png")(recordá que podes declarar la ruta de tu archivo usando el paquete here)
knitr::include_graphics(here::here("path", "to", "image.png"))Tablas
Creá una tabla utilizando guiones ( - ) y barras ( | ). El número de guiones entre las barras determina el número de espacios en la celda a patrir del cual el texto comienza a envolverse.
Column 1 |Column 2 |Column 3
----------|-----------|--------
Cell A |Cell B |Cell C
Cell D |Cell E |Cell FEl código anterior produce la siguiente tabla:
| Column 1 | Column 2 | Column 3 |
|---|---|---|
| Cell A | Cell B | Cell C |
| Cell D | Cell E | Cell F |
Secciones con pestañas
Para las salidas HTML, podés organizar las secciones con “pestañas”. Basta con añadir .tabset entre las llaves { } que se colocan después de un encabezamiento. Todos los subtítulos debajo de ese encabezado (hasta el próximo encabezado del mismo nivel) aparecerán como pestañas en las que el usuario puedes clicar. Lee más aquí
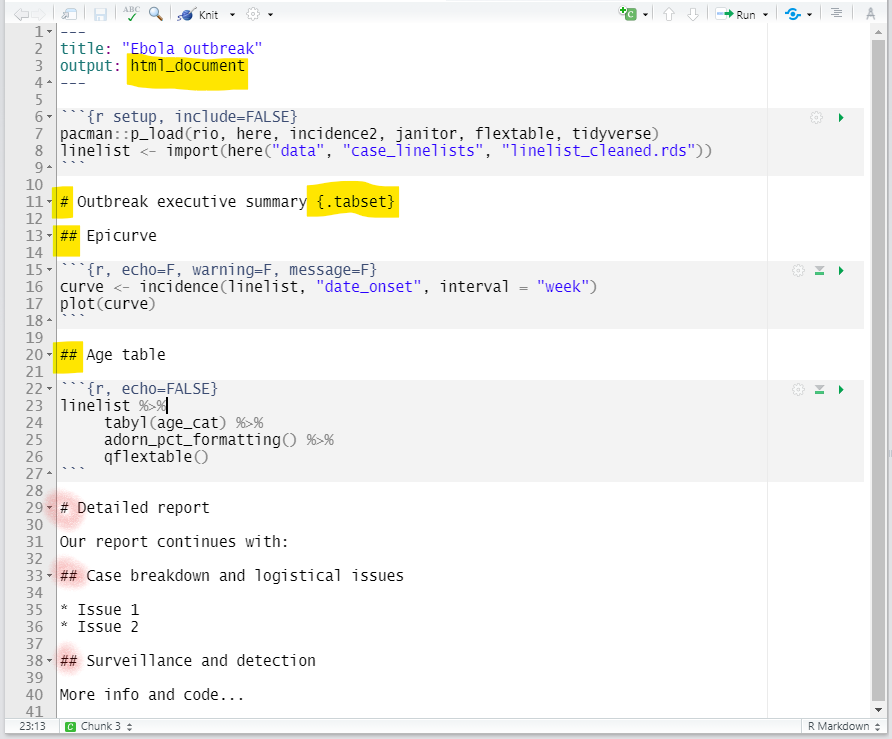
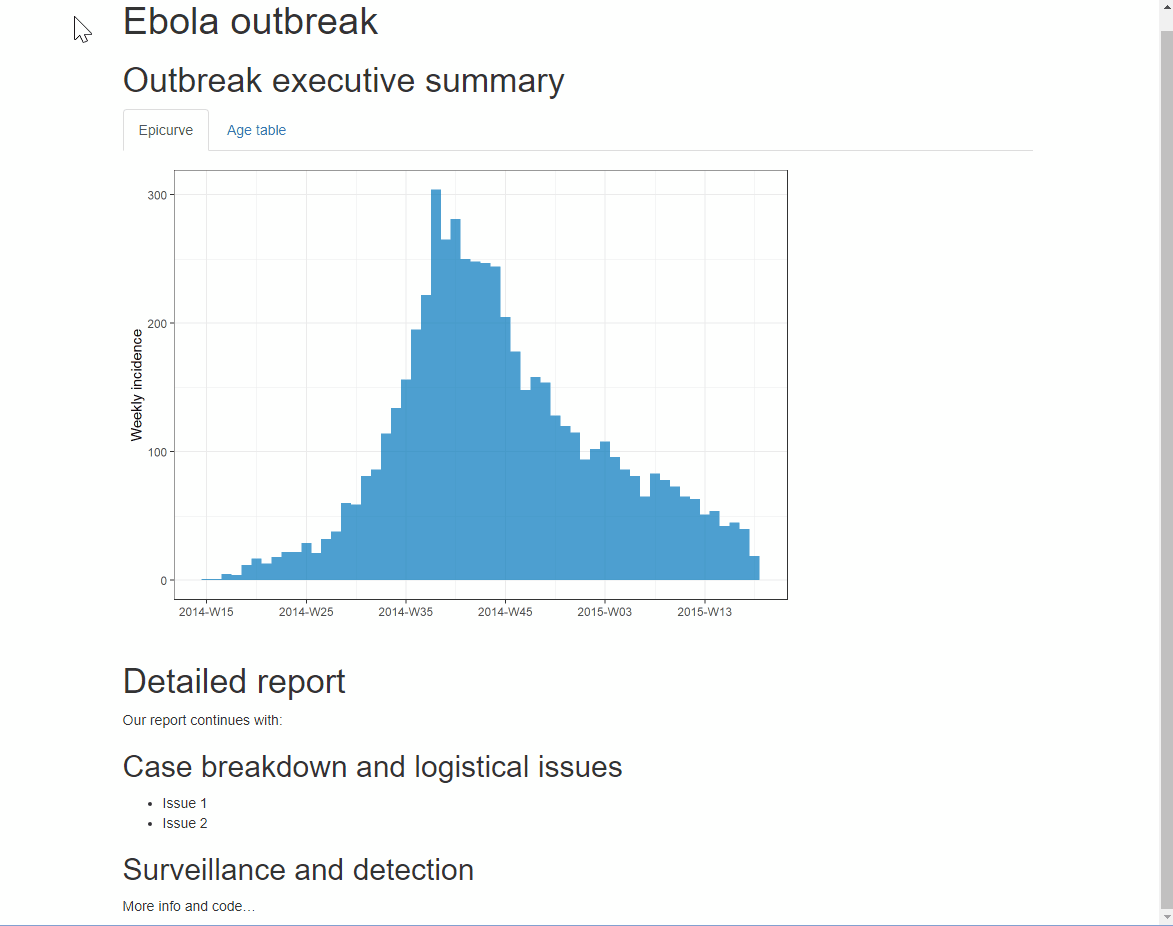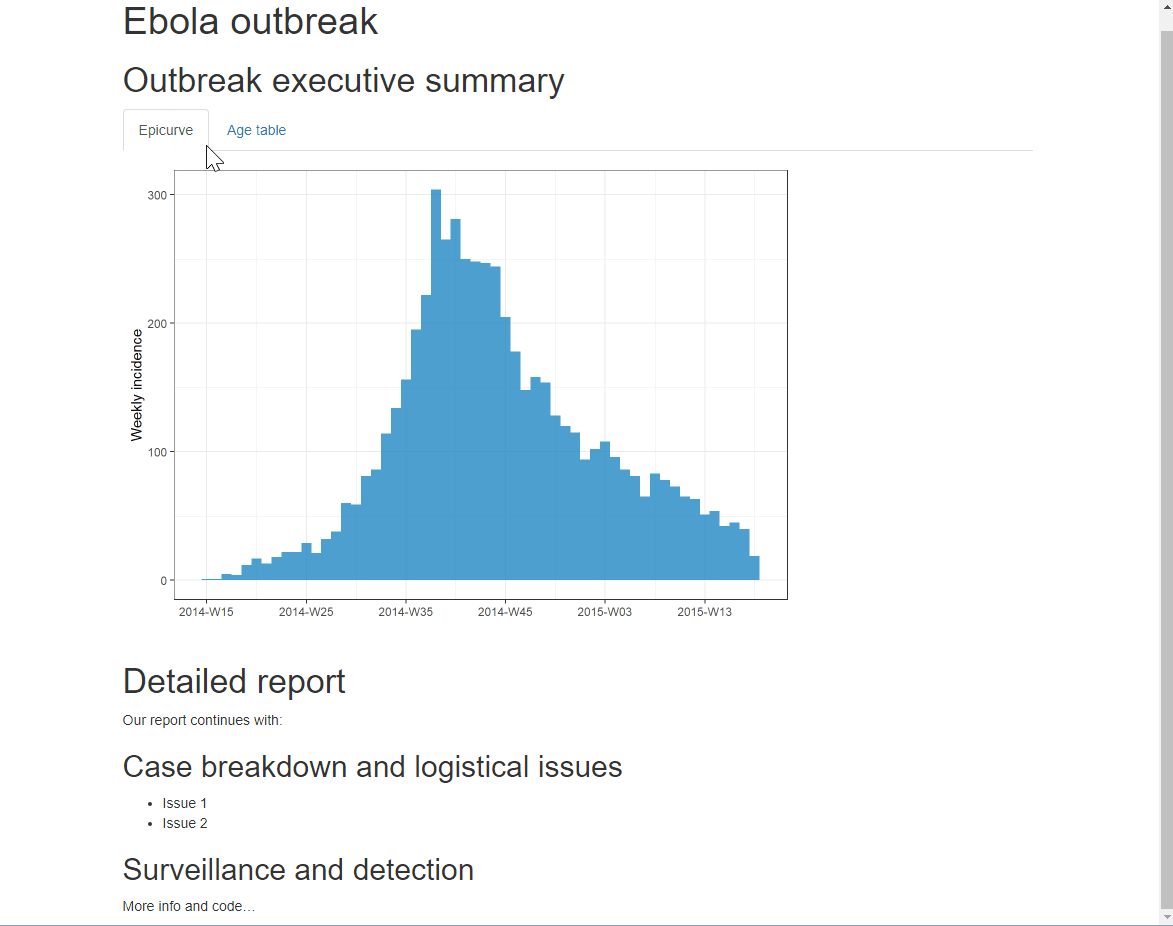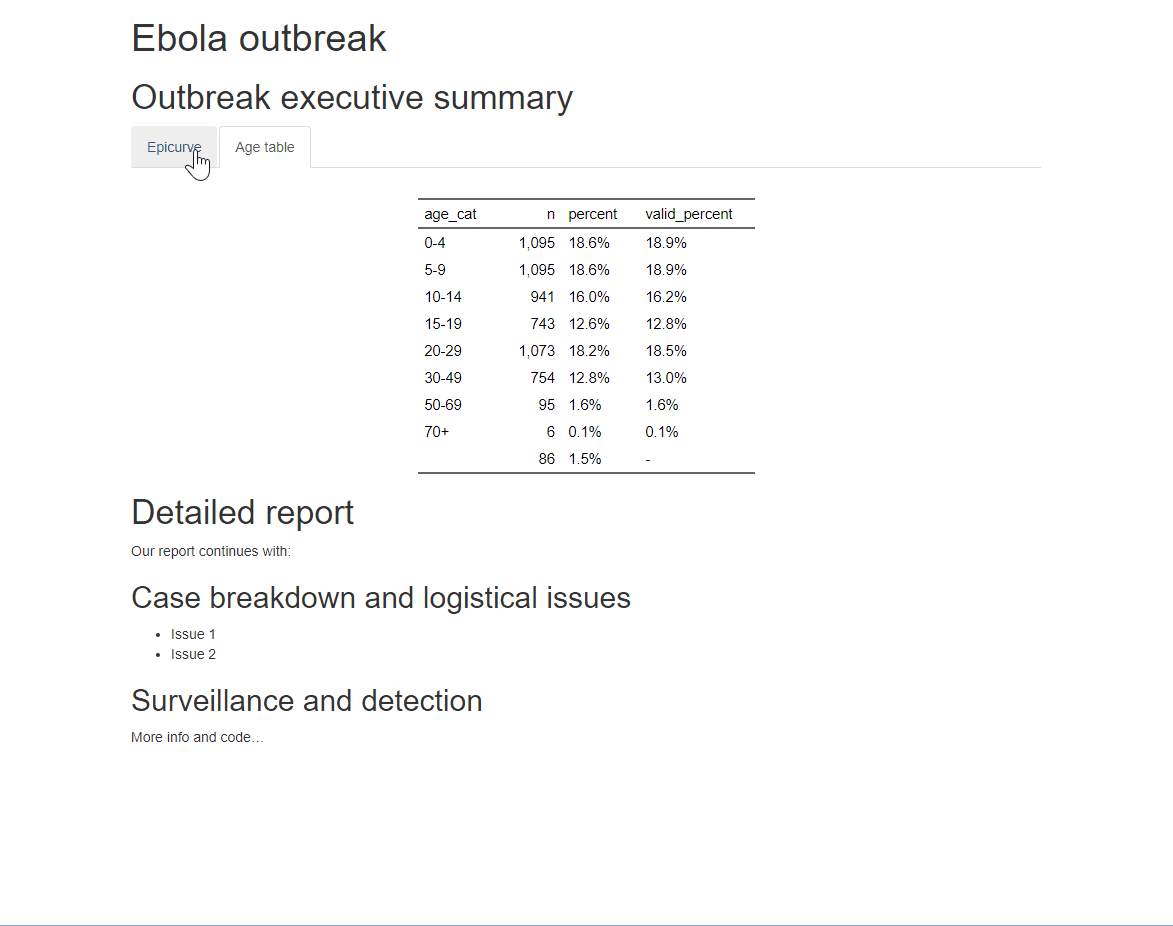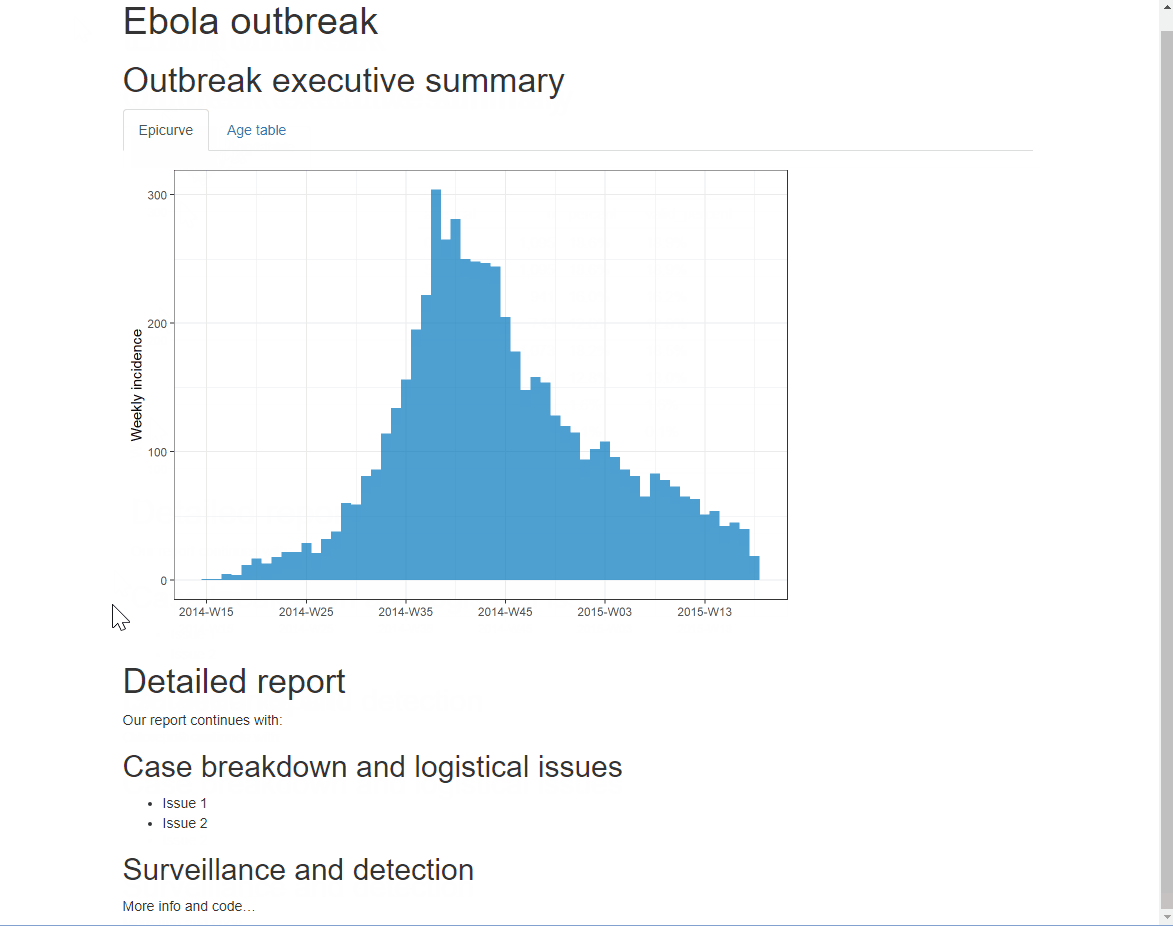
Puedes añadir una opción adicional .tabset-pills después de .tabset para dar a las pestañas una apariencia “en forma de píldora”. Ten en cuenta que al ver la salida HTML con etiquetas, la funcionalidad de búsqueda Ctrl+f sólo buscará en las etiquetas “activas”, no en las ocultas.
40.4 Estructura de los archivos
Hay varias maneras de estructurar el archivo de R Markdown y sus scripts de R asociados. Cada una tiene sus ventajas y desventajas:
- R Markdown autónomo - todo lo necesario para el informe se importa o se crea dentro del R Markdown
- Ubicar otros archivos - Podés ejecutar scripts R externos con el comando
source()y utilizar sus salidas en el Rmd - Scripts hijos - un mecanismo alternativo para
source()
- Ubicar otros archivos - Podés ejecutar scripts R externos con el comando
- Utilizar un “archivo de ejecución” - Ejecutar comandos en un script R antes de renderizar el R Markdown
Rmd autónomo
Para un informe relativamente sencillo, puedes optar por organizar tu script de R Markdown de manera que sea “autosuficiente” y no implique utilizar ningún script externo.
Todo lo que se necesite para ejecutar el R Markdown se importa o se crea dentro del archivo Rmd, incluyendo todos los trozos de código y la carga de paquetes. Este enfoque “autosuficiente” es apropiado cuando no necesitás hacer mucho procesamiento de datos (por ejemplo, cuando se importa un archivo de datos limpio o semilimpio) y el procesamiento del R Markdown no tomará demasiado tiempo.
En este escenario, una organización lógica del script de R Markdown podría ser:
- Establecer las opciones globales de knitr
- Cargar paquetes
- Importar los datos
- Procesar los datos
- Generar resultados (tablas, gráficos, etc.)
- Guardar los resultados, si es el caso (.csv, .png, etc.)
Obtener otros archivos
Una variación del enfoque “autocontenido” es hacer que los trozos de código R Markdown busquen (ejecuten) scripts de R externos. Esto puede hacer que tu script de R Markdown sea menos desordenado, más simple y más fácil de organizar. También puede ayudar si quieres mostrar las cifras finales al principio del informe. En este enfoque, el script de R Markdown final simplemente combina las salidas preprocesadas en un documento.
Una forma de hacerlo es proporcionando los scripts de R (ruta del archivo y nombre con extensión) al comando source() R base.
source("your-script.R", local = knitr::knit_global())
# o sys.source("your-script.R", envir = knitr::knit_global())Tené en cuenta que cuando utilizás source() dentro de R Markdown, los archivos externos se ejecutarán durante el curso del procesamiento de tu archivo Rmd. Por lo tanto, cada script se ejecuta cada vez que se procesa el informe. Por lo tanto, utilizar comandos source() dentro del R Markdown no acelera el tiempo de ejecución, ni ayuda mucho a la depuración, ya que el error producido todavía se imprimirá al producir el R Markdown.
Una alternativa es utilizar la opción child = knitr. #EXPLICAR MÁS PARA HACER
Debes ser consciente de los distintos entornos de R. Los objetos creados dentro de un entorno no estarán necesariamente disponibles para el entorno utilizado por R Markdown.
Ejecutar archivo
Este enfoque implica utilizar el script de R que contiene el comando(s) render() para preprocesar los objetos que se introducen en el R markdown.
Por ejemplo, podés cargar los paquetes, cargar y limpiar los datos, e incluso crear los gráficos de interés antes de ejecutarrender(). Estos pasos pueden ocurrir en el script de R, o en otros scripts que se convocan. Siempre y cuando estos comandos ocurran en la misma sesión de RStudio y los objetos se guarden en el entorno, los objetos pueden ser convocados dentro del contenido de Rmd. Entonces R markdown sólo se utilizará para el paso final, es decir, para producir la salida con todos los objetos pre-procesados. Esto es mucho más fácil de depurar si se genera algún error.
Este enfoque es útil por las siguientes razones:
- Mensajes de error más informativos - estos mensajes serán generados por el script de R, no por el R Markdown. Los errores de R Markdown tienden a informar qué trozo tuvo un problema, pero no te dirán qué línea.
- Si ejecutás muchos pasos de procesamiento antes de usar el comando
render()- se ejecutarán sólo una vez.
En el ejemplo siguiente, tenemos un script de R en el que preprocesamos el objeto data en el entorno de R y luego procesamos “create_output.Rmd” usando render().
data <- import("datafile.csv") %>% # Cargar datos y guardarlos en el entorno
select(age, hospital, weight) # Seleccionar columnas
rmarkdown::render(input = "create_output.Rmd") # Crear archivo Rmd Estructura de carpetas
El flujo de trabajo también se refiere a la estructura general de las carpetas, como tener una carpeta de ‘salida’ para los documentos y figuras creados, y carpetas de ‘datos’ o ‘entradas’ para los datos depurados. No entramos en más detalles aquí, pero echa un vistazo a la página de organización de informes rutinarios.
40.5 Producir el documento
Puedes generar el documento de las siguientes maneras:
- Manualmente haciendo click sobre el botón “Knit” en la parte superior del editor de scripts de RStudio (rápido y fácil)
- Ejecutando el comando
render()(ejecutado fuera del script de R Markdown)
Opción 1: botón “Knit”
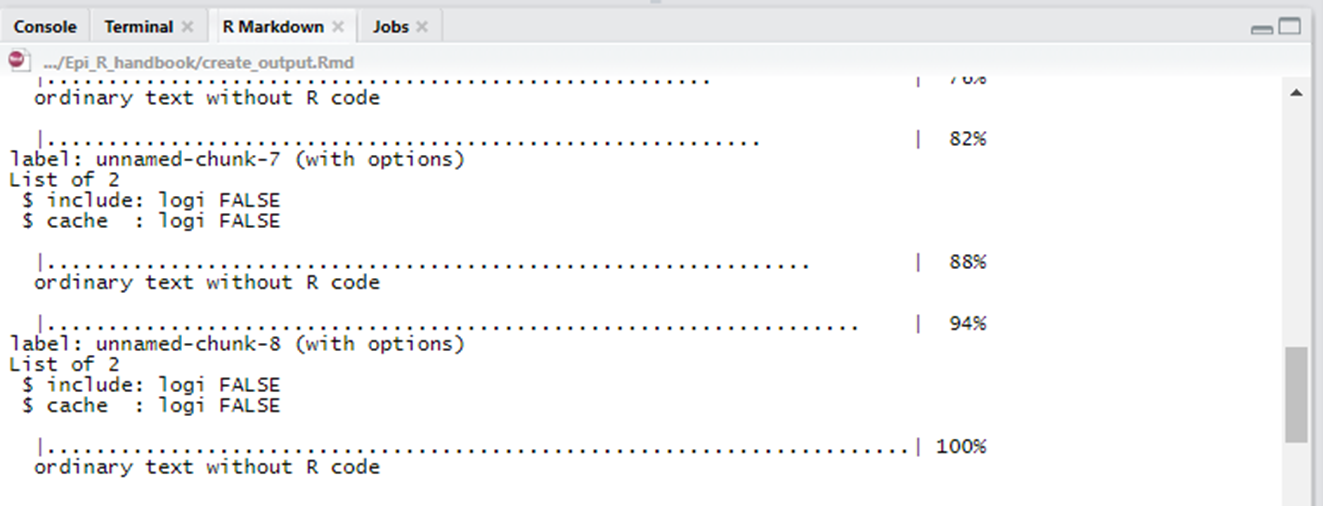
Cuando tengas el archivo Rmd abierto, cliqueá el botón ‘Knit’ en la parte superior del archivo.
R Studio te mostrará el progreso dentro de una pestaña ‘R Markdown’ cerca de la consola R. El documento se abrirá automáticamente cuando esté completo.
El documento se guardará en la misma carpeta que tu script de R markdown, y con el mismo nombre de archivo (excepto la extensión). Obviamente, esto no es ideal para el control de versiones (se sobreescribirá cada vez que se haga un knit, a menos que se mueva manualmente), ya que entonces puede que tengas que renombrar el archivo (por ejemplo, añadir una fecha).
Este es el botón de acceso directo de RStudio para la función render() de rmarkdown. Este enfoque sólo es compatible con un R markdown autocontenido, donde todos los componentes necesarios existen o se convocan dentro del archivo.
Opción 2: comando render()
Otra forma de producir el documento de salida de R Markdown es ejecutar la función render() (del paquete rmarkdown). Debés ejecutar este comando fuera del script de R Markdown, ya sea en un script de R separado (a menudo llamado “archivo de ejecución”), o como un comando independiente en la consola de R.
rmarkdown::render(input = "my_report.Rmd")Al igual que con “knit”, la configuración predeterminada guardará la salida Rmd en la misma carpeta que el script Rmd, con el mismo nombre de archivo (excepto la extensión del archivo). Por ejemplo, “mi_informe.Rmd” cuando se procese creará “mi_informe.docx” si se procesa a un documento de Word. Sin embargo, al usar render() existe la opción de usar diferentes configuraciones. render() puede aceptar argumentos que incluyen:
output_format =Este es el formato del documento salida al que se va a convertir (por ejemplo,"html_document","pdf_document","word_document", o"all"). Esto también se puede especificar en el YAML dentro del script de R Markdown.output_file =Este es el nombre del archivo de salida (y la ruta del archivo). Se puede crear a través de funciones de R comohere()ostr_glue()como se demuestra a continuación.output_dir =Este es un directorio de salida (carpeta) para guardar el archivo. Esto te permite elegir un directorio distinto en el que se guarda el archivo Rmd.output_options =Podés proporcionar una lista de opciones que anulen las del YAML del scriptoutput_yaml =Podés proporcionar la ruta a un archivo .yml que contenga las especificaciones YAMLparams =Ver la sección de parámetros más abajo- Ver la lista completa aquí
Como ejemplo, para mejorar el control de versiones, el siguiente comando guardará el archivo de salida dentro de una subcarpeta ‘outputs’, con la fecha actual en el nombre del archivo. Para crear el nombre del archivo, se utiliza la función str_glue() del paquete stringr para “pegar” las cadenas estáticas (escritas sin formato) con el código dinámico de R (escrito entre corchetes). Por ejemplo, si es 10 de abril de 2021, el nombre del archivo será “Informe_2021-04-10.docx”. Consultá la página sobre Caracteres y cadenas para obtener más detalles sobre str_glue().
rmarkdown::render(
input = "create_output.Rmd",
output_file = stringr::str_glue("outputs/Report_{Sys.Date()}.docx")) A medida que el archivo se procesa, la consola de RStudio mostrará el progreso hasta el 100%, y un mensaje final para indicar que la renderización se ha completado.
Opción 3: paquete reportfactory
El paquete de R reportfactory ofrece un método alternativo de organización y compilación de informes R Markdown para situaciones en las que se ejecutan informes de forma rutinaria (por ejemplo, diariamente, semanalmente…). Facilita la compilación de múltiples archivos R Markdown y la organización de sus resultados. En esencia, proporciona una “fábrica” desde la que se pueden ejecutar los informes R Markdown, obtener automáticamente carpetas con fecha y hora para los resultados, y tener un control de versiones “ligero”.
Leé más sobre este flujo de trabajo en la página sobre la organización de informes rutinarios.
40.6 Informes parametrizados
Podés utilizar la parametrización para generar informes dinámicos, de forma que pueda ejecutarse con una configuración específica (por ejemplo, una fecha o lugar concretos o con determinadas opciones de procesamiento). A continuación, nos centramos en los aspectos básicos, pero hay más detalles en línea sobre los informes parametrizados.
Utilizando el listado de casos de Ébola como ejemplo, digamos que queremos ejecutar un informe de diario vigilancia estándar para cada hospital. Mostramos cómo se puede hacer esto usando parámetros.
Importante: los informes dinámicos también son posibles sin la estructura formal de parámetros (sin params:), utilizando simples objetos R en un script adyacente. Esto se explica al final de esta sección.
Establecer parámetros
Existen varias opciones para especificar los valores de los parámetros para tu documento de salida de R Markdown.
Opción 1: Establecer parámetros dentro de YAML
Editá el YAML para incluir una opción params:, con declaraciones indentadas para cada parámetro a definir. En este ejemplo creamos los parámetros date y hospital, y especificamos sus valores. Estos valores están sujetos a cambios cada vez que se ejecuta el informe. Si utilizás el botón “Knit” para producir la salida, los parámetros estarán predeterminados por estos valores. Del mismo modo, si utilizás render() los parámetros tendrán estos valores por defecto a menos que se especifiquen de otra manera en el comando render().
---
title: Informe de vigilancia
output: html_document
params:
date: 2021-04-10
hospital: Hospital Central
---En un segundo plano, los valores de los parámetros están contenidos en una lista de sólo lectura llamada params. Así, puedes insertar los valores de los parámetros en el código de R como lo harías con otro objeto/valor de R en tu entorno. Simplemente escriba params$ seguido del nombre del parámetro. Por ejemplo params$hospital para representar el nombre del hospital (“Hospital Central” por defecto).
Tené en cuenta que los parámetros también pueden tener valores true o false, y por lo tanto estos pueden ser incluidos en sus opciones de knitr dentro de un chunk de R. Por ejemplo, puedes establecer {r, eval=params$run} en lugar de {r, eval=FALSE}, y ahora si el chunk se ejecuta o no depende del valor de un parámetro run:.
Los parámetros que son fechas, serán introducidos como una cadena. Por lo tanto, para que params$date se interprete en el código de R, es probable que tenga que ser envuelto con as.Date() o una función similar para convertir al tipo Date.
Opción 2: Establecer los parámetros dentro de render()
Como se ha mencionado anteriormente, como alternativa a cliquear el botón “Knit” para producir la salida es ejecutar la función render() desde un script independiente. En este último caso, se pueden especificar los parámetros a utilizar con el argumento params = de render().
Hay que tener en cuenta que los valores de los parámetros asignados aquí sobrescribirán sus valores predeterminados si aparacen el YAML. Escribimos los valores entre comillas ya que en este caso deben ser definidos como valores de carácter/cadena.
El siguiente comando genera “surveillance_report.Rmd”, especifica un nombre dinámico para el archivo de salida y una carpeta, y proporciona un list() de dos parámetros y sus valores al argumento params =.
rmarkdown::render(
input = "surveillance_report.Rmd",
output_file = stringr::str_glue("outputs/Report_{Sys.Date()}.docx"),
params = list(date = "2021-04-10", hospital = "Central Hospital"))Opción 3: Establecer los parámetros mediante una interfaz gráfica de usuario
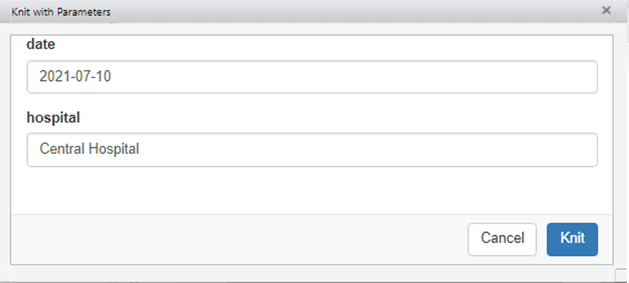
Para obtener una experiencia más interactiva, se puede utilizar la interfaz gráfica de usuario (GUI, por sus siglas en ingles) para seleccionar manualmente los valores de los parámetros. Para ello, podemos clicar en el menú desplegable situado junto al botón ‘Knit’ y elegir ‘Knit with parameters’.
Aparecerá una ventana que te permitirá introducir los valores de los parámetros establecidos en el YAML del documento.
Se puede lograr lo mismo a través del comando render() especificando params = "ask", como se demuestra a continuación.
rmarkdown::render(
input = "surveillance_report.Rmd",
output_file = stringr::str_glue("outputs/Report_{Sys.Date()}.docx"),
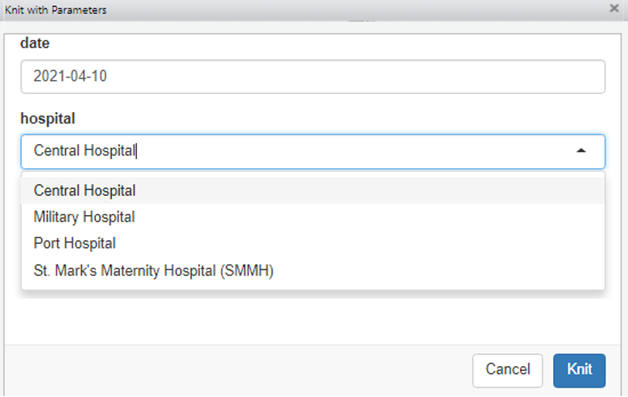
params = “ask”)Sin embargo, la asignación de valores en esta ventana emergente está sujeta a errores y faltas de ortografía. Es posible añadir restricciones a los valores que se pueden introducir a través de los menús desplegables. Podés hacerlo añadiendo en el YAML especificaciones para cada entrada params:.
label:es el título para ese menú desplegable en particularvalue:es el valor predeterminado (inicial)input:establecerselectpara utilizar un menú desplegable
choices:Indique los valores opcionales en el menú desplegable
A continuación, estas especificaciones están escritas para el parámetro hospital
---
title: Surveillance report
output: html_document
params:
date: 2021-04-10
hospital:
label: “Town:”
value: Central Hospital
input: select
choices: [Central Hospital, Military Hospital, Port Hospital, St. Mark's Maternity Hospital (SMMH)]
---Al procesarlo (con el botón ‘knit with parameters’ o con render(), la ventana emergente tendrá opciones desplegables para seleccionarlos.
Ejemplo parametrizado
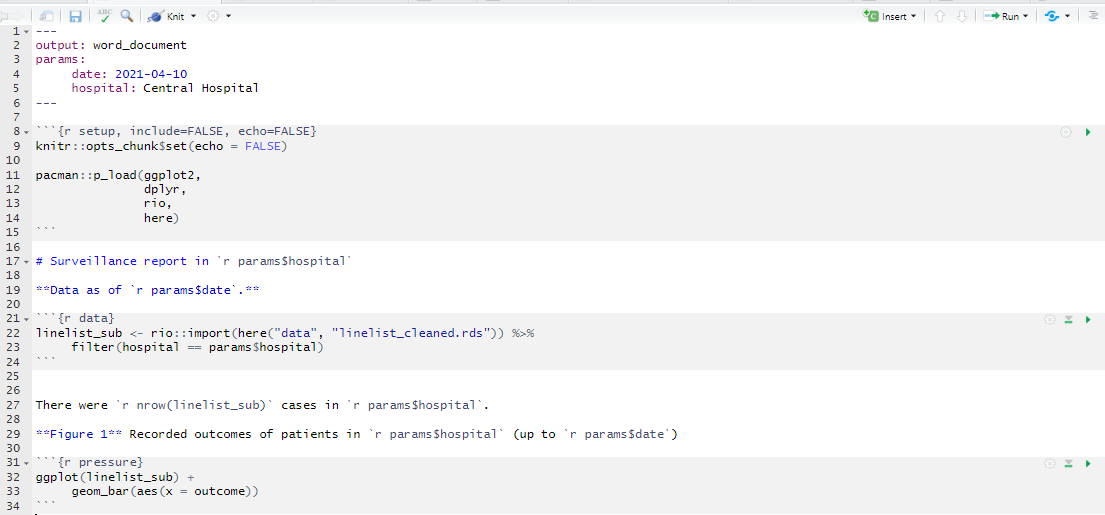
El siguiente código crea parámetros para date y hospital, que se utilizan en el R Markdown como params$date y params$hospital, respectivamente.
En la salida del informe resultante, los datos se filtran al hospital específico, y el título del gráfico se refiere al hospital y a la fecha correctos. En este caso utilizamos el archivo “linelist_cleaned.rds”, pero sería especialmente adecuado que la propia lista de casos tuviera también un sello de fecha para alinearse con la fecha parametrizada.
Si se procesa esto se obtiene la salida final con la fuente y el diseño predeterminados.
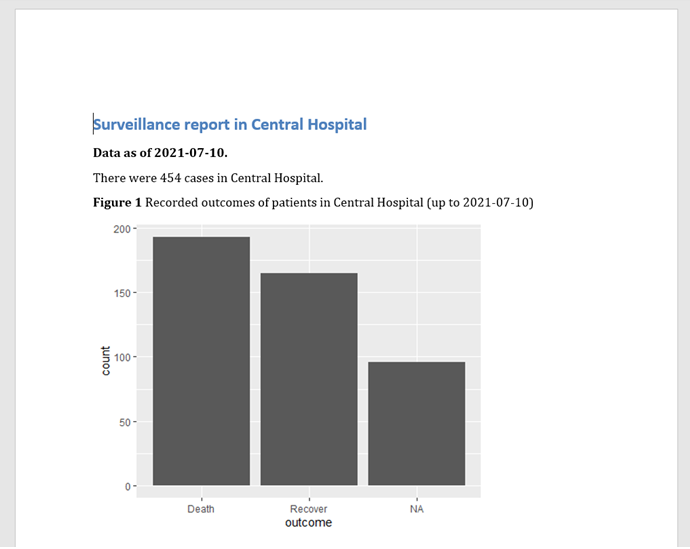
Parametrización sin parámetros
Si estás procesando un archivo R Markdown con render() desde un script independiente, puede crear el mismo efecto de parametrización sin usar la funcionalidad params:.
Por ejemplo, en el script de R que contiene el comando render(), podés simplemente definir hospital y date como dos objetos R (valores) antes del comando render(). En el R Markdown, no sería necesario tener una sección params: en el YAML, y nos referiríamos al objeto date en lugar de params$date y a hospital en lugar de params$hospital.
# Este es un script de R separado de R Markdown
# define objetos de R
hospital <- "Central Hospital"
date <- "2021-04-10"
# Renderiza (procesa) el R markdown
rmarkdown::render(input = "create_output.Rmd") Este enfoque significa que no se puede procesar con “knit with parameters”, ni utilizar la interfaz gráfica, ni incluir opciones de procesamiento dentro de los parámetros. Sin embargo, permite simplificar el código, lo cual puede resultar ventajoso.
40.7 Informes en bucle
Es posible que queramos ejecutar un informe varias veces, variando los parámetros de entrada, para producir un informe para cada jurisdicción/unidad. Esto puede hacerse utilizando herramientas para la iteración, que se explican en detalle en la página sobre Iteración, bucles y listas. Las opciones incluyen el paquete purrr, o el uso de un for loop como se explica a continuación.
A continuación, utilizamos un simple for loop para generar un informe de vigilancia para todos los hospitales de interés. Esto se hace con un solo comando (en lugar de cambiar manualmente el parámetro del hospital uno por uno). El comando para generar los informes debe existir en un script separado fuera del informe Rmd. Este script también contendrá objetos definidos para “hacer un bucle” - la fecha de hoy, y un vector de nombres de hospitales para hacer un bucle.
hospitals <- c("Central Hospital",
"Military Hospital",
"Port Hospital",
"St. Mark's Maternity Hospital (SMMH)") A continuación, introducimos estos valores uno a uno en el comando render() mediante un bucle, que ejecuta el comando una vez por cada valor del vector hospitales. La letra “i” representa la posición del índice (del 1 al 4) del hospital que se está utilizando en esa iteración, de modo que “lista_de_hospitales[1]sería "Hospital Central". Esta información se suministra en dos lugares en el comandorender()`:
- Al nombre del archivo, de forma que el nombre del archivo de la primera iteración, si se produce el 10 de abril de 2021, sería “Informe_Hospital Central_2021-04-10.docx”, guardado en la subcarpeta ‘output’ del directorio de trabajo.
- A
params =de forma que el Rmd utilice el nombre del hospital internamente siempre que se llame al valorparams$hospital(por ejemplo, para filtrar los datos sólo a un hospital determinado). En este ejemplo, se crearían cuatro archivos, uno por cada hospital.
for(i in 1:length(hospitals)){
rmarkdown::render(
input = "surveillance_report.Rmd",
output_file = str_glue("output/Report_{hospitals[i]}_{Sys.Date()}.docx"),
params = list(hospital = hospitals[i]))
} 40.8 Plantillas
Utilizando un documento de plantilla que contenga cualquier formato deseado, podés ajustar la estética del archivo de salida Rmd. Podés crear, por ejemplo, un archivo de MS Word o Powerpoint que contenga páginas/diapositivas con las dimensiones, marcas de agua, fondos y fuentes deseadas.
Documentos en Word
Para crear una plantilla, iniciá un nuevo documento de Word (o utiliza uno ya existente con el formato deseado), y editá las fuentes definiendo los Estilos. En el Estilo, los encabezados 1, 2 y 3 se refieren a los distintos niveles de encabezado de markdown (# Header 1, ## Header 2 and ### Header 3, respectivamente). Cliqueá con el botón derecho en el estilo y selectioná ‘modificar’ para cambiar el formato de la fuente, así como el párrafo (por ejemplo, podés introducir saltos de página antes de ciertos estilos que pueden ayudar con el espaciado). Otros aspectos del documento de Word, como los márgenes, el tamaño de la página, los encabezados, etc., pueden modificarse como un documento de Word normal en el que se trabaja directamente.
Documentos en Powerpoint
Como en el caso anterior, creá un nuevo conjunto de diapositivas o utiliza un archivo PowerPoint existente con el formato deseado. Para seguir editando, cliqueá en “Ver” y “Patrón de diapositivas”. Desde aquí se puede cambiar la apariencia de la diapositiva “maestra” editando el formato del texto en los cuadros de texto, así como el fondo y las dimensiones del página.
Desgraciadamente, la edición de archivos PowerPoint es un poco menos flexible:
- Un encabezado de primer nivel (
# Header 1) se convertirá automáticamente en el título de una nueva diapositiva, - El texto del
# Header 2no aparecerá como subtítulo, sino como texto dentro del cuadro de texto principal de la diapositiva (a menos que encuentre una manera de manipular la vista del Patrón). - Los gráficos y las tablas resultantes irán automáticamente a nuevas diapositivas. Tendrás que combinarlos, por ejemplo con la función patchwork para combinar ggplots, para que aparezcan en la misma página. Esta entrada del blog trata el uso del paquete patchwork para colocar múltiples imágenes en una diapositiva.
En el paquete oficcer encontrarás una herramienta para trabajar más a fondo con las presentaciones de PowerPoint.
Integración de plantillas en el YAML
Una vez preparada la plantilla, el detalle de la misma puede añadirse en el YAML del Rmd debajo de la línea ‘output’ y debajo de donde se especifica el tipo de documento (que va a una línea aparte). Para las plantillas de diapositivas de PowerPoint se puede utilizar reference_doc.
Lo más fácil es guardar la plantilla en la misma carpeta en la que está el archivo Rmd (como en el ejemplo siguiente), o en una subcarpeta dentro de ella.
---
title: Surveillance report
output:
word_document:
reference_docx: "template.docx"
params:
date: 2021-04-10
hospital: Central Hospital
template:
---Formateo de archivos HTML
Los archivos HTML no utilizan plantillas, pero pueden tener los estilos configurados dentro del YAML. Los HTML son documentos interactivos y particularmente flexibles. Aquí cubrimos algunas opciones básicas.
Tabla de contenidos: Podemos añadir una tabla de contenidos con
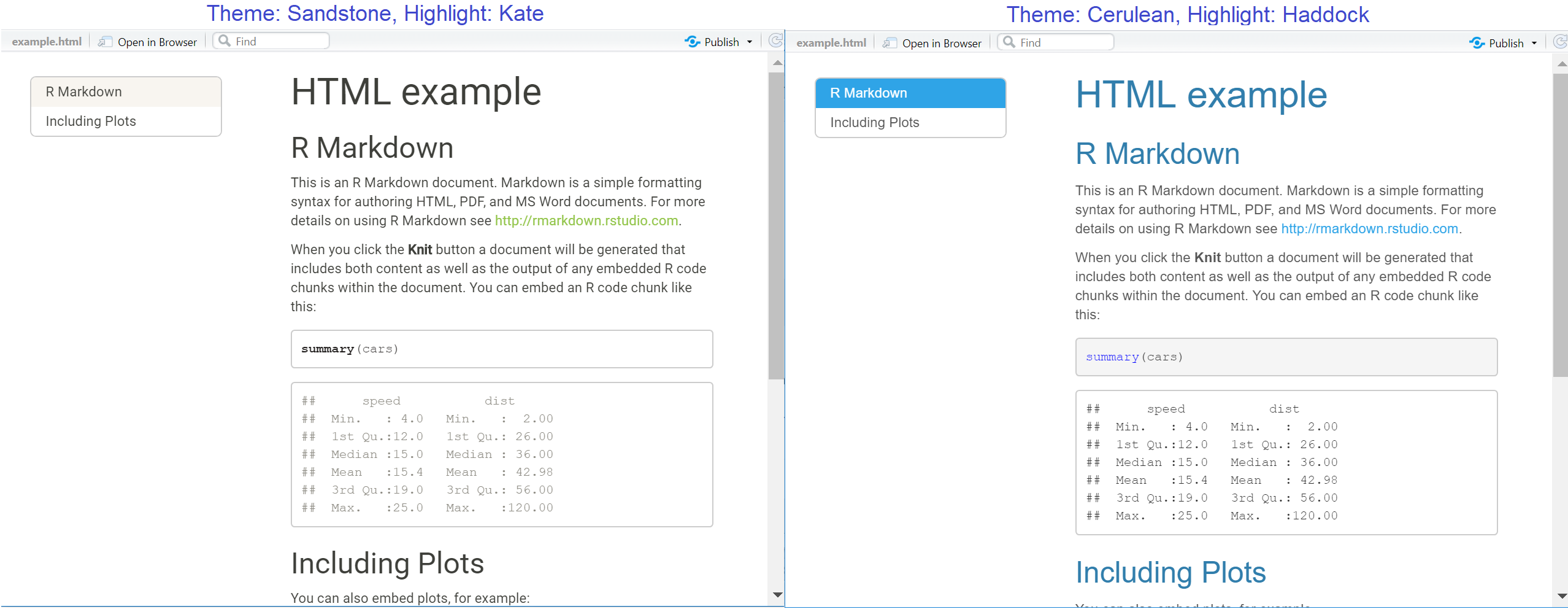
toc: true, y también especificar que permanezca visible (“flotante”) al desplazarse, contoc_float: true.Temas: Nos referimos a algunos temas prearmados, que provienen de una biblioteca de temas de Bootswatch. En el siguiente ejemplo utilizamos cerulean. Otras opciones son: journal, flatly, darkly, readable, spacelab, united, cosmo, lumen, paper, sandstone, simplex y yeti.
Resaltar: Configurando esto se cambia el aspecto del texto resaltado (por ejemplo, el código dentro de los trozos que se muestran). Los estilos disponibles son default, tango, pygments, kate, monochrome, espresso, zenburn, haddock, breezedark y textmate.
He aquí un ejemplo de cómo integrar las opciones anteriores en el YAML.
---
title: "HTML example"
output:
html_document:
toc: true
toc_float: true
theme: cerulean
highlight: kate
---A continuación se muestran dos ejemplos de salidas HTML ambas con tablas de contenido flotantes pero con diferentes estilos de tema y resaltado seleccionados:
40.9 Contenido dinámico
En una salida HTML, el contenido de tu informe puede ser dinámico. A continuación, veremos algunos ejemplos:
Tablas
En un informe HTML, se puede imprimir un dataframe / tibble de manera que el contenido sea dinámico, con filtros y barras de desplazamiento. Hay varios paquetes que ofrecen esta capacidad.
Para hacer esto con el paquete DT, como se utiliza en este manual, se puede insertar un trozo de código como este:

La función datatable() imprimirá el dataframe proporcionado como una tabla dinámica para el lector. Puedes establecer rownames = FALSE para simplificar el extremo izquierdo de la tabla. filter = "top" proporciona un filtro sobre cada columna. En el argumento options() proporciona una lista de otras especificaciones. A continuación incluimos dos: pageLength = 5 determina que el número de filas a mostrar sea 5 (las filas restantes se pueden ver paginando a través de flechas), y scrollX=TRUE habilita una barra de desplazamiento en la parte inferior de la tabla (para visualizar las columnas que se extienden a la extrema derecha).
Si tu conjunto de datos es muy grande, considerá mostrar sólo las filas superiores envolviendo los datos en head().
Widgets HTML
Los widgets HTML para R son un tipo especial de paquetes de R que permiten una mayor interactividad utilizando bibliotecas de JavaScript. Puedes incorporarlos en salidas HTML R Markdown.
Algunos ejemplos comunes de estos widgets son:
- Plotly (utilizado en la página de este manual y en la página de Gráficos interactivos
- visNetwork (utilizado en la página de Cadenas de transmisión de este manual)
- Leaflet (Folleto) (utilizado en la página Conceptos básicos de los SIG de este manual)
- dygraphs (útil para mostrar interactivamente los datos de las series temporales)
- DT (
datatable()) (se utiliza para mostrar tablas dinámicas con filtro, ordenación, etc.)
La función ggplotly() de plotly es particularmente fácil de usar. Consúltalo en la sección en la página de Gráficos interactivos.
40.10 Recursos
Podés encontrar más información en:
- https://bookdown.org/yihui/rmarkdown/
- https://rmarkdown.rstudio.com/articles_intro.html
Aquí encontras una buena explicación de markdown vs knitr vs Rmarkdown: https://stackoverflow.com/questions/40563479/relationship-between-r-markdown-knitr-pandoc-and-bookdown