![]()
“Isı haritaları” veya “ısı karoları” olarak da bilinen ısı grafikleri, 3 değişkeni (x ekseni, y ekseni ve dolgu) görüntülemeye çalışırken yararlı görselleştirmeler olabilir. Aşağıda iki örnek gösteriliyor:
![]()
Bu kod parçası, analizler için gerekli olan paketlerin yüklenmesini gösterir. Bu el kitabında, gerekirse paketi kuran ve kullanım için yükleyen pacman’ın p_load() fonksiyonunu vurguluyoruz. Ayrıca, R tabanı’ndan library() ile kurulu paketleri yükleyebilirsiniz. R paketleri hakkında daha fazla bilgi için [R temelleri] sayfasına bakın.
pacman::p_load(
tidyverse, # data manipulation and visualization
rio, # importing data
lubridate # working with dates
)Veri setleri
Bu sayfa, iletim matrisi bölümü için simüle edilmiş bir salgının vaka satır listesini ve ölçüm izleme bölümü için tesise göre günlük sıtma vaka sayımlarının ayrı bir veri setini kullanır. Ayrı bölümlerine yüklenir ve temizlenirler.
Isı karoları, matrisleri görselleştirmek için faydalı olabilir. Örnek olarak, bir salgında “kimin kime bulaştığını” göstermektir. Bu, aktarım olayları hakkında bilgi sahibi olduğunuzu varsayar.
[Temaslı izleme] sayfasının, vakaların yaşlarının ve kaynaklarının veri çerçevesinin aynı satırında düzgün bir şekilde hizalandığı farklı (belki de daha basit) bir veri kümesi kullanarak bir ısı karosu temas matrisi oluşturmanın başka bir örneğini içerdiğine dikkat edin. Bu aynı veriler, [ggplot ipuçları] sayfasında bir yoğunluk haritası yapmak için kullanılır. Aşağıdaki bu örnek, bir durum satır listesinden başlar ve bu nedenle, çizilebilir bir veri çerçevesi elde etmeden önce önemli miktarda veri işlemeyi içerir. Yani seçebileceğiniz birçok senaryo var…
Simüle edilmiş bir Ebola salgınının vaka listesiyle başlıyoruz. Devam etmek istiyorsanız, “temiz” satır listesini (.rds dosyası olarak) indirmek için tıklayın. Verilerinizi rio paketinden import() fonksiyonuyla içe aktarın (.xlsx, .rds, .csv gibi birçok dosya türünü kabul eder - ayrıntılar için [İçe Aktarma ve Dışa Aktarma] sayfasına bakın).
Çizgi listesinin ilk 50 satırı, gösterim için aşağıda gösterilmiştir:
linelist <- import("linelist_cleaned.rds")Bu satır listesinde:
case_id ile tanımlandığı gibi, vaka başına bir satır vardırcase_id’sini içeren daha sonraki bir sütun olan infector vardır.Amaç: Olası yaştan yaşa iletim yolu başına bir satır içeren ve satır listesindeki tüm gözlenen iletim olaylarının o satırın oranını kapsayan sayısal bir sütun içeren “uzun” tarzda bir veri çerçevesi elde etmemiz gerekiyor.
Bu, aşağıdakileri elde etmek için birkaç veri işleme adımı alacaktır:
Başlamak için, vakaların, yaşlarının ve bulaştırıcılarının bir veri çerçevesini oluşturuyoruz - veri çerçevesine case_ages diyoruz. İlk 50 satır aşağıda gösterilmiştir.
case_ages <- linelist %>%
select(case_id, infector, age_cat) %>%
rename("case_age_cat" = "age_cat")Ardından, bulaşıcıların veri çerçevesini oluşturuyoruz - şu anda tek bir sütundan oluşuyor. Bunlar, satır listesindeki bulaştırıcı kimlikleridir. Her vakanın bilinen bir bulaştırıcısı yoktur, bu nedenle eksik değerleri kaldırıyoruz. İlk 50 satır aşağıda gösterilmiştir.
infectors <- linelist %>%
select(infector) %>%
drop_na(infector)Daha sonra, bulaştırıcıların yaşlarını elde etmek için birleşimleri kullanırız. Bu basit değil, çünkü linelist’de, bulaştırıcının yaşları bu şekilde listelenmiyor. Bu sonuca, linelist’i bulaştırıcılara ekleyerek ulaşıyoruz. Bulaştırıcılarla başlıyoruz ve vaka linelist’ne left_join() (ekliyoruz), öyle ki infector kimliği sütunu sol taraftaki “temel” veri çerçevesi sağ taraftaki linelist veri çerçevesindeki case_id sütunuyla birleşiyor.
Böylece satır listesindeki (yaş dahil) bulaştırıcının vaka kaydındaki veriler bulaştırıcı satırına eklenir. İlk 50 satır aşağıda gösterilmiştir.
infector_ages <- infectors %>% # begin with infectors
left_join( # add the linelist data to each infector
linelist,
by = c("infector" = "case_id")) %>% # match infector to their information as a case
select(infector, age_cat) %>% # keep only columns of interest
rename("infector_age_cat" = "age_cat") # rename for clarityDaha sonra vakaları ve yaşlarını bulaştırıcılar ve yaşları ile birleştiriyoruz. Bu veri çerçevelerinin her biri sütun infector’e sahiptir, bu nedenle birleştirme için kullanılır. İlk satırlar aşağıda görüntülenir:
ages_complete <- case_ages %>%
left_join(
infector_ages,
by = "infector") %>% # each has the column infector
drop_na() # drop rows with any missing dataWarning in left_join(., infector_ages, by = "infector"): Detected an unexpected many-to-many relationship between `x` and `y`.
ℹ Row 1 of `x` matches multiple rows in `y`.
ℹ Row 6 of `y` matches multiple rows in `x`.
ℹ If a many-to-many relationship is expected, set `relationship =
"many-to-many"` to silence this warning.Aşağıda, vaka ve enfeksiyon etkeni yaş grupları arasındaki sayıların basit bir çapraz tablosu. Netlik için etiketler eklendi.
table(cases = ages_complete$case_age_cat,
infectors = ages_complete$infector_age_cat) infectors
cases 0-4 5-9 10-14 15-19 20-29 30-49 50-69 70+
0-4 105 156 105 114 143 117 13 0
5-9 102 132 110 102 117 96 12 5
10-14 104 109 91 79 120 80 12 4
15-19 85 105 82 39 75 69 7 5
20-29 101 127 109 80 143 107 22 4
30-49 72 97 56 54 98 61 4 5
50-69 5 6 15 9 7 5 2 0
70+ 1 0 2 0 0 0 0 0Bu tabloyu, R tabanından data.frame() ile bir veri çerçevesine dönüştürebiliriz, bu da onu otomatik olarak ggplot() için istenen “uzun” biçime dönüştürür. İlk satırlar aşağıda gösterilmiştir.
long_counts <- data.frame(table(
cases = ages_complete$case_age_cat,
infectors = ages_complete$infector_age_cat))Şimdi biz de aynısını yapıyoruz, ancak tabloya R tabanından prop.table() uygularız, böylece sayımlar yerine toplamın oranlarını elde ederiz. İlk 50 satır aşağıda gösterilmiştir.
long_prop <- data.frame(prop.table(table(
cases = ages_complete$case_age_cat,
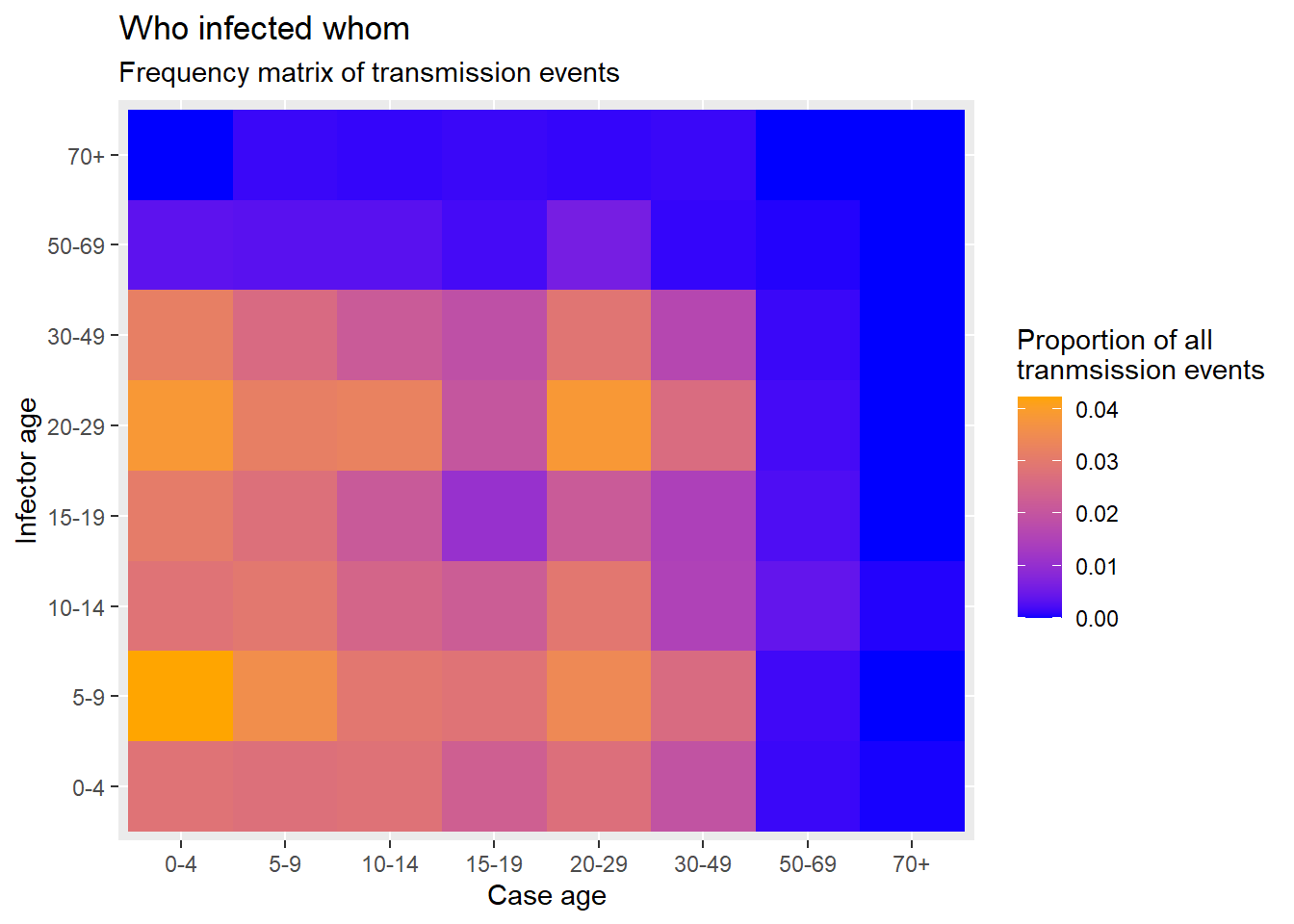
infectors = ages_complete$infector_age_cat)))Şimdi nihayet geom_tile() fonksiyonunu kullanarak ggplot2 paketi ile ısı grafiğini oluşturabiliriz. Renk/dolgu ölçekleri, özellikle de scale_fill_gradient() fonksiyonu hakkında daha kapsamlı bilgi edinmek için [ggplot ipuçları] sayfasına bakın.
geom_tile() estetik aes()’inde x ve y’yi vaka yaşı ve bulaştırıcı yaşı olarak ayarlayınaes() içinde fill = argümanını Freq sütununa ayarlayın - bu, kutucuk rengine dönüştürülecek değerdirscale_fill_gradient() ile bir ölçek rengi ayarlayın - yüksek/düşük renkleri belirleyebilirsiniz
scale_color_gradient() öğesinin farklı olduğuna dikkat edin! Bu durumda doldurmak istersinizlabs() içindeki fill = bağımsız değişkenini kullanabilirsiniz.ggplot(data = long_prop)+ # use long data, with proportions as Freq
geom_tile( # visualize it in tiles
aes(
x = cases, # x-axis is case age
y = infectors, # y-axis is infector age
fill = Freq))+ # color of the tile is the Freq column in the data
scale_fill_gradient( # adjust the fill color of the tiles
low = "blue",
high = "orange")+
labs( # labels
x = "Case age",
y = "Infector age",
title = "Who infected whom",
subtitle = "Frequency matrix of transmission events",
fill = "Proportion of all\ntranmsission events" # legend title
)
Halk sağlığında genellikle bir amaç, birçok kuruluş (tesisler, yargı alanları, vb.) için zaman içindeki eğilimleri değerlendirmektir. Bu tür eğilimleri zaman içinde görselleştirmenin bir yolu, x ekseninin zaman olduğu ve y ekseninde birçok öğenin bulunduğu bir ısı grafiğidir.
Birçok tesisten günlük sıtma raporlarının bir veri setini içe aktararak başlıyoruz. Raporlar bir tarih, il, ilçe ve sıtma sayılarını içerir. Bu verilerin nasıl indirileceği hakkında bilgi için [El kitabı ve verileri indirme] sayfasına bakın. İlk 30 satır aşağıdadır:
facility_count_data <- import("malaria_facility_count_data.rds")Bu örnekteki amaç, günlük tesis toplam sıtma vakası sayılarını (önceki sekmede görülen) tesis raporlama performansının haftalık özet istatistiklerine dönüştürmektir - bu durum için tesisin herhangi bir veriyi bildirdiği haftadaki günlerin oranıdır. Bu örnek için sadece Spring District için veri göstereceğiz.
Bunu başarmak için aşağıdaki veri yönetimi adımlarını uygulayacağız:
floor_date() kullanarak bir hafta sütunu oluşturun
summarise() işlevi, tesis-hafta grubu başına özet istatistikleri yansıtmak için yeni sütunlar oluşturur:
right_join() ile birleştirilir. Tüm olası kombinasyonların matrisi, veri çerçevesinin bu iki sütununa veri tüneli akışı o anda olduğu gibi (. ile temsil edilir) expand() uygulanarak oluşturulur. Bir right_join() kullanıldığından, expand() veri çerçevesindeki tüm satırlar tutulur ve gerekirse agg_weeks’e eklenir. Bu yeni satırlar, NA (eksik) özetlenmiş değerlerle görünür.Aşağıda adım adım gösteriyoruz:
# Create weekly summary dataset
agg_weeks <- facility_count_data %>%
# filter the data as appropriate
filter(
District == "Spring",
data_date < as.Date("2020-08-01")) Şimdi veri setinde, daha önce nrow(facility_count_data) olduğunda, nrow(agg_weeks) satırı vardır.
Ardından, her kayıt için haftanın başlangıç tarihini yansıtan bir week sütunu oluştururuz. Bu, lubridate paketi ve “hafta” olarak ayarlanan ve haftaların Pazartesi gününden itibaren başlayacağı (haftanın 1. günü - Pazar 7 olacaktır) floor_date() fonksiyonuyla elde edilir. Üst sıralar aşağıda gösterilmiştir.
agg_weeks <- agg_weeks %>%
# Create week column from data_date
mutate(
week = lubridate::floor_date( # create new column of weeks
data_date, # date column
unit = "week", # give start of the week
week_start = 1)) # weeks to start on Mondays Yeni hafta sütunu, veri çerçevesinin en sağında görülebilir
Şimdi veriler tesis-haftalar halinde gruplandırılır ve tesis-hafta başına istatistik üretmek için bunlar özetlenir. İpuçları için [Açıklayıcı tablolar] sayfasına bakın. Gruplandırmanın kendisi veri çerçevesini değiştirmez, ancak sonraki özet istatistiklerin nasıl hesaplandığını etkiler.
Üst sıralar aşağıda gösterilmiştir. Sütunların, istenen özet istatistikleri yansıtacak şekilde nasıl tamamen değiştiğine dikkat edin. Her satır bir tesis-haftayı yansıtır.
agg_weeks <- agg_weeks %>%
# Group into facility-weeks
group_by(location_name, week) %>%
# Create summary statistics columns on the grouped data
summarize(
n_days = 7, # 7 days per week
n_reports = dplyr::n(), # number of reports received per week (could be >7)
malaria_tot = sum(malaria_tot, na.rm = T), # total malaria cases reported
n_days_reported = length(unique(data_date)), # number of unique days reporting per week
p_days_reported = round(100*(n_days_reported / n_days))) %>% # percent of days reporting
ungroup(location_name, week)Son olarak, daha önce eksik olsalar bile, olası TÜM tesis-haftalarının verilerde mevcut olduğundan emin olmak için aşağıdaki komutu çalıştırılır.
Kendi üzerinde bir right_join() kullanıyoruz (veri seti “.” ile temsil edilir), ancak week ve location_name sütunlarının tüm olası kombinasyonlarını içerecek şekilde genişletildi. [Pivoting] sayfasındaki expand() işleviyle ilgili belgelere bakın. Bu kodu çalıştırmadan önce veri seti nrow(agg_weeks) satırlarını içerir.
# Create data frame of every possible facility-week
expanded_weeks <- agg_weeks %>%
tidyr::expand(location_name, week)expanded_weeks burada:
Bu kodu çalıştırmadan önce agg_weeks, nrow(agg_weeks) satırlarını içerir.
# Use a right-join with the expanded facility-week list to fill-in the missing gaps in the data
agg_weeks <- agg_weeks %>%
right_join(expanded_weeks) %>% # Ensure every possible facility-week combination appears in the data
mutate(p_days_reported = replace_na(p_days_reported, 0)) # convert missing values to 0 Joining with `by = join_by(location_name, week)`Bu kodu çalıştırdıktan sonra agg_weeks, nrow(agg_weeks) satırlarını içerir.
ggplot(), ggplot2 paketindeki geom_tile() kullanılarak yapılır:
scale_x_date() kullanımına izin verilir,location_name tüm tesis adlarını gösterecek,fill, p_days_reported, o tesisin haftalık performansı (sayısal),scale_fill_gradient() yüksek, düşük ve NA için renkleri belirterek sayısal dolguda kullanılır,scale_x_date(), her 2 haftada bir etiketleri ve formatlarını belirten x ekseninde kullanılır,Aşağıda, varsayılan renkler, ölçekler vb. kullanılarak temel bir ısı grafiği üretilmiştir.Yukarıda açıklandığı gibi, geom_tile() için aes() içinde bir x ekseni sütunu, y ekseni sütunu ve fill = için bir sütun sağlamalısınız. Dolgu, kutucuk rengi olarak sunulan sayısal değerdir.
ggplot(data = agg_weeks)+
geom_tile(
aes(x = week,
y = location_name,
fill = p_days_reported))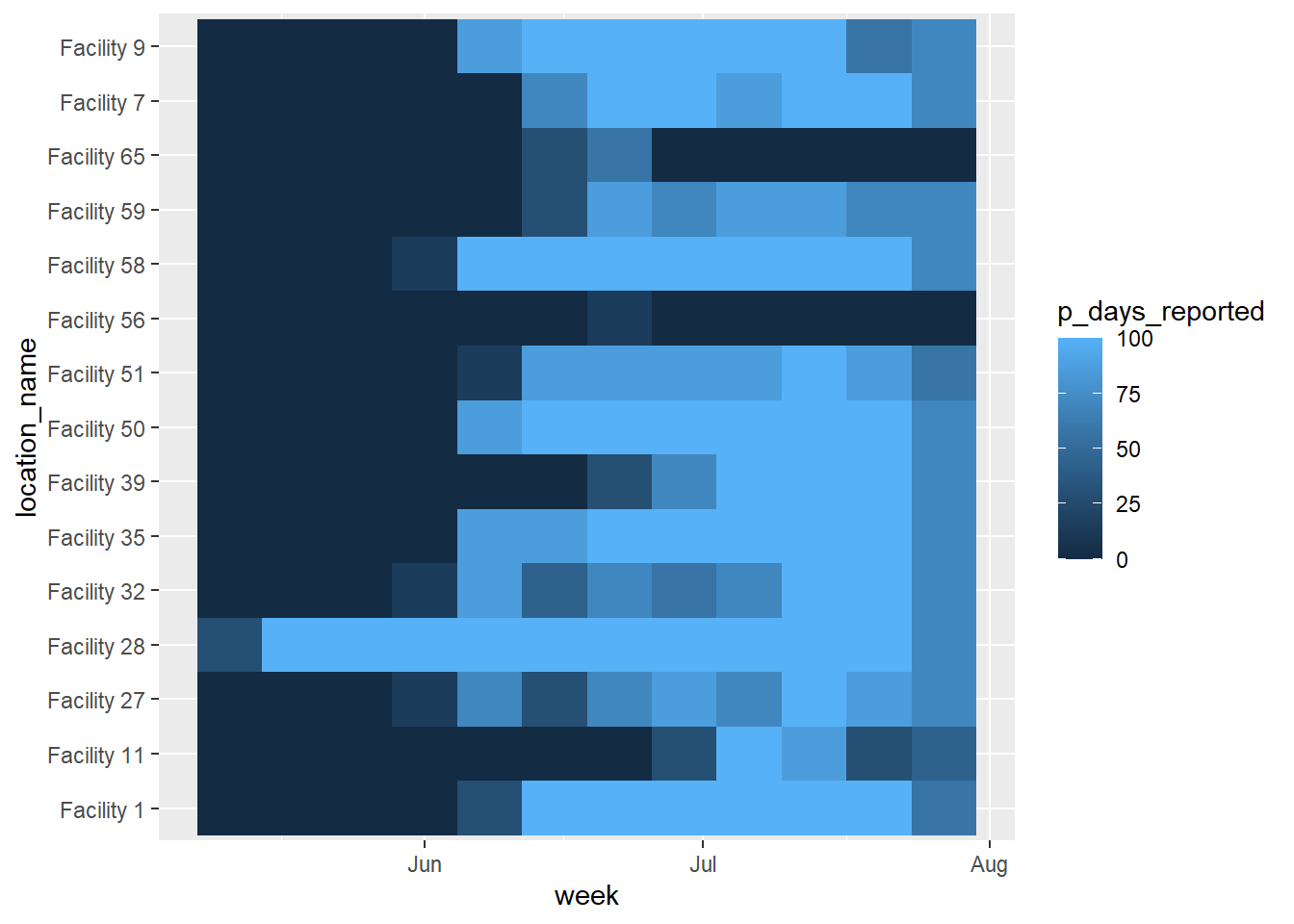
Aşağıda gösterildiği gibi ek ggplot2 işlevleri ekleyerek bu grafiğin daha iyi görünmesini sağlayabiliriz. Ayrıntılar için [ggplot ipuçları] sayfasına bakın.
ggplot(data = agg_weeks)+
# show data as tiles
geom_tile(
aes(x = week,
y = location_name,
fill = p_days_reported),
color = "white")+ # white gridlines
scale_fill_gradient(
low = "orange",
high = "darkgreen",
na.value = "grey80")+
# date axis
scale_x_date(
expand = c(0,0), # remove extra space on sides
date_breaks = "2 weeks", # labels every 2 weeks
date_labels = "%d\n%b")+ # format is day over month (\n in newline)
# aesthetic themes
theme_minimal()+ # simplify background
theme(
legend.title = element_text(size=12, face="bold"),
legend.text = element_text(size=10, face="bold"),
legend.key.height = grid::unit(1,"cm"), # height of legend key
legend.key.width = grid::unit(0.6,"cm"), # width of legend key
axis.text.x = element_text(size=12), # axis text size
axis.text.y = element_text(vjust=0.2), # axis text alignment
axis.ticks = element_line(size=0.4),
axis.title = element_text(size=12, face="bold"), # axis title size and bold
plot.title = element_text(hjust=0,size=14,face="bold"), # title right-aligned, large, bold
plot.caption = element_text(hjust = 0, face = "italic") # caption right-aligned and italic
)+
# plot labels
labs(x = "Week",
y = "Facility name",
fill = "Reporting\nperformance (%)", # legend title, because legend shows fill
title = "Percent of days per week that facility reported data",
subtitle = "District health facilities, May-July 2020",
caption = "7-day weeks beginning on Mondays.")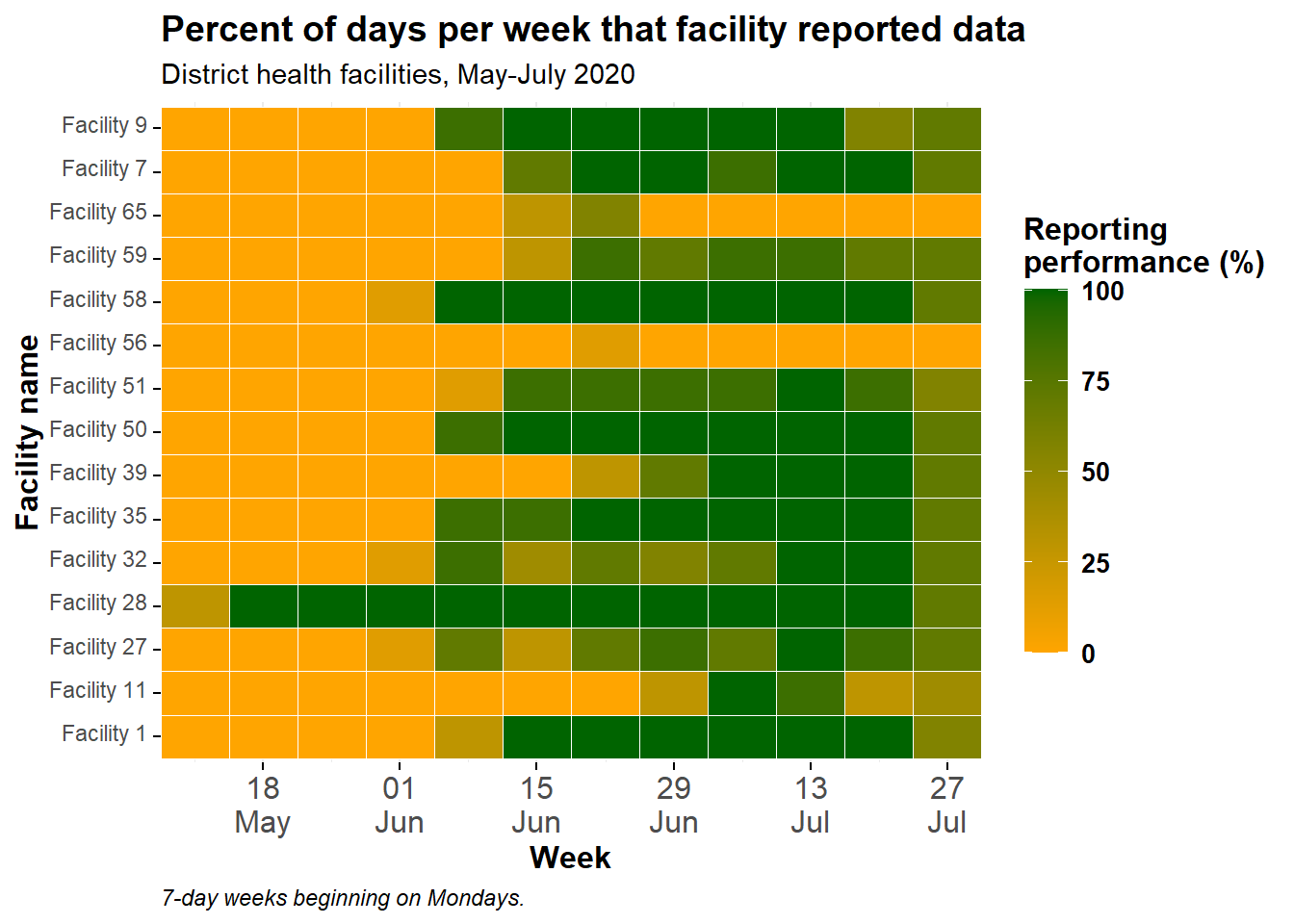
Şu anda tesisler, aşağıdan yukarıya doğru “alfa-nümerik olarak” sıralanmıştır. Eğer y ekseni tesislerinin sırasını ayarlamak istiyorsanız, bunları sınıf faktörüne dönüştürün ve sırayı sağlayın. İpuçları için [Faktörler] sayfasına bakın.
Pek çok tesis olduğundan ve hepsini yazmak istemediğimizden, başka bir yaklaşım deneyeceğiz bu da tesisleri bir veri çerçevesinde sıralamak ve sonuç sütununu faktör düzeyi sırası olarak kullanmak olacak. Aşağıda, location_name sütunu bir faktöre dönüştürülür ve düzeylerinin sırası, tüm zaman aralığında tesis tarafından dosyalanan toplam raporlama günü sayısına göre belirlenir.
Bunu yapmak için, artan düzende düzenlenmiş, tesis başına toplam rapor sayısını temsil eden bir veri çerçevesi oluşturuyoruz. Grafikteki faktör seviyelerini sıralamak için bu vektör kullanılabilir.
facility_order <- agg_weeks %>%
group_by(location_name) %>%
summarize(tot_reports = sum(n_days_reported, na.rm=T)) %>%
arrange(tot_reports) # ascending orderAşağıdaki veri çerçevesine bakın:
Şimdi, agg_weeks veri çerçevesindeki location_name faktör düzeylerinin sırası olmak için yukarıdaki veri çerçevesinden (facility_order$location_name) bir sütun kullanın:
# load package
pacman::p_load(forcats)
# create factor and define levels manually
agg_weeks <- agg_weeks %>%
mutate(location_name = fct_relevel(
location_name, facility_order$location_name)
)Ve şimdi, location_name sıralı bir faktör olacak şekilde veriler yeniden çizilir:
ggplot(data = agg_weeks)+
# show data as tiles
geom_tile(
aes(x = week,
y = location_name,
fill = p_days_reported),
color = "white")+ # white gridlines
scale_fill_gradient(
low = "orange",
high = "darkgreen",
na.value = "grey80")+
# date axis
scale_x_date(
expand = c(0,0), # remove extra space on sides
date_breaks = "2 weeks", # labels every 2 weeks
date_labels = "%d\n%b")+ # format is day over month (\n in newline)
# aesthetic themes
theme_minimal()+ # simplify background
theme(
legend.title = element_text(size=12, face="bold"),
legend.text = element_text(size=10, face="bold"),
legend.key.height = grid::unit(1,"cm"), # height of legend key
legend.key.width = grid::unit(0.6,"cm"), # width of legend key
axis.text.x = element_text(size=12), # axis text size
axis.text.y = element_text(vjust=0.2), # axis text alignment
axis.ticks = element_line(size=0.4),
axis.title = element_text(size=12, face="bold"), # axis title size and bold
plot.title = element_text(hjust=0,size=14,face="bold"), # title right-aligned, large, bold
plot.caption = element_text(hjust = 0, face = "italic") # caption right-aligned and italic
)+
# plot labels
labs(x = "Week",
y = "Facility name",
fill = "Reporting\nperformance (%)", # legend title, because legend shows fill
title = "Percent of days per week that facility reported data",
subtitle = "District health facilities, May-July 2020",
caption = "7-day weeks beginning on Mondays.")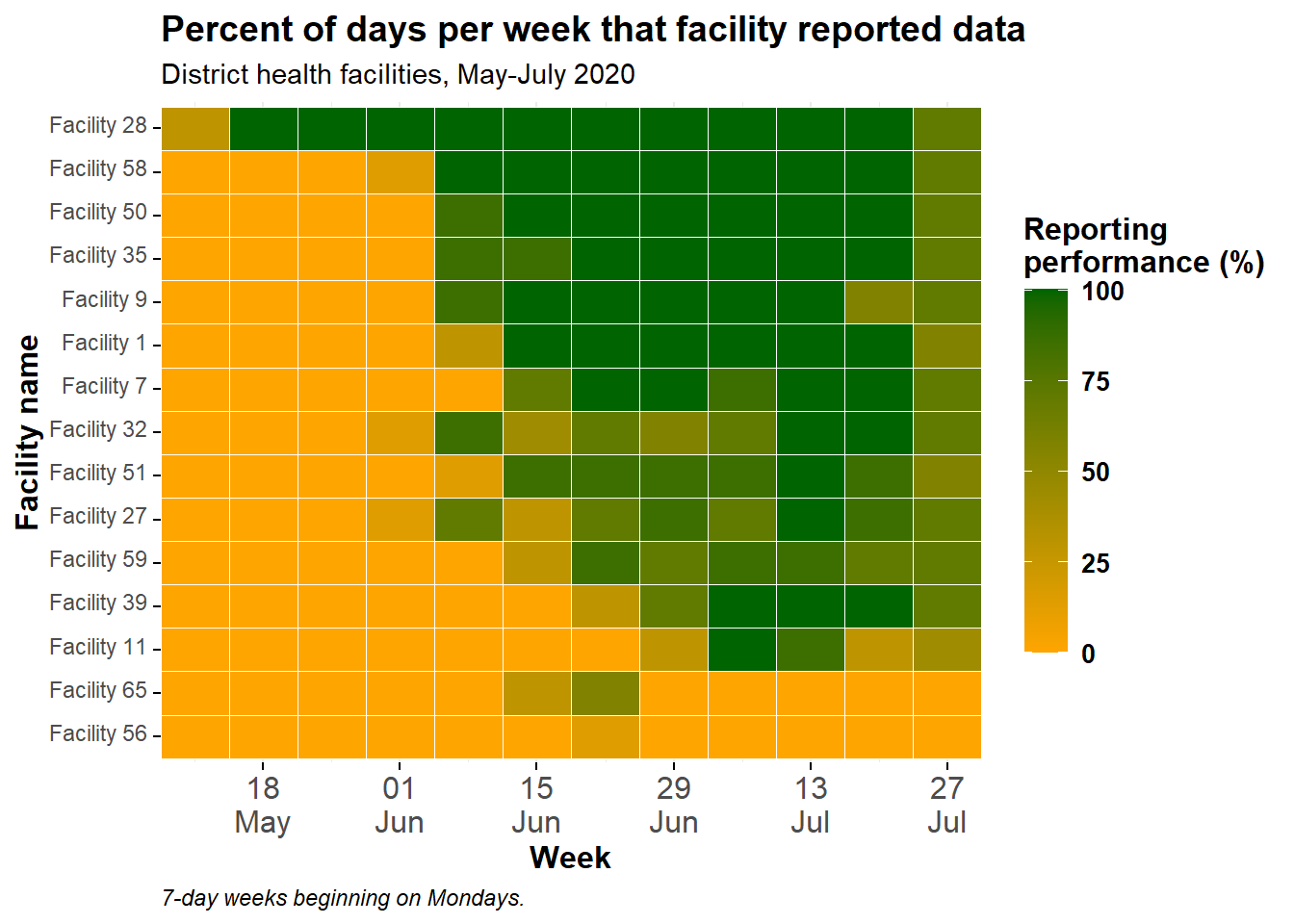
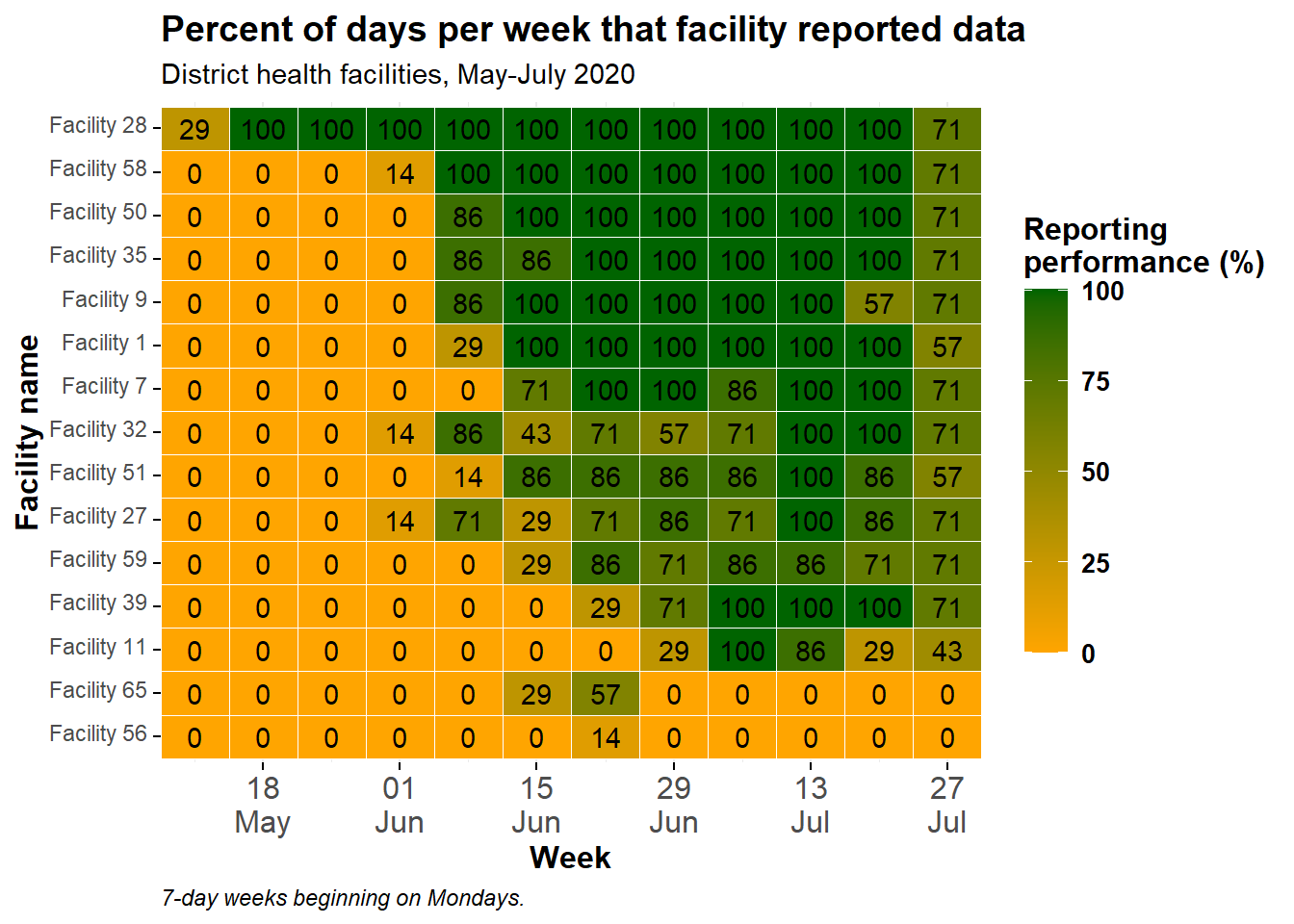
Her kutucuğun gerçek sayılarını görüntülemek için kutucukların üzerine bir geom_text() katmanı ekleyebilirsiniz. Çok sayıda küçük kutucuğunuz varsa, bunun hoş görünmeyebileceğini unutmayın!
Şu kod eklendi: geom_text(aes(label = p_days_reported)). Bu, her döşemeye metin ekler. Görüntülenen metin, bu durumda renk gradyanını oluşturmak için kullanılan p_days_reported ile aynı sayısal sütuna ayarlanmış olan label = bağımsız değişkenine atanan değerdir.
ggplot(data = agg_weeks)+
# show data as tiles
geom_tile(
aes(x = week,
y = location_name,
fill = p_days_reported),
color = "white")+ # white gridlines
# text
geom_text(
aes(
x = week,
y = location_name,
label = p_days_reported))+ # add text on top of tile
# fill scale
scale_fill_gradient(
low = "orange",
high = "darkgreen",
na.value = "grey80")+
# date axis
scale_x_date(
expand = c(0,0), # remove extra space on sides
date_breaks = "2 weeks", # labels every 2 weeks
date_labels = "%d\n%b")+ # format is day over month (\n in newline)
# aesthetic themes
theme_minimal()+ # simplify background
theme(
legend.title = element_text(size=12, face="bold"),
legend.text = element_text(size=10, face="bold"),
legend.key.height = grid::unit(1,"cm"), # height of legend key
legend.key.width = grid::unit(0.6,"cm"), # width of legend key
axis.text.x = element_text(size=12), # axis text size
axis.text.y = element_text(vjust=0.2), # axis text alignment
axis.ticks = element_line(size=0.4),
axis.title = element_text(size=12, face="bold"), # axis title size and bold
plot.title = element_text(hjust=0,size=14,face="bold"), # title right-aligned, large, bold
plot.caption = element_text(hjust = 0, face = "italic") # caption right-aligned and italic
)+
# plot labels
labs(x = "Week",
y = "Facility name",
fill = "Reporting\nperformance (%)", # legend title, because legend shows fill
title = "Percent of days per week that facility reported data",
subtitle = "District health facilities, May-July 2020",
caption = "7-day weeks beginning on Mondays.")