Demografik piramitler, yaş ve cinsiyet dağılımlarını göstermek için kullanışlıdır. Benzer kod, Likert tarzı anket sorularının sonuçlarını görselleştirmek için de kullanılabilir (örneğin, “Kesinlikle katılıyorum”, “Katılıyorum”, “Nötr”, “Katılıyorum”, “Kesinlikle katılmıyorum”). Bu sayfada aşağıdaki başlıkları ele alacağız:
ggplot() kullanarak daha fazla özelleştirilebilir piramit grafiği oluşturmaAşağıdaki kod parçası, analizler için gerekli olan paketlerin yüklenmesini göstermektedir. Bu el kitabında, gerekirse paketi kuran ve kullanım için yükleyen pacman’dan p_load() fonksiyonunu ön plana çıkardık. R tabanından library() ile kurulu paketleri de yükleyebilirsiniz. R paketleri hakkında daha fazla bilgi için [R temelleri] sayfasına bakınız.
pacman::p_load(rio, # verileri içe aktarmak için
here, # dosyaları bulmak için
tidyverse, # verileri temizlemek, işlemek ve çizmek için (ggplot2 paketini içerir)
apyramid, # yaş piramitleri oluşturmak için
janitor, # tablo ve veri temizlemek için
stringr) # başlık, alt yazı vb. dizelerle çalışmak içinBaşlamak için, Ebola salgını simulasyonuna ait temizlenmiş vaka listesini içe aktarıyoruz. Takip etmek isterseniz, “temiz satır listesi” dosyasını indirmek için tıklayınız. (.rds dosyası olarak). rio paketinden import() fonksiyonu ile veriler içe aktarılmalıdır (.xlsx, .csv, .rds gibi birçok dosya türünü işler - ayrıntılar için [İçe ve dışa aktarma] sayfasına bakınız).
# vaka satır listesini içe aktar
linelist <- import("linelist_cleaned.rds")Satır listesinin ilk 50 satırı aşağıda gösterilmiştir.
Geleneksel bir yaş/cinsiyet demografik piramidi oluşturmak için verilerin öncelikle aşağıda tanımlandığı gibi temizlenmesi gerekir:
Eğer Yaş kategorileri kullanılacaksa, sütun değerleri varsayılan olarak alfasayısal olarak veya sınıf faktörüne dönüştürülerek düzeltilmelidir.
Aşağıda, gender ve age_cat5 sütunlarını incelemek için janitor paketinden tabyl() fonksiyonunu kullanıyoruz.
linelist %>%
tabyl(age_cat5, gender) age_cat5 f m NA_
0-4 640 416 39
5-9 641 412 42
10-14 518 383 40
15-19 359 364 20
20-24 305 316 17
25-29 163 259 13
30-34 104 213 9
35-39 42 157 3
40-44 25 107 1
45-49 8 80 5
50-54 2 37 1
55-59 0 30 0
60-64 0 12 0
65-69 0 12 1
70-74 0 4 0
75-79 0 0 1
80-84 0 1 0
85+ 0 0 0
<NA> 0 0 86Ayrıca, temiz ve doğru şekilde sınıflandırıldığından emin olmak için “age” sütununu hızlıca histograma dönüştürüyoruz:
hist(linelist$age)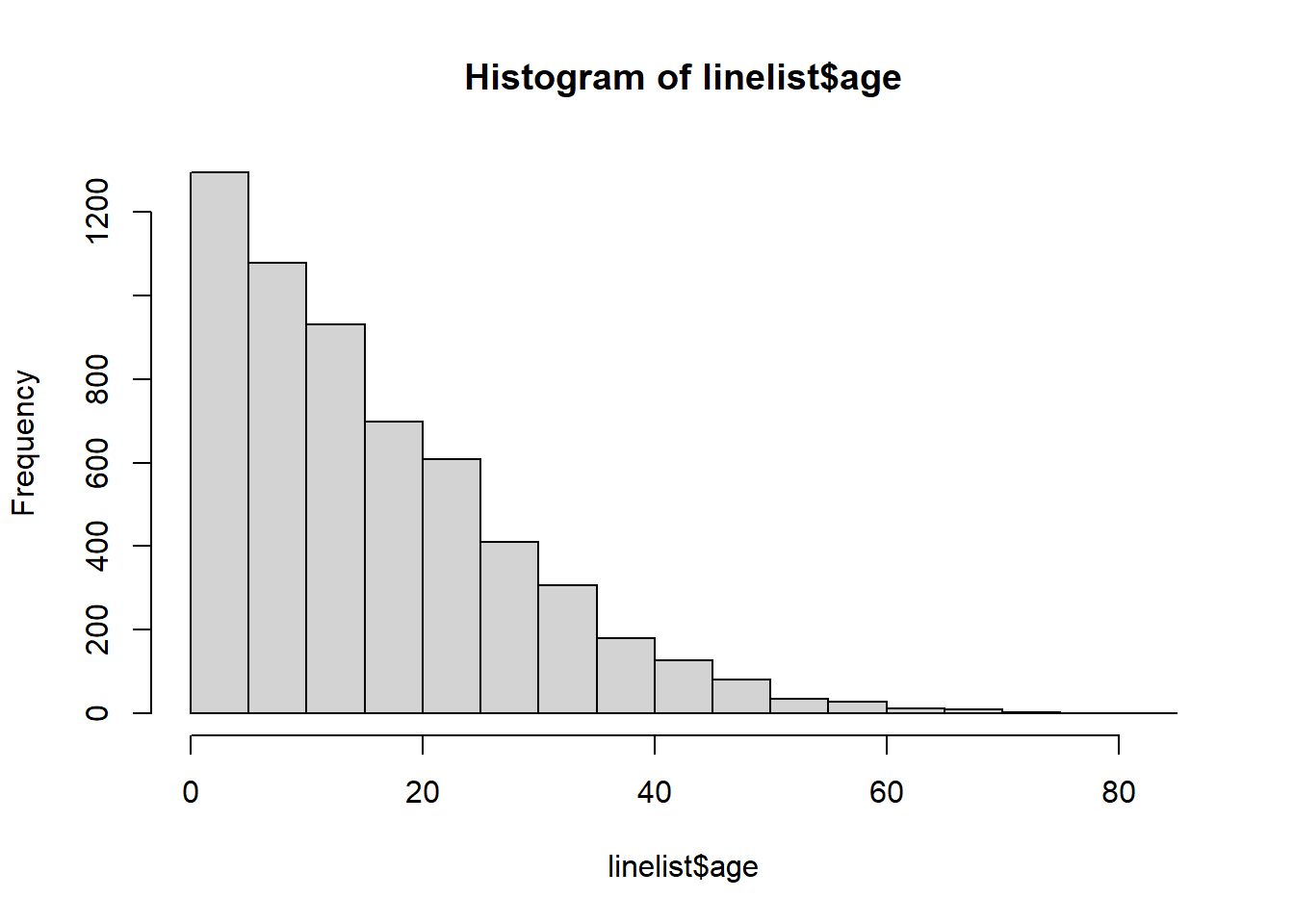
apyramid paketi R4Epis projesinin bir ürünüdür. Bu paket hakkında daha fazla bilgiyi buradan okuyabilirsiniz. Paket, hızlı bir şekilde bir yaş piramidi yapmanızı sağlar. Daha ayrıntılı durumlar için aşağıdaki bölüme bakabilirsiniz ggplot() kullanarak. R konsolunuza ?age_pyramid girerek yardım sayfasında apyramid paketi hakkında daha fazla bilgi edinebilirsiniz.
Temizlenmiş ‘satır listesi’ veri setini kullanarak, age_pyramid() komutuyla basit bir yaş piramidi oluşturabiliriz. Bu komutta:
data = argümanı “satır listesi” veri çerçevesi olarak ayarlanırage_group = argümanı (y ekseni için) kategorik yaş sütununun adına ayarlanır (tırnak içinde)split_by = argüman (x ekseni için) cinsiyet sütununa ayarlanırapyramid::age_pyramid(data = linelist,
age_group = "age_cat5",
split_by = "gender")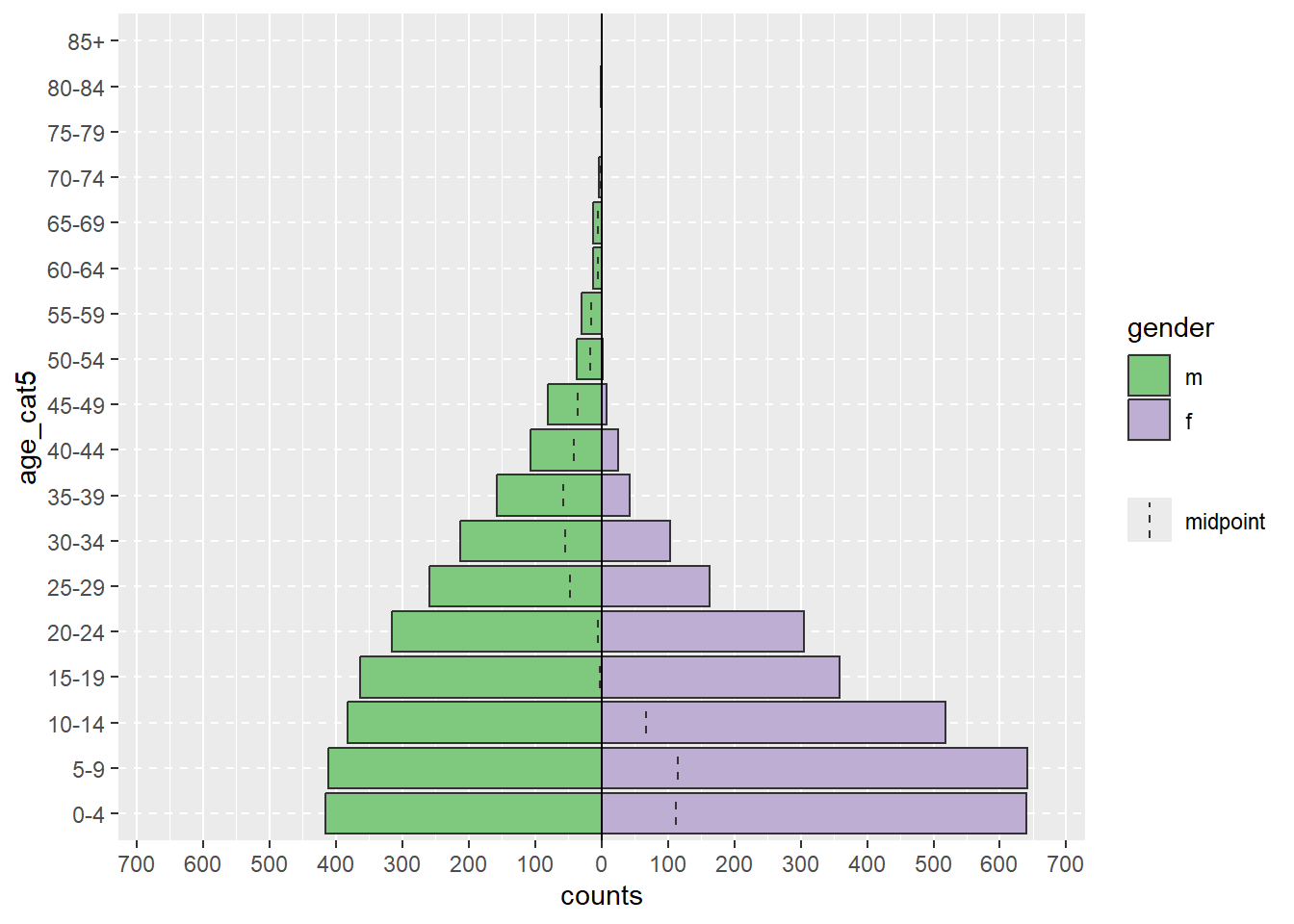
Piramit, proportional = TRUE argümanı dahil edilerek, sayılar yerine x eksenindeki tüm verileri yüzdesi ile görüntülenebilir.
apyramid::age_pyramid(data = linelist,
age_group = "age_cat5",
split_by = "gender",
proportional = TRUE)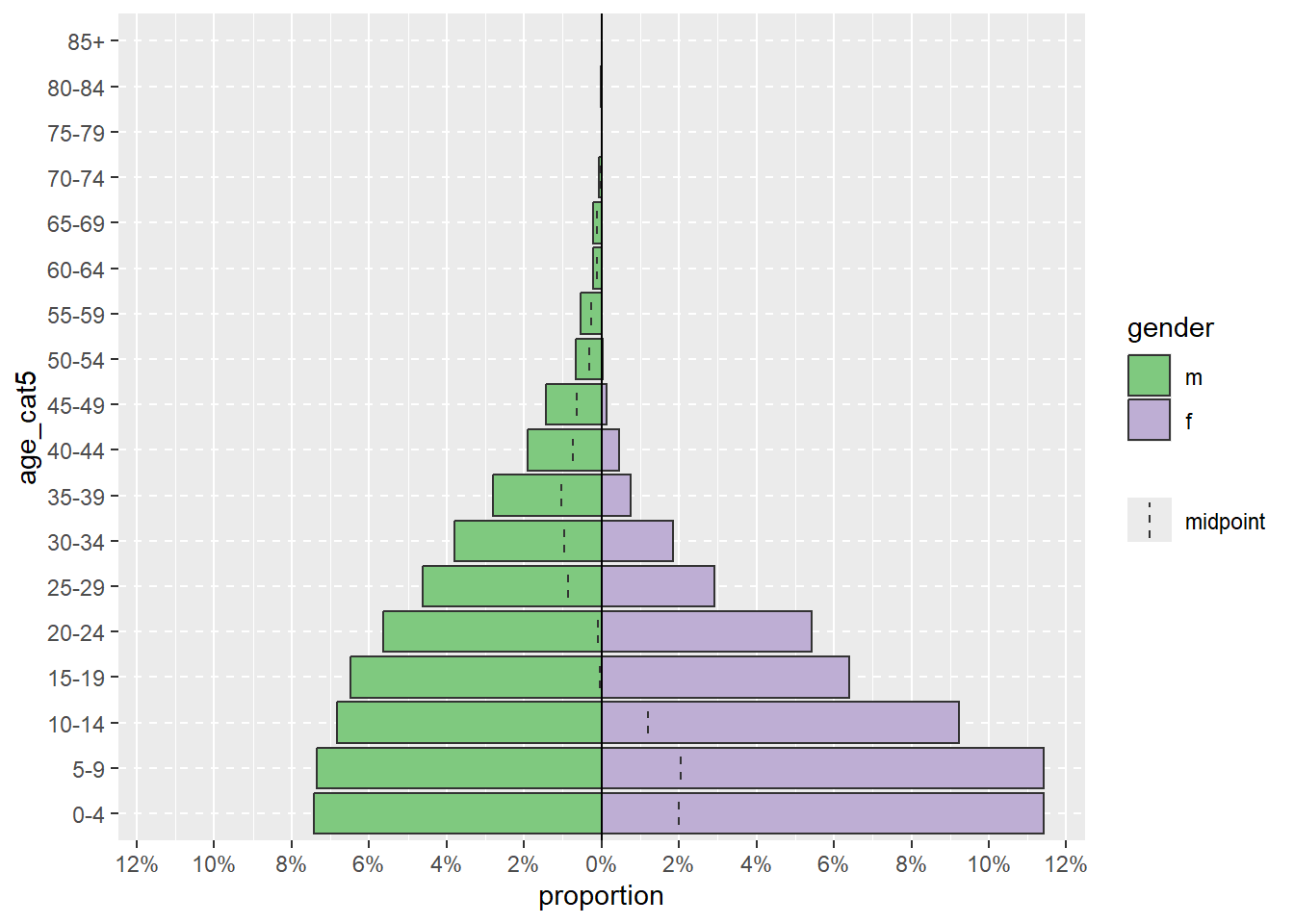
agepyramid paketini kullanırken, split_by sütunu ikili ise (ör. erkek/dişi veya evet/hayır), sonuç bir piramit olarak görünecektir. Bununla birlikte, split_by sütununda ikiden fazla değer varsa (NA dahil değildir), piramit “arka planda” gri çubuklar olan yönlü bir çubuk grafiği olarak görünecektir. Bu durum yaş grubu gibi yönlü olmayan verilerin aralığını gösterir. Bu durumda, split_by = değerleri her yön panelinin üstünde etiketler olarak görünecektir. Örneğin, split_by =, hospital sütununa atanırsa kodun nasıl yazılacağı aşağıda belirtilmiştir.
apyramid::age_pyramid(data = linelist,
age_group = "age_cat5",
split_by = "hospital") 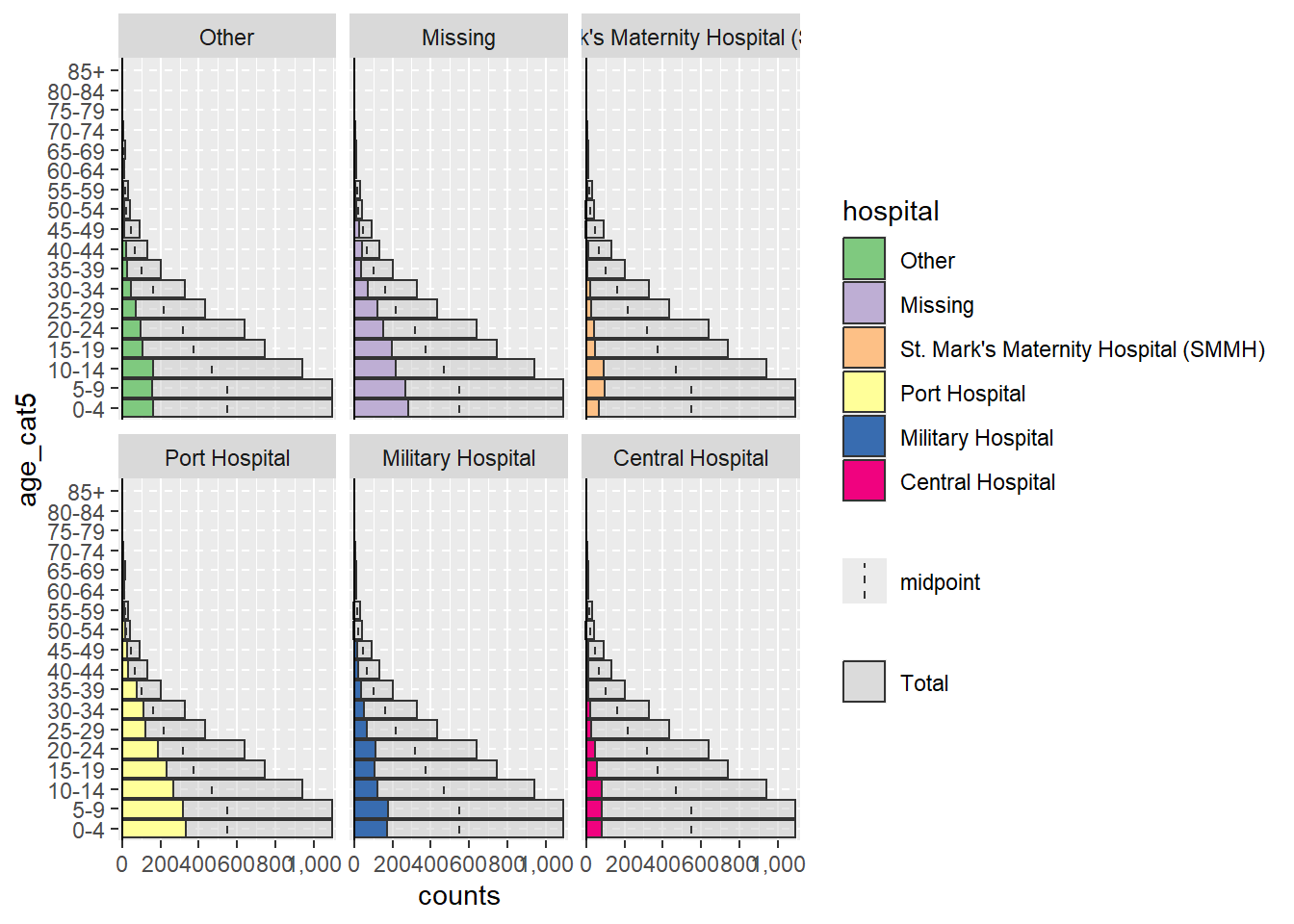
Eğer eksik veriler NA olarak kodlanmışsa, split_by = veya age_group = sütunlarındaki eksik veri olan satırlar, grafiğin oluşmasını etkilemez. Varsayılan olarak bu satırlar gösterilmeyecektir. Bununla birlikte, na.rm = FALSE argümanıyla üstte, ayrı bir bitişik çubuk grafiğinde görünmelerini sağlayabilirsiniz.
apyramid::age_pyramid(data = linelist,
age_group = "age_cat5",
split_by = "gender",
na.rm = FALSE) # show patients missing age or gender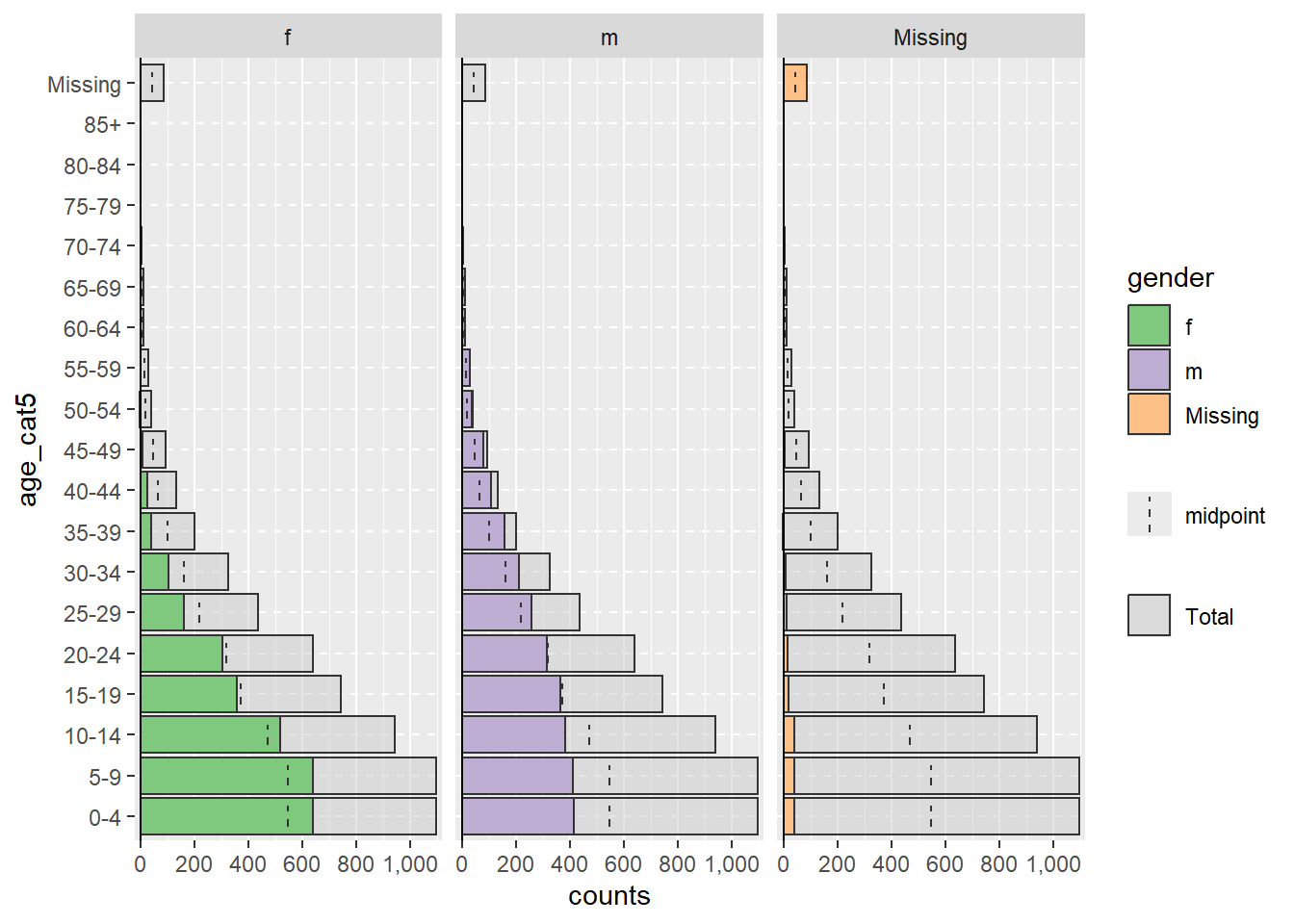
Varsayılan olarak, çubuklar sayılarını belirtmektedir (yüzdelerini değil). Her grup kesikli bir orta çizgi ile gösterilir ve rengi yeşil/mordur. Bu parametrelerin her biri aşağıda gösterildiği gibi ayarlanabilir:
İstediğiniz estetik ve etiket ayarlamalarını standart ggplot() fonksiyonu ve “+” argümanını kullanarak ek ggplot() komutlarıyla belirleyebilirsiniz:
apyramid::age_pyramid(
data = linelist,
age_group = "age_cat5",
split_by = "gender",
proportional = TRUE, # yüzdeyi göster, sayıları değil
show_midpoint = FALSE, # orta nokta çizgisini kaldır
#pal = c("orange", "purple") # burada alternatif renkler belirtebilirsiniz (ancak etiketleri değil)
)+
# additional ggplot commands
theme_minimal()+ # arka planı basitleştir
scale_fill_manual( # renkleri VE etiketleri belirtin
values = c("orange", "purple"),
labels = c("m" = "Male", "f" = "Female"))+
labs(y = "Percent of all cases", # x ve y laboratuvarları değiştirildiğine dikkat edin
x = "Age categories",
fill = "Gender",
caption = "My data source and caption here",
title = "Title of my plot",
subtitle = "Subtitle with \n a second line...")+
theme(
legend.position = "bottom", # açıklama aşağıya
axis.text = element_text(size = 10, face = "bold"), # font ve boyut
axis.title = element_text(size = 12, face = "bold"))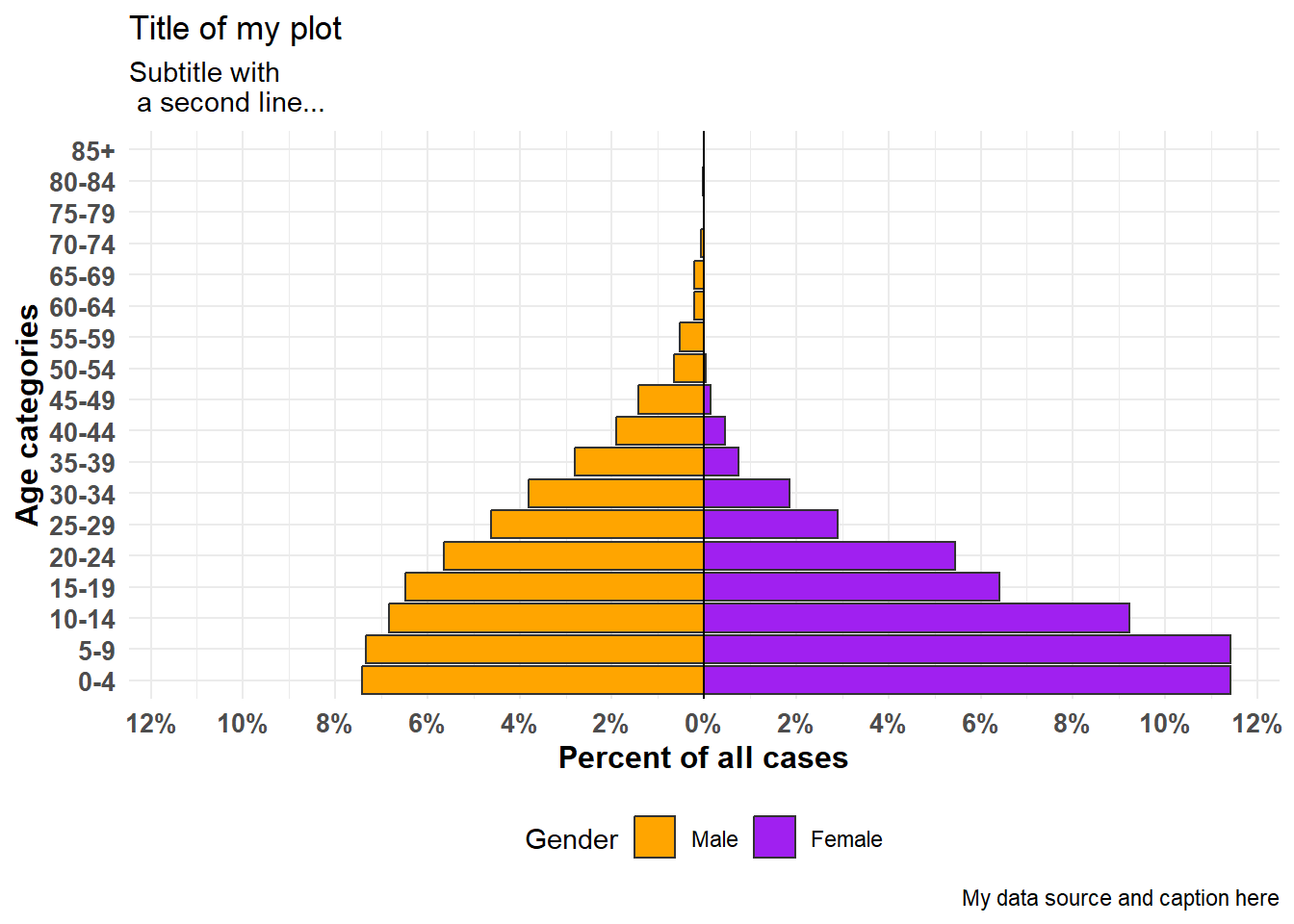
Yukarıdaki örnekler, verilerinizin gözlem başına bir satır olacak şekilde bir satır listesi biçiminde olduğunu varsaymaktadır. Verileriniz zaten yaş kategorisine göre sayılar halinde toplanmışsa, aşağıda gösterildiği gibi apyramid paketini kullanmaya devam edebilirsiniz.
Örnek olması için, satır listesi verilerini yaş kategorisine ve cinsiyete göre sayımlar halinde “geniş” bir formatta topluyoruz. Burada, verileriniz başlangıçta sayıymış gibi simüle edilecektir. İlgili sayfalarında [Gruplama verileri] ve [Özetleme verileri] hakkında daha fazla bilgi edinebilirsiniz.
demo_agg <- linelist %>%
count(age_cat5, gender, name = "cases") %>%
pivot_wider(
id_cols = age_cat5,
names_from = gender,
values_from = cases) %>%
rename(`missing_gender` = `NA`)…bu da veri setinin şu şekilde görünmesini sağlar: yaş kategorisi, erkek sayısı, kadın sayısı ve eksik veri sütunları.
Bu verileri yaş piramidine uyarlamak için, veriler dplyr paketinden pivot_longer() fonksiyonuyla “long” formatına döndürülecektir. Bunun nedeni, ggplot() fonksiyonunun genellikle “long” verileri tercih etmesi ve apyramid paketinin ggplot()u kullanmasıdır.
# Toplu veriyi long formatına döndür
demo_agg_long <- demo_agg %>%
pivot_longer(
col = c(f, m, missing_gender), # long formatına çevrilecek sütunlar
names_to = "gender", # kategori sütunu için yeni ad
values_to = "counts") %>% # sayım sütunları için yeni ad
mutate(
gender = na_if(gender, "missing_gender")) # "missing_gender"ı NA'ya çevirArdından, verilerdeki ilgili sütunları belirtmek için age_pyramid() fonksiyonunun split_by = ve count = argümanını kullanın:
apyramid::age_pyramid(data = demo_agg_long,
age_group = "age_cat5",# yaş kategorisi sütunu için yeni ad
split_by = "gender", # cinsiyet sütunu için yeni ad
count = "counts") # vaka sayıları sütunu için yeni ad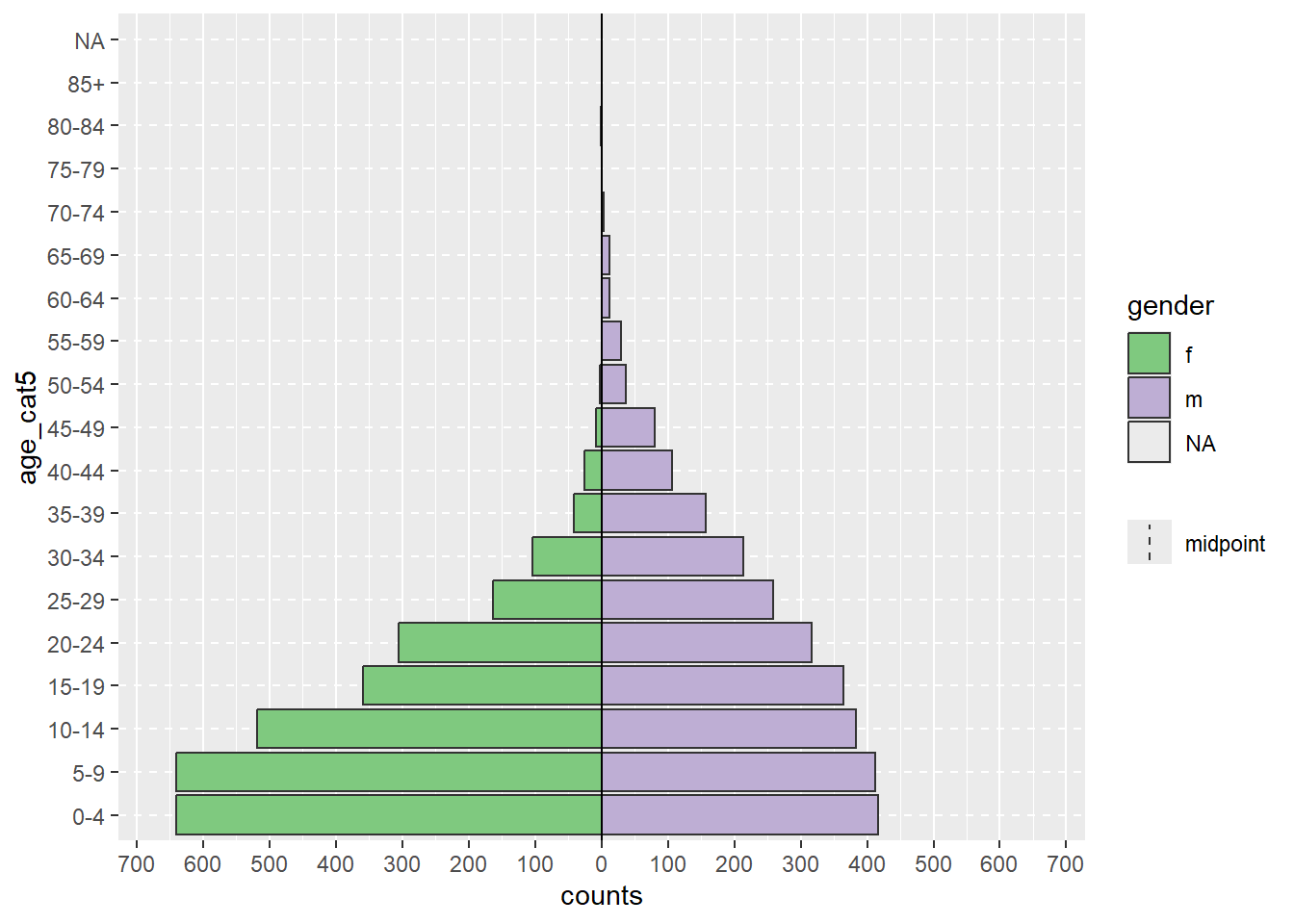
Yukarıda “m” ve “f” faktör sırasının farklı olduğuna dikkat edin (ters piramit). Sıralamayı ayarlamak için, toplu verilerde cinsiyeti Faktör olarak yeniden tanımlamalı ve seviyeleri istediğiniz gibi sıralamalısınız. [Faktörler] sayfasına bakınız.
ggplot()Yaş piramidinizi oluşturmak için ggplot()u kullanmak daha fazla esneklik sağlar, ancak ggplot()un nasıl çalıştığına dair daha fazla bilgi sahibi olmanız gerekmektedir. Çünkü bu pakette hata yapmak da daha kolaydır.
Demografik piramitler yapmak üzere ggplot()u kullanmak için, iki çubuk grafiği (her cinsiyet için bir tane) oluşturursunuz, bir grafikteki değerleri negatife çevirirsiniz ve son olarak çubuk grafiklerini dikey olarak, tabanlarını görüntülemek için x ve y eksenlerini çevirirsiniz.
Bu yaklaşım, age_cat5 verilerinin kategorik değil, sayısal yaş sütununu kullanır. Bu yüzden bu sütunun sınıfının gerçekten sayısal olup olmadığını kontrol edeceğiz.
class(linelist$age)[1] "numeric"Aşağıdaki mantığı, geom_histogram() yerine geom_col() kullanarak kategorik verilerden bir piramit oluşturmak için de kullanabilirsiniz.
İlk olarak, ggplot() kullanarak bir piramit yapmak için aşağıdaki yaklaşımı anlamanız gerekmektedir:
ggplot() içinde, sayısal yaş sütununu kullanarak iki histogram oluşturun: İki gruplama değerinin her biri için bir tane (bu durumda cinsiyetler erkek ve kadın). Bunu yapmak için, her bir histogram için veriler, ilgili filtreler “satır listesine” uygulanarak ilgili geom_histogram() komutlarında tanımlanır.
Bir grafik pozitif değerlere sahip olacak, diğeri ise negatif değerlere dönüştürülecek - bu, grafiğin ortasında “0” değeri olan bir “piramit” yaratır. Negatif değerler, özel bir ggplot2 terimi ..count.. kullanılarak ve -1 ile çarpılarak oluşturulur.
coord_flip() komutu X ve Y eksenlerini değiştirerek grafiklerin 90 derece dönmesine ve piramidin oluşturulmasına neden olur.
Son olarak, sayım ekseni değer etiketleri, piramidin her iki tarafında “pozitif” sayımlar olarak görünecek şekilde değiştirilmelidir (bir taraftaki temel değerlerin negatif olmasına rağmen).
geom_histogram() fonksiyonu kullanılarak hazırlanan basit bir versiyonu aşağıdadır:
# ggplotu başlat
ggplot(mapping = aes(x = age, fill = gender)) +
# kadın histogram
geom_histogram(data = linelist %>% filter(gender == "f"),
breaks = seq(0,85,5),
colour = "white") +
# erkek histogram (veriler negatife çevrilecek)
geom_histogram(data = linelist %>% filter(gender == "m"),
breaks = seq(0,85,5),
mapping = aes(y = ..count..*(-1)),
colour = "white") +
# X ve Y eksenlerini çevir
coord_flip() +
# sayım ekseni ölçeğini ayarla
scale_y_continuous(limits = c(-600, 900),
breaks = seq(-600,900,100),
labels = abs(seq(-600, 900, 100)))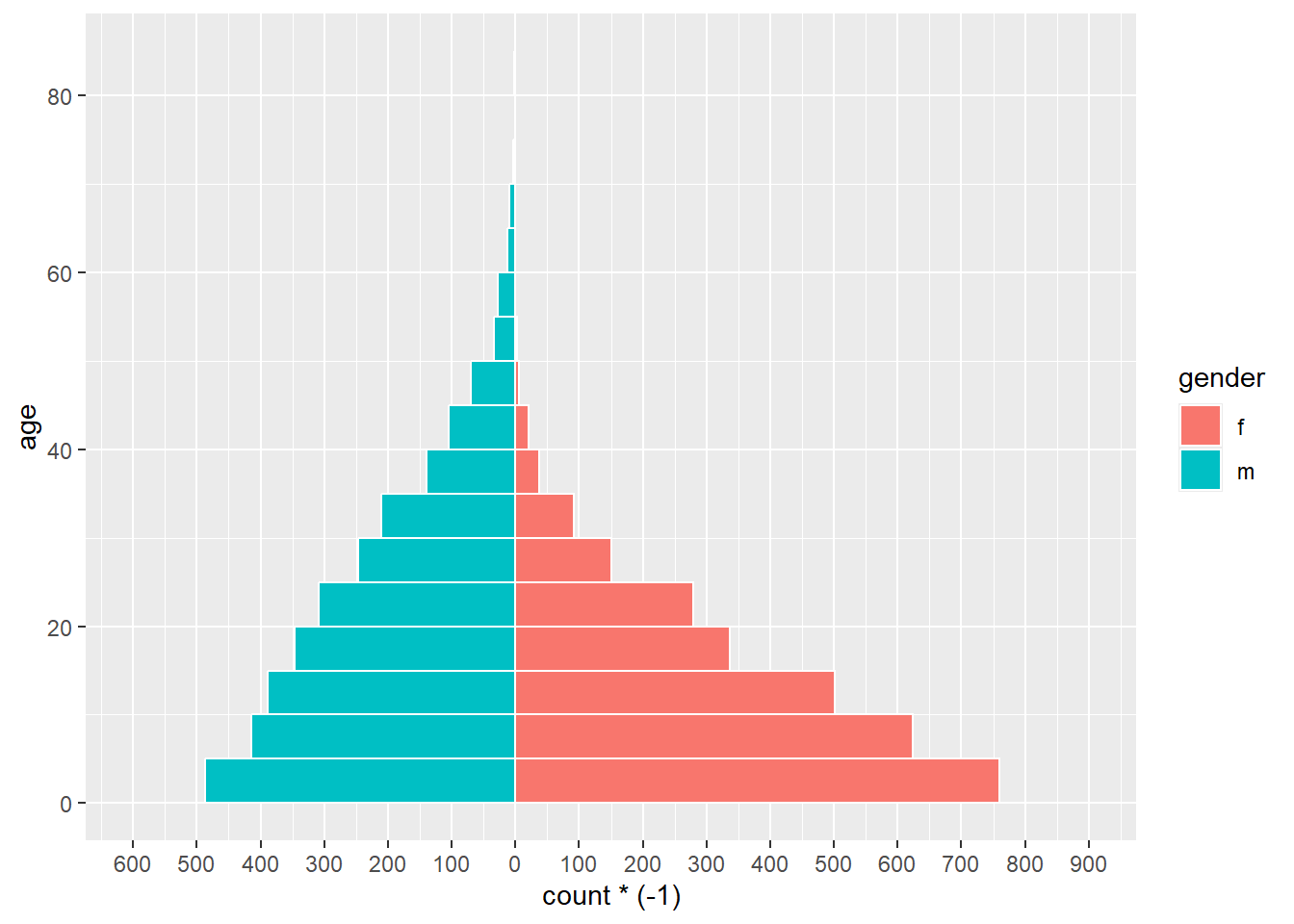
TEHLİKE: Sayım ekseninizin sınırları çok düşük ayarlanmışsa ve bir sayım çubuğu bunları aşarsa, çubuk tamamen kaybolur veya yapay olarak kısaltılır! Rutin olarak güncellenen verileri analiz ediyorsanız buna dikkat etmelisiniz. Sayım ekseni sınırlarınızın aşağıdaki gibi verilerinize göre otomatik olarak ayarlanmasını sağlayarak bunu önleyebilirsiniz.
Bu basit versiyonda değiştirebileceğiniz/ekleyebileceğiniz pek çok şey vardır:
Sayıları yüzdelere dönüştürme
Sayıları yüzdelere (toplamına göre) dönüştürmek için, hazırlıklarınızı çizimden önce yapmanız gerekmektedir. Aşağıda, yeni yüzde sütunları oluşturmak için yaş-cinsiyet sayılarını, ungroup() ve ardından mutate() fonksiyonlarını kullanıyoruz. Cinsiyete göre yüzdeleri istiyorsanız, ungroup() adımını atlayabilirsiniz.
# toplama göre oranlamak için veri kümesi oluştur
pyramid_data <- linelist %>%
count(age_cat5,
gender,
name = "counts") %>%
ungroup() %>% # grubu çöz, böylece yüzdeler gruba göre belirlenmesin
mutate(percent = round(100*(counts / sum(counts, na.rm=T)), digits = 1),
percent = case_when(
gender == "f" ~ percent,
gender == "m" ~ -percent, # erkeği negatife çevir
TRUE ~ NA_real_)) # NA değeri de sayısal olmalıdırDaha da önemlisi, maksimum ve minimum değerleri kaydederek ölçeğin sınırlarının ne olması gerektiğini biliriz. Bunlar aşağıdaki ggplot() komutunda kullanılacaktır.
max_per <- max(pyramid_data$percent, na.rm=T)
min_per <- min(pyramid_data$percent, na.rm=T)
max_per[1] 10.9min_per[1] -7.1Son olarak yüzde verisi üzerinde ggplot() komutunu kullanıyoruz. Önceden tanımlı uzunlukları her yönde (pozitif ve “negatif”) uzatmak için scale_y_continuous() fonksiyonunu tanımlıyoruz. Ondalık sayıları eksenin kenarı için uygun yöne (aşağı veya yukarı) yuvarlamak için floor() ve ceiling() argümanlarını kullanırız.
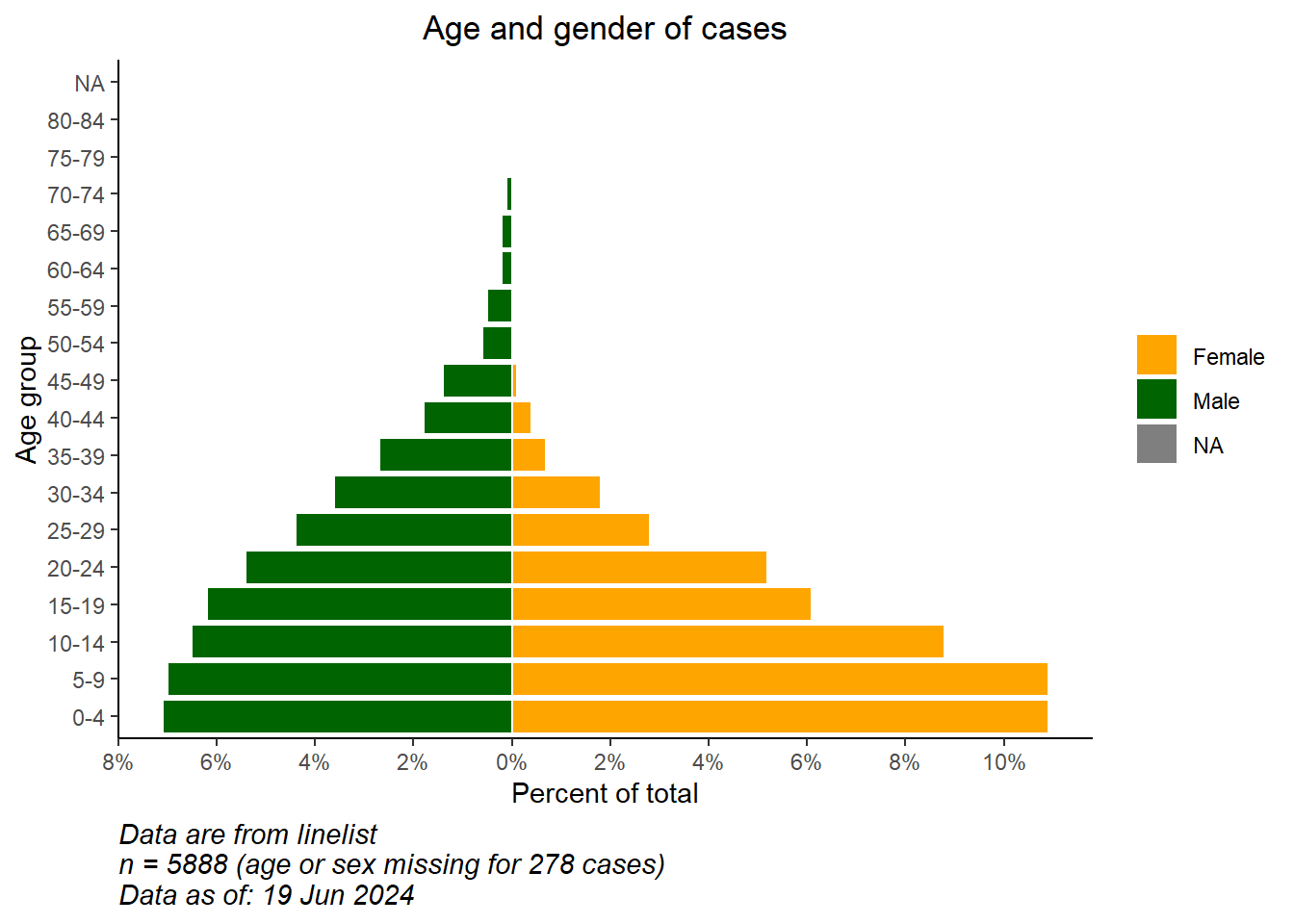
# ggplot başlangıcı
ggplot()+ # varsayılan x ekseni, yıl cinsinden yaştır;
# vaka veri grafiği
geom_col(data = pyramid_data,
mapping = aes(
x = age_cat5,
y = percent,
fill = gender),
colour = "white")+ # her çubuğun etrafı beyaz
# piramidi dikey yapmak için X ve Y eksenlerini çevir
coord_flip()+
# eksen boyunu düzenle
# scale_x_continuous(breaks = seq(0,100,5), labels = seq(0,100,5)) +
scale_y_continuous(
limits = c(min_per, max_per),
breaks = seq(from = floor(min_per), # 2s ile değer dizisi
to = ceiling(max_per),
by = 2),
labels = paste0(abs(seq(from = floor(min_per), # mutlak değerler dizisi, 2s ile, "%" ile
to = ceiling(max_per),
by = 2)),
"%"))+
#renkleri ve açıklama etiketlerini manuel olarak belirle
scale_fill_manual(
values = c("f" = "orange",
"m" = "darkgreen"),
labels = c("Female", "Male")) +
# etiket değerleri (şimdi X ve Y'nin çevrildiğini unutmayın)
labs(
title = "Age and gender of cases",
x = "Age group",
y = "Percent of total",
fill = NULL,
caption = stringr::str_glue("Data are from linelist \nn = {nrow(linelist)} (age or sex missing for {sum(is.na(linelist$gender) | is.na(linelist$age_years))} cases) \nData as of: {format(Sys.Date(), '%d %b %Y')}")) +
# temayı görüntüle
theme(
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.background = element_blank(),
axis.line = element_line(colour = "black"),
plot.title = element_text(hjust = 0.5),
plot.caption = element_text(hjust=0, size=11, face = "italic")
)
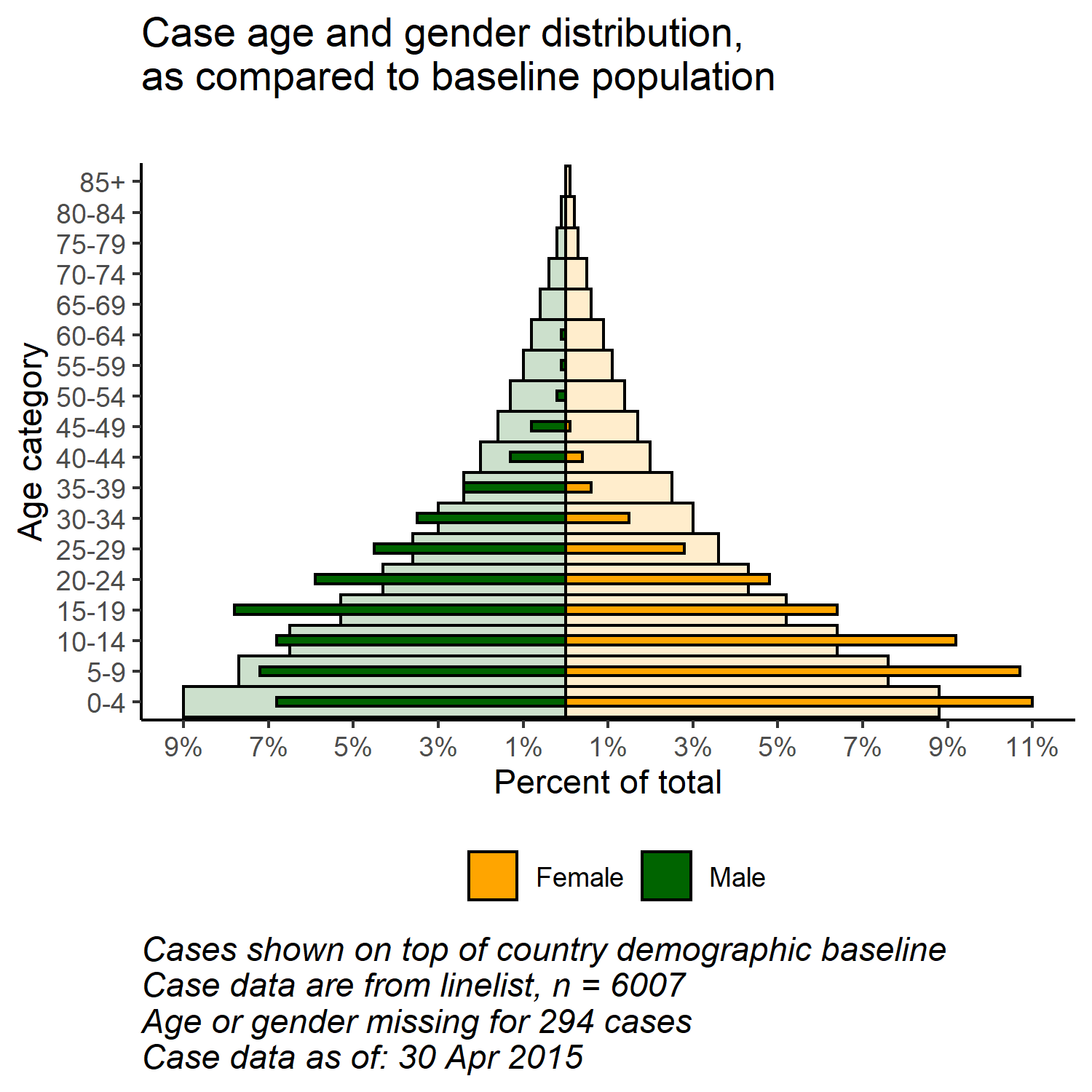
ggplot()un esnekliğiyle, arka planda “gerçek” veya “baz” nüfus piramidini temsil eden ikinci bir çubuk katmanına sahip olabilirsiniz. Bu, gözlemlenenleri taban çizgisiyle karşılaştırmak için güzel bir görselleştirme sağlayabilir.
Nüfus verilerini içe aktarın ve görüntüleyin (bkz. [El kitabını ve verileri indirin] sayfası):
# nüfus demografisi verilerini içe aktar
pop <- rio::import("country_demographics.csv")İlk önce bazı veri yönetimi adımları:
Burada görünmesini istediğimiz yaş kategorilerinin sırasını kaydediyoruz. ggplot()un uygulanma biçimindeki bazı tuhaflıklar nedeniyle, bu özel senaryoda bunları bir karakter vektörü olarak saklamak ve daha sonra çizim işlevinde kullanmak en kolay yoldur.
# doğru yaş kategorisi seviyelerini kaydedin
age_levels <- c("0-4","5-9", "10-14", "15-19", "20-24",
"25-29","30-34", "35-39", "40-44", "45-49",
"50-54", "55-59", "60-64", "65-69", "70-74",
"75-79", "80-84", "85+")Popülasyon ve vaka verilerini dplyr paketinden bind_rows() fonksiyonu aracılığıyla birleştirin:
bind_rows())# toplamın yüzdesi ile nüfus verilerini oluştur/dönüştür
########################################################
pop_data <- pop %>%
pivot_longer( # cinsiyet sütunlarını long formatına döndür
cols = c(m, f),
names_to = "gender",
values_to = "counts") %>%
mutate(
percent = round(100*(counts / sum(counts, na.rm=T)),1), # % of total
percent = case_when(
gender == "f" ~ percent,
gender == "m" ~ -percent, # erkek ise, %'yi negatife çevir
TRUE ~ NA_real_))Değiştirilen nüfus veri kümesini gözden geçirin
Şimdi aynısını vaka satır listesi için uygulayın. Burada durum biraz farklıdır çünkü veriler vaka satırlarıyla başlıyor, sayılarla değil.
# toplamın yüzdesi ile yaşa/cinsiyete göre vaka verileri oluştur
#######################################################
case_data <- linelist %>%
count(age_cat5, gender, name = "counts") %>% # yaş-cinsiyet gruplarına göre say
ungroup() %>%
mutate(
percent = round(100*(counts / sum(counts, na.rm=T)),1), # yaş-cinsiyet grupları için toplamın yüzdesini hesapla
percent = case_when( # erkek ise %'yi negatife çevir
gender == "f" ~ percent,
gender == "m" ~ -percent,
TRUE ~ NA_real_))Değiştirilen vaka veri kümesini gözden geçirin
Şimdi iki veri çerçevesi, biri diğerinin üzerinde olacak şekilde birleştirilmiştir (aynı sütun adlarına sahiptirler). Veri çerçevesinin her birini yeniden “adlandırabiliriz” ve her satırın hangi veri çerçevesinden kaynaklandığını gösterecek yeni bir “veri_kaynağı” sütunu oluşturmak için .id = argümanını kullanabiliriz. Bu sütunu daha sonrasında ggplot() içinde filtrelemek için kullanabiliriz.
# vaka ve popülasyon verilerini birleştir (aynı sütun adları, age_cat değerleri ve cinsiyet değerleri)
pyramid_data <- bind_rows("cases" = case_data, "population" = pop_data, .id = "data_source")Çizimin kapsamını tanımlamak için çizim işlevinde kullanılan maksimum ve minimum yüzde değerlerini saklayabilirsiniz (ve herhangi bir çubuğu daha kısa kesmeyin!)
# Çizim sınırları için kullanılan yüzde ekseninin kapsamını tanımla
max_per <- max(pyramid_data$percent, na.rm=T)
min_per <- min(pyramid_data$percent, na.rm=T)Şimdi grafik ggplot() ile hazırlanabilir:
# ggplot'u başlat
##############
ggplot()+ # varsayılan x ekseni, yıl cinsinden yaştır;
# nüfus veri grafiği
geom_col(
data = pyramid_data %>% filter(data_source == "population"),
mapping = aes(
x = age_cat5,
y = percent,
fill = gender),
colour = "black", # çubukların etrafındaki siyah renk
alpha = 0.2, # daha şeffaf
width = 1)+ # tam genişlik
# vaka veri grafiği
geom_col(
data = pyramid_data %>% filter(data_source == "cases"),
mapping = aes(
x = age_cat5, # orijinal X ekseni olarak yaş kategorileri
y = percent, # orijinal Y ekseni olarak %
fill = gender), # cinsiyete göre çubukların doldurulması
colour = "black", # çubukların etrafındaki siyah renk
alpha = 1, # opak
width = 0.3)+ # yarım genişlik
# piramidi dikey yapmak için X ve Y eksenlerini çevir
coord_flip()+
# yaş ekseninin doğru sıralandığından manuel olarak emin ol
scale_x_discrete(limits = age_levels)+ # yukarıdaki parçada tanımlanmış
# yüzde ekseni ayarla
scale_y_continuous(
limits = c(min_per, max_per), # yukarıda tanımlanan min ve max
breaks = seq(floor(min_per), ceiling(max_per), by = 2), # min%'den maksimum% 2'ye
labels = paste0( # etiketler için birlikte yapıştır...
abs(seq(floor(min_per), ceiling(max_per), by = 2)), "%"))+
# renkleri ve açıklama etiketlerini manuel olarak belirle
scale_fill_manual(
values = c("f" = "orange", # verilerdeki değerlere renk ata
"m" = "darkgreen"),
labels = c("f" = "Female",
"m"= "Male"), # göstergede görünen etiketleri değiştir, not sırası
) +
# grafik etiketleri, başlıklar, başlık
labs(
title = "Case age and gender distribution,\nas compared to baseline population",
subtitle = "",
x = "Age category",
y = "Percent of total",
fill = NULL,
caption = stringr::str_glue("Cases shown on top of country demographic baseline\nCase data are from linelist, n = {nrow(linelist)}\nAge or gender missing for {sum(is.na(linelist$gender) | is.na(linelist$age_years))} cases\nCase data as of: {format(max(linelist$date_onset, na.rm=T), '%d %b %Y')}")) +
# opsiyonel estetik ayarlamalar
theme(
legend.position = "bottom", # açıklamayı aşağıya taşı
panel.grid.major = element_blank(),
panel.grid.minor = element_blank(),
panel.background = element_blank(),
axis.line = element_line(colour = "black"),
plot.title = element_text(hjust = 0),
plot.caption = element_text(hjust=0, size=11, face = "italic"))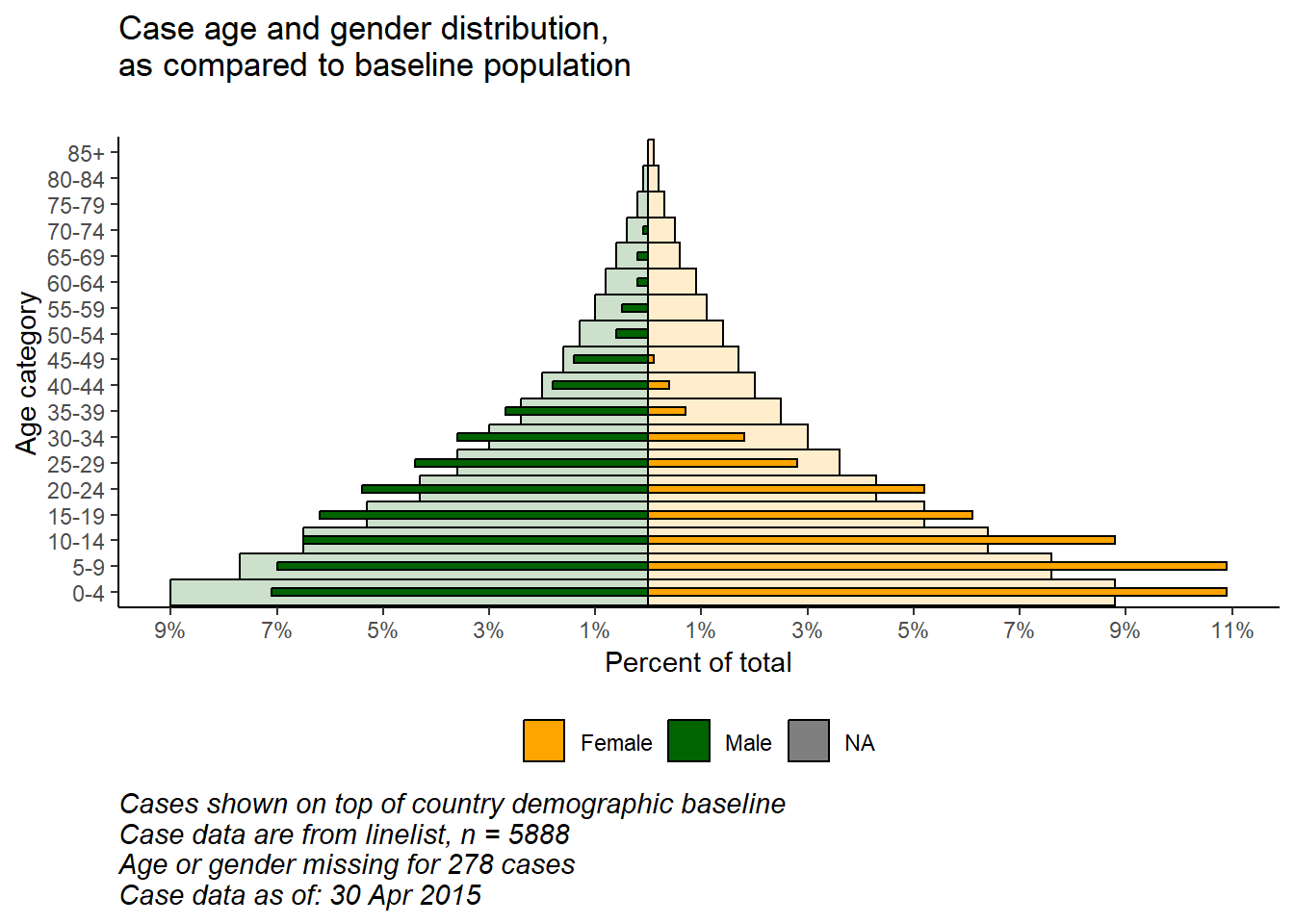
‘ggplot()’ ile bir nüfus piramidi yapmak için kullanılan teknikler, Likert ölçekli anket verilerinin çizimlerini yapmak için de kullanılabilir.
Verileri içe aktarın ([El kitabını ve verileri indir] sayfasına bakabilirsiniz).
# likert anketi yanıt verilerini içe aktar
likert_data <- rio::import("likert_data.csv")Her katılımcının kategorik bir sınıflandırması (status) ve 4 puanlı Likert tipi bir ölçekte 8 soruya verdikleri yanıtlara (“Çok kötü”, “Kötü”, “İyi”, “Çok iyi”) ait verileri ele alacağız.
İlk olarak, veri yönetimi adımları:
pivot_longer fonksiyonuyla alt gruplarına döndürmedirection sütunu oluşturmastatus sütunu ve Response sütunu için Faktör düzeyi sırasını ayarlamamelted <- likert_data %>%
pivot_longer(
cols = Q1:Q8,
names_to = "Question",
values_to = "Response") %>%
mutate(
direction = case_when(
Response %in% c("Poor","Very Poor") ~ "Negative",
Response %in% c("Good", "Very Good") ~ "Positive",
TRUE ~ "Unknown"),
status = fct_relevel(status, "Junior", "Intermediate", "Senior"),
# çalışması için 'Çok Zayıf' ve 'Zayıf' kelimeleri tersine çevirilmelidir
Response = fct_relevel(Response, "Very Good", "Good", "Very Poor", "Poor"))
# ölçek limitleri için en büyük değeri al
melted_max <- melted %>%
count(status, Question) %>% # sayıları al
pull(n) %>% # sütunu 'n'i
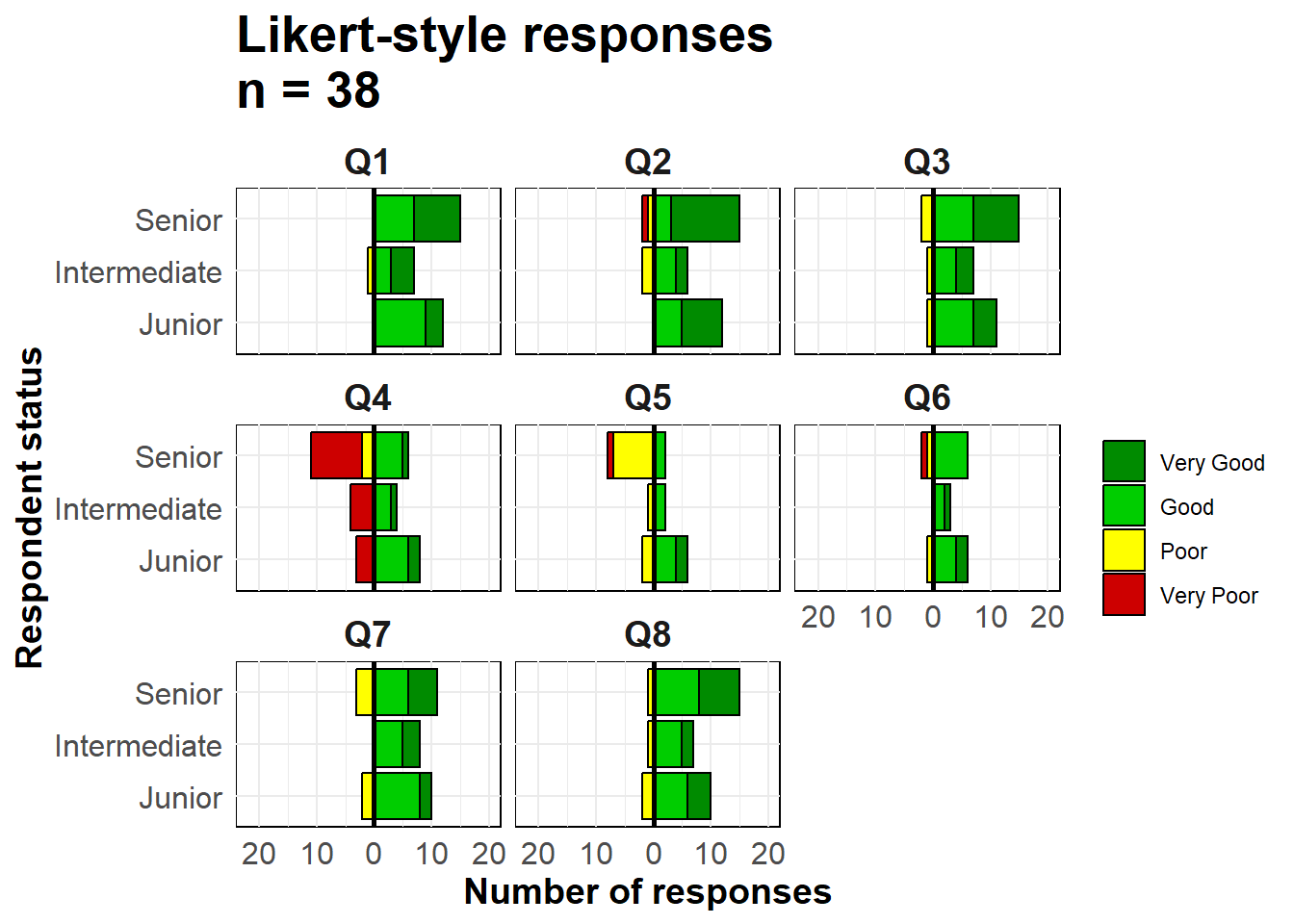
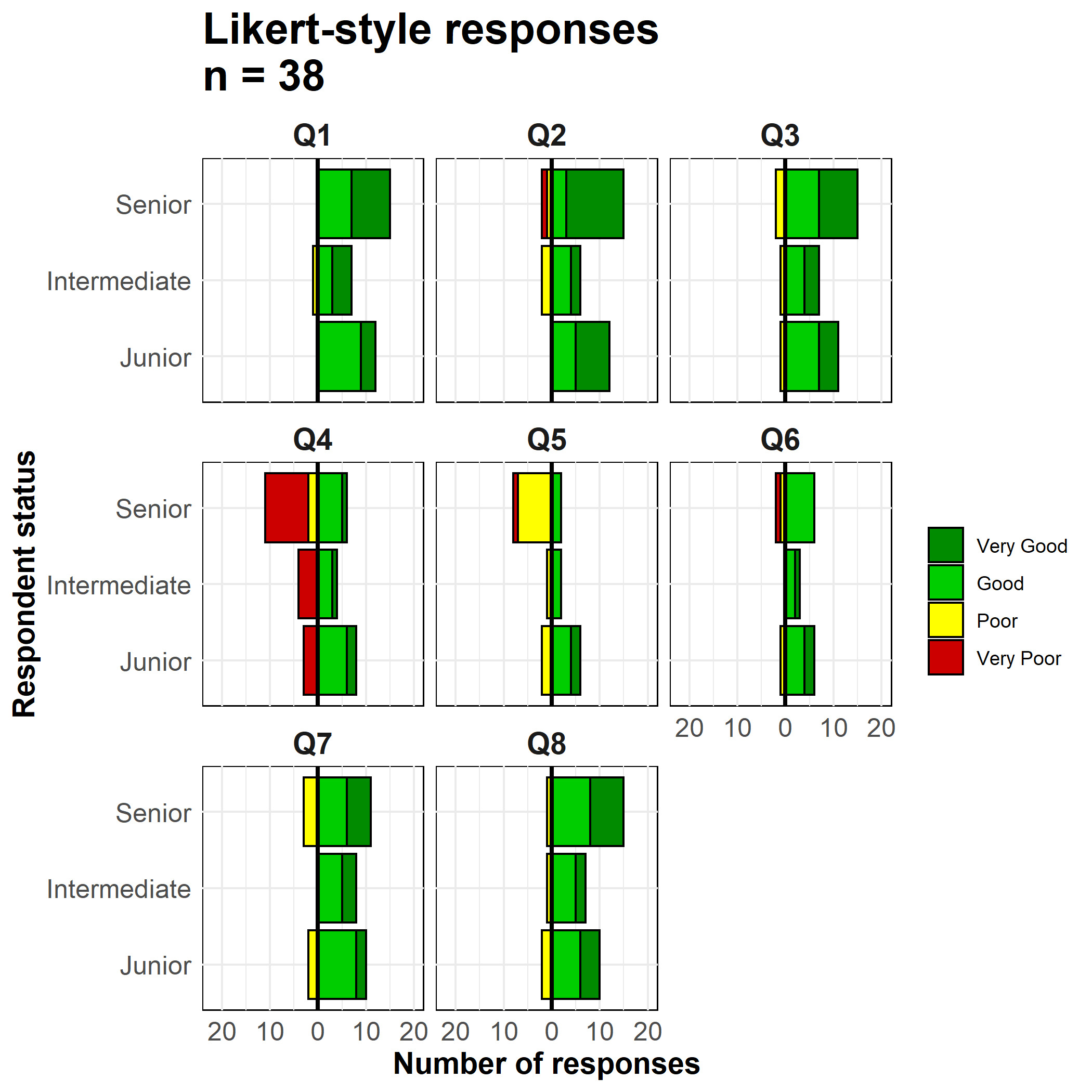
max(na.rm=T) # maksimumu alŞimdi grafiği hazırlayabiliriz. Yukarıdaki yaş piramitlerinde olduğu gibi iki çubuk grafiği oluşturuyoruz ve bunlardan birinin değerlerini negatife çeviriyoruz.
geom_bar() fonksiyonunu kullanıyoruz çünkü verilerimiz toplu sayı olarak değil, gözlem başına bir satır olacak şekilde düzenlendi. Negatif değerleri (-1) tersine çevirmek için çubuk grafiklerden birinde özel ggplot2 terimi olan ..count..u ve değerlerin üstüne eklenmesi için position = "stack" argümanını kullanıyoruz.
# garfiği hazırla
ggplot()+
# "olumsuz" yanıtların çubuk grafiği
geom_bar(
data = melted %>% filter(direction == "Negative"),
mapping = aes(
x = status,
y = ..count..*(-1), # negatife çevrilen sayımlar
fill = Response),
color = "black",
closed = "left",
position = "stack")+
# "olumlu" yanıtların çubuk grafiği
geom_bar(
data = melted %>% filter(direction == "Positive"),
mapping = aes(
x = status,
fill = Response),
colour = "black",
closed = "left",
position = "stack")+
# X ve Y eksenlerini çevirin
coord_flip()+
# 0'da siyah dikey çizgi
geom_hline(yintercept = 0, color = "black", size=1)+
# etiketlerin tümünü pozitif sayılara dönüştür
scale_y_continuous(
# x ekseni ölçeğinin sınırları
limits = c(-ceiling(melted_max/10)*11, # 10 ile negatiften pozitife doğru sıra, kenarlar dışa doğru en yakın 5'e yuvarlanır
ceiling(melted_max/10)*10),
# x ekseni ölçeğinin değerleri
breaks = seq(from = -ceiling(melted_max/10)*10,
to = ceiling(melted_max/10)*10,
by = 10),
# x ekseni ölçeğinin etiketleri
labels = abs(unique(c(seq(-ceiling(melted_max/10)*10, 0, 10),
seq(0, ceiling(melted_max/10)*10, 10))))) +
# manuel olarak atanan renk skalaları
scale_fill_manual(
values = c("Very Good" = "green4", # renk ata
"Good" = "green3",
"Poor" = "yellow",
"Very Poor" = "red3"),
breaks = c("Very Good", "Good", "Poor", "Very Poor"))+ # açıklamanın sırası
# tüm grafiği şekillendirin, böylece her soru bir alt grafik olur
facet_wrap( ~ Question, ncol = 3)+
# etiketler, başlıklar, başlık
labs(
title = str_glue("Likert-style responses\nn = {nrow(likert_data)}"),
x = "Respondent status",
y = "Number of responses",
fill = "")+
# görselin ayarları
theme_minimal()+
theme(axis.text = element_text(size = 12),
axis.title = element_text(size = 14, face = "bold"),
strip.text = element_text(size = 14, face = "bold"), # alt başlıklar
plot.title = element_text(size = 20, face = "bold"),
panel.background = element_rect(fill = NA, color = "black")) # her metin etrafındaki siyah çerçeve