# install the latest version of the Epi R Handbook package
pacman::p_install_gh("appliedepi/epirhandbook")2 Tải sách và dữ liệu
2.1 Tải sách ngoại tuyến
Bạn có thể tải xuống phiên bản ngoại tuyến của sổ tay này dưới dạng tệp HTML để có thể xem trong trình duyệt web của mình ngay cả khi bạn không có kết nối internet. Nếu bạn đang cân nhắc việc sử dụng ngoại tuyến Sổ tay Epi R, dưới đây là một số điều bạn cần cân nhắc:
- Khi bạn mở tệp, có thể mất một đến hai phút để tải các hình ảnh và mục lục
- Phiên bản ngoại tuyến có bố cục hơi khác so với phiên bản trực tuyến - là một trang rất dài với Mục lục ở phía bên trái. Để tìm kiếm các cụm từ cụ thể, hãy sử dụng Ctrl + F (Cmd-f)
- Xem chương Package đề xuất để hỗ trợ bạn cài đặt các R package thích hợp trước khi bạn mất kết nối internet
- Cài đặt package epirhandbook của chúng tôi trong đó chứa tất cả các dữ liệu minh họa (quy trình cài đặt được mô tả bên dưới)
Có hai cách bạn có thể tải xuống sổ tay:
Sử dụng link download
Để truy cập nhanh, nháy phải chuột vào link này và lựa chọn “Save link as”.
Nếu trên máy Mac, hãy sử dụng Cmd + Nhấp chuột. Nếu trên điện thoại di động, hãy bấm và giữ liên kết và chọn “Save link”. Sổ tay sẽ tải xuống thiết bị của bạn. Nếu trên màn hình xuất hiện mã HTML gốc, hãy đảm bảo bạn đã làm đúng theo các hướng dẫn bên trên hoặc thử Phương án 2.
Sử dụng package của chúng tôi
Chúng tôi cung cấp một R package có tên là epirhandbook. Nó bao gồm một hàm có tên download_book() giúp bạn tải xuống sổ tay này từ kho Github của chúng tôi vào máy tính của bạn.
Package này cũng chứa hàm get_data() giúp tải xuống toàn bộ các dữ liệu minh họa vào máy tính của bạn.
Chạy dòng code sau để cài đặt package epirhandbook từ Github repository appliedepi. Đây không phải là package thuộc CRAN, do đó cần sử dụng hàm đặc biệt p_install_gh() để cài đặt nó từ Github.
Bây giờ, bạn gọi package để sử dụng cho phiên làm việc R hiện tại:
# load the package for use
pacman::p_load(epirhandbook)Tiếp theo, bạn chạy hàm download_book() (phần trong ngoặc bỏ trống) để tải sổ tay vào máy tính của bạn. Nếu bạn sử dụng RStudio, một cửa sổ sẽ xuất hiện cho phép bạn lựa chọn thư mục lưu trữ.
# download the offline handbook to your computer
download_book()2.2 Tải dữ liệu xuống để tiện theo dõi
Để “tiện theo dõi” cùng với sổ tay này, bạn có thể tải xuống các bộ dữ liệu minh họa và các kết quả.
Sử dụng package của chúng tôi
Cách dễ nhất để tải xuống tất cả dữ liệu là cài đặt package epirhandbook của chúng tôi. Nó chứa hàm get_data() giúp lưu toàn bộ dữ liệu minh họa vào một thư mục bạn chọn trên máy tính của mình.
Để cài đặt package epirhandbook, bạn chạy theo code dưới đây. Lưu ý là package này không từ CRAN, do đó cần sử dụng hàm p_install_gh() để cài đặt. Thông tin đầu vào sẽ được chuyển tới trang Github của chúng tôi (“appliedepi”) và package epirhandbook.
# install the latest version of the Epi R Handbook package
pacman::p_install_gh("appliedepi/epirhandbook")Bây giờ, bạn gọi package để sử dụng cho phiên làm việc hiện tại:
# load the package for use
pacman::p_load(epirhandbook)Tiếp theo, sử dụng hàm get_data() trong package để tải dữ liệu minh họa và máy tính của bạn. Chạy hàm get_data("all") để tải toàn bộ dữ liệu minh họa, hoặc bạn có thể nêu tên một tệp cụ thể và phần mở rộng bên trong dấu ngoặc kép để tải một tệp duy nhất.
Dữ liệu sẽ được tải xuống cùng với package và bạn đơn giản chỉ cần lưu nó vào một thư mục trên máy tính của bạn. Một cửa sổ sẽ xuất hiện, cho phép bạn chọn vị trí lưu thư mục. Chúng tôi khuyên bạn nên tạo một thư mục mới tên là “data” vì có khoảng 30 tệp (bao gồm các bộ dữ liệu minh họa và kết quả).
# download all the example data into a folder on your computer
get_data("all")
# download only the linelist example data into a folder on your computer
get_data(file = "linelist_cleaned.rds")# download a specific file into a folder on your computer
get_data("linelist_cleaned.rds")Khi bạn dùng hàm get_data() để lưu tệp dữ liệu vào máy tính của mình, bạn sẽ vẫn cần nhập dữ liệu vào R. Xem chương Nhập xuất dữ liệu để biết thêm chi tiết.
Nếu bạn muốn, bạn có thể xem toàn bộ dữ liệu sử dụng trong cuốn sách này ở thư mục “dữ liệu” trong kho Github của chúng tôi.
Tải từng thứ một
Tùy chọn này liên quan đến việc tải xuống từng tệp dữ liệu từ kho lưu trữ Github của chúng tôi thông qua liên kết hoặc lệnh R dành riêng cho từng tệp. Một số loại tệp cho phép nút tải xuống, trong khi những loại khác có thể được tải xuống thông qua lệnh R.
Dữ liệu linelist
Đây là số liệu bùng phát Ebola giả định, được nhóm tác giả cẩm nang mở rộng từ bộ dữ liệu thực hành ebola_sim trong package outbreaks.
Bấm để tải xuống dữ liệu “thô” linelist (.xlsx). Bộ dữ liệu “thô” là một trang tính Excel với dữ liệu lộn xộn. Sử dụng số liệu này trong chương Làm sạch số liệu và các hàm quan trọng.
Bấm để tải xuống dữ liệu “đã làm sạch” linelist (.rds). Sử dụng tệp này cho tất cả các chương khác trong sổ tay có sử dụng bộ dữ liệu linelist. Tệp mở rộng .rds là một kiểu file của R có khả năng lưu trữ các thông tin cột. Điều này đảm bảo bạn sẽ có ít việc phải làm khi làm sạch số liệu sau khi nhập số liệu vào R.
Các tệp liên quan khác:
Bấm để tải xuống dữ liệu “đã làm sạch” linelist dưới dạng tệp Excel
Một phần của chương làm sạch sử dụng “từ điển làm sạch” (tệp .csv). Bạn có thể tải nó trực tiếp vào R bằng cách chạy các lệnh sau:
pacman::p_load(rio) # install/load the rio package
# import the file directly from Github
cleaning_dict <- import("https://github.com/appliedepi/epirhandbook_eng/raw/master/data/case_linelists/cleaning_dict.csv")Dữ liệu số trường hợp sốt rét
Đây là số liệu giả định về số lượng trường hợp sốt rét theo nhóm tuổi, cơ sở điều trị và ngày. Tệp mở rộng .rds là một kiểu file của R có khả năng lưu trữ các thông tin cột. Điều này đảm bảo bạn sẽ có ít việc phải làm khi làm sạch số liệu sau khi nhập số liệu vào R.
Dữ liệu thang đo Likert
Đây là dữ liệu giả định từ một cuộc khảo sát sử dụng thang đo Likert, được sử dụng trong chương Tháp dân số và thang đo Likert. Bạn có thể tải những dữ liệu này trực tiếp vào R bằng cách chạy các lệnh sau:
pacman::p_load(rio) # install/load the rio package
# import the file directly from Github
likert_data <- import("https://raw.githubusercontent.com/nsbatra/Epi_R_handbook/master/data/likert_data.csv")Flexdashboard
Dưới đây là các liên kết đến tệp được dùng trong chương Dashboards với R Markdown:
Truy vết tiếp xúc
Chương Truy vết tiếp xúc trình bày phân tích dữ liệu truy vết tiếp xúc, sử dụng dữ liệu minh họa từ Go.Data. Dữ liệu được sử dụng trong chương này có thể được tải xuống dưới dạng tệp .rds bằng cách bấm vào các liên kết sau:
Bấm để tải xuống dữ liệu điều tra trường hợp (.rds file)
Bấm để tải xuống dữ liệu ghi nhận tiếp xúc (.rds file)
Bấm để tải xuống dữ liệu theo dõi liên hệ (.rds file)
LƯU Ý: Dữ liệu truy vết tiếp xúc có cấu trúc từ phần mềm khác (ví dụ: KoBo, DHIS2 Tracker, CommCare) có thể sẽ khác. Nếu bạn muốn đóng góp dữ liệu hoặc nội dung mẫu thay thế cho trang này, vui lòng liên hệ chúng tôi.
MẸO: Nếu bạn đang triển khai Go.Data và muốn kết nối với API phiên bản của bạn, vui lòng xem chương Nhập xuất dữ liệu (mục API) và Go.Data Cộng đồng thực hành.
GIS
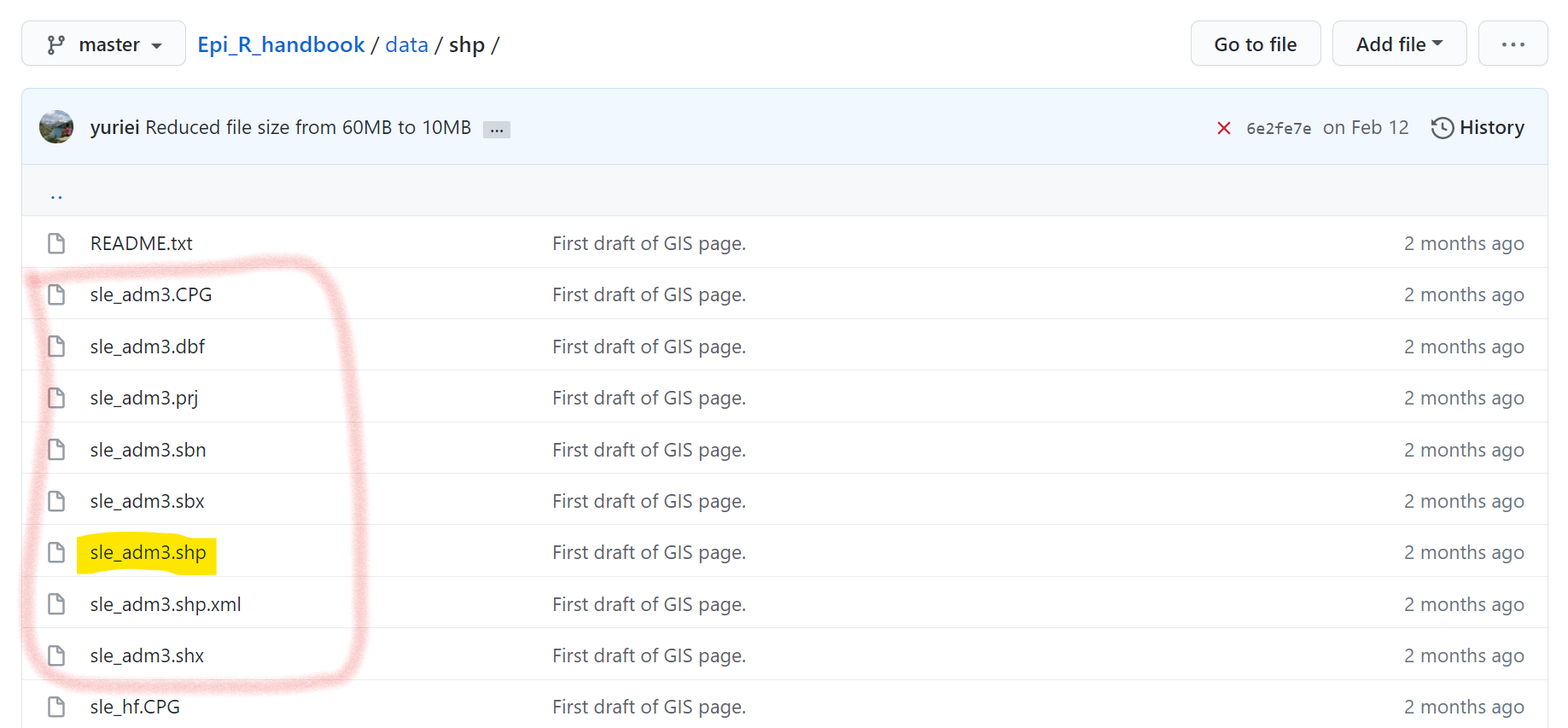
Shapefiles có nhiều tệp thành phần phụ, mỗi tệp có một phần mở rộng tệp khác nhau. Một tệp sẽ có phần mở rộng “.shp”, nhưng những tệp khác có thể là “.dbf”, “.prj”, v.v.
Chương GIS cơ bản cung cấp các liên kết đến trang web Humanitarian Data Exchange, nơi bạn có thể tải xuống trực tiếp các shapefiles dưới dạng tệp nén.
Ví dụ, dữ liệu phân bố của các cơ sở y tế có thể được tải xuống tại đây. Bạn tải tệp “hotosm_sierra_leone_health_facilities_points_shp.zip”. Sau khi được lưu vào máy tính của bạn, hãy “giải nén” thư mục. Bạn sẽ thấy một số tệp có các phần mở rộng khác nhau (ví dụ: “.shp”, “.prj”, “.shx”) - tất cả những tệp này phải được lưu vào cùng một thư mục trên máy tính của bạn. Sau đó, để nhập vào R, hãy cung cấp đường dẫn đến tệp và tên của tệp “.shp” bằng hàm st_read() từ package sf (đã được mô tả trong chương GIS cơ bản).
Nếu bạn làm theo Cách 1 để tải xuống tất cả dữ liệu minh họa (thông qua package epirhandbook của chúng tôi), tất cả các shapefiles đã được bao gồm.
Ngoài ra, bạn có thể tải xuống các shapefiles từ thư mục “data” trên trang R Handbook Github (xem thư mục con “gis”). Tuy nhiên, cần lưu ý rằng bạn sẽ phải tải từng tệp con xuống máy tính của mình. Trong Github, nhấp vào từng tệp riêng lẻ và tải chúng xuống bằng cách nhấp vào nút “Download”. Xem hình minh họa dưới đây, bạn có thể thấy shapefile “sl_adm3” bao gồm nhiều tệp con như thế nào - và mỗi tệp đều cần được tải xuống từ Github.
Cây phả hệ
Xem chương Cây phả hệ. Tệp có tên Newick về cây phả hệ được xây dựng từ việc giải trình tự toàn bộ bộ gen của 299 mẫu Shigella sonnei và dữ liệu mẫu tương ứng (được chuyển đổi thành tệp văn bản). Các mẫu và kết quả từ nước Bỉ được cung cấp thông qua Trung tâm tham khảo quốc gia về Salmonella và Shigella (NRC Bỉ) trong phạm vi dự án do EUPHEM Fellow của ECDC thực hiện, và cũng sẽ được xuất bản dưới dạng bản thảo. Dữ liệu quốc tế được cung cấp công khai trên cơ sở dữ liệu công cộng (ncbi) và đã được xuất bản trước đó.
- Để tải xuống file cây phả hệ “Shigella_tree.txt”, nhấn chuột phải vào link này (Cmd+click đối với Mac) và chọn “Save link as”.
- Để tải xuống file “sample_data_Shigella_tree.csv” với thông tin bổ sung cho từng mẫu, nhấn chuột phải vào link này (Cmd+click đối với Mac) và chọn “Save link as”.
- Để xem subset-tree mới được tạo, nhấn chuột phải vào link này (Cmd+click đối với Mac) và chọn “Save link as”. Tệp .txt sẽ được tải xuống máy tính của bạn.
Sau đó bạn có thể nhập tệp .txt files bằng hàm read.tree() từ ape package, như đã được trình bày trong chương này.
ape::read.tree("Shigella_tree.txt")Chuẩn hóa
Xem trong chương Tỷ lệ chuẩn hóa. Bạn có thể tải dữ liệu trực tiếp từ kho lưu trữ Github của chúng tôi trên internet vào phiên làm việc R của bạn bằng các lệnh sau :
# install/load the rio package
pacman::p_load(rio)
##############
# Country A
##############
# import demographics for country A directly from Github
A_demo <- import("https://github.com/appliedepi/epirhandbook_eng/raw/master/data/standardization/country_demographics.csv")
# import deaths for country A directly from Github
A_deaths <- import("https://github.com/appliedepi/epirhandbook_eng/raw/master/data/standardization/deaths_countryA.csv")
##############
# Country B
##############
# import demographics for country B directly from Github
B_demo <- import("https://github.com/appliedepi/epirhandbook_eng/raw/master/data/standardization/country_demographics_2.csv")
# import deaths for country B directly from Github
B_deaths <- import("https://github.com/appliedepi/epirhandbook_eng/raw/master/data/standardization/deaths_countryB.csv")
###############
# Reference Pop
###############
# import demographics for country B directly from Github
standard_pop_data <- import("https://github.com/appliedepi/epirhandbook_eng/raw/master/data/standardization/world_standard_population_by_sex.csv")Chuỗi thời gian và phát hiện ổ dịch
Xem trong chương Chuỗi thời gian và phát hiện ổ dịch. Chúng tôi sử dụng các trường hợp campylobacter được báo cáo ở Đức từ 2002-2011, có sẵn từ package surveillance của R. (lưu ý. tập dữ liệu này đã được điều chỉnh từ bản gốc, trong đó 3 tháng dữ liệu cuối năm 2011 đã bị xóa để dùng với mục đích minh họa)
Bấm để tải xuống dữ liệu Campylobacter ở Đức (.xlsx)
Chúng tôi cũng sử dụng dữ liệu khí hậu ở Đức từ 2002-2011 (nhiệt độ tính bằng độ C và lượng mưa tính bằng milimet). Dữ liệu được tải xuống từ tập dữ liệu phân tích vệ tinh Copernicus của EU bằng cách sử dụng package ecmwfr . Bạn sẽ cần tải xuống tất cả những thứ này và nhập chúng vào R bằng hàm stars::read_stars() như đã được giải thích trong chương chuỗi thời gian.
Bấm để tải dữ liệu thời tiết ở Đức 2002 (.nc file)
Bấm để tải dữ liệu thời tiết ở Đức 2003 (.nc file)
Bấm để tải dữ liệu thời tiết ở Đức 2004 (.nc file)
Bấm để tải dữ liệu thời tiết ở Đức 2005 (.nc file)
Bấm để tải dữ liệu thời tiết ở Đức 2006 (.nc file)
Bấm để tải dữ liệu thời tiết ở Đức 2007 (.nc file)
Bấm để tải dữ liệu thời tiết ở Đức 2008 (.nc file)
Bấm để tải dữ liệu thời tiết ở Đức 2009 (.nc file)
Phân tích sống còn
Đối với chương phân tích sống còn, chúng tôi sử dụng dữ liệu khảo sát tử vong giả định dựa trên mẫu khảo sát của MSF OCA. Dữ liệu giả định này là một phần của Dự án “R4Epis”.
Bấm để tài xuống dữ liệu khảo sát giả định (.xlsx)
Shiny
Chương Dashboards với Shiny trình diễn việc xây dựng một ứng dụng đơn giản để hiển thị dữ liệu bệnh sốt rét.
Để tải xuống các tệp R dùng để tạo thành ứng dụng Shiny:
Bạn có thể bấm vào đây để tải xuống tệp app.R trong đó chứa code của cả UI và Server của ứng dụng Shiny.
Bạn có thể bấm vào đây để tải tệp facility_count_data.rds có chứa dữ liệu sốt rét cho ứng dụng Shiny. Lưu ý rằng bạn có thể cần phải lưu trữ nó trong thư mục “data” để các đường dẫn tệp here () hoạt động chính xác.
Bạn có thể bấm vào đây để tải tệp global.R mà sẽ được chạy trước khi mở ứng dụng, như đã được giải thích trong chương.
Bạn có thể bấm vào đây để tải tệp plot_epicurve.R có nguồn từ tệp global.R. Lưu ý rằng bạn có thể cần phải lưu trữ nó trong thư mục “funcs” để các đường dẫn tệp here () hoạt động chính xác.