24 Mô hình hóa dịch bệnh
24.1 Tổng quan
Ngày càng có nhiều công cụ để tạo một mô hình dịch bệnh cho phép chúng ta tiến hành các phân tích khá phức tạp và tiết kiệm nguồn lực. Chương này sẽ cung cấp một cái nhìn tổng quan về cách sử dụng các công cụ để:
- ước tính hệ số lây nhiễm hiệu quả Rt và các thống kê liên quan chẳng hạn như thời gian tăng gấp đôi
- đưa ra các dự báo ngắn hạn về số mắc mới trong tương lai
Chương này không tổng quan về các phương pháp luận và phương pháp thống kê cơ bản của các công cụ này, vì vậy vui lòng tham khảo mục Tài liệu tham khảo để đọc các bài báo có đề cập tới. Hãy chắc chắn rằng bạn có kiến thức cơ bản về các phương pháp trước khi sử dụng các công cụ này; điều này sẽ đảm bảo bạn có thể giải thích chính xác các kết quả của chúng.
Dưới đây là một ví dụ về những kết quả đầu ra mà chúng ta sẽ thực hiện trong chương này.
24.2 Chuẩn bị
Chúng ta sẽ sử dụng hai phương pháp và package khác nhau để ước tính Rt, cụ thể là package EpiNow và package EpiEstim, cũng như package projections cho dự báo các trường hợp mới mắc.
Đoạn code này hiển thị tải các package cần thiết cho các phân tích. Trong sổ tay này, chúng tôi nhấn mạnh đến hàm p_load() từ package pacman, để cài đặt package nếu cần thiết và gọi package để sử dụng. Bạn cũng có thể gọi các package đã cài đặt với hàm library() từ base R. Xem thêm chương R cơ bản để biết thêm thông tin về package R.
pacman::p_load(
rio, # File import
here, # File locator
tidyverse, # Data management + ggplot2 graphics
epicontacts, # Analysing transmission networks
EpiNow2, # Rt estimation
EpiEstim, # Rt estimation
projections, # Incidence projections
incidence2, # Handling incidence data
epitrix, # Useful epi functions
distcrete # Discrete delay distributions
)Chúng ta sẽ sử dụng bộ dữ liệu các trường hợp linelist đã được làm sạch cho tất cả các phân tích trong chương này. Để tiện theo dõi, bấm để tải xuống bộ dữ liệu linelist đã được “làm sạch” (dưới dạng tệp .rds). Xem chương Tải sách và dữ liệu để tải xuống tất cả các dữ liệu minh họa được sử dụng trong sổ tay này.
# import the cleaned linelist
linelist <- import("linelist_cleaned.rds")24.3 Ước tính Rt
EpiNow2 và EpiEstim
Hệ số lây nhiễm R là thước đo khả năng lây truyền của một bệnh và được định nghĩa là số ca thứ phát kỳ vọng trên mỗi trường hợp nhiễm bệnh. Trong một quần thể cảm nhiễm toàn bộ, giá trị này đại diện cho hệ số lây nhiễm cơ bản R0. Tuy nhiên, vì số lượng các cá thể cảm nhiễm trong một quần thể thay đổi trong suốt vụ dịch hoặc đại dịch và khi các biện pháp ứng phó khác nhau được thực hiện, chỉ số đo lường khả năng lây truyền thường được sử dụng phổ biến nhất là hệ số lây nhiễm hiệu quả Rt; nó được định nghĩa là số trường hợp thứ cấp kỳ vọng trên mỗi trường hợp bị nhiễm tại một thời điểm t nhất định.
Package EpiNow2 cung cấp một framework phức tạp nhất cho việc ước tính Rt. Package này có hai điểm mạnh chính so với package thường dùng khác là EpiEstim như sau:
- Nó giải thích cho thời gian trì hoãn (delay) trong báo cáo và do đó có thể ước tính Rt ngay cả khi dữ liệu không đầy đủ.
- Nó ước tính Rt dựa vào ngày nhiễm bệnh hơn là ngày khởi phát được báo cáo, có nghĩa là ảnh hưởng của một can thiệp sẽ được thể hiện ngay lập tức bởi sự thay đổi của Rt, thay vì có một sự trì hoãn.
Tuy nhiên, nó cũng có hai nhược điểm chính:
- Nó yêu cầu kiến thức về phân phối thời gian phát sinh một thế hệ (generation time: tức là phân phối khoảng thời gian giữa ca nhiễm trùng sơ cấp và các ca thứ cấp), phân bố thời gian ủ bệnh (incubation period: tức là phân bố khoảng thời gian giữa nhiễm trùng và khởi phát triệu chứng) và bất kỳ phân phối khoảng thời gian nào khác có liên quan đến dữ liệu của bạn (ví dụ: nếu bạn có ngày báo cáo, bạn cần thông tin phân phối độ trễ từ khi bắt đầu có triệu chứng đến khi được báo cáo). Trong khi điều này sẽ cho phép ước tính Rt chính xác hơn thì package EpiEstim chỉ yêu cầu phân bố của khoảng thời gian liên tiếp (serial interval: khoảng thời gian từ lúc bệnh nhân ban đầu khởi phát triệu chứng đến lúc bệnh nhân thứ phát có triệu chứng khởi phát), mà đó có thể là phân phối duy nhất có sẵn cho bạn.
- Package EpiNow2 chậm hơn đáng kể so với package EpiEstim theo một hệ số khoảng 100-1000 (tin đồn)! Ví dụ: ước tính Rt đối với đợt bùng phát được lấy ví dụ trong phần này mất khoảng bốn giờ (được chạy lặp lại một số lượng lớn lần để đảm bảo độ chính xác và tất nhiên có thể giảm nếu cần thiết, tuy nhiên nói chung là thuật toán chậm). Điều này có thể không khả thi nếu bạn thường xuyên phải cập nhật ước tính Rt.
Do đó, package bạn chọn sử dụng sẽ phụ thuộc vào dữ liệu, thời gian và tài nguyên tính toán có sẵn cho bạn.
###Package EpiNow2 {.unnumbered}
Ước tính phân phối thời gian trì hoãn
Phân phối độ trễ yêu cầu chạy package EpiNow2 tùy thuộc vào dữ liệu bạn có. Về cơ bản, bạn cần có khả năng mô tả độ trễ từ ngày nhiễm bệnh đến ngày diễn ra sự kiện bạn muốn sử dụng để ước tính Rt. Nếu bạn đang sử dụng ngày bắt đầu, thì nó sẽ chỉ đơn giản là phân bố thời kỳ ủ bệnh. Nếu bạn đang sử dụng ngày báo cáo, bạn yêu cầu thời gian trì hoãn từ khi lây nhiễm đến khi báo cáo. Bởi vì phân phối này khó có thể được biết trực tiếp, package EpiNow2 cho phép bạn xâu chuỗi nhiều phân phối trì hoãn với nhau; trong trường hợp này, đó là thời gian trì hoãn từ khi nhiễm trùng đến khi khởi phát triệu chứng (ví dụ: thời kỳ ủ bệnh, thường có khả năng biết) và từ khi bắt đầu có triệu chứng đến khi báo cáo ca bệnh (mà bạn có thể thường xuyên ước tính từ dữ liệu).
Vì chúng ta có ngày bắt đầu cho tất cả các trường hợp trong ví dụ của bộ dữ liệu linelist, chúng ta sẽ chỉ cần phân phối thời gian ủ bệnh để liên kết dữ liệu của chúng ta (ví dụ: ngày bắt đầu có triệu chứng) đến ngày nhiễm bệnh. Chúng ta có thể ước tính phân phối này từ dữ liệu hoặc sử dụng các giá trị từ y văn.
Tài liệu về ước tính thời gian ủ bệnh của Ebola (trích dẫn từ bài báo này) với giá trị trung bình là 9.1, độ lệch chuẩn là 7.3 và giá trị lớn nhất là 30 sẽ được chỉ định như sau:
incubation_period_lit <- list(
mean = log(9.1),
mean_sd = log(0.1),
sd = log(7.3),
sd_sd = log(0.1),
max = 30
)Lưu ý rằng package EpiNow2 yêu cầu các phân phối thời gian trì hoãn này phải được cung cấp trên thang đo log bằng cách dùng lệnh gọi log xung quanh mỗi giá trị (ngoại trừ tham số max, hơi rắc rối, cung cấp theo thang đo tự nhiên). mean_sd và sd_sd xác định độ lệch chuẩn của ước tính giá trị trung bình và độ lệch chuẩn. Vì chúng không được biết trong trường hợp này, chúng tôi chọn giá trị khá tùy ý là 0.1.
Trong phân tích này, thay vào đó, chúng ta ước tính phân phối thời gian ủ bệnh từ chính bộ dữ liệu linelist bằng cách sử dụng hàm bootstrapped_dist_fit, để fit một phân phối lognormal cho thời gian trì hoãn giữa nhiễm trùng và khởi phát quan sát được trong linelist.
## estimate incubation period
incubation_period <- bootstrapped_dist_fit(
linelist$date_onset - linelist$date_infection,
dist = "lognormal",
max_value = 100,
bootstraps = 1
)Phân phối khác mà chúng ta cần là thời gian phát sinh một thế hệ. Vì chúng ta có dữ liệu về thời gian nhiễm bệnh và đường lây truyền, chúng ta có thể ước tính phân phối này từ linelist bằng cách tính toán đỗ trễ giữa các lần lây nhiễm của các cặp người lây nhiễm-người bị lây nhiễm. Để làm điều này, chúng ta sử dụng hàm get_pairwise từ package epicontacts, cho phép chúng ta tính toán sự khác biệt từng cặp trường hợp lây nhiễm của linelist. Đầu tiên, chúng ta tạo một đối tượng epicontacts (xem chương Chuỗi lây nhiễm để biết thêm chi tiết):
## generate contacts
contacts <- linelist %>%
transmute(
from = infector,
to = case_id
) %>%
drop_na()
## generate epicontacts object
epic <- make_epicontacts(
linelist = linelist,
contacts = contacts,
directed = TRUE
)Sau đó, chúng ta fit một phân phối gamma cho sự khác biệt về thời gian nhiễm bệnh giữa các cặp lây nhiễm (được tính toán bằng cách sử dụng hàm get_pairwise)
## estimate gamma generation time
generation_time <- bootstrapped_dist_fit(
get_pairwise(epic, "date_infection"),
dist = "gamma",
max_value = 20,
bootstraps = 1
)Chạy EpiNow2
Bây giờ chúng ta chỉ cần tính toán số mới mắc hàng ngày từ linelist mà có thể thực hiện dễ dàng với các hàm group_by() và n() từ package dplyr. Lưu ý rằng EpiNow2 yêu cầu tên cột phải là date và confirm.
## get incidence from onset dates
cases <- linelist %>%
group_by(date = date_onset) %>%
summarise(confirm = n())Sau đó, chúng ta có thể ước tính Rt bằng cách sử dụng hàm epinow. Một vài lưu ý về các dữ liệu đầu vào:
- Chúng ta có thể cung cấp một số lượng bất kỳ các ‘chuỗi’ phân phối thời gian trì hoãn tới đối số
delays; chúng ta chỉ cần chèn chúng cùng với đối tượngincubation_periodbên trong hàmdelay_opts. return_outputđảm bảo đầu ra được trả về trong R chứ không chỉ được lưu vào một tệp.verbosenếu chúng ta muốn đọc tiến trình.horizonđể yêu cầu hiển thị số ngày chúng ta muốn tính số mới mắc trong tương lai- Chúng ta chuyển các tùy chọn bổ sung cho đối số
stanđể chỉ định cách chúng ta muốn chạy suy luận. Tăng số lượng mẫusamplesvà chuỗichainsẽ cung cấp cho bạn một ước tính chính xác hơn với những phẩm chất tốt hơn cho sự không chắc chắn, tuy nhiên sẽ mất nhiều thời gian hơn để chạy.
## run epinow
epinow_res <- epinow(
reported_cases = cases,
generation_time = generation_time,
delays = delay_opts(incubation_period),
return_output = TRUE,
verbose = TRUE,
horizon = 21,
stan = stan_opts(samples = 750, chains = 4)
)Phân tích kết quả đầu ra
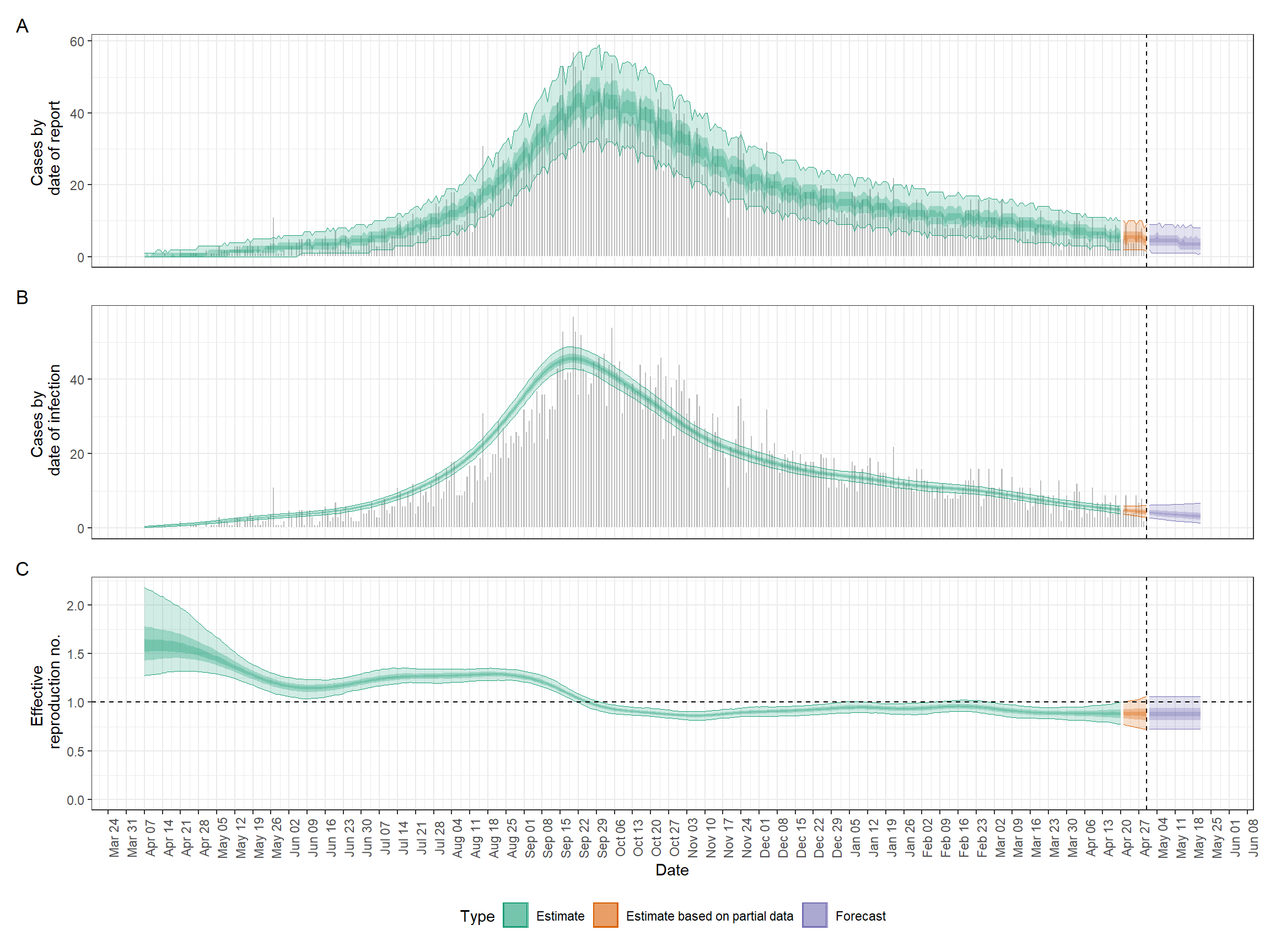
Khi code đã chạy xong, chúng ta có thể vẽ biểu đồ tóm tắt rất dễ dàng như sau. Cuộn hình ảnh để xem toàn bộ.
## plot summary figure
plot(epinow_res)
Chúng ta cũng có thể xem xét các thống kê tóm tắt khác nhau:
## summary table
epinow_res$summary measure estimate
<char> <char>
1: New confirmed cases by infection date 4 (2 -- 6)
2: Expected change in daily cases Unsure
3: Effective reproduction no. 0.88 (0.73 -- 1.1)
4: Rate of growth -0.012 (-0.028 -- 0.0052)
5: Doubling/halving time (days) -60 (130 -- -25)
numeric_estimate
<list>
1: <data.table[1x9]>
2: 0.56
3: <data.table[1x9]>
4: <data.table[1x9]>
5: <data.table[1x9]>Để có các phân tích sâu hơn và vẽ biểu đồ tùy chỉnh, bạn có thể truy cập vào phần ước tính hàng ngày tổng hợp thông qua $estimates$summarised. Chúng ta sẽ chuyển nó từ định dạng mặc định data.table thành định dạng tibble để dễ dàng sử dụng với package dplyr.
## extract summary and convert to tibble
estimates <- as_tibble(epinow_res$estimates$summarised)
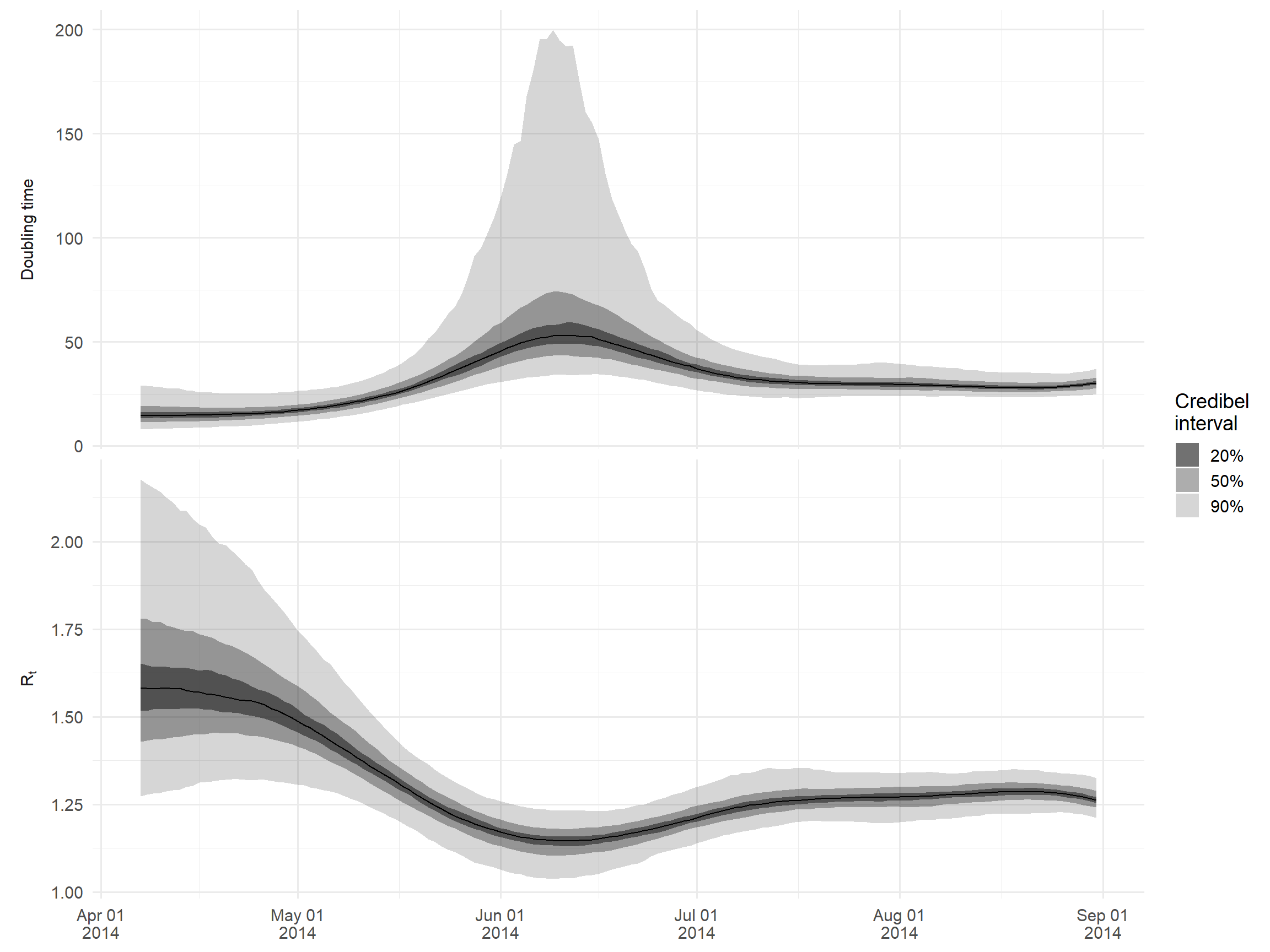
estimatesĐể ví dụ, chúng ta hãy vẽ một biểu đồ về thời gian nhân đôi và Rt. Chúng ta sẽ chỉ xem xét vài tháng đầu tiên của đợt bùng phát khi Rt chỉ cao hơn một, để tránh vẽ biểu đồ số lần nhân đôi quá cao.
Chúng ta sử dụng công thức log(2)/growth_rate để tính thời gian nhân đôi từ tốc độ tăng trưởng ước tính.
## make wide df for median plotting
df_wide <- estimates %>%
filter(
variable %in% c("growth_rate", "R"),
date < as.Date("2014-09-01")
) %>%
## convert growth rates to doubling times
mutate(
across(
c(median, lower_90:upper_90),
~ case_when(
variable == "growth_rate" ~ log(2)/.x,
TRUE ~ .x
)
),
## rename variable to reflect transformation
variable = replace(variable, variable == "growth_rate", "doubling_time")
)
## make long df for quantile plotting
df_long <- df_wide %>%
## here we match matching quantiles (e.g. lower_90 to upper_90)
pivot_longer(
lower_90:upper_90,
names_to = c(".value", "quantile"),
names_pattern = "(.+)_(.+)"
)
## make plot
ggplot() +
geom_ribbon(
data = df_long,
aes(x = date, ymin = lower, ymax = upper, alpha = quantile),
color = NA
) +
geom_line(
data = df_wide,
aes(x = date, y = median)
) +
## use label_parsed to allow subscript label
facet_wrap(
~ variable,
ncol = 1,
scales = "free_y",
labeller = as_labeller(c(R = "R[t]", doubling_time = "Doubling~time"), label_parsed),
strip.position = 'left'
) +
## manually define quantile transparency
scale_alpha_manual(
values = c(`20` = 0.7, `50` = 0.4, `90` = 0.2),
labels = function(x) paste0(x, "%")
) +
labs(
x = NULL,
y = NULL,
alpha = "Credibel\ninterval"
) +
scale_x_date(
date_breaks = "1 month",
date_labels = "%b %d\n%Y"
) +
theme_minimal(base_size = 14) +
theme(
strip.background = element_blank(),
strip.placement = 'outside'
)
EpiEstim
Để chạy EpiEstim, chúng ta cần cung cấp dữ liệu về số trường hợp mới mắc hàng ngày và cụ thể khoảng thời gian nối tiếp (tức là phân bố thời gian trì hoãn khởi phát triệu chứng giữa các trường hợp sơ cấp và thứ cấp).
Dữ liệu về con số mới mắc có thể được cung cấp cho EpiEstim dưới dạng một vectơ, một bảng số liệu, hoặc một đối tượng incidence nguyên bản từ package incidence. Bạn thậm chí có thể phân biệt giữa ca nhiễm bệnh từ nơi khác đến và tại địa phương; xem tài liệu hướng dẫn bằng cách gõ ?estimate_R để biết thêm chi tiết.
Chúng ta sẽ tạo dữ liệu đầu vào bằng cách sử dụng package incidence2. Xem chương Đường cong dịch bệnh để xem thêm các ví dụ về package incidence2. Do có một số cập nhật của package incidence2 khiến nó không hoàn toàn phù hợp với đầu vào kỳ vọng của hàm estimateR(), bạn cần thực hiện một số bước bổ sung cần thiết. Đối tượng incidence bao gồm một tibble với thông tin về ngày tháng và số lượng trường hợp tương ứng. Chúng ta sử dụng hàm complete() từ package tidyr để đảm bảo tất cả các ngày đều được bao gồm (kể cả những ngày không có trường hợp), và sau đó dùng hàm rename() để đổi tên các cột để căn chỉnh sao cho phù hợp với hàm estimate_R() ở bước sau.
## get incidence from onset date
cases <- incidence2::incidence(linelist, date_index = "date_onset") %>% # get case counts by day
tidyr::complete(date_index = seq.Date( # ensure all dates are represented
from = min(date_index, na.rm = T),
to = max(date_index, na.rm=T),
by = "day"),
fill = list(count = 0)) %>% # convert NA counts to 0
rename(I = count, # rename to names expected by estimateR
dates = date_index)Package này cung cấp một số tùy chọn để cụ thể khoảng thời gian nối tiếp, chi tiết được cung cấp trong tài liệu hướng dẫn bằng cách gõ ?estimate_R. Chúng tôi sẽ đề cập đến hai trong số chúng ở đây.
Sử dụng ước tính khoảng thời gian nối tiếp từ y văn
Sử dụng tùy chọn method = "parametric_si", chúng ta có thể chỉ định thủ công trung bình và độ lệch chuẩn của khoảng thời gian nối tiếp của đối tượng config được tạo bằng hàm make_config. Chúng ta sử dụng giá trị trung bình và độ lệch chuẩn tương ứng là 12.0 và 5.2, được xác định trong bài báo này:
## make config
config_lit <- make_config(
mean_si = 12.0,
std_si = 5.2
)Sau đó, chúng ta có thể ước tính Rt bằng hàm estimate_R:
cases <- cases %>%
filter(!is.na(date))
#create a dataframe for the function estimate_R()
cases_incidence <- data.frame(dates = seq.Date(from = min(cases$dates),
to = max(cases$dates),
by = 1))
cases_incidence <- left_join(cases_incidence, cases) %>%
select(dates, I) %>%
mutate(I = ifelse(is.na(I), 0, I))Joining with `by = join_by(dates)`epiestim_res_lit <- estimate_R(
incid = cases_incidence,
method = "parametric_si",
config = config_lit
)Default config will estimate R on weekly sliding windows.
To change this change the t_start and t_end arguments. và vẽ tóm tắt các kết quả đầu ra:
plot(epiestim_res_lit)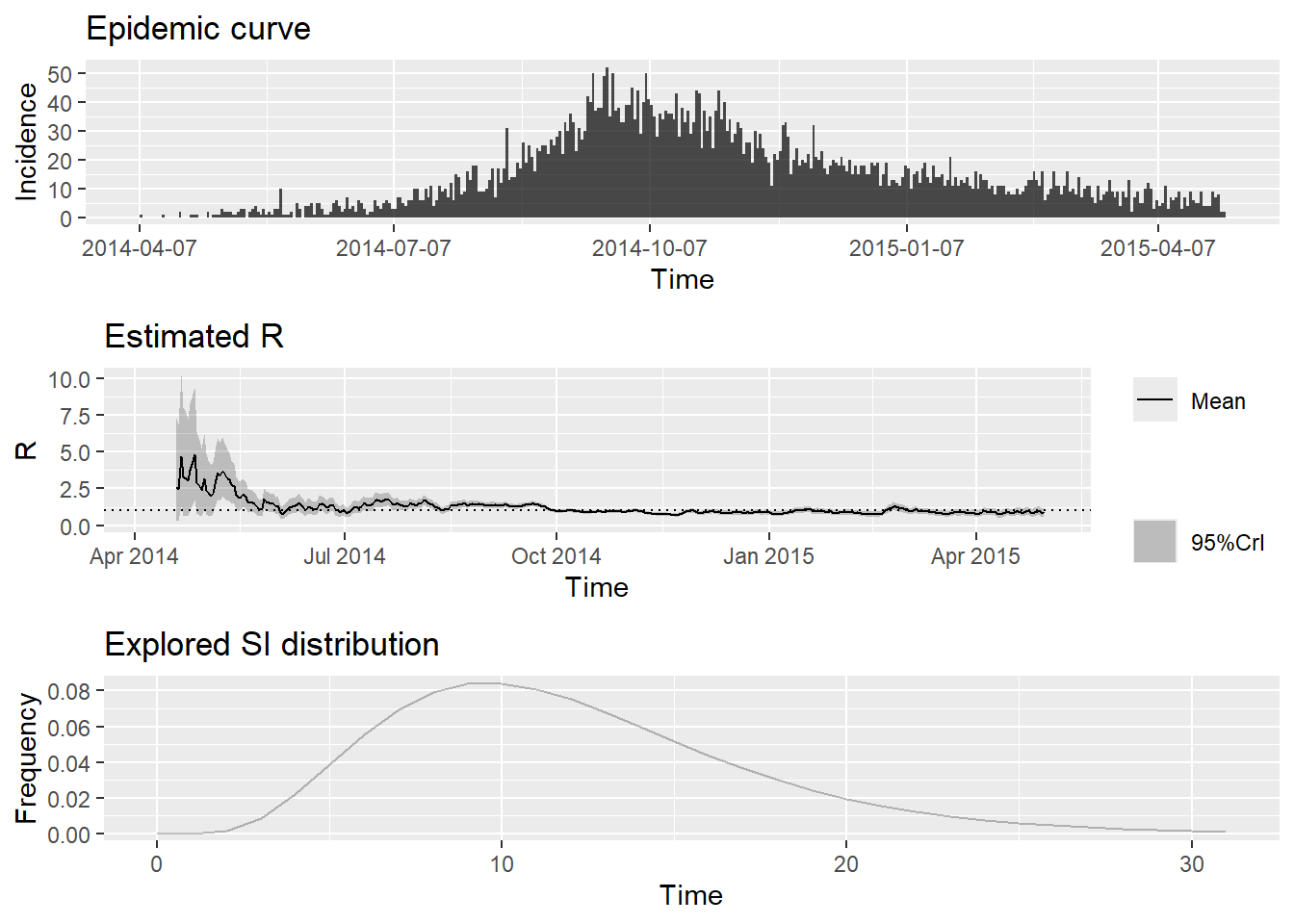
Sử dụng ước tính khoảng thời gian nối tiếp từ dữ liệu
Vì chúng ta có dữ liệu về ngày khởi phát triệu chứng và các liên kết lây truyền, chúng ta cũng có thể ước tính khoảng thời gian nối tiếp từ bộ số liệu linelist bằng cách tính toán độ trễ giữa ngày khởi phát của các cặp người truyền bệnh-người nhiễm bệnh. Như chúng ta đã làm trong mục EpiNow2, chúng ta sẽ sử dụng hàm get_pairwise từ package epicontacts, cho phép chúng ta tính toán theo từng cặp sự khác biệt giữa các cặp lây truyền trong bộ số liệu linelist. Chúng ta trước hết tạo một đối tượng epicontacts (xem chương Chuỗi lây nhiễm để biết thêm chi tiết):
## generate contacts
contacts <- linelist %>%
transmute(
from = infector,
to = case_id
) %>%
drop_na()
## generate epicontacts object
epic <- make_epicontacts(
linelist = linelist,
contacts = contacts,
directed = TRUE
)Sau đó, chúng ta fit một phân phối gamma cho sự khác biệt về ngày khởi phát giữa các cặp lây truyền (được tính toán bằng hàm get_pairwise). Chúng ta sử dụng hàm fit_disc_gamma từ package epitrix cho quy trình kết hợp này, vì chúng ta yêu cầu một phân phối rời rạc (discretised).
## estimate gamma serial interval
serial_interval <- fit_disc_gamma(get_pairwise(epic, "date_onset"))Sau đó, chúng ta chuyển thông tin này đến đối tượng config, và chạy EpiEstim một lần nữa và vẽ biểu đồ kết quả:
## make config
config_emp <- make_config(
mean_si = serial_interval$mu,
std_si = serial_interval$sd
)
## run epiestim
epiestim_res_emp <- estimate_R(
incid = cases_incidence,
method = "parametric_si",
config = config_emp
)Default config will estimate R on weekly sliding windows.
To change this change the t_start and t_end arguments. ## plot outputs
plot(epiestim_res_emp)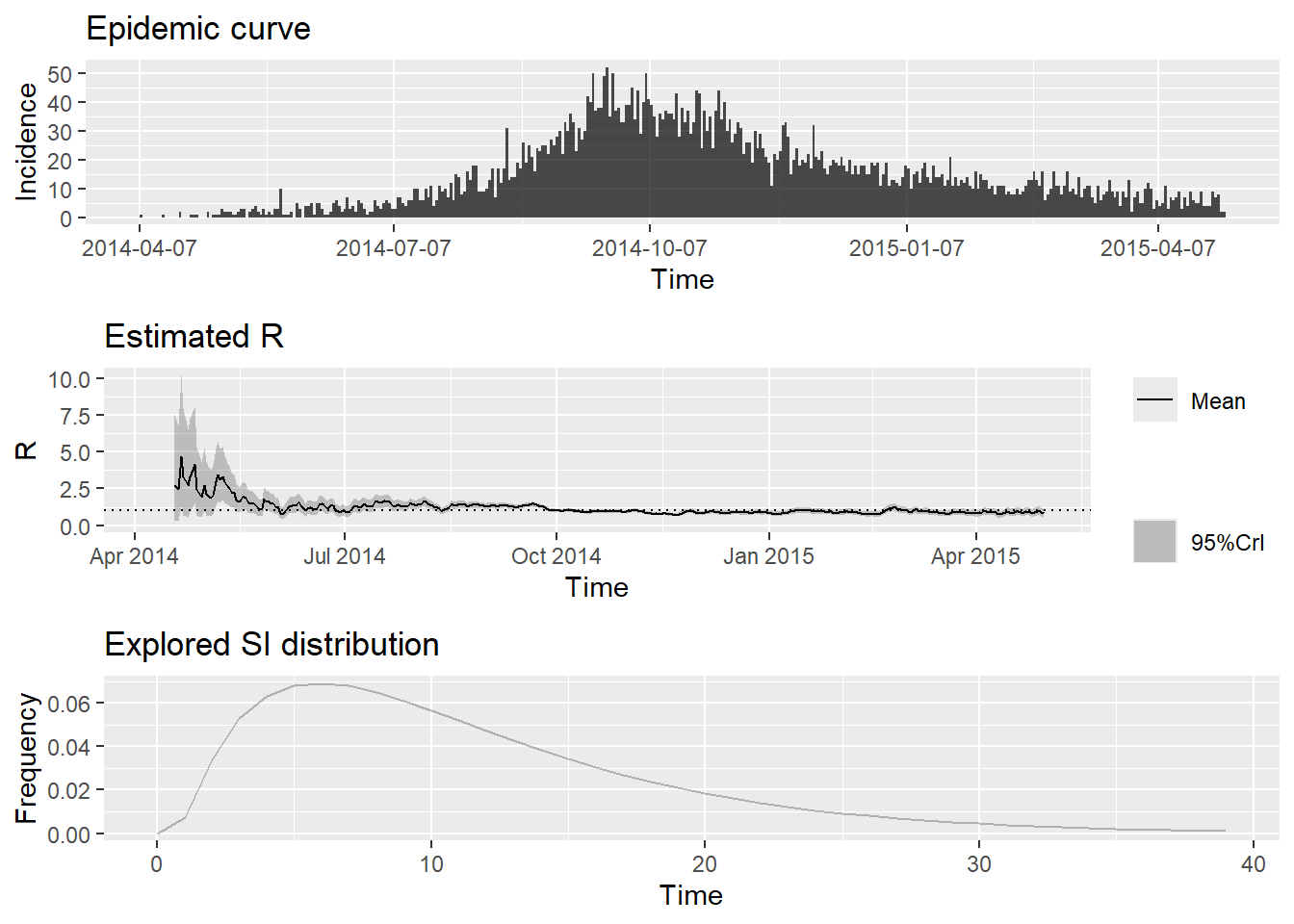
Cụ thể thời gian bắt đầu ước tính
Các tùy chọn mặc định này sẽ cung cấp một ước tính theo tuần và có thể hoạt động như một cảnh báo rằng bạn đang ước tính Rt quá sớm trong đợt bùng phát để có một ước tính chính xác. Bạn có thể thay đổi điều này bằng cách đặt ngày bắt đầu ước tính muộn hơn như dưới đây. Thật không may, EpiEstim chỉ cung cấp một cách rất khó hiểu để cụ thể thời gian ước tính này, trong đó bạn phải cung cấp một vectơ số nguyên đề cập đến ngày bắt đầu và ngày kết thúc cho mỗi cửa sổ thời gian.
## define a vector of dates starting on June 1st
start_dates <- seq.Date(
as.Date("2014-06-01"),
max(cases$dates) - 7,
by = 1
) %>%
## subtract the starting date to convert to numeric
`-`(min(cases$dates)) %>%
## convert to integer
as.integer()
## add six days for a one week sliding window
end_dates <- start_dates + 6
## make config
config_partial <- make_config(
mean_si = 12.0,
std_si = 5.2,
t_start = start_dates,
t_end = end_dates
)Bây giờ chúng ta chạy lại EpiEstim và có thể thấy rằng các ước tính chỉ bắt đầu từ tháng 6:
## run epiestim
epiestim_res_partial <- estimate_R(
incid = cases_incidence,
method = "parametric_si",
config = config_partial
)
## plot outputs
plot(epiestim_res_partial)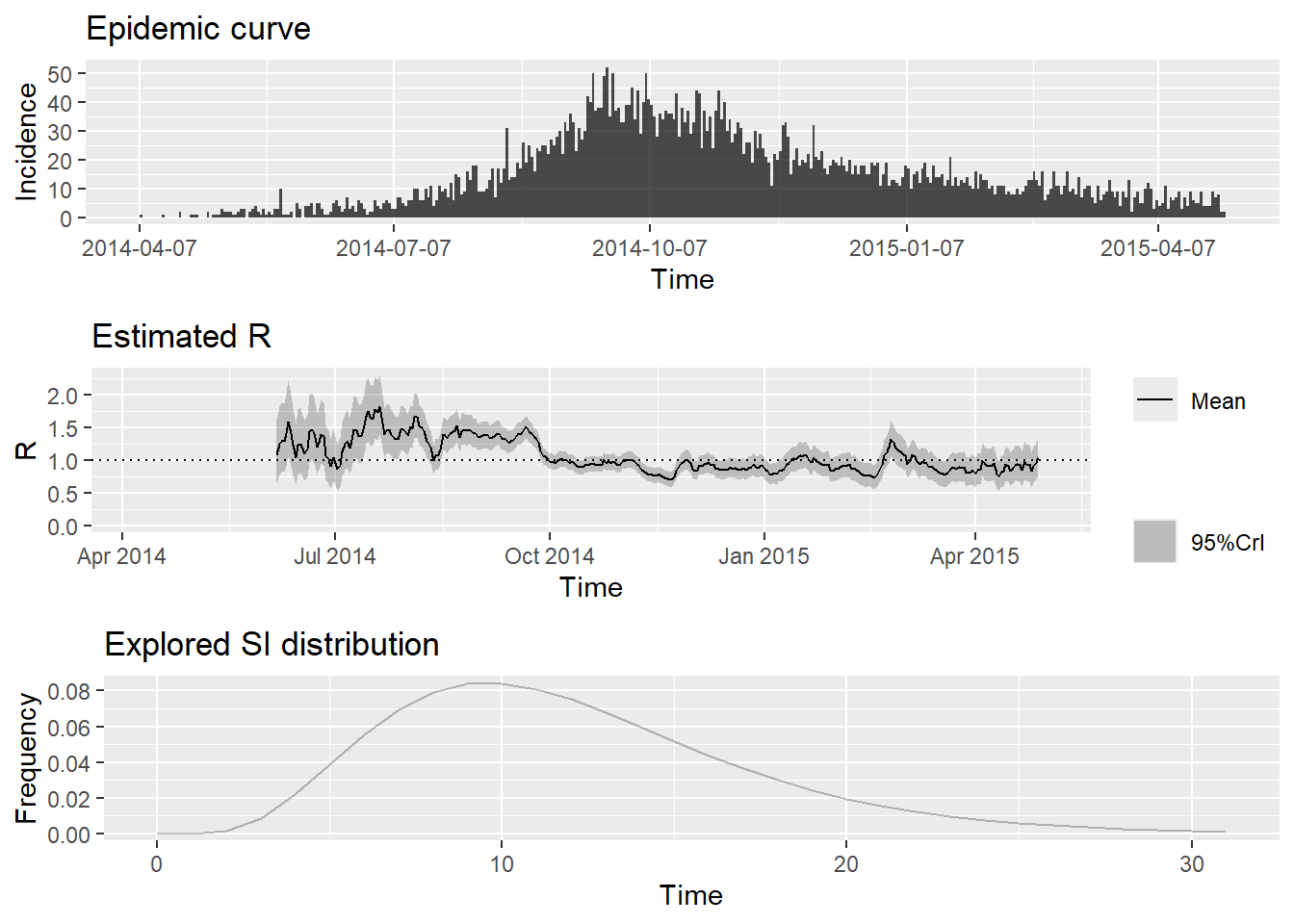
Phân tích kết quả đầu ra
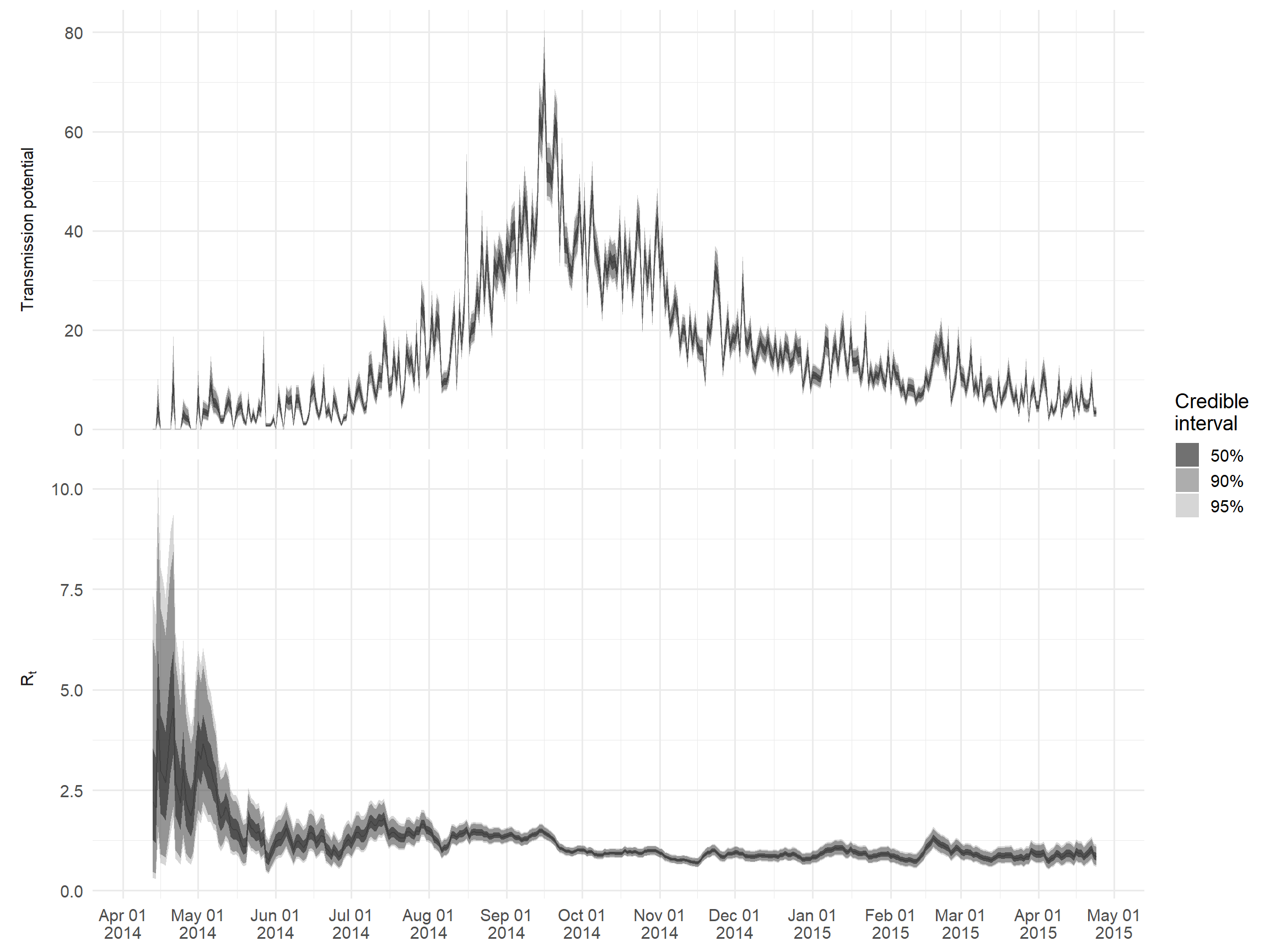
Các đầu ra chính có thể được truy cập thông qua $R. Ví dụ: chúng ta sẽ tạo một biểu đồ của Rt và một thước đo “khả năng truyền bệnh” được đưa ra bởi sản phẩm của Rt và số trường hợp được báo cáo vào ngày đó; điều này thể hiện số trường hợp dự kiến trong thế hệ lây nhiễm tiếp theo.
## make wide dataframe for median
df_wide <- epiestim_res_lit$R %>%
rename_all(clean_labels) %>%
rename(
lower_95_r = quantile_0_025_r,
lower_90_r = quantile_0_05_r,
lower_50_r = quantile_0_25_r,
upper_50_r = quantile_0_75_r,
upper_90_r = quantile_0_95_r,
upper_95_r = quantile_0_975_r,
) %>%
mutate(
## extract the median date from t_start and t_end
dates = epiestim_res_emp$dates[round(map2_dbl(t_start, t_end, median))],
var = "R[t]"
) %>%
## merge in daily incidence data
left_join(cases, "dates") %>%
## calculate risk across all r estimates
mutate(
across(
lower_95_r:upper_95_r,
~ .x*I,
.names = "{str_replace(.col, '_r', '_risk')}"
)
) %>%
## seperate r estimates and risk estimates
pivot_longer(
contains("median"),
names_to = c(".value", "variable"),
names_pattern = "(.+)_(.+)"
) %>%
## assign factor levels
mutate(variable = factor(variable, c("risk", "r")))
## make long dataframe from quantiles
df_long <- df_wide %>%
select(-variable, -median) %>%
## seperate r/risk estimates and quantile levels
pivot_longer(
contains(c("lower", "upper")),
names_to = c(".value", "quantile", "variable"),
names_pattern = "(.+)_(.+)_(.+)"
) %>%
mutate(variable = factor(variable, c("risk", "r")))
## make plot
ggplot() +
geom_ribbon(
data = df_long,
aes(x = dates, ymin = lower, ymax = upper, alpha = quantile),
color = NA
) +
geom_line(
data = df_wide,
aes(x = dates, y = median),
alpha = 0.2
) +
## use label_parsed to allow subscript label
facet_wrap(
~ variable,
ncol = 1,
scales = "free_y",
labeller = as_labeller(c(r = "R[t]", risk = "Transmission~potential"), label_parsed),
strip.position = 'left'
) +
## manually define quantile transparency
scale_alpha_manual(
values = c(`50` = 0.7, `90` = 0.4, `95` = 0.2),
labels = function(x) paste0(x, "%")
) +
labs(
x = NULL,
y = NULL,
alpha = "Credible\ninterval"
) +
scale_x_date(
date_breaks = "1 month",
date_labels = "%b %d\n%Y"
) +
theme_minimal(base_size = 14) +
theme(
strip.background = element_blank(),
strip.placement = 'outside'
)
24.4 Dự đoán số trường hợp mắc mới
EpiNow2
Bên cạnh ước tính Rt, package EpiNow2 cũng hỗ trợ dự báo Rt và dự báo các số trường hợp bằng cách tích hợp với package EpiSoon. Tất cả những gì bạn cần làm là chỉ định đối số horizon trong hàm epinow của bạn, cho biết số ngày bạn muốn dự báo trong tương lai; xem phần EpiNow2 trong mục “Ước tính Rt” để biết chi tiết về cách thiết lập và chạy EpiNow2. Trong phần này, chúng ta sẽ chỉ vẽ các kết quả đầu ra từ phân tích đó, được lưu trữ trong đối tượng epinow_res.
## define minimum date for plot
min_date <- as.Date("2015-03-01")
## extract summarised estimates
estimates <- as_tibble(epinow_res$estimates$summarised)
## extract raw data on case incidence
observations <- as_tibble(epinow_res$estimates$observations) %>%
filter(date > min_date)
## extract forecasted estimates of case numbers
df_wide <- estimates %>%
filter(
variable == "reported_cases",
type == "forecast",
date > min_date
)
## convert to even longer format for quantile plotting
df_long <- df_wide %>%
## here we match matching quantiles (e.g. lower_90 to upper_90)
pivot_longer(
lower_90:upper_90,
names_to = c(".value", "quantile"),
names_pattern = "(.+)_(.+)"
)
## make plot
ggplot() +
geom_histogram(
data = observations,
aes(x = date, y = confirm),
stat = 'identity',
binwidth = 1
) +
geom_ribbon(
data = df_long,
aes(x = date, ymin = lower, ymax = upper, alpha = quantile),
color = NA
) +
geom_line(
data = df_wide,
aes(x = date, y = median)
) +
geom_vline(xintercept = min(df_long$date), linetype = 2) +
## manually define quantile transparency
scale_alpha_manual(
values = c(`20` = 0.7, `50` = 0.4, `90` = 0.2),
labels = function(x) paste0(x, "%")
) +
labs(
x = NULL,
y = "Daily reported cases",
alpha = "Credible\ninterval"
) +
scale_x_date(
date_breaks = "1 month",
date_labels = "%b %d\n%Y"
) +
theme_minimal(base_size = 14)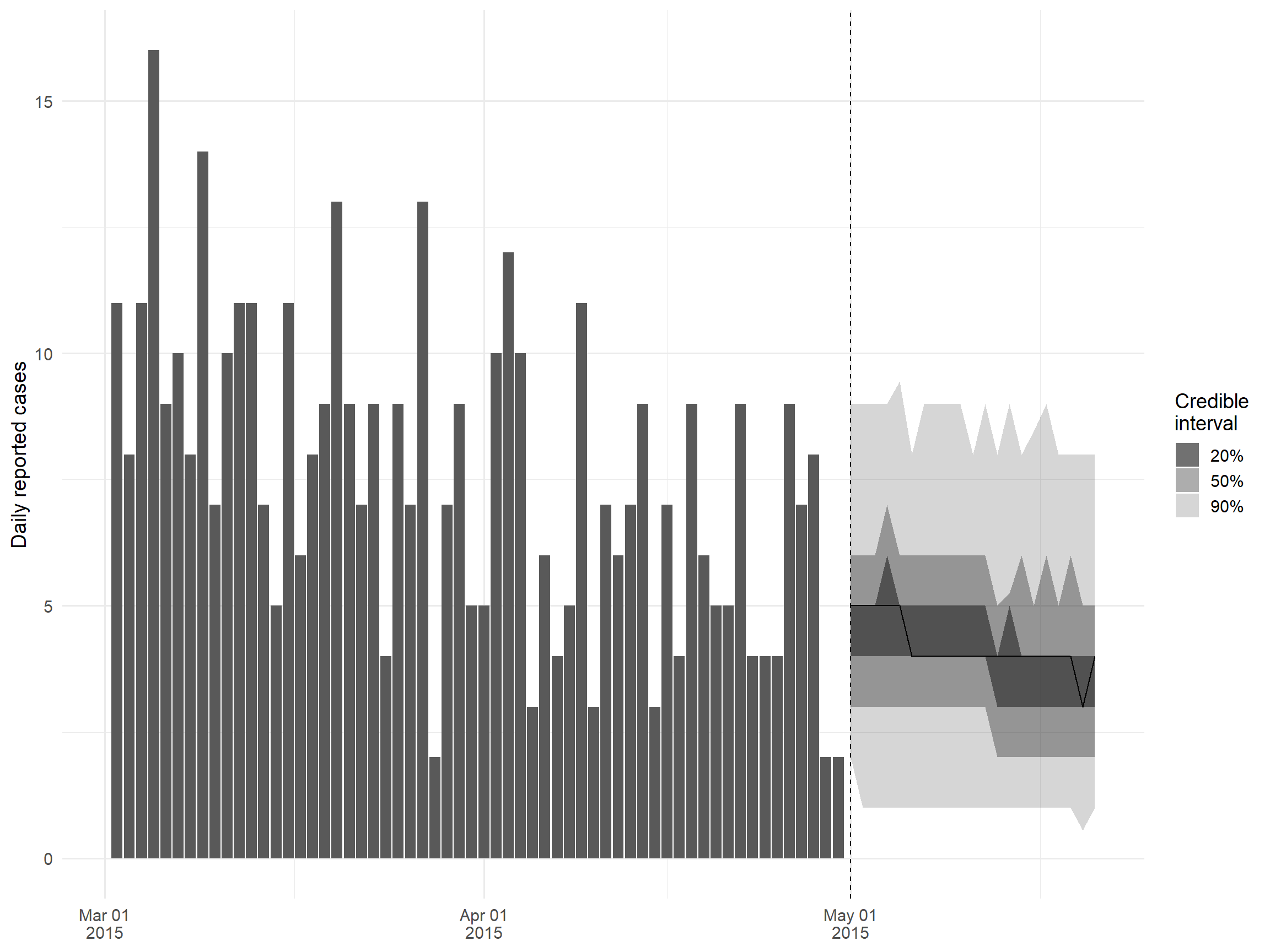
Dự đoán
Package projections do RECON phát triển giúp bạn dễ dàng đưa ra dự báo số trường hợp mắc mới trong ngắn hạn, chỉ yêu cầu kiến thức về hệ số lây nhiễm hiệu quả Rt và khoảng thời gian nối tiếp. Ở đây chúng tôi sẽ trình bày cách sử dụng ước tính khoảng thời gian nối tiếp từ y văn và từ ước tính của riêng chúng ta từ dữ liệu linelist.
Sử dụng ước tính khoảng thời gian nối tiếp từ y văn
projections yêu cầu một phân phối rời rạc của khoảng thời gian nối tiếp của class distcrete từ package distcrete. Chúng ta sẽ sử dụng phân phối gamma với giá trị trung bình là 12.0 và và độ lệch chuẩn là 5.2 được lấy từ bài báo này. Để chuyển đổi các giá trị này thành các tham số shape và scale cần thiết cho phân phối gamma, chúng ta sẽ sử dụng hàm gamma_mucv2shapescale từ package epitrix.
## get shape and scale parameters from the mean mu and the coefficient of
## variation (e.g. the ratio of the standard deviation to the mean)
shapescale <- epitrix::gamma_mucv2shapescale(mu = 12.0, cv = 5.2/12)
## make distcrete object
serial_interval_lit <- distcrete::distcrete(
name = "gamma",
interval = 1,
shape = shapescale$shape,
scale = shapescale$scale
)Sau đây là một cách kiểm tra nhanh để đảm bảo rằng khoảng thời gian nối tiếp chính xác. Chúng ta truy cập mật độ của phân phối gamma mà chúng ta vừa xác định thông qua $d, tương đương với cách gọi dgamma:
## check to make sure the serial interval looks correct
qplot(
x = 0:50, y = serial_interval_lit$d(0:50), geom = "area",
xlab = "Serial interval", ylab = "Density"
)Warning: `qplot()` was deprecated in ggplot2 3.4.0.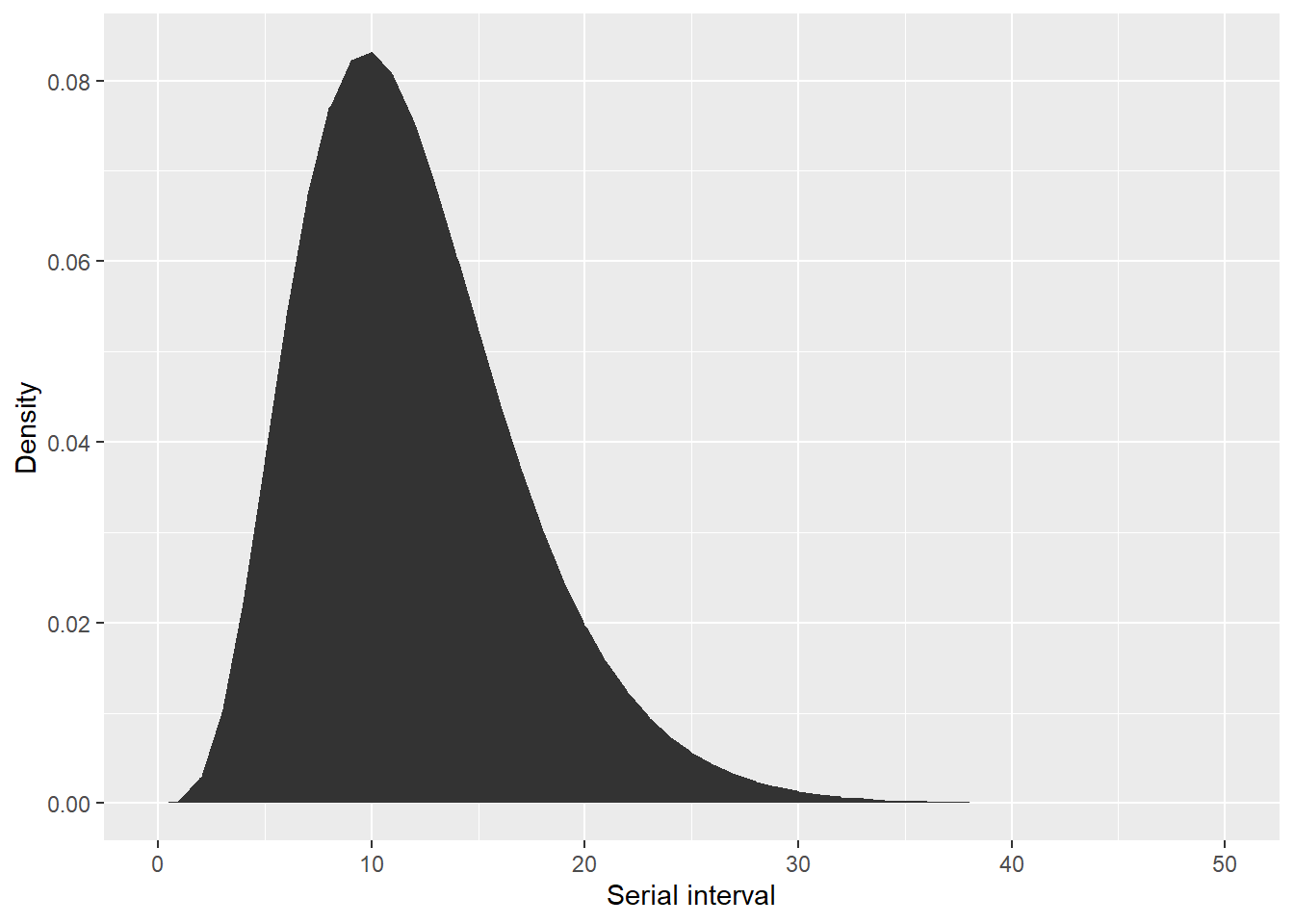
Sử dụng ước tính khoảng thời gian nối tiếp từ dữ liệu
Vì chúng ta có dữ liệu về ngày khởi phát triệu chứng và các liên kết lây truyền, chúng ta cũng có thể ước tính khoảng thời gian nối tiếp từ bộ số liệu linelist bằng cách tính toán độ trễ giữa ngày khởi phát của các cặp người truyền bệnh-người nhiễm bệnh. Như chúng ta đã làm trong mục EpiNow2, chúng ta sẽ sử dụng hàm get_pairwise từ package epicontacts, cho phép chúng ta tính toán theo từng cặp sự khác biệt giữa các cặp lây truyền trong bộ số liệu linelist. Chúng ta trước hết tạo một đối tượng epicontacts (xem chương Chuỗi lây nhiễm để biết thêm chi tiết):
## generate contacts
contacts <- linelist %>%
transmute(
from = infector,
to = case_id
) %>%
drop_na()
## generate epicontacts object
epic <- make_epicontacts(
linelist = linelist,
contacts = contacts,
directed = TRUE
)Sau đó, chúng ta fit một phân phối gamma cho sự khác biệt về ngày khởi phát giữa các cặp lây truyền (được tính toán bằng hàm get_pairwise). Chúng ta sử dụng hàm fit_disc_gamma từ package epitrix cho quy trình kết hợp này, vì chúng ta yêu cầu một phân phối rời rạc (discretised).
## estimate gamma serial interval
serial_interval <- fit_disc_gamma(get_pairwise(epic, "date_onset"))
## inspect estimate
serial_interval[c("mu", "sd")]$mu
[1] 11.51047
$sd
[1] 7.696056Dự đoán số trường hợp mắc mới
Để dự đoán số mắc mới trong tương lai, chúng ta vẫn cần cung cấp lịch sử số mới mắc dưới dạng một đối tượng incidence, cũng như một mẫu các giá trị Rt khả dĩ. Chúng ta sẽ tạo các giá trị này bằng cách sử dụng ước tính Rt được sinh ra bởi EpiEstim trong phần trước (trong mục “Ước tính Rt”) và được lưu trữ trong đối tượng epiestim_res_emp. Trong đoạn code dưới đây, chúng ta trích xuất các ước tính trung bình và độ lệch chuẩn của Rt cho khoảng thời gian cửa sổ cuối cùng của đợt bùng phát (sử dụng hàm tail để truy cập giá trị cuối cùng trong một vectơ) và mô phỏng 1000 giá trị từ phân phối gamma bằng cách sử dụng hàm rgamma. Bạn cũng có thể cung cấp vectơ của các giá trị Rt của riêng mình mà bạn muốn sử dụng để dự báo.
## create incidence object from dates of onset
inc <- incidence::incidence(linelist$date_onset)256 missing observations were removed.## extract plausible r values from most recent estimate
mean_r <- tail(epiestim_res_emp$R$`Mean(R)`, 1)
sd_r <- tail(epiestim_res_emp$R$`Std(R)`, 1)
shapescale <- gamma_mucv2shapescale(mu = mean_r, cv = sd_r/mean_r)
plausible_r <- rgamma(1000, shape = shapescale$shape, scale = shapescale$scale)
## check distribution
qplot(x = plausible_r, geom = "histogram", xlab = expression(R[t]), ylab = "Counts")`stat_bin()` using `bins = 30`. Pick better value with `binwidth`.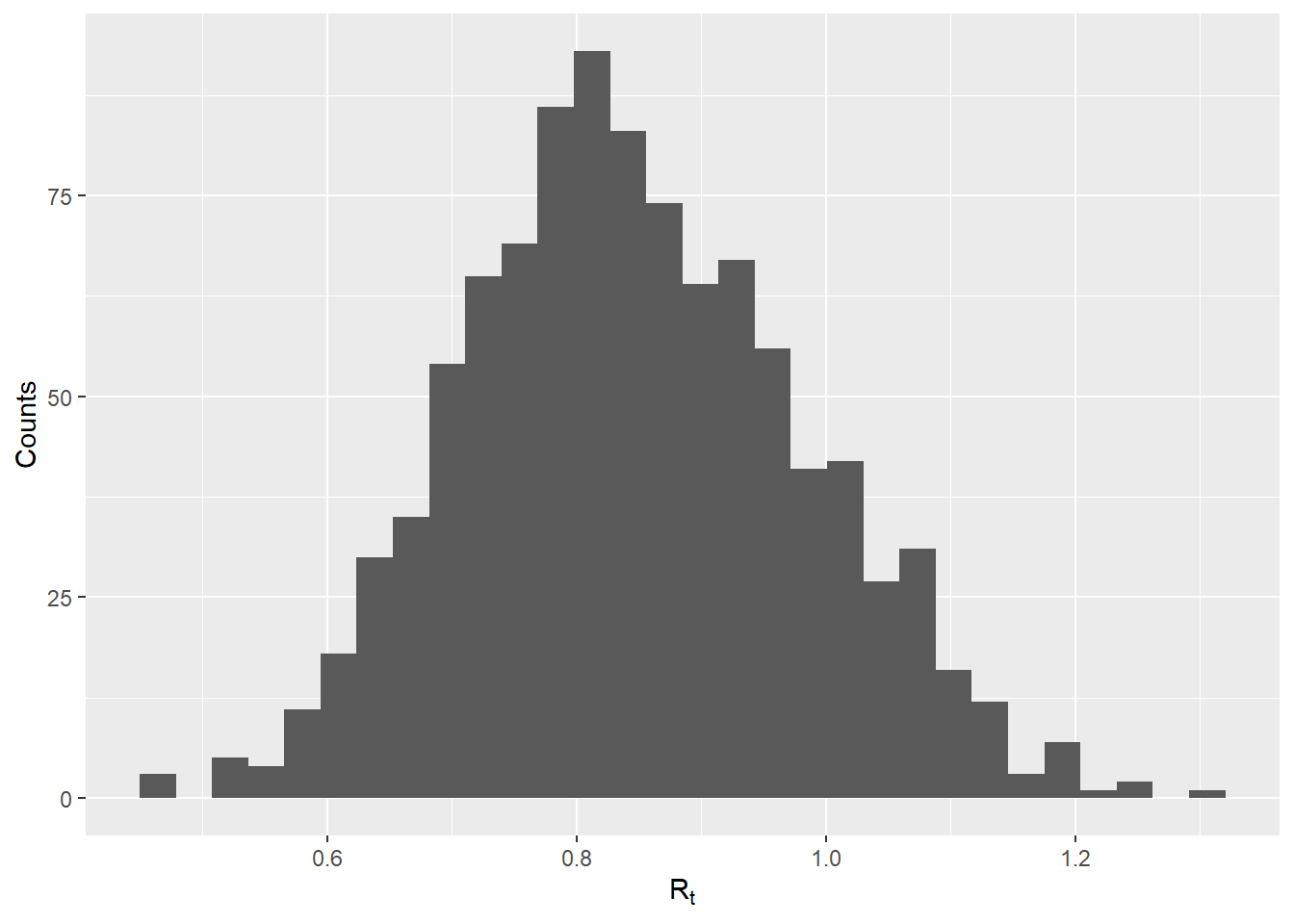
Sau đó, chúng ta sử dụng hàm project() để đưa ra dự báo thực tế. Chúng ta cụ thể số ngày chúng ta muốn dự báo qua đối số n_days và chỉ định số lượng mô phỏng bằng cách sử dụng đối số n_sim.
## make projection
proj <- project(
x = inc,
R = plausible_r,
si = serial_interval$distribution,
n_days = 21,
n_sim = 1000
)Sau đó, chúng ta có thể vẽ biểu đồ số trường hợp mắc mới và số dự báo bằng cách sử dụng các hàm plot() và add_projections(). Chúng ta có thể dễ dàng lấy tập con của đối tượng incidence để chỉ hiển thị các trường hợp gần đây nhất bằng cách sử dụng toán tử dấu ngoặc vuông.
## plot incidence and projections
plot(inc[inc$dates > as.Date("2015-03-01")]) %>%
add_projections(proj)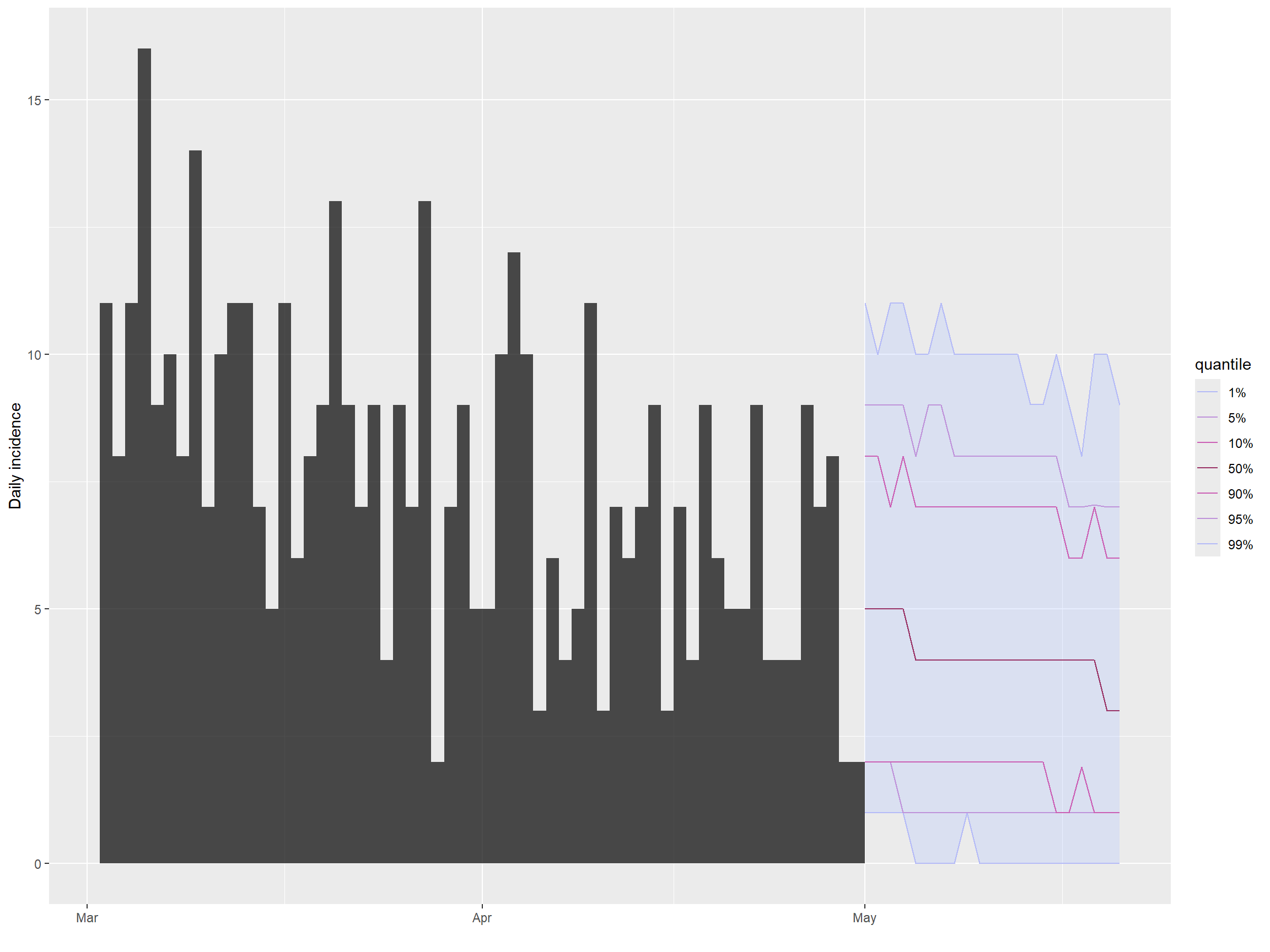
Bạn cũng có thể dễ dàng trích xuất các ước tính thô của số trường hợp hàng ngày bằng cách chuyển đổi đầu ra thành một dataframe.
## convert to data frame for raw data
proj_df <- as.data.frame(proj)
proj_df24.5 Tài liệu tham khảo
- Bài báo này mô tả phương pháp được thực hiện trong EpiEstim.
- Bài báo này mô tả phương pháp được thực hiện trong EpiNow2.
- Bài báo này mô tả các cân nhắc phương pháp luận và thực tế khác nhau để ước tính Rt.