22 Médias móveis
Nesta página, dois métodos para calcular e visualizar médias móveis serão abordados:
- Calcule com o pacote slider
- Calcule com um comando dentro da função
ggplot(), utilizando o pacote tidyquant
22.1 Preparação
Carregue os pacotes
O código abaixo realiza o carregamento dos pacotes necessários para a análise dos dados. Neste manual, enfatizamos o uso da função p_load(), do pacman, que instala os pacotes, caso não estejam instalados, e os carrega no R para utilização. Também é possível carregar pacotes instalados utilizando a função library(), do R base. Para mais informações sobre os pacotes do R, veja a página Introdução ao R.
pacman::p_load(
tidyverse, # para gerenciamento e visualização dos dados
slider, # para calcular médias móveis
tidyquant # para calcular médias móveis dentro do ggplot
)Importe os dados para R
Nós iremos importar o banco de dados de casos de uma simulação de epidemia de Ebola. Se você quiser acompanhar os passos abaixo, clique aqui para fazer o download do banco de dados ‘limpo’ (como arquivo .rds). Importe seus dados utilizando a função import() do pacote rio (esta função importa muitos tipos de arquivos, como .xlsx, .rds, .csv - veja a página Importar e exportar para detalhes).
# importe o *linelist*
linelist <- import("linelist_cleaned.xlsx")As primeiras 50 linhas do banco de dados são mostradas abaixo.
22.2 Calculando com o pacote slider
Utilize esta abordagem para calcular uma média móvel em um conjunto de dados antes de traçar o gráfico.
O pacote slider fornece diferentes funções que utilizam a abordagem de “janelas deslizantes” (do inglês, sliding window) para calcular médias móveis, somas cumulativas, regressões móveis, etc. Este pacote trata o conjunto de dados como um vetor de linhas, permitindo a iteração entre as linhas do conjunto de dados.
Aqui estão algumas das funções mais comuns:
-
slide_dbl()- realiza a iteração de uma coluna numérica (logo “_dbl”) enquanto executa uma operação usando o protocolo das janelas deslizantes-
slide_sum()- função atalho para realizar a soma móvel para a funçãoslide_dbl()
-
slide_mean()- função atalho para realizar a média móvel para a funçãoslide_dbl()
-
-
slide_index_dbl()- aplica as janelas deslizantes em uma coluna numérica, utilizando uma coluna separada para indexar a progressão das janelas (útil se a progressão estiver sendo por datas e algumas estiverem ausentes)-
slide_index_sum()- função atalho para realizar a soma móvel usando indexador
-
slide_index_mean()- função atalho para realizar a média móvel usando indexador
-
O pacote slider possui muitas outras funções que são cobertas na seção sobre Recursos extras desta página. Aqui, nós abordamos brevemente as funções mais comuns.
Argumentos essenciais
.x, por padrão, o primeiro argumento é o vetor sobre o qual serão realizadas as iterarações e sobre o qual será aplicada a função.i =para as versões “index” das funções do pacote slider - indique a coluna para “indexar” o “delizamento” (veja a seção abaixo)-
.f =, por padrão, o segundo argumento é:- Uma função, escrita sem parênteses, como
mean, ou
- Uma fórmula, que será convertida em uma função. Por exemplo,
~ .x - mean(.x)irá gerar o resultado do valor corrente menos a média do valor da janela
- Uma função, escrita sem parênteses, como
Para mais detalhes, veja esse material de referência
Tamanho da janela
Especifique a extensão da janela ao usar .before, .after, ou ambos argumentos:
-
.before =- Forneça um número inteiro
-
.after =- Forneça um número inteiro
-
.complete =- Ajuste isso paraTRUEse você apenas quiser realizar os cálculos em janelas completas
Por exemplo, para atingir uma janela de 7 dias incluindo o valor corrente e os seis anteriores, utilize .before = 6. Para obter uma janela “central”, forneça o mesmo número tanto para .before = quanto para .after =.
Por padrão, .complete = será FALSE. Então, se a janela inteira de linhas não existir, as funções irão utilizar linhas disponíveis para executar os cálculos. Alterar para TRUE restringue isso, de forma que os cálculos serão realizados apenas em janelas completas.
Janelas em expansão
Para obter operações cumulativas, ajuste o argumento .before = para Inf. Isto irá realizar a operação no valor corrente e em todos os valores anteriores.
Deslizando por data
A aplicação mais provável de cálculos móveis em epidemiologia aplicada é para examinar um indicador ao longo do tempo. Por exemplo, uma medida móvel da incidência de casos, baseado na contagem diária dos casos.
Se você possuir dados com séries cronológicas limpas, com valores para cada data, você pode estar OK para utilizar a função slide_dbl(), como demonstrado aqui na página sobre Séries temporais e detecção de surtos.
Entretanto, em muitas situações da epidemiologia aplicada, você pode não ter algumas datas nos seus dados, em que os eventos não foram registrados. Nestes casos, é melhor utilizar as versões “index” das funções do slider.
Dados indexados
Abaixo, nós mostramos um exemplo utilizando a função slide_index_dbl() no objeto linelist criado acima. Digamos que nosso objetivo é calcular uma incidência móvel de 7 dias - a soma dos casos utilizando uma janela de 7 dias. Se você estiver procurando por um exemplo de média móvel, veja a seção abaixo sobre deslocamento agrupado.
Para iniciar, o conjunto de dados daily_counts é criado para refletir a contagem diária de casos do linelist, sendo calculado com a função count() do dplyr.
# crie um conjunto de dados das contagens diárias
daily_counts <- linelist %>%
count(date_hospitalisation, name = "new_cases")Aqui estão os dados do daily_counts - existem nrow(daily_counts) linhas, onde cada dia é representado por uma linha mas, especialmente no início da epidemia, alguns dias não estão presentes (não existem casos admitidos nestes dias).
É crucial reconhecer que uma função móvel padrão (como slide_dbl()) iria utilizar uma janela de 7 linhas, não de 7 dias. Logo, se existirem datas ausentes, algumas janelas irão abrangir mais do que 7 dias de um calendário!
Uma janela móvel “inteligente” pode ser obtida com a função slide_index_dbl(). O “index” significa que a função utiliza uma coluna separada como “indexador” para a janela deslizante. Assim, a janela não é simplesmente baseada nas linhas do conjunto de dados.
Se a coluna indexadora for uma data, você possui a habilidade para especificar a extensão da janela em .before = e/ou .after = em diferentes unidades, utilizando as funções days() ou months() do pacote lubridate. Se você fizer isto, a função irá incluir os dias ausentes nas janelas como se lá estivessem (com valores NA).
Vamos mostrar uma comparação. Abaixo, nós calculamos a incidência móvel de casos por 7 dias, utilizando uma janela regular e uma indexada.
rolling <- daily_counts %>%
mutate( # crie novas colunas
# Utilizando slide_dbl()
###################
reg_7day = slide_dbl(
new_cases, # calcule utilizando new_cases
.f = ~sum(.x, na.rm = T), # função sum() com os campos em branco removidos
.before = 6), # a janela é a LINHA corrente e as 6 LINHAS anteriores
# Utilizando slide_index_dbl()
#########################
indexed_7day = slide_index_dbl(
new_cases, # calcule com new_cases
.i = date_hospitalisation, # indexado com date_onset
.f = ~sum(.x, na.rm = TRUE), # função sum() com os campos em branco removidos
.before = days(6)) # a janela é o DIA e os 6 DIAS anteriores
)Observe como, na coluna regular, a contagem aumenta constantemente nas primeiras 7 linhas, mesmo com estas linhas estando fora do intervalo de 7 dias entre elas! A coluna adjacente “indexada” leva em consideração estes dias ausentes do calendário, então suas somas móveis de 7 dias são muito menores, pelo menos neste período da epidemia, quando os casos estão mais distantes uns dos outros.
Agora você pode traçar um gráfico desses dados utilizando o ggplot():
ggplot(data = rolling)+
geom_line(mapping = aes(x = date_hospitalisation, y = indexed_7day), size = 1)
Deslizando por grupo
Se você agrupar seus dados antes de utilizar uma função do slider, as janelas deslizantes serão aplicadas por grupos. Tenha cuidado para organizar suas linhas na ordem desejada por grupo.
A cada momento que um novo grupo se inicia, as janelas deslizantes irão reiniciar. Logo, um detalhe para se ter em mente é, se seus dados são agrupados e você realizou o ajuste .complete = TRUE, você terá valores em branco a cada transição entre os grupos. Enquanto a função se desloca para baixo ao longo das linhas, cada transição na coluna de agrupamento irá reiniciar o acúmulo do tamanho mínimo da janela, de forma a permitir a realização do cálculo.
Veja a página sobre Agrupamento dos dados, deste manual, para detalhes sobre agrupamento dos dados.
Abaixo, nós contamos os casos do linelist por dia e por hospital. Então, ordenamos as linhas em ordem ascendente, primeiro ordenando por hospital, e então por dia (dentro da ordem dos hospitais). Por fim, nós ajustamos a função group_by(), e assim criamos a nossa nova média móvel.
grouped_roll <- linelist %>%
count(hospital, date_hospitalisation, name = "new_cases") %>%
arrange(hospital, date_hospitalisation) %>% # organize as linhas por hospital, e então por datas
group_by(hospital) %>% # agrupe por hospital
mutate( # média móvel
mean_7day_hosp = slide_index_dbl(
.x = new_cases, # a contagem de casos por hospital-dia
.i = date_hospitalisation, # indexe por dia de admissão
.f = mean, # utilize mean()
.before = days(6) # utilize o dia corrente e os 6 dias anteriores
)
)Aqui está o novo conjunto de dados:
Agora, nós podemos traçar os gráficos das médias móveis, mostrando os dados por grupo ao especificar ~ hospital para facet_wrap() no ggplot(). Por diversão, incluímos dois tipos de visualização - uma geom_col(), mostrando a contagem diária de casos, e uma geom_line(), mostrando a média móvel de 7 dias.
ggplot(data = grouped_roll)+
geom_col( # adicione a contagem diária de casos como barras cinzas
mapping = aes(
x = date_hospitalisation,
y = new_cases),
fill = "grey",
width = 1)+
geom_line( # adicione a média móvel como linhas coloridas por hospital
mapping = aes(
x = date_hospitalisation,
y = mean_7day_hosp,
color = hospital),
size = 1)+
facet_wrap(~hospital, ncol = 2)+ # crie pequenos gráficos por hospital
theme_classic()+ # simplifique o plano de fundo
theme(legend.position = "none")+ # remova a legenda
labs( # adicione legendas aos eixos e título do gráfico
title = "7-day rolling average of daily case incidence",
x = "Date of admission",
y = "Case incidence")
PERIGO: Se você obtiver um erro dizendo “slide() was deprecated in tsibble 0.9.0 and is now defunct. Please use slider::slide() instead.”, significa que a função slide(), do pacote tsibble, está mascarando a função slide(), do pacote slider. Corrija isso ao especificar o pacote no comando, como em slider::slide_dbl().
22.3 Calcule com o pacote tidyquant dentro da função ggplot()
O pacote tidyquant oferece outra abordagem para calcular médias móveis - desta vez, de dentro de um comando ggplot().
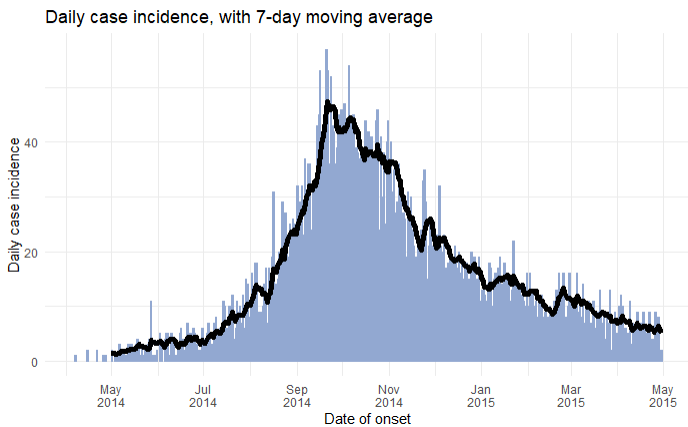
Abaixo, os dados do linelist são contados por dia do início de sintomas, e isto é adicionado ao gráfico como uma linha desbotada (alpha < 1). Em frente à essa linha, está uma outra linha criada com a função geom_ma(), do pacote tidyquant, com uma janela de 7 dias (n = 7), cor e espessura especificados.
Por padrão, geom_ma() utiliza uma média móvel simples (ma_fun = "SMA"), mas outros tipos podem ser especificados, como:
- “EMA” - média móvel exponencial (mais peso para observações recentes)
- “WMA” - média móvel ponderada (
wtssão utilizadas para ponder observações na média móvel)
- Outros tipos podem ser encontrados na documentação da função
linelist %>%
count(date_onset) %>% # conte os casos por dia
drop_na(date_onset) %>% # remova casos sem a data de início dos sintomas
ggplot(aes(x = date_onset, y = n))+ # inicie o ggplot
geom_line( # adicione uma linha com os valores brutos
size = 1,
alpha = 0.2 # linha semi-transparente
)+
tidyquant::geom_ma( # adicione a média móvel
n = 7,
size = 1,
color = "blue")+
theme_minimal() # plano de fundo simples## Warning: Using the `size` aesthetic in this geom was deprecated in ggplot2 3.4.0.
## ℹ Please use `linewidth` in the `default_aes` field and elsewhere instead.
## This warning is displayed once every 8 hours.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was generated.
Veja esse tutorial para mais detalhes das opções disponíveis dentro do pacote tidyquant.
22.4 Recursos extras
Veja este útil tutorial online do pacote slider
A página do pacote slider no github
Se seus casos necessitam que você “pule” fins de semana, ou até mesmo feriados, você pode gostar do pacote almanac.