7 Importar e exportar

Nesta página descrevemos formas de localizar, importar e exportar arquivos:
- Utilização do pacote rio para flexivelmente
import()eexport()muitos tipos de arquivos
- Uso do pacote here para localizar arquivos relativos a uma raiz de projeto R - para evitar complicações de caminhos de arquivos que são específicos de um computador
- Cenários específicos de importação, como por exemplo:
- Planilhas específicas do Excel
- Cabeçalhos confusos e linhas para pular
- Planilhas do Google
- A partir de dados postados em websites
- Com APIs
- Importação do arquivo mais recente
- Planilhas específicas do Excel
- Entrada manual de dados
- Tipos de arquivos específicos de R, como RDS e RData
- Exportar / salvar arquivos e gráficos
7.1 Visão geral
Quando você importa um “conjunto de dados” para o R, você geralmente está criando um novo objeto do tipo data frame em seu ambiente R e definindo-o como um arquivo importado (por exemplo, Excel, CSV, TSV, RDS) que está localizado em suas pastas em um determinado caminho/endereço de arquivo.
Você pode importar/exportar muitos tipos de arquivos, inclusive aqueles criados por outros programas estatísticos (SAS, STATA, SPSS). Você também pode se conectar a bancos de dados relacionais.
R tem até seus próprios formatos de dados:
- Um arquivo RDS (.rds) armazena um único objeto R, como um data frame. Estes são úteis para armazenar dados limpos, pois eles mantêm as classes de colunas R. Leia mais em esta seção.
- Um arquivo RData (.Rdata) pode ser usado para armazenar vários objetos, ou mesmo um espaço de trabalho R completo. Leia mais em esta seção.
7.2 O pacote rio
O pacote R que recomendamos é: rio. O nome “rio” é uma abreviação de “R I/O” (input/output ).
Suas funções import() e export() podem lidar com muitos tipos diferentes de arquivos (por exemplo, .xlsx, .csv, .rds, .tsv). Quando você fornece um caminho de arquivo para qualquer uma destas funções (incluindo a extensão do arquivo como “.csv”), rio lerá a extensão e utilizará a ferramenta correta para importar ou exportar o arquivo.
A alternativa ao uso do rio é usar funções de muitos outros pacotes, cada um dos quais é específico para um tipo de arquivo. Por exemplo, read.csv() (R base ), read.xlsx() (openxlsx pacote), e write_csv() (readr pacakge), etc. Estas alternativas podem ser difíceis de lembrar, enquanto que utilizar import() e export() de rio* é fácil.
As funções do rio import() e export() utilizam o pacote e função apropriados para um determinado arquivo, com base em sua extensão. Veja no final desta página uma tabela completa de quais pacotes/funções rio utilizam em segundo plano. Ele também pode ser utilizado para importar arquivos STATA, SAS e SPSS, entre dezenas de outros tipos de arquivos.
A importação/exportação de shapefiles (para mapas) requer outros pacotes, conforme detalhado na página sobre GIS básico.
7.3 O pacote here
O pacote here e sua função here() tornam fácil dizer a R onde encontrar e salvar seus arquivos - em essência, ele constrói os caminhos dos arquivos.
Utilizado em conjunto com um projeto R, here permite descrever a localização dos arquivos em seu projeto R em relação ao diretório root do projeto R (a pasta de nível superior). Isto é útil quando o projeto R pode ser compartilhado ou acessado por várias pessoas/computadores. Ele evita complicações devido aos caminhos exclusivos dos arquivos em diferentes computadores (por exemplo, `“C:/Users/Laura/Documents…’’,”iniciando” o caminho do arquivo em um lugar comum a todos os usuários (a raiz do projeto R).
É assim como here() funciona dentro de um projeto R:
- Quando o pacote here é carregado pela primeira vez dentro do projeto R, ele coloca um pequeno arquivo chamado “.here” na pasta raiz de seu projeto R como um “benchmark” ou “âncora”.
- Em seus scripts, para referenciar um arquivo nas subpastas do projeto R, você utiliza a função
here()para construir o caminho do arquivo em relação a essa âncora. - Para construir o caminho do arquivo, escreva os nomes das pastas além da raiz, entre aspas, separados por vírgulas, finalmente terminando com o nome do arquivo e a extensão do arquivo, como mostrado abaixo
- Caminhos de arquivos com a função ’here()` podem ser utilizados tanto para importação quanto para exportação
Por exemplo, abaixo, a função import() está sendo fornecida um caminho de arquivo construído com here().
O comando here("data", "linelists", "ebola_linelist.xlsx") está na verdade fornecendo o caminho completo do arquivo que é único para o computador do usuário:
"C:/Users/Laura/Documents/my_R_project/data/linelists/ebola_linelist.xlsx"A beleza é que o comando R utilizando here() pode ser executado com sucesso em qualquer computador que acesse o projeto R.
DICA: Se você não tiver certeza de onde a raiz “.here” está definida, execute a função here() com parênteses vazios.
Leia mais sobre o pacote here neste link.
7.4 Caminhos dos arquivos
Ao importar ou exportar dados, você deve fornecer um caminho para o arquivo. Você pode fazer isso de três maneiras:
- Recomendado: fornecer um caminho de arquivo “relativo” com o pacote here
- Fornecer o caminho “completo” / “absoluto” do arquivo
- Seleção manual do arquivo
Caminhos ‘relativo’ dos arquivos
No R, os caminhos de arquivo “relativos” consistem no caminho de arquivo relativo à raiz de um projeto R. Eles permitem caminhos de arquivo mais simples que podem funcionar em computadores diferentes (por exemplo, se o projeto R estiver em um drive compartilhado ou for enviado por e-mail). Como descrito acima, os caminhos de arquivo relativos são facilitados pelo uso do pacote here.
Um exemplo de um caminho de arquivo relativo construído com here() está abaixo. Supomos que o trabalho esteja em um projeto R que contém uma subpasta “dados” e dentro dela uma subpasta “linelists”, na qual há o arquivo .xlsx de interesse.
Caminhos ‘absoluto’ dos arquivos
Caminhos de arquivo absolutos ou “completos” podem ser fornecidos para funções como import() mas são “frágeis”, pois são exclusivos para o computador específico do usuário e portanto não são recomendados.
Abaixo está um exemplo de um caminho de arquivo absoluto, onde no computador de Laura há uma pasta “analises”, uma subpasta “dados” e dentro dela uma subpasta “linelists”, na qual há o arquivo .xlsx de interesse.
linelist <- import("C:/Users/Laura/Documents/analises/dados/linelists/ebola_linelist.xlsx")Algumas coisas a serem observadas sobre os caminhos absolutos dos arquivos:
- Evite o uso de caminhos de arquivo absolutos, pois eles quebrarão se o script for executado em um computador diferente.
- Utilize barras normais (
/), como no exemplo acima (nota: este é NÃO o padrão para caminhos de arquivos do Windows)
- Os caminhos de arquivos que começam com barras duplas (por exemplo, “//…”) provavelmente não serão reconhecidos por R e produzirão um erro. Considere mover seu trabalho para uma unidade “nomeado” ou ” com letras” que comece com uma letra (por exemplo, “J:” ou “C:”). Consulte a página em Interações do diretório para obter mais detalhes sobre este assunto.
Um cenário onde caminhos de arquivo absolutos podem ser apropriados é quando você deseja importar um arquivo de um drive compartilhado que tenha o mesmo caminho de arquivo completo para todos os usuários.
DICA: Para converter rapidemente todas as barras invertidas \ em barras normais /, destaque o código de interesse, use Ctrl+f (no Windows), selecione a caixa de opção “Em seleção” (In selection), e depois usar a funcionalidade de substituição para convertê-los.
Selecionando um arquivo manualmente
Você pode importar dados manualmente por meio de um destes métodos:
- Painel Ambiente (Environment) do RStudio, clique em “Importar Dados” (Import Dataset), e selecione o tipo de dado
- Clique em File / Import Dataset / (selecione o tipo de dados)
- Para seleção manual por código, utilize o comando do R base
file.choose()(deixando os parênteses vazios) para acionar a aparência de uma janela pop-up que permite ao usuário selecionar manualmente o arquivo de seu computador. Por exemplo:
# Seleção manual de um arquivo. Quando este comando for executado, uma janela POP-UP aparecerá.
# O caminho do arquivo selecionado será fornecido ao comando import().
my_data <- import(file.choose())DICA: A janela pop-up window pode aparecer ATRÁS di seu RStudio.
7.5 Importar dados
Utilizar import() para importar um conjunto de dados é bastante simples. Basta fornecer o caminho para o arquivo (incluindo o nome do arquivo e a extensão do arquivo) entre aspas. Se utilizar here() para construir o caminho do arquivo, siga as instruções acima. Abaixo estão alguns exemplos:
Importar um arquivo csv que está localizado em seu “diretório de trabalho” ou na pasta raiz do projeto R:
linelist <- import("linelist_cleaned.csv")Importação da primeira planilha de uma pasta de trabalho do Excel que está localizada nas subpastas “dados” e “linelists” do projeto R (o caminho do arquivo construído utilizando here()):
Importação de um “quadro de dados” ( referido nesse livro como data frame)(um arquivo .rds) usando um caminho de arquivo absoluto:
linelist <- import("C:/Users/Laura/Documents/tuberculosis/data/linelists/linelist_cleaned.rds")Planilhas específicas do Excel
Por padrão, se você fornecer uma pasta de trabalho Excel (.xlsx) para a função import(), a primeira planilha da pasta de trabalho será importada. Se você quiser importar uma aba (sheet) específica, inclua o nome da planilha ao which = argument. Por exemplo:
my_data <- import("my_excel_file.xlsx", which = "Sheetname")Se utilizar o método here() para fornecer um caminho relativo para import(), você ainda pode indicar uma aba específica adicionando o which = argumento depois dos parênteses de fechamento da função here().
# Demonstração: importação de uma planilha específica do Excel ao utilizar caminhos relativos com o pacote 'here'.
linelist_raw <- import(here("data", "linelist.xlsx"), which = "Sheet1")` Para exportar um data frame do R para uma planilha específica do Excel e ter o resto da pasta de trabalho do Excel inalterado, você terá que importar, editar e exportar com um pacote alternativo criado para este propósito, como openxlsx*. Veja mais informações na página em Interações do diretório ou nesta página do github.
Se sua pasta de trabalho Excel for .xlsb (pasta de trabalho Excel em formato binário) você talvez não consiga importá-la usando rio. Considere a possibilidade de salvá-la como .xlsx, ou usando um pacote como readxlsb* que é construído para este propósito.
Valores faltantes
Você pode querer designar que valor(es) em seu conjunto de dados que deve(m) ser considerado(s) como ausente(s)/faltante(s). Como explicado na página em Dados faltantes, o valor em R para dados ausentes é NA, mas talvez o conjunto de dados que você deseja importar utilize 99, “Ausente”, ou apenas espaço vazio de caracteres “” em vez disso.
Utilize o na = argumento para import() e forneça o(s) valor(es) entre aspas (mesmo que sejam números). Você pode especificar múltiplos valores incluindo-os dentro de um vetor, utilizando c() como mostrado abaixo.
Aqui, o valor “99” no conjunto de dados importados é considerado ausente e convertido para NA em R.
Qualquer um dos valores “Missing”, “” (célula vazia), ou “” (espaço único) no conjunto de dados importados são convertidos para NA no R.
Pular linhas
Às vezes, você pode querer evitar a importação de uma linha específica de dados. Você pode fazer isso com o argumento skip = se utilizar import() de rio em um arquivo .xlsx ou .csv. Forneça o número de linhas que você deseja pular.
linelist_raw <- import("linelist_raw.xlsx", skip = 1) # Não importa a linha de cabeçalhoInfelizmente ’skip = ’aceita apenas um valor inteiro, não um intervalo (por exemplo, “2:10” não funciona). Para pular a importação de linhas específicas que não são consecutivas do topo, considere importar várias vezes e utilizar bind_rows() a partir de dplyr*. Veja o exemplo abaixo de pular apenas a linha 2.
Como lidar com uma segunda linha de cabeçalho
Às vezes, seus dados podem ter uma segunda linha de cabeçalho, por exemplo, se for uma linha de “dicionário de dados”, como mostrado abaixo. Esta situação pode ser problemática porque pode resultar na importação de todas as colunas como a classe “caractere”.
Abaixo está um exemplo deste tipo de conjunto de dados (sendo a primeira linha o dicionário de dados).
Remover uma segunda linha de cabeçalho
Para ignorar a segunda linha de cabeçalho, você provavelmente precisará importar os dados duas vezes.
- Importar os dados para armazenar os nomes corretos das colunas
- Importar os dados novamente, pulando as primeiras duas fileiras (cabeçalho e segunda fileira)
- Ligar os nomes corretos no campo de dados reduzido
O argumento exato usado para ligar os nomes corretos das colunas depende do tipo de arquivo de dados (.csv, .tsv, .xlsx, etc.). Isto porque rio está usando uma função diferente para os diferentes tipos de arquivo (ver tabela acima).
Para arquivos Excel: (col_names =)
# importe a primeira vez; salve o nome das colunas
linelist_raw_names <- import("linelist_raw.xlsx") %>% names() # Salva o nome veradeiro das colunas
# Importe uma segunda vez; pule a segunda linha e designe os nomes das colunas para o argumento col_names =
linelist_raw <- import("linelist_raw.xlsx",
skip = 2,
col_names = linelist_raw_names
) Para arquivos CSV: (col.names =)
# importe a primeira vez; salve o nome das colunas
linelist_raw_names <- import("linelist_raw.csv") %>% names() # salve o nome verdadeiro das colunas
# note que o argumento para arquivos csv é 'col.names = '
linelist_raw <- import("linelist_raw.csv",
skip = 2,
col.names = linelist_raw_names
) Opção de Backup - atribuir/sobreescrever cabeçalhos usando a função ‘colnames()’ do base
# assign/overwrite headers using the base 'colnames()' function
colnames(linelist_raw) <- linelist_raw_namesFazendo um dicionário de dados
Bônus! Se você tiver uma segunda linha que seja um dicionário de dados, você pode facilmente criar um dicionário de dados adequado a partir dele. Esta dica é adaptada a partir deste post.
dict <- linelist_2headers %>% # começa: linelist com um dicionário como a primeira linha
head(1) %>% # mantenha apenas os nomes das colunas e a primeira linha com o dicionário
pivot_longer(cols = everything(), # faça o pivotamento de todas as coluna spara o formato "longo"
names_to = "Column", # nomeie as colunas
values_to = "Description")Combinar duas linhas de cabeçalho
Em alguns casos, quando seu conjunto de dados brutos tiver duas linhas de cabeçalho (ou mais especificamente, a segunda linha de dados é um cabeçalho secundário), você pode querer “combiná-las” ou adicionar os valores da segunda linha de cabeçalho à primeira linha de cabeçalho.
O comando abaixo definirá os nomes das colunas do data frame como a combinação (colando em conjunto) dos primeiros cabeçalhos (verdadeiros) com o valor imediatamente abaixo (na primeira linha).
Planilhas do Google
Você pode importar dados de uma planilha on-line do Google com o pacote googlesheet4 e autenticando seu acesso à planilha.
pacman::p_load("googlesheets4")Abaixo, uma planilha de demonstração do Google é importada e salva. Este comando pode solicitar a confirmação da autenticação de sua conta Google. Siga as instruções e pop-ups em seu navegador de internet para conceder permissões aos pacotes Tidyverse API para editar, criar e excluir suas planilhas no Google Drive.
A planilha abaixo é “visualizável para qualquer pessoa com o link” e você pode tentar importá-la.
Gsheets_demo <- read_sheet("https://docs.google.com/spreadsheets/d/1scgtzkVLLHAe5a6_eFQEwkZcc14yFUx1KgOMZ4AKUfY/edit#gid=0")A planilha também pode ser importada usando apenas a identificação da planilha, uma parte mais curta da URL:
Gsheets_demo <- read_sheet("1scgtzkVLLHAe5a6_eFQEwkZcc14yFUx1KgOMZ4AKUfY")Outro pacote, googledrive oferece funções úteis para escrever, editar e excluir planilhas do Google. Por exemplo, utilizando as funções gs4_create() e sheet_write() encontradas neste pacote.
Aqui estão alguns outros tutoriais on-line úteis:
tutorial básico de importação de planilhas do Google
tutorial mais detalhado
interação entre as googlesheets4 e tidyverse
7.6 Múltiplos arquivos- importar, exportar, dividir, combinar
Veja a página em Iteração, loops e listas para exemplos de como importar e combinar vários arquivos, ou vários arquivos de pastas de trabalho Excel. Essa página também tem exemplos de como dividir um data frame em partes e exportar cada uma separadamente, ou como planilhas nomeadas em uma pasta de trabalho do Excel.
7.7 Importar do GitHub
A importação de dados diretamente do Github para R pode ser muito fácil ou pode exigir alguns passos - dependendo do tipo de arquivo. Abaixo estão algumas abordagens:
Arquivos CSV
Pode ser fácil importar um arquivo .csv diretamente do Github para R com um comando R.
- Vá até o repositório Github, localize o arquivo de interesse e clique sobre ele
- Clique no botão “Raw” (você verá então os dados “brutos” do csv, como mostrado abaixo)
- Copiar a URL (endereço web)
- Colocar a URL entre aspas dentro do comando
import()no R

Arquivo XLSX
Talvez você não consiga visualizar os dados “Raw” de alguns arquivos (por exemplo, .xlsx, .rds, .nwk, .shp)
- Vá até o repositório Github, localize o arquivo de interesse e clique sobre ele
- Clique no botão “Download”, como mostrado abaixo
- Salve o arquivo em seu computador, e importe-o para o R

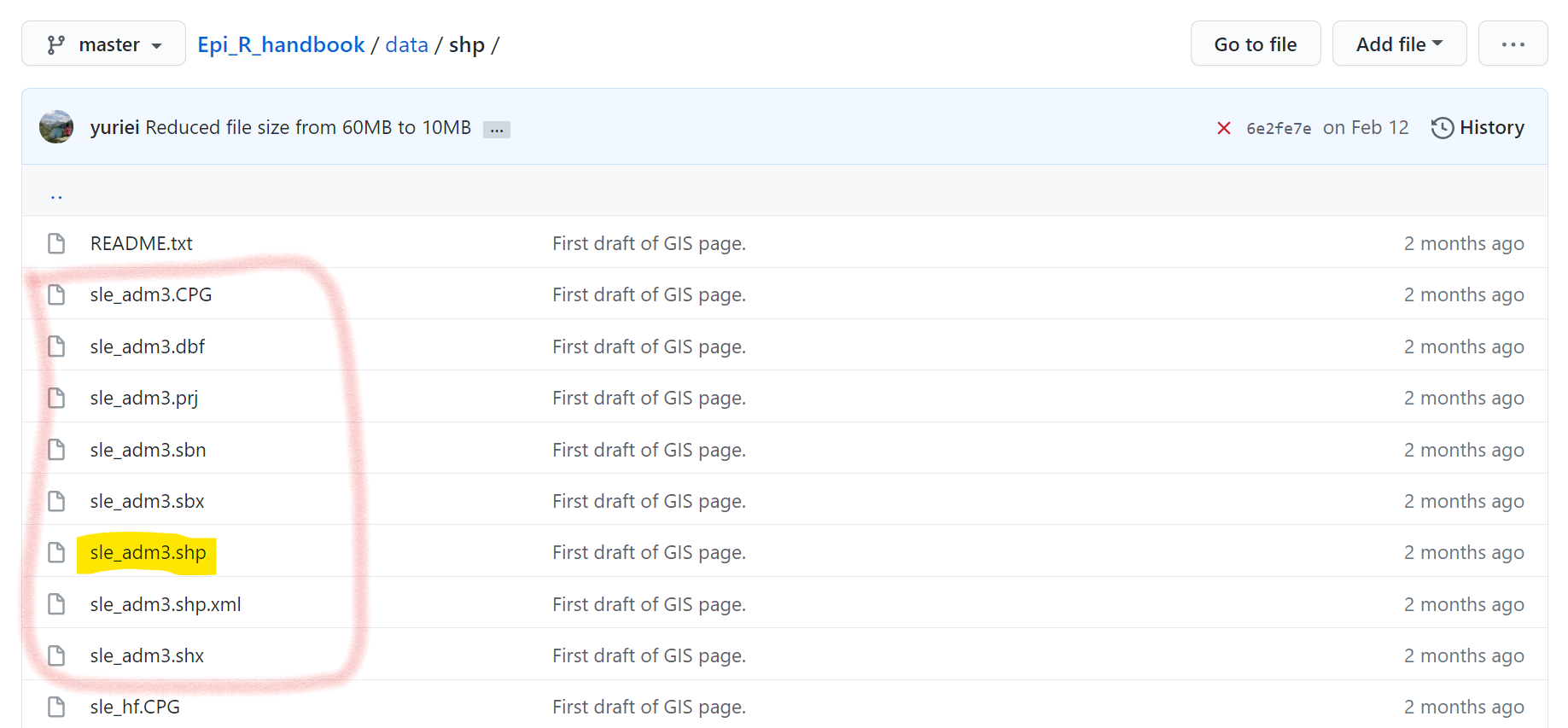
Shapefiles
Os shapefiles têm muitos sub-componentes, cada um com uma extensão de arquivo diferente. Um arquivo terá a extensão “.shp”, mas outros podem ter “.dbf”, “.prj”, etc. Para baixar um shapefile do Github, você precisará baixar cada um dos arquivos de subcomponentes individualmente, e salvá-los na mesma pasta em seu computador. No Github, clique em cada arquivo individualmente e faça o download deles clicando no botão “Download”.
Uma vez salvo em seu computador, você pode importar o shapefile como mostrado na página GIS básico utilizando st_read() do pacote sf. Você só precisa fornecer o caminho do arquivo e o nome do arquivo “.shp” - desde que os outros arquivos relacionados estejam dentro da mesma pasta em seu computador.
Abaixo, você pode ver como o shapefile “sle_adm3” consiste de muitos arquivos - cada um dos quais deve ser baixado do Github.
7.8 Inserir dados munualmente
Inserção por linhas
Utilize a função tribble do pacote tibble do tidyverse (referência online tibble).
Observe como os cabeçalhos das colunas começam com um til (~). Observe também que cada coluna deve conter apenas uma classe de dados (caractere, numérico, etc.). Você pode utilizar abas, espaçamento e novas linhas para tornar a entrada de dados mais intuitiva e legível. Os espaços não importam entre os valores, mas cada linha é representada por uma nova linha de código. Por exemplo:
# Crie um conjunto de dados manualmente por linha
manual_entry_rows <- tibble::tribble(
~colA, ~colB,
"a", 1,
"b", 2,
"c", 3
)A agora nós exibimos o novo data frame::
Inserção por colunas
Como um data frame consiste em vetores (colunas verticais), a abordagem base para a criação manual de data frames no R espera que você defina cada coluna e depois as vincule juntas. Isto pode ser contra-intuitivo em epidemiologia, pois geralmente pensamos em nossos dados em linhas (como acima).
# definir cada vetor (coluna vertical) separadamente, cada um com seu próprio nome
PatientID <- c(235, 452, 778, 111)
Treatment <- c("Yes", "No", "Yes", "Yes")
Death <- c(1, 0, 1, 0)CUIDADO: Todos os vetores devem ter o mesmo comprimento (mesmo número de valores).
The vectors can then be bound together using the function data.frame():
# combine as colunas em um *data frame*, referenciando os nomes dos vetores
manual_entry_cols <- data.frame(PatientID, Treatment, Death)E agora vamos vizualizar o novo conjunto de dados:
Colando a partir da área de transferência
Se você copiar dados de outro lugar e os tem na “área de transferência” (clipboard), você pode tentar uma das duas maneiras abaixo:
Do pacote clipr*, você pode utilizar read_clip_tbl() para importar como um data frame, ou apenas read_clip() para importar como um vetor de caracteres. Em ambos os casos, deixe os parênteses vazios.
linelist <- clipr::read_clip_tbl() # importa a área de transferência atual como uma data frame
linelist <- clipr::read_clip() # importa como um vetor de caracteresVocê também pode exportar facilmente para a área de transferência do seu sistema com clipr*. Veja a seção abaixo sobre Exportação.
Alternativamente, você pode utilizar a função read.table() do R base com file = "clipboard") para importar como um data frame:
df_from_clipboard <- read.table(
file = "clipboard", # specify this as "clipboard"
sep = "t", # separator could be tab, or commas, etc.
header=TRUE) # if there is a header row7.9 Importar o arquivo mais recente
Muitas vezes você pode receber atualizações diárias de seus conjuntos de dados. Neste caso, você vai querer escrever o código que importa o arquivo mais recente. A seguir, apresentamos duas formas de abordar este assunto:
- Selecionando o arquivo com base na data no nome do arquivo
- Seleção do arquivo com base nos metadados do arquivo (última modificação)
Datas no nome de um arquivo
Esta abordagem depende de três premissas:
- Você confia nas datas nos nomes dos arquivos
- As datas são numéricas e aparecem em geralmente no mesmo formato (por exemplo, ano, mês e dia)
- Não há outros números no nome do arquivo
Explicaremos cada passo e, no final, mostraremos a combinação deles.
Primeiro, utilize dir() do R base para extrair apenas os nomes dos arquivos para cada arquivo na pasta de interesse. Consulte a página em Interações de diretório para obter mais detalhes sobre dir(). Neste exemplo, a pasta de interesse é a pasta “linelists” dentro da pasta “exemplo” dentro de “data” dentro do projeto R.
linelist_filenames <- dir(here("data", "example", "linelists")) # pega o nome dos arquivos da pasta
linelist_filenames # exibe ## [1] "20201007linelist.csv" "case_linelist_2020-10-02.csv"
## [3] "case_linelist_2020-10-03.csv" "case_linelist_2020-10-04.csv"
## [5] "case_linelist_2020-10-05.csv" "case_linelist_2020-10-08.xlsx"
## [7] "case_linelist20201006.csv"Uma vez que você tenha este vetor de nomes, você pode extrair as datas a partir deles aplicando str_extract() de stringr utilizando esta expressão regular. Ela extrai quaisquer números no nome do arquivo (incluindo quaisquer outros caracteres no meio, tais como traços ou cortes). Você pode ler mais sobre stringr* na página Strings e caracteres.
linelist_dates_raw <- stringr::str_extract(linelist_filenames, "[0-9].*[0-9]") # extrai números e quaisquer caracteres no meio
linelist_dates_raw # print## [1] "20201007" "2020-10-02" "2020-10-03" "2020-10-04" "2020-10-05" "2020-10-08"
## [7] "20201006"Assumindo que as datas são escritas geralmente no mesmo formato (por exemplo, Ano e depois Mês e depois Dia) e os anos têm 4 dígitos, você pode utilizar lubridate’s funções flexíveis de conversão (ymd(), dmy(), ou mdy()) para convertê-las em datas. Para estas funções, os traços, espaços ou cortes não importam, apenas a ordem dos números. Leia mais na página Trabalhando com datas.
linelist_dates_clean <- lubridate::ymd(linelist_dates_raw)
linelist_dates_clean## [1] "2020-10-07" "2020-10-02" "2020-10-03" "2020-10-04" "2020-10-05" "2020-10-08"
## [7] "2020-10-06"A função do R base which.max() pode então ser utilizada para retornar a posição do índice (por exemplo, 1º, 2º, 3º, …) do valor máximo da data. O último arquivo é corretamente identificado como o 6º arquivo - “case_linelist_2020-10-08.xlsx”.
index_latest_file <- which.max(linelist_dates_clean)
index_latest_file## [1] 6Se nós condensarmos todos esses comandos, o cógico compelto deve parecer com o abaixo. Observe que o . na ultima linha é um marcador para o objeto pipe naquele ponta da sequência de pipes. Naquele ponto o valor é implesmente o número 6. Isso é colocado entre cochetes para extrair o sexto elemnto do vetor de nomes do arquivo produzido por dir().
# carrega os pacotes
pacman::p_load(
tidyverse, # manipulação de dados
stringr, # trabalha com strings/caravteres
lubridate, # trabalha com datas
rio, # importar / exportar
here, # caminhos relativos dos arquivos
fs) # interações entre diretórios
# extrai o nome do arquivo mais recente
latest_file <- dir(here("data", "example", "linelists")) %>% # nomes dos aequivos da subpasta "linelists"
str_extract("[0-9].*[0-9]") %>% # extrai as datas (números)
ymd() %>% # converte números pra datas (assumindo o formato ano-mês-dia)
which.max() %>% # pega o índice da maior data (arquivo mais recente)
dir(here("data", "example", "linelists"))[[.]] # retorna o nome do arquivo da linelist mais recente
latest_file # mostra o nome do arquivo do artigo mais recente## [1] "case_linelist_2020-10-08.xlsx"Você pode agora usar esse nome para finalizar o caminho relativo do arquivo, com here():
here("dados", "example", "linelists", latest_file) E agora você pode importar o arquivo mais recente:
Use as informações do arquivo
Se seus arquivos não tiverem datas em seus nomes (ou se você não confiar nessas datas), você pode tentar extrair a data da última modificação dos metadados do arquivo. Use funções do pacote fs para examinar as informações dos metadados de cada arquivo, que incluem o tempo da última modificação e o caminho do arquivo.
Abaixo, fornecemos a pasta de interesse para fs’s dir_info(). Neste caso, a pasta de interesse está no projeto R na pasta “dados”, na subpasta “exemplo” e em sua subpasta “linelists”. O resultado é um data frame com uma linha por arquivo e colunas para modification_time',path’, etc. Você pode ver um exemplo visual disto na página em interações de diretório.
Podemos ordenar este data frame de arquivos pela coluna modification_time, e então manter apenas a linha superior/última linha (arquivo) com a função do R base* head(). Então podemos extrair o caminho do arquivo deste último arquivo somente com a função dplyr* pull() na coluna path. Finalmente, podemos passar este caminho de arquivo para import(). O arquivo importado é salvo como latest_file.
latest_file <- dir_info(here("dados", "examplo", "linelists")) %>% # coleta dados sobre todos os arquivos no diretório
arrange(desc(modification_time)) %>% # classifica por data da última modificação
head(1) %>% # mantém apenas o arquivo modificado por último
pull(path) %>% # extrai apenas o endereço do arquivo
import() # importa o arquivo7.10 APIs
Uma “Interface de Programação Automatizada” (API) pode ser usada para solicitar dados diretamente de um website. As APIs são um conjunto de regras que permitem que uma aplicação de software interaja com outra. O cliente (você) envia uma “solicitação” e recebe uma “resposta” contendo o conteúdo. Os pacotes R httr e jsonlite* podem facilitar este processo.
Cada website habilitado para API terá sua própria documentação e especificações para se familiarizar. Alguns sites estão disponíveis publicamente e podem ser acessados por qualquer pessoa. Outros, tais como plataformas com IDs de usuário e credenciais, requerem autenticação para acessar seus dados.
Não é preciso dizer que é necessário ter uma conexão com a Internet para importar dados via API. Daremos breves exemplos de uso de APIs para importar dados e conectá-lo a outros recursos.
Note: lembre-se que os dados podem ser postados* em um website sem API, o que pode ser mais fácil de ser recuperado. Por exemplo, um arquivo CSV postado pode ser acessível simplesmente fornecendo a URL do site para import() como descrito na seção sobre importação de Github.*
Requisição HTTP
A troca de API é mais comumente feita através de uma solicitação HTTP. HTTP é o Protocolo de Transferência de Hipertexto, e é o formato subjacente de uma solicitação/resposta entre um cliente e um servidor. A entrada e saída exata pode variar dependendo do tipo de API, mas o processo é o mesmo - uma “Solicitação” (geralmente Solicitação HTTP) do usuário, muitas vezes contendo uma consulta, seguida por uma “Resposta”, contendo informações de status sobre a solicitação e possivelmente o conteúdo solicitado.
Aqui estão alguns componentes de uma solicitação HTTP:
- A URL do endpoint da API
- O “Método” (ou “Verbo”)
- Cabeçalhos
- Corpo
O “método” de solicitação HTTP é a ação que você deseja realizar. Os dois métodos HTTP mais comuns são GET e POST, mas outros poderiam incluir PUT, DELETE, PATCH, etc. Ao importar dados para R, é mais provável que você utilize GET.
Após sua solicitação, seu computador receberá uma “resposta” em um formato similar ao que você enviou, incluindo URL, status HTTP (Status 200 é o que você quer!), tipo de arquivo, tamanho e o conteúdo desejado. Você precisará então analisar esta resposta e transformá-la em um data frame funcional dentro de seu ambiente R.
Pacotes
O pacote httr funciona bem para lidar com solicitações HTTP em R. Ele requer pouco conhecimento prévio de APIs Web e pode ser usado por pessoas menos familiarizadas com a terminologia de desenvolvimento de software. Além disso, se a resposta HTTP for .json, você pode usar jsonlite para analisar a resposta.
# carrega pacotes
pacman::p_load(httr, jsonlite, tidyverse)Dados públicos
Abaixo é um exemplo de uma solicitação de HTTP, originalmente de um tutorial do the Trafford Data Lab. Esse site têm vários outros recursos para aprender esse tema e exercícios sobre API.
Cenário: nós queremos importar uma lista de restaurantes fast food na cidade de Trafford, Reino Unido. Os dados podem ser acessados pela API da Food Standards Agency, que disponibiliza dados e classificações acerca de hiigiene alimentar no Reino Unido.
OAqui estão os parâmetros para a nossa solicitação:
- HTTP verb: GET
- API endpoint URL: http://api.ratings.food.gov.uk/Establishments
- Parâmetros selecionados: name, address, longitude, latitude, businessTypeId, ratingKey, localAuthorityId
- Cabeçalho: “x-api-version”, 2
- Formato(s) dos dados: JSON, XML
- Documentação: http://api.ratings.food.gov.uk/help
O código no R seria como seguinte:
# prepare a solicitação
path <- "http://api.ratings.food.gov.uk/Establishments"
request <- GET(url = path,
query = list(
localAuthorityId = 188,
BusinessTypeId = 7844,
pageNumber = 1,
pageSize = 5000),
add_headers("x-api-version" = "2"))
# cheque para algum erro no servidor ("200" é bom!)
request$status_code
# submita a solicitação, separe a resposta, e converta para um data frame
response <- content(request, as = "text", encoding = "UTF-8") %>%
fromJSON(flatten = TRUE) %>%
pluck("establishments") %>%
as_tibble()Agora você pode limpar e utilizar o data frame resposta (response), que contém uma linha por estabelecimento de fast food.
Autenticação necessária
Algumas APIs requerem autenticação - para que você possa provar quem você é, para que possa acessar dados restritos. Para importar estes dados, você pode precisar primeiro usar um método POST para fornecer um nome de usuário, senha, ou código. Isto retornará um token de acesso, que pode ser usado para solicitações posteriores do método GET para recuperar os dados desejados.
Abaixo está um exemplo de consulta de dados do Go.Data, que é uma ferramenta de investigação de surtos. Go.Data usa uma API para todas as interações entre o front-end da web e os aplicativos smartphone usados para a coleta de dados. O Go.Data é usado em todo o mundo. Como os dados do surto são sensíveis e você só deve ser capaz de acessar os dados para seu surto, a autenticação é necessária.
Abaixo estão alguns exemplos de código R usando httr e jsonlite para conexão com a API Go.Data para importar dados sobre o acompanhamento de contato de seu surto.
# configure as credenciais para a autorização
url <- "https://godatasampleURL.int/" # instânica url Go.Data válida
username <- "username" # nome de usuário do Go.Data válido
password <- "password" # senha do Go.Data válida
outbreak_id <- "xxxxxx-xxxx-xxxx-xxxx-xxxxxxx" # ID do surto do Go.Data outbreak válida
# obtenha o token de acesso
url_request <- paste0(url,"api/oauth/token?access_token=123") # defina a solicitação da url base
# prepare a solicitação
response <- POST(
url = url_request,
body = list(
username = username, # use o nome de usuario e senha salvos acima para autorizar
password = password),
encode = "json")
# execute a rolicitação e separe a resposta
content <-
content(response, as = "text") %>%
fromJSON(flatten = TRUE) %>% # flatten nested JSON
glimpse()
# Salve o token de acesso da resposta
access_token <- content$access_token # salve o token de acesso para permitir as chamadas subsequentes abaixo
# importat os contatos dos surtos
# Use o token de access
response_contacts <- GET(
paste0(url,"api/outbreaks/",outbreak_id,"/contacts"), # OBTENHA (GET) a solicitação
add_headers(
Authorization = paste("Bearer", access_token, sep = " ")))
json_contacts <- content(response_contacts, as = "text") # converta para texto JSON
contacts <- as_tibble(fromJSON(json_contacts, flatten = TRUE)) # "achate" o JSON para um tibbleCUIDADO: Se você estiver importando grandes quantidades de dados de um API que requeira autenticação, poderá haver um intervalo de tempo. Para evitar isto, recupere o access_token novamente antes de cada solicitação GET API e tente usar filtros ou limites na consulta.
DICA: A função fromJSON() no pacote jsonlite não desalinha totalmente na primeira vez em que é executada, então você provavelmente ainda terá itens de lista em seu tibble resultante. Você precisará des-nidificar ainda mais para certas variáveis; dependendo de como seu .json está aninhado. Para ver mais informações sobre isto, veja a documentação do pacote jsonlite, como a função flatten().
Para mais detalhes, Veja a documentação em LoopBack Explorer, a página Rastreamento de Contatos ou dicas de API em Go.Data Github repository
Você pode ler mais sobre o pacote httr aqui
Esta seção também foi informada por este tutorial e este tutorial.
7.11 Exportar
7.11.1 Com o pacote rio {.não numerado}
Com rio*, você pode utilizar a função export() de uma forma muito semelhante à import(). Primeiro dê o nome do objeto R que você deseja salvar (por exemplo, linelist) e depois, entre aspas, coloque o caminho do arquivo onde você deseja salvar o arquivo, incluindo o nome do arquivo desejado e a extensão do arquivo. Por exemplo, o nome do objeto R:
Isto salva o data frame linelist como uma pasta de trabalho do Excel para a pasta raiz do diretório de trabalho/R do projeto:
export(linelist, "my_linelist.xlsx") # will save to working directoryVocê poderia salvar o mesmo data frame que um arquivo csv, alterando a extensão. Por exemplo, nós também o salvamos em um caminho de arquivo construído com aqui():
Para a área de transferência
Para exportar um data frame para a “área de transferência” do seu computador (para depois colar em outro software como Excel, Google Spreadsheets, etc.) você pode utilizar write_clip() do pacote clipr*.
# exporte a linelist para a área de transferência do seu sistema
clipr::write_clip(linelist)7.12 Arquivos RDS
Junto com .csv, .xlsx, etc., você também pode exportar/vendar data frame R como arquivos .rds. Este é um formato de arquivo específico para R, e é muito útil se você souber que irá trabalhar com os dados exportados novamente em R.
As classes de colunas são armazenadas, de modo que você não terá que limpar novamente quando for importado (com um arquivo Excel ou mesmo um arquivo CSV isto pode ser uma dor de cabeça!). É também um arquivo menor, que é útil para exportação e importação se seu conjunto de dados for grande.
Por exemplo, se você trabalha em uma equipe de Epidemiologia e precisa enviar arquivos para uma equipe GIS para mapeamento, e eles usam R também, basta enviar-lhes o arquivo .rds! Então todas as classes de colunas são mantidas e têm menos trabalho a fazer.
7.13 Arquivos e listas Rdata
Arquivos do tipo .Rdata cpode armazenar múltiplos objetos R - por exemplo, múltiplos data frames, resultados de modelos, listas, etc. Isto pode ser muito útil para consolidar ou compartilhar muitos de seus dados para um determinado projeto.
No exemplo abaixo, múltiplos objetos R são armazenados dentro do arquivo exportado “my_objects.Rdata”:
rio::export(my_list, my_dataframe, my_vector, "my_objects.Rdata")Nota: se você estiver tentando importar uma lista, utilize import_list() de rio para importá-la com a estrutura e o conteúdo original completo.
rio::import_list("my_list.Rdata")7.14 Salvando gráficos
Instruções em como salvar gráficos, incluindo os criados pelo pacote ggplot(), são discutidos com profundidado na página ggplot basics.
Em resumo, execute o código ggsave("my_plot_filepath_and_name.png") após exibir o seu gráfico. Você pode prover um objeto de gráfico para o argumento plot =, ou especificar o endereço de salvamento (com extensão de arquivo desejada) para salvar o último gráfico exibido. Você pode tamb[ém controlar o tamanho e qualidade por meio dos argumentos: width =, height =, units = e dpi =.
Como salvar um gráfico de redes, como uma árvore de transmissão, é discutido na página Cadeias de Transmissão.
7.15 Recursos
O Manual de Importação/Exportação de Dados R
R 4 Capítulo de ciência dos dados sobre importação de dados
documentação ggsave()
Abaixo está uma tabela, extraída do rio online vinheta. Para cada tipo de dado ele mostra: a extensão de arquivo esperada, o pacote rio* utilizado para importar ou exportar os dados, e se esta funcionalidade está incluída na versão instalada padrão do rio.
Formato | Extensão típica | Pacote de Importação | Pacote de exportação | Instalado por padrão
—————————_|—————–|————————|———————-|———————
Dados separados por vírgulas | .csv | data.table fread() | data.table | Sim
Dados separados por Pipe | .psv | data.table fread() | data.table | Sim
Dados separados por Tab .tsv | data.table fread() | data.table | Sim
SAS | .sas7bdat | haven | haven | Sim
SPSS | .sav | haven | haven | Sim
Stata | .dta | haven | haven | Sim
SAS | XPORT | .xpt | haven | haven | Sim
SPSS Portable | .por | haven | | Sim
Excel | .xls | readxl | | Sim
Excel | .xlsx | readxl | openxlsx | Sim
R syntax | .R | base | base | Sim
Objetos R salvos | .RData, .rda | base | base | Sim
Objetos R seriados | .rds | base | base | Sim
Epiinfo | .rec | foreign | | Sim
Minitab | .mtp | foreign | | Sim
Systat | .syd | foreign | | Sim
“XBASE” | database files | .dbf | foreign | foreign | Sim
Weka Attribute-Relation File Format | .arff | foreign | foreign | Sim
Dados no formato de intercâmbio| .dif | utils | | Sim
Dados Fortran da | no recognized extension | utils | | Sim
Dados no formato largura fixa | .fwf | utils | utils | Sim
dados separados por vírgulas gzip | .csv.gz | utils | utils | v
CSVY (CSV + YAML metadata header) | .csvy | csvy | csvy | Não
EViews | .wf1 |hexView | | Não
Formato de intercâmbio Feather R/Python | .feather | feather | feather | Não
Fast Storage | .fst | fst | fst | Não
JSON | .json | jsonlite | jsonlite | Não
Matlab | .mat | rmatio | rmatio | Não
Planilhas OpenDocument | .ods | readODS | readODS | Não
Tabelas HTML | .html | xml2 | xml2 | Não
Documentos Shallow XML | .xml | xml2 | xml2 | Não
YAML | .yml | yaml | yaml | Não
Padrão da área de transferência é tsv | | clipr | clipr | Não